本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 Amazon Bedrock 代理和知识库开发基于聊天的全自动助手
乔俊东、曹帅、诺亚·汉密尔顿、Kiowa Jackson、Praveen Kumar Jeyarajan 和 Amazon Web Services 的 Kara Yang
摘要
许多组织在创建能够协调各种数据源以提供全面答案的基于聊天的助手时面临挑战。这种模式为开发基于聊天的助手提供了一种解决方案,该助手能够回答来自文档和数据库的查询,并且部署简单。
从 A mazon Bedrock 开始,这项完全托管的生成式人工智能 (AI) 服务提供了各种高级基础模型 (FMs)。这有助于高效创建生成式 AI 应用程序,重点关注隐私和安全。在文档检索的背景下,检索增强生成 (RAG) 是一项关键功能。它使用知识库使用来自外部来源的上下文相关信息来扩充调频提示。A mazon OpenSearch Serverless 索引充当 Amazon Bedrock 知识库背后的矢量数据库。通过仔细的及时工程来增强这种集成,以最大限度地减少不准确之处,并确保答复以事实文档为基础。对于数据库查询,Amazon Bedrock 将文本查询转换为包含特定参数的结构化 SQL 查询。 FMs 这使得可以从 AWS Glue 数据库管理的数据库中精确检索数据。这些@@ 查询使用亚马逊 A thena。
要处理更复杂的查询,要获得全面的答案,就需要来自文档和数据库的信息。Amazon Bedrock 代理是一项生成式 AI 功能,可帮助您构建能够理解复杂任务的自主代理,并将其分解为更简单的任务进行编排。在 Amazon Bedrock 自主代理的推动下,将从简化任务中检索到的见解相结合,增强了信息的合成,从而得出了更全面和详尽的答案。此模式演示了如何使用 Amazon Bedrock 以及自动解决方案中的相关生成人工智能服务和功能来构建基于聊天的助手。
先决条件和限制
先决条件
限制
此解决方案部署至单个 Amazon Web Services account。
此解决方案只能部署在支持 Amazon Bedrock 和 Amazon OpenSearch Serverless 的 AWS 区域。有关更多信息,请参阅 Amazon B edrock 和 Amazon OpenSearch Serverless 的文档。
产品版本
llama-Index 版本 0.10.6 或更高版本
Sqlalchemy 版本 2.0.23 或更高版本
openSearch-py 版本 2.4.2 或更高版本
requests_aws4Auth 版本 1.2.3 或更高版本
适用于 Python 的 AWS 开发工具包 (Boto3) SDK 版本 1.34.57 或更高版本
架构
目标技术堆栈
AWS Cloud Development Kit (AWS CDK) 是一个开源软件开发框架,用于在代码中定义云基础设施并通过 AWS CloudFormation 进行配置。此模式中使用的 AWS CDK 堆栈部署以下 AWS 资源:
AWS Key Management Service(AWS KMS)
Amazon Simple Storage Service(Amazon S3)
AWS Glue 数据目录,适用于 AWS Glue 数据库组件
AWS Lambda
AWS Identity and Access Management (IAM)
Amazon OpenSearch 无服务器
Amazon Elastic Container Registry(Amazon ECR)
Amazon Elastic Container Service(Amazon ECS)
AWS Fargate
Amazon Virtual Private Cloud(Amazon VPC)
目标架构
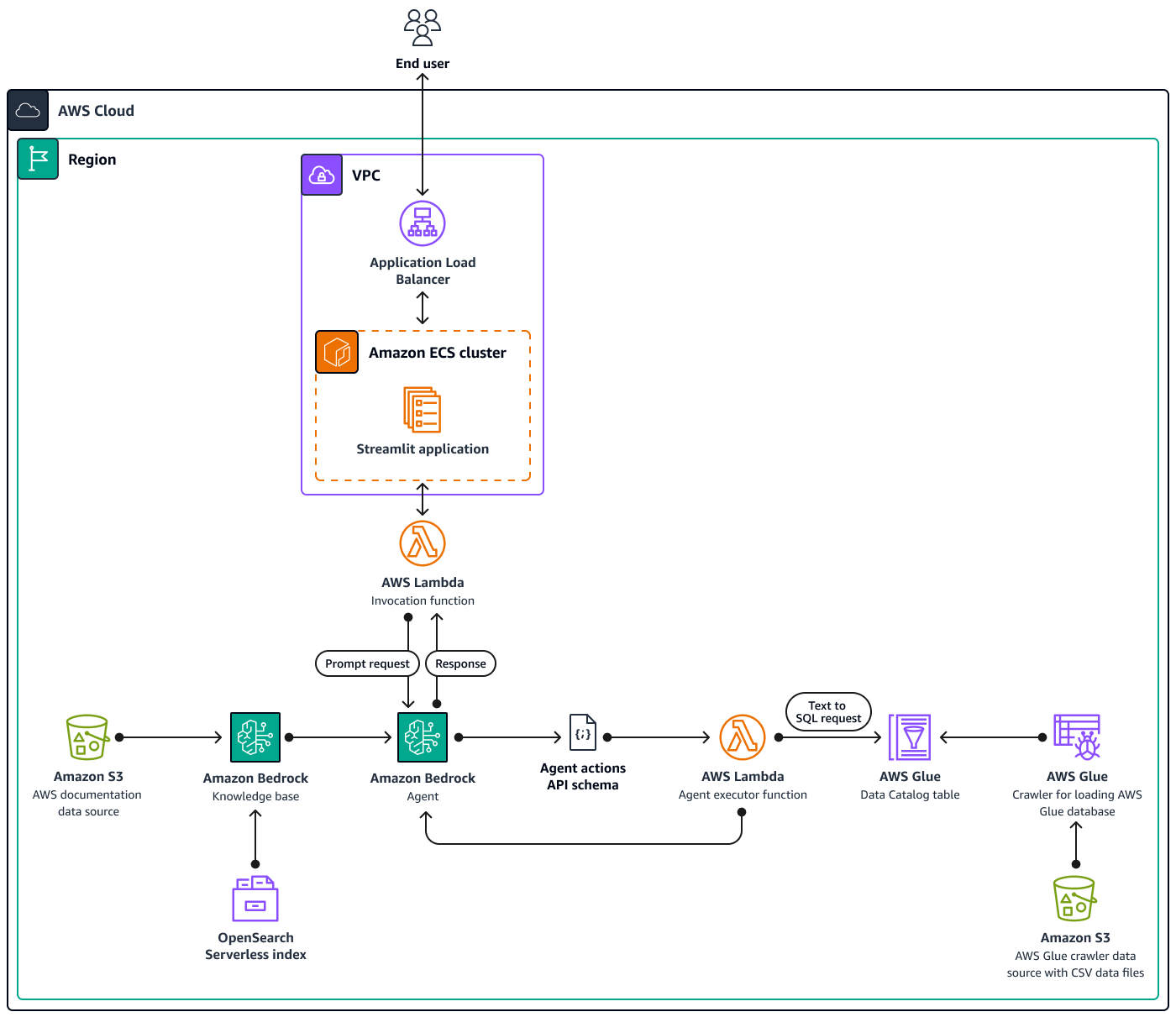
该图显示了在单个 AWS 区域内使用多个 AWS 服务的全面的 AWS 云原生设置。基于聊天的助手的主要界面是托管在 Amazon ECS 集群上的 StreamlitInvocation Lambda 函数,然后该函数与 Amazon Bedrock 的代理进行交互。该代理通过查阅 Amazon Bedrock 的知识库或调用 Lambda 函数Agent executor来回应用户的询问。此函数按照预定义的 API 架构触发一组与代理关联的操作。Amazon Bedrock 的知识库使用 OpenSearch 无服务器索引作为其矢量数据库的基础。此外,该Agent executor函数还会生成通过 Amazon Athena 对 AWS Glue 数据库执行的 SQL 查询。
工具
Amazon Web Services
Amazon Athena 是一种交互式查询服务,使您可使用标准 SQL 直接分析 Amazon Simple Storage Service(Amazon S3)中的数据。
Amazon Bedrock 是一项完全托管的服务,它通过统一的 API 提供来自领先的人工智能初创公司和亚马逊的高性能基础模型 (FMs) 供您使用。
AWS Cloud Development Kit (AWS CDK) 是一个软件开发框架,可帮助您在代码中定义和预调配 Amazon Web Services Cloud 基础设施。
AWS 命令行界面 (AWS CLI) L ine AWS CLI 是一款开源工具,可帮助您通过命令行外壳中的命令与 AWS 服务进行交互。
Amazon Elastic Container Service (Amazon ECS)是一项快速且可扩展的容器管理服务,可帮助运行、停止和管理集群上的容器。
弹性负载均衡(ELB) 将传入的应用程序或网络流量分配到多个目标。例如,您可以跨亚马逊弹性计算云 (Amazon EC2) 实例、容器以及一个或多个可用区中的 IP 地址分配流量。
AWS Glue 是一项完全托管的提取、转换、加载(ETL)服务。它可以帮助您在数据存储和数据流之间对数据进行可靠地分类、清理、扩充和移动。此模式使用 AWS Glue 爬网程序与 AWS Glue Data Catalog 表。
AWS Lambda 是一项计算服务,可帮助您运行代码,而无需预置或管理服务器。它仅在需要时运行您的代码,并且能自动扩缩,因此您只需为使用的计算时间付费。
Amazon OpenSearch Server less 是亚马逊 OpenSearch 服务的按需无服务器配置。在这种模式下, OpenSearch 无服务器索引充当 Amazon Bedrock 知识库的矢量数据库。
Amazon Simple Storage Service (Amazon S3) 是一项基于云的对象存储服务,可帮助您存储、保护和检索任意数量的数据。
其他工具
Streamlit
是一个用于创建数据应用程序的开源 Python 框架。
代码存储库
此模式的代码可在 GitHub genai-bedrock-agent-chatbot
assetsfolder-静态资产,例如架构图和公共数据集。code/lambdas/action-lambda文件夹 — 用作 Amazon Bedrock 代理操作的 Lambda 函数的 Python 代码。code/lambdas/create-index-lambda文件夹 — 用于创建 OpenSearch 无服务器索引的 Lambda 函数的 Python 代码。code/lambdas/invoke-lambda文件夹 — 调用 Amazon Bedrock 代理的 Lambda 函数的 Python 代码,该代理直接从 Streamlit 应用程序调用。code/lambdas/update-lambda文件夹 — Lambda 函数的 Python 代码,用于在通过 AWS CDK 部署 AWS 资源后更新或删除资源。code/layers/boto3_layer文件夹 — AWS CDK 堆栈,用于创建在所有 Lambda 函数之间共享的 Boto3 层。code/layers/opensearch_layer文件夹 — 创建 OpenSearch 无服务器层的 AWS CDK 堆栈,该层安装所有依赖项以创建索引。code/streamlit-app文件夹 — 在 Amazon ECS 中作为容器镜像运行的 Python 代码code/code_stack.py— AWS CDK 构建用于创建 AWS 资源的 Python 文件。app.py— 在目标 AWS 账户中部署 AWS 资源的 AWS CDK 堆栈 Python 文件。requirements.txt— 必须为 AWS CDK 安装的所有 Python 依赖项的列表。cdk.json— 用于提供创建资源所需的值的输入文件。此外,在context/config字段中,您可以相应地自定义解决方案。有关自定义的更多信息,请参阅 “其他信息” 部分。
最佳实践
此处提供的代码示例仅用于 proof-of-concept (PoC) 或试运行目的。如果要将代码投入生产环境,请务必使用以下最佳实践:
启用 VPC 流日志
为 Lambda 函数设置监控和警报。有关更多信息,请参阅 Lambda 函数监控和故障排除。有关最佳实践,请参阅使用 AWS Lambda 函数的最佳实践。
操作说明
| Task | 描述 | 所需技能 |
|---|---|---|
导出账户和地区的变量。 | 要使用环境变量为 AWS CDK 提供 AWS 凭证,请运行以下命令。
| AWS DevOps, DevOps 工程师 |
设置名为 “配置文件” 的 AWS CLI。 | 要为账户设置名为 profile 的 AWS CLI,请按照配置和凭证文件设置中的说明进行操作。 | AWS DevOps, DevOps 工程师 |
| Task | 描述 | 所需技能 |
|---|---|---|
将存储库克隆到您的本地工作站。 | 要克隆存储库,请在终端中运行以下命令。
| DevOps 工程师,AWS DevOps |
设置 Python 虚拟环境。 | 要设置 Python 虚拟环境,请运行以下命令。
要设置所需的依赖关系,请运行以下命令。
| DevOps 工程师,AWS DevOps |
设置 AWS CDK 环境。 | 要将代码转换为 AWS CloudFormation 模板,请运行命令 | AWS DevOps, DevOps 工程师 |
| Task | 描述 | 所需技能 |
|---|---|---|
在账户中部署资源。 | 要使用 AWS CDK 在 AWS 账户中部署资源,请执行以下操作:
成功部署后,您可以使用控制台输出选项卡上提供的 URL 访问基于聊天的助手应用程序。 CloudFormation | DevOps 工程师,AWS DevOps |
| Task | 描述 | 所需技能 |
|---|---|---|
移除 AWS 资源。 | 测试解决方案后,要清理资源,请运行命令 | AWS DevOps, DevOps 工程师 |
相关资源
AWS 文档
Amazon Bedrock 资源:
AWS CDK 资源:
其他 AWS 资源
其他资源
其他信息
使用您自己的数据自定义基于聊天的助手
要整合用于部署解决方案的自定义数据,请遵循以下结构化指南。这些步骤旨在确保无缝高效的集成流程,使您能够使用定制数据有效地部署解决方案。
用于知识库数据集成
数据准备
找到该
assets/knowledgebase_data_source/目录。将您的数据集放在此文件夹中。
配置调整
打开
cdk.json文件。导航到该
context/configure/paths/knowledgebase_file_name字段,然后相应地对其进行更新。导航到该
bedrock_instructions/knowledgebase_instruction字段,然后对其进行更新以准确反映新数据集的细微差别和上下文。
用于结构数据集成
数据组织
在该
assets/data_query_data_source/目录中,创建一个子目录,例如。tabular_data将您的结构化数据集(可接受的格式包括 CSV、JSON、ORC 和 Parquet)放入这个新创建的子文件夹。
如果您要连接到现有数据库,请更新
create_sql_engine()中的函数code/lambda/action-lambda/build_query_engine.py以连接到您的数据库。
配置和代码更新
在
cdk.json文件中,更新context/configure/paths/athena_table_data_prefix字段以使其与新的数据路径保持一致。code/lambda/action-lambda/dynamic_examples.csv通过加入与您的数据集对应的新 text-to-SQL示例进行修改。修改
code/lambda/action-lambda/prompt_templates.py以反映结构化数据集的属性。在
cdk.json文件中,更新context/configure/bedrock_instructions/action_group_description字段以解释Action groupLambda 函数的目的和功能。在
assets/agent_api_schema/artifacts_schema.json文件中,解释您的 LambdAction groupa 函数的新功能。
一般更新
在cdk.json文件中,考虑到新整合的数据,在该context/configure/bedrock_instructions/agent_instruction部分中,全面描述了Amazon Bedrock代理的预期功能和设计目的。
