Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Konfiguration von AWS DataSync Übertragungen mit Amazon S3
Um Daten zu oder von Ihrem Amazon S3 S3-Bucket zu übertragen, erstellen Sie einen AWS DataSync Übertragungsort. DataSync kann diesen Speicherort als Quelle oder Ziel für die Übertragung von Daten verwenden.
Bereitstellung des DataSync Zugriffs auf S3-Buckets
DataSync benötigt Zugriff auf den S3-Bucket, in den oder von dem Sie übertragen. Dazu müssen Sie eine AWS Identity and Access Management (IAM-) Rolle erstellen, die über die für DataSync den Zugriff auf den Bucket erforderlichen Berechtigungen verfügt. Diese Rolle geben Sie dann an, wenn Sie Ihren Amazon S3 S3-Standort für erstellen DataSync.
Inhalt
Erforderliche Berechtigungen
Die Berechtigungen, die Ihre IAM-Rolle benötigt, können davon abhängen, ob es sich bei dem Bucket um einen DataSync Quell- oder Zielspeicherort handelt. Für Amazon S3 on Outposts sind andere Berechtigungen erforderlich.
Erstellen einer IAM-Rolle für den Zugriff DataSync auf Ihren Amazon S3 S3-Standort
Wenn Sie Ihren Amazon S3 S3-Standort in der Konsole erstellen, DataSync können Sie automatisch eine IAM-Rolle erstellen und annehmen, die normalerweise über die richtigen Berechtigungen für den Zugriff auf Ihren S3-Bucket verfügt.
In einigen Situationen müssen Sie diese Rolle möglicherweise manuell erstellen (z. B. für den Zugriff auf Buckets mit zusätzlichen Sicherheitsebenen oder für die Übertragung zu oder von einem Bucket in einem anderen AWS-Konten).
Öffnen Sie unter https://console.aws.amazon.com/iam/
die IAM-Konsole. -
Wählen Sie im linken Navigationsbereich unter Zugriffsverwaltung die Option Rollen und dann Rolle erstellen aus.
-
Wählen Sie auf der Seite Vertrauenswürdige Entität auswählen für Vertrauenswürdigen Entitätstyp die Option AWS-Service.
-
Wählen Sie DataSyncin der Dropdownliste für Anwendungsfall die Option aus und wählen Sie aus DataSync. Wählen Sie Weiter aus.
-
Wählen Sie auf der Seite Add permissions (Berechtigungen hinzufügen) die Option Next (Weiter) aus. Geben Sie Ihrer Rolle einen Namen und wählen Sie Rolle erstellen.
-
Suchen Sie auf der Seite Rollen nach der Rolle, die Sie gerade erstellt haben, und wählen Sie ihren Namen aus.
-
Wählen Sie auf der Detailseite der Rolle den Tab Berechtigungen aus. Wählen Sie Berechtigungen hinzufügen und dann Inline-Richtlinie erstellen aus.
-
Wählen Sie die Registerkarte JSON und fügen Sie die für den Zugriff auf Ihren Bucket erforderlichen Berechtigungen zum Richtlinieneditor hinzu.
-
Wählen Sie Weiter aus. Geben Sie Ihrer Richtlinie einen Namen und wählen Sie Richtlinie erstellen aus.
-
(Empfohlen) Gehen Sie wie folgt vor, um das dienstübergreifende Problem mit verwirrten Stellvertretern zu vermeiden:
-
Wählen Sie auf der Detailseite der Rolle die Registerkarte Vertrauensbeziehungen aus. Wählen Sie Vertrauensrichtlinie bearbeiten aus.
-
Aktualisieren Sie die Vertrauensrichtlinie anhand des folgenden Beispiels, das die Kontextschlüssel
aws:SourceArnund dieaws:SourceAccountglobalen Bedingungsschlüssel enthält: -
Wählen Sie Richtlinie aktualisieren.
-
Sie können diese Rolle bei der Erstellung Ihres Amazon S3 S3-Standorts angeben.
Zugriff auf S3-Buckets mithilfe serverseitiger Verschlüsselung
DataSync kann Daten zu oder von S3-Buckets übertragen, die serverseitige Verschlüsselung verwenden. Die Art des Verschlüsselungsschlüssels, den ein Bucket verwendet, kann bestimmen, ob Sie eine benutzerdefinierte Richtlinie für den DataSync Zugriff auf den Bucket benötigen.
Beachten Sie bei der Verwendung DataSync mit S3-Buckets, die serverseitige Verschlüsselung verwenden, Folgendes:
-
Wenn Ihr S3-Bucket mit einem AWS verwalteten Schlüssel verschlüsselt ist, DataSync können Sie standardmäßig auf die Objekte des Buckets zugreifen, wenn sich alle Ihre Ressourcen im selben Bucket befinden. AWS-Konto
-
Wenn Ihr S3-Bucket mit einem vom Kunden verwalteten AWS Key Management Service (AWS KMS) Schlüssel (SSE-KMS) verschlüsselt ist, muss die Richtlinie des Schlüssels die IAM-Rolle enthalten, die für den Zugriff auf den Bucket DataSync verwendet wird.
-
Wenn Ihr S3-Bucket mit einem vom Kunden verwalteten SSE-KMS-Schlüssel verschlüsselt ist und sich in einem anderen AWS-Konto befindet, ist eine Zugriffsberechtigung für den Bucket im anderen DataSync erforderlich. AWS-Konto Sie können dies wie folgt einrichten:
-
In der DataSync verwendeten IAM-Rolle müssen Sie den SSE-KMS-Schlüssel des kontoübergreifenden Buckets angeben, indem Sie den vollqualifizierten Amazon-Ressourcennamen (ARN) des Schlüssels verwenden. Dies ist derselbe Schlüssel-ARN, den Sie verwenden, um die Standardverschlüsselung des Buckets zu konfigurieren. In dieser Situation können Sie keine Schlüssel-ID, keinen Aliasnamen oder einen Alias-ARN angeben.
Hier ist ein Beispiel für einen Schlüssel-ARN:
arn:aws:kms:us-west-2:111122223333:key/1234abcd-12ab-34cd-56ef-1234567890abWeitere Informationen zur Angabe von KMS-Schlüsseln in IAM-Richtlinienerklärungen finden Sie im AWS Key Management Service Entwicklerhandbuch.
-
Geben Sie in der SSE-KMS-Schlüsselrichtlinie die IAM-Rolle an, die von verwendet wird. DataSync
-
-
Wenn Ihr S3-Bucket mit einem vom Kunden verwalteten AWS KMS Schlüssel (DSSE-KMS) für die serverseitige Dual-Layer-Verschlüsselung verschlüsselt ist, muss die Richtlinie des Schlüssels die IAM-Rolle enthalten, die für den Zugriff auf den Bucket verwendet wird. DataSync (Beachten Sie, dass DSSE-KMS keine S3-Bucket-Keys unterstützt, wodurch die Anforderungskosten gesenkt werden können.) AWS KMS
-
Wenn Ihr S3-Bucket mit einem vom Kunden bereitgestellten Verschlüsselungsschlüssel (SSE-C) verschlüsselt ist, DataSync können Sie nicht auf diesen Bucket zugreifen.
Das folgende Beispiel ist eine Schlüsselrichtlinie für einen vom Kunden verwalteten SSE-KMS-Schlüssel. Die Richtlinie ist einem S3-Bucket zugeordnet, der serverseitige Verschlüsselung verwendet.
Wenn Sie dieses Beispiel verwenden möchten, ersetzen Sie die folgenden Werte durch Ihre eigenen:
-
account-id— Ihr AWS-Konto. -
admin-role-name— Der Name der IAM-Rolle, die den Schlüssel verwalten kann. -
datasync-role-name— Der Name der IAM-Rolle, die es ermöglicht, den Schlüssel beim Zugriff auf den Bucket DataSync zu verwenden.
Zugriff auf eingeschränkte S3-Buckets
Wenn Sie zu oder von einem S3-Bucket wechseln müssen, der normalerweise jeglichen Zugriff verweigert, können Sie die Bucket-Richtlinie so bearbeiten, dass nur für Ihre Übertragung auf den Bucket zugegriffen werden DataSync kann.
-
Kopieren Sie die folgende S3-Bucket-Richtlinie.
-
Ersetzen Sie in der Richtlinie die folgenden Werte:
-
amzn-s3-demo-bucket -
datasync-iam-role-idFühren Sie den folgenden AWS CLI Befehl aus, um die IAM-Rollen-ID abzurufen:
aws iam get-role --role-namedatasync-iam-role-nameSuchen Sie in der Ausgabe nach dem
RoleIdWert:"RoleId": "ANPAJ2UCCR6DPCEXAMPLE" -
your-iam-role-idFühren Sie den folgenden Befehl aus, um die IAM-Rollen-ID abzurufen:
aws iam get-role --role-nameyour-iam-role-nameSuchen Sie in der Ausgabe nach dem
RoleIdWert:"RoleId": "AIDACKCEVSQ6C2EXAMPLE"
-
-
Fügen Sie diese Richtlinie zu Ihrer S3-Bucket-Richtlinie hinzu.
-
Wenn Sie den eingeschränkten Bucket nicht mehr verwenden DataSync , entfernen Sie die Bedingungen für beide IAM-Rollen aus der Bucket-Richtlinie.
Zugriff auf S3-Buckets mit eingeschränktem VPC-Zugriff
Ein Amazon S3 S3-Bucket, der den Zugriff auf bestimmte Virtual Private Cloud (VPC) -Endpunkte einschränkt oder VPCs die Übertragung zu oder DataSync von diesem Bucket verweigert. Um Übertragungen in diesen Situationen zu ermöglichen, können Sie die Richtlinie des Buckets so aktualisieren, dass sie die IAM-Rolle enthält, die Sie mit Ihrem Standort angeben. DataSync
Überlegungen zur Speicherklasse bei Amazon S3 S3-Übertragungen
Wenn Amazon S3 Ihr Zielort ist, DataSync können Sie Ihre Daten direkt in eine bestimmte Amazon S3 S3-Speicherklasse
Einige Speicherklassen weisen Verhaltensweisen auf, die sich auf Ihre Amazon S3 S3-Speicherkosten auswirken können. Wenn Sie Speicherklassen verwenden, für die zusätzliche Gebühren für das Überschreiben, Löschen oder Abrufen von Objekten anfallen können, führen Änderungen an Objektdaten oder Metadaten zu solchen Gebühren. Weitere Informationen finden Sie unter Amazon S3 – Preise
Wichtig
Neue Objekte, die an Ihren Amazon S3 S3-Zielort übertragen werden, werden mit der Speicherklasse gespeichert, die Sie bei der Erstellung Ihres Standorts angeben.
Standardmäßig wird die Speicherklasse vorhandener Objekte an Ihrem Zielort DataSync beibehalten, sofern Sie Ihre Aufgabe nicht so konfigurieren, dass alle Daten übertragen werden. In diesen Situationen wird die Speicherklasse, die Sie bei der Erstellung Ihres Standorts angeben, für alle Objekte verwendet.
| Amazon S3 S3-Speicherklasse | Überlegungen |
|---|---|
| S3 Standard | Wählen Sie S3 Standard, um Ihre häufig aufgerufenen Dateien redundant in mehreren Availability Zones zu speichern, die geografisch getrennt sind. Dies ist die Standardeinstellung, wenn Sie keine Speicherklasse angeben. |
| S3 Intelligent-Tiering |
Wählen Sie S3 Intelligent-Tiering, um die Speicherkosten zu optimieren, indem Sie Daten automatisch zur kostengünstigsten Speicherzugriffsstufe verschieben. Sie zahlen eine monatliche Gebühr pro Objekt, das in der Speicherklasse S3 Intelligent-Tiering gespeichert ist. Diese Amazon S3 S3-Gebühr beinhaltet die Überwachung von Datenzugriffsmustern und das Verschieben von Objekten zwischen Stufen. |
| S3 Standard-IA |
Wählen Sie S3 Standard-IA, um Ihre Objekte, auf die selten zugegriffen wird, redundant in mehreren Availability Zones zu speichern, die geografisch getrennt sind. Für Objekte, die in der Speicherklasse S3 Standard-IA gespeichert sind, können zusätzliche Gebühren für das Überschreiben, Löschen oder Abrufen anfallen. Bedenken Sie, wie oft diese Objekte geändert werden, wie lange Sie diese Objekte behalten möchten und wie oft Sie darauf zugreifen müssen. Änderungen an Objektdaten oder Metadaten entsprechen dem Löschen eines Objekts und dem Erstellen eines neuen Objekts, um es zu ersetzen. Dies führt zu zusätzlichen Gebühren für Objekte, die in der Speicherklasse S3 Standard-IA gespeichert sind. Objekte mit weniger als 128 KB unterschreiten die Mindestkapazitätsgebühr pro Objekt in der Speicherklasse S3 Standard-IA. Diese Objekte werden in der Speicherklasse S3 Standard gespeichert. |
| S3 One Zone-IA |
Wählen Sie S3 One Zone-IA, um Ihre selten aufgerufenen Objekte in einer einzigen Availability Zone zu speichern. Für Objekte, die in der Speicherklasse S3 One Zone-IA gespeichert sind, können zusätzliche Gebühren für das Überschreiben, Löschen oder Abrufen anfallen. Bedenken Sie, wie oft diese Objekte geändert werden, wie lange Sie diese Objekte behalten möchten und wie oft Sie darauf zugreifen müssen. Änderungen an Objektdaten oder Metadaten entsprechen dem Löschen eines Objekts und dem Erstellen eines neuen Objekts, um es zu ersetzen. Dies führt zu zusätzlichen Gebühren für Objekte, die in der Speicherklasse S3 One Zone-IA gespeichert sind. Objekte mit weniger als 128 KB unterschreiten die Mindestkapazitätsgebühr pro Objekt in der Speicherklasse S3 One Zone-IA. Diese Objekte werden in der Speicherklasse S3 Standard gespeichert. |
| S3 Glacier Instant Retrieval |
Wählen Sie S3 Glacier Instant Retrieval, um Objekte zu archivieren, auf die selten zugegriffen wird, die aber innerhalb von Millisekunden abgerufen werden müssen. Daten, die in der Speicherklasse S3 Glacier Instant Retrieval gespeichert sind, bieten Kosteneinsparungen im Vergleich zur Speicherklasse S3 Standard-IA bei gleicher Latenz und Durchsatzleistung. S3 Glacier Instant Retrieval hat jedoch höhere Datenzugriffskosten als S3 Standard-IA. Bei Objekten, die in S3 Glacier Instant Retrieval gespeichert sind, können zusätzliche Gebühren für das Überschreiben, Löschen oder Abrufen anfallen. Bedenken Sie, wie oft diese Objekte geändert werden, wie lange Sie diese Objekte behalten möchten und wie oft Sie darauf zugreifen müssen. Änderungen an Objektdaten oder Metadaten entsprechen dem Löschen eines Objekts und dem Erstellen eines neuen Objekts, um es zu ersetzen. Dies führt zu zusätzlichen Gebühren für Objekte, die in der Speicherklasse S3 Glacier Instant Retrieval gespeichert sind. Objekte mit weniger als 128 KB unterschreiten die Mindestkapazitätsgebühr pro Objekt in der Speicherklasse S3 Glacier Instant Retrieval. Diese Objekte werden in der Speicherklasse S3 Standard gespeichert. |
| S3 Glacier Flexible Retrieval | Wählen Sie S3 Glacier Flexible Retrieval für aktivere Archive. Bei Objekten, die in S3 Glacier Flexible Retrieval gespeichert sind, können zusätzliche Gebühren für das Überschreiben, Löschen oder Abrufen anfallen. Bedenken Sie, wie oft diese Objekte geändert werden, wie lange Sie diese Objekte behalten möchten und wie oft Sie darauf zugreifen müssen. Änderungen an Objektdaten oder Metadaten entsprechen dem Löschen eines Objekts und dem Erstellen eines neuen Objekts, um es zu ersetzen. Dies führt zu zusätzlichen Gebühren für Objekte, die in der Speicherklasse S3 Glacier Flexible Retrieval gespeichert sind. Die Speicherklasse S3 Glacier Flexible Retrieval erfordert 40 KB an zusätzlichen Metadaten für jedes archivierte Objekt. DataSync platziert Objekte, die weniger als 40 KB groß sind, in die Speicherklasse S3 Standard. Sie müssen in dieser Speicherklasse archivierte Objekte wiederherstellen, bevor Sie sie lesen DataSync können. Weitere Informationen finden Sie unter Arbeiten mit archivierten Objekten im Amazon S3 S3-Benutzerhandbuch.Wenn Sie S3 Glacier Flexible Retrieval verwenden, wählen Sie die Option Nur übertragene Daten verifizieren, um die Prüfsummen der Daten und Metadaten am Ende der Übertragung zu vergleichen. Sie können die Option Alle Daten im Ziel verifizieren für diese Speicherklasse nicht verwenden, da dafür alle vorhandenen Objekte vom Ziel abgerufen werden müssen. |
| S3 Glacier Deep Archive |
Wählen Sie S3 Glacier Deep Archive, um Ihre Objekte für die langfristige Datenspeicherung und digitale Aufbewahrung zu archivieren, wobei ein- oder zweimal pro Jahr auf Daten zugegriffen wird. Bei Objekten, die in S3 Glacier Deep Archive gespeichert sind, können zusätzliche Gebühren für das Überschreiben, Löschen oder Abrufen anfallen. Bedenken Sie, wie oft diese Objekte geändert werden, wie lange Sie diese Objekte behalten möchten und wie oft Sie darauf zugreifen müssen. Änderungen an Objektdaten oder Metadaten entsprechen dem Löschen eines Objekts und dem Erstellen eines neuen Objekts, um es zu ersetzen. Dies führt zu zusätzlichen Gebühren für Objekte, die in der Speicherklasse S3 Glacier Deep Archive gespeichert sind. Die Speicherklasse S3 Glacier Deep Archive benötigt 40 KB an zusätzlichen Metadaten für jedes archivierte Objekt. DataSync platziert Objekte, die weniger als 40 KB groß sind, in die Speicherklasse S3 Standard. Sie müssen in dieser Speicherklasse archivierte Objekte wiederherstellen, bevor Sie sie lesen DataSync können. Weitere Informationen finden Sie unter Arbeiten mit archivierten Objekten im Amazon S3 S3-Benutzerhandbuch. Wenn Sie S3 Glacier Deep Archive verwenden, wählen Sie die Aufgabenoption Nur übertragene Daten verifizieren, um die Daten- und Metadaten-Prüfsummen am Ende der Übertragung zu vergleichen. Sie können die Option Alle Daten im Ziel verifizieren für diese Speicherklasse nicht verwenden, da dafür alle vorhandenen Objekte vom Ziel abgerufen werden müssen. |
|
S3-Outposts |
Die Speicherklasse für Amazon S3 auf Outposts. |
Bewertung der Kosten für S3-Anfragen bei der Verwendung DataSync
Bei Amazon S3 S3-Standorten entstehen Ihnen Kosten im Zusammenhang mit S3-API-Anfragen von DataSync. In diesem Abschnitt erfahren Sie, wie diese Anfragen DataSync verwendet werden und wie sie sich auf Ihre Amazon S3 S3-Kosten
S3-Anfragen von DataSync
In der folgenden Tabelle werden die S3-Anfragen beschrieben, die beim Kopieren von Daten an oder von einem Amazon S3 S3-Standort gestellt werden DataSync können.
| S3-Anfrage | Wie DataSync benutzt es |
|---|---|
|
DataSync stellt mindestens eine |
|
DataSync stellt während der Vorbereitungs - und Überprüfungsphase einer Aufgabe |
|
|
DataSync stellt während der Übertragungsphase einer Aufgabe |
|
|
Wenn Sie Ihre Aufgabe so konfigurieren, dass sie Objekt-Tags kopiert, DataSync sendet diese |
|
|
DataSync stellt während der Übertragungsphase einer Aufgabe |
|
Wenn Ihre Quellobjekte über Tags verfügen und Sie Ihre Aufgabe so konfigurieren, dass Objekt-Tags kopiert werden, DataSync stellt diese |
|
|
DataSync |
Kostenüberlegungen
DataSync stellt jedes Mal, wenn Sie Ihre Aufgabe ausführen, S3-Anfragen an S3-Buckets. Dies kann dazu führen, dass sich die Gebühren in bestimmten Situationen summieren. Zum Beispiel:
-
Sie übertragen häufig Objekte in oder aus einem S3-Bucket.
-
Sie übertragen vielleicht nicht viele Daten, aber Ihr S3-Bucket enthält viele Objekte. In diesem Szenario können Sie immer noch hohe Gebühren feststellen, da DataSync S3-Anfragen für jedes Objekt des Buckets gestellt werden.
-
Sie übertragen zwischen S3-Buckets, ebenso DataSync wie S3-Anfragen an die Quelle und das Ziel.
Beachten Sie Folgendes, um die damit verbundenen Kosten für S3-Anfragen zu DataSync minimieren:
Welche S3-Speicherklassen verwende ich?
Die Gebühren für S3-Anfragen können je nach der Amazon S3 S3-Speicherklasse, die Ihre Objekte verwenden, variieren, insbesondere für Klassen, die Objekte archivieren (wie S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval und S3 Glacier Deep Archive).
Im Folgenden sind einige Szenarien aufgeführt, in denen sich Speicherklassen auf Ihre Gebühren für S3-Anfragen auswirken können, wenn Sie sie verwenden: DataSync
-
Stellt jedes Mal, wenn Sie eine Aufgabe ausführen, DataSync
HEADAnfragen zum Abrufen von Objektmetadaten. Diese Anfragen führen zu Gebühren, auch wenn Sie keine Objekte verschieben. Wie stark sich diese Anfragen auf Ihre Rechnung auswirken, hängt von der Speicherklasse ab, die Ihre Objekte verwenden, und von der Anzahl der Objekte, die DataSync gescannt werden. -
Wenn Sie Objekte in die Speicherklasse S3 Glacier Instant Retrieval verschoben haben (entweder direkt oder über eine Bucket-Lebenszykluskonfiguration), sind Anfragen für Objekte dieser Klasse teurer als Objekte in anderen Speicherklassen.
-
Wenn Sie Ihre DataSync Aufgabe so konfigurieren, dass überprüft wird, ob Ihre Quell- und Zielspeicherorte vollständig synchronisiert sind, werden
GETAnfragen für jedes Objekt in allen Speicherklassen (außer S3 Glacier Flexible Retrieval und S3 Glacier Deep Archive) gestellt. -
Zusätzlich zu
GETAnfragen fallen für Sie Kosten für den Datenabruf für Objekte der Speicherklasse S3 Standard-IA, S3 One Zone-IA oder S3 Glacier Instant Retrieval an.
Weitere Informationen finden Sie unter Amazon S3 – Preise
Wie oft muss ich meine Daten übertragen?
Wenn Sie Daten regelmäßig verschieben müssen, sollten Sie sich einen Zeitplan überlegen, in dem nicht mehr Aufgaben ausgeführt werden, als Sie benötigen.
Sie können auch erwägen, den Umfang Ihrer Übertragungen einzuschränken. Sie können beispielsweise so konfigurieren, dass der Fokus DataSync auf Objekte in bestimmten Präfixen liegt, oder Sie können filtern, welche Daten übertragen werden. Diese Optionen können dazu beitragen, die Anzahl der S3-Anfragen zu reduzieren, die bei jeder Ausführung Ihrer DataSync Aufgabe gestellt werden.
Überlegungen zu Objekten bei Amazon S3 S3-Übertragungen
-
Wenn Sie Daten aus einem S3-Bucket übertragen, verwenden Sie S3 Storage Lens, um zu ermitteln, wie viele Objekte Sie verschieben.
-
Bei der Übertragung zwischen S3-Buckets empfehlen wir, den erweiterten Aufgabenmodus zu verwenden, da für Sie keine DataSync Aufgabenkontingente gelten.
-
DataSync überträgt möglicherweise kein Objekt mit Sonderzeichen im Namen. Weitere Informationen finden Sie in den Richtlinien zur Benennung von Objektschlüsseln im Amazon S3 S3-Benutzerhandbuch.
-
Beachten Sie bei der Verwendung DataSync mit einem S3-Bucket, der Versionierung verwendet, Folgendes:
-
DataSync Erstellt bei der Übertragung in einen S3-Bucket eine neue Version eines Objekts, wenn dieses Objekt an der Quelle geändert wird. Dies führt zu zusätzlichen Gebühren.
-
Ein Objekt hat unterschiedliche Versionen IDs im Quell- und Ziel-Bucket.
-
-
Nach der anfänglichen Übertragung von Daten aus einem S3-Bucket in ein Dateisystem (z. B. NFS oder Amazon FSx) enthalten nachfolgende Ausführungen derselben DataSync Aufgabe keine Objekte, die geändert wurden, aber dieselbe Größe wie bei der ersten Übertragung haben.
Ihren Übertragungsort für einen Amazon S3 S3-Allzweck-Bucket erstellen
Um einen Standort für Ihre Übertragung zu erstellen, benötigen Sie einen vorhandenen S3-Allzweck-Bucket. Falls Sie noch keinen haben, finden Sie weitere Informationen im Amazon S3 S3-Benutzerhandbuch.
Wichtig
Bevor Sie Ihren Standort erstellen, stellen Sie sicher, dass Sie die folgenden Abschnitte gelesen haben:
Öffnen Sie die AWS DataSync Konsole unter https://console.aws.amazon.com/datasync/
. -
Erweitern Sie im linken Navigationsbereich die Option Datenübertragung und wählen Sie dann Standorte und Standort erstellen aus.
-
Wählen Sie als Standorttyp Amazon S3 und dann General Purpose Bucket aus.
-
Geben Sie für S3-URI den Bucket und das Präfix ein, das Sie für Ihren Standort verwenden möchten, oder wählen Sie es aus.
Warnung
DataSync kann keine Objekte übertragen, deren Präfix mit einem Schrägstrich (
/) beginnt oder/../Muster enthält//././Zum Beispiel:-
/photos -
photos//2006/January -
photos/./2006/February -
photos/../2006/March
-
-
Wählen Sie für S3-Speicherklasse bei Verwendung als Ziel eine Speicherklasse aus, die Ihre Objekte verwenden sollen, wenn Amazon S3 ein Übertragungsziel ist.
Weitere Informationen finden Sie unter Überlegungen zur Speicherklasse bei Amazon S3 S3-Übertragungen.
-
Führen Sie für IAM role (IAM-Rolle) einen der folgenden Schritte aus:
-
Wählen Sie Automatisch generieren für DataSync , um automatisch eine IAM-Rolle mit den für den Zugriff auf den S3-Bucket erforderlichen Berechtigungen zu erstellen.
Wenn Sie DataSync zuvor eine IAM-Rolle für diesen S3-Bucket erstellt haben, wird diese Rolle standardmäßig ausgewählt.
-
Wählen Sie eine benutzerdefinierte IAM-Rolle aus, die Sie erstellt haben. Weitere Informationen finden Sie unter Erstellen einer IAM-Rolle für den Zugriff DataSync auf Ihren Amazon S3 S3-Standort.
-
-
(Optional) Wählen Sie Neues Tag hinzufügen, um Ihren Amazon S3 S3-Standort zu kennzeichnen.
Mithilfe von Tags können Sie Ihre Ressourcen verwalten, filtern und suchen. Wir empfehlen, ein Namensschild für Ihren Standort zu erstellen.
-
Wählen Sie Standort erstellen.
-
Kopieren Sie den folgenden
create-location-s3Befehl:aws datasync create-location-s3 \ --s3-bucket-arn 'arn:aws:s3:::amzn-s3-demo-bucket' \ --s3-storage-class 'your-S3-storage-class' \ --s3-config 'BucketAccessRoleArn=arn:aws:iam::account-id:role/role-allowing-datasync-operations' \ --subdirectory /your-prefix-name -
Geben Sie für
--s3-bucket-arnden ARN des S3-Buckets an, den Sie als Speicherort verwenden möchten. -
Geben Sie für
--s3-storage-classeine Speicherklasse an, die Ihre Objekte verwenden sollen, wenn Amazon S3 ein Übertragungsziel ist. -
Geben Sie für
--s3-configden ARN der IAM-Rolle an, die auf Ihren Bucket zugreifen DataSync muss.Weitere Informationen finden Sie unter Erstellen einer IAM-Rolle für den Zugriff DataSync auf Ihren Amazon S3 S3-Standort.
-
Geben Sie für
--subdirectoryein Präfix im S3-Bucket an, aus dem DataSync gelesen oder geschrieben wird (je nachdem, ob es sich bei dem Bucket um einen Quell- oder Zielspeicherort handelt).Warnung
DataSync kann keine Objekte mit einem Präfix übertragen, das mit einem Schrägstrich (
/) beginnt oder/../Muster einschließt//././Zum Beispiel:-
/photos -
photos//2006/January -
photos/./2006/February -
photos/../2006/March
-
-
Führen Sie den Befehl
create-location-s3aus.Wenn der Befehl erfolgreich ist, erhalten Sie eine Antwort, die Ihnen den ARN des Speicherorts anzeigt, den Sie erstellt haben. Zum Beispiel:
{ "LocationArn": "arn:aws:datasync:us-east-1:111222333444:location/loc-0b3017fc4ba4a2d8d" }
Sie können diesen Speicherort als Quelle oder Ziel für Ihre DataSync Aufgabe verwenden.
Erstellen Sie Ihren Transferort für einen S3-Bucket auf Outposts
Um einen Standort für Ihre Übertragung zu erstellen, benötigen Sie einen vorhandenen Amazon S3 on Outposts-Bucket. Falls Sie noch keinen haben, finden Sie weitere Informationen im Amazon S3 on Outposts-Benutzerhandbuch.
Sie benötigen auch einen DataSync Agenten. Weitere Informationen finden Sie unter Bereitstellen Sie Ihren Agenten auf AWS Outposts.
Bei der Übertragung von einem S3-Bucket-Präfix auf Outposts, das einen großen Datensatz enthält (z. B. Hunderttausende oder Millionen von Objekten), kann es zu einem Timeout für Ihre DataSync Aufgabe kommen. Um dies zu vermeiden, sollten Sie ein DataSync Manifest verwenden, mit dem Sie genau die Objekte angeben können, die Sie übertragen müssen.
Öffnen Sie die AWS DataSync Konsole unter https://console.aws.amazon.com/datasync/
. -
Erweitern Sie im linken Navigationsbereich die Option Datenübertragung und wählen Sie dann Standorte und Standort erstellen aus.
-
Wählen Sie als Standorttyp Amazon S3 und dann Outposts Bucket aus.
-
Wählen Sie für den S3-Bucket einen Amazon S3 S3-Zugriffspunkt, der auf Ihren S3 on Outposts-Bucket zugreifen kann.
Weitere Informationen finden Sie im Amazon S3 S3-Benutzerhandbuch.
-
Wählen Sie für S3-Speicherklasse bei Verwendung als Ziel eine Speicherklasse aus, die Ihre Objekte verwenden sollen, wenn Amazon S3 ein Übertragungsziel ist.
Weitere Informationen finden Sie unterÜberlegungen zur Speicherklasse bei Amazon S3 S3-Übertragungen. DataSync verwendet standardmäßig die Speicherklasse S3 Outposts für Amazon S3 auf Outposts.
-
Geben Sie für Agenten den Amazon-Ressourcennamen (ARN) des DataSync Agenten in Ihrem Outpost an.
-
Geben Sie für Ordner ein Präfix im S3-Bucket ein, das aus oder DataSync in das geschrieben wird (je nachdem, ob es sich bei dem Bucket um einen Quell- oder Zielspeicherort handelt).
Warnung
DataSync kann keine Objekte mit einem Präfix übertragen, das mit einem Schrägstrich (
/) beginnt oder/../Muster einschließt//././Zum Beispiel:-
/photos -
photos//2006/January -
photos/./2006/February -
photos/../2006/March
-
-
Führen Sie für IAM role (IAM-Rolle) einen der folgenden Schritte aus:
-
Wählen Sie Automatisch generieren für DataSync , um automatisch eine IAM-Rolle mit den für den Zugriff auf den S3-Bucket erforderlichen Berechtigungen zu erstellen.
Wenn Sie DataSync zuvor eine IAM-Rolle für diesen S3-Bucket erstellt haben, wird diese Rolle standardmäßig ausgewählt.
-
Wählen Sie eine benutzerdefinierte IAM-Rolle aus, die Sie erstellt haben. Weitere Informationen finden Sie unter Erstellen einer IAM-Rolle für den Zugriff DataSync auf Ihren Amazon S3 S3-Standort.
-
-
(Optional) Wählen Sie Neues Tag hinzufügen, um Ihren Amazon S3 S3-Standort zu kennzeichnen.
Mithilfe von Tags können Sie Ihre Ressourcen verwalten, filtern und suchen. Wir empfehlen, ein Namensschild für Ihren Standort zu erstellen.
-
Wählen Sie Standort erstellen.
-
Kopieren Sie den folgenden
create-location-s3Befehl:aws datasync create-location-s3 \ --s3-bucket-arn 'bucket-access-point' \ --s3-storage-class 'your-S3-storage-class' \ --s3-config 'BucketAccessRoleArn=arn:aws:iam::account-id:role/role-allowing-datasync-operations' \ --subdirectory /your-folder\ --agent-arns 'arn:aws:datasync:your-region:account-id::agent/agent-agent-id' -
Geben Sie für
--s3-bucket-arnden ARN einen Amazon S3 S3-Zugriffspunkt an, der auf Ihren S3 on Outposts-Bucket zugreifen kann.Weitere Informationen finden Sie im Amazon S3 S3-Benutzerhandbuch.
-
Geben Sie für
--s3-storage-classeine Speicherklasse an, die Ihre Objekte verwenden sollen, wenn Amazon S3 ein Übertragungsziel ist.Weitere Informationen finden Sie unterÜberlegungen zur Speicherklasse bei Amazon S3 S3-Übertragungen. DataSync verwendet standardmäßig die Speicherklasse S3 Outposts für S3 auf Outposts.
-
Geben Sie für
--s3-configden ARN der IAM-Rolle an, die auf Ihren Bucket zugreifen DataSync muss.Weitere Informationen finden Sie unter Erstellen einer IAM-Rolle für den Zugriff DataSync auf Ihren Amazon S3 S3-Standort.
-
Geben Sie für
--subdirectoryein Präfix im S3-Bucket an, aus dem DataSync gelesen oder geschrieben wird (je nachdem, ob es sich bei dem Bucket um einen Quell- oder Zielspeicherort handelt).Warnung
DataSync kann keine Objekte mit einem Präfix übertragen, das mit einem Schrägstrich (
/) beginnt oder/../Muster einschließt//././Zum Beispiel:-
/photos -
photos//2006/January -
photos/./2006/February -
photos/../2006/March
-
-
Geben Sie für
--agent-arnsden ARN des DataSync Agenten in Ihrem Outpost an. -
Führen Sie den Befehl
create-location-s3aus.Wenn der Befehl erfolgreich ist, erhalten Sie eine Antwort, die Ihnen den ARN des Speicherorts anzeigt, den Sie erstellt haben. Zum Beispiel:
{ "LocationArn": "arn:aws:datasync:us-east-1:111222333444:location/loc-0b3017fc4ba4a2d8d" }
Sie können diesen Speicherort als Quelle oder Ziel für Ihre DataSync Aufgabe verwenden.
Amazon S3 S3-Übertragungen zwischen AWS-Konten
Mit DataSync können Sie Daten in verschiedene AWS-Konten S3-Buckets verschieben. Weitere Informationen finden Sie in den folgenden Tutorials:
Amazon S3 S3-Übertragungen zwischen kommerziellen und AWS GovCloud (US) Regions
Standardmäßig werden DataSync keine Übertragungen zwischen S3-Buckets im kommerziellen und AWS GovCloud (US) Regions. Sie können diese Art der Übertragung jedoch trotzdem einrichten, indem Sie einen Objektspeicherort für einen der S3-Buckets in Ihrer Übertragung erstellen. Sie können diese Art der Übertragung mit oder ohne Agenten durchführen. Wenn Sie einen Agenten verwenden, muss Ihre Aufgabe für den Basismodus konfiguriert sein. Um ohne Agenten zu übertragen, müssen Sie den erweiterten Modus verwenden.
Bevor Sie beginnen: Vergewissern Sie sich, dass Sie die Kosten verstehen, die eine Übertragung zwischen Regionen mit sich bringt. Weitere Informationen finden Sie unter AWS DataSync
– Preise
Inhalt
Bereitstellung des DataSync Zugriffs auf den Bucket Ihres Objektspeichers
Wenn Sie den Objektspeicherort für diese Übertragung erstellen, müssen Sie DataSync die Anmeldeinformationen eines IAM-Benutzers angeben, der berechtigt ist, auf den S3-Bucket des Standorts zuzugreifen. Weitere Informationen finden Sie unter Erforderliche Berechtigungen.
Warnung
IAM-Benutzer verfügen über langfristige Anmeldeinformationen, was ein Sicherheitsrisiko darstellt. Um dieses Risiko zu minimieren, empfehlen wir, diesen Benutzern nur die Berechtigungen zu gewähren, die sie für die Ausführung der Aufgabe benötigen, und diese Benutzer zu entfernen, wenn sie nicht mehr benötigt werden.
Erstellen Sie Ihren DataSync Agenten (optional)
Wenn Sie Ihre Übertragung im Basismodus ausführen möchten, müssen Sie einen Agenten verwenden. Da Sie zwischen einer kommerziellen und einer anderen wechseln AWS GovCloud (US) Region, setzen Sie Ihren DataSync Agenten als EC2 Amazon-Instance in einer der Regionen ein. Wir empfehlen, dass Ihr Agent einen VPC-Serviceendpunkt verwendet, um Gebühren für die Datenübertragung ins öffentliche Internet zu vermeiden. Weitere Informationen finden Sie unter Amazon EC2 Data Transfer — Preise
Wählen Sie eines der folgenden Szenarien, in denen beschrieben wird, wie Sie einen Agenten erstellen, der auf der Region basiert, in der Sie Ihre DataSync Aufgabe ausführen möchten.
Das folgende Diagramm zeigt eine Übertragung, bei der sich Ihre DataSync Aufgabe und Ihr Agent in der Handelsregion befinden.
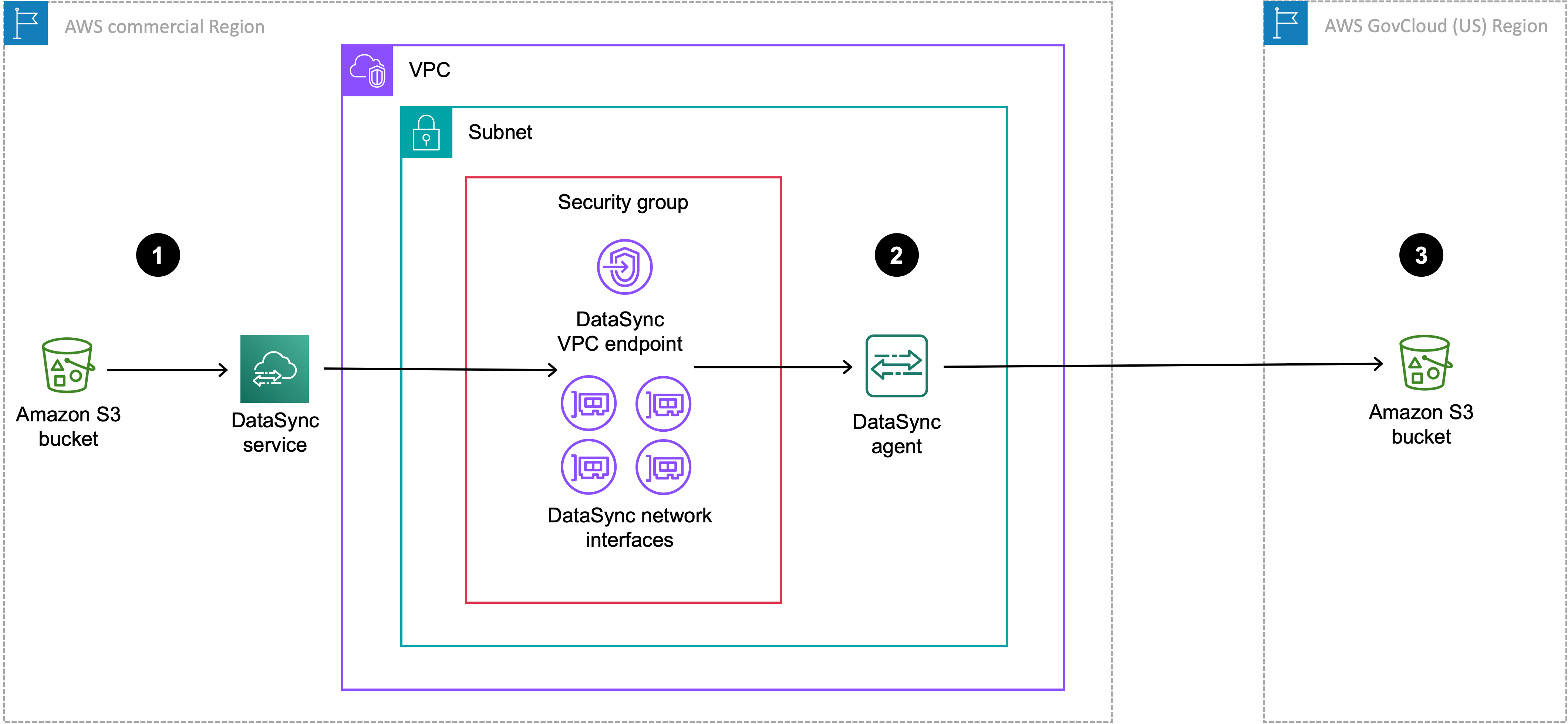
| Referenz | Beschreibung |
|---|---|
| 1 | In der kommerziellen Region, in der Sie eine DataSync Aufgabe ausführen, werden Daten aus dem S3-Quell-Bucket übertragen. Der Quell-Bucket ist als Amazon S3 S3-Standort in der Handelsregion konfiguriert. |
| 2 | Datenübertragungen über den DataSync Agenten, der sich in derselben VPC und demselben Subnetz befindet, in denen sich der VPC-Dienstendpunkt und die Netzwerkschnittstellen befinden. |
| 3 | Datenübertragungen an den Ziel-S3-Bucket im. AWS GovCloud (US) Region Der Ziel-Bucket ist als Objektspeicherort in der Handelsregion konfiguriert. |
Sie können dasselbe Setup verwenden, um auch die umgekehrte Richtung von der Region in die kommerzielle Region AWS GovCloud (US) Region zu übertragen.
Um Ihren DataSync Agenten zu erstellen
-
Stellen Sie einen EC2 Amazon-Agenten in Ihrer Handelsregion bereit.
-
Konfigurieren Sie Ihren Agenten für die Verwendung eines VPC-Serviceendpunkts.
Das folgende Diagramm zeigt eine Übertragung, bei der sich Ihre DataSync Aufgabe und Ihr Agent in der AWS GovCloud (US) Region
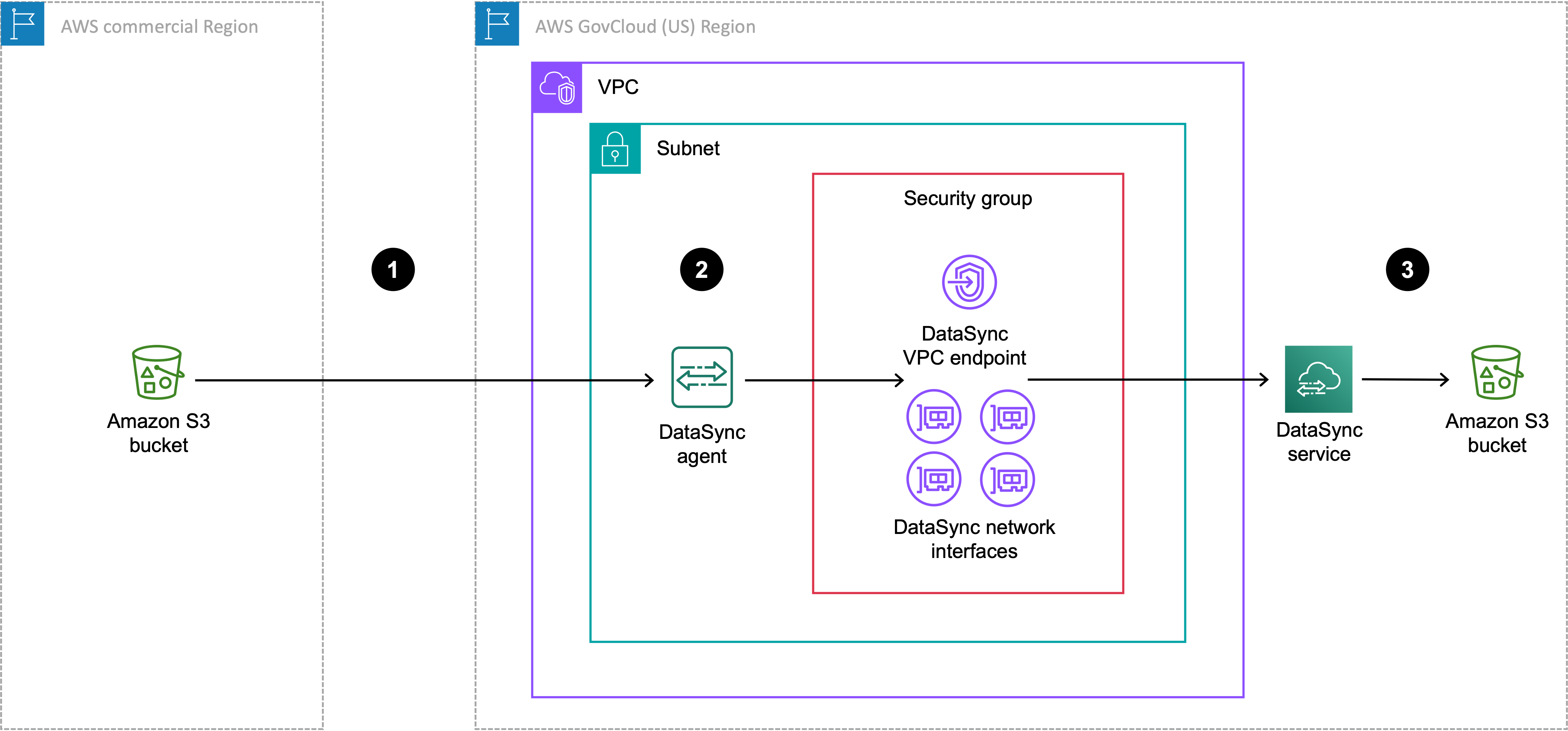
| Referenz | Beschreibung |
|---|---|
| 1 | Datenübertragungen vom S3-Quell-Bucket in der Handelsregion zu dem AWS GovCloud (US) Region Ort, an dem Sie eine DataSync Aufgabe ausführen. Der Quell-Bucket ist als Objektspeicherort im konfiguriert AWS GovCloud (US) Region. |
| 2 | In der AWS GovCloud (US) Region, Datenübertragungen über den DataSync Agenten in derselben VPC und demselben Subnetz, in dem sich der VPC-Dienstendpunkt und die Netzwerkschnittstellen befinden. |
| 3 | Datenübertragungen an den Ziel-S3-Bucket im. AWS GovCloud (US) Region Der Ziel-Bucket ist als Amazon S3 S3-Standort in der konfiguriert AWS GovCloud (US) Region. |
Sie können dasselbe Setup verwenden, um auch die umgekehrte Richtung von der AWS GovCloud (US) Region zur Handelsregion zu übertragen.
Um Ihren DataSync Agenten zu erstellen
-
Stellen Sie einen EC2 Amazon-Agenten in Ihrem bereit AWS GovCloud (US) Region.
-
Konfigurieren Sie Ihren Agenten für die Verwendung eines VPC-Serviceendpunkts.
Wenn Ihr Datensatz stark komprimierbar ist, können Sie die Kosten senken, wenn Sie Ihren Agenten stattdessen in einer Handelsregion erstellen und gleichzeitig eine Aufgabe in einer ausführen. AWS GovCloud (US) Region Die Erstellung dieses Agenten erfordert mehr Einstellungen als üblich, einschließlich der Vorbereitung des Agenten für den Einsatz in einer Handelsregion. Informationen zum Erstellen eines Agenten für dieses Setup finden Sie im AWS DataSync Blog Daten ein- und AWS GovCloud (US) auslagern
Einen Objektspeicherort für Ihren S3-Bucket erstellen
Sie benötigen einen Objektspeicherort für den S3-Bucket, der sich in der Region befindet, in der Sie Ihre DataSync Aufgabe nicht ausführen.
Öffnen Sie die AWS DataSync Konsole unter https://console.aws.amazon.com/datasync/
. -
Stellen Sie sicher, dass Sie sich in derselben Region befinden, in der Sie Ihre Aufgabe ausführen möchten.
Erweitern Sie im linken Navigationsbereich die Option Datenübertragung und wählen Sie dann Standorte und Standort erstellen aus.
-
Wählen Sie als Standorttyp die Option Objektspeicher aus.
-
Wählen Sie für Agenten den DataSync Agenten aus, den Sie für diese Übertragung erstellt haben.
-
Geben Sie für Server einen Amazon S3 S3-Endpunkt für Ihren Bucket ein, indem Sie eines der folgenden Formate verwenden:
-
Bucket für die Handelsregion:
s3.your-region.amazonaws.com -
AWS GovCloud (US) Region Eimer:
s3.your-gov-region.amazonaws.com
Eine Liste der Amazon S3 S3-Endpunkte finden Sie unter Allgemeine AWS-Referenz.
-
-
Geben Sie als Bucket-Namen den Namen des S3-Buckets ein.
-
Geben Sie für Ordner ein Präfix im S3-Bucket ein, das aus oder DataSync in das geschrieben wird (je nachdem, ob es sich bei dem Bucket um einen Quell- oder Zielspeicherort handelt).
Warnung
DataSync kann keine Objekte mit einem Präfix übertragen, das mit einem Schrägstrich (
/) beginnt oder/../Muster einschließt//././Zum Beispiel:-
/photos -
photos//2006/January -
photos/./2006/February -
photos/../2006/March
-
-
Wählen Sie Anmeldedaten erforderlich aus und gehen Sie wie folgt vor:
-
Geben Sie unter Zugriffsschlüssel den Zugriffsschlüssel für einen IAM-Benutzer ein, der auf den Bucket zugreifen kann.
-
Geben Sie unter Geheimer Schlüssel den geheimen Schlüssel desselben IAM-Benutzers ein.
-
-
(Optional) Wählen Sie Tag hinzufügen, um Ihren Standort zu taggen.
Mithilfe von Tags können Sie Ihre Ressourcen verwalten, filtern und suchen. Wir empfehlen, ein Namensschild für Ihren Standort zu erstellen.
-
Wählen Sie Standort erstellen aus.
-
Kopieren Sie den folgenden
create-location-object-storageBefehl:aws datasync create-location-object-storage \ --server-hostnames3-endpoint\ --bucket-nameamzn-s3-demo-bucket\ --agent-arns arn:aws:datasync:your-region:123456789012:agent/agent-01234567890deadfb -
Geben Sie für den
--server-hostnameParameter einen Amazon S3 S3-Endpunkt für Ihren Bucket an, indem Sie eines der folgenden Formate verwenden:-
Bucket für die Handelsregion:
s3.your-region.amazonaws.com -
AWS GovCloud (US) Region Eimer:
s3.your-gov-region.amazonaws.com
Stellen Sie sicher, dass Sie für die Region auf dem Endpunkt dieselbe Region angeben, in der Sie Ihre Aufgabe ausführen möchten.
Eine Liste der Amazon S3 S3-Endpunkte finden Sie unter Allgemeine AWS-Referenz.
-
-
Geben Sie für den
--bucket-nameParameter den Namen des S3-Buckets an. -
Geben Sie für den
--agent-arnsParameter den DataSync Agenten an, den Sie für diese Übertragung erstellt haben. -
Geben Sie für den
--access-keyParameter den Zugriffsschlüssel für einen IAM-Benutzer an, der auf den Bucket zugreifen kann. -
Geben Sie für den
--secret-keyParameter den geheimen Schlüssel desselben IAM-Benutzers ein. -
(Optional) Geben Sie für den
--subdirectoryParameter ein Präfix im S3-Bucket an, das DataSync Lese- oder Schreibvorgänge vornimmt (je nachdem, ob es sich bei dem Bucket um einen Quell- oder Zielspeicherort handelt).Warnung
DataSync kann keine Objekte übertragen, deren Präfix mit einem Schrägstrich (
/) beginnt oder ein Include-///./, oder/../Muster enthält. Zum Beispiel:-
/photos -
photos//2006/January -
photos/./2006/February -
photos/../2006/March
-
-
(Optional) Geben Sie für den
--tagsParameter Schlüssel-Wert-Paare an, die Tags für die Standortressource darstellen.Mithilfe von Tags können Sie Ihre Ressourcen verwalten, filtern und suchen. Wir empfehlen, ein Namensschild für Ihren Standort zu erstellen.
-
Führen Sie den Befehl
create-location-object-storageaus.Sie erhalten eine Antwort, die Ihnen den Standort-ARN anzeigt, den Sie gerade erstellt haben.
{ "LocationArn": "arn:aws:datasync:us-east-1:123456789012:location/loc-01234567890abcdef" }
Sie können diesen Speicherort als Quelle oder Ziel für Ihre DataSync Aufgabe verwenden. Erstellen Sie für den anderen S3-Bucket in dieser Übertragung einen Amazon S3 S3-Standort.
Nächste Schritte
Zu den möglichen nächsten Schritten gehören:
-
Erstellen Sie bei Bedarf Ihren anderen Standort. Weitere Informationen finden Sie unter Mit wem kann ich meine Daten übertragen AWS DataSync?.
-
Konfigurieren Sie unter anderem DataSync Aufgabeneinstellungen, z. B. welche Dateien übertragen werden sollen, wie mit Metadaten umgegangen werden soll.
-
Legen Sie einen Zeitplan für Ihre DataSync Aufgabe fest.
-
Konfigurieren Sie die Überwachung für Ihre DataSync Aufgabe.
-
Starten Sie Ihre Aufgabe.
