Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Options de reprise après sinistre dans le cloud
Les stratégies de reprise après sinistre mises à votre disposition au sein d'AWS peuvent être classées en quatre grandes catégories, allant du faible coût et de la faible complexité des sauvegardes aux stratégies plus complexes utilisant plusieurs régions actives. Active/passive les stratégies utilisent un site actif (tel qu'une région AWS) pour héberger la charge de travail et gérer le trafic. Le site passif (tel qu'une autre région AWS) est utilisé pour la restauration. Le site passif ne dessert pas activement le trafic tant qu'un événement de basculement n'est pas déclenché.
Il est essentiel d'évaluer et de tester régulièrement votre stratégie de reprise après sinistre afin de pouvoir l'invoquer en toute confiance, le cas échéant. Utilisez AWS Resilience Hub
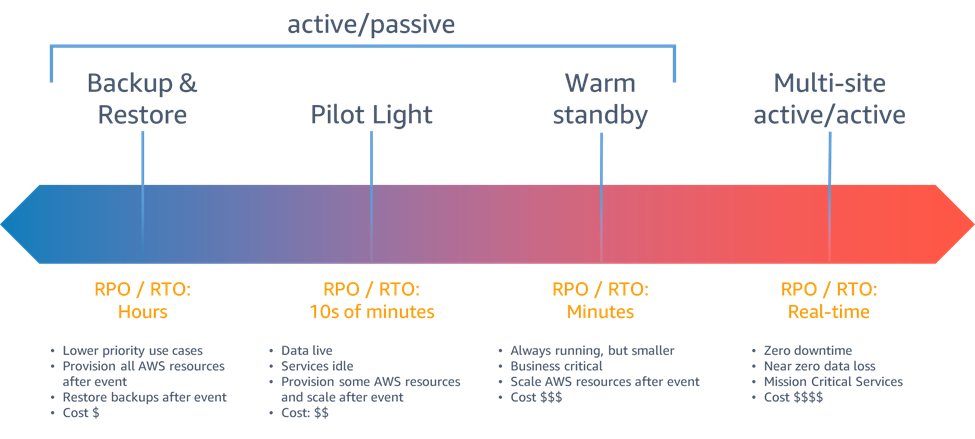
Figure 6 - Stratégies de reprise après sinistre
En cas de sinistre dû à une interruption ou à la perte d'un centre de données physique pour une charge de travail bien conçue
Lorsque vous choisissez votre stratégie et les ressources AWS pour la mettre en œuvre, gardez à l'esprit qu'au sein d'AWS, nous divisons généralement les services entre le plan de données et le plan de contrôle. Le plan de données vise à fournir un service en temps réel, tandis que les plans de contrôle servent à configurer l’environnement. Pour une résilience maximale, vous devez utiliser uniquement les opérations du plan de données dans le cadre de votre opération de basculement. Cela est dû au fait que les plans de données ont généralement des objectifs de conception de disponibilité plus élevés que les plans de contrôle.
Sauvegarde et restauration
La sauvegarde et la restauration constituent une approche appropriée pour prévenir la perte ou la corruption des données. Cette approche peut également être utilisée pour faire face à un sinistre régional en répliquant les données vers d'autres régions AWS, ou pour pallier le manque de redondance des charges de travail déployées dans une seule zone de disponibilité. Outre les données, vous devez redéployer l'infrastructure, la configuration et le code de l'application dans la région de restauration. Pour permettre le redéploiement rapide de l'infrastructure sans erreur, vous devez toujours effectuer le déploiement en utilisant l'infrastructure en tant que code (IaC) à l'aide de services tels que AWS CloudFormation
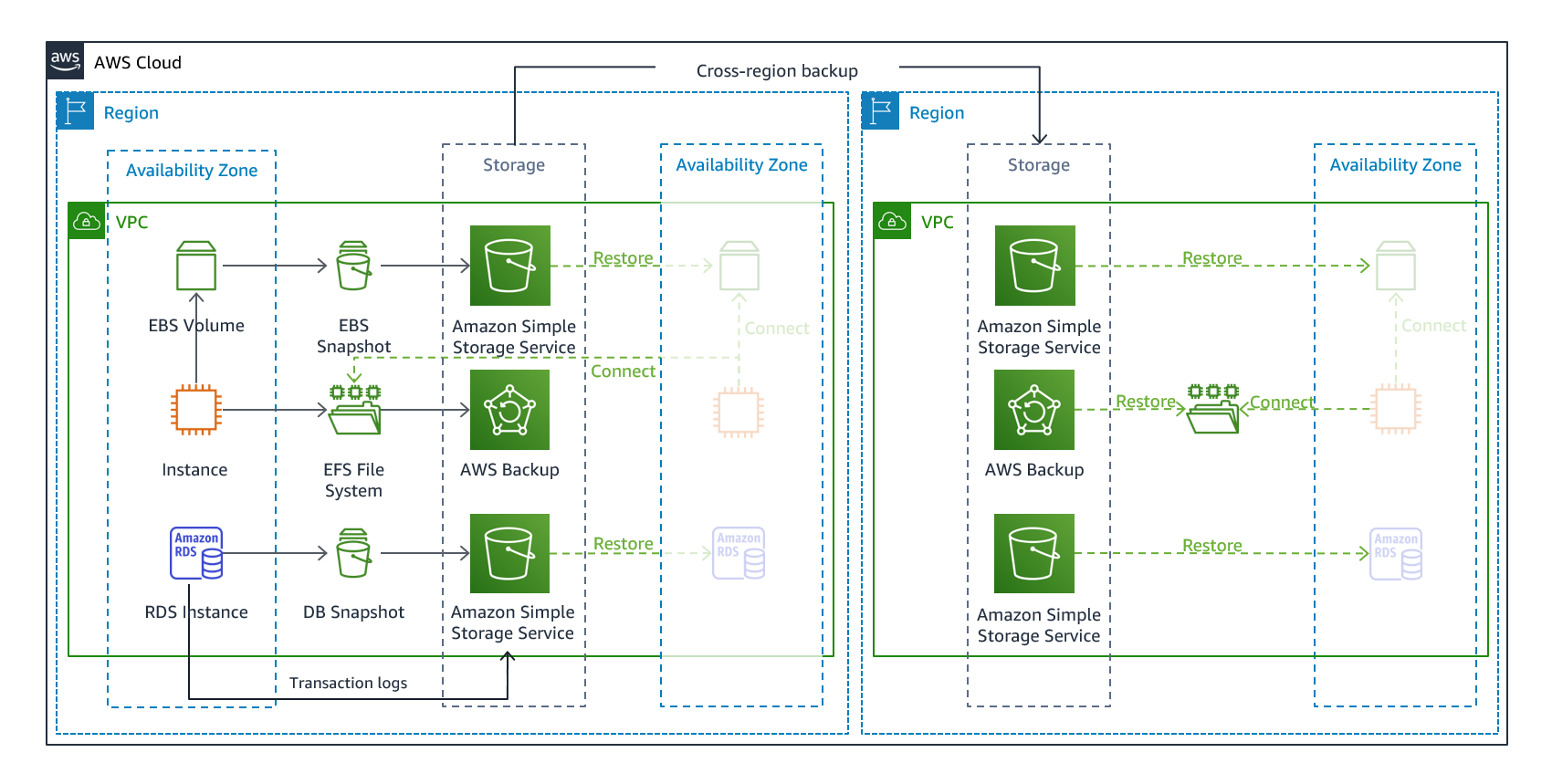
Figure 7 : architecture de sauvegarde et de restauration
Services AWS
Les données de votre charge de travail nécessiteront une stratégie de sauvegarde exécutée périodiquement ou en continu. La fréquence à laquelle vous exécutez votre sauvegarde déterminera le point de restauration que vous pouvez atteindre (qui doit correspondre à votre RPO). La sauvegarde doit également offrir un moyen de la restaurer à l'endroit où elle a été effectuée. La sauvegarde avec point-in-time restauration est disponible via les services et ressources suivants :
-
Sauvegarde Amazon EFS (lors de l'utilisation AWS Backup)
-
Amazon FSx pour Windows File Server, Amazon FSx pour Lustre, Amazon FSx pour NetApp ONTAP et Amazon FSx pour OpenZFS
Pour Amazon Simple Storage Service (Amazon S3), vous pouvez utiliser Amazon S3 Cross-Region Replication (CRR
AWS Backup
-
EC2Instances Amazon
-
Bases de données Amazon Relational Database Service (Amazon RDS
) (y compris les bases de données Amazon Aurora ) -
Systèmes de fichiers Amazon Elastic File System (Amazon EFS)
-
AWS Storage Gateway
Volumes -
Amazon FSx pour Windows File Server, Amazon FSx pour Lustre, Amazon FSx pour NetApp ONTAP et Amazon FSx pour OpenZFS
AWS Backup prend en charge la copie de sauvegardes entre régions, par exemple vers une région de reprise après sinistre.
En tant que stratégie de reprise après sinistre supplémentaire pour vos données Amazon S3, activez la gestion des versions des objets S3. Le versionnement des objets protège vos données dans S3 des conséquences des actions de suppression ou de modification en conservant la version d'origine avant l'action. Le versionnement des objets peut être une solution utile pour atténuer les catastrophes liées à des erreurs humaines. Si vous utilisez la réplication S3 pour sauvegarder des données dans votre région DR, Amazon S3 ajoute par défaut un marqueur de suppression uniquement dans le compartiment source lorsqu'un objet est supprimé dans le compartiment source. Cette approche protège les données de la région DR contre les suppressions malveillantes dans la région source.
Outre les données, vous devez également sauvegarder la configuration et l'infrastructure nécessaires pour redéployer votre charge de travail et atteindre votre objectif de temps de restauration (RTO). AWS CloudFormation
Toutes les données stockées dans la région de reprise après sinistre sous forme de sauvegarde doivent être restaurées au moment du basculement. AWS Backup offre une fonctionnalité de restauration, mais n'active pas actuellement la restauration planifiée ou automatique. Vous pouvez implémenter la restauration automatique dans la région de reprise après sinistre à l'aide du SDK AWS. APIs AWS Backup Vous pouvez configurer cette tâche comme une tâche récurrente régulière ou déclencher une restauration chaque fois qu'une sauvegarde est terminée. La figure suivante montre un exemple de restauration automatique à l'aide d'Amazon Simple Notification Service (Amazon SNS

Figure 8 : restauration et test des sauvegardes
Note
Votre stratégie de sauvegarde doit inclure le test de vos sauvegardes. Consultez la section Tests de reprise après sinistre pour plus d'informations. Reportez-vous au document AWS Well-Architected Lab : Testing Backup and Restore of Data pour une démonstration pratique de la
Veilleuse
Avec l'approche pilote, vous répliquez vos données d'une région à l'autre et vous fournissez une copie de votre infrastructure de charge de travail principale. Les ressources requises pour prendre en charge la réplication et la sauvegarde des données, telles que les bases de données et le stockage d’objets, sont toujours actives. D'autres éléments, tels que les serveurs d'applications, sont chargés avec le code et les configurations de l'application, mais sont « désactivés » et ne sont utilisés que pendant les tests ou lorsque le basculement après sinistre est invoqué. Dans le cloud, vous avez la flexibilité de déprovisionner les ressources lorsque vous n'en avez pas besoin et de les provisionner lorsque vous en avez besoin. Une bonne pratique en cas de « désactivation » consiste à ne pas déployer la ressource, puis à créer la configuration et les fonctionnalités nécessaires pour la déployer (« activation ») en cas de besoin. Contrairement à l'approche de sauvegarde et de restauration, votre infrastructure principale est toujours disponible et vous avez toujours la possibilité de fournir rapidement un environnement de production à grande échelle en activant et en développant vos serveurs d'applications.
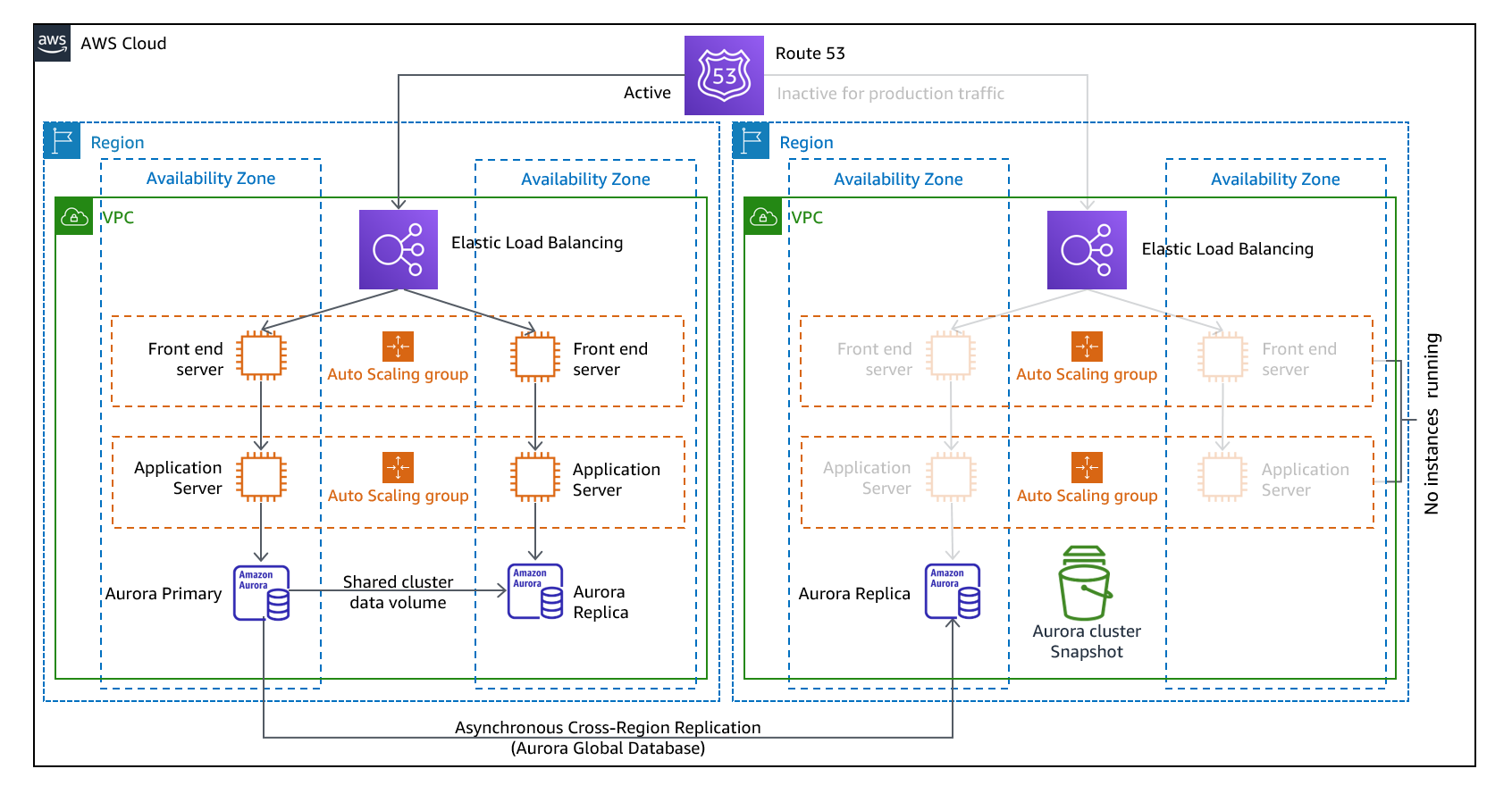
Figure 9 : architecture de la veilleuse
Une approche pilote légère minimise le coût permanent de la reprise après sinistre en minimisant les ressources actives, et simplifie la reprise au moment d'un sinistre, car les exigences d'infrastructure de base sont toutes réunies. Cette option de restauration vous oblige à modifier votre approche de déploiement. Vous devez apporter des modifications d'infrastructure de base à chaque région et déployer les modifications de charge de travail (configuration, code) simultanément dans chaque région. Cette étape peut être simplifiée en automatisant vos déploiements et en utilisant l'infrastructure en tant que code (IaC) pour déployer l'infrastructure sur plusieurs comptes et régions (déploiement complet de l'infrastructure dans la région principale et déploiement de l'infrastructure réduite/désactivée dans les régions DR). Il est recommandé d'utiliser un compte différent par région afin de garantir le plus haut niveau d'isolation des ressources et de sécurité (dans le cas où des informations d'identification compromises font également partie de vos plans de reprise après sinistre).
Avec cette approche, vous devez également vous prémunir contre un sinistre lié aux données. La réplication continue des données vous protège contre certains types de catastrophes, mais elle peut ne pas vous protéger contre la corruption ou la destruction des données, sauf si votre stratégie inclut également le versionnement des données stockées ou des options de point-in-time restauration. Vous pouvez sauvegarder les données répliquées dans la région sinistrée pour créer des point-in-time sauvegardes dans cette même région.
Services AWS
Outre l'utilisation des services AWS décrits dans la section Backup and Restore pour créer point-in-time des sauvegardes, considérez également les services suivants pour votre stratégie pilote.
Dans un premier temps, la réplication continue des données vers des bases de données actives et des magasins de données dans la région de reprise après sinistre est la meilleure approche pour un faible RPO (lorsqu'elle est utilisée en plus des point-in-time sauvegardes évoquées précédemment). AWS fournit une réplication continue, asynchrone et interrégionale des données à l'aide des services et ressources suivants :
Grâce à la réplication continue, les versions de vos données sont disponibles presque immédiatement dans votre région DR. Les temps de réplication réels peuvent être surveillés à l'aide de fonctionnalités de service telles que le contrôle du temps de réplication S3 (S3 RTC) pour les objets S3 et les fonctionnalités de gestion des bases de données mondiales Amazon Aurora.
Lorsque vous basculez pour exécuter votre read/write charge de travail depuis la région de reprise après sinistre, vous devez promouvoir une réplique en lecture RDS pour en faire l'instance principale. Pour les instances de base de données autres qu'Aurora, le processus prend quelques minutes et le redémarrage fait partie du processus. Pour la réplication entre régions (CRR) et le basculement avec RDS, l'utilisation de la base de données globale Amazon Aurora présente plusieurs avantages. La base de données globale utilise une infrastructure dédiée qui laisse vos bases de données entièrement disponibles pour servir votre application et peut être répliquée vers la région secondaire avec une latence généralement inférieure à une seconde (et bien inférieure à 100 millisecondes dans une région AWS). Avec la base de données mondiale Amazon Aurora, si votre région principale subit une dégradation des performances ou une panne, vous pouvez confier la responsabilité de lecture/écriture à l'une des régions secondaires en moins d'une minute, même en cas de panne régionale complète. Vous pouvez également configurer Aurora pour surveiller le temps de latence du RPO de tous les clusters secondaires afin de vous assurer qu'au moins un cluster secondaire reste dans votre fenêtre de RPO cible.
Une version réduite de votre infrastructure de charge de travail principale avec moins ou moins de ressources doit être déployée dans votre région de reprise après sinistre. Vous pouvez ainsi définir votre infrastructure et la déployer de manière cohérente sur les comptes AWS et les régions AWS. AWS CloudFormation AWS CloudFormation utilise des pseudo-paramètres prédéfinis pour identifier le compte AWS et la région AWS dans lesquels il est déployé. Par conséquent, vous pouvez implémenter une logique conditionnelle dans vos CloudFormation modèles afin de déployer uniquement la version réduite de votre infrastructure dans la région DR. Pour les déploiements d' EC2 instances, une Amazon Machine Image (AMI) fournit des informations telles que la configuration matérielle et les logiciels installés. Vous pouvez implémenter un pipeline Image Builder qui crée les éléments dont AMIs vous avez besoin et les copier à la fois dans votre région principale et dans votre région de sauvegarde. Cela permet de s'assurer que ces golden AMIs disposent de tout ce dont vous avez besoin pour redéployer ou augmenter votre charge de travail dans une nouvelle région, en cas de sinistre. Les EC2 instances Amazon sont déployées dans une configuration réduite (moins d'instances que dans votre région principale). Pour étendre l'infrastructure afin de prendre en charge le trafic de production, consultez Amazon EC2 Auto Scaling
Pour une active/passive configuration telle que la veilleuse, tout le trafic est initialement dirigé vers la région principale et passe à la région de reprise après sinistre si la région principale n'est plus disponible. Cette opération de basculement peut être lancée automatiquement ou manuellement. Le basculement automatique basé sur des contrôles de santé ou des alarmes doit être utilisé avec prudence. Même en utilisant les meilleures pratiques décrites ici, le temps et le point de restauration seront supérieurs à zéro, ce qui entraînera une certaine perte de disponibilité et de données. Si vous tombez alors que vous n'en avez pas besoin (fausse alerte), vous subissez ces pertes. Le basculement manuel est donc souvent utilisé. Dans ce cas, nous vous conseillons tout de même d’automatiser les étapes de basculement, de sorte que vous n’ayez à appuyer que sur un bouton pour lancer le basculement.
Il existe plusieurs options de gestion du trafic à prendre en compte lors de l'utilisation AWS des services.
L’une des options consiste à utiliser Amazon Route 53
Une autre option consiste à utiliser AWS Global Accelerator
Amazon CloudFront
AWS Reprise après sinistre élastique
AWS Elastic Disaster Recovery
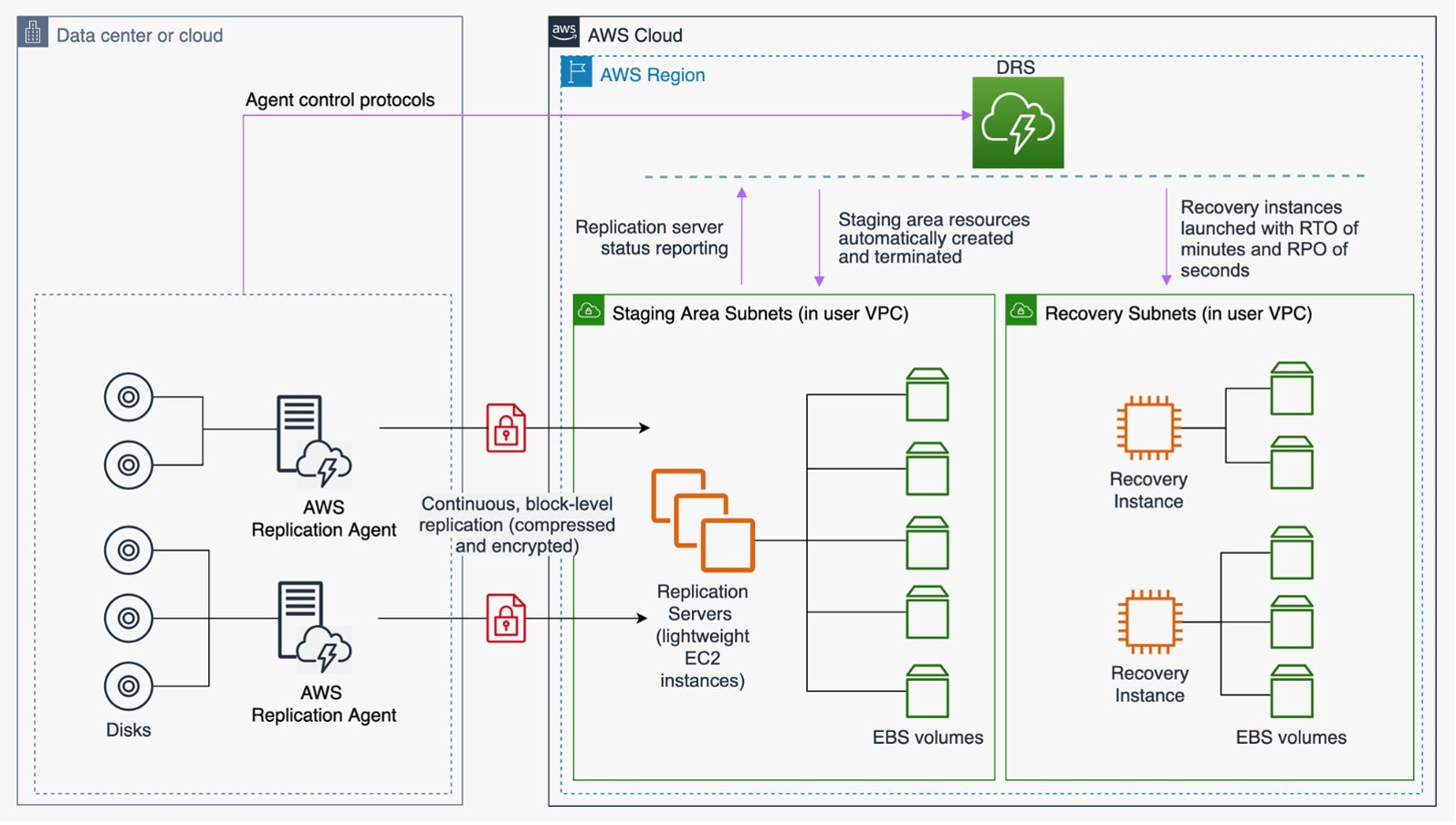
Figure 10 : architecture AWS Elastic Disaster Recovery
Secours semi-automatique
L’approche du secours semi-automatique consiste à s’assurer qu’il existe une copie réduite verticalement, mais entièrement fonctionnelle, de votre environnement de production dans une autre région. Cette approche étend le concept d’environnement en veille et réduit le temps de récupération, car votre charge de travail reste active dans une autre région. Cette approche vous permet également d'effectuer plus facilement des tests ou de mettre en œuvre des tests continus afin de renforcer la confiance dans votre capacité à vous remettre après un sinistre.
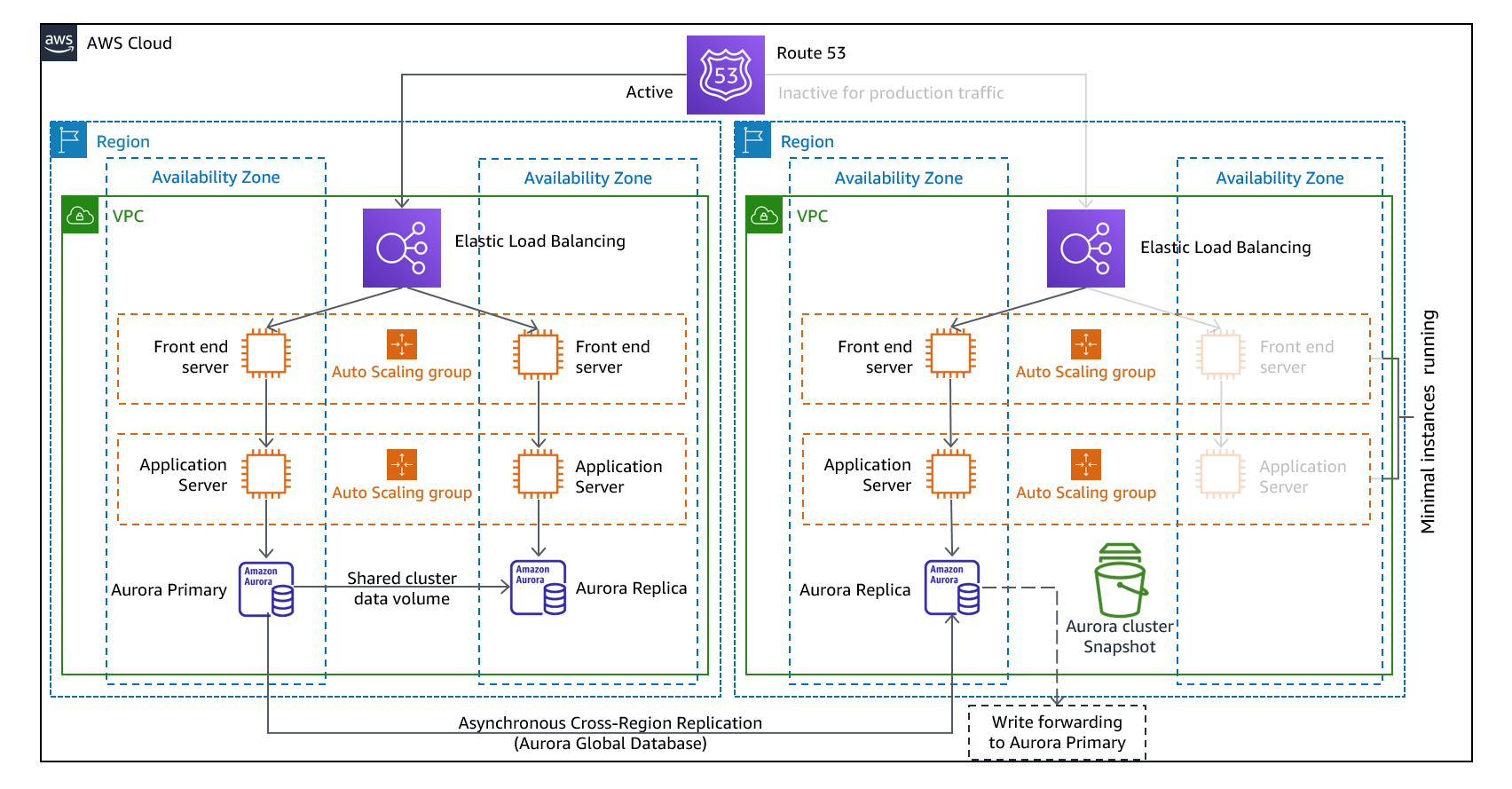
Figure 11 : architecture Warm Standby
Remarque : La différence entre veilleuse et veille chaude peut parfois être difficile à comprendre. Les deux incluent un environnement dans votre région DR avec des copies des actifs principaux de votre région. La différence est que la lampe pilote ne peut pas traiter les demandes sans que des mesures supplémentaires ne soient prises au préalable, tandis que le mode veille peut gérer le trafic (à des niveaux de capacité réduits) immédiatement. L'approche pilote vous oblige à « activer » les serveurs, éventuellement à déployer une infrastructure supplémentaire (non essentielle) et à passer à l'échelle supérieure, tandis que le mode veille chaude vous oblige uniquement à le faire évoluer (tout est déjà déployé et fonctionne). Utilisez vos besoins en matière de RTO et de RPO pour vous aider à choisir entre ces approches.
Services AWS
Tous les services AWS couverts par les rubriques sauvegarde, restauration et pilote sont également utilisés en mode veille pour la sauvegarde des données, la réplication des données, le routage active/passive du trafic et le déploiement de l'infrastructure, y compris EC2 les instances.
Amazon EC2 Auto Scaling
Auto Scaling étant une activité relevant du plan de contrôle, le fait d'en dépendre diminuera la résilience de votre stratégie de restauration globale. Il s'agit d'un compromis. Vous pouvez choisir de fournir une capacité suffisante pour que la région de restauration puisse gérer l'intégralité de la charge de production telle que déployée. Cette configuration statiquement stable est appelée hot standby (voir la section suivante). Vous pouvez également choisir de fournir moins de ressources, ce qui vous coûtera moins cher, tout en vous appuyant sur Auto Scaling. Certaines implémentations de DR déploieront suffisamment de ressources pour gérer le trafic initial, garantissant ainsi un faible RTO, puis s'appuieront sur Auto Scaling pour accélérer le trafic suivant.
Multisite actif/actif
Vous pouvez exécuter votre charge de travail simultanément dans plusieurs régions dans le cadre d'une stratégie actif/active ou actif/passive multisite. Le multisite active/active gère le trafic provenant de toutes les régions dans lesquelles il est déployé, tandis que le mode de veille active ne traite que le trafic provenant d'une seule région, et les autres régions ne sont utilisées que pour la reprise après sinistre. Grâce à une active/active approche multisite, les utilisateurs peuvent accéder à votre charge de travail dans toutes les régions dans lesquelles elle est déployée. Cette approche est l'approche la plus complexe et la plus coûteuse en matière de reprise après sinistre, mais elle peut réduire le temps de reprise à un niveau proche de zéro dans la plupart des cas de sinistre si les choix technologiques et la mise en œuvre sont appropriés (toutefois, la corruption des données peut nécessiter des sauvegardes, ce qui se traduit généralement par un point de reprise différent de zéro). La mise en veille prolongée utilise une active/passive configuration dans laquelle les utilisateurs ne sont dirigés que vers une seule région et les régions DR n'absorbent pas de trafic. La plupart des clients trouvent que s'ils veulent créer un environnement complet dans la deuxième région, il est logique de l'utiliser actif/actif. Sinon, si vous ne souhaitez pas utiliser les deux régions pour gérer le trafic utilisateur, Warm Standby propose une approche plus économique et moins complexe sur le plan opérationnel.
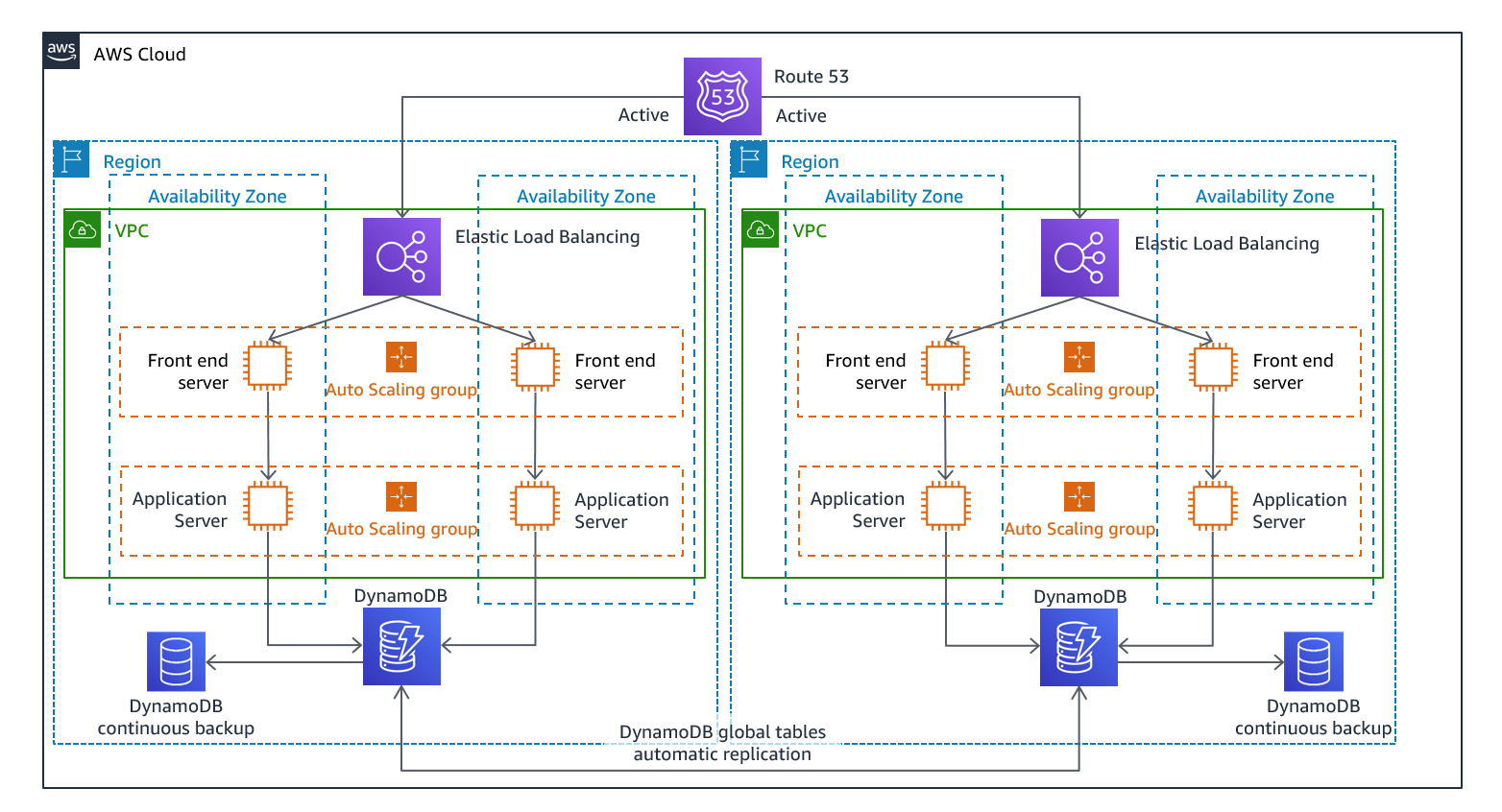
Figure 12 : active/active architecture multisite (remplacez un chemin actif par Inactif pour le mode veille à chaud)
Une approche multisite active/active, because the workload is running in more than one Region, there is no such thing as failover in this scenario. Disaster recovery testing in this case would focus on how the workload reacts to loss of a Region: Is traffic routed away from the failed Region? Can the other Region(s) handle all the traffic? Testing for a data disaster is also required. Backup and recovery are still required and should be tested regularly. It should also be noted that recovery times for a data disaster involving data corruption, deletion, or obfuscation will always be greater than zero and the recovery point will always be at some point before the disaster was discovered. If the additional complexity and cost of a multi-site active/active (ou « hot standby ») étant nécessaire pour maintenir des temps de restauration proches de zéro, des efforts supplémentaires doivent être déployés pour maintenir la sécurité et prévenir les erreurs humaines afin d'atténuer les risques de catastrophes humaines.
Services AWS
Tous les services AWS couverts par les rubriques sauvegarde et restauration, Pilot Light et Warm Standby sont également utilisés ici pour la sauvegarde des données, la réplication point-in-time des données, le routage active/active du trafic, ainsi que le déploiement et le dimensionnement de l'infrastructure, y compris EC2 les instances.
Pour les active/passive scénarios décrits précédemment (Pilot Light et Warm Standby), Amazon Route 53 AWS Global Accelerator peut être utilisé pour acheminer le trafic réseau vers la région active. Dans le active/active cadre de cette stratégie, ces deux services permettent également de définir des politiques qui déterminent quels utilisateurs accèdent à quel point de terminaison régional actif. AWS Global Accelerator Vous définissez alors un numéro de trafic pour contrôler le pourcentage de trafic dirigé vers chaque point de terminaison de l'application. Amazon Route 53 prend en charge cette approche basée sur le pourcentage, ainsi que de nombreuses autres politiques disponibles, notamment celles basées sur la géoproximité et la latence. Global Accelerator exploite automatiquement le vaste réseau de serveurs périphériques AWS pour intégrer le trafic au backbone du réseau AWS dès que possible, réduisant ainsi les latences des demandes.
La réplication asynchrone des données avec cette stratégie permet un RPO proche de zéro. Les services AWS tels que la base de données mondiale Amazon Aurora utilisent une infrastructure dédiée qui laisse vos bases de données entièrement disponibles pour servir votre application, et peuvent être répliquées dans un maximum de cinq régions secondaires avec une latence typique inférieure à une seconde. With conçoit active/passive strategies, writes occur only to the primary Region. The difference with active/active la manière dont la cohérence des données avec les écritures dans chaque région active est gérée. Il est courant de concevoir les lectures des utilisateurs pour qu'elles soient diffusées depuis la région la plus proche de chez eux, connue sous le nom de lecture locale. Avec les écritures, plusieurs options s'offrent à vous :
-
Une stratégie globale d'écriture achemine toutes les écritures vers une seule région. En cas d'échec de cette région, une autre région serait encouragée à accepter les écrits. La base de données globale Aurora convient parfaitement à Write Global, car elle prend en charge la synchronisation avec les répliques en lecture dans toutes les régions, et vous pouvez promouvoir l'une des régions secondaires pour qu'elle prenne des read/write responsabilités en moins d'une minute. Aurora prend également en charge le transfert d'écriture, qui permet aux clusters secondaires d'une base de données globale Aurora de transférer des instructions SQL qui effectuent des opérations d'écriture vers le cluster principal.
-
Une stratégie locale d'écriture achemine les écritures vers la région la plus proche (tout comme les lectures). Les tables globales Amazon DynamoDB permettent une telle stratégie, en autorisant la lecture et l'écriture depuis toutes les régions dans lesquelles votre table globale est déployée. Les tables globales Amazon DynamoDB utilisent un dernier rédacteur pour gagner la réconciliation entre les mises à jour simultanées.
-
Une stratégie partitionnée en écriture attribue les écritures à une région spécifique en fonction d'une clé de partition (comme l'ID utilisateur) afin d'éviter les conflits d'écriture. La réplication Amazon S3 configurée de manière bidirectionnelle
peut être utilisée dans ce cas et prend actuellement en charge la réplication entre deux régions. Lorsque vous mettez en œuvre cette approche, veillez à activer la synchronisation des modifications des répliques sur les compartiments A et B afin de répliquer les modifications des métadonnées des répliques, telles que les listes de contrôle d'accès aux objets (ACLs), les balises d'objets ou les verrous d'objets sur les objets répliqués. Vous pouvez également configurer s'il faut ou non répliquer les marqueurs de suppression entre les compartiments de vos régions actives. Outre la réplication, votre stratégie doit également inclure point-in-time des sauvegardes afin de vous protéger contre les événements de corruption ou de destruction des données.
AWS CloudFormation est un outil puissant permettant d'appliquer une infrastructure déployée de manière cohérente entre les comptes AWS dans plusieurs régions AWS. AWS CloudFormation StackSetsétend cette fonctionnalité en vous permettant de créer, de mettre à jour ou de supprimer des CloudFormation piles sur plusieurs comptes et régions en une seule opération. Bien qu'il AWS CloudFormation utilise YAML ou JSON pour définir l'infrastructure en tant que code, il vous AWS Cloud Development Kit (AWS CDK)
