REL13-BP02 復旧目標を満たすため、定義された復旧戦略を使用する
ワークロードの復旧目標を満たすディザスタリカバリ (DR) 戦略を定義します。バックアップと復元、スタンバイ (アクティブ/パッシブ)、またはアクティブ/アクティブなどの戦略を選択します。
期待される成果: 各ワークロードについて、定義され、実装された DR 戦略があり、ワークロードは DR 目標を達成できます。ワークロード間の DR 戦略では、再利用可能なパターンを利用します (以前に記載された戦略など)。
一般的なアンチパターン:
-
同じような DR 目標を持つワークロードについて、一貫性のない復旧手順を実装する。
-
DR 戦略は、災害が発生したときにアドホックに実装すればよいとする。
-
ディザスタリカバリが計画されていない。
-
復旧時にコントロールプレーンのオペレーションに依存する。
このベストプラクティスを活用するメリット:
-
定義された復旧戦略を使用すると、一般的なツールとテスト手順を使用できます。
-
定義された復旧戦略を使用すると、チーム間のナレッジ共有と、チームが所有するワークロードでの DR の実装が改善します。
このベストプラクティスを活用しない場合のリスクレベル: 高 計画され、実装され、テストされた DR 戦略がなければ、災害発生時に復旧目標を達成できない可能性があります。
実装のガイダンス
DR 戦略は、プライマリロケーションでワークロードを実行できなくなった場合に復旧サイトでワークロードに耐えられる能力に依存します。最も一般的な復旧目標は、RTO と RPO です (「REL13-BP01 ダウンタイムやデータ損失に関する復旧目標を定義する」を参照)。
単一の AWS リージョン内の複数のアベイラビリティーゾーン (AZ) にまたがる DR 戦略は、火災、洪水、大規模な停電などの災害イベントに対して影響を緩和できます。ワークロードを特定の AWS リージョンで実行できなくなるような、可能性の低いイベントに対する保護を実装する必要がある場合には、複数のリージョンを使用する DR 戦略を使用できます。
複数のリージョンにまたがる DR 戦略を設計するときには、以下のいずれかの戦略を選んでください。戦略は、コストと複雑さが低く、かつ RTO と RPO が長い順にリストされます。リカバリリージョンとは、ワークロードに使用されるプライマリ以外の AWS リージョンを指します。
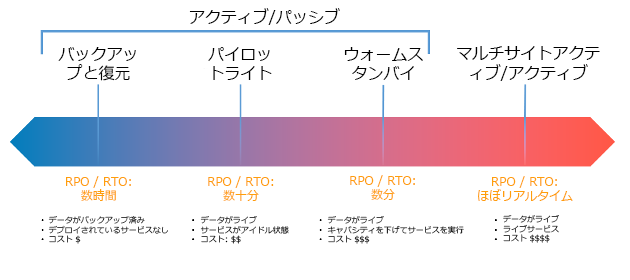
図 17: ディザスタリカバリ (DR) 戦略
-
バックアップと復元 (数時間での RPO、24 時間以下での RTO): データとアプリケーションを復旧リージョンにバックアップします。自動化されたバックアップまたは連続バックアップを使用すると、ポイントインタイムリカバリ (PITR) が可能であり、場合によっては RPO を 5 分間に短縮できます。災害の際には、インフラストラクチャをデプロイし (インフラストラクチャをコードとして使用して RTO を削減)、コードをデプロイし、バックアップされたデータを復元して、復旧リージョンで災害から復旧します。
-
パイロットライト (数分間の RPO、数十分間の RTO): コアワークロードインフラストラクチャのコピーを復旧リージョンにプロビジョニングします。データを復旧リージョンにレプリケートして、そこでバックアップを作成します。データベースやオブジェクトストレージなど、データのレプリケーションとバックアップのサポートに必要なリソースは、常にオンです。アプリケーションサーバーやサーバーレスコンピューティングなど、その他の要素はデプロイされませんが、必要なときには、必須の設定とアプリケーションコードで作成できます。
-
ウォームスタンバイ (数秒間の RPO、数分間の RTO): 完全に機能する縮小バージョンのワークロードを復旧リージョンで常に実行している状態に保ちます。ビジネスクリティカルなシステムは完全に複製され、常に稼働していますが、フリートは縮小されています。データは復旧リージョンでレプリケートされ、使用可能です。復旧時には、システムをすばやくスケールアップして本番環境の負荷を処理できるようにします。ウォームスタンバイの規模が大きいほど、RTO とコントロールプレーンへの依存は低くなります。これを完全にスケールアップしたものはホットスタンバイと呼ばれます。
-
マルチリージョン (マルチサイト) アクティブアクティブ (ゼロに近い RPO、ほぼゼロの RTO): ワークロードは複数の AWS リージョンにデプロイされ、そこからトラフィックにアクティブに対応します。この戦略では、複数のリージョン間でデータを同期する必要があります。2 つの異なるリージョンレプリカ内の同じレコードへの書き込みによって生じる矛盾を回避または処理する必要があり、これは複雑になることがあります。データレプリケーションは、データの同期に便利であり、特定のタイプの災害から保護しますが、ソリューションがポイントインタイムリカバリのためのオプションを含んでいない限り、データの破損や破壊からは保護しません。
注記
パイロットライトとウォームスタンバイの違いは、理解しにくいかもしれません。どちらも、プライマリリージョンアセットのコピーがある復旧リージョン内の環境を含みます。その違いは、パイロットライトが最初に追加アクションを取らなければリクエストを処理できないのに対して、ウォームスタンバイはトラフィックを直ちに (削減された能力レベルで) 処理できることです。パイロットライトでは、サーバーをオンにして、おそらく追加の (非コア) インフラストラクチャをデプロイし、スケールアップする必要があるのに対して、ウォームスタンバイでは、スケールアップするだけです (すべてが既にデプロイされ、実行しています)。RTO と RPO のニーズに基づいて、両者の中から選択してください。
コストが懸念事項であり、ウォームスタンバイ戦略での定義と同様の RPO および RTO 目標の達成を目指す場合は、パイロットライトアプローチを採用して、改善された RPO および RTO 目標を提供する AWS Elastic Disaster Recovery などのクラウドネイティブソリューションを検討することができます。
実装手順
-
このワークロードの復旧要件を満たす DR 戦略を決定します。
DR 戦略を選ぶということは、ダウンタイムとデータ損失の削減 (RTO と RPO) 、戦略を実装するコストと複雑性のトレードオフです。必要以上に厳格な戦略の実装は、不要なコストにつながるため避けてください。
例えば、次の図では、許容可能な最大 RTO と、サービス復元戦略に費やすことができるコストの限界を決定しています。特定のビジネス目標の場合、パイロットライトまたはウォームスタンバイの DR 戦略は、RTO とコスト基準の両方を満たすことができます。
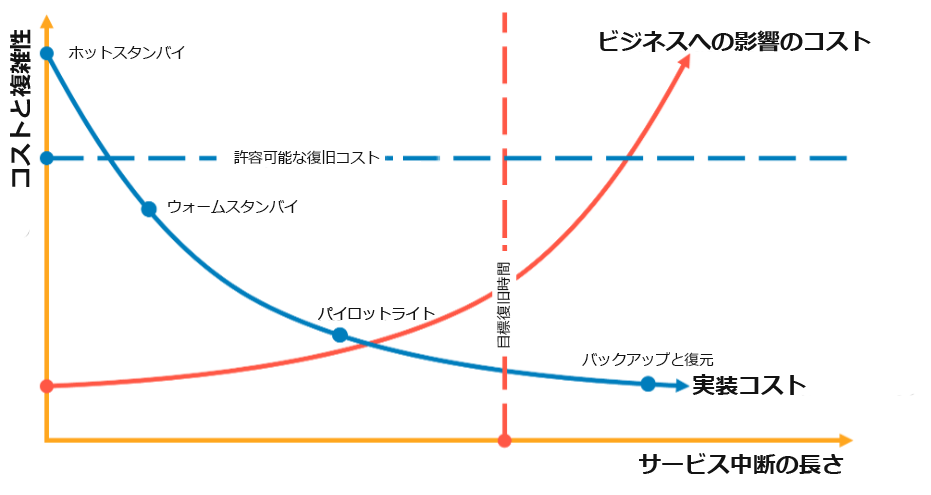
図 18: RTO とコストに基づく DR 戦略の選択を示すグラフ
詳細については、「ビジネス継続計画 (BCP)」を参照してください。
-
選択した DR 戦略の実装パターンをレビューします。
このステップでは、選択した戦略の実装方法を理解します。戦略は、プライマリサイトと復旧サイトとしての AWS リージョンを使用して説明されています。ただし、単一リージョン内のアベイラビリティーゾーンを DR 戦略として使用することもでき、その場合は、これら複数の戦略の要素を利用します。
以下の手順では、戦略を特定のワークロードに適用できます。
バックアップと復元
バックアップと復元は、実装の複雑さが最も少ない戦略ですが、ワークロードの復元に必要な時間と労力が多く、より高い RTO と RPO につながります。常にデータのバックアップを取り、これらを別のサイト (別の AWS リージョンなど) にコピーすることをお勧めします。
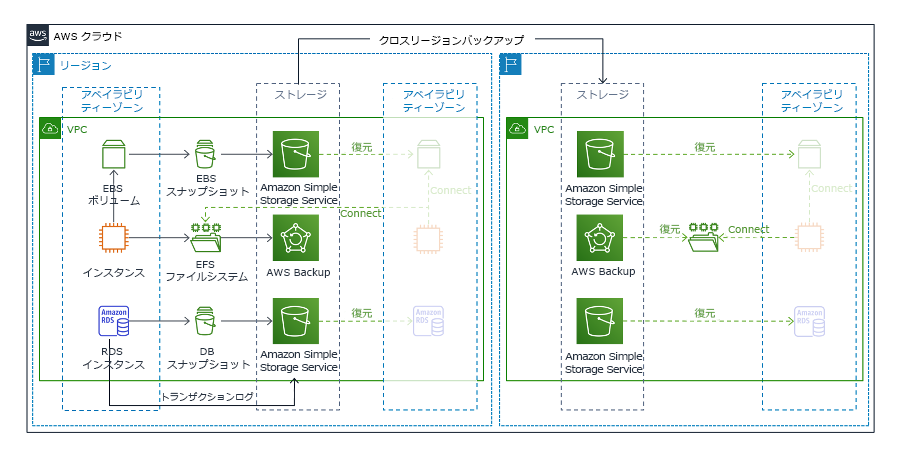
図 19: バックアップと復元アーキテクチャ
この戦略の詳細については、「AWS でのディザスタリカバリ (DR) アーキテクチャ、パート II: 迅速な復旧によるバックアップと復元
」を参照してください。 パイロットライト
パイロットライトアプローチでは、プライマリリージョンから復旧リージョンにデータをレプリケートします。ワークロードインフラストラクチャに使用されるコアリソースは復旧リージョンにデプロイされますが、これを機能するスタックにするには、やはり追加のリソースと依存関係が必要です。例えば、図 20 では、コンピューティングインスタンスはデプロイされていません。
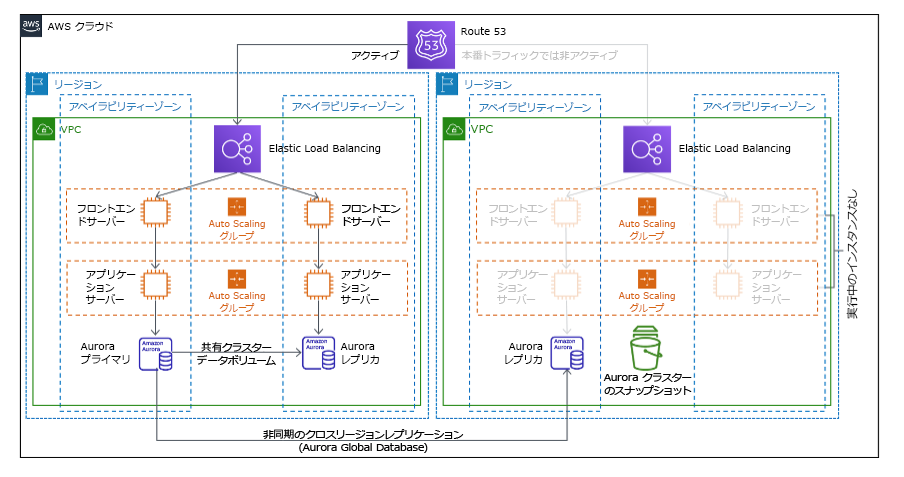
図 20: パイロットライトアーキテクチャ
この戦略の詳細については、「AWS でのディザスタリカバリ (DR) アーキテクチャ、パート III: パイロットライトとウォームスタンバイ
」を参照してください。 ウォームスタンバイ
ウォームスタンバイアプローチでは、本番稼働環境の完全に機能する縮小コピーを別のリージョンに用意します。このアプローチは、パイロットライトの概念を拡張して、ワークロードが別のリージョンに常駐するため、復旧時間が短縮されます。復旧リージョンが完全なキャパシティでデプロイされた場合は、ホットスタンバイと呼ばれます。
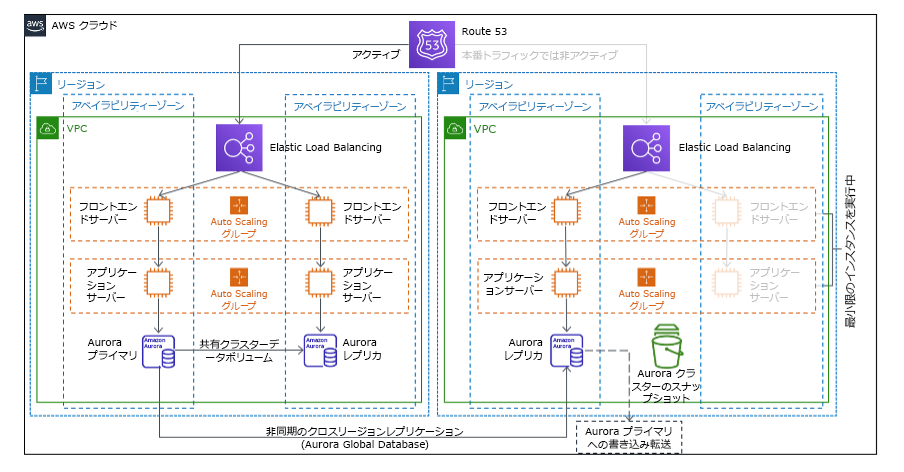
図 21: ウォームスタンバイアーキテクチャ
ウォームスタンバイまたはパイロットライトを使用するには、復旧リージョンのリソースをスケールアップする必要があります。必要に応じてキャパシティが利用可能であることを保証するには、EC2 インスタンスのキャパシティ予約の使用を検討してください。AWS Lambda を使用する場合、プロビジョニングされた同時実行はランタイム環境を提供して、関数の呼び出しにすぐに応答する準備を整えることができます。
この戦略の詳細については、「AWS でのディザスタリカバリ (DR) アーキテクチャ、パート III: パイロットライトとウォームスタンバイ
」を参照してください。 マルチサイトアクティブ/アクティブ
マルチサイトアクティブ/アクティブ戦略の一部として、複数のリージョンでワークロードを同時実行できます。マルチサイトアクティブ/アクティブは、デプロイされたすべてのリージョンからのトラフィックを処理します。DR 以外の理由でこの戦略を選択することもあります。可用性を高めるためや、グローバルオーディエンスにワークロードをデプロイするときに (エンドポイントをエンドユーザーに近づけるためや、そのリージョン内のオーディエンスに対してローカライズされたスタックをデプロイするため) 使用できます。DR 戦略としては、ワークロードがデプロイされている AWS リージョンの 1 つでワークロードをサポートできない場合、そのリージョンは隔離され、残りのリージョンを使用して可用性を維持します。マルチサイトアクティブ/アクティブは、運用が最も複雑な DR 戦略であり、ビジネス要件上、必須の場合のみ選択してください。
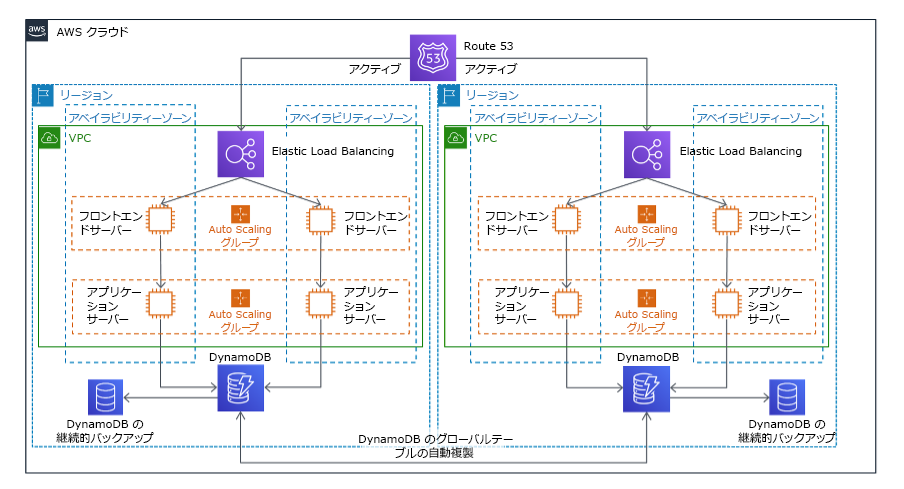
図 22: マルチサイトアクティブ/アクティブアーキテクチャ
この戦略の詳細については、「AWS のディザスタリカバリ (DR) アーキテクチャ、パート IV: マルチサイトアクティブ/アクティブ
」を参照してください。 AWS Elastic Disaster Recovery
ディザスタリカバリのためのパイロットライトまたはウォームスタンバイ戦略を検討している場合、AWS Elastic Disaster Recovery はより優れた代替アプローチを提供できる場合があります。Elastic Disaster Recovery は、ウォームスタンバイと同様の RPO と RTO ターゲットを提供できますが、パイロットライトの低コストアプローチを維持します。Elastic Disaster Recovery は、プライマリリージョンからリカバリリージョンにデータをレプリケートします。継続的なデータ保護を使用して、数秒で測定される RPO と数分で測定できる RTO を実現します。パイロットライト戦略と同様、データのレプリケートに必要となるリソースのみが復旧リージョンにデプロイされるため、コストが抑えられます。Elastic Disaster Recovery では、サービスがフェイルオーバーまたはドリルの一環として開始されたコンピューティングリソースの回復を調整します。
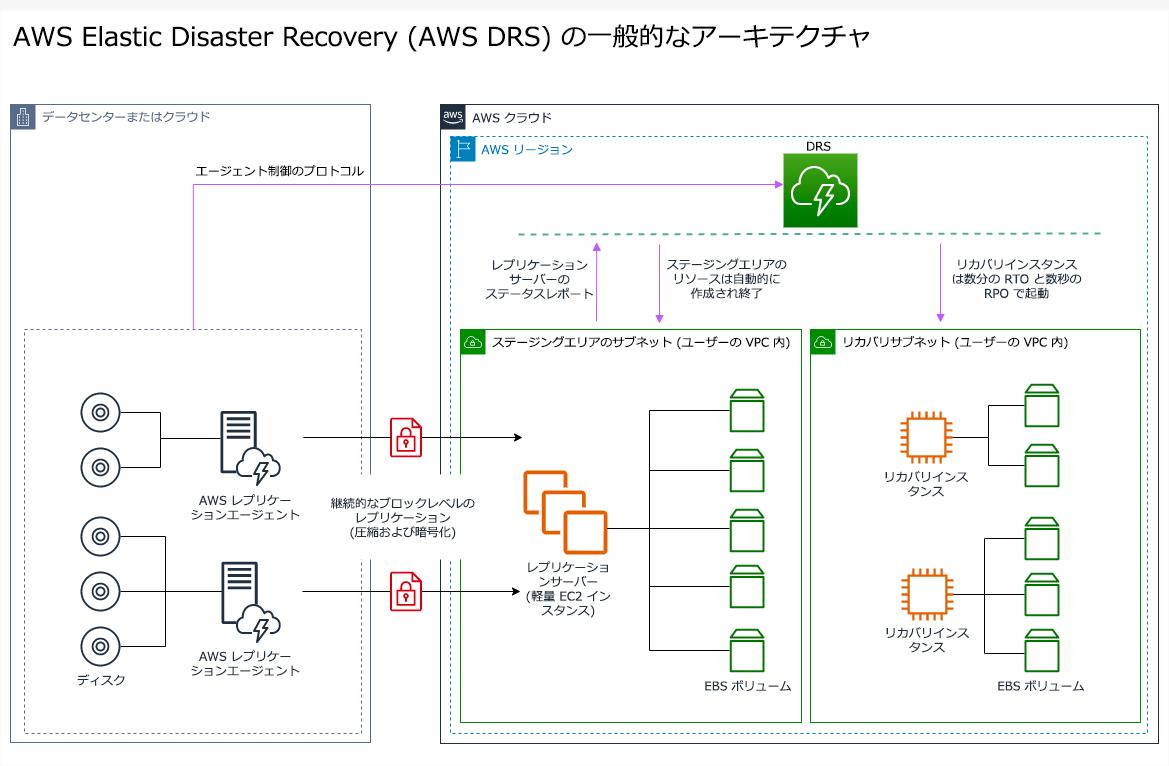
図 23: AWS Elastic Disaster Recovery アーキテクチャ
データを保護するためのその他のプラクティス
どの戦略でも、データ災害に対する緩和も必要です。連続的なデータレプリケーションは、特定のタイプの災害から保護しますが、戦略に、保存データのバージョニングまたはポイントインタイムリカバリのためのオプションが含まれていない限り、データの破損や破壊からは保護しません。復旧サイトにレプリケートしたデータもバックアップして、レプリカに加えて、ポイントインタイムバックアップを作成する必要があります。
単一の AWS リージョン内の複数のアベイラビリティーゾーン (AZ) の使用
単一のリージョン内の複数の AZ を使用する場合、DR 実装は上記の戦略の複数の要素を使用します。まず、図 23 に示されているとおり、複数の AZ を使用して、高可用性 (HA) アーキテクチャを作成する必要があります。このアーキテクチャでは、Amazon EC2 インスタンスと Elastic Load Balancer にリソースが複数の AZ にデプロイされ、リクエストがアクティブに処理されるため、マルチサイトアクティブ/アクティブアプローチを使用します。このアーキテクチャはホットスタンバイでもあります。プライマリ Amazon RDS インスタンスが停止 (または AZ 自体が停止) すると、スタンバイインスタンスはプライマリに昇格されます。
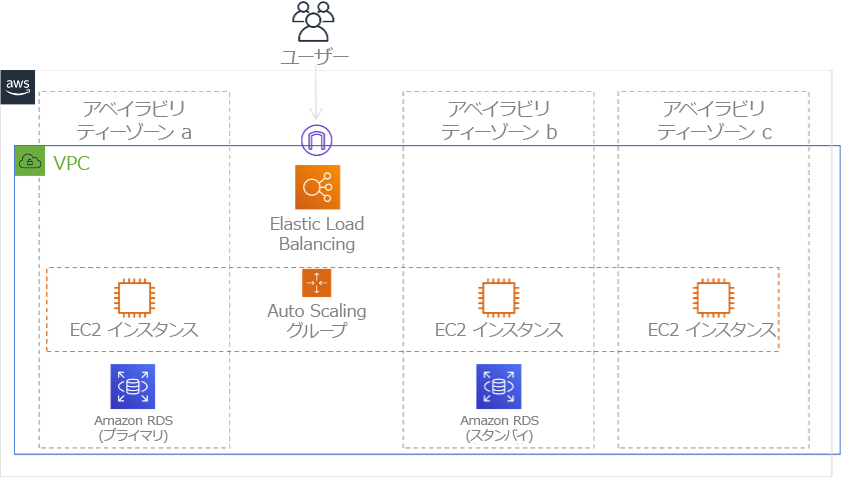
図 24: マルチ AZ アーキテクチャ
この HA アーキテクチャに加えて、ワークロードの実行に必要なすべてのデータのバックアップを追加する必要があります。これは、Amazon EBS ボリュームまたは Amazon Redshift クラスターなど、単一のゾーンに制約されるデータの場合に特に重要です。AZ に障害が発生した場合、このデータを別の AZ に復元する必要があります。可能な場合には、追加の保護層として、データバックアップも別の AWS リージョンにコピーしてください。
単一リージョンに対するあまり一般的でない代替アプローチとして、マルチ AZ DR があります。これはブログ記事「Amazon Application Recovery Controller を使用して回復力の高いアプリケーションを構築する、パート 1: 単一リージョンスタック
」で説明されています。ここでは、戦略は、AZ 間の分離をできるだけ高く維持して、リージョンのように動作させることです。この代替戦略を使用すると、アクティブ/アクティブまたはアクティブ/パッシブアプローチを選ぶことができます。 注記
ワークロードによっては、規制によるデータレジデンシー要件があります。現在 AWS リージョンが 1 つだけの地域のワークロードにこれが該当する場合、マルチリージョンではビジネスニーズに適しません。マルチ AZ 戦略は、ほとんどの災害に対して良好な保護を提供します。
-
ワークロードのリソースと、それらの設定がフェイルオーバー前 (正常なオペレーション時) に復旧リージョンでどうなるかを評価します。
インフラストラクチャと AWS リソースには、AWS CloudFormation
などのコードとしてインフラストラクチャ、または Hashicorp Terraform などのサードパーティーツールを使用します。複数のアカウントとリージョンに単一の操作でデプロイするには、AWS CloudFormation StackSets を使用できます。マルチサイトアクティブ/アクティブとホットスタンバイ戦略の場合、復旧リージョンにデプロイされるインフラストラクチャはプライマリリージョンと同じリソースを持ちます。パイロットライトとウォームスタンバイ戦略の場合、デプロイされたインフラストラクチャを本番稼働で使用するには追加のアクションが必要です。CloudFormation パラメータおよび条件付きロジックを使用すると、デプロイされるスタックがアクティブかスタンバイかを単一のテンプレート で制御できます。Elastic Disaster Recovery を使用する場合、サービスがアプリケーション設定とコンピューティングリソースの復元をレプリケートおよび調整します。 すべての DR 戦略では、データソースを AWS リージョン内でバックアップし、それらのバックアップをリカバリリージョンにコピーします。AWS Backup
は、これらのリソースのバックアップを設定、スケジュール、モニタリングする一元的なビューを提供します。パイロットライト、ウォームスタンバイ、およびマルチサイトアクティブ/アクティブの場合、Amazon Relational Database Service (Amazon RDS) DB インスタンスまたは Amazon DynamoDB テーブルなど、プライマリリージョンのデータを復旧リージョンのデータリソースにレプリケートする必要があります。したがって、これらのデータリソースはライブであり、復旧リージョンのリクエストに対応できます。 リージョン間での AWS サービスの運用方法の詳細については、「AWS のサービスによるマルチリージョンアプリケーションの作成
」に関するブログシリーズを参照してください。 -
必要なとき (災害発生時) に復旧リージョンをフェイルオーバーに備える方法を決定し、実装します。
マルチサイトアクティブ/アクティブの場合、フェイルオーバーとは、リージョンを隔離して、残りのアクティブリージョンに頼ることを意味します。一般に、これらのリージョンはトラフィックを受け入れる準備ができています。パイロットライトとウォームスタンバイ戦略の場合、復旧アクションとして、図 20 の EC2 インスタンスなど、不足しているリソースやその他の不足リソースをデプロイする必要があります。
上記の戦略のすべてで、データベースの読み取り専用インスタンスを昇格して、プライマリの読み書きインスタンスにしなければならない場合があります。
バックアップと復元の場合、バックアップからのデータの復元によって、EBS ボリューム、RDS DB インスタンス、DynamoDB テーブルなど、そのデータのリソースを作成します。インフラストラクチャを復元し、コードをデプロイする必要もあります。AWS Backup を使用して、データを復旧リージョンに復元できます。詳細については、「REL09-BP01 バックアップが必要なすべてのデータを特定してバックアップする、またはソースからデータを再現する」を参照してください。インフラストラクチャを再構築するには、Amazon Virtual Private Cloud (Amazon VPC)
、サブネット、セキュリティグループに加えて、EC2 インスタンスなどのリソースの作成も必要です。復元プロセスの大部分を自動化できます。詳細については、このブログ記事 を参照してください。 -
必要なとき (災害発生時) にフェイルオーバーするトラフィックを再ルーティングする方法を決定し、実装します。
このフェイルオーバー操作は、自動または手動で開始できます。ヘルスチェックまたはアラームに基づくフェイルオーバーの自動開始を使用するときには、不要なフェイルオーバー (誤ったアラーム) によって、使用できないデータやデータ損失などのコストが発生するため、注意が必要です。そのため、多くの場合、手動によるフェイルオーバーの開始が使用されます。この場合でも、フェイルオーバーのステップを自動化できるため、手動開始はボタンを押すようなものです。
AWS サービスを使用するときに検討すべき、いくつかのトラフィック管理オプションがあります。1 つのオプションは、Amazon Route 53
を使用することです。Amazon Route 53 を使用すると、1 つ以上の AWS リージョンの複数の IP エンドポイントを Route 53 ドメイン名に関連付けることができます。手動で開始されるフェイルオーバーを実装するには、Amazon Application Recovery Controller を使用できます。これは、リカバリリージョンにトラフィックを再ルーティングするための高可用性データプレーン API を提供します。フェイルオーバーを実装するときには、「REL11-BP04 復旧中はコントロールプレーンではなくデータプレーンを利用する」で説明されているように、データプレーン操作を使用し、コントロールプレーンを避けてください。 これらのオプションの詳細については、「ディザスタリカバリホワイトペーパー」のセクションを参照してください。
-
ワークロードをフェイルバックする方法のプランを設計します。
フェイルバックとは、災害イベントの終息後、ワークロード操作をプライマリリージョンに戻すことを言います。インフラストラクチャとコードをプライマリリージョンにプロビジョニングするときには、一般に、最初に使用したのと同じステップに従い、コードとしてのインフラストラクチャとコードデプロイパイプラインに依存します。フェイルバックでの課題は、データストアを復元し、動作中の復旧リージョンとの一貫性を確認することです。
フェイルオーバー状態では、復旧リージョンのデータベースはライブであり、最新データを保持しています。目的は、復旧リージョンからプライマリリージョンへ再同期して、最新であることを確認することです。
いくつかの AWS のサービスは、これを自動的に行います。Amazon DynamoDB グローバルテーブル
を使用している場合、プライマリリージョンのテーブルが使用できなくなった場合でも、オンラインに復帰すると、DynamoDB が保留中の書き込みの伝播を再開します。Amazon Aurora Global Database を使用していて、管理された計画的なフェイルオーバー を使用している場合、Aurora Global Database の既存のレプリケーショントポロジは維持されます。そのため、プライマリリージョンの以前の読み書きインスタンスがレプリカになり、復旧リージョンから更新を受け取ります。 これが自動でない場合、プライマリリージョンで復旧リージョンのデータベースのレプリカとしてデータベースを再確立する必要があります。多くの場合、これには、古いプライマリデータベースを削除して、新しいレプリカを作成する必要があります。
フェイルオーバー後、復旧リージョンでの実行を続行できる場合は、これを新しいプライマリリージョンにすることを検討してください。その場合でも、上記のすべてのステップを実行して、前のプライマリリージョンを復旧リージョンにします。一部の組織は、計画的ローテーションを実行して、プライマリリージョンと復旧リージョンを定期的に (3 か月ごとなど) 交換しています。
フェイルオーバーとフェイルバックに必要なすべてのステップをプレイブックに記載して、チームのメンバー全員が使用できるようにし、定期的にレビューする必要があります。
Elastic Disaster Recovery を使用する場合、サービスはフェイルバックプロセスの調整と自動化のサポートを提供します。詳細については、「フェイルバックの実行」を参照してください。
実装計画に必要な工数レベル: 高
リソース
関連するベストプラクティス:
関連ドキュメント:
関連動画:
