클라우드의 재해 복구 옵션
AWS 내에서 사용할 수 있는 재해 복구 전략은 백업을 만드는 비용이 저렴하고 복잡성이 낮은 것부터 여러 활성 리전을 사용하는 보다 복잡한 전략에 이르기까지 크게 4가지 방식으로 분류할 수 있습니다. 필요할 때 바로 실행할 수 있도록 재해 복구 전략을 정기적으로 테스트하는 것이 중요합니다.
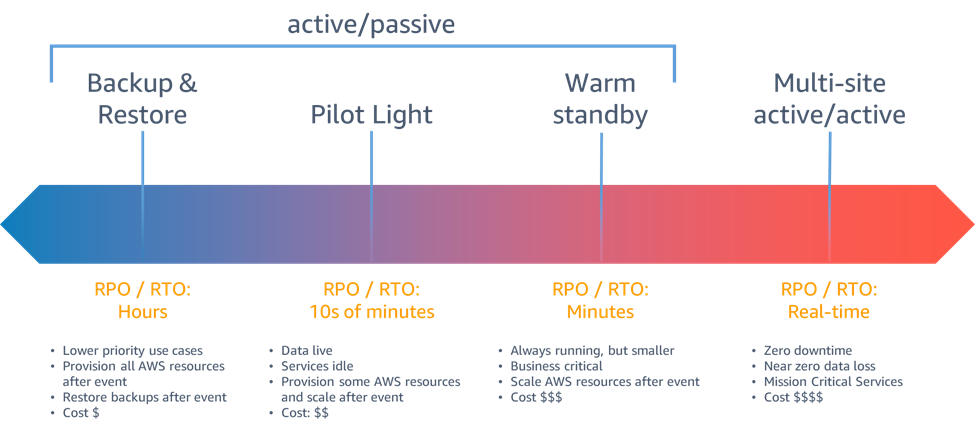
그림 6 - 재해 복구 전략
잘 설계되고
백업 및 복원
백업 및 복원은 데이터 손실 또는 손상을 완화하는 데 적합한 방식입니다. 이 방식은 데이터를 다른 AWS 리전으로 복제하여 리전 재해에 대비하거나 단일 가용 영역에 배포된 워크로드의 중복성 부족을 완화하는 데에도 사용할 수 있습니다. 데이터 외에도 복구 리전에 인프라, 구성 및 애플리케이션 코드를 재배포해야 합니다. 인프라를 오류 없이 신속하게 재배포할 수 있으려면 항상 AWS CloudFormation
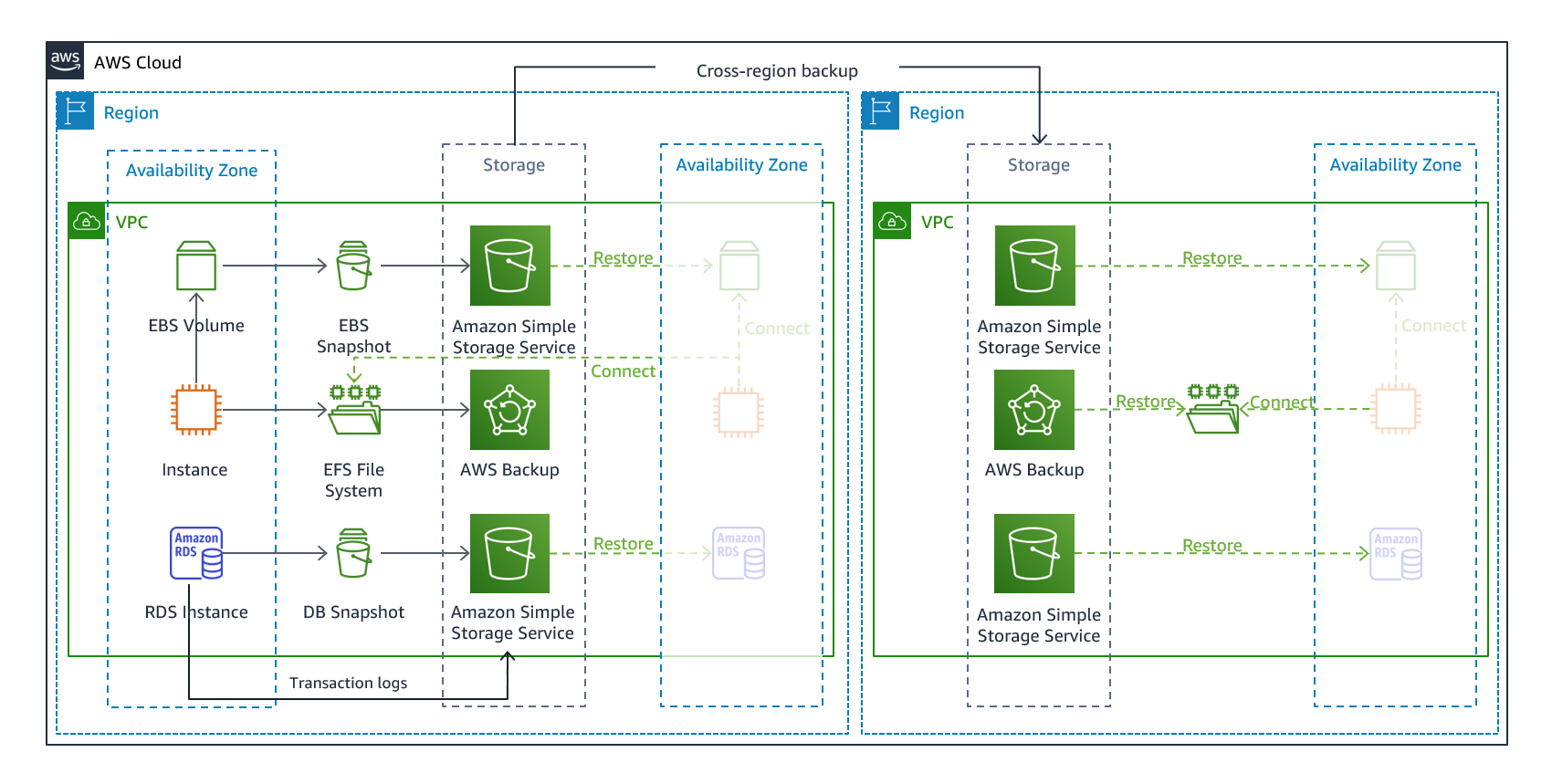
그림 7 - 백업 및 복원 아키텍처
AWS 서비스
워크로드 데이터에는 주기적으로 실행되거나 지속적인 백업 전략이 필요합니다. 백업을 얼마나 자주 실행하느냐에 따라 달성 가능한 복구 시점이 결정됩니다(RPO에 맞게 조정되어야 함). 또한 백업의 경우 백업을 수행한 시점으로 복원할 수 있는 방법을 제공해야 합니다. 특정 시점으로 복구를 사용한 백업은 다음 서비스 및 리소스를 통해 사용할 수 있습니다.
Amazon Simple Storage Service(Amazon S3)의 경우 Amazon S3 교차 리전 복제(CRR)
AWS Backup
AWS Backup은 리전 간 백업 복사(예: 재해 복구 리전으로 복사)를 지원합니다.
Amazon S3 데이터에 대한 추가 재해 복구 전략으로 S3 객체 버전 관리를 활성화는 것이 좋습니다. 객체 버전 관리는 작업 전의 원래 버전을 유지함으로써 S3의 데이터를 삭제 또는 수정 작업의 결과로부터 보호합니다. 객체 버전 관리는 사람의 실수로 인한 재해의 위험을 완화하는 데 유용할 수 있습니다. S3 복제를 사용하여 DR 리전에 데이터를 백업하는 경우, 기본적으로 소스 버킷에서 객체가 삭제되면 Amazon S3은 소스 버킷에만 삭제 마커를 추가합니다. 이 방식은 DR 리전의 데이터를 소스 리전의 악의적인 삭제로부터 보호합니다.
데이터 외에도 워크로드를 재배포하고 복구 시간 목표(RTO)를 달성하는 데 필요한 구성 및 인프라를 백업해야 합니다. AWS CloudFormation
재해 복구 리전에 백업으로 저장된 모든 데이터는 장애 조치 시 복원해야 합니다. AWS Backup은 복원 기능을 제공하지만 현재 예약된 복원 또는 자동 복원은 사용할 수 없습니다. AWS Backup용 API를 호출하는 AWS SDK를 사용하여 DR 리전에 자동 복원을 구현할 수 있습니다. 이를 정기적으로 반복하는 작업으로 설정하거나 백업이 완료될 때마다 복원을 트리거할 수 있습니다. 다음 그림은 Amazon Simple Notification Service(Amazon SNS)
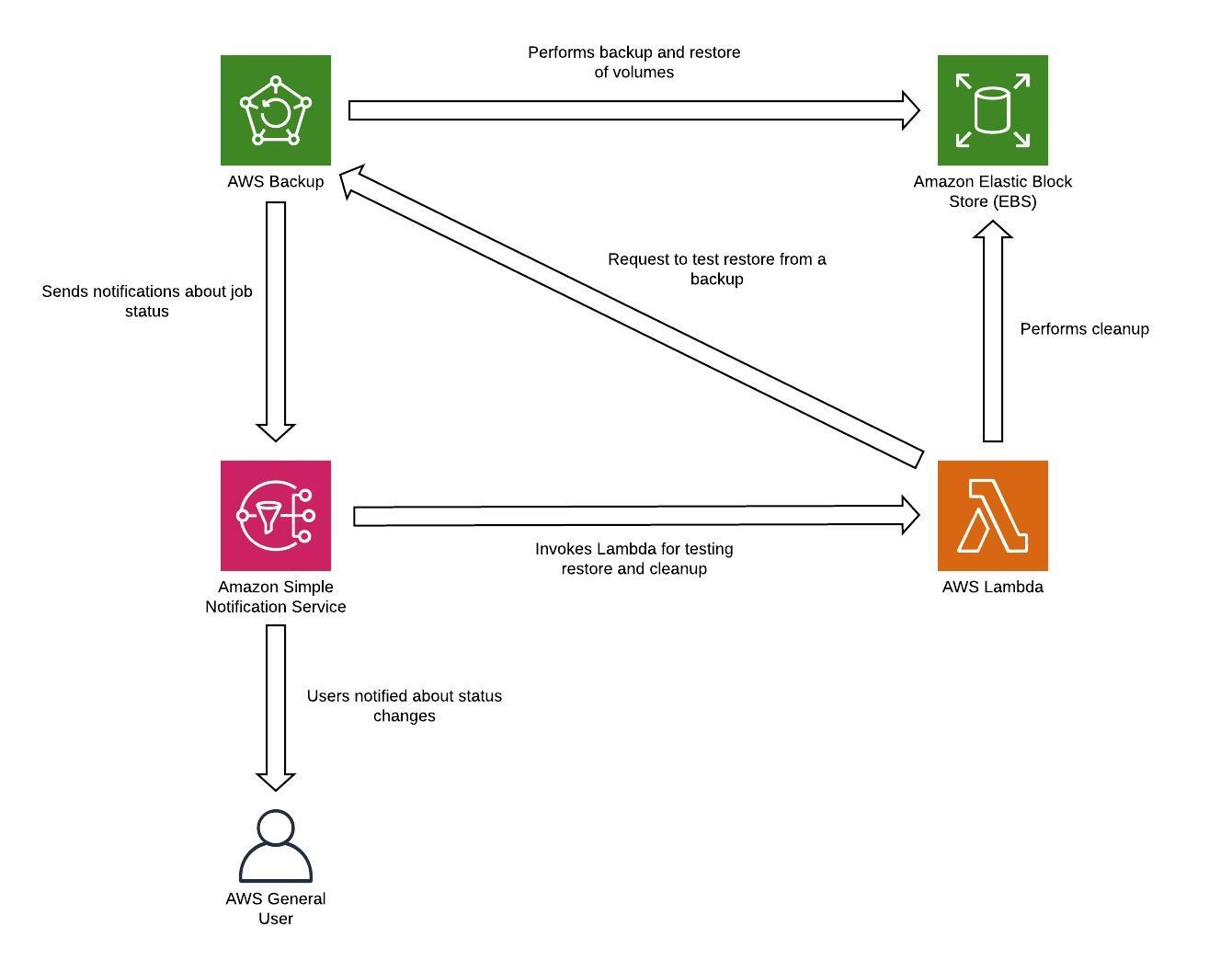
그림 8 - 백업 복원 및 테스트
참고
백업 전략에는 백업 테스트가 포함되어야 합니다. 자세한 내용은 재해 복구 테스트 단원을 참조하세요. 구현 실습 데모는 AWS Well-Architected 랩: 데이터 백업 및 복원 테스트
파일럿 라이트
파일럿 라이트 방식을 사용하면 한 리전에서 다른 리전으로 데이터를 복제하고 핵심 워크로드 인프라의 복사본을 프로비저닝할 수 있습니다. 데이터베이스 및 객체 스토리지와 같이 데이터 복제 및 백업을 지원하는 데 필요한 리소스는 항상 켜져 있습니다. 애플리케이션 서버와 같은 다른 요소는 애플리케이션 코드 및 구성과 함께 로드되지만 꺼져 있으며 테스트 중에 또는 재해 복구 장애 조치가 호출될 때만 사용됩니다. 백업 및 복원 방식과 달리 핵심 인프라는 항상 사용할 수 있으며 애플리케이션 서버를 켜고 확장하여 전체 규모의 프로덕션 환경을 신속하게 프로비저닝할 수 있는 옵션이 항상 있습니다.
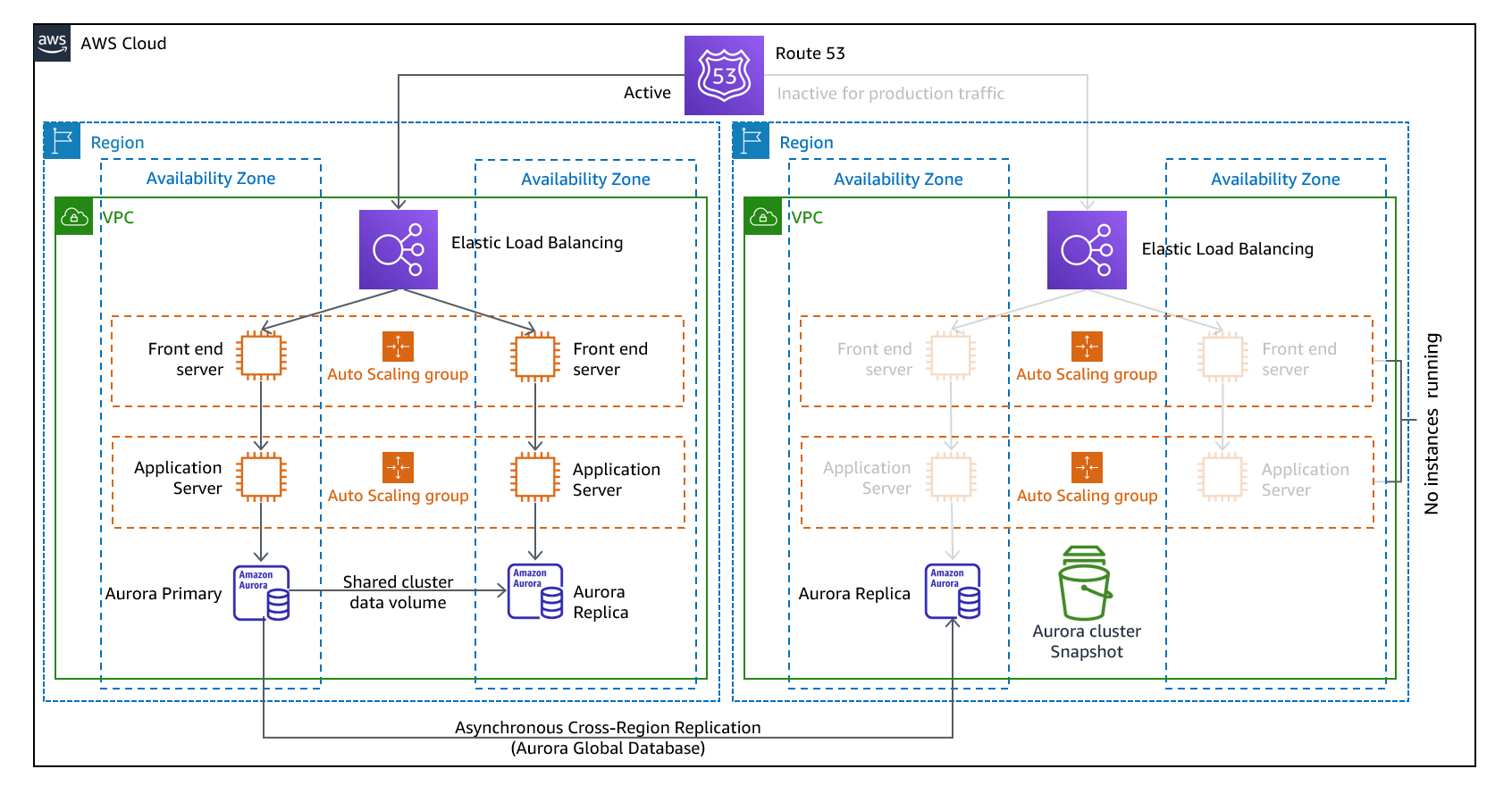
그림 9 - 파일럿 라이트 아키텍처
파일럿 라이트 방식은 활성 리소스를 최소화하여 지속적인 재해 복구 비용을 최소화하며 핵심 인프라 요구 사항이 모두 갖추어져 있기 때문에 재해 발생 시 복구를 단순화합니다. 이 복구 옵션을 사용하려면 배포 방식을 변경해야 합니다. 각 리전에서 핵심 인프라를 변경하고 워크로드(구성, 코드) 변경 사항을 각 리전에 동시에 배포해야 합니다. 배포를 자동화하고 코드형 인프라(IaC)를 사용하여 여러 계정 및 리전에 인프라를 배포하면 이 단계를 간소화할 수 있습니다(전체 인프라를 기본 리전에 배포하고 DR 리전으로의 인프라 배포는 축소하거나 끔). 리전별로 다른 계정을 사용하여 최고 수준의 리소스 및 보안 격리를 제공하는 것이 좋습니다(손상된 자격 증명이 재해 복구 계획의 일부인 경우).
이 방식을 사용하면 데이터 재해에도 대비해야 합니다. 지속적인 데이터 복제는 일부 유형의 재해로부터 사용자를 보호하지만 저장된 데이터의 버전 관리나 특정 시점으로 복구 옵션까지 전략에 포함하지 않으면 데이터 손상 또는 파괴로부터 사용자를 보호하지 못할 수 있습니다. 재해 리전에서 복제한 데이터를 백업하여 동일한 리전에 특정 시점으로 백업을 생성할 수 있습니다.
AWS 서비스
백업 및 복원 단원에서 다루는 AWS 서비스를 사용하여 특정 시점으로 백업을 생성하는 것 외에도 파일럿 라이트 전략을 사용할 때 다음 서비스도 고려하는 것이 좋습니다.
파일럿 라이트의 경우 DR 리전의 라이브 데이터베이스 및 데이터 스토어로의 지속적인 데이터 복제는 낮은 RPO에 가장 적합한 방법입니다(앞에서 설명한 특정 시점으로 백업과 함께 사용하는 경우). AWS는 다음 서비스 및 리소스를 사용하여 데이터에 대한 지속적인 리전 간 비동기 데이터 복제를 제공합니다.
연속 복제를 사용하면 DR 리전에서 거의 즉시 데이터 버전을 사용할 수 있습니다. 실제 복제 시간은 S3 객체용 S3 Replication Time Control(S3 RTC) 및 Amazon Aurora Global Database의 관리 기능과 같은 서비스를 사용하여 모니터링할 수 있습니다.
재해 복구 리전에서 읽기/쓰기 워크로드를 실행하기 위해 장애 조치를 수행하는 경우 RDS 읽기 전용 복제본을 기본 인스턴스로 승격해야 합니다. Aurora가 아닌 DB 인스턴스의 경우 프로세스를 완료하는 데 몇 분이 걸리며 재부팅도 프로세스의 일부입니다. RDS를 통한 교차 리전 복제(CRR) 및 장애 조치의 경우 Amazon Aurora Global Database를 사용하면 몇 가지 이점이 있습니다. Global Database는 전용 인프라를 사용하여 애플리케이션을 지원하는 데 데이터베이스를 완전히 사용할 수 있으며, 일반적인 대기 시간이 1초 미만인 보조 리전(AWS 리전 내에서는 100밀리초 미만)에 복제할 수 있습니다. Amazon Aurora Global Database를 사용하면 기본 리전의 성능 저하 또는 중단이 발생하는 경우 리전 전체가 중단되더라도 1분 이내에 보조 리전 중 하나를 승격하여 읽기/쓰기 작업을 맡도록 할 수 있습니다. 승격은 자동으로 수행될 수 있으며 재부팅할 필요가 없습니다.
리소스가 더 적거나 작은 핵심 워크로드 인프라의 축소 버전을 DR 리전에 배포해야 합니다. AWS CloudFormation을 사용하면 인프라를 정의하고 AWS 계정과 AWS 리전 전체에 일관되게 배포할 수 있습니다. AWS CloudFormation에서는 사전 정의된 의사 파라미터를 사용하여 AWS 계정 및 해당 계정이 배포된 AWS 리전을 식별합니다. 따라서 CloudFormation 템플릿에 조건 로직을 구현하여 DR 리전에 축소 버전의 인프라만 배포할 수 있습니다. EC2 인스턴스 배포의 경우 Amazon Machine Image(AMI)가 하드웨어 구성 및 설치된 소프트웨어와 같은 정보를 제공합니다. 필요한 AMI를 생성하는 Image Builder 파이프라인을 구현하고 이를 기본 리전과 백업 리전 모두에 복사할 수 있습니다. 이렇게 하면 재해 발생 시 새 리전에서 워크로드를 재배포하거나 확장하는 데 필요한 모든 것을 이 골든 AMI에 포함할 수 있습니다. Amazon EC2 인스턴스는 축소된 구성(기본 리전보다 인스턴스 수가 적음)으로 배포됩니다. 최대 절전 모드를 사용하여 EC2 인스턴스를 중지된 상태로 전환하면 EC2 비용을 지불하지 않고 사용한 스토리지에 대해서만 비용을 지불하면 됩니다. EC2 인스턴스를 시작하려면 AWS Command Line Interface(CLI)
파일럿 라이트와 같은 활성/대기 구성의 경우 모든 트래픽은 처음에 기본 리전으로 이동하고 기본 리전을 더 이상 사용할 수 없는 경우 재해 복구 리전으로 전환됩니다. AWS 서비스 사용을 고려할 트래픽 관리 옵션에는 두 가지가 있습니다. 첫 번째 옵션은 Amazon Route 53
두 번째 옵션은 AWS Global Accelerator
CloudEndure Disaster Recovery
AWS Marketplace

그림 10 - CloudEndure Disaster Recovery 아키텍처
웜 스탠바이
웜 스탠바이 방식에는 축소되었지만 완전히 작동하는 프로덕션 환경의 복사본이 다른 리전에 있는지 확인하는 작업이 포함됩니다. 이 방식은 워크로드가 다른 리전에서 항상 켜져 있기 때문에 파일럿 라이트 개념을 확장하고 복구 시간을 단축합니다. 또한 이 방식을 사용하면 보다 쉽게 테스트를 수행하거나 지속적인 테스트를 구현하여 재해 복구 역량에 대한 확신을 높일 수 있습니다.
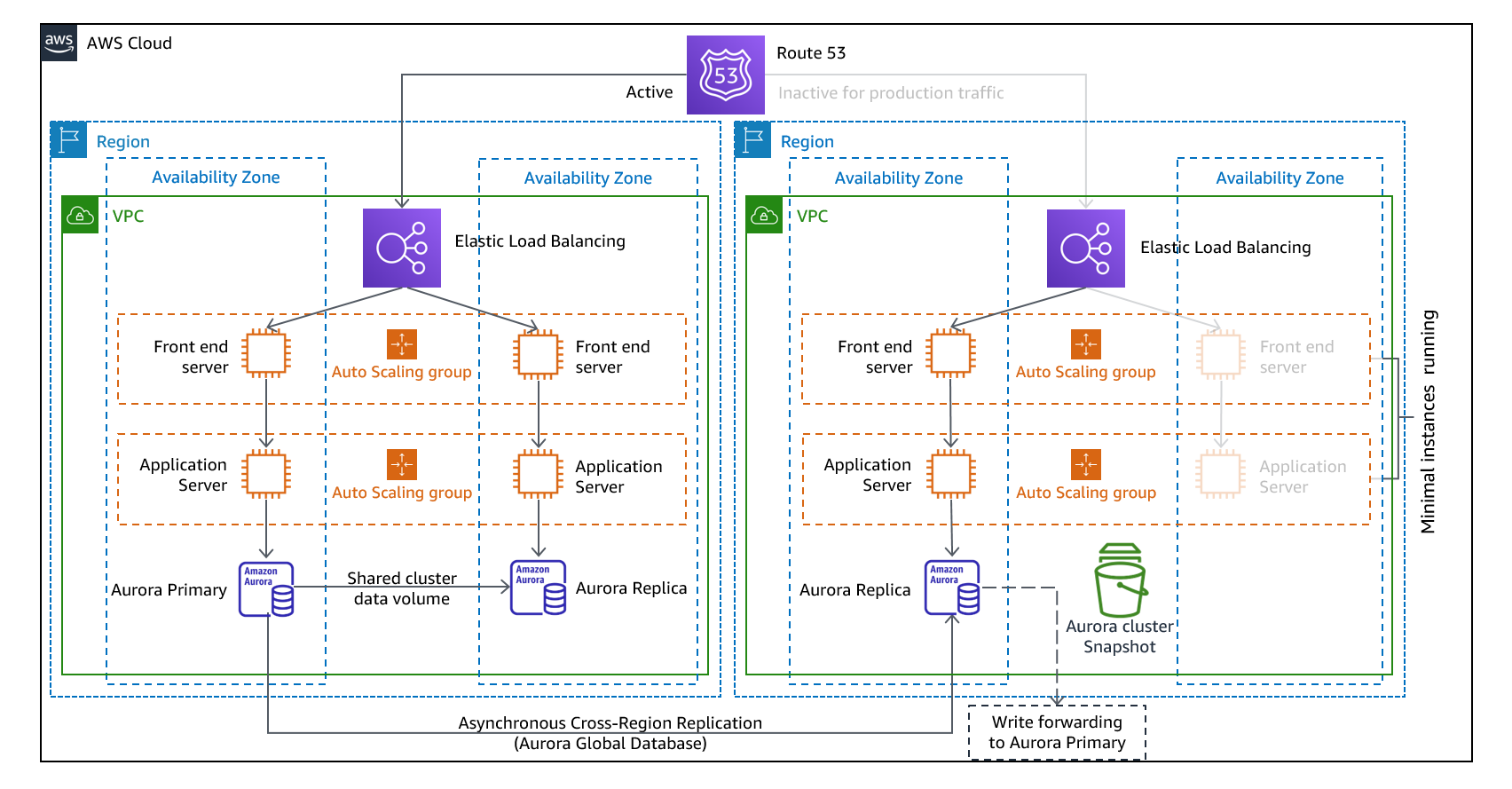
그림 11 - 웜 스탠바이 아키텍처
참고: 파일럿 라이트와 웜 스탠바이의 차이를 이해하기 어려울 수 있습니다. 둘 다 기본 리전 자산의 복사본이 있는 DR 리전의 환경을 포함합니다. 차이점은 파일럿 라이트는 먼저 추가 조치를 취하지 않으면 요청을 처리할 수 없는 반면, 웜 스탠바이는 트래픽을 (감소된 용량 수준에서) 즉시 처리할 수 있다는 것입니다. 파일럿 라이트 방식에서는 서버를 ‘켜고’, 추가(비 코어) 인프라를 배포하고 확장해야 하는 반면, 웜 스탠바이 방식에서는 확장만 하면 됩니다(모든 것이 이미 배포되어 실행 중임). RTO 및 RPO 요구 사항을 검토하여 두 방식 중에서 선택할 수 있습니다.
AWS 서비스
백업 및 복원과 파일럿 라이트가 적용되는 모든 AWS 서비스는 데이터 백업, 데이터 복제, 활성/대기 트래픽 라우팅, EC2 인스턴스를 포함한 인프라 배포를 위해 웜 스탠바이 모드에서도 사용됩니다.
AWS Auto Scaling
다중 사이트 활성/활성
다중 사이트 활성/활성 또는 상시 대기 활성/활성 전략의 일부로 워크로드를 여러 리전에서 동시에 실행할 수 있습니다. 다중 사이트 활성/활성 방식에서는 배포된 모든 리전의 트래픽을 처리하는 반면, 상시 대기 전략에서는 단일 리전의 트래픽만 처리하고 다른 리전은 재해 복구에만 사용됩니다. 다중 사이트 활성/활성 방식을 통해 사용자는 워크로드가 배포된 모든 리전에서 워크로드에 액세스할 수 있습니다. 이 방법은 가장 복잡하고 비용이 많이 드는 재해 복구 방식이지만 올바른 기술 선택 및 구현을 통해 대부분의 재해에 대한 복구 시간을 거의 제로에 가깝게 줄일 수 있습니다. 그러나 데이터 손상은 백업에 의존해야 하므로 일반적으로 복구 시점은 0이 아닙니다. 상시 대기는 사용자가 단일 리전으로만 연결되고 DR 리전은 트래픽을 받지 않는 활성/비활성 구성을 사용합니다. 대부분의 고객은 두 번째 리전에서 전체 환경을 구축하려는 경우 활성/활성 환경을 사용하는 것이 합리적이라는 것을 알게 됩니다. 또는 사용자 트래픽을 처리하는 데 두 리전을 모두 사용하지 않으려는 경우 웜 스탠바이는 경제적이며 운영 면에서 덜 복잡한 방식을 제공합니다.
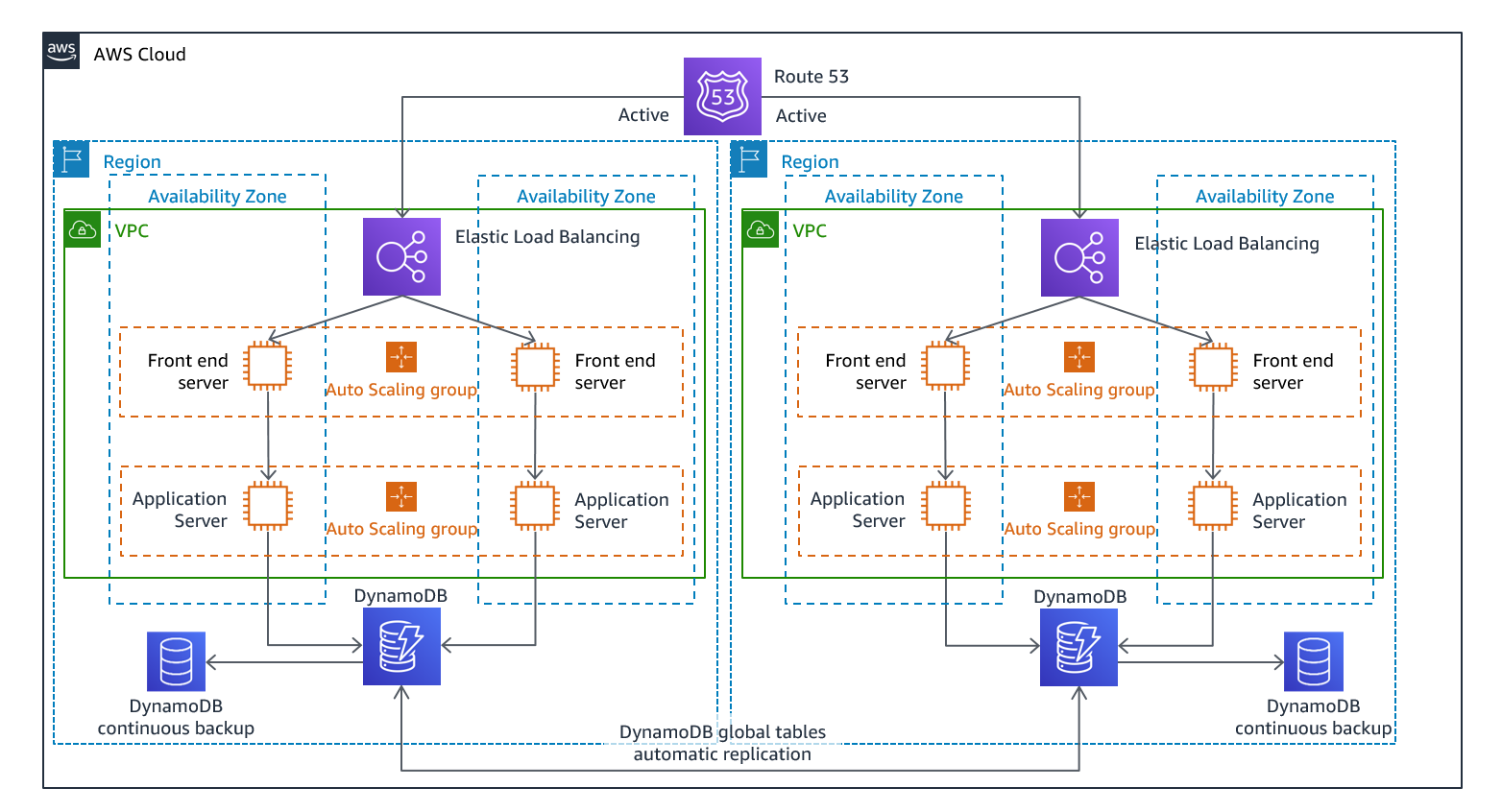
그림 12 - 다중 사이트 활성/활성 아키텍처(상시 대기의 경우 활성 경로 하나를 비활성으로 변경)
다중 사이트 활성/활성의 경우 워크로드가 둘 이상의 리전에서 실행 중이므로 이 시나리오에서는 장애 조치와 같은 상황이 없습니다. 이 경우 재해 복구 테스트는 워크로드가 리전의 손실에 어떻게 반응하는지에 초점을 맞춥니다. 가령 장애가 발생한 리전에서 먼 곳으로 트래픽이 라우팅되는지와 같은 사항에 중점을 둡니다. 다른 리전에서 모든 트래픽을 처리할 수 있는지와 같은 사항도 고려합니다. 데이터 재해에 대한 테스트도 필요합니다. 백업 및 복구는 여전히 필요하며 정기적으로 테스트해야 합니다. 또한 데이터 손상, 삭제 또는 난독화와 관련된 데이터 재해의 복구 시간은 항상 0보다 길며 복구 지점은 항상 재해가 발견되기 전의 특정 시점입니다. 복구 시간을 0에 가깝게 유지하기 위해 다중 사이트 활성/활성(또는 상시 대기) 방식에 추가적인 복잡성과 비용이 필요한 경우 보안을 유지하고 인적 오류를 방지하여 인적 재해를 완화하기 위해 추가적인 노력을 기울여야 합니다.
AWS 서비스
백업 및 복원, 파일럿 라이트 및 웜 스탠바이가 적용되는 모든 AWS 서비스는 특정 시점으로 데이터 백업, 데이터 복제, 활성/활성 트래픽 라우팅, EC2 인스턴스를 포함한 인프라 배포 및 확장을 위해 다중 사이트 활성/활성 모드에서도 사용됩니다.
앞에서 설명한 활성/비활성 시나리오(파일럿 라이트 및 웜 스탠바이)의 경우 네트워크 트래픽을 활성 리전으로 라우팅하는 데 Amazon Route 53과 AWS Global Accelerator를 모두 사용할 수 있습니다. 또한 활성/활성 전략의 경우 이 두 서비스는 어떤 사용자를 어떤 활성 리전 엔드포인트로 연결할지 결정하는 정책을 정의할 수 있습니다. AWS Global Accelerator를 사용하여 각 애플리케이션 엔드포인트로 향하는 트래픽 다이얼을 설정함으로써 트래픽의 비율을 제어할 수 있습니다. Amazon Route 53은 이 백분율 방식과 지리 근접성 및 대기 시간 기반 방식을 포함한 여러 다른 사용 가능한 정책도 지원합니다. Global Accelerator는 AWS 엣지 서버의 광범위한 네트워크를 자동으로 활용하여 가능한 한 빨리 트래픽을 AWS 네트워크 백본으로 온보딩하므로 요청 대기 시간이 단축됩니다.
이 전략을 사용한 데이터 복제는 0에 가까운 RPO를 가능하게 합니다. Amazon Aurora Global Database와 같은 AWS 서비스는 데이터베이스를 애플리케이션 지원에 전적으로 사용할 수 있는 전용 인프라를 사용하며, 일반적으로 1초 미만의 대기 시간으로 1개의 보조 리전에 복제할 수 있습니다. 활성/비활성 전략을 사용하면 기본 리전에만 쓰기가 발생합니다. 활성/활성와의 차이점은 각 활성 리전에 대한 쓰기가 처리되는 방식을 설계하는 데 있습니다. 사용자와 가장 가까운 리전에서 사용자 읽기가 처리되도록 설계하는 것이 일반적이며 이를 로컬 읽기라고 합니다. 쓰기 방식을 설계할 때는 다음과 같은 몇 가지 옵션이 있습니다.
-
글로벌 쓰기 전략은 모든 쓰기를 단일 리전으로 라우팅합니다. 해당 리전에서 장애가 발생할 경우 다른 리전이 승격되어 쓰기를 처리합니다. Aurora Global Database는 리전 전체에서 읽기 복제본과의 동기화를 지원하며 읽기/쓰기 작업을 처리하도록 보조 리전 중 하나를 1분 이내에 승격할 수 있으므로 글로벌 쓰기에 적합합니다.
-
로컬 쓰기 전략은 읽기와 마찬가지로 가장 가까운 리전으로 쓰기를 라우팅합니다. Amazon DynamoDB 글로벌 테이블은 이러한 전략을 지원하여 글로벌 테이블이 배포된 모든 리전에서 읽고 쓸 수 있도록 합니다. Amazon DynamoDB 글로벌 테이블은 동시 업데이트 간에 last writer wins 조정을 사용합니다.
-
쓰기 파티션 전략은 쓰기 충돌을 피하기 위해 파티션 키(예: 사용자 ID)를 기반으로 특정 리전에 쓰기를 할당합니다. 이 경우 양방향으로 구성된
Amazon S3 복제를 사용할 수 있으며 현재 두 리전 간 복제를 지원합니다. 이 방식을 구현할 때는 A와 B 두 버킷 모두에서 복제본 수정 동기화를 활성화하여 복제된 객체에 대한 객체 ACL(액세스 제어 목록), 객체 태그 또는 객체 잠금과 같은 복제본 메타데이터 변경 사항을 복제해야 합니다. 활성 리전의 버킷 간에 삭제 마커를 복제할지 여부도 구성할 수 있습니다. 복제 외에도 데이터 손상 또는 파괴 이벤트로부터 보호하기 위해 특정 시점으로 백업도 전략에 포함해야 합니다.
AWS CloudFormation은 여러 AWS 리전의 AWS 계정 간에 일관되게 배포된 인프라를 적용할 수 있는 강력한 도구입니다. AWS CloudFormation StackSets는 단일 작업으로 여러 계정과 리전에서 CloudFormation 스택을 생성, 업데이트 또는 삭제할 수 있도록 하여 이 기능을 확장합니다. AWS CloudFormation은 YAML 또는 JSON을 사용하여 코드형 인프라를 정의하지만 AWS Cloud Development Kit (AWS CDK)
