Criar um cluster de bancos de dados do Amazon Aurora
Um cluster de banco de dados do Amazon Aurora consiste em uma instância de banco de dados compatível com o MySQL ou o PostgreSQL e um volume de cluster que detém os dados do cluster de banco de dados copiados em três zonas de disponibilidade como um único volume virtual. Por padrão, um cluster de banco de dados Aurora contém uma instância de banco de dados primária que faz leituras e gravações e, como opção, até 15 réplicas do Aurora (instâncias de banco de dados de leitor). Para obter mais informações sobre clusters de bancos de dados Aurora, consulte Clusters de banco de dados do Amazon Aurora.
O Aurora tem dois tipos principais de cluster de banco de dados:
-
Provisionado pelo Aurora: você escolhe a classe de instância de banco de dados para as instâncias do gravador e do leitor com base na workload prevista. Para obter mais informações, consulte Classes de instâncias de banco de dados Amazon Aurora. O provisionado pelo Aurora tem várias opções, incluindo bancos de dados globais do Aurora. Para obter mais informações, consulte Usar o Amazon Aurora Global Database.
-
Aurora Serverless: Aurora Serverless v2 é uma configuração de ajuste de escala automático sob demanda do Aurora. A capacidade é ajustada automaticamente com base na demanda da aplicação. Você será cobrado apenas pelos recursos que seu cluster de banco de dados consumir. Essa automação é especialmente útil para ambientes com workloads altamente variáveis e imprevisíveis. Para obter mais informações, consulte Usar o Aurora Serverless v2.
A seguir, é possível descobrir como criar um cluster de banco de dados Aurora. Para começar, primeiro consulte Pré-requisitos do cluster de banco de dados.
Para obter instruções sobre como se conectar ao cluster de bancos de dados Aurora, consulte Como conectar-se a um cluster de bancos de dados Amazon Aurora.
Sumário
Pré-requisitos do cluster de banco de dados
Importante
Antes de criar um cluster de bancos de dados do Aurora, você deve concluir as tarefas no Configuração de seu ambiente para Amazon Aurora.
As etapas a seguir são pré-requisitos que devem ser concluídos antes da criação de um cluster de banco de dados.
Configurar a rede para o cluster de banco de dados
Um cluster de banco de dados do Amazon Aurora pode ser criado apenas em uma nuvem privada virtual (VPC) baseada no serviço Amazon VPC em uma região Região da AWS que tenha pelo menos duas zonas de disponibilidade. O grupo de sub-redes do banco de dados escolhido para o cluster de banco de dados deve incluir pelo menos duas zonas de disponibilidade. Essa configuração garante que o cluster de banco de dados tenha sempre pelo menos uma instância de banco de dados disponível para failover, no caso improvável de ocorrer uma falha em uma zona de disponibilidade.
Se você planeja configurar a conectividade entre o novo cluster de banco de dados e uma instância do EC2 na mesma VPC, pode fazer isso durante a criação do cluster. Se você planeja se conectar ao cluster de banco de dados usando recursos que não sejam instâncias do EC2 na mesma VPC, pode configurar as conexões de rede manualmente.
Tópicos
Configurar a conectividade automática de rede com uma instância do EC2
Ao criar um cluster de banco de dados do Aurora, use o AWS Management Console para configurar a conectividade entre uma instância do Amazon EC2 e o novo cluster. Quando você faz isso, o RDS configura automaticamente as definições de VPC e rede. O cluster de banco de dados é criado na mesma VPC da instância do EC2 para que a instância do EC2 possa acessar o cluster de banco de dados.
Confira a seguir os requisitos para conectar uma instância do EC2 ao cluster de banco de dados:
-
A instância do EC2 deve existir na Região da AWS antes de criar o cluster de banco de dados.
Se não houver nenhuma instância do EC2 na Região da AWS, o console fornecerá um link para que você crie uma.
-
No momento, o cluster de banco de dados não pode ser um cluster de banco de dados do Aurora Serverless ou parte de um banco de dados global do Aurora.
-
O usuário que está criando a instância de banco de dados deve ter permissões para realizar as seguintes operações:
-
ec2:AssociateRouteTable -
ec2:AuthorizeSecurityGroupEgress -
ec2:AuthorizeSecurityGroupIngress -
ec2:CreateRouteTable -
ec2:CreateSubnet -
ec2:CreateSecurityGroup -
ec2:DescribeInstances -
ec2:DescribeNetworkInterfaces -
ec2:DescribeRouteTables -
ec2:DescribeSecurityGroups -
ec2:DescribeSubnets -
ec2:ModifyNetworkInterfaceAttribute -
ec2:RevokeSecurityGroupEgress
-
Usar essa opção cria um cluster de banco de dados privado. O cluster de banco de dados usa um grupo de sub-redes de banco de dados somente com sub-redes privadas para restringir o acesso aos recursos da VPC.
Para conectar uma instância do EC2 ao cluster de banco de dados, escolha Connect to an EC2 compute resource (Conectar-se a um recurso de computação do EC2) na seção Connectivity (Conectividade) da página Create database (Criar banco de dados).

Quando você escolhe Connect to an EC2 compute resource (Conectar-se a um recurso de computação do EC2), o RDS define as opções a seguir automaticamente. Você não pode alterar essas configurações, a menos que opte por não configurar a conectividade com uma instância do EC2 escolhendo Don't connect to an EC2 compute resource (Não conectar a um recurso de computação do EC2).
| Opção do console | Configuração automática |
|---|---|
|
Tipo de rede |
O RDS define o tipo de rede como IPv4. No momento, o modo de pilha dupla não é compatível quando você configura uma conexão entre uma instância do EC2 e o cluster de banco de dados. |
|
Virtual Private Cloud (VPC) |
O RDS define a VPC como aquela associada à instância do EC2. |
|
DB subnet group (Grupo de subredes do banco de dados) |
O RDS requer um grupo de sub-redes de banco de dados com uma sub-rede privada na mesma zona de disponibilidade da instância do EC2. Se existir um grupo de sub-redes de banco de dados que atenda a esse requisito, o RDS usará o grupo de sub-redes de banco de dados existente. Por padrão, essa opção está definida como Automatic setup (Configuração automática). Quando você escolhe Automatic setup (Configuração automática) e não há nenhum grupo de sub-redes de banco de dados que atenda a esse requisito, ocorre a ação a seguir. O RDS usa três sub-redes privadas disponíveis em três zonas de disponibilidade, das quais uma é a mesma da instância do EC2. Se não houver uma sub-rede privada disponível em uma zona de disponibilidade, o RDS criará uma sub-rede privada na zona de disponibilidade. O RDS cria o grupo de sub-redes de banco de dados. Quando houver uma sub-rede privada disponível, o RDS usará a tabela de rotas associada a ela e adicionará todas as sub-redes que criar a essa tabela de rotas. Quando não houver nenhuma sub-rede privada disponível, o RDS criará uma tabela de rotas sem acesso ao gateway da Internet e adicionará as sub-redes que criar à tabela de rotas. O RDS também permite que você use grupos de sub-redes de banco de dados existentes. Selecione Choose existing (Selecionar existente) se quiser usar um grupo de sub-redes de banco de dados existente de sua escolha. |
|
Acesso público |
O RDS escolhe No (Não) para que o cluster de banco de dados não fique publicamente acessível. Por motivos de segurança, é uma prática recomendada manter o banco de dados privado e garantir que ele não possa ser acessado pela Internet. |
|
VPC security group (firewall) [Grupo de segurança da VPC (firewall)] |
O RDS cria um grupo de segurança associado ao cluster de banco de dados. O grupo de segurança é chamado de O RDS também cria um grupo de segurança associado à instância de banco de dados. O grupo de segurança é chamado de Para adicionar outro novo grupo de segurança, escolha Create new (Criar novo) e digite o nome do novo grupo de segurança. Para adicionar grupos de segurança existentes, escolha Choose existing (Escolher existente) e selecione os grupos de segurança que deseja adicionar. |
|
Zona de disponibilidade |
Quando você não cria uma réplica do Aurora em Availability & durability (Disponibilidade e durabilidade) durante a criação do cluster de banco de dados (implantação single-AZ), o RDS escolhe a zona de disponibilidade da instância do EC2. Quando você cria uma réplica do Aurora durante a criação do cluster de banco de dados (implantação multi-AZ), o RDS escolhe a zona de disponibilidade da instância do EC2 para uma instância de banco de dados no cluster de banco de dados. O RDS escolhe aleatoriamente uma zona de disponibilidade diferente para a outra instância de banco de dados no cluster de banco de dados. A instância de banco de dados primária ou a réplica do Aurora é criada na mesma zona de disponibilidade da instância do EC2. Existe a possibilidade de custos entre zonas de disponibilidade se ocorrer um failover e a instância de banco de dados gravadora estiver em uma zona de disponibilidade diferente. |
Para ter mais informações sobre essas configurações, consulte Configurações de clusters de bancos de dados do Aurora.
Se você fizer alguma alteração nessas configurações após a criação do cluster de banco de dados, as alterações poderão afetar a conexão entre a instância do EC2 e o cluster de banco de dados.
Configurar a rede manualmente
Se você planeja se conectar ao cluster de banco de dados usando recursos que não sejam instâncias do EC2 na mesma VPC, pode configurar as conexões de rede manualmente. Se você usar o AWS Management Console para criar o cluster de banco de dados, o Amazon RDS poderá criar automaticamente uma VPC para você. Ou você poderá usar a VPC existente ou criar uma nova VPC para o cluster de bancos de dados do Aurora. Seja qual for a abordagem escolhida, a VPC deve ter pelo menos uma sub-rede em pelo menos duas das zonas de disponibilidade para você usá-la com um cluster de banco de dados do Amazon Aurora.
Por padrão, o Amazon RDS cria automaticamente a instância de banco de dados primária e a réplica do Aurora nas zonas de disponibilidade para você. Para escolher uma zona de disponibilidade específica, é necessário alterar a configuração de implantação multi-AZ Availability & durability (Disponibilidade e durabilidade) para Don't create an Aurora Replica (Não criar uma réplica do Aurora). Essa ação exibe uma configuração de Availability Zone (Zona de disponibilidade) que permite escolher entre as zonas de disponibilidade em sua VPC. No entanto, recomendamos manter a configuração padrão e permitir que o Amazon RDS crie uma implantação multi-AZ e escolha as zonas de disponibilidade para você. Ao fazer isso, o cluster de banco de dados do Aurora é criado com os recursos de failover rápido e alta disponibilidade, que são dois dos principais benefícios do Aurora.
Se você não tiver uma VPC padrão, ou não tiver criado uma VPC, o Amazon RDS poderá criar automaticamente uma VPC para você ao criar um cluster de bancos de dados usando o console. Caso contrário, você deverá fazer o seguinte:
-
Crie uma VPC com com no mínimo uma sub-rede em pelo menos duas das zonas de disponibilidade na Região da AWS em que você deseja implantar o cluster de banco de dados. Para ter mais informações, consulte Trabalhar com um cluster de banco de dados em uma VPC e Tutorial: Criar uma VPC para usar com um cluster de banco de dados (somente IPv4).
-
Especifique um grupo de segurança da VPC que autorize conexões ao seu cluster de banco de dados. Para ter mais informações, consulte Fornecer acesso ao cluster de banco de dados na VPC criando um grupo de segurança e Controlar acesso com grupos de segurança.
-
Especifique um grupo de sub-redes de banco de dados do RDS que defina pelo menos duas sub-redes na VPC que possam ser usadas pelo cluster de banco de dados. Para obter mais informações, consulte Trabalhar com grupos de sub-redes de banco de dados.
Para obter informações sobre as VPCs, consulte Amazon VPC e Amazon Aurora. Para obter um tutorial que configura a rede para um cluster de banco de dados privado, consulte Tutorial: Criar uma VPC para usar com um cluster de banco de dados (somente IPv4).
Se você quiser se conectar a um recurso que não esteja na mesma VPC do cluster de banco de dados Aurora, veja os cenários apropriados em Cenários para acessar um cluster de banco de dados em uma VPC.
Pré-requisitos adicionais
Antes de criar o cluster de banco de dados multi-AZ, considere os seguintes pré-requisitos adicionais:
-
Se estiver se conectando à AWS usando credenciais do AWS Identity and Access Management (IAM), sua conta da AWS deverá ter políticas do IAM que concedam as permissões necessárias para executar operações do Amazon RDS. Para obter mais informações, consulte Gerenciamento de identidade e acesso no Amazon Aurora.
Se você estiver usando o IAM para acessar o console do Amazon RDS, primeiro será necessário fazer login no AWS Management Console com suas credenciais de usuário. Depois, acesse o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
Se quiser personalizar os parâmetros de configuração do cluster de banco de dados, você deverá especificar um grupo de parâmetros do cluster de banco de dados e um grupo de parâmetros de banco de dados com as configurações de parâmetro obrigatórias. Para obter informações sobre como criar ou modificar um grupo de parâmetros do cluster de banco de dados ou um grupo de parâmetros de banco de dados, consulte Grupos de parâmetros para Amazon Aurora.
-
Determine o número de porta de TCP/IP a ser especificado para seu cluster de banco de dados. Em algumas empresas, os firewalls bloqueiam conexões com as portas padrão (3306 para MySQL, 5432 para PostgreSQL) do Aurora. Se o firewall da sua empresa bloquear a porta padrão, escolha outra porta para o cluster de banco de dados. Todas as instâncias em um cluster de banco de dados usam a mesma porta.
-
Se a versão principal do mecanismo do banco de dados tiver atingido a data de término do suporte padrão do RDS, você deverá usar a opção Suporte estendido da CLI ou o parâmetro de API do RDS. Consulte mais informações em “RDS Extended Support” no Configurações de clusters de bancos de dados do Aurora.
Criar um cluster de banco de dados
Você pode criar um novo cluster de bancos de dados Aurora usando o AWS Management Console, a AWS CLI ou a API do RDS.
É possível criar um cluster de banco de dados usando o AWS Management Console com a opção Fácil de criar habilitada ou não. Com a Easy create (Criação fácil) habilitada, você especifica apenas o tipo de mecanismo de banco de dados, o tamanho da instância de banco de dados e o identificador da instância de banco de dados. A Easy create (Criação fácil) usa a configuração padrão para outras opções de configuração. Com a Easy create (Criação fácil) desabilitada, você especifica mais opções de configuração ao criar um banco de dados, incluindo as de disponibilidade, segurança, backups e manutenção.
nota
Para este exemplo, a opção Standard Create (Criação padrão) está habilitada e a Easy Create (Criação fácil) não está habilitada. Para ter informações sobre como criar um cluster de banco de dados com a opção Fácil de criar habilitada, consulte Conceitos básicos do Amazon Aurora.
Como criar um cluster de bancos de dados do Aurora usando o console
-
Faça login no AWS Management Console e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
No canto superior direito do AWS Management Console, escolha a região da AWS em que você deseja criar o cluster de banco de dados.
O Aurora não está disponível em todas as regiões da AWS. Para obter uma lista das regiões da AWS em que o Aurora esteja disponível, consulte Disponibilidade de regiões.
-
No painel de navegação, escolha Databases (Bancos de dados).
-
Selecione Criar banco de dados.
-
Em Escolher um método de criação de banco de dados, escolha Criação padrão.
-
Em Tipo de mecanismo, selecione uma das seguintes opções:
-
Aurora (compatível com MySQL)
-
Aurora (compatível com PostgreSQL)

-
-
Escolha a Versão do mecanismo.
Para obter mais informações, consulte Versões do Amazon Aurora. Você pode usar os filtros para escolher versões compatíveis com os recursos que você deseja, como Aurora Serverless v2. Para obter mais informações, consulte Usar o Aurora Serverless v2.
-
Em Templates (Modelos), escolha o modelo que corresponde ao seu caso de uso.
-
Para inserir sua senha mestre, faça o seguinte:
Na seção Configurações, abra Configurações de credencial.
Desmarque a caixa de seleção Auto generate a password (Gerar uma senha automaticamente).
(Opcional) Altere o valor Master username (Nome do usuário principal) e insira a mesma senha em Master password (Senha mestre) e Confirm password (Confirmar senha).
Por padrão, a nova instância de banco de dados usa uma senha gerada automaticamente para o usuário mestre.
-
Na seção Conectividade em Grupo de segurança da VPC (firewall), se você selecionar Criar, um grupo de segurança da VPC será criado com uma regra de entrada que permite que o endereço IP do computador local acesse o banco de dados.
-
Para Configuração de armazenamento do cluster, escolha Aurora I/O-Optimized ou Aurora Standard. Para obter mais informações, consulte Configurações de armazenamento para clusters de banco de dados do Amazon Aurora.
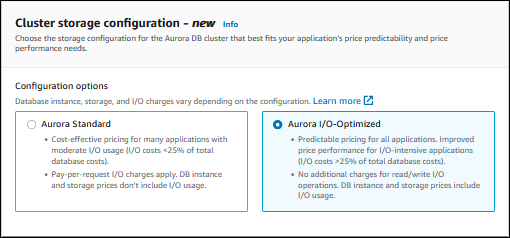
-
(Opcional) Configure uma conexão com um recurso de computação para esse cluster de banco de dados.
Você pode configurar a conectividade entre uma instância do Amazon EC2 e o novo cluster de banco de dados durante a criação do cluster de banco de dados. Para obter mais informações, consulte Configurar a conectividade automática de rede com uma instância do EC2.
-
Nas seções restantes, especifique suas configurações de cluster de banco de dados. Para obter informações sobre cada configuração, consulte Configurações de clusters de bancos de dados do Aurora.
-
Escolha Create database (Criar banco de dados).
Se você optar por usar uma senha gerada automaticamente, o botão View credential details (Visualizar detalhes da credencial) será exibido na página Databases (Bancos de dados).
Para visualizar o nome do usuário principal e a senha do cluster de banco de dados, escolha View credential details (Ver detalhes da credencial).
Para se conectar à instância de banco de dados como o usuário mestre, use o nome de usuário e a senha exibidos.
Importante
Você não pode visualizar a senha do usuário principal novamente. Caso você não a registre, talvez seja necessário alterá-la. Se for necessário alterar a senha do usuário mestre depois que a instância de banco de dados estiver disponível, será possível modificar a instância de banco de dados para fazer isso. Para obter mais informações sobre a modificação de uma instância de banco de dados, consulte Modificar um cluster de bancos de dados Amazon Aurora.
-
Em Databases (Bancos de dados), escolha o nome do novo cluster de bancos de dados do Aurora.
No console do RDS, os detalhes do novo cluster de banco de dados são exibidos. O cluster de banco de dados e sua instância de banco de dados têm um status creating (criando) até que o cluster de banco de dados esteja pronto para uso.

Quando o status muda para available (disponível) para ambos, você pode se conectar ao cluster de banco de dados. Dependendo da classe da instância de banco de dados e da quantidade de armazenamento, pode levar até 20 minutos para que o novo cluster de banco de dados esteja disponível.
Para visualizar o cluster recém-criado, selecione Databases (Bancos de dados) no painel de navegação no console do Amazon RDS. Depois, escolha o cluster de banco de dados para mostrar os detalhes dele. Para obter mais informações, consulte Visualizar um cluster de bancos de dados Amazon Aurora.
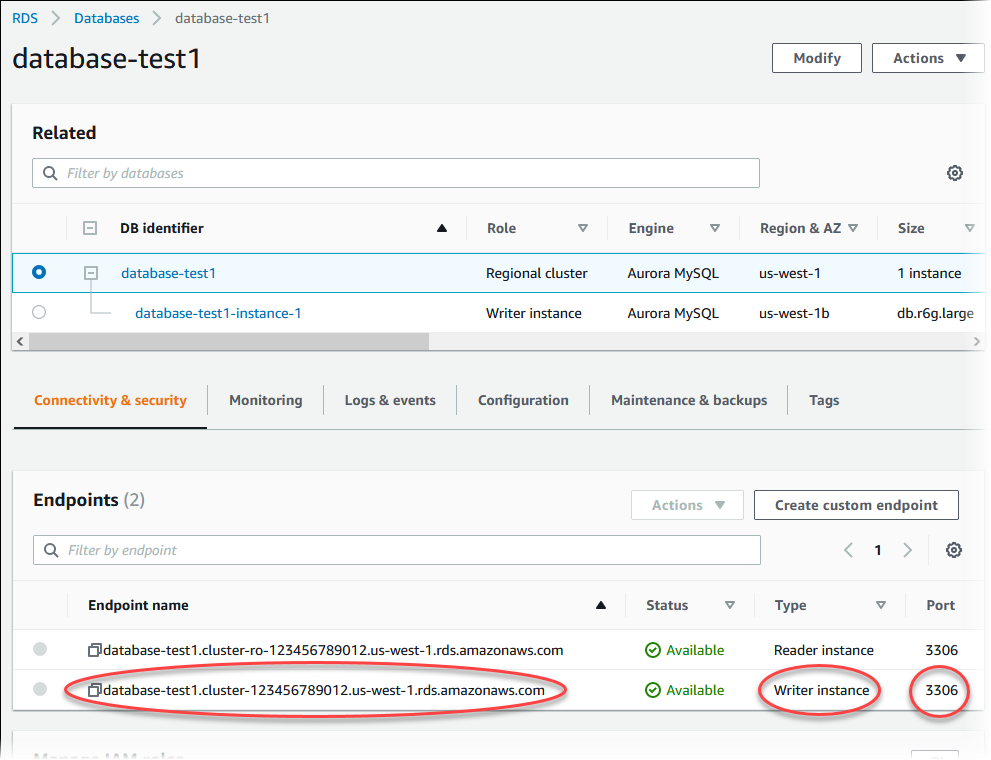
Na guia Connectivity & security (Conectividade e segurança), observe a porta e o endpoint da instância de banco de dados do gravador. Use o endpoint e a porta do cluster nas suas strings de conexão JDBC e ODBC para qualquer aplicação que realize operações de gravação ou leitura.
nota
Antes de criar um cluster de bancos de dados do Aurora usando a AWS CLI, é necessário cumprir os pré-requisitos necessários, como criar uma VPC e um grupo de sub-redes de banco de dados do RDS. Para obter mais informações, consulte Pré-requisitos do cluster de banco de dados.
Você também pode usar a AWS CLI para criar um cluster de bancos de dados Aurora MySQL ou do Aurora PostgreSQL.
Como criar um cluster de bancos de dados do Aurora MySQL usando a AWS CLI
Ao criar um cluster ou uma instância de banco de dados compatível com o Aurora MySQL 8.0 ou 5.7, especifique aurora-mysql para a opção --engine.
Execute as etapas a seguir:
-
Identifique o grupo de sub-redes do banco de dados e o ID do grupo de segurança da VPC de seu novo cluster de banco de dados e chame o comando create-db-cluster da AWS CLI para criar o cluster de bancos de dados do Aurora MySQL.
Por exemplo, o seguinte comando cria um novo cluster de banco de dados compatível com o MySQL 8.0 chamado
sample-cluster. O cluster usa a versão padrão do mecanismo e o tipo de armazenamento Aurora I/O-Optimized.Para Linux, macOS ou Unix:
aws rds create-db-cluster --db-cluster-identifier sample-cluster \ --engine aurora-mysql --engine-version 8.0 \ --storage-type aurora-iopt1 \ --master-usernameuser-name--manage-master-user-password \ --db-subnet-group-name mysubnetgroup --vpc-security-group-ids sg-c7e5b0d2Para Windows:
aws rds create-db-cluster --db-cluster-identifier sample-cluster ^ --engine aurora-mysql --engine-version 8.0 ^ --storage-type aurora-iopt1 ^ --master-usernameuser-name--manage-master-user-password ^ --db-subnet-group-name mysubnetgroup --vpc-security-group-ids sg-c7e5b0d2O comando a seguir cria um novo cluster de banco de dados compatível com o MySQL 5.7 chamado
sample-cluster. O cluster usa a versão padrão do mecanismo e o tipo de armazenamento Aurora Standard.Para Linux, macOS ou Unix:
aws rds create-db-cluster --db-cluster-identifier sample-cluster \ --engine aurora-mysql --engine-version 5.7 \ --storage-type aurora \ --master-usernameuser-name--manage-master-user-password \ --db-subnet-group-name mysubnetgroup --vpc-security-group-ids sg-c7e5b0d2Para Windows:
aws rds create-db-cluster --db-cluster-identifier sample-cluster sample-cluster ^ --engine aurora-mysql --engine-version 5.7 ^ --storage-type aurora ^ --master-usernameuser-name--manage-master-user-password ^ --db-subnet-group-name mysubnetgroup --vpc-security-group-ids sg-c7e5b0d2 -
Se você usar o console para criar um cluster de banco de dados, o Amazon RDS criará automaticamente a instância primária (leitura) para o cluster de banco de dados. Se você usar a AWS CLI para criar um cluster de banco de dados, você deverá criar explicitamente a instância primária para o cluster de banco de dados. A instância primária é a primeira instância criada em um cluster de banco de dados. Até você criar a instância de banco de dados primária, os endpoints do cluster de banco de dados permanecerão no status
Creating.Chame o comando create-db-instance da AWS CLI para criar a instância primária do seu cluster de banco de dados. Inclua o nome de um cluster de banco de dados como o valor da opção
--db-cluster-identifier.nota
Não é possível definir a opção
--storage-typepara instâncias de banco de dados. Você pode configurá-la somente para clusters de banco de dados.Por exemplo, o comando a seguir cria uma nova instância de banco de dados compatível com o MySQL 5.7 ou o MySQL 8.0 chamada
sample-instance.Para Linux, macOS ou Unix:
aws rds create-db-instance --db-instance-identifier sample-instance \ --db-cluster-identifier sample-cluster --engine aurora-mysql --db-instance-class db.r5.largePara Windows:
aws rds create-db-instance --db-instance-identifier sample-instance ^ --db-cluster-identifier sample-cluster --engine aurora-mysql --db-instance-class db.r5.large
Para criar um cluster de bancos de dados do Aurora PostgreSQL usando a AWS CLI
-
Identifique o grupo de sub-redes do banco de dados e o ID do grupo de segurança da VPC de seu novo cluster de banco de dados e chame o comando create-db-cluster da AWS CLI para criar o cluster de bancos de dados do Aurora PostgreSQL.
Por exemplo, o seguinte comando cria um novo cluster de banco de dados chamado
sample-cluster. O cluster usa a versão padrão do mecanismo e o tipo de armazenamento Aurora I/O-Optimized.Para Linux, macOS ou Unix:
aws rds create-db-cluster --db-cluster-identifier sample-cluster \ --engine aurora-postgresql \ --storage-type aurora-iopt1 \ --master-usernameuser-name--manage-master-user-password \ --db-subnet-group-name mysubnetgroup --vpc-security-group-ids sg-c7e5b0d2Para Windows:
aws rds create-db-cluster --db-cluster-identifier sample-cluster ^ --engine aurora-postgresql ^ --storage-type aurora-iopt1 ^ --master-usernameuser-name--manage-master-user-password ^ --db-subnet-group-name mysubnetgroup --vpc-security-group-ids sg-c7e5b0d2 -
Se você usar o console para criar um cluster de banco de dados, o Amazon RDS criará automaticamente a instância primária (leitura) para o cluster de banco de dados. Se você usar a AWS CLI para criar um cluster de banco de dados, você deverá criar explicitamente a instância primária para o cluster de banco de dados. A instância primária é a primeira instância criada em um cluster de banco de dados. Até você criar a instância de banco de dados primária, os endpoints do cluster de banco de dados permanecerão no status
Creating.Chame o comando create-db-instance da AWS CLI para criar a instância primária do seu cluster de banco de dados. Inclua o nome de um cluster de banco de dados como o valor da opção
--db-cluster-identifier.Para Linux, macOS ou Unix:
aws rds create-db-instance --db-instance-identifier sample-instance \ --db-cluster-identifier sample-cluster --engine aurora-postgresql --db-instance-class db.r5.largePara Windows:
aws rds create-db-instance --db-instance-identifier sample-instance ^ --db-cluster-identifier sample-cluster --engine aurora-postgresql --db-instance-class db.r5.large
Estes exemplos especificam a opção --manage-master-user-password para gerar a senha mestra do usuário e gerenciá-la no Secrets Manager. Para obter mais informações, consulte Gerenciamento de senhas com Amazon Aurora e AWS Secrets Manager. Como alternativa, você pode usar a opção --master-password para especificar e gerenciar a senha por conta própria.
nota
Antes de criar um cluster de bancos de dados Aurora usando a AWS CLI, é necessário cumprir com os pré-requisitos necessários, como criar uma VPC e um grupo de sub-redes de banco de dados do RDS. Para obter mais informações, consulte Pré-requisitos do cluster de banco de dados.
Identifique o grupo de sub-redes do banco de dados e o ID do grupo de segurança da VPC de seu novo cluster de banco de dados. Depois, chame a operação CreateDBInstance para criar o cluster de banco de dados.
Ao criar um cluster ou uma instância de banco de dados do Aurora MySQL versão 2 ou 3, especifique aurora-mysql para o parâmetro Engine.
Ao criar um cluster de banco de dados ou instância de bancos de dados do Aurora PostgreSQL, especifique aurora-postgresql para o parâmetro Engine.
Se você usar o console para criar um cluster de banco de dados, o Amazon RDS criará automaticamente a instância primária (leitura) para o cluster de banco de dados. Se você usar a API do RDS para restaurar um cluster de banco de dados, será necessário criar explicitamente a instância primária para o cluster de banco de dados usando CreateDBInstance. A instância primária é a primeira instância criada em um cluster de banco de dados. Até você criar a instância de banco de dados primária, os endpoints do cluster de banco de dados permanecerão no status Creating.
Criar uma instância de banco de dados primária (de gravador)
Se você usar o AWS Management Console para criar um cluster de banco de dados, o Amazon RDS criará automaticamente a instância primária (de gravador) para o cluster de banco de dados. Se você usar a AWS CLI ou a API do RDS para criar um cluster de banco de dados, deverá criar explicitamente a instância primária para o cluster de banco de dados. A instância primária é a primeira instância criada em um cluster de banco de dados. Até você criar a instância de banco de dados primária, os endpoints do cluster de banco de dados permanecerão no status Creating.
Para obter mais informações, consulte Criar um cluster de banco de dados.
nota
Se você tiver um cluster de banco de dados sem uma instância de banco de dados de gravador, também chamado de cluster headless, não poderá usar o console para criar uma instância de gravador. Use a AWS CLI ou a API do RDS.
O exemplo a seguir usa o comando create-db-instance da AWS CLI para criar uma instância de gravador para um cluster de banco de dados do Aurora PostgreSQL chamado headless-test.
aws rds create-db-instance \ --db-instance-identifier no-longer-headless \ --db-cluster-identifier headless-test \ --engine aurora-postgresql \ --db-instance-class db.t4g.medium
Configurações de clusters de bancos de dados do Aurora
A tabela a seguir contém detalhes sobre as configurações que você escolhe quando cria um cluster de banco de dados do Aurora.
| Configuração do console | Descrição da configuração | Opção da CLI e parâmetro da API do RDS |
|---|---|---|
|
Atualização da versão secundária automática |
Escolha Enable auto minor version upgrade (Habilitar atualização automática de versão secundária) se você quiser permitir que o cluster de bancos de dados do Aurora receba automaticamente as atualizações de versão secundária preferida no mecanismo de banco de dados quando disponíveis. A configuração Atualização automática de versão secundária se aplica aos clusters de bancos de dados do Aurora PostgreSQL e do Aurora MySQL. Para obter mais informações sobre atualizações de mecanismos para o Aurora PostgreSQL, consulte Atualizações do mecanismo de banco de dados do Amazon Aurora PostgreSQL. Para obter mais informações sobre atualizações de mecanismos para o Aurora MySQL, consulte Atualizações do mecanismo de banco de dados Amazon Aurora MySQL. |
Defina esse valor para cada instância de banco de dados em seu cluster do Aurora. Se qualquer instância de banco de dados em seu cluster tiver essa configuração desativada, o cluster não será atualizado automaticamente. Usando a AWS CLI, execute Usando a API do RDS, chame |
|
AWS KMS key |
Disponível apenas quando Encryption (Criptografia) estiver definido como Enable encryption (Habilitar criptografia). Escolha a AWS KMS key a ser usada para criptografar esse cluster de banco de dados. Para obter mais informações, consulte Criptografar recursos do Amazon Aurora. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Retrocesso |
Aplica-se somente ao Aurora MySQL. Escolha Enable Backtrack (Habilitar retrocesso) para habilitar o retrocesso ou Disable Backtrack (Desabilitar retrocesso) para desabilitá-lo. Usando o retrocesso, você pode retroceder um cluster de banco de dados a um período específico, sem criar um novo cluster de banco de dados. O recurso é desabilitado por padrão. Se você habilitar o retrocesso, especifique também a quantidade de tempo que deseja retroceder o cluster de banco de dados (a janela do retrocesso de destino). Para obter mais informações, consulte Retroceder um cluster de banco de dados Aurora. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Autoridade certificadora |
A autoridade de certificação (CA) para o certificado do servidor usado pelas instâncias de banco de dados no cluster de banco de dados. Para obter mais informações, consulte Usar SSL/TLS para criptografar uma conexão com um cluster de banco de dados. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Configuração de armazenamento do cluster |
O tipo de armazenamento do cluster de banco de dados: Aurora I/O-Optimized ou Aurora Standard. Para obter mais informações, consulte Configurações de armazenamento para clusters de banco de dados do Amazon Aurora. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
| Copiar tags para snapshots |
Escolha esta opção para copiar qualquer tag da instância de banco de dados para um snapshot de banco de dados quando você cria um snapshot. Para obter mais informações, consulte Marcar recursos do Amazon Aurora e do Amazon RDS. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
| Autenticação de banco de dados |
A autenticação de banco de dados que você deseja usar. Para MySQL:
Para PostgreSQL:
|
Para usar a autenticação de banco de dados do IAM com a AWS CLI, execute Para usar a autenticação de banco de dados do IAM com a API do RDS, chame Para usar a autenticação Kerberos com a AWS CLI, execute Para usar a autenticação Kerberos com a API do RDS, chame |
|
Porta de banco de dados |
Especifique a porta que as aplicações e os utilitários usam para acessar o banco de dados. Os clusters de bancos de dados do Aurora MySQL assumem como padrão a porta do MySQL padrão, 3306. Os clusters de bancos de dados do Aurora PostgreSQL assumem como padrão a porta do PostgreSQL padrão, 5432. Em algumas empresas, os firewalls bloqueiam conexões com essas portas padrão. Se o firewall da sua empresa bloquear a porta padrão, escolha outra porta para o novo cluster de banco de dados. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Identificador do cluster de banco de dados |
Insira um nome para o cluster de banco de dados exclusivo da sua conta na região da AWS escolhida. Esse identificador é usado no endereço do endpoint do cluster para o seu cluster de banco de dados. Para obter informações sobre o endpoint do cluster, consulte Conexões de endpoints do Amazon Aurora. O identificador do cluster de banco de dados tem as seguintes restrições:
|
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Grupo de parâmetros do cluster de banco de dados |
Escolha um grupo de parâmetros de cluster de banco de dados. O Aurora conta com um grupo de parâmetros de cluster de banco de dados que você pode usar, ou é possível criar seu próprio grupo de parâmetros. Para obter mais informações sobre os grupos de parâmetros do cluster de banco de dados, consulte Grupos de parâmetros para Amazon Aurora. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Classe de instância de banco de dados |
Aplica-se apenas ao tipo de capacidade provisionada. Selecione uma classe de instância de banco de dados que defina os requisitos de processamento e de memória de cada instância no cluster de banco de dados. Para obter mais informações sobre classes de instância de banco de dados, consulte Classes de instâncias de banco de dados Amazon Aurora. |
Defina esse valor para cada instância de banco de dados em seu cluster do Aurora. Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Grupo de parâmetros de banco de dados |
Escolha um grupo de parâmetros. O Aurora conta com um grupo de parâmetros padrão que você pode usar, ou você pode criar seu próprio grupo de parâmetros. Para obter mais informações sobre grupos de parâmetros, consulte Grupos de parâmetros para Amazon Aurora. |
Defina esse valor para cada instância de banco de dados em seu cluster do Aurora. Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Grupo de sub-rede de banco de dados |
O grupo de sub-redes de banco de dados que você deseja usar para o cluster de banco de dados. Selecione Choose existing (Selecionar existente) para usar um grupo de sub-redes de banco de dados existente. Depois, escolha o grupo de sub-redes necessário na lista suspensa Existing DB subnet groups (Grupos de sub-redes de banco de dados existentes).Escolha Automatic setup (Configuração automática) para permitir que o RDS selecione um grupo de sub-redes de banco de dados compatível. Se não existir nenhum, o RDS criará um grupo de sub-redes para o cluster. Para obter mais informações, consulte Pré-requisitos do cluster de banco de dados. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
| Habilitar proteção contra exclusão | Escolha Enable deletion protection (Habilitar proteção contra exclusão) para impedir que seu cluster de banco de dados seja excluído. Por padrão, se você criar um cluster de banco de dados de produção com o console, a proteção contra exclusão será habilitada. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Habilitar criptografia |
Selecione |
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Habilitar monitoramento avançado |
Selecione Enable enhanced monitoring (Habilitar monitoramento aprimorado) para habilitar a coleta de métricas em tempo real do sistema operacional em que o cluster de banco de dados é executado. Para obter mais informações, consulte Monitorar métricas do SO com o monitoramento avançado. |
Defina esses valores para cada instância de banco de dados em seu cluster do Aurora. Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Habilitar a API de dados do RDS |
Selecione Habilitar a API de dados do RDS para habilitar a API de dados do RDS (API de dados). A API de dados fornece um endpoint HTTP seguro para executar declarações SQL sem gerenciar conexões. Para obter mais informações, consulte Usar a API de dados do Amazon RDS. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Tipo de mecanismo |
Escolha o mecanismo de banco de dados a ser usado para este cluster de banco de dados. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Versão do mecanismo |
Aplica-se apenas ao tipo de capacidade provisionada. Escolha o número da versão de seu mecanismo de banco de dados. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Prioridade de failover |
Escolha uma prioridade de failover para a instância. Se você não selecionar um valor, o padrão será tier-1. Essa prioridade determina a ordem em que as réplicas do Aurora são promovidas durante a recuperação de uma falha de instância primária. Para obter mais informações, consulte Tolerância a falhas para um cluster de banco de dados do Aurora. |
Defina esse valor para cada instância de banco de dados em seu cluster do Aurora. Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Nome do banco de dados inicial |
Insira um nome para seu banco de dados padrão. Se não fornecer um nome para um cluster de bancos de dados do Aurora MySQL, Amazon RDS não criará um banco de dados no cluster de banco de dados que estiver criando. Se você não fornecer um nome para um cluster de bancos de dados Aurora PostgreSQL, Amazon RDS criar um banco de dados chamado Para o Aurora MySQL, o nome do banco de dados padrão tem estas restrições:
Para o Aurora PostgreSQL, o nome do banco de dados padrão tem estas restrições:
Para criar bancos de dados adicionais, conecte-se ao cluster de banco de dados e use o comando CREATE DATABASE do SQL. Para obter mais informações sobre como se conectar ao cluster de banco de dados, consulte Como conectar-se a um cluster de bancos de dados Amazon Aurora. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
Exportações de log |
Na seção Log exports (Exportações de log), escolha os logs que deseja começar a publicar no Amazon CloudWatch Logs. Para obter mais informações sobre publicação de logs do Aurora MySQL no CloudWatch Logs, consulte Publicar logs do Amazon Aurora MySQL no Amazon CloudWatch Logs. Para obter mais informações sobre publicação de logs do Aurora PostgreSQL no CloudWatch Logs, consulte Publicar logs do Aurora PostgreSQL no Amazon CloudWatch Logs. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Janela de manutenção |
Escolha Select window (Selecionar janela) e especifique o período semanal durante o qual a manutenção do sistema pode ser realizada. Ou selecione No preference (Sem preferência) para que o Amazon RDS atribua um período aleatoriamente. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Gerenciar credenciais principais no AWS Secrets Manager |
Selecione Gerenciar credenciais principais no AWS Secrets Manager para gerenciar a senha do usuário principal em um segredo no Secrets Manager. Opcionalmente, selecione uma chave do KMS a ser usada para proteger o segredo. Escolha entre uma das chaves do KMS da sua conta ou insira a chave de uma conta distinta. Para obter mais informações, consulte Gerenciamento de senhas com Amazon Aurora e AWS Secrets Manager. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Senha mestre |
Insira uma senha para fazer login no cluster de banco de dados:
|
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Nome do usuário principal |
Insira um nome a ser usado como o nome do usuário mestre para fazer login no cluster de banco de dados:
Você não pode alterar o nome do usuário principal após a criação do cluster de banco de dados. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Implantação multi-AZ |
Aplica-se apenas ao tipo de capacidade provisionada. Determine se você deseja criar réplicas do Aurora em outras Zonas de disponibilidade para suporte a failover. Se você escolher Create Replica in Different Zone (Criar réplica em outra zona), o Amazon RDS criará uma réplica do Aurora para você no cluster de banco de dados, em uma zona de disponibilidade diferente da instância primária do cluster. Para obter mais informações sobre várias Zonas de disponibilidade, consulte Regiões e zonas de disponibilidade. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Tipo de rede |
Os protocolos de endereçamento IP compatíveis com o cluster de banco de dados. IPv4. para especificar que os recursos podem se comunicar com o cluster de banco de dados somente por meio do protocolo de endereçamento IPv4. Dual-stack mode (Modo de pilha dupla), para especificar que os recursos podem se comunicar com o cluster de banco de dados por IPv4, IPv6 ou ambos. Use o modo de pilha dupla se você tiver algum recurso que precise se comunicar com o cluster de banco de dados pelo protocolo de endereçamento IPv6. Para usar o modo de pilha dupla, pelo menos duas sub-redes devem abranger duas zonas de disponibilidade compatíveis com os protocolos de rede IPv4 e IPv6. Além disso, associe um bloco CIDR IPv6 às sub-redes no grupo de sub-redes de banco de dados especificado. Para obter mais informações, consulte Endereçamento IP do Amazon Aurora. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Acesso público |
Escolha Publicly accessible (Acessível ao público geral) para fornecer ao cluster de banco de dados um endereço IP público ou escolha Not publicly accessible (Não acessível ao público geral). As instâncias no seu cluster de banco de dados podem ser uma combinação de instâncias de banco de dados públicas e privadas. Para obter mais informações sobre como ocultar instâncias do acesso público, consulte Ocultar um cluster de banco de dados em uma VPC da Internet. Para se conectar a uma instância de banco de dados de fora de sua Amazon VPC, a instância de banco de dados deve ser acessível ao público geral, o acesso deve ser concedido usando as regras de entrada do grupo de segurança da instância de banco de dados e outros requisitos devem ser atendidos. Para obter mais informações, consulte Não é possível conectar-se à instância de banco de dados do Amazon RDS. Se sua instância de banco de dados não estiver acessível publicamente, também será possível usar uma conexão AWS Site-to-Site VPN ou uma conexão do AWS Direct Connect para acessá-la de uma rede privada. Para obter mais informações, consulte Privacidade do tráfego entre redes. |
Defina esse valor para cada instância de banco de dados em seu cluster do Aurora. Usando a AWS CLI, execute Usando a API do RDS, chame |
| Suporte estendido do RDS | Selecione Habilitar Suporte estendido do RDS para permitir que as versões principais do mecanismo compatíveis continuem funcionando após a data de término do suporte padrão do Aurora. Quando você cria um cluster de banco de dados, o Amazon Aurora usa como padrão o Suporte estendido do RDS. Para evitar a criação de um cluster de banco de dados após a data de fim do suporte padrão do Aurora e para evitar cobranças pelo Suporte estendido do RDS, desabilite essa configuração. Os clusters de banco de dados existentes não incorrerão em cobranças até a data de início dos preços do Suporte estendido do RDS. Para obter mais informações, consulte Suporte estendido do Amazon RDS com Amazon Aurora. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
RDS Proxy |
Selecione Create an RDS Proxy (Criar um proxy RDS) para criar um proxy para seu cluster de banco de dados. O Amazon RDS cria automaticamente um perfil do IAM e um segredo do Secrets Manager para o proxy. Para obter mais informações, consulte Amazon RDS Proxy para o Aurora. |
Não disponível ao criar um cluster de banco de dados. |
|
Período de retenção |
Escolha o tempo, de 1 a 35 dias, que o Aurora retém cópias de backup do banco de dados. As cópias de backup podem ser usadas para restaurações point-in-time (PITR) do banco de dados, contabilizando até os segundos. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Ativar DevOps Guru |
Escolha Turn on DevOps Guru (Ativar DevOps Guru) para ativar o Amazon DevOps Guru para seu banco de dados do Aurora. Para que o DevOps Guru para RDS forneça uma análise detalhada de anomalias de performance, o Performance Insights deve estar ativado. Para obter mais informações, consulte Configurar o DevOps Guru para RDS. |
Você pode ativar o DevOps Guru para RDS no console do RDS, mas não use a API nem a CLI do RDS. Para obter mais informações sobre como executar o DevOps Guru, consulte o Guia do usuário do Amazon DevOps Guru. |
|
Ativar o Performance Insights |
Escolha Turn on Performance Insights (Ativar Performance Insights) para ativar o Amazon RDS Performance Insights. Para obter mais informações, consulte Monitorar a carga de banco de dados com o Performance Insights no Amazon Aurora. |
Defina esses valores para cada instância de banco de dados em seu cluster do Aurora. Usando a AWS CLI, execute Usando a API do RDS, chame |
|
Virtual Private Cloud (VPC) |
Escolha a VPC que hospeda o cluster de banco de dados. Selecione Create a New VPC (Criar uma nova VPC) para fazer o Amazon RDS criar uma VPC para você. Para obter mais informações, consulte Pré-requisitos do cluster de banco de dados. |
Para a AWS CLI e a API, especifique os IDs do grupo de segurança da VPC. |
|
Grupo de segurança da VPC (firewall) |
Escolha Create new (Criar novo) para fazer o Amazon RDS criar um grupo de segurança da VPC para você. Ou selecione Choose existing (Escolher existente) e especifique um ou mais grupos de segurança de VPC para proteger o acesso de rede ao cluster de banco de dados. Quando você escolhe Create new (Criar novo) no console do RDS, um novo grupo de segurança é criado com uma regra de entrada que permite acesso à instância de banco de dados pelo endereço IP detectado no navegador. Para obter mais informações, consulte Pré-requisitos do cluster de banco de dados. |
Usando a AWS CLI, execute Usando a API do RDS, chame |
Configurações não aplicáveis ao Amazon Aurora para clusters de banco de dados
As configurações a seguir no comando create-db-cluster da AWS CLI e na operação da API do RDS CreateDBCluster não são aplicáveis aos clusters de banco de dados do Amazon Aurora.
nota
O AWS Management Console não mostra essas configurações para clusters de banco de dados do Aurora.
| Configuração da AWS CLI | Configuração da API do RDS |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Configurações não aplicáveis a instâncias de banco de dados do Amazon Aurora
As configurações a seguir no comando create-db-instance da AWS CLI e na operação da API do RDS CreateDBInstance não se aplicam ao cluster de banco de dados do Amazon Aurora de instâncias de banco de dados.
nota
O AWS Management Console não mostra essas configurações para instâncias de banco de dados Aurora.
| Configuração da AWS CLI | Configuração da API do RDS |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
