As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Configurando AWS DataSync transferências com o Amazon S3
Para transferir dados para ou do seu bucket do Amazon S3, você cria um local de AWS DataSync transferência. DataSync pode usar esse local como origem ou destino para transferir dados.
Fornecendo DataSync acesso aos buckets do S3
DataSync precisa acessar o bucket do S3 para o qual você está transferindo ou do qual você está transferindo. Para fazer isso, você deve criar uma função AWS Identity and Access Management (IAM) que DataSync assuma as permissões necessárias para acessar o bucket. Em seguida, você especifica essa função ao criar sua localização no Amazon S3 para. DataSync
Sumário
Permissões obrigatórias
As permissões que sua função do IAM precisa podem depender se o bucket é um local de DataSync origem ou destino. O Amazon S3 no Outposts requer um conjunto diferente de permissões.
Criação de uma função do IAM DataSync para acessar sua localização no Amazon S3
Ao criar sua localização do Amazon S3 no console, DataSync você pode criar e assumir automaticamente uma função do IAM que normalmente tem as permissões certas para acessar seu bucket do S3.
Em algumas situações, talvez seja necessário criar essa função manualmente (por exemplo, acessar buckets com camadas extras de segurança ou transferir para ou de um bucket em outro Contas da AWS).
Abra o console do IAM em https://console.aws.amazon.com/iam/
. -
No painel de navegação esquerdo, em Gerenciamento de acesso, escolha Perfis e, em seguida, escolha Criar perfil.
-
Na página Selecionar entidade confiável, para Tipo de entidade confiável, escolha AWS service (Serviço da AWS).
-
Em Caso de uso, escolha DataSyncna lista suspensa e selecione. DataSync Escolha Próximo.
-
Na página Adicionar permissões, escolha Próximo. Forneça um nome ao perfil e escolha Criar perfil.
-
Na página Perfis, procure o perfil que você acabou de criar e escolha seu nome.
-
Na página do perfil, escolha a guia Permissões. Selecione Adicionar permissões e, em seguida, Criar política em linha.
-
Escolha a guia JSON e adicione as permissões necessárias para acessar o bucket no editor de políticas.
-
Escolha Próximo. Digite um nome para a política e escolha Criar política.
-
(Recomendado) Para evitar o problema “confused deputy” entre serviços, faça o seguinte:
-
Na página Detalhes do perfil, escolha a guia Relações de confiança. Escolha Editar política de confiança.
-
Atualize a política de confiança usando o exemplo a seguir, que inclui as chaves de contexto de condição global
aws:SourceArneaws:SourceAccount: -
Escolha Atualizar política.
-
Você pode especificar esse perfil ao criar seu local no Amazon S3.
Acessar buckets do S3 usando criptografia no lado do servidor
DataSync pode transferir dados de ou para buckets do S3 que usam criptografia do lado do servidor. O tipo de chave de criptografia que um bucket usa pode determinar se você precisa de uma política personalizada que DataSync permita acessar o bucket.
Ao usar DataSync com buckets S3 que usam criptografia do lado do servidor, lembre-se do seguinte:
-
Se seu bucket do S3 estiver criptografado com uma chave AWS gerenciada, DataSync poderá acessar os objetos do bucket por padrão se todos os seus recursos estiverem no mesmo Conta da AWS.
-
Se seu bucket do S3 estiver criptografado com uma chave gerenciada pelo cliente AWS Key Management Service (AWS KMS) (SSE-KMS), a política da chave deve incluir a função do IAM DataSync usada para acessar o bucket.
-
Se seu bucket do S3 estiver criptografado com uma chave SSE-KMS gerenciada pelo cliente e em uma chave diferente Conta da AWS, DataSync precisará de permissão para acessar o bucket no outro. Conta da AWS Para isso, você pode configurar fazendo o seguinte:
-
Na função do IAM DataSync usada, você deve especificar a chave SSE-KMS do bucket entre contas usando o Amazon Resource Name (ARN) totalmente qualificado da chave. Esse é o mesmo ARN da chave que você usa para configurar a criptografia padrão do bucket. Você não pode especificar um ID de chave, um nome alias ou um ARN alias nessa situação.
Aqui está um exemplo de ARN de chave:
arn:aws:kms:us-west-2:111122223333:key/1234abcd-12ab-34cd-56ef-1234567890abPara obter mais informações sobre a especificação de chaves do KMS em instruções de política do IAM, consulte o Guia do desenvolvedor do AWS Key Management Service.
-
Na política de chaves SSE-KMS, especifique a função do IAM usada por. DataSync
-
-
Se seu bucket do S3 for criptografado com uma AWS KMS chave gerenciada pelo cliente (DSSE-KMS) para criptografia de camada dupla no lado do servidor, a política da chave deve incluir a função do IAM usada para acessar o bucket. DataSync (Lembre-se de que o DSSE-KMS não é compatível com chaves de bucket do S3, o que pode reduzir AWS KMS os custos da solicitação.)
-
Se seu bucket do S3 estiver criptografado com uma chave de criptografia fornecida pelo cliente (SSE-C), não é DataSync possível acessar esse bucket.
O exemplo a seguir é uma política de chave para uma chave SSE-KMS gerenciada pelo cliente. A política está associada a um bucket do S3 que usa criptografia no lado do servidor.
Se você desejar usar esse exemplo, substitua os valores a seguir pelos seus:
-
account-id— Seu Conta da AWS. -
admin-role-name— O nome da função do IAM que pode administrar a chave. -
datasync-role-name— O nome da função do IAM que permite DataSync usar a chave ao acessar o bucket.
Acesso aos buckets restritos do S3
Se você precisar transferir para ou de um bucket do S3 que normalmente nega todo o acesso, você pode editar a política do bucket para que DataSync possa acessar o bucket somente para sua transferência.
-
Copie a política de bucket do S3 a seguir.
-
Na política, substitua os seguintes valores:
-
amzn-s3-demo-bucket -
datasync-iam-role-idExecute o AWS CLI comando a seguir para obter o ID da função do IAM:
aws iam get-role --role-namedatasync-iam-role-nameNa saída, procure o valor
RoleId:"RoleId": "ANPAJ2UCCR6DPCEXAMPLE" -
your-iam-role-idExecute o comando a seguir para criar a ID do perfil do IAM:
aws iam get-role --role-nameyour-iam-role-nameNa saída, procure o valor
RoleId:"RoleId": "AIDACKCEVSQ6C2EXAMPLE"
-
-
Adicione essa política à política do bucket do S3.
-
Quando você terminar de usar DataSync o bucket restrito, remova as condições para ambas as funções do IAM da política do bucket.
Acesso aos buckets do S3 com acesso restrito à VPC
Um bucket do Amazon S3 que limita o acesso a endpoints específicos de nuvem privada virtual (VPC) ou VPCs negará a transferência DataSync de ou para esse bucket. Para permitir transferências nessas situações, você pode atualizar a política do bucket para incluir a função do IAM que você especifica com sua DataSync localização.
Considerações sobre a classes de armazenamento com transferências do Amazon S3
Quando o Amazon S3 é seu local de destino, DataSync você pode transferir seus dados diretamente para uma classe de armazenamento específica do Amazon S3
Algumas classes de armazenamento têm comportamentos que podem afetar os custos de armazenamento do Amazon S3. Ao usar classes de armazenamento que podem gerar custos adicionais por substituição, exclusão ou recuperação de objetos, as alterações em dados ou metadados de objetos resultam nesses custos. Para obter mais informações, consulte Preço do Amazon S3
Importante
Novos objetos transferidos para o local de destino no Amazon S3 são armazenados usando a classe de armazenamento que você especifica ao criar o local.
Por padrão, DataSync preserva a classe de armazenamento dos objetos existentes em seu local de destino, a menos que você configure sua tarefa para transferir todos os dados. Nessas situações, a classe de armazenamento que você especifica ao criar sua localização é usada para todos os objetos.
| Classe de armazenamento do Amazon S3 | Considerações |
|---|---|
| S3 Standard | Selecione S3 Standard (Padrão) para armazenar seus arquivos acessados com frequência de forma redundante em várias zonas de disponibilidade separadas geograficamente. Esse será o padrão se você não especificar uma classe de armazenamento. |
| S3 Intelligent-Tiering |
Escolha S3 Intelligent-Tiering para otimizar os custos de armazenamento movendo automaticamente os dados para o nível de acesso de armazenamento mais econômico. Você paga uma taxa mensal por objeto armazenado na classe de armazenamento S3 Intelligent-Tiering. Essa cobrança do Amazon S3 inclui o monitoramento de padrões de acesso a dados e a movimentação de objetos entre níveis. |
| S3 Standard – IA |
Selecione S3 Standard-IA para armazenar seus objetos raramente acessados de forma redundante em várias zonas de disponibilidade separadas geograficamente. Os objetos armazenados na classe de armazenamento S3 Standard-IA podem incorrer em cobranças adicionais pela substituição, exclusão ou recuperação. Considere a frequência com que esses objetos mudam, por quanto tempo você planeja manter esses objetos e com que frequência você precisa acessá-los. Alterações nos dados ou metadados do objeto equivalem a excluir um objeto e criar um novo para substituí-lo. Isso resulta em cobranças adicionais para objetos armazenados na classe de armazenamento S3 Standard-IA. Objetos com menos de 128 KB são menores que a cobrança de capacidade mínima por objeto na classe de armazenamento S3 Standard-IA. Esses objetos são armazenados na classe de armazenamento S3 Standard. |
| S3 One Zone-IA |
Selecione S3 One Zone-IA para armazenar seus objetos raramente acessados em uma única zona de disponibilidade. Os objetos armazenados na classe de armazenamento S3 One Zone-IA podem incorrer em cobranças adicionais pela substituição, exclusão ou recuperação. Considere a frequência com que esses objetos mudam, por quanto tempo você planeja manter esses objetos e com que frequência você precisa acessá-los. Alterações nos dados ou metadados do objeto equivalem a excluir um objeto e criar um novo para substituí-lo. Isso resulta em cobranças adicionais para objetos armazenados na classe de armazenamento S3 One Zone-IA. Objetos com menos de 128 KB são menores que a cobrança de capacidade mínima por objeto na classe de armazenamento S3 One Zone-IA. Esses objetos são armazenados na classe de armazenamento S3 Standard. |
| S3 Glacier Instant Retrieval |
Escolha o S3 Glacier Instant Retrieval para arquivar objetos que raramente são acessados, mas que precisam ser recuperados em milissegundos. Os dados armazenados na classe de armazenamento S3 Glacier Instant Retrieval oferecem economia de custos em comparação à classe de armazenamento S3 Standard – IA, com a mesma latência e performance do throughput. Contudo, os custos de acesso a dados do S3 Glacier Instant Retrieval são mais altos que os do S3 Standard-IA. Os objetos armazenados no S3 Glacier Instant Retrieval podem incorrer em cobranças adicionais pela substituição, exclusão ou recuperação. Considere a frequência com que esses objetos mudam, por quanto tempo você planeja manter esses objetos e com que frequência você precisa acessá-los. Alterações nos dados ou metadados do objeto equivalem a excluir um objeto e criar um novo para substituí-lo. Isso resulta em cobranças adicionais para objetos armazenados na classe de armazenamento S3 Glacier Instant Retrieval. Objetos com menos de 128 KB são menores que a cobrança mínima de capacidade por objeto na classe de armazenamento S3 Glacier Instant Retrieval. Esses objetos são armazenados na classe de armazenamento S3 Standard. |
| S3 Glacier Flexible Retrieval | Escolha S3 Glacier Flexible Retrieval para arquivos mais ativos. Os objetos armazenados na classe S3 Glacier Flexible Retrieval podem incorrer em cobranças adicionais pela substituição, exclusão ou recuperação. Considere a frequência com que esses objetos mudam, por quanto tempo você planeja manter esses objetos e com que frequência você precisa acessá-los. Alterações nos dados ou metadados do objeto equivalem a excluir um objeto e criar um novo para substituí-lo. Isso resulta em cobranças adicionais para objetos armazenados na classe de armazenamento S3 Glacier Flexible Retrieval. A classe de armazenamento S3 Glacier Flexible Retrieval exige 40 KB de metadados adicionais para cada objeto arquivado. DataSync coloca objetos com menos de 40 KB na classe de armazenamento S3 Standard. Você deve restaurar objetos arquivados nessa classe de armazenamento antes de DataSync poder lê-los. Para obter mais informações, consulte Trabalhar com objetos arquivados no Guia do usuário do Amazon S3.Ao usar o S3 Glacier Flexible Retrieval, escolha a opção de tarefa Verificar somente os dados transferidos para comparar somas de verificação de dados e metadados no final da transferência. Você não pode usar aopção Verificar todos os dados no destino para essa classe de armazenamento, pois requer a recuperação de todos os objetos existentes do destino. |
| S3 Glacier Deep Archive |
Escolha S3 Glacier Deep Archive para arquivar seus objetos para retenção de dados de longo prazo e preservação digital, no caso em que os dados são acessados uma ou duas vezes por ano. Os objetos armazenados no S3 Glacier Deep Archive podem incorrer em cobranças adicionais pela substituição, exclusão ou recuperação. Considere a frequência com que esses objetos mudam, por quanto tempo você planeja manter esses objetos e com que frequência você precisa acessá-los. Alterações nos dados ou metadados do objeto equivalem a excluir um objeto e criar um novo para substituí-lo. Isso resulta em cobranças adicionais para objetos armazenados na classe de armazenamento S3 Glacier Deep Archive. A classe de armazenamento S3 Glacier Deep Archive exige 40 KB de metadados adicionais para cada objeto arquivado. DataSync coloca objetos com menos de 40 KB na classe de armazenamento S3 Standard. Você deve restaurar objetos arquivados nessa classe de armazenamento antes de DataSync poder lê-los. Para obter mais informações, consulte Trabalhar com objetos arquivados no Guia do usuário do Amazon S3. Ao usar o S3 Glacier Deep Archive, escolha a opção de tarefa Verificar somente os dados transferidos para comparar somas de verificação de dados e metadados no final da transferência. Você não pode usar aopção Verificar todos os dados no destino para essa classe de armazenamento, pois requer a recuperação de todos os objetos existentes do destino. |
|
S3 Outposts |
Classe de armazenamento para o Amazon S3 no Outposts. |
Avaliando os custos de solicitação do S3 ao usar DataSync
Com os locais do Amazon S3, você incorre em custos relacionados às solicitações de API do S3 feitas por. DataSync Esta seção pode ajudá-lo a entender como DataSync usa essas solicitações e como elas podem afetar seus custos do Amazon S3
Solicitações do S3 feitas por DataSync
A tabela a seguir descreve as solicitações do S3 que você DataSync pode fazer quando você está copiando dados de ou para um local do Amazon S3.
| Solicitação do S3 | Como DataSync o usa |
|---|---|
|
DataSync faz pelo menos uma |
|
DataSync faz |
|
|
DataSync faz |
|
|
Se você configurar sua tarefa para copiar tags de objeto, DataSync faça essas |
|
|
DataSync faz |
|
Se seus objetos de origem tiverem tags e você configurar sua tarefa para copiar tags de objetos, DataSync faça essas |
|
|
DataSync faz uma |
Considerações sobre custos
DataSync faz solicitações do S3 nos buckets do S3 toda vez que você executa sua tarefa. Isso pode fazer com que as cobranças aumentem em determinadas situações. Por exemplo:
-
Você está frequentemente transferindo objetos para ou de um bucket do S3.
-
Talvez você não esteja transferindo muitos dados, mas o bucket do S3 contém muitos objetos. Você ainda pode ver altas cobranças nesse cenário porque DataSync faz solicitações do S3 em cada um dos objetos do bucket.
-
Você está transferindo entre buckets do S3, assim DataSync como fazendo solicitações do S3 na origem e no destino.
Para ajudar a minimizar os custos de solicitação do S3 relacionados a DataSync, considere o seguinte:
Tópicos
Quais classes de armazenamento do S3 eu estou usando?
As taxas de solicitação do S3 podem variar de acordo com a classe de armazenamento do Amazon S3 que os objetos estão usando, principalmente para classes que arquivam objetos (como S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval e S3 Glacier Deep Archive).
Aqui estão alguns cenários nos quais as classes de armazenamento podem afetar suas cobranças de solicitação do S3 durante o uso DataSync:
-
Sempre que você executa uma tarefa, DataSync faz
HEADsolicitações para recuperar metadados do objeto. Essas solicitações resultam em cobranças mesmo se você não estiver movendo nenhum objeto. O quanto essas solicitações afetam sua fatura depende da classe de armazenamento que seus objetos estão usando, juntamente com o número de objetos DataSync digitalizados. -
Se você moveu objetos para a classe de armazenamento S3 Glacier Instant Retrieval (diretamente ou por meio de uma configuração de ciclo de vida do bucket), as solicitações de objetos dessa classe são mais caras do que de outras classes de armazenamento.
-
Se você configurar sua DataSync tarefa para verificar se os locais de origem e destino estão totalmente sincronizados, haverá
GETsolicitações para cada objeto em todas as classes de armazenamento (exceto S3 Glacier Flexible Retrieval e S3 Glacier Deep Archive). -
Além das solicitações de
GET, você incorre em custos de recuperação de dados para objetos nas classes de armazenamento S3 Standard-IA, S3 One Zone-IA ou S3 Glacier Instant Retrieval.
Para obter mais informações, consulte Definição de preço do Amazon S3
Com que frequência preciso transferir meus dados?
Se você precisar mover dados de forma recorrente, pense em um cronograma que não execute mais tarefas do que o necessário.
Você também pode considerar limitar o escopo de suas transferências. Por exemplo, você pode configurar DataSync para focar em objetos em determinados prefixos ou filtrar quais dados são transferidos. Essas opções podem ajudar a reduzir o número de solicitações do S3 feitas sempre que você executa sua DataSync tarefa.
Outras considerações sobre transferências do Amazon S3
-
Se você estiver transferindo de um bucket S3, use a Lente de Armazenamento do S3 para descobrir quantos objetos você está movendo.
-
DataSync talvez não transfira um objeto com caracteres não padrão em seu nome. Para obter mais informações, consulte Diretrizes de nomeação de chave de objeto no Guia do usuário do Amazon S3.
-
Ao usar DataSync com um bucket do S3 que usa controle de versão, lembre-se do seguinte:
-
Ao transferir para um bucket do S3, DataSync cria uma nova versão de um objeto se esse objeto for modificado na origem. Isso resulta em custos adicionais.
-
Um objeto tem uma versão diferente IDs nos buckets de origem e destino.
-
-
Depois de transferir inicialmente os dados de um bucket do S3 para um sistema de arquivos (por exemplo, NFS ou Amazon FSx), as execuções subsequentes da mesma DataSync tarefa não incluirão objetos que foram modificados, mas têm o mesmo tamanho da primeira transferência.
Criando seu local de transferência para um bucket de uso geral do Amazon S3
Para criar um local para sua transferência, você precisa de um bucket S3 de uso geral existente. Se você não tiver um, consulte o Guia do usuário do Amazon S3.
Importante
Antes de criar seu local, leia as seguintes seções:
Abra o AWS DataSync console em https://console.aws.amazon.com/datasync/
. -
No painel de navegação esquerdo, expanda Transferência de dados e escolha Locais e Criar local.
-
Em Tipo de localização, escolha Amazon S3 e, em seguida, escolha Balde de uso geral.
-
Para URI do S3, insira ou escolha o bucket e o prefixo que você deseja usar para sua localização.
Atenção
DataSync não é possível transferir objetos com um prefixo que comece com uma barra (
/) ou inclua///./, ou/../padrões. Por exemplo:-
/photos -
photos//2006/January -
photos/./2006/February -
photos/../2006/March
-
-
Para a classe de armazenamento S3 quando usada como destino, escolha uma classe de armazenamento que você deseja que seus objetos usem quando o Amazon S3 for um destino de transferência.
Para obter mais informações, consulte Considerações sobre a classes de armazenamento com transferências do Amazon S3.
-
Em Perfil do IAM, siga um destes procedimentos:
-
Escolha Autogenerate DataSync para criar automaticamente uma função do IAM com as permissões necessárias para acessar o bucket do S3.
Se uma função do IAM foi criada DataSync anteriormente para esse bucket do S3, essa função é escolhida por padrão.
-
Escolha um perfil do IAM personalizado que você criou. Para obter mais informações, consulte Criação de uma função do IAM DataSync para acessar sua localização no Amazon S3.
-
-
(Opcional) Escolha Adicionar nova tag para marcar sua localização no Amazon S3.
Tags ajudam a gerenciar, filtrar e procurar recursos. Recomendamos criar uma etiqueta de nome para a sua localização.
-
Escolha Criar local.
-
Copie o seguinte comando
create-location-s3:aws datasync create-location-s3 \ --s3-bucket-arn 'arn:aws:s3:::amzn-s3-demo-bucket' \ --s3-storage-class 'your-S3-storage-class' \ --s3-config 'BucketAccessRoleArn=arn:aws:iam::account-id:role/role-allowing-datasync-operations' \ --subdirectory /your-prefix-name -
Em
--s3-bucket-arn, especifique o ARN do bucket do S3 que você deseja usar como um local. -
Em
--s3-storage-class, especifique uma classe de armazenamento que você deseja que os objetos usem quando o Amazon S3 for um destino de transferência. -
Para
--s3-config, especifique o ARN da função do IAM que DataSync precisa acessar seu bucket.Para obter mais informações, consulte Criação de uma função do IAM DataSync para acessar sua localização no Amazon S3.
-
Para
--subdirectory, especifique um prefixo no bucket do S3 que DataSync leia ou grave (dependendo se o bucket é um local de origem ou destino).Atenção
DataSync não é possível transferir objetos com um prefixo que comece com uma barra (
/) ou inclua///./, ou/../padrões. Por exemplo:-
/photos -
photos//2006/January -
photos/./2006/February -
photos/../2006/March
-
-
Execute o comando
create-location-s3.Se o comando for bem-sucedido, você receberá uma resposta que mostra o ARN do local que você criou. Por exemplo:
{ "LocationArn": "arn:aws:datasync:us-east-1:111222333444:location/loc-0b3017fc4ba4a2d8d" }
Você pode usar esse local como origem ou destino para sua DataSync tarefa.
Criando seu local de transferência para um bucket do S3 on Outposts
Para criar um local para sua transferência, você precisa de um bucket existente do Amazon S3 on Outposts. Se você não tiver um, consulte o Guia do usuário do Amazon S3 on Outposts.
Você também precisa de um DataSync agente. Para obter mais informações, consulte Implantando seu agente em AWS Outposts.
Ao transferir de um prefixo de bucket do S3 on Outposts que contém um grande conjunto de dados (como centenas de milhares ou milhões de objetos), sua tarefa pode atingir o tempo limite. DataSync Para evitar isso, considere usar um DataSync manifesto, que permite especificar os objetos exatos que você precisa transferir.
Abra o AWS DataSync console em https://console.aws.amazon.com/datasync/
. -
No painel de navegação esquerdo, expanda Transferência de dados e escolha Locais e Criar local.
-
Para Tipo de localização, escolha Amazon S3 e, em seguida, escolha Outposts bucket.
-
Para o bucket do S3, escolha um ponto de acesso do Amazon S3 que possa acessar seu bucket do S3 on Outposts.
Para obter mais informações, consulte o Guia do usuário do Amazon S3.
-
Para a classe de armazenamento S3 quando usada como destino, escolha uma classe de armazenamento que você deseja que seus objetos usem quando o Amazon S3 for um destino de transferência.
Para obter mais informações, consulteConsiderações sobre a classes de armazenamento com transferências do Amazon S3. DataSync por padrão, usa a classe de armazenamento S3 Outposts para Amazon S3 on Outposts.
-
Para agentes, especifique o Amazon Resource Name (ARN) do DataSync agente em seu Outpost.
-
Em Pasta, insira um prefixo no bucket do S3 que DataSync lê ou grava (dependendo se o bucket é um local de origem ou destino).
Atenção
DataSync não é possível transferir objetos com um prefixo que comece com uma barra (
/) ou inclua///./, ou/../padrões. Por exemplo:-
/photos -
photos//2006/January -
photos/./2006/February -
photos/../2006/March
-
-
Em Perfil do IAM, siga um destes procedimentos:
-
Escolha Autogenerate DataSync para criar automaticamente uma função do IAM com as permissões necessárias para acessar o bucket do S3.
Se uma função do IAM foi criada DataSync anteriormente para esse bucket do S3, essa função é escolhida por padrão.
-
Escolha um perfil do IAM personalizado que você criou. Para obter mais informações, consulte Criação de uma função do IAM DataSync para acessar sua localização no Amazon S3.
-
-
(Opcional) Escolha Adicionar nova tag para marcar sua localização no Amazon S3.
Tags ajudam a gerenciar, filtrar e procurar recursos. Recomendamos criar uma etiqueta de nome para a sua localização.
-
Escolha Criar local.
-
Copie o seguinte comando
create-location-s3:aws datasync create-location-s3 \ --s3-bucket-arn 'bucket-access-point' \ --s3-storage-class 'your-S3-storage-class' \ --s3-config 'BucketAccessRoleArn=arn:aws:iam::account-id:role/role-allowing-datasync-operations' \ --subdirectory /your-folder\ --agent-arns 'arn:aws:datasync:your-region:account-id::agent/agent-agent-id' -
Para
--s3-bucket-arn, especifique o ARN de um ponto de acesso Amazon S3 que pode acessar seu bucket do S3 no Outposts.Para obter mais informações, consulte o Guia do usuário do Amazon S3.
-
Em
--s3-storage-class, especifique uma classe de armazenamento que você deseja que os objetos usem quando o Amazon S3 for um destino de transferência.Para obter mais informações, consulteConsiderações sobre a classes de armazenamento com transferências do Amazon S3. DataSync por padrão, usa a classe de armazenamento S3 Outposts para S3 on Outposts.
-
Para
--s3-config, especifique o ARN da função do IAM que DataSync precisa acessar seu bucket.Para obter mais informações, consulte Criação de uma função do IAM DataSync para acessar sua localização no Amazon S3.
-
Para
--subdirectory, especifique um prefixo no bucket do S3 que DataSync leia ou grave (dependendo se o bucket é um local de origem ou destino).Atenção
DataSync não é possível transferir objetos com um prefixo que comece com uma barra (
/) ou inclua///./, ou/../padrões. Por exemplo:-
/photos -
photos//2006/January -
photos/./2006/February -
photos/../2006/March
-
-
Para
--agent-arns, especifique o ARN do DataSync agente em seu Posto Avançado. -
Execute o comando
create-location-s3.Se o comando for bem-sucedido, você receberá uma resposta que mostra o ARN do local que você criou. Por exemplo:
{ "LocationArn": "arn:aws:datasync:us-east-1:111222333444:location/loc-0b3017fc4ba4a2d8d" }
Você pode usar esse local como origem ou destino para sua DataSync tarefa.
Transferências do Amazon S3 entre Contas da AWS
Com DataSync, você pode mover dados de ou para buckets do S3 em diferentes. Contas da AWS Para obter mais informações, consulte os seguintes tutoriais:
Transferências do Amazon S3 entre regiões comerciais e AWS GovCloud (US) Regions
Por padrão, DataSync não é transferido entre buckets S3 em ambientes comerciais e. AWS GovCloud (US) Regions Porém, você ainda pode configurar esse tipo de transferência criando um local de armazenamento de objetos para um dos buckets do S3 da transferência. Você pode realizar esse tipo de transferência com ou sem um agente. Se você usa um agente, sua tarefa deve ser configurada para o modo Básico. Para transferir sem um agente, você deve usar o modo Avançado.
Antes de começar: certifique-se de que compreende as implicações de custos de transferir entre regiões. Para obter mais informações, consulte Preços do AWS DataSync
Sumário
Fornecendo DataSync acesso ao bucket do seu local de armazenamento de objetos
Ao criar o local de armazenamento de objetos para essa transferência, você deve fornecer DataSync as credenciais de um usuário do IAM com permissão para acessar o bucket S3 do local. Para obter mais informações, consulte Permissões obrigatórias.
Atenção
Os usuários do IAM têm credenciais de longo prazo, o que representa um risco de segurança. Para ajudar a reduzir esse risco, recomendamos que você forneça a esses usuários somente as permissões necessárias para realizar a tarefa e que você os remova quando não forem mais necessários.
Criando seu DataSync agente (opcional)
Se você quiser executar sua transferência usando o modo Básico, precisará usar um agente. Como você está se transferindo entre um comercial e um AWS GovCloud (US) Region, você implanta seu DataSync agente como uma EC2 instância da Amazon em uma das regiões. Recomendamos que o agente use um endpoint de serviço da VPC para evitar custos de transferência de dados para a Internet pública. Para obter mais informações, consulte os preços do Amazon EC2 Data Transfer
Escolha um dos cenários a seguir que descrevem como criar um agente com base na região em que você planeja executar sua DataSync tarefa.
O diagrama a seguir mostra uma transferência em que sua DataSync tarefa e seu agente estão na região comercial.
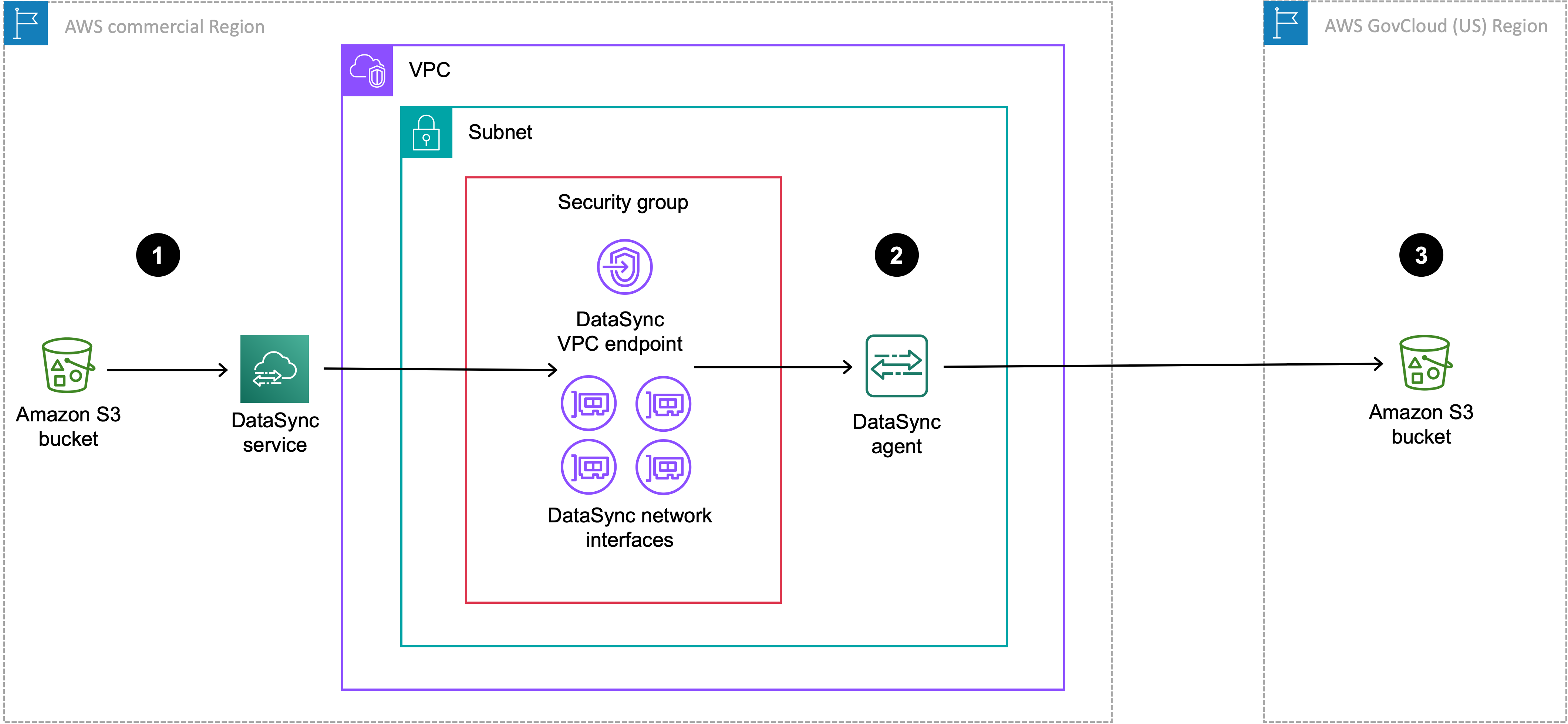
| Referência | Descrição |
|---|---|
| 1 | Na região comercial em que você está executando uma DataSync tarefa, os dados são transferidos do bucket S3 de origem. O bucket de origem é configurado como um local no Amazon S3 na região comercial. |
| 2 | Transferências de dados por meio do DataSync agente, que está na mesma VPC e sub-rede em que o endpoint do serviço VPC e as interfaces de rede estão localizados. |
| 3 | Transferências de dados para o bucket do S3 de destino na AWS GovCloud (US) Region. O bucket de destino é configurado como um local de armazenamento de objetos na região comercial. |
Você também pode usar essa mesma configuração para transferir a direção oposta da AWS GovCloud (US) Region para a região comercial.
Para criar seu DataSync agente
-
Implante um EC2 agente da Amazon em sua região comercial.
-
Configure o agente para usar um endpoint de serviço da VPC.
O diagrama a seguir mostra uma transferência em que sua DataSync tarefa e seu agente estão no AWS GovCloud (US) Region.
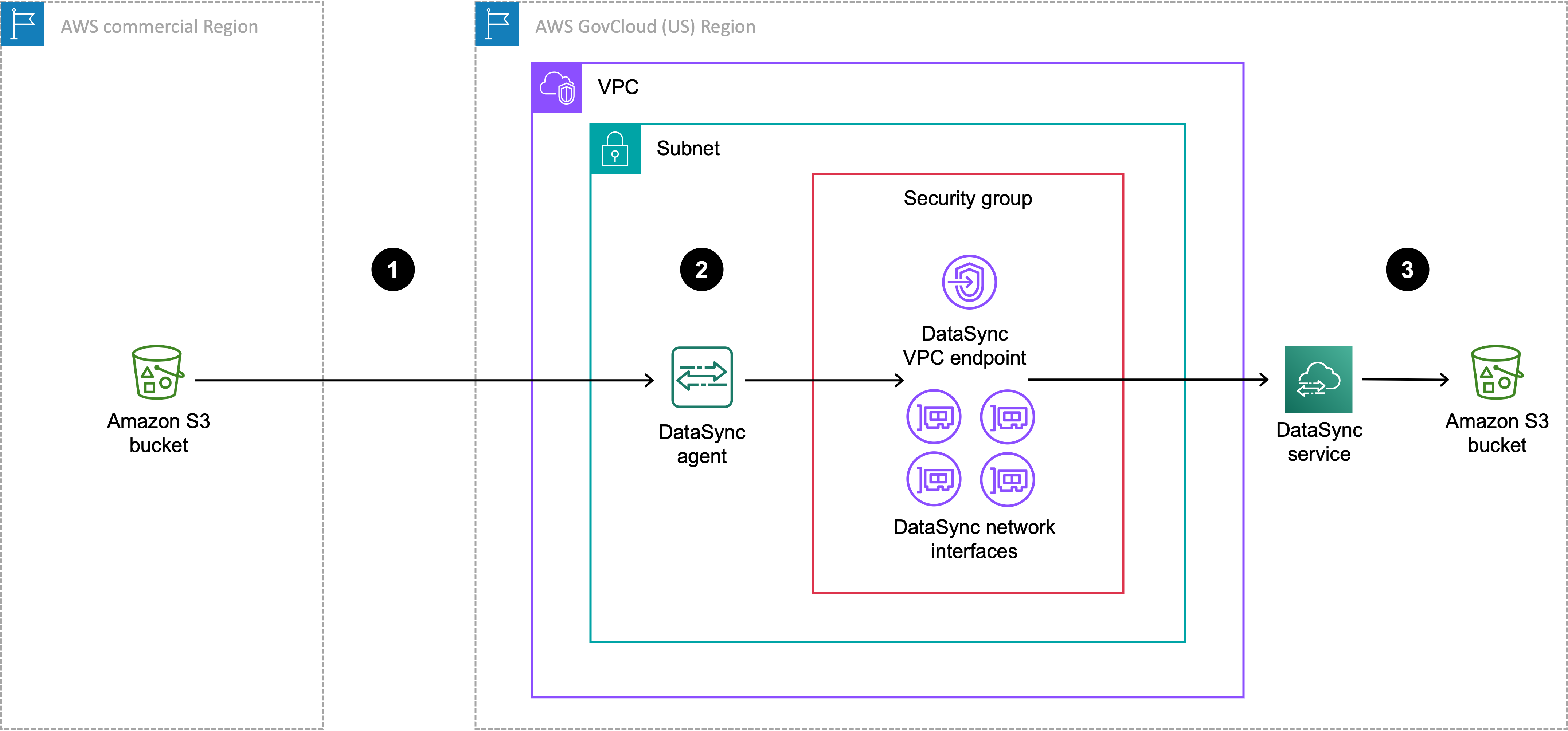
| Referência | Descrição |
|---|---|
| 1 | Transferências de dados do bucket S3 de origem na região comercial para o AWS GovCloud (US) Region local em que você está executando uma DataSync tarefa. O bucket de origem é configurado como um local de armazenamento de objetos na AWS GovCloud (US) Region. |
| 2 | No AWS GovCloud (US) Region, os dados são transferidos por meio do DataSync agente na mesma VPC e sub-rede em que o endpoint do serviço VPC e as interfaces de rede estão localizados. |
| 3 | Transferências de dados para o bucket do S3 de destino na AWS GovCloud (US) Region. O bucket de destino é configurado como um local do Amazon S3 na AWS GovCloud (US) Region. |
Você também pode usar essa mesma configuração para transferir a direção oposta da AWS GovCloud (US) Region para a região comercial.
Para criar seu DataSync agente
-
Implante um EC2 agente da Amazon em seu AWS GovCloud (US) Region.
-
Configure o agente para usar um endpoint de serviço da VPC.
Se o conjunto de dados for altamente compactável, você poderá ter uma redução de custos se criar o agente em uma região comercial enquanto executa uma tarefa em uma AWS GovCloud (US) Region. Há necessidade de mais configuração do que o normal para criar esse agente, incluindo preparar o agente para uso em uma região comercial. Para obter informações sobre como criar um agente para essa configuração, consulte o AWS DataSync blog Mover dados para dentro e para fora AWS GovCloud (US) com
Criação de um local de armazenamento de objetos para o bucket do S3
Você precisa de um local de armazenamento de objetos para o bucket do S3 que esteja na região em que você não está executando sua DataSync tarefa.
Abra o AWS DataSync console em https://console.aws.amazon.com/datasync/
. -
Verifique se você está na mesma região em que planeja executar a tarefa.
No painel de navegação esquerdo, expanda Transferência de dados e escolha Locais e Criar local.
-
Em Tipo de localização, escolha Armazenamento de objetos.
-
Para Agentes, escolha o DataSync agente que você criou para essa transferência.
-
Em Servidor, insira um endpoint do Amazon S3 para o bucket usando um dos seguintes formatos:
-
Bucket de região comercial:
s3.your-region.amazonaws.com -
Bucket de AWS GovCloud (US) Region :
s3.your-gov-region.amazonaws.com
Para obter uma lista dos endpoints do Amazon S3, consulte Referência geral da AWS.
-
-
Em nome do bucket, insira o nome do bucket do S3.
-
Em Pasta, insira um prefixo no bucket do S3 que DataSync lê ou grava (dependendo se o bucket é um local de origem ou destino).
Atenção
DataSync não é possível transferir objetos com um prefixo que comece com uma barra (
/) ou inclua///./, ou/../padrões. Por exemplo:-
/photos -
photos//2006/January -
photos/./2006/February -
photos/../2006/March
-
-
Selecione Exige credenciais e faça o seguinte:
-
Em Chave de acesso, insira a chave de acesso de um usuário do IAM que possa acessar o bucket.
-
Em Chave secreta, insira a mesma chave secreta do usuário do IAM.
-
-
(Opcional) Escolha Adicionar tag para marcar sua localização.
Tags ajudam a gerenciar, filtrar e procurar recursos. Recomendamos criar uma etiqueta de nome para a sua localização.
-
Escolha Criar local.
-
Copie o seguinte comando
create-location-object-storage:aws datasync create-location-object-storage \ --server-hostnames3-endpoint\ --bucket-nameamzn-s3-demo-bucket\ --agent-arns arn:aws:datasync:your-region:123456789012:agent/agent-01234567890deadfb -
No parâmetro
--server-hostname, especifique um endpoint do Amazon S3 para o bucket usando um dos seguintes formatos:-
Bucket de região comercial:
s3.your-region.amazonaws.com -
Bucket de AWS GovCloud (US) Region :
s3.your-gov-region.amazonaws.com
Para a região no endpoint, certifique-se de especificar a mesma região em que você planeja executar a tarefa.
Para obter uma lista dos endpoints do Amazon S3, consulte Referência geral da AWS.
-
-
No parâmetro
--bucket-name, especifique o nome do bucket do S3. -
Para o
--agent-arnsparâmetro, especifique o DataSync agente que você criou para essa transferência. -
No parâmetro
--access-key, especifique a chave de acesso para um usuário do IAM que possa acessar o bucket. -
No parâmetro
--secret-key, insira a mesma chave secreta do usuário do IAM. -
(Opcional) Para o
--subdirectoryparâmetro, especifique um prefixo no bucket do S3 que DataSync lê ou grava (dependendo se o bucket é um local de origem ou destino).Atenção
DataSync não é possível transferir objetos com um prefixo que comece com uma barra (
/) ou inclua///./, ou/../padrões. Por exemplo:-
/photos -
photos//2006/January -
photos/./2006/February -
photos/../2006/March
-
-
(Opcional) No parâmetro
--tags, especifique os pares chave-valor que representam as tags para o recurso do local.Tags ajudam a gerenciar, filtrar e procurar recursos. Recomendamos criar uma etiqueta de nome para a sua localização.
-
Execute o comando
create-location-object-storage.Você recebe uma resposta que mostra o ARN do local que você acabou de criar.
{ "LocationArn": "arn:aws:datasync:us-east-1:123456789012:location/loc-01234567890abcdef" }
Você pode usar esse local como origem ou destino para sua DataSync tarefa. Para o outro bucket do S3 nessa transferência, crie um local do Amazon S3.
Próximas etapas
Algumas das próximas etapas possíveis incluem:
-
Se necessário, crie outro local. Para obter mais informações, consulte Para onde posso transferir meus dados com AWS DataSync?.
-
Defina as configurações da DataSync tarefa, como quais arquivos transferir, como lidar com metadados, entre outras opções.
-
Defina um cronograma para sua DataSync tarefa.
-
Configure o monitoramento para sua DataSync tarefa.
-
Inicie a tarefa.
