本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 AWS DeepRacer 控制台训练和评估 AWS DeepRacer 模型
要训练强化学习模型,您可以使用 AWS DeepRacer 控制台。在控制台中,创建一个训练任务,选择支持的框架以及可用的算法,添加新的奖励函数,然后配置训练设置。您也可以继续在模拟器中观看训练。你可以在中找到 step-by-step说明训练您的第一个 AWS DeepRacer 模型 。
本节介绍如何训练和评估 AWS DeepRacer 模型。其中还演示了如何创建和改进奖励函数、操作空间如何影响模型的性能以及超级参数如何影响训练成绩。您还可以了解如何克隆模型来扩展训练会话,如何使用模拟器来评估训练成绩,以及如何解决在从模拟转向真实环境时面临的一些挑战。
主题
创建奖励函数
奖励功能描述了当您的 AWS DeepRacer 车辆从赛道上的一个位置移动到新位置时的即时反馈(作为奖励或惩罚分数)。该函数的目的是鼓励车辆沿赛道快速行驶到目的地,避免事故或违规。理想的驾驶过程会由于其操作或其目标状态赢得较高的分数。非法或绕路的驾驶过程得到的分数较低。训练 AWS DeepRacer 模型时,奖励功能是唯一针对应用程序的部分。
通常,您设计奖励函数来用作激励计划。不同的激励策略会导致不同的车辆行为。要使车辆驾驶速度更快,函数应为车辆沿赛道行驶提供奖励。该函数应对车辆完成一圈用时过长或者偏离赛道进行罚分。为了避免之字形驾驶模式,可以为在赛道的直道部分转向更少的车辆进行奖分。奖励函数可在车辆通过特定里程时给出正分数,这一里程通过 waypoints 来测量。这可以减少等待或者在错误方向上驾驶的情况。您也可以更改奖励函数以将赛道情况考虑在内。但是,在奖励函数中越多地考虑特定于环境的信息,您训练的模型过度拟合的可能性就越高,通用性就越低。要使您的模型适用性更强,您可以探索操作空间。
如果激励计划未周详考虑,它可能导致负面效应这样的意外后果
创建奖励函数的一个良好做法是先创建一个涵盖基本场景的简单函数。您可以增强函数来处理更多操作。现在我们来看一些简单的奖励函数。
简单奖励函数示例
我们可以通过首先考虑最基本的情况来构建奖励函数。也就是在直道上从起点行驶到终点且不偏离赛道的情况。在这种情况下,奖励函数逻辑仅依赖于 on_track 和 progress。作为试验,您可以从以下逻辑开始:
def reward_function(params): if not params["all_wheels_on_track"]: reward = -1 else if params["progress"] == 1 : reward = 10 return reward
此逻辑在代理行驶偏离赛道时进行罚分。在代理行驶到终点线时奖分。这对实现既定目标是合理的。但是,代理会在起点线和终点线之间自由行驶,包括在赛道上向后行驶。训练不仅可能需要很长时间才能完成,并且训练模型在部署到实际车辆中时会导致驾驶效率低下。
实际上,如果代理能够在 bit-by-bit整个培训过程中进行学习,则学习效率会更高。这意味着奖励函数应该随着车辆在赛道上的行进逐渐加大给予的奖励。为了让代理在直线赛道上驾驶车辆,我们可以按下面所示改进奖励函数:
def reward_function(params): if not params["all_wheels_on_track"]: reward = -1 else: reward = params["progress"] return reward
利用此函数,代理可以在越接近终点线时获得更多奖励。这应该减少或消除向后驾驶的非生产性试验。通常,我们希望奖励函数在操作空间上更均匀地分配奖励。创建有效的奖励函数可能是一项颇具挑战性的任务。您应该从一个简单的函数开始,并逐步增强或改进该函数。对于系统性试验,函数可能会更稳健和高效。
增强奖励函数
在您成功训练了简单直道的 AWS DeepRacer 模型后,AWS DeepRacer 车辆(虚拟或物理)可以在不偏离赛道的情况下自行驾驶。如果您让车辆在环形赛道上行驶,它将不会保持在赛道上。奖励函数忽略了通过转弯来保持在赛道上的操作。
要使车辆处理这些操作,您必须增强奖励函数。在代理进行允许的转弯时,函数应该予以奖励,如果代理做出了非法转弯,则应给予罚分。然后,您便可以开始另一轮训练。要利用以前的训练,您可以通过克隆以前训练的模型并传递以前学习的知识来开始新的训练。您可以按照这种模式逐步向奖励功能添加更多功能,以训练您的 AWS DeepRacer 车辆在日益复杂的环境中行驶。
有关更高级的奖励函数,请参阅以下示例:
探索操作空间来训练稳健的模型
作为通则,您训练的模型应该尽可能稳健,这样就可以将其应用到尽可能多的环境。稳健的模型是可以应用到广泛赛道形状和条件的模型。一般而言,一个稳健的模型不够“智能”,因为其奖励函数没有包含特定于环境的具体知识的能力。否则,您的模型更可能仅适用于类似于训练环境的环境。
在奖励函数中明确包含特定于环境的信息会导致特征工程。特征工程有助于减少训练时间,在针对特定环境定制解决方案时会很有用。但是,要训练具有一般适用性的模型,您应该避免尝试大量特征工程。
例如,在圆形赛道上训练模型时,如果您在奖励函数中明确包含了这种集合属性,就不能预期得到适合任何非圆形赛道的训练模型。
如何才能在训练出尽可能稳健的模型的同时,确保奖励函数尽可能简单? 探索操作空间的一种方法是生成您的代理可以采取的操作。另一种是通过基础训练算法的超级参数进行实验。通常,您同时使用这两种方法。在这里,我们将重点介绍如何探索操作空间,为您的 AWS DeepRacer 车辆训练一个强大的模型。
在训练 AWS DeepRacer 模型时,动作 (a) 是速度(t米/秒)和转向角度(以度为单位)s的组合。代理的操作空间定义了代理可以使用的速度和转向角度范围。对于具有 m 个速度、(v1, .., vn) 和 n 个转向角度的不连续操作空间 (s1, ..,
sm),操作空间中有 m*n 个可能的操作:
a1: (v1, s1) ... an: (v1, sn) ... a(i-1)*n+j: (vi, sj) ... a(m-1)*n+1: (vm, s1) ... am*n: (vm, sn)
(vi,
sj) 的实际值取决于 vmax 和 |smax| 的范围,不均匀分布。
每次开始训练或迭代 AWS DeepRacer 模型时,都必须先指定nm、vmax和 |smax| /或同意使用其默认值。根据您的选择,AWS DeepRacer 服务会生成您的代理可在培训中选择的可用操作。生成的操作并非均匀分布在操作空间上。
一般情况下,操作数越多、操作范围越大就会向您的代理提供更多的空间或选项,从而根据赛道情况做出更为多变的选择,例如具有不规则转弯角度或方向的弯曲赛道。对代理可用的选项越多,就越能处理赛道情况变化。因此,您即使使用简单奖励函数,训练模型也可以有广泛的应用范围。
例如,您的代理可以使用粗粒度的操作空间,其中只有少量速度和转弯角度,快速学习如何处理直线赛道。在弯曲赛道上,此粗粒度的操作空间可能会导致代理转过头,在转弯时偏离赛道。这是因为没有足够的选项供其处理来调整速度或转弯。增加速度数量和/或转弯角度数量,代理应该具备更好的能力来处理转弯,保持在赛道上。同样,如果您的代理以之字形移动,您可以尝试增加转向范围的数量,从而减少在任意给定步骤中的突然转向。
当操作空间太大时,训练性能可能会受到负面影响,因为探索操作空间用时更长。请确保在模型的一般适用性与训练性能要求之间实现效益平衡。这种优化涉及系统性实验。
系统性调整超级参数
提升模型性能的一种方法是制订更好或更高效的训练过程。例如,为获取稳健的模型,在代理的操作空间中,训练必须向代理提供或多或少的均匀分布采样。这需要充分权衡探索和开发。影响这些情况的变量包括所用的训练数据量(number of episodes between each
training 和 batch size)、代理学习的速度 (learning rate) 以及探索部分 (entropy)。要使训练切实可行,您可能需要加快学习过程。影响这一情况的变量包括 learning rate、batch size、number of
epochs 和 discount factor。
影响训练过程的变量称为超级参数。这些算法特性并非基础模型的属性。遗憾的是,超级参数本质上是经验性的。其最佳值对于所有实际用途未知,需要通过系统性实验来得出。
在讨论可以调整以调整 AWS DeepRacer 模型训练性能的超参数之前,让我们定义以下术语。
- 数据点
-
数据点也称为经验,它是 (s,a,r,s’) 的元组,其中 s 表示摄像头捕捉到的观察(或者状态),a 表示车辆采取的操作,r 表示所述操作带来的预期奖励,以及 s’ 表示在采取之后的新观察。
- 情节
-
情节是一段时间,在这段时间中,车辆从给定起点启动,然后到达终点完成赛道,或者跑出赛道。它是一系列经验的具体表达。不同的情节可以有不同的长度。
- 经验缓冲区
-
经验缓冲区包含多个已排序的数据点,在训练过程中,从不同长度的固定数量情节上收集这些数据点。对于 AWS DeepRacer,它对应于安装在您的 AWS DeepRacer 车辆上的摄像头拍摄的图像以及车辆采取的行动,并作为从中提取用于更新底层(策略和价值)神经网络的输入来源。
- 批处理
-
批次是排序的经验列表,表示一段时间中的一部分模拟,用于更新策略网络权重。它是经验缓冲区的子集。
- 训练数据
-
训练数据是从经验缓冲区中随机采样的批次组,用于训练策略网络权重。
| 超参数 | 描述 |
|---|---|
|
Gradient descent batch size (梯度下降批大小) |
从经验缓冲区中随机采样的最近车辆经验数,用于更新基础深度学习神经网络权重。随机采样有助于减少输入数据中内在的关联。使用较大的批大小可以推动对神经网络更稳定和更平滑的更新,但需要注意训练时间较长或者速度较慢的可能性。
|
|
Number of epochs (纪元数) |
在梯度下降期间,遍历训练数据以更新神经网络权重的次数。训练数据对应于来自经验缓冲区的随机样本。使用较大的纪元数可以推动更稳定的更新,但预计训练速度较慢。当批大小较小时,您可以使用较少的纪元数
|
|
Learning rate (学习速率) |
在每次更新期间,新权重的一部分可以来自梯度下降(或上升)的贡献,其余部分来自现有权重值。学习速率控制控制梯度下降(或上升)更新对网络权重的贡献度。使用较高的学习速率可以包括更多的梯度下降贡献,从而加快训练,但请注意,如果学习速率太高,预期奖励可能不会收敛。
|
Entropy |
用于确定何时向策略分布添加随机性的不确定性程度。增加的不确定性有助于 AWS DeepRacer 车辆更广泛地探索行动领域。较大的熵值会推动车辆更彻底地探索操作空间。
|
| Discount factor (折扣系数) |
系数指定了未来奖励对预期奖励的影响程度。折扣系数值越大,行驶过程中考虑贡献时需要考虑的距离就越远,训练就越慢。使用折扣系数 0.9,车辆根据行驶过程的接下来 10 个步骤提供奖励。使用折扣系数 0.999,车辆根据行驶过程的接下来 1000 个步骤提供奖励。建议的折扣系数值是 0.99、0,999 和 0.9999。
|
| Loss type (损耗类型) |
用于更新网络权重的目标函数的类型。一个良好的训练算法应该对代理的策略进行渐进式改变,使它逐渐从采取随机行动转变为采取战略性行动以增加奖励。但是,如果算法进行了过大的更改,训练将变得不稳定,代理最终也不会学习。Huber loss (Huber 损耗)
|
| Number of experience episodes between each policy-updating iteration (每次策略更新迭代之间的经验情节数) | 从中提取训练数据的经验缓冲区的大小,这些数据用于学习策略网络权重。经验情节是一段时间,在这段时间中,代理从给定起点启动,然后到达终点完成赛道,或者跑出赛道。它由一系列经验组成。不同的情节可以有不同的长度。对于简单强化学习问题,较小的缓冲区可能已足够,学习速度较快。对于具有更多局部最大值的更复杂问题,需要更大的经验缓冲区来提供更多不相关的数据点。在这种情况下,训练更慢但更稳定。建议的值为 10、20 和 40。
|
检查 AWS DeepRacer 培训工作进度
启动训练作业之后,您可以检查各个情节的奖励和赛道完成情况等训练指标,以便确定模型在训练作业中的性能。在 AWS DeepRacer 控制台上,指标显示在奖励图表中,如下图所示。
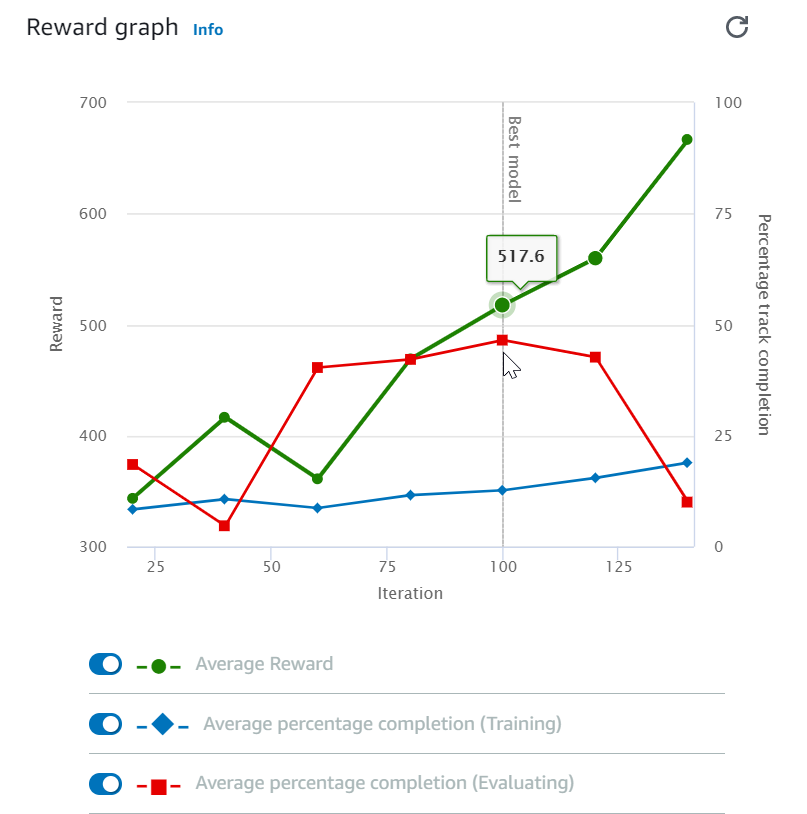
您可以选择查看在各个情节中赢得的奖励、每次迭代的平均奖励、每个情节的进度、每次迭代的平均进度或这些指标的任意组合。为此,请在奖励图表的底部切换奖励(轮次、平均值)或进度(轮次、平均值)开关。每个情节的奖励和进度以不同颜色的散点图显示。平均奖励和赛道完成情况以线形图显示,从第一次迭代之后开始。
奖励范围显示在图形的左侧,进度范围 (0-100) 显示在右侧。要读取某个训练指标的精确值,请将鼠标移动到图形上靠近数据点的位置。
当训练仍在进行时,图形每 10 秒自动更新一次。您可以选择刷新按钮以手动更新指标显示。
如果平均奖励和赛道完成情况表现出收敛的趋势,则训练任务良好。特别是,如果每个情节的进度持续达到 100%,并且奖励呈平稳状态,则表示模型可能已收敛。如果不是,请克隆模型并重新训练。
克隆已训练模型以开始新的训练通行
如果您克隆之前的训练模型作为新一轮训练的起点,就可以提升训练效率。要执行此操作,请修改超级参数以利用已经学习的知识。
在本节中,您将学习如何使用 AWS DeepRacer 控制台克隆经过训练的模型。
使用 AWS DeepRacer 控制台对强化学习模型进行迭代训练
-
如果您尚未登录,请登录 AWS DeepRacer 控制台。
-
在模型页面上,选择已训练的模型,然后从操作下拉菜单列表中选择克隆。
-
对于 Model details (模型详细信息),执行以下操作:
-
如果您不想为克隆的模型生成名称,请将
RL_model_1键入 模型名称中。 -
(可选)在 to-be-cloned模型描述(可选)中给出模型的描述。
-
-
对于 环境模拟,请选择另一个赛道选项。
-
对于 Reward function (奖励函数),请选择可用奖励函数示例之一。修改奖励函数。例如,请考虑转向。
-
展开 Algorithm settings (算法设置) 并尝试不同的选项。例如,将 Gradient descent batch size (梯度下降批大小) 值从 32 更改为 64,或者增加 Learning rate (学习速率) 以加快学习速度。
-
使用选择的不同 Stop conditions (停止条件) 进行实验。
-
选择 Start training (开始训练) 以开始新一轮的训练。
与平时训练稳健的机器学习模型一样,您务必进行系统的实验以找到最佳解决方案。
在模拟中评估 AWS DeepRacer 模型
评估模型是为了测试已训练模型的性能。在 AWS 中 DeepRacer,标准性能指标是连续完成三圈的平均时间。使用此指标,对于任意两个模型,如果一个模型比另一个模型能够让代理在同一个赛道上行驶得更快,那么这个模型就更好。
一般而言,评估模型涉及以下任务:
-
配置并启动评估作业。
-
在任务运行时观察正在进行的评估。这可以在 AWS DeepRacer 模拟器中完成。
-
在评估任务完成后检查评估摘要。您可以随时终止正在进行的评估任务。
注意
评估时间取决于您选择的标准。如果您的模型不符合评估标准,则评估将继续运行,直到达到 20 分钟的上限。
-
(可选)将评估结果提交给符合条件的 AWS DeepRacer 排行榜。排行榜上的排名让您可以了解您的模型相对于其他参赛者的表现如何。
使用 AWS DeepRacer 车辆在物理轨道上行驶时测试 AWS DeepRacer 模型,请参阅操作您的 AWS DeepRacer 车辆 。
针对真实环境优化训练 AWS DeepRacer 模型
许多因素会影响训练模型的真实表现,包括操作空间的选择、奖励函数、训练中使用的超级参数以及车辆校准和真实赛道条件。此外,模拟仅仅是(通常很粗糙)真实世界的近似。这些情况使得将在模拟中训练的模型在应用到真实世界时,取得满意的成绩成为了一项挑战。
训练模型以提供稳定的真实性能通常需要在模拟环境中多次迭代对奖励函数、操作空间、超级参数和评估的探索,然后在真实环境中测试。最后一步涉及所谓的simulation-to-real 世界(sim2real)转移,可能会感到笨拙。
为了帮助应对 sim2real 挑战,请注意以下几点:
-
确保良好校准了您的车辆。
这非常重要,因为模拟环境很可能是部分代表了真实环境。此外,代理在每一步中根据当前赛道情况采取操作,而赛道情况是摄像头捕获的图像。在高速下,它无法探测到足够远的距离来计划其路线。为了适应这种情况,模拟对速度和转向施加了限制。要确保训练模型在真实世界中正常工作,车辆必须经过正确的校准以匹配这些和其他模拟设置。有关校准车辆的更多信息,请参阅校准您的 AWS 车辆 DeepRacer 。
-
首先使用默认模型测试您的车辆。
您的 AWS DeepRacer 车辆带有加载到其推理引擎中的预训练模型。在真实环境中测试自己的模型之前,请确保车辆在默认模型中可以良好地运行。如果不行,请检查物理赛道设置。在修建不正确的物理赛道中测试模型可能会导致性能欠佳。在这种情况下,请重新配置或修理您的赛道,然后再启动或恢复测试。
注意
运行您的 AWS DeepRacer 车辆时,无需调用奖励函数即可根据经过训练的策略网络推断出操作。
-
确保模型在模拟中正常工作。
如果您的模型不能正常工作,可能是整个模型或赛道有缺陷。要找出根本原因,您应首先在模拟中评估模型,检查模拟的代理是否可以至少完成一圈而不偏离赛道。您可以通过检查奖励的收敛并观察代理在模拟器中的轨迹,来查找原因。如果奖励在模拟的代理完成一圈达到最大值而没有衰退时,这可能是一个良好的模型。
-
不要过度训练模型。
模型在模拟中稳定地完成赛道后继续训练会导致模型中的过度拟合。过度拟合的模型无法在真实环境中良好运行,因为它无法处理哪怕是模拟赛道与真实环境中很小的差别。
-
使用来自不同迭代的多个模型。
典型的训练会话会生成一系列模型,这些模型介于拟合不足与过度拟合之间。因为没有先验标准来确定正好合适的模型,所以您应该从代理在模拟器中完成一圈开始,到其能稳定跑圈之间,选择几个模型候选。
-
在测试中,从低速开始,逐步增加驾驶速度。
测试部署到车辆上的模型时,首先从较小的最高速度值开始。例如,您可以将测试速度限制设置为小于训练速度限制 10%。然后,逐渐增加测试速度限制,直到车辆开始正常行驶。您可以在校准车辆时使用设备控制台设置测试速度限制。如果车辆的速度太快,例如速度超过了在模拟器中训练时的速度,模型在实际赛道上可能无法良好表现。
-
使用车辆在不同开始位置测试模型。
模型学习在模拟中采用了特定路线,可能会对其在赛道上的位置比较敏感。您应在赛道边界内的不同位置开始车辆测试(从左边到中间到右边),以查看模型是否在特定位置表现良好。大多数模型倾向于让车辆靠近白线的某一边。为了帮助分析车辆的路径,逐个步骤绘制模拟中车辆的位置 (x, y),确定您的车辆在真实环境中可能采取的路线。
-
在直道上开始测试。
在直道上导航比在弯道上要容易得多。在直道上开始测试有助于快速排除欠佳的模型。如果车辆大部分时间无法按照直道行驶,模型在外道上的表现也不会好。
-
注意车辆仅采取一种类型操作的行为,
当您的车辆仅采取一种类型操作的行为时,例如,车辆仅向左转向,则模型可能过度拟合或拟合不足。对于给定模型参数,训练中过多迭代会导致模型过度拟合。迭代太少会导致拟合不足。
-
注意车辆沿赛道边界纠正其路径的能力。
良好的模型在车辆靠近赛道边界时会纠正自身。大多数良好训练的模型具有此功能。如果车辆可以在赛道两端边界纠正自己,可以认为这是一个稳健的高质量模型。
-
注意车辆表现出的不一致行为。
策略模型表示在给定状态下采取行动的概率分布。将训练模型加载到其推理引擎后,车辆可以根据模型的执行选择最可能的操作,一次一个步骤。如果操作概率均匀分步,则车辆采取概率相等或相近的任意一个操作。这将导致不稳定的驾驶行为。例如,当车辆一段时间(例如,一半时间)沿直线行驶,而其余时间会进行不必要的转向,那么模型拟合不足或过度拟合。
-
注意车辆仅进行一种转向类型(左或右)的情况。
如果车辆左转非常好但在尝试右转时出现问题,或者,如果车辆只能很好地右转但左转则不行,您需要仔细校准或重新校准车辆的转向。或者,您可以尝试使用其训练设置接近实际测试环境设置的模型。
-
注意车辆的突然转弯和偏离赛道。
如果车辆大部分时间按照正确路线行驶,但突然偏离赛道,则可能是由于环境的干扰。大多数常见干扰包括意外或无意识的反光。在这种情况下,在赛道周围使用隔离或者其他方式来减少眩光。
