本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 RAG 和 ReAct 提示,開發進階生成式 AI 聊天式助理
Praveen Kumar Jeyarajan、Shai Cao、Noah Hamilton、Kiowa Jackson、Jundong Qiao 和 Kara Yang、Amazon Web Services
Summary
典型的公司有 70% 的資料被困在孤立系統中。您可以使用生成式 AI 支援的聊天式助理,透過自然語言互動來釋放這些資料孤島之間的洞見和關係。為了充分利用生成式 AI,輸出必須值得信任、準確且包含可用的公司資料。成功的聊天式助理取決於下列項目:
生成式 AI 模型 (例如 Anthropic Claude 2)
資料來源向量化
進階推理技巧,例如 ReAct 架構
,用於提示模型
此模式提供來自資料來源的資料擷取方法,例如 Amazon Simple Storage Service (Amazon S3) 儲存貯體、AWS Glue 和 Amazon Relational Database Service (Amazon RDS)。透過將擷取增強生成 (RAG) 與chain-of-thought方法相交,從該資料中取得值。結果支援以聊天為基礎的複雜助理對話,這些對話會利用您公司儲存的所有資料。
此模式使用 Amazon SageMaker 手冊和定價資料表作為範例,以探索生成式 AI 聊天式助理的功能。您將建置聊天式助理,藉由回答有關定價和服務功能的問題,協助客戶評估 SageMaker 服務。解決方案使用 Streamlit 程式庫來建置前端應用程式,並使用 LangChain 架構來開發採用大型語言模型 (LLM) 的應用程式後端。
對聊天式助理的查詢會符合初始意圖分類,以路由至三個可能工作流程之一。最複雜的工作流程結合了一般諮詢指引與複雜的定價分析。您可以調整模式以符合企業、公司和工業使用案例。
先決條件和限制
先決條件
安裝和設定 AWS Cloud Development Kit (AWS CDK) Toolkit 2.114.1 或更新版本
Python 和 AWS CDK 的基本熟悉度
已安裝 Git
已安裝 Docker
Python 3.11 或更新版本
已安裝並設定 (如需詳細資訊,請參閱工具一節) 使用 AWS CDK 引導的作用中 AWS 帳戶 https://docs.aws.amazon.com/cdk/v2/guide/bootstrapping.html
Amazon Bedrock 服務中啟用了 Amazon Titan 和 Anthropic Claude 模型存取
在終端機環境中正確設定 AWS 安全登入資料,包括 。
AWS_ACCESS_KEY_ID
限制
LangChain 不支援每個 LLM 進行串流。支援 Anthropic Claude 模型,但不支援來自 AI21 實驗室的模型。
此解決方案會部署到單一 AWS 帳戶。
此解決方案只能在可使用 Amazon Bedrock 和 Amazon Kendra 的 AWS 區域中部署。如需可用性的相關資訊,請參閱 Amazon Bedrock 和 Amazon Kendra 的文件。
產品版本
Python 3.11 版或更新版本
串流 1.30.0 版或更新版本
Streamlit-chat 0.1.1 版或更新版本
LangChain 0.1.12 版或更新版本
AWS CDK 2.132.1 版或更新版本
架構
目標技術堆疊
Amazon Athena
Amazon Bedrock
Amazon Elastic Container Service (Amazon ECS)
AWS Glue
AWS Lambda
Amazon S3
Amazon Kendra
Elastic Load Balancing
目標架構
AWS CDK 程式碼會部署在 AWS 帳戶中設定聊天式助理應用程式所需的所有資源。下圖中顯示的聊天式助理應用程式旨在回答來自使用者的 SageMaker 相關查詢。使用者透過 Application Load Balancer 連線至包含託管 Streamlit 應用程式的 Amazon ECS 叢集的 VPC。協同運作 Lambda 函數會連線至應用程式。S3 儲存貯體資料來源透過 Amazon Kendra 和 AWS Glue 將資料提供給 Lambda 函數。Lambda 函數會連線至 Amazon Bedrock,以回應聊天式助理使用者的查詢 (問題)。
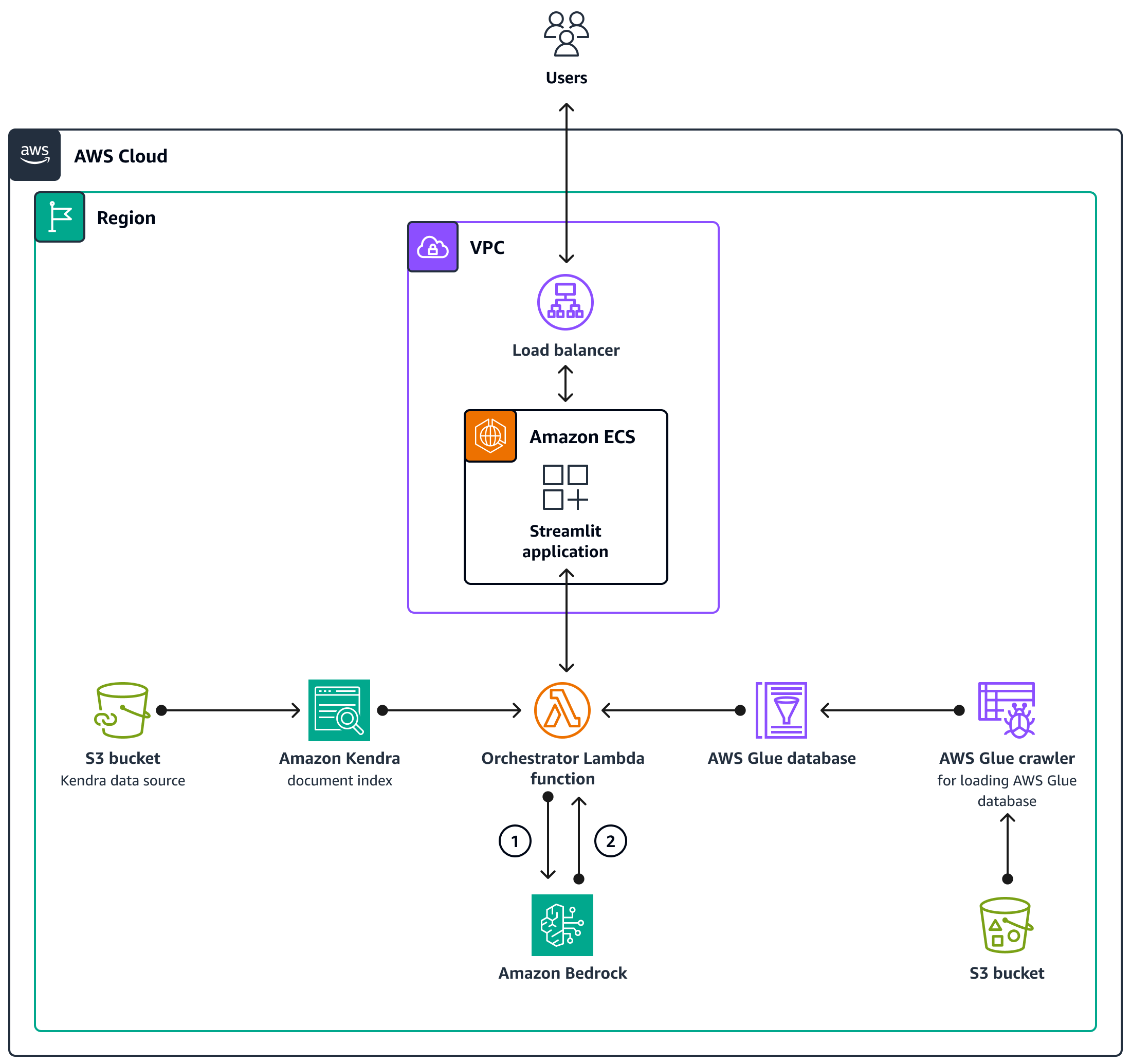
協同運作 Lambda 函數會將 LLM 提示請求傳送至 Amazon Bedrock 模型 (Claude 2)。
Amazon Bedrock 會將 LLM 回應傳回協調 Lambda 函數。
協同運作 Lambda 函數內的邏輯流程
當使用者透過 Streamlit 應用程式提出問題時,它會直接叫用協調 Lambda 函數。下圖顯示叫用 Lambda 函數時的邏輯流程。
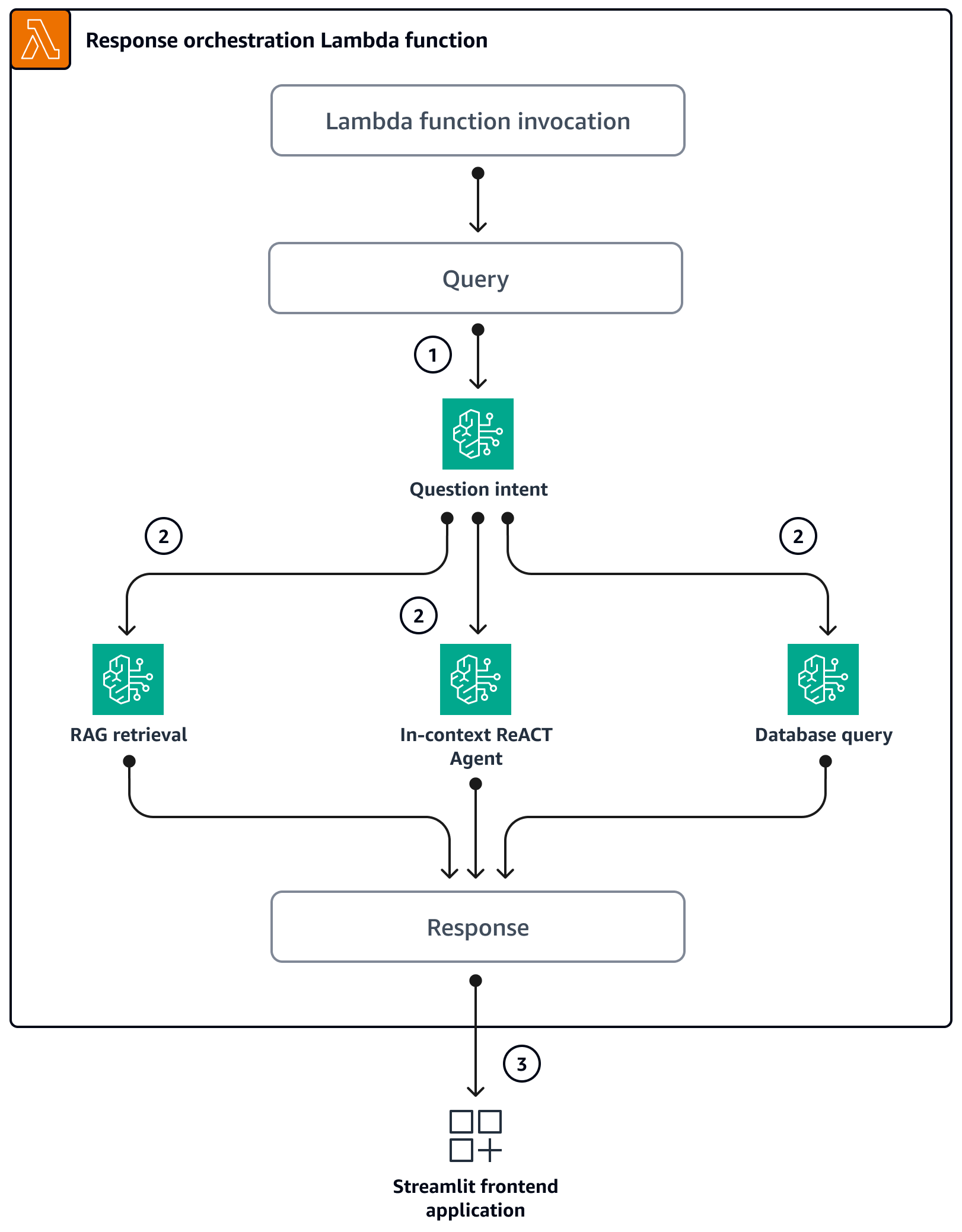
步驟 1 – 輸入
query(問題) 分類為三個意圖之一:一般 SageMaker 指引問題
一般 SageMaker 定價 (訓練/推論) 問題
與 SageMaker 和定價相關的複雜問題
步驟 2 – 輸入會
query啟動以下三種服務之一:RAG Retrieval service,它會從 Amazon Kendra向量資料庫擷取相關內容,並透過 Amazon Bedrock 呼叫 LLM,以摘要擷取的內容作為回應。 Database Query service,其使用 - 相關資料表的 LLM、資料庫中繼資料和範例資料列,將輸入轉換為 SQLquery查詢。資料庫查詢服務會透過 Amazon Athena對 SageMaker 定價資料庫執行 SQL 查詢,並將查詢結果摘要為回應。 In-context ReACT Agent service,這會先將輸入細分為query多個步驟,再提供回應。代理程式使用RAG Retrieval service和Database Query service做為工具,在推理過程中擷取相關資訊。推理和動作程序完成後,客服人員會產生最終答案作為回應。
步驟 3 – 協同運作 Lambda 函數的回應會以輸出形式傳送至 Streamlit 應用程式。
工具
AWS 服務
Amazon Athena 是一種互動式查詢服務,可協助您使用標準 SQL 直接在 Amazon Simple Storage Service (Amazon S3) 中分析資料。
Amazon Bedrock 是一項全受管服務,可讓您透過統一 API 使用來自領導 AI 新創公司的高效能基礎模型 (FMs) 和 Amazon。
AWS 雲端開發套件 (AWS CDK) 是一種軟體開發架構,可協助您在程式碼中定義和佈建 AWS 雲端基礎設施。
AWS Command Line Interface (AWS CLI) 是一種開放原始碼工具,可協助您透過命令列 shell 中的命令與 AWS 服務互動。
Amazon Elastic Container Service (Amazon ECS) 是快速、可擴展的容器管理服務,可協助您執行、停止和管理叢集上的容器。
AWS Glue 是全受管的擷取、轉換和載入 (ETL) 服務。它可協助您可靠地分類、清理、擴充和移動資料存放區和資料串流之間的資料。此模式使用 AWS Glue 爬蟲程式和 AWS Glue Data Catalog 資料表。
Amazon Kendra 是一種智慧型搜尋服務,使用自然語言處理和進階機器學習演算法,傳回從資料搜尋問題的特定答案。
AWS Lambda 是一種運算服務,可協助您執行程式碼,而不需要佈建或管理伺服器。它只會在需要時執行程式碼並自動擴展,因此您只需按使用的運算時間付費。
Amazon Simple Storage Service (Amazon S3) 是一種雲端型物件儲存服務,可協助您儲存、保護和擷取任何數量的資料。
Elastic Load Balancing (ELB) 會將傳入的應用程式或網路流量分散到多個目標。例如,您可以在一或多個可用區域中跨 Amazon Elastic Compute Cloud (Amazon EC2) 執行個體、容器和 IP 地址分配流量。
程式碼儲存庫
此模式的程式碼可在 GitHub genai-bedrock-chatbot
程式碼儲存庫包含下列檔案和資料夾:
assets資料夾 – 架構圖表和公有資料集的靜態資產code/lambda-container資料夾 – 在 Lambda 函數中執行的 Python 程式碼code/streamlit-app資料夾 – 在 Amazon ECS 中做為容器映像執行的 Python 程式碼tests資料夾 – 執行以單元測試 AWS CDK 建構的 Python 檔案code/code_stack.py– 用來建立 AWS 資源的 AWS CDK 建構 Python 檔案app.py– 用於在目標 AWS 帳戶中部署 AWS 資源的 AWS CDK 堆疊 Python 檔案requirements.txt– 必須為 AWS CDK 安裝的所有 Python 相依性清單requirements-dev.txt– 必須安裝才能讓 AWS CDK 執行單元測試套件的所有 Python 相依性清單cdk.json– 輸入檔案,用來提供啟動資源所需的值
注意:AWS CDK 程式碼使用 L3 (第 3 層) 建構和由 AWS 管理的 AWS Identity and Access Management (IAM) 政策來部署解決方案。 |
|---|
最佳實務
此處提供的程式碼範例僅適用於proof-of-concept(PoC) 或試行示範。如果您想要將程式碼帶入生產環境,請務必使用下列最佳實務:
設定 Lambda 函數的監控和提醒。如需詳細資訊,請參閱監控和疑難排解 Lambda 函數。如需使用 Lambda 函數的一般最佳實務,請參閱 AWS 文件。
史詩
| 任務 | 描述 | 所需的技能 |
|---|---|---|
匯出要部署堆疊之帳戶和 AWS 區域的變數。 | 若要使用環境變數為 AWS CDK 提供 AWS 登入資料,請執行下列命令。
| DevOps 工程師,AWS DevOps |
設定 AWS CLI 設定檔。 | 若要設定帳戶的 AWS CLI 設定檔,請遵循 AWS 文件中的指示。 | DevOps 工程師,AWS DevOps |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
在本機電腦上複製儲存庫。 | 若要複製儲存庫,請在終端機中執行下列命令。
| DevOps 工程師,AWS DevOps |
設定 Python 虛擬環境並安裝必要的相依性。 | 若要設定 Python 虛擬環境,請執行下列命令。
若要設定所需的相依性,請執行下列命令。
| DevOps 工程師,AWS DevOps |
設定 AWS CDK 環境並合成 AWS CDK 程式碼。 |
| DevOps 工程師,AWS DevOps |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
佈建 Claude 模型存取。 | 若要為您的 AWS 帳戶啟用 Anthropic Claude 模型存取,請遵循 Amazon Bedrock 文件中的指示。 | AWS DevOps |
在帳戶中部署資源。 | 若要使用 AWS CDK 在 AWS 帳戶中部署資源,請執行下列動作:
成功部署後,您可以使用 CloudFormation Outputs 區段中提供的 URL 來存取聊天式助理應用程式。 | AWS DevOps,DevOps 工程師 |
執行 AWS Glue 爬蟲程式並建立資料目錄資料表。 | AWS Glue 爬蟲程式用於保持資料結構描述動態。解決方案會隨需執行爬蟲程式,在 AWS Glue Data Catalog 資料表中建立和更新分割區。將 CSV 資料集檔案複製到 S3 儲存貯體後,請執行 AWS Glue 爬蟲程式並建立 Data Catalog 資料表結構描述以進行測試:
注意AWS CDK 程式碼會將 AWS Glue 爬蟲程式設定為隨需執行,但您也可以排定它定期執行。 | DevOps 工程師,AWS DevOps |
啟動文件索引。 | 將檔案複製到 S3 儲存貯體後,請使用 Amazon Kendra 來編目和編製索引:
注意AWS CDK 程式碼會將 Amazon Kendra 索引同步設定為隨需執行,但您也可以使用排程參數定期執行。 | AWS DevOps,DevOps 工程師 |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
移除 AWS 資源。 | 測試解決方案之後,請清除資源:
| DevOps 工程師,AWS DevOps |
故障診斷
| 問題 | 解決方案 |
|---|---|
AWS CDK 傳回錯誤。 | 如需 AWS CDK 問題的協助,請參閱疑難排解常見的 AWS CDK 問題。 |
相關資源
其他資訊
AWS CDK 命令
使用 AWS CDK 時,請記住下列有用的命令:
列出應用程式中的所有堆疊
cdk ls發出合成的 AWS CloudFormation 範本
cdk synth將堆疊部署到您的預設 AWS 帳戶和區域
cdk deploy比較已部署堆疊與目前狀態
cdk diff開啟 AWS CDK 文件
cdk docs刪除 CloudFormation 堆疊並移除 AWS 部署的資源
cdk destroy
