Amazon Forecast ya no está disponible para nuevos clientes. Los clientes actuales de Amazon Forecast pueden seguir utilizando el servicio con normalidad. Más información
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Evaluación de la precisión del predictor
Amazon Forecast produce métricas de precisión para evaluar los predictores y ayudarle a elegir cuál usar para generar previsiones. Forecast evalúa los predictores mediante el error cuadrático medio (RMSE), la pérdida cuantil ponderada (wQL), el error porcentual absoluto medio (MAPE), el error escalado absoluto medio (MASE) y el error porcentual absoluto ponderado (WAPE).
Amazon Forecast utiliza pruebas retrospectivas (backtesting) para ajustar los parámetros y producir métricas de precisión. Durante las pruebas retrospectivas, Forecast divide automáticamente los datos de serie temporal en dos conjuntos: un conjunto de entrenamiento y un conjunto de pruebas. El conjunto de entrenamiento se usa para entrenar un modelo y generar previsiones para los puntos de datos del conjunto de pruebas. Forecast evalúa la precisión del modelo comparando los valores pronosticados con los valores observados en el conjunto de pruebas.
Forecast le permite evaluar los predictores mediante diferentes tipos de previsión, que pueden ser un conjunto de previsiones cuantílicas y la previsión media. La previsión media proporciona una estimación puntual, mientras que las previsiones cuantílicas suelen ofrecer un rango de posibles resultados.
Cuadernos de Python
Para obtener una step-by-step guía sobre la evaluación de las métricas predictoras, consulte Calcular métricas mediante pruebas retrospectivas a nivel de elemento
Temas
Interpretación de las métricas de precisión
Amazon Forecast proporciona métricas de error cuadrático medio (RMSE), pérdida cuantil ponderada (wQL), pérdida de cuantil ponderada media (wQL promedio), error de escala absoluto medio (MASE), error porcentual absoluto medio (MAPE) y error porcentual absoluto ponderado (WAPE) para evaluar sus predictores. Junto con las métricas del predictor general, Forecast calcula las métricas para cada ventana de prueba de datos.
Puede ver métricas de precisión para sus predictores mediante el kit de desarrollo de software (SDK) de Amazon Forecast y la consola Amazon Forecast.
nota
En el caso de las métricas wQL promedio, wQL, RMSE, MASE, MAPE y WAPE, un valor inferior indica un modelo superior.
Temas
Pérdida cuantil ponderada (wQL)
La métrica de pérdida cuantil ponderada (wQL) mide la precisión de un modelo en un cuantil específico. Resulta especialmente útil cuando la predicción insuficiente y la sobrepredicción conllevan distintos costos. Al establecer la ponderación (τ) de la función wQL, puede incorporar automáticamente diferentes penalizaciones por predicción insuficiente y sobrepredicción.
La función de pérdida se calcula de la siguiente manera.
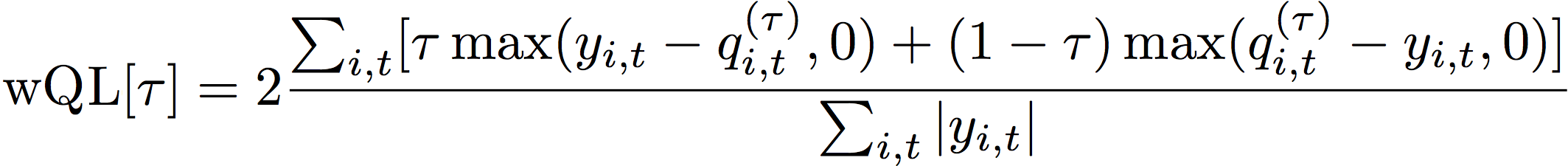
- Donde:
-
τ: un cuantil del conjunto {0,01, 0,02, ..., 0,99}
qi,t(τ): el cuantil τ que predice el modelo.
yi,t: el valor observado en el punto (i,t)
Los cuantiles (τ) de wQL pueden oscilar entre 0,01 (P1) y 0,99 (P99). La métrica wQL no se puede calcular para la previsión media.
De forma predeterminada, Forecast calcula wQL en 0.1 (P10), 0.5 (P50) y 0.9 (P90).
-
P10 (0,1): se espera que el valor real sea menor que el valor predicho el 10 % del tiempo.
-
P50 (0,5): se espera que el valor real sea menor que el valor predicho el 50 % del tiempo. Esto también se conoce como previsión media.
-
P90 (0,9): se espera que el valor real sea menor que el valor predicho el 90 % del tiempo.
En el sector minorista, el costo de la falta de existencias suele ser mayor que el costo de la sobreoferta, por lo que hacer una previsión a P75 (τ=0,75) puede ser más informativo que hacer una previsión a un cuantil medio (P50). En estos casos, wQL[0,75] asigna una penalización mayor a la infraprevisión (0,75) y una penalización menor a la sobreprevisión (0,25).
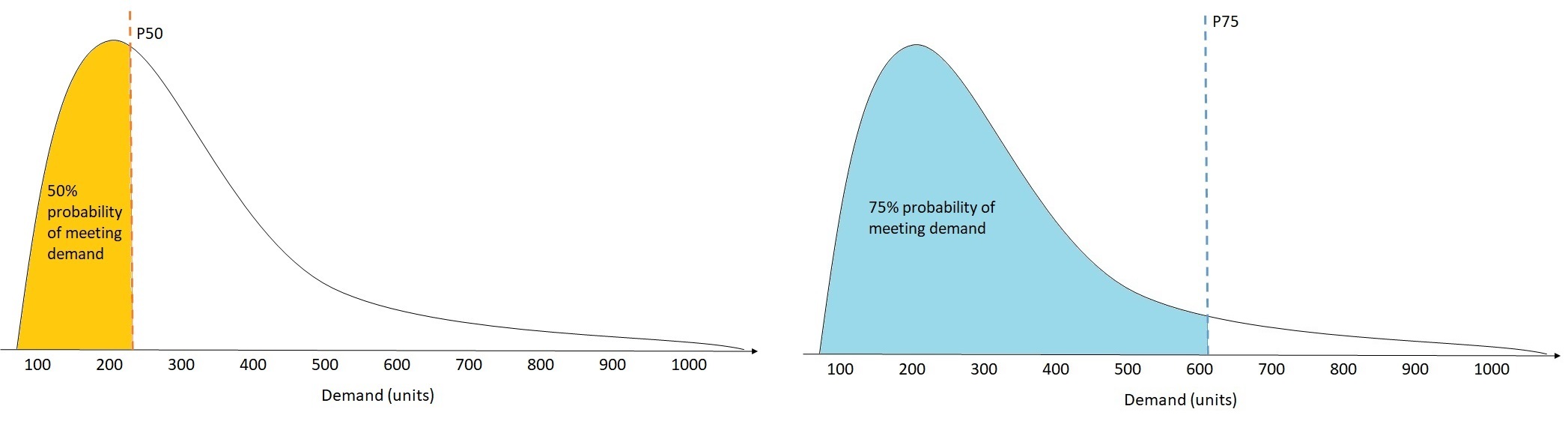
La figura anterior muestra las diferentes previsiones de demanda en wQL[0,50] y wQL[0,75]. El valor previsto en P75 es significativamente superior al valor previsto en P50, ya que se espera que la previsión P75 satisfaga la demanda el 75 % de las veces, mientras que la previsión P50 solo satisfaga la demanda el 50 % de las veces.
Cuando la suma de valores observados de todos los artículos y puntos de tiempo es aproximadamente cero en un determinado período de las pruebas de datos, la expresión de pérdida de cuantil ponderada no está definida. En estos casos, Forecast genera la pérdida de cuantil no ponderada, que es el numerador de la expresión wQL.
Forecast también calcula la wQL promedio, que es el valor medio de las pérdidas cuantiles ponderadas sobre todos los cuantiles especificados. De forma predeterminada, será el promedio de wQL[0,10], wQL[0,50] y wQL[0,90].
Error porcentual absoluto ponderado (WAPE)
El error porcentual absoluto ponderado (WAPE) mide la desviación general de los valores pronosticados con respecto a los valores observados. El WAPE se calcula tomando la suma de los valores observados y la suma de los valores pronosticados y calculando el error entre esos dos valores. Un valor más bajo indica un modelo más exacto.
Cuando la suma de valores observados de todos los artículos y puntos de tiempo es aproximadamente cero en un determinado período de las pruebas de datos, la expresión de error porcentual absoluto ponderado no está definida. En estos casos, Forecast genera la suma de errores absolutos no ponderados, que es el numerador de la expresión WAPE.
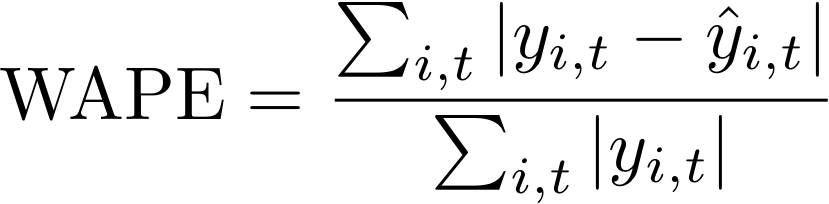
- Donde:
-
yi,t: el valor observado en el punto (i,t)
ŷi,t: el valor previsto en el punto (i,t)
Forecast usa la previsión media como el valor previsto, ŷi,t.
El WAPE es más resistente a los valores atípicos que el error cuadrático medio (RMSE) porque utiliza el error absoluto en lugar del error cuadrático.
Anteriormente, Amazon Forecast denominaba a la métrica WAPE Error porcentual absoluto medio (MAPE) y utilizaba la previsión media (P50) como valor previsto. Forecast ahora usa la previsión media para calcular WAPE. La métrica wQL[0,5] equivale a la métrica WAPE [mediana], como se muestra a continuación:
![Mathematical equation showing the equivalence of wQL[0.5] and WAPE[median] metrics.](images/wql-to-wape.PNG)
Error cuadrático medio (RMSE)
Error cuadrático medio (RMSE) es la raíz cuadrada del promedio de los errores cuadrados y, por tanto, es más sensible a los valores atípicos que otras métricas de precisión. Un valor más bajo indica un modelo más exacto.

- Donde:
-
yi,t: el valor observado en el punto (i,t)
ŷi,t: el valor previsto en el punto (i,t)
nT: el número de puntos de datos en un conjunto de pruebas
Forecast usa la previsión media como el valor previsto, ŷi,t. Al calcular las métricas predictoras, nT es el número de puntos de datos en una ventana de prueba de datos.
RMSE utiliza el valor cuadrado de los valores residuales, lo que amplifica el impacto de los valores atípicos. En los casos de uso en los que solo unas pocas predicciones erróneas importantes pueden resultar muy costosas, RMSE es la métrica más relevante.
Los predictores creados antes del 11 de noviembre de 2020 calcularon el RMSE utilizando el cuantil 0,5 (P50) de forma predeterminada. Forecast ahora usa la previsión media.
Error porcentual absoluto medio (MAPE)
Error porcentual absoluto medio (MAPE) toma el valor absoluto del porcentaje de error entre los valores observados y pronosticados para cada unidad de tiempo y, a continuación, promedia esos valores. Un valor más bajo indica un modelo más exacto.

- Donde:
-
At: el valor observado en el punto t
Ft: el valor previsto en el punto t
n: el número de puntos de datos en la serie temporal
Forecast usa la previsión media como el valor previsto, ŷt.
MAPE es útil para los casos en los que los valores difieren significativamente entre puntos de tiempo y los valores atípicos tienen un impacto significativo.
Error de escala absoluto medio (MASE)
El error de escala absoluto medio (MASE) se calcula dividiendo el error promedio entre un factor de escala. Este factor de escala depende del valor de estacionalidad, m, que se selecciona en función de la frecuencia de previsión. Un valor más bajo indica un modelo más exacto.
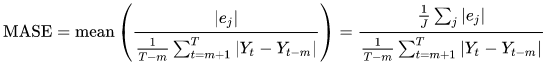
- Donde:
-
Yt: el valor observado en el punto t
Yt-m: el valor observado en el punto t-m
ej: el error en el punto j (valor observado - valor previsto)
m: el valor de estacionalidad
Forecast usa la previsión media como el valor previsto.
MASE es ideal para conjuntos de datos que son de naturaleza cíclica o que tienen propiedades estacionales. Por ejemplo, sería útil tener en cuenta el impacto estacional para pronosticar los artículos que tienen una gran demanda durante los veranos y una demanda baja durante los inviernos.
Exportación de métricas de precisión
nota
Los archivos de exportación pueden devolver directamente información de la importación del conjunto de datos. Esto hace que los archivos sean vulnerables a ejecuciones CSV si los datos importados contienen fórmulas o comandos. Por este motivo, los archivos exportados pueden provocar advertencias de seguridad. Para evitar actividades maliciosas, desactive los enlaces y las macros al leer los archivos exportados.
Forecast le permite exportar los valores previstos y las métricas de precisión generadas durante las pruebas de datos.
Puede utilizar estas exportaciones para evaluar artículos específicos en puntos de tiempo y cuantiles específicos y comprender mejor su predictor. Las exportaciones de prueba de datos se envían a una ubicación de S3 específica y contienen dos carpetas:
-
valores previstos: contiene archivos CSV o Parquet con valores previstos en cada tipo de previsión para cada prueba de datos.
-
accuracy-metrics-values: Contiene archivos CSV o Parquet con las métricas de cada prueba retrospectiva, junto con el promedio de todas las pruebas retrospectivas. Estas métricas incluyen la wQL para cada cuantil, la wQL promedio, el RMSE, el MASE, el MAPE y el WAPE.
La carpeta forecasted-values contiene los valores previstos en cada tipo de previsión para cada período de prueba de datos. También incluye información sobre el elemento IDs, las dimensiones, las marcas de tiempo, los valores objetivo y las horas de inicio y finalización de la ventana de backtest.
La carpeta accuracy-metrics-values contiene las métricas de precisión de cada período de pruebas de datos, así como las métricas medias de todas los períodos de pruebas de datos. Contiene métricas wQL para cada cuantil especificado, así como métricas wQL promedio, RMSE, MASE, MAPE y WAPE.
Los archivos de ambas carpetas siguen la convención de nomenclatura: <ExportJobName>_<ExportTimestamp>_<PartNumber>.csv.
Puede exportar métricas de precisión mediante el kit de desarrollo de software (SDK) de Amazon Forecast y la consola Amazon Forecast.
Elección de los tipos de previsión
Amazon Forecast utiliza tipos de previsión para crear predicciones y evaluar predictores. Los tipos de Forecast se presentan de dos formas:
-
Tipo de previsión media: previsión que utiliza la media como valor esperado. Suele utilizarse como previsiones puntuales para un momento dado.
-
Tipo de previsión de cuantil: previsión en un cuantil especificado. Normalmente se utiliza para proporcionar un intervalo de predicción, que es un rango de valores posibles para tener en cuenta la incertidumbre de la previsión. Por ejemplo, una previsión en el cuantil
0.65estimará un valor inferior al valor observado el 65 % de las veces.
De forma predeterminada, Forecast usa los siguientes valores para los tipos de previsión del predictor: 0.1 (P10), 0.5 (P50) y 0.9 (P90). Puede elegir hasta cinco tipos de previsión personalizados, incluidos cuantiles mean que van desde 0.01 (P1) hasta 0.99 (P99).
Los cuantiles pueden proporcionar un límite superior e inferior para las previsiones. Por ejemplo, el uso de los tipos de previsión 0.1 (P10) y 0.9 (P90) proporciona un rango de valores conocido como intervalo de confianza del 80 %. Se espera que el valor observado sea inferior al valor P10 el 10 % del tiempo y que el valor P90 sea superior al valor observado el 90 % del tiempo. Al generar previsiones en p10 y P90, es de esperar que el valor real se sitúe entre esos límites el 80 % de las veces. Este rango de valores se representa mediante la región sombreada entre P10 y P90 en la siguiente figura.
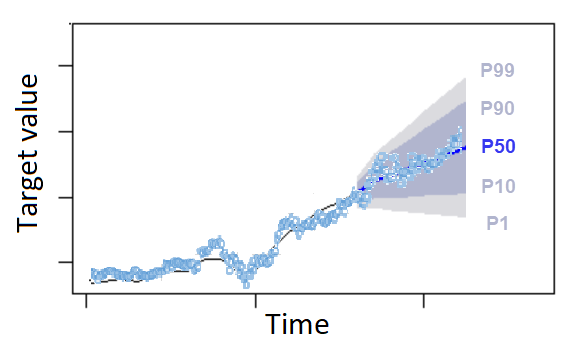
También puede utilizar una previsión de cuantil como previsión puntual cuando el costo de la predicción insuficiente difiera del costo de la sobrepredicción. Por ejemplo, en algunos casos de venta minorista, el costo de no tener existencias suficientes es mayor que el costo de tener un exceso de existencias. En estos casos, la previsión de 0,65 (P65) es más informativa que la mediana (P50) o la previsión media.
Al entrenar un predictor, puede elegir tipos de previsión personalizados mediante el kit de desarrollo de software (SDK) de Amazon Forecast y la consola Amazon Forecast.

Cómo trabajar con predictores heredados
Configuración de los parámetros de la prueba de datos
Forecast utiliza pruebas de datos para calcular las métricas de precisión. Si ejecuta varias pruebas de datos, Forecast calcula el promedio de cada métrica a lo largo de todos los períodos de pruebas de datos. De forma predeterminada, Forecast calcula una prueba de datos, con el tamaño del período de prueba de datos (conjunto de pruebas) igual a la duración del horizonte de previsión (ventana de predicción). Al entrenar un predictor, puede establecer tanto la duración del período de pruebas de datos como el número de escenarios de pruebas de datos.
Forecast omite los valores llenados del proceso de prueba de datos, y cualquier artículo con valores llenados dentro de un período de prueba de datos determinado se excluirá de esa prueba de datos. Esto se debe a que Forecast solo compara los valores previstos con los valores observados durante las pruebas de datos y los valores llenados no son valores observados.
La ventana de prueba de datos debe ser al menos tan grande como el horizonte de previsión y menor de la mitad de la duración de todo el conjunto de datos de series temporales de destino. Puede elegir entre 1 y 5 pruebas de datos.

Por lo general, al aumentar el número de pruebas de datos se obtienen métricas de precisión más fiables, ya que se utiliza una mayor parte de la serie temporal durante las pruebas y Forecast puede obtener una media de las métricas de todas las pruebas de datos.
Puede establecer los parámetros de prueba de datos mediante el kit de desarrollo de software (SDK) de Amazon Forecast y la consola Amazon Forecast.

HPO y AutoML
De forma predeterminada, Amazon Forecast utiliza los cuantiles 0.1 (P10), 0.5 (P50) y 0.9 (P90) para el ajuste de hiperparámetros durante la optimización de hiperparámetros (HPO) y para la selección de modelos durante AutoML. Si especifica tipos de previsión personalizados al crear un predictor, Forecast utiliza esos tipos de previsión durante la HPO y AutoML.
Si se especifican tipos de previsión personalizados, Forecast utiliza esos tipos de previsión especificados para determinar los resultados óptimos durante HPO y AutoML. Durante la HPO, Forecast utiliza el primer período de prueba de datos para encontrar los valores de hiperparámetros óptimos. Durante AutoML, Forecast utiliza los promedios de todos los períodos de prueba de datos y los valores de hiperparámetros óptimos de HPO para encontrar el algoritmo óptimo.
Tanto para AutoML como para HPO, Forecast elige la opción que minimiza las pérdidas medias en comparación con los tipos de previsión. También puede optimizar su predictor durante AutoML y HPO con una de las siguientes métricas de precisión: pérdida de cuantil ponderada media (wQL promedio), error porcentual absoluto ponderado (WAPE), error cuadrático medio (RMSE), error porcentual absoluto medio (MAPE) o error escalado medio absoluto (MASE).
Puede seleccionar una métrica de optimización mediante el kit de desarrollo de software (SDK) de Amazon Forecast y la consola de Amazon Forecast.
