Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Kemampuan 2. Menyediakan akses, penggunaan, dan implementasi yang aman untuk teknik AI RAG generatif
Diagram berikut menggambarkan layanan AWS yang direkomendasikan untuk akun Generative AI untuk kemampuan retrieval augmented generation (RAG). Ruang lingkup skenario ini adalah untuk mengamankan fungsionalitas RAG.
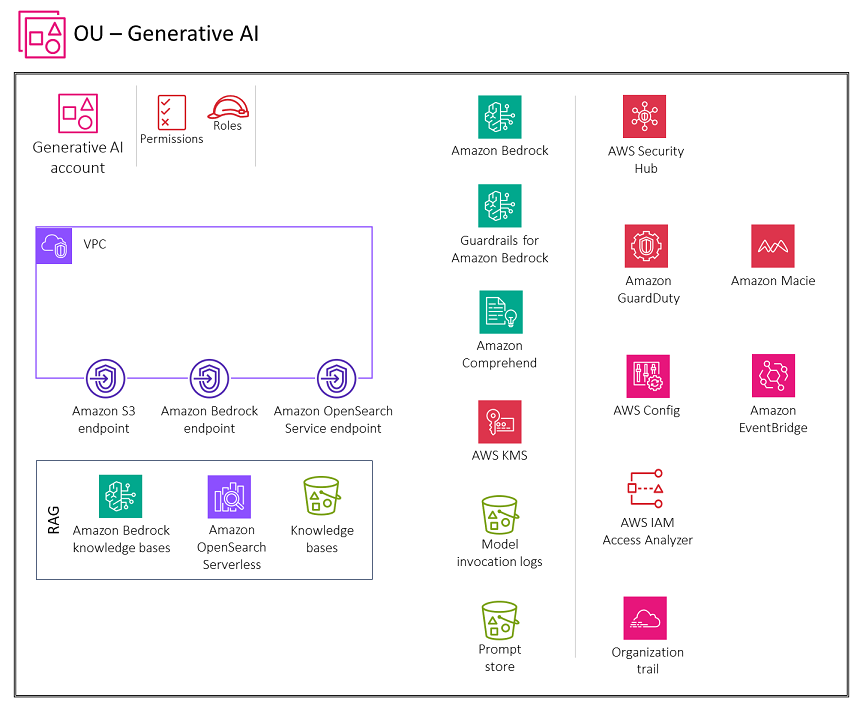
Akun Generative AI mencakup layanan yang diperlukan untuk menyimpan embeddings dalam database vektor, menyimpan percakapan untuk pengguna, dan memelihara toko yang cepat bersama dengan serangkaian layanan keamanan yang diperlukan untuk menerapkan pagar keamanan dan tata kelola keamanan terpusat. Anda harus membuat titik akhir gateway Amazon S3 untuk log pemanggilan model, penyimpanan cepat, dan bucket sumber data basis pengetahuan di Amazon S3 yang dikonfigurasi untuk diakses oleh lingkungan VPC. Anda juga harus membuat titik akhir gateway CloudWatch Log untuk CloudWatch log yang dikonfigurasi untuk diakses oleh lingkungan VPC.
Dasar Pemikiran
Retrieval Augmented Generation (RAG)
Saat Anda memberi pengguna akses ke basis pengetahuan Amazon Bedrock, Anda harus membahas pertimbangan keamanan utama ini:
-
Akses aman ke pemanggilan model, basis pengetahuan, riwayat percakapan, dan penyimpanan cepat
-
Enkripsi percakapan, penyimpanan cepat, dan basis pengetahuan
-
Peringatan untuk potensi risiko keamanan seperti injeksi cepat atau pengungkapan informasi sensitif
Bagian selanjutnya membahas pertimbangan keamanan dan fungsionalitas AI generatif ini.
Pertimbangan desain
Kami menyarankan Anda menghindari penyesuaian FM dengan data sensitif (lihat bagian tentang kustomisasi model AI generatif nanti dalam panduan ini). Sebaliknya, gunakan teknik RAG untuk berinteraksi dengan informasi sensitif. Metode ini menawarkan beberapa keuntungan:
-
Kontrol dan visibilitas yang lebih ketat. Dengan memisahkan data sensitif dari model, Anda dapat melakukan kontrol dan visibilitas yang lebih besar atas informasi sensitif. Data dapat dengan mudah diedit, diperbarui, atau dihapus sesuai kebutuhan, yang membantu memastikan tata kelola data yang lebih baik.
-
Mengurangi pengungkapan informasi sensitif. RAG memungkinkan interaksi yang lebih terkontrol dengan data sensitif selama pemanggilan model. Ini membantu mengurangi risiko pengungkapan informasi sensitif yang tidak diinginkan, yang dapat terjadi jika data secara langsung dimasukkan ke dalam parameter model.
-
Fleksibilitas dan kemampuan beradaptasi. Memisahkan data sensitif dari model memberikan fleksibilitas dan kemampuan beradaptasi yang lebih besar. Ketika persyaratan atau peraturan data berubah, informasi sensitif dapat diperbarui atau dimodifikasi tanpa perlu melatih kembali atau membangun kembali seluruh model bahasa.
Basis pengetahuan Amazon Bedrock
Anda dapat menggunakan basis pengetahuan Amazon Bedrock untuk membangun aplikasi RAG FMs dengan menghubungkan dengan sumber data Anda sendiri secara aman dan efisien. Fitur ini menggunakan Amazon OpenSearch Tanpa Server sebagai penyimpanan vektor untuk mengambil informasi yang relevan dari data Anda secara efisien. Data tersebut kemudian digunakan oleh FM untuk menghasilkan respons. Data Anda disinkronkan dari Amazon S3 ke basis pengetahuan, dan
Pertimbangan keamanan
Beban kerja AI RAG generatif menghadapi risiko unik, termasuk eksfiltrasi data sumber data RAG dan keracunan sumber data RAG dengan suntikan cepat atau malware oleh pelaku ancaman. Basis pengetahuan Amazon Bedrock menawarkan kontrol keamanan yang kuat untuk perlindungan data, kontrol akses, keamanan jaringan, pencatatan dan pemantauan, serta validasi input/output yang dapat membantu mengurangi risiko ini.
Remediasi
Perlindungan data
Enkripsi data basis pengetahuan Anda saat istirahat dengan menggunakan kunci terkelola pelanggan AWS Key Management Service (AWS KMS) yang Anda buat, miliki, dan kelola. Saat Anda mengonfigurasi pekerjaan penyerapan data untuk basis pengetahuan Anda, enkripsi pekerjaan dengan kunci yang dikelola pelanggan. Jika Anda memilih untuk mengizinkan Amazon Bedrock membuat penyimpanan vektor di OpenSearch Layanan Amazon untuk basis pengetahuan Anda, Amazon Bedrock dapat meneruskan kunci AWS KMS pilihan Anda ke Layanan OpenSearch Amazon untuk enkripsi.
Anda dapat mengenkripsi sesi di mana Anda menghasilkan respons dari kueri basis pengetahuan dengan kunci AWS KMS. Anda menyimpan sumber data untuk basis pengetahuan Anda di bucket S3 Anda. Jika Anda mengenkripsi sumber data di Amazon S3 dengan kunci yang dikelola pelanggan, lampirkan kebijakan ke peran layanan basis Pengetahuan Anda. Jika penyimpanan vektor yang berisi basis pengetahuan Anda dikonfigurasi dengan rahasia AWS Secrets Manager, enkripsi rahasia dengan kunci yang dikelola pelanggan.
Untuk informasi selengkapnya dan kebijakan yang akan digunakan, lihat Enkripsi sumber daya basis pengetahuan di dokumentasi Amazon Bedrock.
Manajemen identitas dan akses
Buat peran layanan khusus untuk basis pengetahuan untuk Amazon Bedrock dengan mengikuti prinsip hak istimewa paling sedikit. Buat hubungan kepercayaan yang memungkinkan Amazon Bedrock untuk mengambil peran ini, dan membuat serta mengelola basis pengetahuan. Lampirkan kebijakan identitas berikut ke peran layanan basis Pengetahuan kustom:
-
Izin untuk mengakses model Amazon Bedrock
-
Izin untuk mengakses sumber data Anda di Amazon S3
-
Izin untuk mengakses database vektor Anda di Layanan OpenSearch
-
Izin untuk mengakses kluster basis data Amazon Aurora Anda (opsional)
-
Izin untuk mengakses database vektor yang dikonfigurasi dengan rahasia AWS Secrets Manager (opsional)
-
Izin AWS untuk mengelola kunci AWS KMS untuk penyimpanan data sementara selama penyerapan data
-
Izin untuk mengobrol dengan dokumen Anda
-
Izin bagi AWS untuk mengelola sumber data dari akun AWS pengguna lain (opsional).
Basis pengetahuan mendukung konfigurasi keamanan untuk menyiapkan kebijakan akses data untuk basis pengetahuan dan kebijakan akses jaringan Anda untuk basis pengetahuan Amazon OpenSearch Tanpa Server pribadi Anda. Untuk informasi selengkapnya, lihat Membuat basis pengetahuan dan peran Layanan di dokumentasi Amazon Bedrock.
Validasi input dan output
Validasi input sangat penting untuk basis pengetahuan Amazon Bedrock. Gunakan perlindungan malware di Amazon S3 untuk memindai file dari konten berbahaya sebelum mengunggahnya ke sumber data. Untuk informasi selengkapnya, lihat postingan blog AWS Mengintegrasikan Pemindaian Malware ke dalam Saluran Penyerapan Data Anda dengan Antivirus untuk Amazon S3
Identifikasi dan saring potensi suntikan cepat dalam unggahan pengguna ke sumber data basis pengetahuan. Selain itu, deteksi dan edit informasi identitas pribadi (PII) sebagai kontrol validasi input lain dalam pipeline konsumsi data Anda. Amazon Comprehend dapat membantu mendeteksi dan menyunting data PII dalam unggahan pengguna ke sumber data basis pengetahuan. Untuk informasi selengkapnya, lihat Mendeteksi entitas PII di dokumentasi Amazon Comprehend.
Kami juga menyarankan Anda menggunakan Amazon Macie untuk mendeteksi dan menghasilkan peringatan tentang potensi data sensitif di sumber data basis pengetahuan, untuk meningkatkan keamanan dan kepatuhan secara keseluruhan. Menerapkan Guardrails for Amazon Bedrock untuk membantu menegakkan kebijakan konten, memblokir input/output yang tidak aman, dan membantu mengontrol perilaku model berdasarkan kebutuhan Anda.
Layanan AWS yang direkomendasikan
Amazon Tanpa OpenSearch Server
Amazon OpenSearch Serverless adalah konfigurasi auto-scaling sesuai permintaan untuk Amazon Service. OpenSearch Koleksi OpenSearch Tanpa Server adalah OpenSearch klaster yang menskalakan kapasitas komputasi berdasarkan kebutuhan aplikasi Anda. Basis pengetahuan Amazon Bedrock menggunakan Amazon OpenSearch Tanpa Server untuk penyematan
Terapkan otentikasi dan otorisasi yang kuat untuk penyimpanan vektor Tanpa OpenSearch Server Anda. Menerapkan prinsip hak istimewa terkecil, yang hanya memberikan izin yang diperlukan kepada pengguna dan peran.
Dengan kontrol akses data di OpenSearch Tanpa Server, Anda dapat mengizinkan pengguna mengakses koleksi dan indeks terlepas dari mekanisme akses atau sumber jaringan mereka. Anda mengelola izin akses melalui kebijakan akses data, yang berlaku untuk koleksi dan sumber daya indeks. Saat Anda menggunakan pola ini, verifikasi bahwa aplikasi menyebarkan identitas pengguna ke basis pengetahuan, dan basis pengetahuan memberlakukan kontrol akses berbasis peran atau atribut Anda. Hal ini dicapai dengan mengkonfigurasi peran layanan Basis Pengetahuan dengan prinsip hak istimewa paling sedikit dan mengendalikan akses ke peran secara ketat.
OpenSearch Serverless mendukung enkripsi sisi server dengan AWS KMS untuk melindungi data saat istirahat. Gunakan kunci yang dikelola pelanggan untuk mengenkripsi data tersebut. Untuk mengizinkan pembuatan kunci AWS KMS untuk penyimpanan data sementara dalam proses pengambilan sumber data Anda, lampirkan kebijakan ke basis pengetahuan Anda untuk peran layanan Amazon Bedrock.
Akses pribadi dapat berlaku untuk salah satu atau kedua hal berikut: Titik akhir VPC yang OpenSearch dikelola tanpa server dan layanan AWS yang didukung seperti Amazon Bedrock. Gunakan AWS PrivateLink untuk membuat koneksi pribadi antara VPC Anda dan layanan endpoint Tanpa OpenSearch Server. Gunakan aturan kebijakan jaringan untuk menentukan akses Amazon Bedrock.
Pantau OpenSearch Tanpa Server dengan menggunakan Amazon CloudWatch, yang mengumpulkan data mentah dan memprosesnya menjadi metrik yang dapat dibaca, mendekati waktu nyata. OpenSearch Serverless terintegrasi dengan AWS CloudTrail, yang menangkap panggilan API untuk Tanpa OpenSearch Server sebagai peristiwa. OpenSearch Layanan terintegrasi dengan Amazon EventBridge untuk memberi tahu Anda tentang peristiwa tertentu yang memengaruhi domain Anda. Auditor pihak ketiga dapat menilai keamanan dan kepatuhan OpenSearch Tanpa Server sebagai bagian dari beberapa program kepatuhan AWS.
Amazon S3
Simpan sumber data Anda untuk basis pengetahuan Anda dalam bucket S3. Jika Anda mengenkripsi sumber data di Amazon S3 dengan menggunakan kunci AWS KMS khusus (disarankan), lampirkan kebijakan ke peran layanan basis Pengetahuan Anda. Gunakan perlindungan malware di Amazon S3
Amazon Comprehend
Amazon Comprehend menggunakan Natural Language Processing (NLP) untuk mengekstrak wawasan dari isi dokumen. Anda dapat menggunakan Amazon Comprehend untuk mendeteksi dan menyunting entitas PII dalam dokumen teks bahasa Inggris atau Spanyol. Integrasikan Amazon Comprehend ke dalam pipeline penyerapan data Anda
Amazon S3 memungkinkan Anda mengenkripsi dokumen masukan saat membuat analisis teks, pemodelan topik, atau pekerjaan Amazon Comprehend khusus. Amazon Comprehend terintegrasi dengan AWS KMS untuk mengenkripsi data dalam volume penyimpanan untuk pekerjaan Start* dan Create*, dan mengenkripsi hasil output pekerjaan Start* dengan menggunakan kunci yang dikelola pelanggan. Kami menyarankan Anda menggunakan kunci konteks kondisi SourceAccount global aws: SourceArn dan aws: dalam kebijakan sumber daya untuk membatasi izin yang diberikan Amazon Comprehend kepada layanan lain ke sumber daya. Gunakan AWS PrivateLink untuk membuat koneksi pribadi antara VPC Anda dan layanan titik akhir Amazon Comprehend. Menerapkan kebijakan berbasis identitas untuk Amazon Comprehend dengan prinsip hak istimewa paling sedikit. Amazon Comprehend terintegrasi CloudTrail dengan AWS, yang menangkap panggilan API untuk Amazon Comprehend sebagai peristiwa. Auditor pihak ketiga dapat menilai keamanan dan kepatuhan Amazon Comprehend sebagai bagian dari beberapa program kepatuhan AWS.
Amazon Macie
Macie dapat membantu mengidentifikasi data sensitif di basis pengetahuan Anda yang disimpan sebagai sumber data, log pemanggilan model, dan penyimpanan cepat di bucket S3. Untuk praktik terbaik keamanan Macie, lihat bagian Macie sebelumnya dalam panduan ini.
AWS KMS
Gunakan kunci terkelola pelanggan untuk mengenkripsi hal-hal berikut: pekerjaan pengambilan data untuk basis pengetahuan Anda, database vektor OpenSearch Layanan Amazon, sesi di mana Anda menghasilkan respons dari kueri basis pengetahuan, log pemanggilan model di Amazon S3, dan bucket S3 yang menghosting sumber data.
Gunakan Amazon CloudWatch dan Amazon CloudTrail seperti yang dijelaskan di bagian inferensi model sebelumnya.
