本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
云中的灾难恢复选项
AWS 中可供您使用的灾难恢复策略可以大致分为四种方法,从备份的低成本和低复杂性到使用多个活动区域的更复杂的策略。 Active/passive 策略使用活动站点(例如 AWS 区域)来托管工作负载和提供流量。被动站点(例如不同的 AWS 区域)用于恢复。在触发故障转移事件之前,被动站点不会主动提供流量。
定期评估和测试您的灾难恢复策略至关重要,这样您就有信心在必要时调用该策略。使用 AWS Resilience Hub
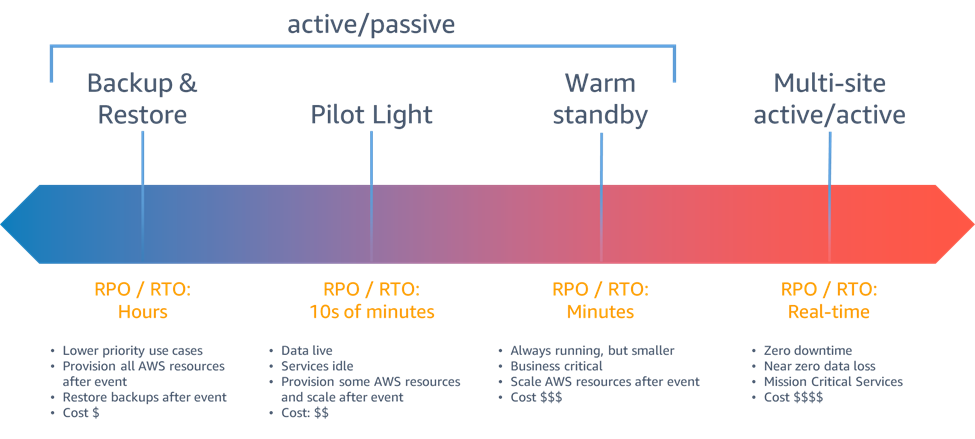
图 6-灾难恢复策略
对于因一个物理数据中心中断或丢失而导致架构良好、高度可用的工作负载而
在选择策略以及实施策略的 AWS 资源时,请记住,在 AWS 中,我们通常将服务分为数据平面和控制平面。数据面板负责交付实时服务,控制面板则用于配置环境。为了获得最大的弹性,您应仅使用数据平面操作作为故障转移操作的一部分。这是因为数据平面通常比控制平面具有更高的可用性设计目标。
备份与还原
Backup and Restore 是缓解数据丢失或损坏的合适方法。这种方法还可用于通过将数据复制到其他 AWS 区域来缓解区域灾难,或者缓解部署到单个可用区的工作负载的冗余不足。除数据外,您还必须在恢复区域中重新部署基础架构、配置和应用程序代码。为了能够在没有错误的情况下快速重新部署基础架构,您应始终使用基础设施即代码 (IaC) 进行部署,并使用诸如AWS CloudFormation
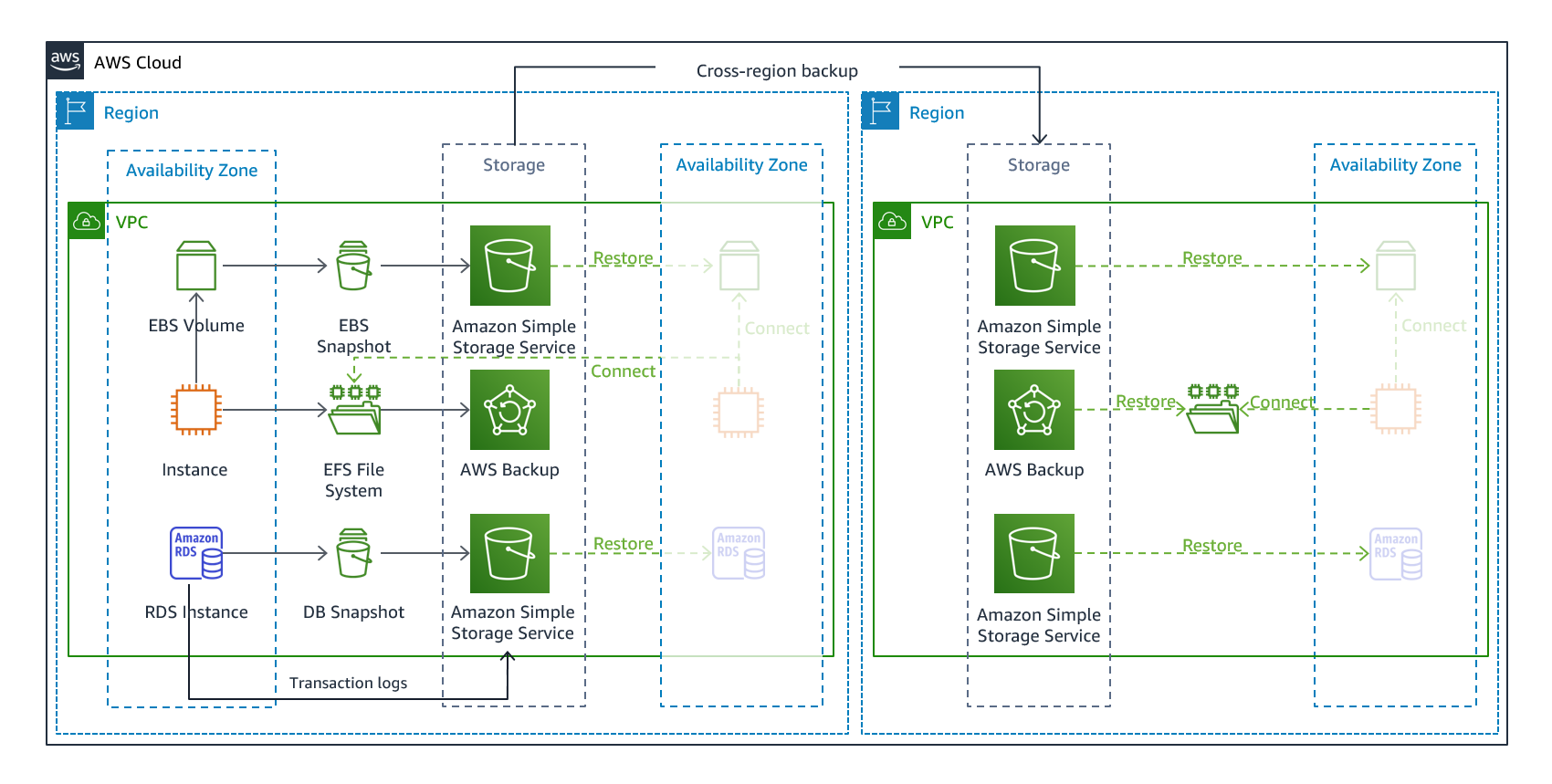
图 7-Backup 和恢复架构
Amazon Web Services
您的工作负载数据需要定期运行或连续运行的备份策略。您运行备份的频率将决定您可实现的恢复点(恢复点应与您的 RPO 保持一致)。备份还应提供一种将其恢复到拍摄时间点的方法。Backup point-in-time with Recovery 可通过以下服务和资源获得:
对于亚马逊简单存储服务 (Amazon S3) Simple Service,您可以使用 Amazon S3 跨区域复制 (CRR
AWS Backup
AWS Backup 支持跨区域复制备份,例如复制到灾难恢复区域。
作为针对您的 Amazon S3 数据的其他灾难恢复策略,请启用 S3 对象版本控制。对象版本控制通过在执行删除或修改操作之前保留原始版本,从而保护您在 S3 中的数据免受删除或修改操作的影响。对象版本控制可以有效缓解人为错误类型的灾难。如果您使用 S3 复制将数据备份到灾难恢复区域,则默认情况下,当删除源存储桶中的对象时,Amazon S3 仅在源存储桶中添加删除标记。这种方法可以保护灾难恢复区域中的数据免遭源区域的恶意删除。
除数据外,您还必须备份必要的配置和基础架构,以重新部署工作负载并满足恢复时间目标 (RTO)。 AWS CloudFormation
作为备份存储在灾难恢复区域中的任何数据都必须在故障转移时恢复。 AWS Backup 提供恢复功能,但目前不支持定时或自动恢复。您可以使用 AWS 软件开发工具包实现灾难恢复区域 APIs 的自动恢复 AWS Backup。您可以将其设置为定期重复的任务,也可以在备份完成时触发恢复。下图显示了使用亚马逊简单通知服务 (Amazon SNS) 进行自动恢复的示例,以及
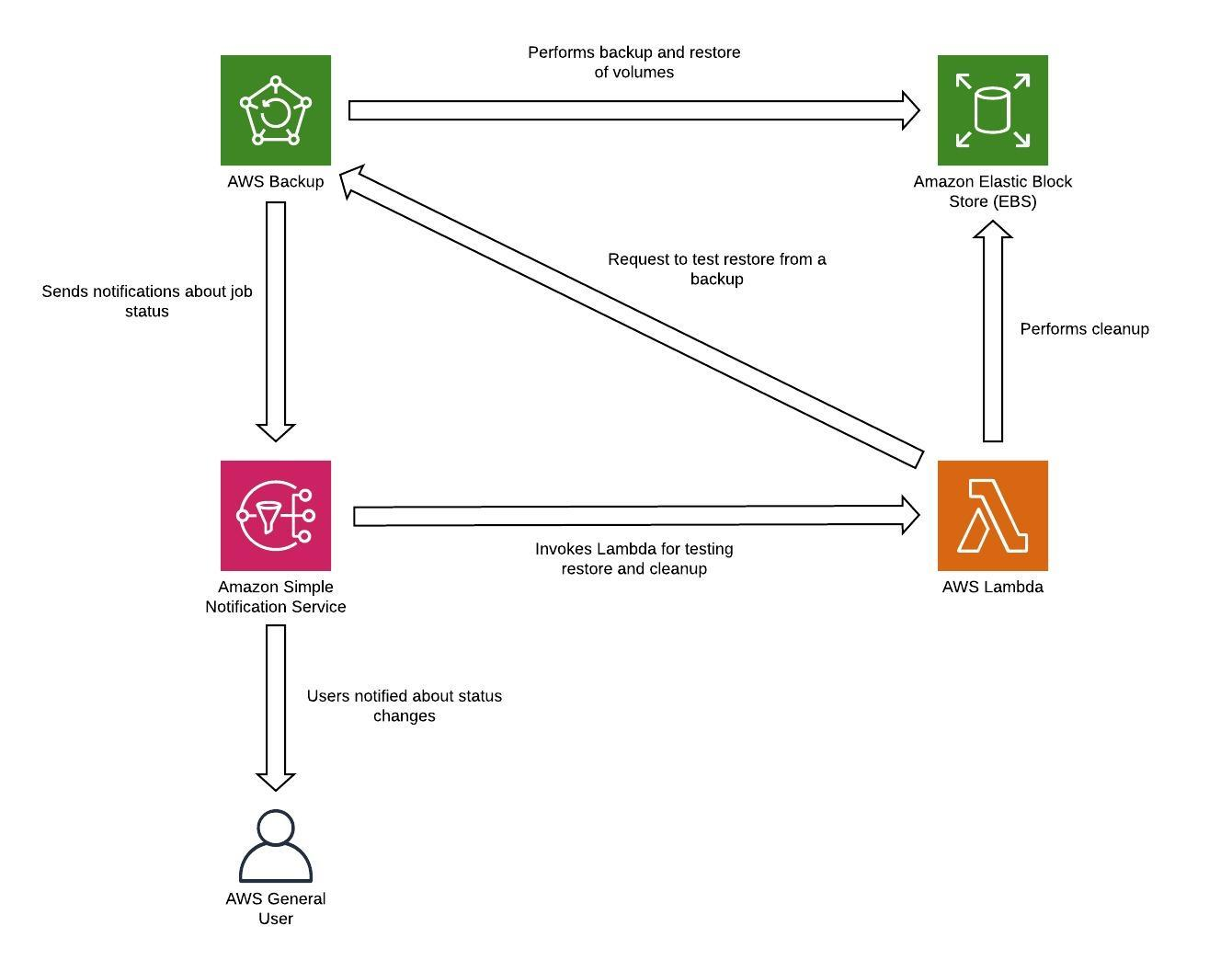
图 8-恢复和测试备份
注意
您的备份策略必须包括测试备份。有关更多信息,请参阅 “测试灾难恢复” 部分。有关实施的实际演示,请参阅 AWS Well-Architected 实验室:测试数据的备份和恢复
指示灯
使用试点方法,您可以将数据从一个区域复制到另一个区域,并配置核心工作负载基础设施的副本。支持数据复制和备份所需的资源(如数据库和对象存储)始终处于启用状态。其他元素(例如应用程序服务器)加载了应用程序代码和配置,但是 “已关闭”,仅在测试期间或调用灾难恢复故障转移时使用。在云中,您可以灵活地在不需要资源时取消配置资源,并在需要时对其进行配置。“关闭” 的最佳做法是不部署资源,然后创建配置和功能以在需要时进行部署(“开启”)。与备份和恢复方法不同,您的核心基础架构始终可用,并且您始终可以选择通过打开和扩展应用程序服务器来快速配置全面的生产环境。
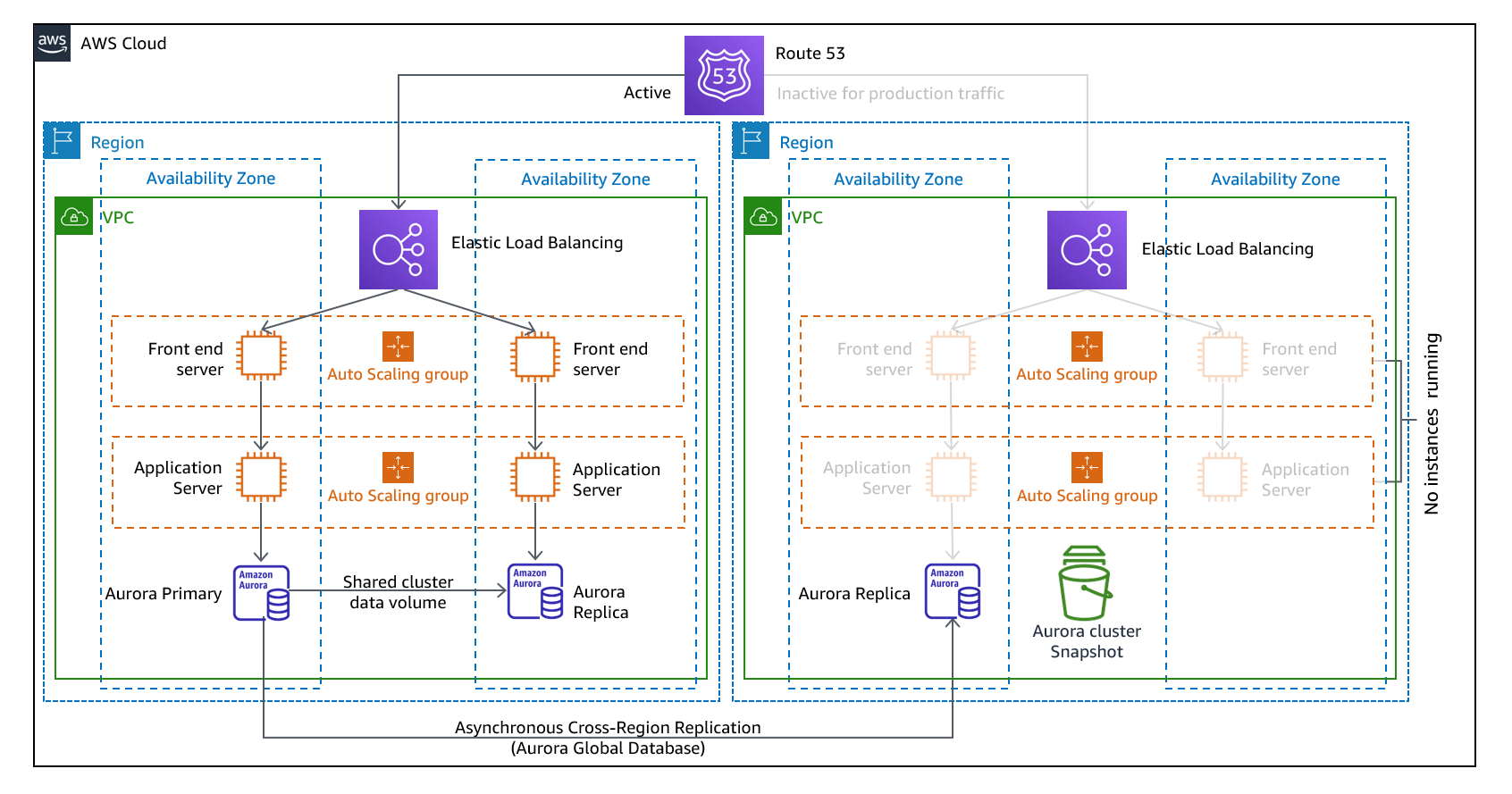
图 9-指示灯架构
指示灯方法通过最大限度地减少活跃资源来最大限度地降低灾难恢复的持续成本,并且由于核心基础设施要求都已到位,因此可以简化灾难发生时的恢复。此恢复选项要求您更改部署方法。您需要对每个区域进行核心基础设施更改,并将工作负载(配置、代码)更改同时部署到每个区域。通过自动化部署并使用基础设施即代码 (IaC) 跨多个账户和地区部署基础架构(将基础设施全面部署到主区域,缩小/关闭基础设施部署到灾难恢复区域),可以简化此步骤。建议您在每个区域使用不同的账户,以提供最高级别的资源和安全隔离(在这种情况下,您的灾难恢复计划中也会包含泄露的凭证)。
使用这种方法,您还必须缓解数据灾难。连续数据复制可以保护您免受某些类型的灾难的侵害,但除非您的策略还包括存储数据的版本控制或 point-in-time恢复选项,否则它可能无法保护您免受数据损坏或破坏的影响。您可以备份灾难区域中复制的数据,以便在同一区域中创建 point-in-time备份。
Amazon Web Services
除了使用 Backup and Re store 部分中介绍的 AWS 服务来创建 point-in-time备份外,还要考虑将以下服务作为试点策略。
首先,将数据连续复制到灾难恢复区域中的实时数据库和数据存储是实现低 RPO 的最佳方法(除了前面讨论的 point-in-time备份之外还使用时)。AWS 使用以下服务和资源为数据提供持续、跨区域、异步的数据复制:
通过连续复制,您的数据版本几乎可以立即在灾难恢复区域中使用。可以使用 S3 对象的 S3 复制时间控制 (S3 RTC) 和 Amazon A urora 全球数据库的管理功能等服务功能来监控实际的复制时间。
在故障转移以从灾难恢复区域运行 read/write 工作负载时,必须将 RDS 只读副本提升为主实例。对于 Aurora 以外的数据库实例,该过程需要几分钟才能完成,重启是该过程的一部分。对于跨区域复制 (CRR) 和使用 RDS 进行故障转移,使用 Amazon Aurora 全球数据库具有多种优势。全球数据库使用专用的基础设施,使您的数据库完全可用于您的应用程序,并且可以复制到辅助区域,延迟通常不到一秒(AWS 区域内的延迟远小于 100 毫秒)。借助 Amazon Aurora 全球数据库,如果您的主要区域出现性能下降或中断,即使在区域完全中断的情况下,您也可以在不到一分钟的时间内将其中一个次要区域提升为承担读/写责任。您还可以将 Aurora 配置为监控所有辅助集群的 RPO 延迟时间,以确保至少有一个辅助集群保持在目标 RPO 窗口内。
必须在灾难恢复区域中部署资源较少或更少的核心工作负载基础架构的缩小版本。使用 AWS CloudFormation,您可以定义您的基础设施,并将其一致地部署在 AWS 账户和 AWS 区域中。 AWS CloudFormation 使用预定义的虚拟参数来识别 AWS 账户及其部署的 AWS 区域。因此,您可以在 CloudFormation 模板中实现条件逻辑,以便在灾难恢复区域中仅部署缩小版本的基础架构。 EC2 例如部署,Amazon 系统映像 (AMI) 提供诸如硬件配置和已安装软件之类的信息。您可以实施一个 Image Builder 管道来创建所需的内容,然后将其复制到您的主区域和备份区域。 AMIs 这有助于确保这些黄金 AMIs拥有在发生灾难事件时在新区域重新部署或扩展工作负载所需的一切。Amazon EC2 实例以缩小配置进行部署(实例数少于您的主区域中的实例)。要扩展基础设施以支持生产流量,请参阅 “热待机” 部分中的 A mazon A EC2 uto Scaling
对于诸如指示灯之类的 active/passive 配置,所有流量最初都会流向主区域,如果主区域不再可用,则切换到灾难恢复区域。此失效转移操作可以自动或手动启动。应谨慎使用基于运行状况检查或警报自动启动的故障转移。即使使用此处讨论的最佳实践,恢复时间和恢复点也将大于零,从而导致一些可用性和数据丢失。如果你在不需要的时候进行故障转移(误报),那么你就会蒙受这些损失。因此,通常会使用手动启动的失效转移。在这种情况下,您仍然应该自动执行失效转移步骤,这样手动启动就像按一下按钮一样简单。
使用 AWS 服务时,需要考虑多种流量管理选项。
一个选项是使用 Amazon Route 53
另一种选择是使用AWS Global Accelerator
Amazon CloudFront
AWS 弹性灾难恢复
AWS Elastic Daser Recovery (DRS) AWS 使用底层服务器的块级复
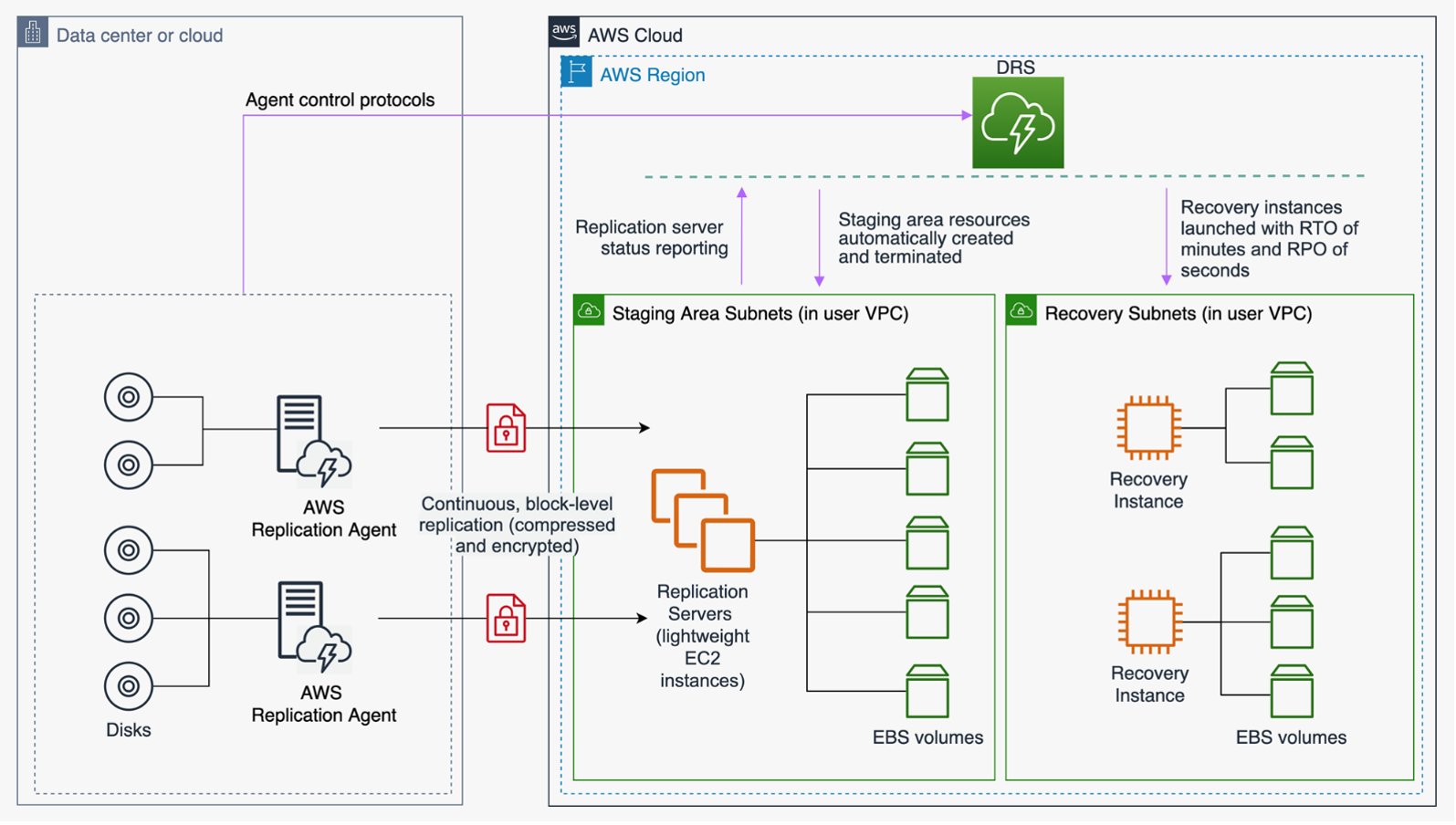
图 10- AWS 弹性灾难恢复架构
温备用
温备用方法涉及到确保在另一个区域中存在生产环境的规模缩减但功能齐全的副本。这种方法扩展了指示灯概念并减少了恢复时间,因为工作负载始终在另一个区域中运行。这种方法还允许您更轻松地执行测试或实施持续测试,从而增强您对灾难中恢复能力的信心。
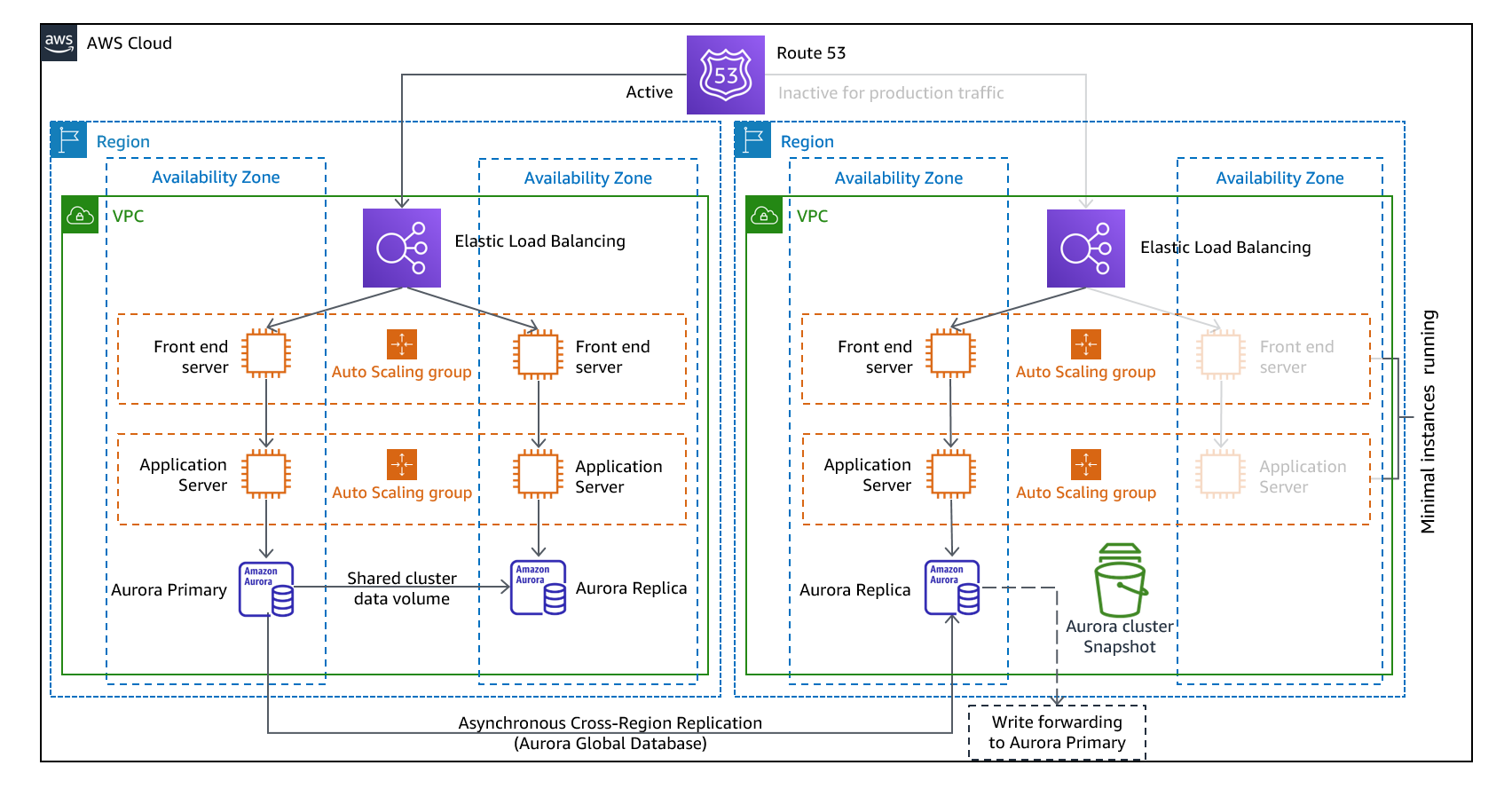
图 11-热备用架构
注意:指示灯和热待机之间的区别有时可能很难理解。两者都包含灾难恢复区域中的一个环境,其中包含您的主要区域资产的副本。区别在于,如果不先采取额外措施,指示灯就无法处理请求,而热备用模式可以立即处理流量(在降低的容量水平下)。指示灯方法要求您 “开启” 服务器,可能部署其他(非核心)基础架构,然后向上扩展,而热待机只需要您向上扩展(所有内容都已部署并正在运行)。使用您的 RTO 和 RPO 需求来帮助您在这些方法之间做出选择。
Amazon Web Services
备份和还原以及指示灯下涵盖的所有 AWS 服务也用于热备用状态,用于数据备份、数据复制、 active/passive 流量路由和基础设施(包括 EC2 实例)的部署。
Amazon A EC2 uto
由于 Auto Scaling 是一项控制平面活动,因此依赖它会降低整体恢复策略的弹性。这是一种权衡取舍。您可以选择预置足够的容量,以便恢复区域能够在部署时处理全部生产负载。这种静态稳定的配置称为热待机(参见下一节)。或者,您可以选择配置更少的资源,这样成本会更低,但要依赖于 Auto Scaling。某些 DR 实现会部署足够的资源来处理初始流量,从而确保低 RTO,然后依靠 Auto Scaling 来增加后续流量。
多站点主动/主动
作为多站点主动/主动或热备用主动/ 被动策略的一部分,您可以在多个区域同时运行工作负载。多站点 active/active 提供来自其部署到的所有区域的流量,而热备用仅为来自单个区域的流量提供服务,而其他区域仅用于灾难恢复。使用多站点 active/active 方法,用户可以在部署工作负载的任何区域访问您的工作负载。这种方法是最复杂、成本最高的灾难恢复方法,但是如果选择正确的技术和实施,它可以将大多数灾难的恢复时间缩短到接近零(但是,数据损坏可能需要依赖于备份,这通常会导致恢复点不为零)。热备用使用的 active/passive 配置仅将用户定向到单个区域,灾难恢复区域不占用流量。大多数客户发现,如果他们要在第二个区域建立完整的环境,那么主动/主动使用它是有意义的。或者,如果您不想同时使用两个区域来处理用户流量,那么 Warm Standby 提供了一种更经济、操作上不那么复杂的方法。
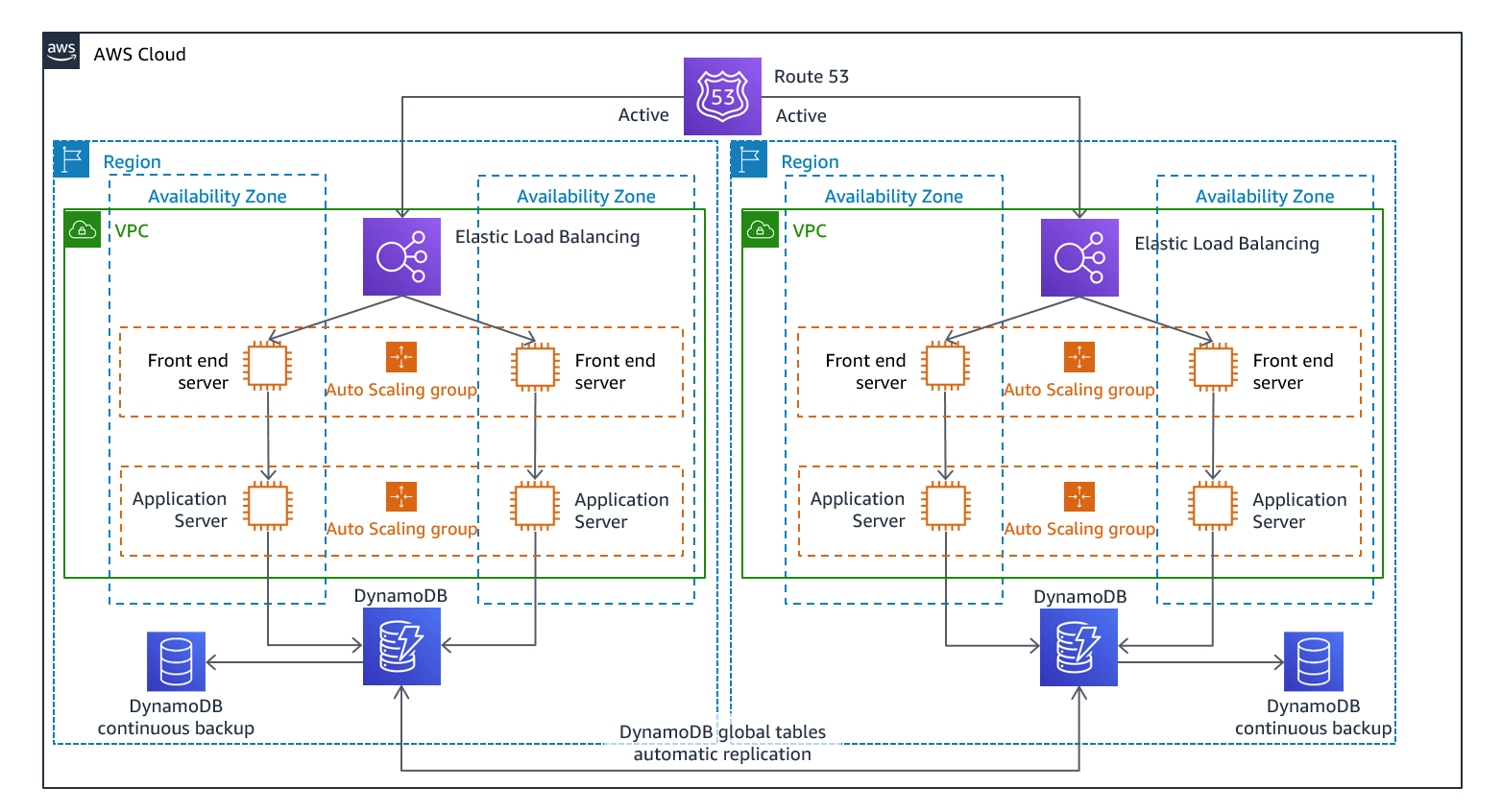
图 12-多站点 active/active 架构(对于热备用,将一条活动路径更改为 “非活动”)
由于需要采用多站点active/active, because the workload is running in more than one Region, there is no such thing as failover in this scenario. Disaster recovery testing in this case would focus on how the workload reacts to loss of a Region: Is traffic routed away from the failed Region? Can the other Region(s) handle all the traffic? Testing for a data disaster is also required. Backup and recovery are still required and should be tested regularly. It should also be noted that recovery times for a data disaster involving data corruption, deletion, or obfuscation will always be greater than zero and the recovery point will always be at some point before the disaster was discovered. If the additional complexity and cost of a multi-site active/active(或热备用)方法来保持接近零的恢复时间,因此应付出更多努力来维护安全并防止人为错误,以缓解人为灾难。
Amazon Web Services
备份和恢复、指示灯和热备用中涵盖的所有 AWS 服务也用于数据备份、 point-in-time数据复制、 active/active 流量路由以及基础设施(包括 EC2 实例)的部署和扩展。
对于前面讨论的 active/passive 场景(指示灯和热待机),Amazon Route 53 和 Amazon Route 53 都 AWS Global Accelerator 可用于将网络流量路由到活动区域。对于此处的 active/active 策略,这两项服务还允许定义政策,以确定哪些用户访问哪个活跃的区域端点。通过 AWS Global Accelerator 设置流量拨号来控制定向到每个应用程序端点的流量百分比。Amazon Route 53 支持这种百分比方法以及其他多种可用策略,包括基于地理位置和延迟的策略。Global Accelerator 会自动利用广泛的 AWS 边缘服务器网络,尽快将流量载入 AWS 网络主干,从而降低请求延迟。
使用此策略进行异步数据复制可实现接近零的 RPO。像 A mazon Aurora 全球数据库这样的 AWS 服务使用专用的基础设施,使您的数据库完全可用于您的应用程序,并且可以复制到多达五个次要区域,典型延迟不到一秒。active/passive strategies, writes occur only to the primary Region. The difference with active/active正在设计如何处理向每个活动区域写入数据时的数据一致性。通常将用户读取设计为从离他们最近的区域(称为本地读取)提供读取。对于写入,您有几种选择:
-
写入全局策略将所有写入路由到单个区域。如果该区域失败,则另一个区域将被提升为接受写入。Aurora 全球数据库非常适合全局写入,因为它支持跨区域的只读副本同步,而且您可以在不到一分钟的时间内将其中一个辅助区域提升为承担 read/write 责任。Aurora 还支持写入转发,它允许 Aurora 全局数据库中的辅助集群将执行写入操作的 SQL 语句转发到主集群。
-
写入本地策略路由写入最近的区域(就像读取一样)。Amazon DynamoDB 全局表支持这样的策略,允许从您的全局表部署到的每个区域进行读取和写入。Amazon DynamoDB 全局表使用最后一个写入器赢得并发更新之间的协调。
-
写入分区策略根据分区键(如用户 ID)将写入分配给特定区域,以避免写入冲突。在这种情况下,可以使用双向配置
的 Amazon S3 复制,并且目前支持在两个区域之间进行复制。实现此方法时,请确保在存储桶 A 和 B 上启用副本修改同步,以复制副本元数据更改,例如对象访问控制列表 (ACLs)、对象标签或复制对象上的对象锁。您还可以配置是否在活动区域的存储桶之间复制删除标记。除了复制之外,您的策略还必须包括 point-in-time备份,以防止数据损坏或破坏事件。
AWS CloudFormation 是一款强大的工具,用于在多个 AWS 区域的 AWS 账户之间强制部署一致的基础设施。 AWS CloudFormation StackSets扩展了此功能,使您能够通过一次操作在多个账户和地区创建、更新或删除 CloudFormation 堆栈。尽管 AWS CloudFormation 使用 YAML 或 JSON 将基础设施定义为代码,但AWS Cloud Development Kit (AWS CDK)
