Was ist Amazon S3?
Amazon Simple Storage Service (Amazon S3) ist ein Objektspeicherservice, der branchenführende Skalierbarkeit, Datenverfügbarkeit, Sicherheit und Leistung bietet. Kunden aller Größen und Branchen können Amazon S3 für die Speicherung und den Schutz beliebiger Datenmengen für eine Reihe von Anwendungsfällen verwenden, wie Data Lakes, Websites, mobile Anwendungen, Backup und Wiederherstellung, Archivierung, Unternehmensanwendungen, IoT-Geräte und Big-Data-Analysen. Amazon S3 bietet Verwaltungsfunktionen, mit denen Sie den Zugriff auf Ihre Daten optimieren, organisieren und konfigurieren können, um Ihre spezifischen geschäftlichen, organisatorischen und Compliance-Anforderungen zu erfüllen.
Anmerkung
Weitere Informationen zur Verwendung der Speicherklasse Amazon S3 Express One Zone mit Verzeichnis-Buckets finden Sie unter S3 Express One Zone und Arbeiten mit Verzeichnis-Buckets.
Themen
Funktionen von Amazon S3
Speicherklassen
Amazon S3 bietet eine Vielzahl von Speicherklassen an, die für diverse Anwendungsfälle genutzt werden können. So können Sie beispielsweise missionskritische Produktionsdaten in S3 Standard für häufigen Zugriff speichern, Kosten sparen, indem Sie selten aufgerufene Daten in S3 Standard-IA speichern und Daten zu den niedrigsten Kosten in S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval und S3 Glacier Deep Archive archivieren.
Amazon S3 Express One Zone ist eine leistungsstarke Amazon-S3-Speicherklasse mit einer einzelnen Zone, die speziell für den konsistenten Datenzugriff im einstelligen Millisekundenbereich für Ihre latenzempfindlichsten Anwendungen entwickelt wurde. S3 Express One Zone ist die derzeit verfügbare Cloud-Objektspeicherklasse mit der niedrigsten Latenz. Sie bietet bis zu zehnmal höhere Datenzugriffsgeschwindigkeiten und um 50 % niedrigere Anforderungskosten als S3 Standard. S3 Express One Zone ist die erste S3-Speicherklasse, bei der Sie eine einzelne Availability Zone mit der Option auswählen können, Ihren Objektspeicher gemeinsam mit Ihren Computingressourcen zu platzieren, was die höchstmögliche Zugriffsgeschwindigkeit bietet. Um die Zugriffsgeschwindigkeit weiter zu erhöhen und Hunderttausende von Anfragen pro Sekunde zu unterstützen, werden Daten außerdem in einem neuen Bucket-Typ gespeichert: einem Amazon-S3-Verzeichnis-Bucket. Weitere Informationen erhalten Sie unter S3 Express One Zone und Arbeiten mit Verzeichnis-Buckets.
Sie können Daten mit sich ändernden oder unbekannten Zugriffsmustern in S3 Intelligent-Tiering speichern, das die Speicherkosten optimiert, indem es Ihre Daten automatisch zwischen vier Zugriffsebenen verschiebt, wenn sich Ihre Zugriffsmuster ändern. Diese vier Zugriffsebenen umfassen zwei Zugriffsebenen mit geringer Latenz, die für häufigen und seltenen Zugriff optimiert sind, und zwei Opt-in-Archivzugriffsebenen, die für den asynchronen Zugriff auf selten abgerufene Daten ausgelegt sind.
Weitere Informationen finden Sie unter Verstehen und Verwalten von Amazon-S3-Speicherklassen.
Speicherverwaltung
Amazon S3 hat Speicherverwaltungsfunktionen, die Sie benutzen können, um Kosten zu verwalten, gesetzliche Anforderungen zu erfüllen, Latenz zu reduzieren und mehrere verschiedene Kopien Ihrer Daten für Compliance-Anforderungen zu speichern.
-
S3-Lebenszyklus – Richten Sie eine Lebenszykluskonfiguration ein, um Ihre Objekte zu verwalten und während ihres gesamten Lebenszyklus kostengünstig zu speichern. Sie können Objekte in andere S3-Speicherklassen umstellen oder Objekte ablaufen, die das Ende ihrer Lebensdauer erreichen.
-
S3-Objektsperre – Verhindern Sie, dass Amazon S3-Objekte für einen bestimmten Zeitraum oder auf unbestimmte Zeit gelöscht oder überschrieben werden. Sie können die Objektsperre verwenden, um regulatorische Anforderungen einzuhalten, die die write-once-read-many (WORM)-Speicherung verlangen, oder um eine zusätzliche Schutzebene gegen Objektänderungen und -löschungen einzurichten.
-
S3-Replikation – Replizieren von Objekten und deren jeweiligen Metadaten und Objekt-Tags auf einen oder mehrere Ziel-Buckets im gleichen oder anderen AWS-Regionen für reduzierte Latenz, Compliance, Sicherheit und andere Anwendungsfälle.
-
S3-Batch-Vorgänge – Verwalten Sie Milliarden von Objekten skalierbar mit einer einzigen S3-API-Anforderung oder ein paar Klicks in der Amazon-S3-Konsole. Sie können Batch-Vorgänge verwenden, um Vorgänge wie Kopieren, AWS-Lambda-Funktion aufrufen, und Wiederherstellen auf Millionen oder Milliarden von Objekten auszuführen.
Zugriffsverwaltung und Sicherheit
Amazon S3 bietet Funktionen für die Überwachung und Verwaltung des Zugriffs auf Ihre Buckets und Objekte. Standardmäßig werden S3-Buckets und -Objekte als privat eingestuft. Sie haben nur Zugriff auf die S3-Ressourcen, die Sie erstellen. Um detaillierte Ressourcenberechtigungen zu erteilen, die Ihren speziellen Anwendungsfall unterstützen, oder um die Berechtigungen Ihrer Amazon S3-Ressourcen zu überprüfen, können Sie die folgenden Funktionen verwenden.
-
S3 öffentlichen Zugriff blockieren – Blockieren Sie den öffentlichen Zugriff auf S3-Buckets und -Objekte. Standardmäßig sind die Einstellungen für das Blockieren des öffentlichen Zugriffs auf Bucket-Ebene aktiviert. Es wird empfohlen, alle Einstellungen für das Blockieren des öffentlichen Zugriffs aktiviert zu lassen, es sei denn, Sie wissen, dass Sie eine oder mehrere dieser Einstellungen für Ihren Anwendungsfall deaktivieren müssen. Weitere Informationen finden Sie unter Konfigurieren von Block-Public-Access-Einstellungen für Ihre S3-Buckets.
-
AWS Identity and Access Management(IAM) – IAM ist ein Webservice, der Ihnen hilft, den Zugriff auf AWS-Ressourcen zu steuern, einschließlich Ihrer Amazon-S3-Ressourcen. Mit IAM können Sie Berechtigungen, die festlegen, auf welche AWS-Ressourcen Benutzer zugreifen dürfen, zentral verwalten. Sie verwenden IAM, um zu steuern, wer authentifiziert (angemeldet) und autorisiert (Berechtigungen besitzt) ist, Ressourcen zu nutzen.
-
Bucket-Richtlinien – Verwenden Sie die IAM-basierte Richtliniensprache, um ressourcenbasierte Berechtigungen für Ihre S3-Buckets und die darin enthaltenen Objekte zu konfigurieren.
-
Amazon-S3-Zugriffspunkte – Konfigurieren Sie benannte Netzwerkendpunkte mit dedizierten Zugriffsrichtlinien, um den Datenzugriff auf freigegebene Datensätze in Amazon S3 skalierbar zu verwalten.
-
Zugriffskontrolllisten (ACLs) – Erteilen Sie autorisierten Benutzern Lese- und Schreibberechtigungen für einzelne Buckets und Objekte. Als allgemeine Regel sollten Sie S3-ressourcenbasierte Richtlinien (Bucket-Richtlinien und Zugriffspunkt-Richtlinien) oder IAM-Benutzerrichtlinien für die Zugriffssteuerung anstelle von ACLs verwenden. Richtlinien stellen eine vereinfachte und flexiblere Zugriffskontrolloption dar. Mit Bucket- und Zugriffspunktrichtlinien können Sie Regeln definieren, die allgemein für alle Anfragen an Ihre Amazon-S3-Ressourcen gelten. Weitere Informationen dazu, wann Sie ACLs anstelle von ressourcenbasierten Richtlinien oder IAM-Benutzerrichtlinien verwenden, finden Sie unter Zugriffsverwaltung mit ACLs.
-
S3 Object Ownership – Übernehmen Sie die Verantwortung für jedes Objekt in Ihrem Bucket, wodurch die Zugriffsverwaltung für in Amazon S3 gespeicherte Daten vereinfacht wird. S3 Object Ownership ist eine Amazon-S3-Einstellung auf Bucket-Ebene, mit der Sie ACLs deaktivieren oder aktivieren können. Standardmäßig sind ACLs deaktiviert. Wenn ACLs deaktiviert sind, besitzt der Bucket-Eigentümer alle Objekte im Bucket und verwaltet den Datenzugriff ausschließlich mithilfe von Zugriffsverwaltungsrichtlinien.
-
IAM-Zugriffs-Analyzer für S3 – Bewerten und überwachen Sie Ihre S3-Bucket-Zugriffsrichtlinien, um sicherzustellen, dass die Richtlinien nur den beabsichtigten Zugriff auf Ihre S3-Ressourcen zulassen.
Datenverarbeitung
Um Daten zu transformieren und Workflows auszulösen, um eine Vielzahl anderer Verarbeitungsaktivitäten maßstabsgerecht zu automatisieren, können Sie die folgenden Funktionen verwenden.
-
S3 Object Lambda – Fügen Sie S3-Anforderungen GET, HEAD und LIST Ihren eigenen Code hinzu, um Daten zu ändern und zu verarbeiten, wenn sie an eine Anwendung zurückgegeben werden. Filtern Sie Zeilen, ändern Sie die Größe von Bildern dynamisch, verkleinern Sie vertrauliche Daten und vieles mehr.
-
Ereignisbenachrichtigungen – Lösen Sie Workflows aus, die Amazon Simple Notification Service (Amazon SNS), Amazon Simple Queue Service (Amazon SQS) verwenden und AWS Lambda, wenn eine Änderung an Ihren S3-Ressourcen vorgenommen wird.
Speicherprotokollierung und Überwachung
Amazon S3 bietet Protokollierungs- und Überwachungstools, mit denen Sie überwachen und steuern können, wie Ihre Amazon S3-Ressourcen verwendet werden. Weitere Informationen finden Sie unter Überwachungstools.
Automatisierte Überwachungstools
-
Amazon-CloudWatch-Metriken für Amazon S3 – Verfolgen Sie den Betriebszustand Ihrer S3-Ressourcen und konfigurieren Sie Gebührenlimit-Warnungen, wenn geschätzte Gebühren einen benutzerdefinierten Schwellenwert erreichen.
-
AWS CloudTrail – Zeichnen Sie Aktionen auf, die von einem Benutzer, einer Rolle oder einem AWS-Service in Amazon S3 durchgeführt werden. CloudTrail-Protokolle bieten Ihnen detailliertes API-Tracking für Vorgänge auf S3-Bucket- und -Objektebene.
Manuelle Überwachungstools
-
Server-Zugriffsprotokollierung – Abrufen detaillierter Datensätze für die Anforderungen, die an einen Bucket gestellt werden. Sie können Serverzugriffsprotokolle für viele Anwendungsfälle verwenden, z. B. für die Durchführung von Sicherheits- und Zugriffsprüfungen, das Kennenlernen Ihres Kundenstamms und das Verstehen Ihrer Amazon S3-Rechnung.
-
AWS Trusted Advisor – Bewerten Sie Ihr Konto mithilfe von AWS bewährte Methoden-Prüfungen, um Möglichkeiten zur Optimierung Ihrer AWS-Infrastruktur, Verbesserung der Sicherheit und Leistung, Senkung der Kosten und Überwachung von Service-Quoten zu identifizieren. Sie können dann die Empfehlungen befolgen, um Ihre Dienste und Ressourcen zu optimieren.
Analytik und Einblicke
Amazon S3 bietet Funktionen, die Ihnen dabei helfen, Einblicke in Ihre Speicherauslastung zu erhalten, sodass Sie Ihren Speicher in großem Umfang besser verstehen, analysieren und optimieren können.
-
Amazon S3 Storage Lens – Verstehen, analysieren und optimieren Sie Ihren Speicher. S3 Storage Lens bietet mehr als 60 Nutzungs- und Aktivitätsmetriken und interaktive Dashboards, um Daten für Ihr gesamtes Unternehmen, bestimmte Konten, AWS-Regionen, Buckets oder Präfixe zu aggregieren.
-
Speicherklassenanalyse – Analysieren Sie Speicherzugriffsmuster, um zu entscheiden, wann es an der Zeit ist, Daten in eine kostengünstigere Speicherklasse zu verschieben.
-
S3-Inventory mit Bestandsberichten – Überwachen und erstellen Sie Berichte zu Objekten und den entsprechenden Metadaten und konfigurieren Sie andere Amazon S3-Funktionen, um in Inventarberichten Maßnahmen zu ergreifen. Sie können beispielsweise einen Bericht über den Replikations- und Verschlüsselungsstatus Ihrer Objekte erstellen. Eine Liste aller verfügbaren Metadaten, die für jedes Objekt in Bestandsberichten verfügbar sind, finden Sie unter Amazon S3-Bestandsliste.
Starke Konsistenz
Amazon S3 bietet eine starke Lesen-nach-Schreiben-Konsistenz für PUT- und DELETE-Anforderungen von Objekten in Ihrem Amazon S3-Bucket in allen AWS-Regionen. Dieses Verhalten gilt sowohl für Schreibvorgänge neuer Objekte als auch für PUT-Anforderungen, die vorhandene Objekte überschreiben, und DELETE-Anforderungen. Darüber hinaus sind Lesevorgänge in Amazon S3 Select, Amazon S3-Zugriffskontrolllisten (ACLs), Amazon S3-Objekt-Markierungen und Objekt-Metadaten (z. B. das HEAD-Objekt) stark konsistent. Weitere Informationen finden Sie unter Amazon S3-Datenkonsistenzmodell.
Funktionsweise von Amazon S3
Amazon S3 ist ein Objektspeicherdienst, der Daten als Objekte in Buckets speichert. Ein Objekt ist eine Datei und alle Metadaten, die diese Datei beschreiben. Ein Bucket ist ein Container für Objekte.
Um Ihre Daten in Amazon S3 zu speichern, erstellen Sie zunächst einen Bucket und geben einen Bucket-Namen und AWS-Region an. Anschließend laden Sie Ihre Daten in diesen Bucket als Objekte in Amazon S3 hoch. Jedes Objekt hat einen Schlüssel (oder Schlüsselnamen), der der eindeutige Bezeichner für das Objekt im Bucket ist.
S3 bietet Funktionen, die Sie konfigurieren können, um Ihren speziellen Anwendungsfall zu unterstützen. Beispielsweise können Sie das S3-Versioning verwenden, um mehrere Versionen eines Objekts im selben Bucket zu halten, wodurch Sie versehentlich gelöschte oder überschriebene Objekte wiederherstellen können.
Buckets und die darin enthaltenen Objekte sind privat und können nur zugegriffen werden, wenn Sie explizit Zugriffsberechtigungen erteilen. Sie können Bucket-Richtlinien,AWS Identity and Access Management-(IAM)-Richtlinien, Zugriffskontrolllisten (ACLs) und S3-Zugriffskontrolllisten für die Verwaltung des Zugriffs verwenden.
Themen
Buckets
Ein Allzweck-Bucket ist ein Container für Objekte, die in Amazon S3 gespeichert werden. Sie können beliebig viele Objekte in einem Bucket speichern. Alle Konten haben ein Standard-Bucket-Kontingent von 10 000 Allzweck-Buckets. Um Ihre Bucket-Auslastung oder Ihr Bucket-Kontingent zu prüfen oder eine Erhöhung dieses Kontingents zu beantragen, besuchen Sie die Service-Quotas-Konsole
Jedes Objekt ist in einem Bucket enthalten. Wenn beispielsweise ein Objekt mit dem Namen photos/puppy.jpg im Bucket amzn-s3-demo-bucket in der Region USA West (Oregon) gespeichert ist, ist es über die URL https://amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpg adressierbar. Weitere Informationen siehe Zugriff auf einen Bucket.
Wenn Sie einen Bucket erstellen, geben Sie einen Bucket-Namen ein und wählen die Option AWS-Region, wo sich der Bucket befindet. Nachdem Sie einen Bucket erstellt haben, können Sie den Namen des Buckets oder seiner Region nicht mehr ändern. Bucket-Namen müssen den Regeln für die Benennung von Buckets folgen. Sie können einen Bucket auch für die Verwendung des S3-Versioning oder anderer Speicherverwaltungs-Funktionen konfigurieren.
Zudem tun Buckets Folgendes:
-
Sie strukturieren den Amazon S3-Namespace auf der höchsten Ebene.
-
Sie identifizieren das Konto, dem die Gebühren für Datenspeicherung und -übertragung belastet werden.
-
Sie stellen Zugriffssteuerungsoptionen wie Bucket-Richtlinien, Zugriffssteuerungslisten (Access Control Lists, ACLs) und S3-Zugriffskontrolllisten bereit, mit denen Sie den Zugriff auf Ihre Amazon S3-Ressourcen verwalten können.
-
Sie dienen im Rahmen der Erstellung von Nutzungsberichten als Auswertungseinheit.
Weitere Informationen über Buckets finden Sie unter Bucket-Übersicht.
Objekte
Objekte sind die Grundeinheiten, die in Amazon S3 gespeichert werden. Objekte bestehen aus Objekt- und Metadaten. Metadaten bestehen aus mehreren Name/Wert-Paaren, die das Objekt beschreiben. Dazu gehören Standardmetadaten wie das Datum der letzten Aktualisierung und HTTP-Standardmetadaten wie Content-Type. Sie können bei der Speicherung des Objekts auch benutzerdefinierte Metadaten angeben.
Ein Objekt wird innerhalb eines Buckets eindeutig durch einen Schlüssel (Name) und eine Versions-ID identifiziert (wenn das S3-Versioning im Bucket aktiviert ist). Weitere Informationen über Objekte finden Sie unter Übersicht über Amazon-S3-Objekte.
Schlüssel
Ein Objektschlüssel (oder Schlüsselname) ist der eindeutige Bezeichner für ein Objekt in einem Bucket. Jedes Objekt in einem Bucket besitzt genau einen Schlüssel. Die Kombination aus Bucket, Objektschlüssel und optional Versions-ID (wenn das S3-Versioning für den Bucket aktiviert ist) identifiziert jedes Objekt eindeutig. Amazon S3 fungiert also als grundlegende Datenzuordnung zwischen „Bucket + Schlüssel + Version“ und dem Objekt selbst.
Jedes Objekt in Amazon S3 ist über eine Kombination von Webservice-Endpunkt, Bucket-Name, Schlüssel und wahlweise einer Version aufrufbar. So ist in der URL https:// amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpgamzn-s3-demo-bucketphotos/puppy.jpg der Schlüssel.
Weitere Informationen über Objektschlüssel finden Sie unter Markieren von Amazon-S3-Objekten.
S3-Versioning
Sie S3-Versioning verwenden, um mehrere Versionen eines Objekts im selben Bucket aufzubewahren. Mit S3-Versioning können Sie jede Version jedes in Ihren Buckets gespeicherten Objekts beibehalten, abrufen und wiederherstellen. Sie können sowohl nach unbeabsichtigten Benutzeraktionen als auch nach Anwendungsfehlern problemlos wiederherstellen.
Weitere Informationen finden Sie unter Beibehalten mehrerer Versionen von Objekten mit der S3-Versionsverwaltung.
Versions-ID
Wenn Sie das S3-Versioning in einem Bucket aktivieren, generiert Amazon S3 eine eindeutige Versions-ID für jedes Objekt, das dem Bucket hinzugefügt wird. Objekte, die zum Zeitpunkt der Aktivierung des Versioning bereits im Bucket vorhanden waren, haben die Versions-IDnull . Wenn Sie diese (oder andere) Objekte mit anderen Vorgängen wie CopyObject und PutObject verändern, erhalten die neuen Objekte eine eindeutige Versions-ID.
Weitere Informationen finden Sie unter Beibehalten mehrerer Versionen von Objekten mit der S3-Versionsverwaltung.
Bucket-Richtlinie
Eine Bucket-Richtlinie ist eine auf Ressourcen basierende AWS Identity and Access Management-(IAM)-Richtlinie, die Sie verwenden können, um Zugriffsberechtigungen für Ihren Bucket und die darin enthaltenen Objekte zu erteilen. Nur der Bucket-Eigentümer kann einem Bucket eine Richtlinie zuordnen. Die dem Bucket zugeordneten Berechtigungen gelten für alle Objekte im Bucket, die dem Bucket-Eigentümer gehören. Bucket-Richtlinien sind auf eine Größe von 20 KB beschränkt.
Bucket-Richtlinien verwenden JSON-basierte Sprache der Zugriffsrichtlinie, die standardmäßig in AWS ist. Sie können Bucket-Richtlinien verwenden, um Berechtigungen für die Objekte in einem Bucket hinzuzufügen oder zu verweigern. Bucket-Richtlinien erlauben oder verweigern Anforderungen basierend auf den Elementen in der Richtlinie, einschließlich des Anforderers, S3-Aktionen, Ressourcen und Aspekten oder Bedingungen der Anforderung (z. B. die IP-Adresse, die für die Anforderung verwendet wird). Sie können beispielsweise eine Bucket-Richtlinie erstellen, die kontoübergreifende Berechtigungen zum Hochladen von Objekten in einen S3-Bucket gewährt, während gleichzeitig sichergestellt wird, dass der Bucket-Eigentümer die volle Kontrolle über die hochgeladenen Objekte hat. Weitere Informationen finden Sie unter Beispiele für Amazon-S3-Bucket-Richtlinien.
In Ihrer Bucket-Richtlinie können Sie Platzhalterzeichen für Amazon-Ressourcennamen (ARNs) und andere Werte verwenden, um Berechtigungen für eine Teilmenge von Objekten zu erteilen. Sie können beispielsweise den Zugriff auf Gruppen von Objekten steuern, die mit einem gemeinsamen Präfixbeginnen oder mit einer bestimmten Erweiterung wie .html enden.
S3-Zugriffspunkte
Amazon S3-Zugriffspunkte sind benannte Netzwerkendpunkte mit dedizierten Zugriffsrichtlinien, die beschreiben, wie mit diesem Endpunkt auf Daten zugegriffen werden kann. Zugriffspunkte sind Buckets zugeordnet, mit denen Sie S3-Objektvorgänge ausführen können, z. B. GetObject und PutObject. Zugriffspunkte vereinfachen die skalierbare Verwaltung des Datenzugriffs auf freigegebene Datensätze in Amazon S3.
Jeder Zugriffspunkt verfügt über eine eigene Zugriffspunktrichtlinie. Sie können Block Public Access-Einstellungen für jeden Zugriffspunkt konfigurieren. Um den Amazon S3-Datenzugriff auf ein privates Netzwerk zu beschränken, können Sie auch jeden Zugriffspunkt so konfigurieren, dass Anforderungen nur von einer Virtual Private Cloud (VPC) akzeptiert werden.
Weitere Informationen finden Sie unter Verwalten des Zugriffs auf gemeinsam genutzte Datensätze mit Zugangspunkten.
Zugriffssteuerungslisten (ACLs)
Sie können ACLs verwenden, um autorisierten Benutzern Lese- und Schreibberechtigungen für einzelne Buckets und Objekte zu erteilen. Jedem Bucket und jedem Objekt ist eine ACL als Subressource zugeordnet. Die ACL definiert, welche AWS-Konten oder -Gruppen Zugriff erhalten, und den Zugriffstyp. ACLs sind ein Zugriffssteuerungsmechanismus, der IAM vorausgeht. Weitere Informationen über ACLs finden Sie in Zugriffskontrolllisten (ACL) – Übersicht.
S3 Object Ownership ist eine Amazon-S3-Einstellung auf Bucket-Ebene, mit der Sie sowohl die Eigentümerschaft von den Objekten steuern können, die in Ihre Buckets hochgeladen werden, als auch ACLs deaktivieren oder aktivieren können. Standardmäßig ist die Objekteigentümerschaft auf die Einstellung „Vom Bucket-Eigentümer erzwungen“ festgelegt und alle ACLs sind deaktiviert. Wenn ACLs deaktiviert sind, besitzt der Bucket-Eigentümer alle Objekte im Bucket und verwaltet den Zugriff darauf ausschließlich mithilfe von Zugriffsverwaltungsrichtlinien.
Die meisten modernen Anwendungsfälle in Amazon S3 erfordern keine ACLs mehr. Wir empfehlen Ihnen, ACLs deaktiviert zu lassen, außer unter ungewöhnlichen Umständen, in denen Sie den Zugriff für jedes Objekt einzeln steuern müssen. Wenn ACLs deaktiviert sind, können Sie mithilfe von Richtlinien den Zugriff auf alle Objekte in Ihrem Bucket steuern, unabhängig davon, wer die Objekte in Ihren Bucket hochgeladen hat. Weitere Informationen finden Sie unter Weitere Informationen finden Sie unter Steuern des Eigentums an Objekten und Deaktivieren von ACLs für Ihren Bucket..
Regionen
Sie können auswählen, in welcher geografischen AWS-Region Amazon S3 die erstellten Buckets speichern soll. Sie sollten eine Region im Hinblick auf Latenz, Kosten sowie Einhaltung der relevanten Vorschriften auswählen. In einer AWS-Region gespeicherte Objekte verbleiben in der Region, bis sie explizit in eine andere Region verschoben oder repliziert werden. In der Region EU (Irland) gespeicherte Objekte verlassen diese Region nicht.
Anmerkung
Sie können auf Amazon S3 und die zugehörigen Funktionen in AWS-Regionen zugreifen, die für das Konto aktiviert sind. Weitere Informationen darüber, wie eine Region für die Erstellung und Verwaltung von AWS-Ressourcen aktiviert wird, finden Sie unter Verwalten von AWS-Regionen in der Allgemeine AWS-Referenz.
Eine Liste der Amazon-S3-Regionen und -Endpunkte finden Sie unter Regionen und Endpunkte in der Allgemeine AWS-Referenz.
Amazon S3-Datenkonsistenzmodell
Amazon S3 bietet eine starke Lesen-nach-Schreiben-Konsistenz für PUT- und DELETE-Anforderungen von Objekten in Ihrem Amazon S3-Bucket in allen AWS-Regionen. Dieses Verhalten gilt sowohl für Schreibvorgänge neuer Objekte als auch für PUT-Anforderungen, die vorhandene Objekte überschreiben, und DELETE-Anforderungen. Darüber hinaus sind Lesevorgänge in Amazon S3 Select, Amazon S3-Zugriffskontrolllisten (ACLs), Amazon S3-Objekt-Markierungen und Objekt-Metadaten (z. B. das HEAD-Objekt) stark konsistent.
Aktualisierungen an einem einzelnen Schlüssel sind unteilbar. Wenn Sie beispielsweise eine PUT-Anforderung aus einem Thread für einen vorhandenen Schlüssel ausführen und gleichzeitig eine GET-Anforderung für denselben Schlüssel aus einem zweiten Thread ausführen, erhalten Sie entweder die alten Daten oder die neuen Daten, aber niemals teilweise neue bzw. alte oder beschädigte Daten.
Amazon S3 erzielt hohe Verfügbarkeit, indem die Daten innerhalb der AWS-Rechenzentren über mehrere Server repliziert werden. Wenn eine PUT-Anfrage erfolgreich ist, sind die Daten sicher gespeichert. Jeder Lesevorgang (GET- oder LIST-Anforderung), der nach Eingang einer erfolgreichen PUT-Antwort eingeleitet wird, gibt die von der PUT-Anforderung geschriebenen Daten zurück. Hier finden Sie Beispiele für dieses Verhalten:
-
Ein Prozess schreibt ein neues Objekt in Amazon S3 und listet sofort Schlüssel innerhalb seines Buckets auf. Das neue Objekt wird in der Liste angezeigt.
-
Ein Prozess ersetzt ein vorhandenes Objekt und versucht sofort, es zu lesen. Amazon S3 gibt die neuen Daten zurück.
-
Ein Prozess löscht ein vorhandenes Objekt und versucht sofort, es zu lesen. Amazon S3 gibt keine Daten zurück, da das Objekt gelöscht wurde.
-
Ein Prozess löscht ein vorhandenes Objekt und listet sofort Schlüssel innerhalb seines Buckets auf. Das Objekt wird nicht im Verzeichnis angezeigt.
Anmerkung
-
Amazon S3 unterstützt keine Objektsperre für gleichzeitige Schreibvorgänge. Wenn gleichzeitig zwei PUT-Anforderungen für denselben Schlüssel eingehen, hat die Anforderung mit dem ältesten Zeitstempel Priorität. Wenn das ein Problem ist, müssen Sie in Ihre Anwendung einen Sperrmechanismus für Objekte einbauen.
-
Updates basieren auf Schlüsseln. Es gibt keine Möglichkeit für unteilbare Aktualisierungen über Schlüssel hinweg. Sie können beispielsweise die Aktualisierung eines Schlüssels nicht von der Aktualisierung eines anderen Schlüssels abhängig machen. Dazu müssten Sie diese Funktionalität in Ihrer Anwendung implementieren.
Bucket-Konfigurationen haben ein Modell mit letztendlicher Datenkonsistenz. Dies bedeutet insbesondere, dass:
-
Wenn Sie einen Bucket löschen und sofort alle Buckets auflisten, wird der gelöschte Bucket möglicherweise weiterhin in der Liste angezeigt.
-
Wenn Sie das Versioning für einen Bucket zum ersten Mal aktivieren, kann es einen Moment dauern, bis die Änderung vollständig verbreitet ist. Wir empfehlen, dass Sie nach dem Aktivieren des Versioning 15 Minuten warten, bevor Sie Schreibvorgänge (PUT oder DELETE-Anforderungen) für Objekte im Bucket ausführen.
Gleichzeitige Anwendungen
Dieser Abschnitt enthält Beispiele für das zu erwartende Verhalten von Amazon S3, wenn mehrere Kunden in dieselben Elemente schreiben.
In diesem Beispiel werden W1 (Lesen 1) und W2 (Lesen 2) abgeschlossen, bevor R1 (Lesen 1) und R2 (Lesen 2) starten. Da S3 stark konsistent ist, geben R1 und R2 beide color = ruby zurück.
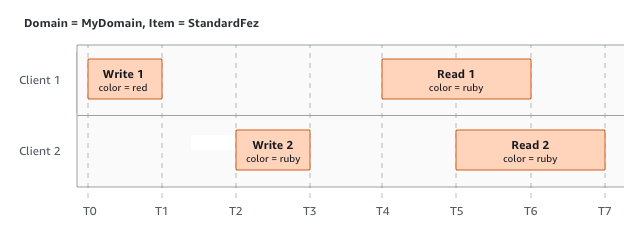
Im nächsten Beispiel ist W2 vor dem Start von R1 nicht abgeschlossen. Daher könnte R1 color = ruby oder color = garnet zurückgeben. Da W1 und W2 jedoch vor dem Start von R2 fertig sind, gibt R2 zurück color =
garnet.
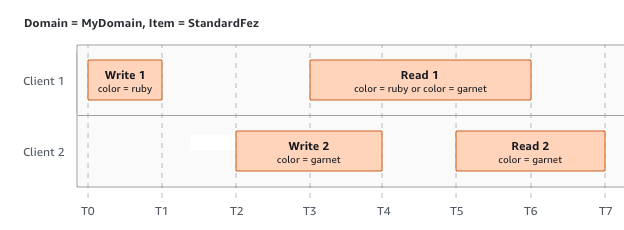
Im letzten Beispiel beginnt W2, bevor W1 eine Bestätigung erhalten hat. Daher werden diese Schreibvorgänge als gleichzeitig betrachtet. Amazon S3 verwendet intern die Semantik "last-writer-wins", um zu bestimmen, welcher Schreibvorgang Vorrang hat. Die Reihenfolge, in der Amazon S3 die Anforderungen erhält, und die Reihenfolge, in der Anwendungen Bestätigungen erhalten, können aber aufgrund von verschiedenen Faktoren wie Netzwerklatenz nicht vorhergesagt werden. W2 könnte z. B. von einer Amazon EC2-Instance in derselben Region initiiert werden, während W1 von einem weiter entfernten Host initiiert wird. Die beste Methode, um den endgültigen Wert zu bestimmen, besteht darin, einen Lesevorgang auszuführen, nachdem beide Schreibvorgänge bestätigt wurden.

Zugehörige Services
Nachdem Sie Daten zu Amazon S3 hochgeladen haben, können Sie sie mit anderen AWS-Services nutzen. Häufig genutzte Services:
-
Amazon Elastic Compute Cloud (Amazon EC2)
– Bietet sichere und skalierbare Rechenkapazität in der AWS Cloud. Bei Verwendung von Amazon EC2 entfällt die Notwendigkeit von Vorabinvestitionen in Hardware. Daher können Sie Anwendungen schneller entwickeln und bereitstellen. Mit Amazon EC2 können Sie so viele oder so wenige virtuelle Server starten, wie Sie benötigen, die Sicherheit und das Netzwerk konfigurieren und den Speicher verwalten. -
Amazon EMR
– Hilft Unternehmen, Forschungseinrichtungen, Datenanalysten und Entwickler einfach und kosteneffektiv riesige Datenmengen zu verarbeiten. Amazon EMR verwendet ein gehostetes Hadoop-Framework, das in der Cloud Computing-Infrastruktur von Amazon EC2 und Amazon S3 ausgeführt wird. -
AWSSnow-Familie
– Hilft Kunden, die Betriebsabläufe in strengen Umgebungen ohne Rechenzentrum und an Orten ausführen müssen, an denen keine konsistente Netzwerkkonnektivität besteht. Sie können AWS-Snow-Family-Geräte verwenden, um lokal und kostengünstig auf die Speicher- und Rechenleistung des AWS Cloud an Orten zuzugreifen, an denen eine Internetverbindung möglicherweise keine Option ist. -
AWS Transfer Family
– Bietet vollständig verwaltete Unterstützung für Dateiübertragungen direkt in und aus Amazon S3 oder Amazon Elastic File System (Amazon EFS) mit Secure Shell (SSH) File Transfer Protocol (SFTP), File Transfer Protocol over SSL (FTPS) und File Transfer Protocol (FTP).
Zugriff auf Amazon S3
Sie können mit Amazon S3 auf eine der folgenden Arten arbeiten:
AWS Management Console
Die Konsole ist eine webbasierte Benutzeroberfläche für die Verwaltung von Amazon S3 und AWS-Ressourcen. Wenn Sie sich für ein AWS-Konto registriert haben, können Sie auf die Amazon-S3-Konsole zugreifen, indem Sie sich bei AWS Management Console anmelden und auf der Startseite der AWS Management Console S3 auswählen.
AWS Command Line Interface
Sie können die Befehlszeilen-Tools von AWS verwenden, um Befehle in der Befehlszeile Ihres Systems auszugeben, mit denen AWS-Aufgaben (einschließlich S3) durchgeführt werden.
Die AWS Command Line Interface (AWS CLI)
AWS SDKs
AWS stellt SDKs (Software Development Kits) zur Verfügung, die aus Bibliotheken und Beispiel-Codes für verschiedene Programmiersprachen und Plattformen (Java, Python, Ruby, .NET, iOS, Android usw.) bestehen. Die AWS-SDKs sind gut zur Einrichtung des programmgesteuerten Zugriffs auf S3 und AWS geeignet. Amazon S3 ist ein REST-Service. Sie können Anfragen an Amazon S3 über die AWS-SDK-Bibliotheken senden, die die zugrunde liegende Amazon-S3-REST-API umschließen. Dies vereinfacht Ihre Programmieraufgaben. Beispielsweise übernehmen die SDKs Aufgaben wie das Berechnen von Signaturen, das kryptografische Signieren von Anforderungen, das Verwalten von Fehlern und das automatische erneute Ausführen von Anforderungen. Weitere Informationen über die AWS-SDKs, das Herunterladen und die Installation finden Sie unter Tools für AWS
Jede Interaktion mit Amazon S3 erfolgt entweder authentifiziert oder anonym. Wenn Sie die AWS-SDKs verwenden, berechnen die Bibliotheken die Signatur für die Authentifizierung anhand der von Ihnen bereitgestellten Schlüssel. Weitere Informationen darüber, wie Sie Anforderungen an Amazon S3 stellen, finden Sie unter Senden von Anforderungen.
Amazon S3-REST-API
Die Amazon S3-Architektur ist so ausgelegt, dass sie unabhängig von Programmiersprachen ist und unsere von AWS unterstützten Schnittstellen verwendet, um Objekte zu speichern und abzurufen. Sie können auf S3 und AWS programmgesteuert mithilfe der Amazon S3-REST-API zugreifen. Die REST-API ist eine HTTP-Schnittstelle zu Amazon S3. Mit REST-API verwenden Sie HTTP-Standardanfragen, um Buckets und Objekte zu erstellen, laden oder löschen.
Sie können einen beliebigen Toolkit einsetzen, der HTTP unterstützt, um die REST-API verwenden zu können. Sie können sogar einen Browser verwenden, um Objekte zu laden, wenn diese anonym lesbar sind.
Die REST-API verwendet HTTP-Standard-Header und -Statuscodes, sodass sich Standard-Browser und -Toolkits wie erwartet verhalten. In einigen Bereichen haben wir HTTP um zusätzliche Funktionen erweitert (wir haben beispielsweise Header hinzugefügt, um die Zugriffskontrolle zu unterstützen). In diesen Fällen haben wir alles dafür getan, die neue Funktion so hinzuzufügen, dass sie der standardmäßigen Nutzung von HTTP entsprechen.
Wenn Sie in Ihrer Anwendung direkte REST-API-Aufrufe senden, müssen Sie den Code für die Berechnung der Signatur schreiben und diesen der Anforderung hinzufügen. Weitere Informationen darüber, wie Sie Anforderungen an Amazon S3 stellen, finden Sie unter Senden von Anforderungen in der API-Referenz zu Amazon S3.
Anmerkung
Die SOAP-API-Unterstützung über HTTP ist veraltet, steht über HTTPS aber noch zur Verfügung. Neuere Amazon-S3-Funktionen werden unter SOAP nicht unterstützt. Wir empfehlen, entweder die REST-API oder die AWS-SDKs zu verwenden.
Bezahlen für Amazon S3
Die Preise für Amazon S3 sind so ausgelegt, dass Sie nicht im Hinblick auf die Speicheranforderungen Ihrer Anwendung planen müssen. Die meisten Speicheranbieter verlangen, dass Sie eine vorgegebene Menge an Speicherkapazität und Netzwerkübertragungskapazität erwerben. Wenn Sie in diesem Szenario diese Kapazität überschreiten, wird Ihr Service abgeschaltet, oder Sie zahlen hohe Überziehungsgebühren. Wenn Sie diese Kapazität nicht überschreiten, zahlen Sie genauso viel, als wenn Sie sie verwendet hätten.
Amazon S3 stellt Ihnen nur Gebühren für Kapazitäten in Rechnung, die Sie tatsächlich genutzt haben, ohne verborgene Kosten und Überziehungsgebühren. Dieses Modell bietet Ihnen einen Service mit variablen Kosten, der mit Ihrem Unternehmen wachsen kann und Ihnen gleichzeitig die Kostenvorteile der AWS-Infrastruktur bietet. Weitere Informationen finden Sie unter Amazon S3 – Preise
Wenn Sie sich bei AWS registrieren, wird Ihr AWS-Konto automatisch für alle Services in AWS registriert, einschließlich Amazon S3. Es werden jedoch nur die Services in Rechnung gestellt, die Sie tatsächlich nutzen. Wenn Sie neuer Amazon-S3-Kunde sind, können Sie kostenlos mit Amazon S3 beginnen. Weitere Informationen finden Sie unter Kostenloses Kontingent für AWS
Um Ihre Rechnung anzuzeigen, navigieren Sie zu Abrechnungs- und Kostenverwaltungs-Dashboard in der AWS Billing and Cost Management-Konsole
Compliance mit PCI DSS
Amazon S3 unterstützt die Verarbeitung, Speicherung und Übertragung von Kreditkartendaten durch einen Händler oder Dienstanbieter. Außerdem wurde seine Konformität mit dem Payment Card Industry (PCI) Data Security Standard (DSS) bestätigt. Weitere Informationen über PCI DSS, einschließlich der Anforderung einer Kopie des AWS PCI Compliance Package, finden Sie unter PCI DSS Level 1
