Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Bewerten Sie Ihre bereitgestellte Kapazität für die Bereitstellung in der richtigen Größe in Ihrer DynamoDB-Tabelle
In diesem Abschnitt erfahren Sie, wie Sie prüfen können, ob die Kapazitätsbereitstellung für Ihre DynamoDB-Tabellen angemessen ist. Im Zuge der Weiterentwicklung Ihres Workloads sollten Sie Ihre Betriebsverfahren entsprechend ändern, insbesondere wenn Ihre DynamoDB-Tabelle im Modus bereitgestellter Kapazität konfiguriert ist und die Gefahr einer zu geringen oder übermäßigen Kapazitätsbereitstellung für Ihre Tabellen besteht.
Für die unten beschriebenen Verfahren werden statistische Informationen benötigt. Diese sollten aus den DynamoDB-Tabellen erfasst werden, die Ihre Produktionsanwendung unterstützen. Um Ihr Anwendungsverhalten zu verstehen, sollten Sie einen Zeitraum definieren, der signifikant genug ist, um die Saisonalität der Daten aus Ihrer Anwendung zu erfassen. Wenn Ihre Anwendung beispielsweise wöchentliche Muster aufweist, sollte ein Zeitraum von drei Wochen ausreichen, um die Anforderungen an den Anwendungsdurchsatz zu analysieren.
Wenn Sie nicht wissen, wo Sie anfangen sollen, verwenden Sie für die folgenden Berechnungen die Datennutzung von mindestens einem Monat.
Bei der Bewertung der Kapazität können DynamoDB-Tabellen Lesekapazitätseinheiten (RCUs) und Schreibkapazitätseinheiten (WCU) unabhängig voneinander konfigurieren. Wenn in Ihren Tabellen Global Secondary Indexes (GSI) konfiguriert sind, müssen Sie den Durchsatz angeben, den diese Indizes verbrauchen, der auch unabhängig von der Basistabelle RCUs und WCUs von der Basistabelle ist.
Lokale sekundäre Indizes (LSI) verbrauchen Kapazität aus der Basistabelle.
So rufen Sie Verbrauchsmetriken aus Ihren DynamoDB-Tabellen ab
Um die Tabelle und die GSI-Kapazität zu bewerten, überwachen Sie die folgenden CloudWatch Messwerte und wählen Sie die entsprechende Dimension aus, um entweder Tabellen- oder GSI-Informationen abzurufen:
| Lesekapazitätseinheiten |
Schreibkapazitätseinheiten |
|
ConsumedReadCapacityUnits
|
ConsumedWriteCapacityUnits
|
|
ProvisionedReadCapacityUnits
|
ProvisionedWriteCapacityUnits
|
|
ReadThrottleEvents
|
WriteThrottleEvents
|
Sie können dies entweder über die AWS CLI oder die tun. AWS Management Console
- AWS CLI
-
Bevor wir die Kennzahlen zum Tabellenverbrauch abrufen, müssen wir zunächst einige historische Datenpunkte mithilfe der CloudWatch API erfassen.
Erstellen Sie zunächst zwei Dateien: write-calc.json und read-calc.json. Diese Dateien stellen die Berechnungen für eine Tabelle oder einen GSI dar. Sie müssen einige der Felder, die in der folgenden Tabelle dargestellt sind, Ihrer Umgebung entsprechend aktualisieren.
| Feldname |
Definition |
Beispiel |
<table-name> |
Der Name der Tabelle, die Sie analysieren |
SampleTable |
<period> |
Der Zeitraum, den Sie zum Auswerten des Auslastungsziels verwenden werden, in Sekunden |
Für einen Zeitraum von 1 Stunde müssen Sie Folgendes angeben: 3600 |
<start-time> |
Der Beginn Ihres Bewertungsintervalls, angegeben im Format ISO86 01 |
2022-02-21T23:00:00 |
<end-time> |
Das Ende Ihres Bewertungsintervalls, angegeben im Format ISO86 01 |
2022-02-22T06:00:00 |
Die Datei mit den Schreibberechnungen ruft die Anzahl der in dem Zeitraum bereitgestellten und verbrauchten WCU für den angegebenen Datumsbereich ab. Zudem generiert sie einen Prozentsatz für die Auslastung, der für die Analyse verwendet wird. Der vollständige Inhalt der Datei write-calc.json sollte wie folgt aussehen:
{
"MetricDataQueries": [
{
"Id": "provisionedWCU",
"MetricStat": {
"Metric": {
"Namespace": "AWS/DynamoDB",
"MetricName": "ProvisionedWriteCapacityUnits",
"Dimensions": [
{
"Name": "TableName",
"Value": "<table-name>"
}
]
},
"Period": <period>,
"Stat": "Average"
},
"Label": "Provisioned",
"ReturnData": false
},
{
"Id": "consumedWCU",
"MetricStat": {
"Metric": {
"Namespace": "AWS/DynamoDB",
"MetricName": "ConsumedWriteCapacityUnits",
"Dimensions": [
{
"Name": "TableName",
"Value": "<table-name>""
}
]
},
"Period": <period>,
"Stat": "Sum"
},
"Label": "",
"ReturnData": false
},
{
"Id": "m1",
"Expression": "consumedWCU/PERIOD(consumedWCU)",
"Label": "Consumed WCUs",
"ReturnData": false
},
{
"Id": "utilizationPercentage",
"Expression": "100*(m1/provisionedWCU)",
"Label": "Utilization Percentage",
"ReturnData": true
}
],
"StartTime": "<start-time>",
"EndTime": "<ent-time>",
"ScanBy": "TimestampDescending",
"MaxDatapoints": 24
}
Die Datei mit den Leseberechnungen ist ähnlich. In dieser Datei wird abgerufen, wie viele während des angegebenen Zeitraums bereitgestellt und genutzt RCUs wurden. Der Inhalt der Datei read-calc.json sollte wie folgt aussehen:
{
"MetricDataQueries": [
{
"Id": "provisionedRCU",
"MetricStat": {
"Metric": {
"Namespace": "AWS/DynamoDB",
"MetricName": "ProvisionedReadCapacityUnits",
"Dimensions": [
{
"Name": "TableName",
"Value": "<table-name>"
}
]
},
"Period": <period>,
"Stat": "Average"
},
"Label": "Provisioned",
"ReturnData": false
},
{
"Id": "consumedRCU",
"MetricStat": {
"Metric": {
"Namespace": "AWS/DynamoDB",
"MetricName": "ConsumedReadCapacityUnits",
"Dimensions": [
{
"Name": "TableName",
"Value": "<table-name>"
}
]
},
"Period": <period>,
"Stat": "Sum"
},
"Label": "",
"ReturnData": false
},
{
"Id": "m1",
"Expression": "consumedRCU/PERIOD(consumedRCU)",
"Label": "Consumed RCUs",
"ReturnData": false
},
{
"Id": "utilizationPercentage",
"Expression": "100*(m1/provisionedRCU)",
"Label": "Utilization Percentage",
"ReturnData": true
}
],
"StartTime": "<start-time>",
"EndTime": "<end-time>",
"ScanBy": "TimestampDescending",
"MaxDatapoints": 24
}
Wenn Sie die Dateien erstellt haben, können Sie mit dem Abrufen von Auslastungsdaten beginnen.
-
Geben Sie den folgenden Befehl aus, um die Daten zur Schreibauslastung abzurufen:
aws cloudwatch get-metric-data --cli-input-json file://write-calc.json
-
Geben Sie den folgenden Befehl aus, um die Daten zur Leseauslastung abzurufen:
aws cloudwatch get-metric-data --cli-input-json file://read-calc.json
Das Ergebnis beider Abfragen ist eine Reihe von Datenpunkten im JSON-Format, die für die Analyse verwendet werden. Ihr Ergebnis hängt von der Anzahl der angegebenen Datenpunkte, dem Zeitraum und Ihren spezifischen Workload-Daten ab. Es könnte etwa wie folgt aussehen:
{
"MetricDataResults": [
{
"Id": "utilizationPercentage",
"Label": "Utilization Percentage",
"Timestamps": [
"2022-02-22T05:00:00+00:00",
"2022-02-22T04:00:00+00:00",
"2022-02-22T03:00:00+00:00",
"2022-02-22T02:00:00+00:00",
"2022-02-22T01:00:00+00:00",
"2022-02-22T00:00:00+00:00",
"2022-02-21T23:00:00+00:00"
],
"Values": [
91.55364583333333,
55.066631944444445,
2.6114930555555556,
24.9496875,
40.94725694444445,
25.61819444444444,
0.0
],
"StatusCode": "Complete"
}
],
"Messages": []
}
Wenn Sie einen kurzen Zeitraum und einen langen Zeitbereich angeben, müssen Sie möglicherweise den Wert für MaxDatapoints ändern. Dieser ist im Skript standardmäßig auf 24 gesetzt. Dies entspricht einem Datenpunkt pro Stunde und 24 pro Tag.
- AWS Management Console
-
-
Melden Sie sich bei an AWS Management Console und navigieren Sie zur CloudWatch Serviceseite. Wählen Sie bei AWS-Region Bedarf eine geeignete aus.
-
Suchen Sie in der linken Navigationsleiste den Abschnitt Metriken und wählen Sie Alle Metriken aus.
-
Daraufhin wird ein Dashboard mit zwei Bereichen geöffnet. Im oberen Bereich wird die Grafik angezeigt, und im unteren Bereich werden die Kennzahlen angezeigt, die Sie grafisch darstellen möchten. Wählen Sie DynamoDB.
-
Wählen Sie Table Metrics aus. Daraufhin werden die Tabellen in Ihrer aktuellen Region angezeigt.
-
Verwenden Sie das Suchfeld, um nach Ihrem Tabellennamen zu suchen und die Messwerte für Schreibvorgänge auszuwählen: ConsumedWriteCapacityUnits und ProvisionedWriteCapacityUnits
In diesem Beispiel geht es um Metriken für Schreibvorgänge, Sie können diese Schritte jedoch auch verwenden, um die Metriken für Lesevorgänge grafisch darzustellen.
-
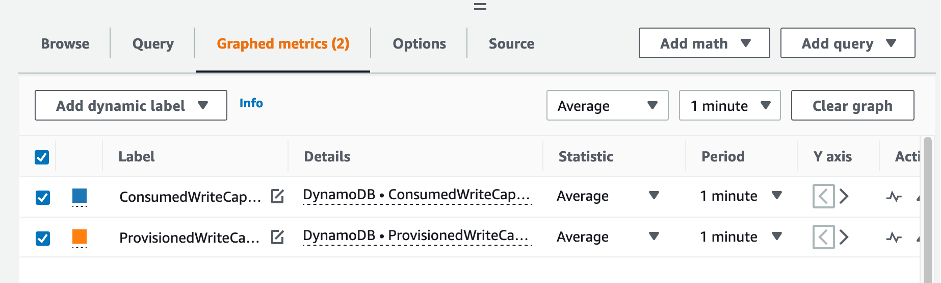
Wählen Sie die Registerkarte Graphische Metriken (2), um die Formeln zu ändern. CloudWatch Wählt standardmäßig die Statistikfunktion Durchschnitt für die Grafiken aus.
-
Wenn beide grafisch dargestellten Metriken ausgewählt sind (Kontrollkästchen auf der linken Seite), wählen Sie das Menü Add math (Math. hinzufügen), dann Common (Allgemein) und schließlich die Funktion Percentage (Prozent) aus. Wiederholen Sie den Vorgang zweimal.
Erstes Auswählen der Funktion Percentage (Prozent):
Zweites Auswählen der Funktion Percentage (Prozent):
-
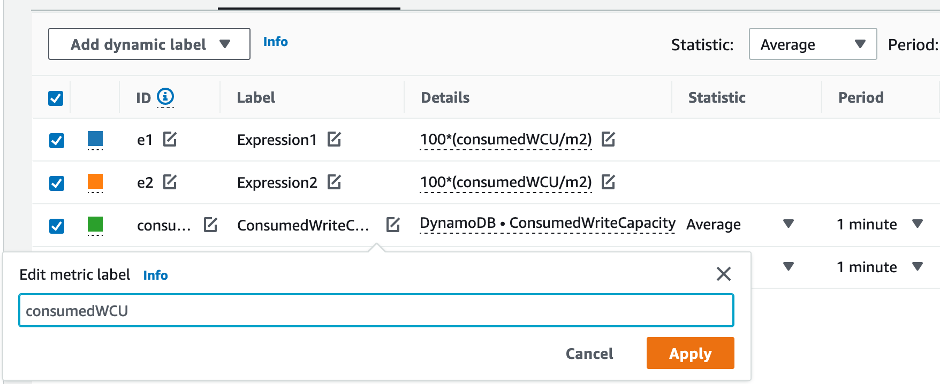
Zu diesem Zeitpunkt sollten vier Metriken im unteren Menü aufgeführt sein. Befassen wir uns nun mit der Berechnung von ConsumedWriteCapacityUnits. Um konsistent zu sein, müssen wir die Namen mit denen abgleichen, die wir im AWS CLI Abschnitt verwendet haben. Klicken Sie auf die m1 ID und ändern Sie diesen Wert in consumedWCU.
Benennen Sie die Bezeichnung um als. ConsumedWriteCapacityUnitconsumedWCU
-
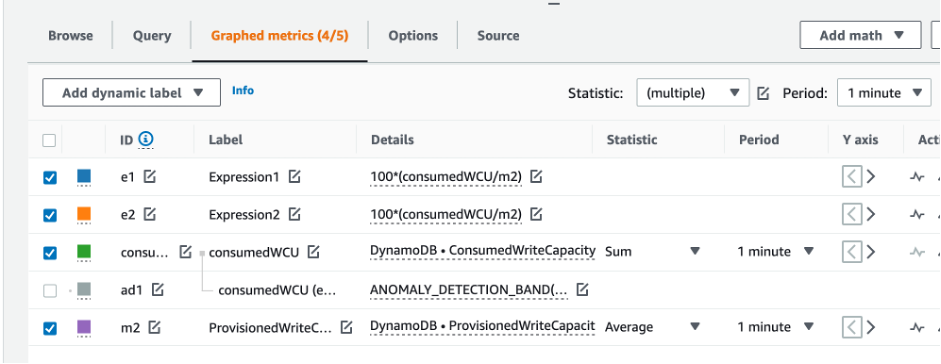
Ändern Sie die Statistik von Average (Durchschnitt) in Sum (Summe). Bei dieser Aktion wird automatisch eine weitere Metrik namens ANOMALY_DETECTION_BAND erstellt. Was den Umfang dieses Verfahrens angeht, ignorieren wir es, indem wir das Kontrollkästchen für die neu generierte ad1-Metrik entfernen.
-
Wiederholen Sie Schritt 8, um die m2 ID in provisionedWCU umzubenennen. Lassen Sie die Statistik auf Average (Durchschnitt) eingestellt.
-
Wählen Sie das Label Expression1 aus und aktualisieren Sie den Wert auf m1 und das Label auf Consumed. WCUs
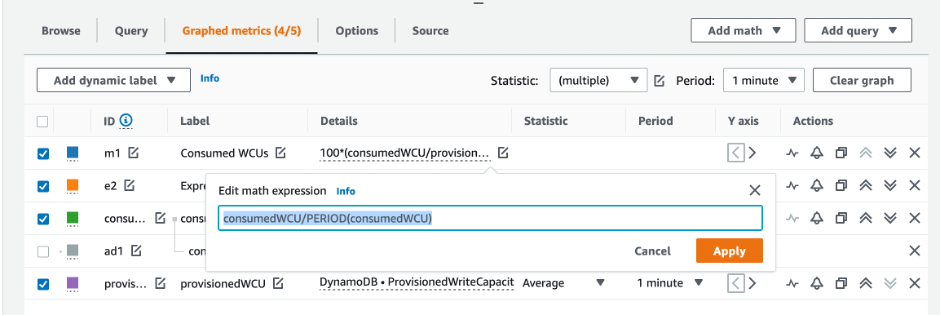
Stellen Sie sicher, dass Sie nur m1 (Kontrollkästchen links) und provisionedWCU ausgewählt haben, damit die Daten richtig angezeigt werden. Aktualisieren Sie die Formel, indem Sie auf Details klicken und die Formel in consumedWCU/PERIOD(consumedWCU) ändern. In diesem Schritt könnte eine weitere Metrik ANOMALY_DETECTION_BAND generiert werden, für die Zwecke dieses Verfahrens können wir diese jedoch ignorieren.
-
Sie sollten jetzt über zwei Grafiken verfügen: eine, die Ihre bereitgestellten Daten in der Tabelle anzeigt, und eine andere, die WCUs den Verbrauch anzeigt. WCUs Die Grafik kann sich in ihrer Form von der unten dargestellten Grafik unterscheiden, Sie können sie jedoch als Referenz verwenden:
-
Aktualisieren Sie die Prozentformel, indem Sie die Grafik für Expression2 (e2) auswählen. Benennen Sie die Beschriftungen und in UtilizationPercentage IDs um. Benennen Sie die Formel so um, dass sie 100*(m1/provisionedWCU) entspricht.
-
Entfernen Sie das Kontrollkästchen für alle Metriken außer utilizationPercentage, um Ihre Nutzungsmuster anzuzeigen. Als Standardintervall ist 1 Minute eingestellt, Sie können dies jedoch nach Bedarf ändern.
Hier sehen Sie die Ansicht eines längeren Zeitraums sowie eines größeren Zeitbereichs von 1 Stunde. Wie Sie sehen, gibt es einige Intervalle mit einer Auslastung von über 100 %, doch bei diesem speziellen Workload sind längere Intervalle mit einer Auslastung von null zu finden.
Hier unterscheiden sich Ihre Ergebnisse möglicherweise von den hier dargestellten Ergebnissen. Es hängt alles von den Daten aus Ihrem Workload ab. Wenn es Intervalle mit einer Auslastung von mehr als 100 % gibt, besteht die Gefahr einer Drosselung. DynamoDB bietet Burst-Kapazität, doch sobald die Burst-Kapazität erschöpft ist, wird alles über 100 % gedrosselt.
So ermitteln Sie DynamoDB-Tabellen mit zu geringer bereitgestellter Kapazität
Bei den meisten Workloads gilt die bereitgestellte Kapazität einer Tabelle als zu gering, wenn die Tabelle ständig mehr als 80 % ihrer bereitgestellten Kapazität beansprucht.
Burst-Kapazität ist eine DynamoDB-Funktion, mit der Kunden vorübergehend mehr RCUs/WCUs als ursprünglich bereitgestellt nutzen können (mehr als den bereitgestellten Durchsatz pro Sekunde, der in der Tabelle definiert wurde). Die Burst-Kapazität soll plötzliche Zunahmen des Datenverkehrs aufgrund von besonderen Ereignissen oder Auslastungsspitzen auffangen. Doch die Burst-Kapazität ist irgendwann erschöpft. Sobald die ungenutzten RCUs Daten aufgebraucht WCUs sind, werden Sie gedrosselt, wenn Sie versuchen, mehr Kapazität als die bereitgestellte Kapazität zu verbrauchen. Wenn sich Ihr Anwendungsdatenverkehr der Auslastungsrate von 80 % nähert, ist das Risiko einer Drosselung deutlich höher.
Die Regel der Auslastungsrate von 80 % hängt von der Saisonalität Ihrer Daten und dem Wachstums Ihres Datenverkehrs ab. Betrachten Sie folgende Szenarien:
-
Wenn Ihr Datenverkehr in den letzten 12 Monaten bei einer Auslastung von ~ 90 % stabil war, hat Ihre Tabelle genau die richtige Kapazität.
-
Wenn Ihr Anwendungsdatenverkehr monatlich um 8 % wächst, werden Sie in weniger als 3 Monaten 100 % erreichen.
-
Auch wenn Ihr Anwendungsdatenverkehr monatlich um 5 % wächst, werden Sie in etwas mehr als 4 Monaten 100 % erreichen.
Die Ergebnisse der obigen Abfragen vermitteln ein Bild Ihrer Auslastungsrate. Verwenden Sie sie als Orientierungshilfe für die Auswertung weiterer Metriken, die bei der Entscheidung, Ihre Tabellenkapazität nach Bedarf zu erhöhen, hilfreich sein können (z. B. monatliche oder wöchentliche Wachstumsrate). Legen Sie gemeinsam mit Ihrem Operations-Team fest, welcher Prozentsatz für Ihren Workload und Ihre Tabellen geeignet ist.
Es gibt gewisse Situationen, in denen die Daten verzerrt sind, wenn wir sie täglich oder wöchentlich analysieren. Beispielsweise könnten Sie bei saisonalen Anwendungen, die während der Arbeitszeit stark ausgelastet sind (außerhalb der Geschäftszeiten auf nahezu Null sinken), von Vorteil sein, wenn Sie Auto Scaling einplanen, bei dem Sie die Tageszeiten (und Wochentage) angeben, um die bereitgestellte Kapazität zu erhöhen, und wann sie reduziert werden soll. Anstatt eine höhere Kapazität anzustreben, um die geschäftigen Zeiten abzudecken, können Sie auch von den Konfigurationen für die auto Skalierung von DynamoDB-Tabellen profitieren, wenn Ihre Saisonalität weniger ausgeprägt ist.
Denken Sie beim Erstellen einer DynamoDB-Auto-Scaling-Konfiguration für Ihre Basistabelle daran, eine weitere Konfiguration für jeden GSI hinzuzufügen, der der Tabelle zugeordnet ist.
So ermitteln Sie DynamoDB-Tabellen mit zu viel bereitgestellter Kapazität
Die mit den obigen Skripts erhaltenen Abfrageergebnisse liefern die für eine erste Analyse erforderlichen Datenpunkte. Wenn Ihr Datensatz für mehrere Intervalle Auslastungswerte von weniger als 20 % aufweist, wurde für Ihre Tabelle möglicherweise zu viel Kapazität bereitgestellt. Um genauer zu definieren, ob Sie die Anzahl von WCUs und RCUS reduzieren müssen, sollten Sie die anderen Messwerte in den Intervallen erneut überprüfen.
Wenn Ihre Tabellen mehrere niedrige Nutzungsintervalle enthalten, können Sie wirklich von der Verwendung von Auto Scaling-Richtlinien profitieren, indem Sie entweder Auto Scaling planen oder einfach die standardmäßigen Auto Scaling-Richtlinien für die Tabelle konfigurieren, die auf der Auslastung basieren.
Wenn Sie eine Arbeitslast mit einem Verhältnis von geringer Auslastung zu hohem Drosselungsverhältnis (Max (ThrottleEventsThrottleEvents) /Min () im Intervall) haben, kann dies passieren, wenn Sie eine sehr hohe Arbeitslast haben, bei der der Verkehr an einigen Tagen (oder Stunden) stark zunimmt, der Verkehr aber im Allgemeinen konstant gering ist. In diesen Szenarien kann es von Vorteil sein, die geplante auto Skalierung zu verwenden.