Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Lebenszyklus eines Data Lake
Der Aufbau eines Data Lakes umfasst in der Regel fünf Phasen:
-
Speicher einrichten
-
Daten verschieben
-
Daten aufbereiten und katalogisieren
-
Konfiguration von Sicherheitsrichtlinien
-
Bereitstellung von Daten für den Konsum
Die folgende Abbildung zeigt ein allgemeines Architekturdiagramm eines Amazon Connect-Contact-Center-Data Lakes, der in AWS-Dienste für Analytik und künstliche Intelligenz und maschinelles Lernen (KI/ML) integriert ist. Der folgende Abschnitt behandelt die in dieser Abbildung gezeigten Szenarien und AWS-Services.
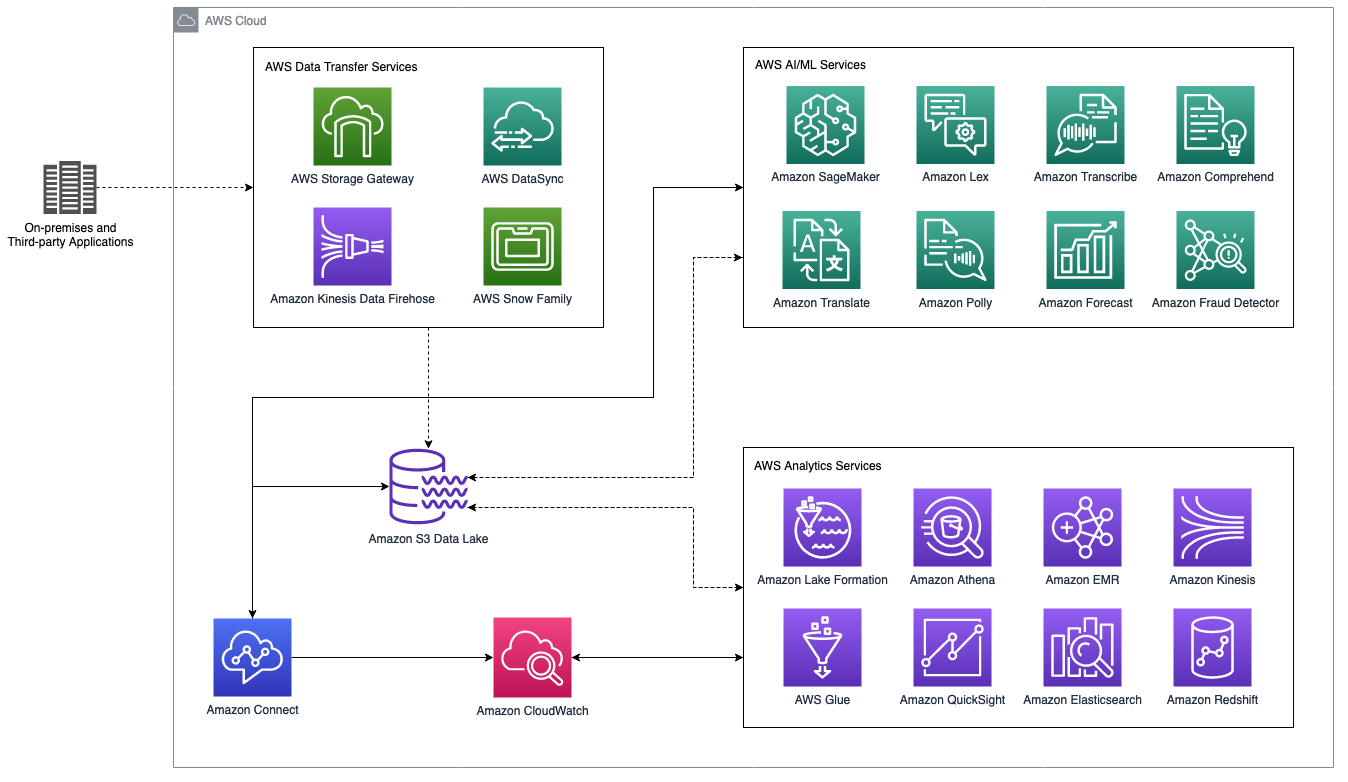
Amazon Connect Contact Center-Data Lake mit AWS-Analyse- und KI-/ML-Services
Speicher
Amazon S3
S3-Buckets und -Objekte sind privat, wobei S3 Block Public Access standardmäßig für alle Regionen weltweit aktiviert ist. Sie können zentralisierte Zugriffskontrollen für S3-Ressourcen mithilfe von Bucket-Richtlinien, AWS Identity and Access Management
AWS CloudTrail
S3 Intelligent-Tiering
Das Speichern von Daten in Spaltenformaten wie Apache Parquet
Mit S3 Select und S3 Glacier Select können Sie Objektmetadaten mithilfe eines SQL-Ausdrucks (Structured Query Language) abfragen, ohne die Objekte in einen anderen Datenspeicher verschieben zu müssen.
S3 Batch Operations
S3 Access Points
S3 Transfer Acceleration
Wenn Ihr Data Lake wächst, bietet S3 Storage Lens
Aufnahme
AWS bietet ein umfassendes Portfolio an Datenübertragungsservices, mit dem Sie Ihre vorhandenen Daten in einen zentralen Data Lake verschieben können. Amazon Storage Gateway
-
AWS Storage Gatewayerweitert Ihre lokalen Umgebungen auf AWS-Speicher, indem Bandbibliotheken durch Cloud-Speicher ersetzt werden, auf Cloud-Speicher gestützte Dateifreigaben bereitgestellt oder ein Cache mit niedriger Latenz für den Zugriff auf Ihre Daten in AWS aus lokalen Umgebungen erstellt wird.
-
AWS Direct Connectstellt eine private Konnektivität zwischen Ihren lokalen Umgebungen und AWS her, um die Netzwerkkosten zu senken, den Durchsatz zu erhöhen und ein konsistentes Netzwerkerlebnis zu bieten.
-
AWS DataSync kann Millionen von Dateien in S3, Amazon Elastic File System
(Amazon EFS) oder Amazon FSx for Windows File Server übertragen und gleichzeitig die Netzwerkauslastung optimieren. -
Amazon Kinesis bietet eine sichere Möglichkeit, Streaming-Daten zu erfassen und in S3 zu laden. Amazon Data Firehose
ist ein vollständig verwalteter Service für die direkte Übertragung von Echtzeit-Streaming-Daten an S3. Firehose passt sich automatisch dem Volumen und dem Durchsatz der Streaming-Daten an und erfordert keine laufende Verwaltung. Sie können Streaming-Daten mithilfe von Komprimierung, Verschlüsselung, Datenstapelung oder AWS Lambda Funktionen in Firehose transformieren, bevor Sie Daten in S3 speichern. Die Firehose-Verschlüsselung unterstützt die serverseitige S3-Verschlüsselung mit AWS Key Management Service ()AWS KMS. Alternativ können Sie die Daten mit Ihrem benutzerdefinierten Schlüssel verschlüsseln. Firehose kann mehrere eingehende Datensätze zu einem einzigen S3-Objekt verketten und bereitstellen, um die Kosten zu senken und den Durchsatz zu optimieren. AWS Snow Family bietet einen Offline-Datenübertragungsmechanismus. AWS Snowball Edge
bietet ein tragbares und robustes Edge-Computing-Gerät für die Datenerfassung, -verarbeitung und -migration. Für Datenübertragungen im Exabyte-Bereich können Sie AWS Snowmobile verwenden, um riesige Datenmengen in die Cloud zu verschieben. DistCp
bietet eine verteilte Kopierfunktion zum Verschieben von Daten im Hadoop-Ökosystem. S3 DisctCp ist eine Erweiterung, die für die DistCp Übertragung von Daten zwischen Hadoop Distributed File System (HDFS) und S3 optimiert ist. Dieser Blog enthält Informationen zum Verschieben von Daten zwischen HDFS und S3 mithilfe von S3. DistCp
Katalogisierung
Ein häufiges Problem bei einer Data-Lake-Architektur ist die mangelnde Kontrolle über den Inhalt der im Data Lake gespeicherten Rohdaten. Organizations benötigen Governance, semantische Konsistenz und Zugriffskontrollen, um die Fallstricke zu vermeiden, die mit der Schaffung eines Datensumpfs ohne Pflege einhergehen.
AWS Lake Formation
AWS Glue DataBrew
Sicherheit
Amazon Connect trennt Daten nach AWS-Konto-ID und Amazon Connect Connect-Instance-ID, um den autorisierten Datenzugriff auf Amazon Connect Connect-Instance-Ebene sicherzustellen.
Amazon Connect verschlüsselt personenbezogene Daten (PII), Kontaktdaten und Kundenprofile im Speicher mithilfe eines zeitlich begrenzten Schlüssels, der für Ihre Amazon Connect Connect-Instanz spezifisch ist. Die serverseitige S3-Verschlüsselung schützt sowohl Sprach- als auch Chat-Aufzeichnungen im Ruhezustand mithilfe eines für jedes AWS-Konto eindeutigen KMS-Datenschlüssels. Sie behalten die vollständige Sicherheitskontrolle bei, um den Benutzerzugriff auf Anrufaufzeichnungen in Ihrem S3-Bucket zu konfigurieren, einschließlich der Nachverfolgung, wer Anrufaufzeichnungen abhört oder löscht. Amazon Connect verschlüsselt die Stimmabdrücke der Kunden mit einem diensteigenen KMS-Schlüssel, um die Kundenidentität zu schützen. Alle zwischen Amazon Connect und anderen AWS-Services oder externen Anwendungen ausgetauschten Daten werden bei der Übertragung immer mit der branchenüblichen Transport Layer Security (TLS) -Verschlüsselung verschlüsselt.
Die Sicherung eines Data Lakes erfordert detaillierte Kontrollen, um den autorisierten Datenzugriff und die Nutzung sicherzustellen. S3-Ressourcen sind privat und standardmäßig nur für ihren Ressourcenbesitzer zugänglich. Der Ressourcenbesitzer kann eine Kombination aus ressourcen- oder identitätsbasierten IAM-Richtlinien erstellen, um Berechtigungen für S3-Buckets und -Objekte zu gewähren und zu verwalten. Ressourcenbasierte Richtlinien, wie z. B. Bucket-Richtlinien, sind an Ressourcen angehängt. ACLs Im Gegensatz dazu sind identitätsbasierte Richtlinien an die IAM-Benutzer, -Gruppen oder -Rollen in Ihrem AWS-Konto angehängt.
Wir empfehlen für die meisten Data Lake-Umgebungen identitätsbasierte Richtlinien, um die Verwaltung des Ressourcenzugriffs und die Serviceberechtigungen für Ihre Data Lake-Benutzer zu vereinfachen. Sie können IAM-Benutzer, -Gruppen und -Rollen in AWS-Konten erstellen und sie identitätsbasierten Richtlinien zuordnen, die Zugriff auf S3-Ressourcen gewähren.
Das AWS Lake Formation Berechtigungsmodell funktioniert in Verbindung mit IAM-Berechtigungen, um den Zugriff auf den Data Lake zu steuern. Das Lake Formation Formation-Berechtigungsmodell verwendet einen GRANT- oder REVOKE-Mechanismus im Stil eines Datenbankmanagementsystems (DBMS). IAM-Berechtigungen enthalten identitätsbasierte Richtlinien. Beispielsweise muss ein Benutzer die Berechtigungsprüfungen sowohl durch IAM- als auch durch Lake Formation Formation-Berechtigungen bestehen, bevor er auf eine Data Lake-Ressource zugreifen kann.
AWS CloudTrail verfolgt Amazon Connect Connect-API-Aufrufe, einschließlich der IP-Adresse und Identität des Anfragenden sowie Datum und Uhrzeit der Anfrage im CloudTrail Ereignisverlauf. Die Erstellung eines AWS CloudTrail Trails ermöglicht die kontinuierliche Bereitstellung von AWS CloudTrail Protokollen an Ihren S3-Bucket.
Amazon Athena Workgroups können die Ausführung von Abfragen trennen und den Zugriff durch Benutzer, Teams oder Anwendungen mithilfe ressourcenbasierter Richtlinien kontrollieren. Sie können die Kostenkontrolle durchsetzen, indem Sie die Datennutzung in den Arbeitsgruppen einschränken.
Überwachen
Beobachtbarkeit ist unerlässlich, um die Verfügbarkeit, Zuverlässigkeit und Leistung eines Kontaktzentrums und eines Data Lakes sicherzustellen. Amazon CloudWatch
Amazon Connect sendet die Nutzungsdaten der Instance als CloudWatch Amazon-Metriken im Abstand von einer Minute. Die Datenspeicherung für CloudWatch Amazon-Metriken beträgt zwei Wochen. Definieren Sie frühzeitig die Anforderungen für die Aufbewahrung von Protokollen und Lebenszyklusrichtlinien, um die Einhaltung gesetzlicher Vorschriften sicherzustellen und Kosten für die langfristige Datenarchivierung zu sparen.
Amazon CloudWatch Logs bietet eine einfache Möglichkeit, Protokolldaten zu filtern und Verstöße zu identifizieren, um Vorfälle zu untersuchen und deren Lösung zu beschleunigen. Sie können die Kontaktabläufe anpassen, um Anrufer mit hohem Risiko oder potenziell betrügerische Aktivitäten zu erkennen. Sie können beispielsweise die Verbindung zu allen eingehenden Kontakten trennen, die auf Ihrer vordefinierten Ablehnungsliste stehen.
Analysen
Ein Data Lake für Kontaktzentren, der auf einem Portfolio mit beschreibenden, vorausschauenden Analysen und Echtzeitanalysen basiert, hilft Ihnen dabei, aussagekräftige Erkenntnisse zu gewinnen und wichtige Geschäftsfragen zu beantworten.
Sobald Ihre Daten im S3-Datensee gelandet sind, können Sie alle speziell entwickelten Analysedienste wie Amazon Athena und Amazon QuickSight
Für eine hoch skalierbare Data Warehousing-Lösung können Sie Datenstreaming in Amazon Connect aktivieren, um Kontaktdatensätze über Amazon Kinesis in Amazon Redshift
Machine Learning
Der Aufbau eines Data Lakes bringt ein neues Paradigma in die Contact-Center-Architektur und ermöglicht es Ihrem Unternehmen, mithilfe von Funktionen für maschinelles Lernen (ML) einen verbesserten und personalisierten Kundenservice zu bieten.
Die herkömmliche ML-Entwicklung ist ein komplexer und teurer Prozess. AWS bietet die Tiefe und Breite einer leistungsstarken, kostengünstigen, skalierbaren Infrastruktur und flexiblen ML-Services für jedes ML-Projekt
Amazon SageMaker AI
Um Kundenabwanderungen zu vermeiden, ist es wichtig, die Reibung während einer Kundenreise zu reduzieren. Um Ihr Kontaktzentrum intelligenter zu gestalten, können Sie KI-gestützte Konversations-Chatbots
Um die allgemeine Servicequalität zu verbessern, ist es wichtig, die Dynamik zwischen Anrufer und Agent zu verstehen. In diesem Blog
Für Unternehmen mit internationaler Präsenz können Sie mit Amazon Polly
Herkömmliche Finanzplanungssoftware erstellt Prognosen auf der Grundlage historischer Zeitreihendaten, ohne inkonsistente Trends und relevante Variablen zu korrelieren. Amazon Forecast
Amazon Connect stellt Anrufattribute von Telefonanbietern bereit, z. B. den geografischen Standort der Sprachausrüstung, um zu zeigen, woher der Anruf stammt, Telefongerätetypen wie Festnetz oder Mobilfunk, Anzahl der Netzwerksegmente, die der Anruf durchquert hat, und andere Informationen zur Anruferzeugung. Mit dem vollständig verwalteten Amazon Fraud Detector
