¿Qué es Amazon S3?
Amazon Simple Storage Service (Amazon S3) es un servicio de almacenamiento de objetos que ofrece escalabilidad, disponibilidad de datos, seguridad y rendimiento líderes del sector. Los clientes de todos los tamaños y sectores pueden utilizar Amazon S3 para almacenar y proteger cualquier cantidad de datos para diversos casos de uso, tales como lagos de datos, sitios web, aplicaciones móviles, copia de seguridad y restauración, archivado, aplicaciones empresariales, dispositivos IoT y análisis de big data. Amazon S3 proporciona funciones de gestión para que pueda optimizar, organizar y configurar el acceso a sus datos para satisfacer sus requisitos empresariales, organizativos y de conformidad específicos.
nota
Para obtener más información sobre el uso de la clase de almacenamiento Amazon S3 Express One Zone con buckets de directorio, consulte S3 Express One Zone y Trabajar con buckets de de directorio.
Temas
Características de Amazon S3
Clases de almacenamiento
Amazon S3 ofrece varios tipos de almacenamiento diseñados para distintos casos de uso. Por ejemplo, puede almacenar datos de producción críticos en S3 Standard o S3 Express One Zone para obtener acceso frecuente, ahorrar costes al almacenar datos a los que se accede con poca frecuencia en S3 Standard-IA o S3 One Zone-IA, y archivar datos con los costos más bajos en S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval y S3 Glacier Deep Archive.
Amazon S3 Express One Zone es una clase de almacenamiento de Amazon S3 en zona única de alto rendimiento que está diseñada específicamente para ofrecer acceso constante a los datos en milisegundos de un solo dígito para los datos a los que accede para las aplicaciones sensibles a la latencia. S3 Express One Zone es la clase de almacenamiento de objetos en la nube con la latencia más baja disponible en la actualidad, con una velocidad de acceso a los datos hasta 10 veces más rápida y unos costos de solicitud un 50 % más bajos que los de S3 Standard. S3 Express One Zone es la primera clase de almacenamiento de S3 en la que se puede seleccionar una única zona de disponibilidad con la opción de coubicar su almacenamiento de objetos junto con sus recursos informáticos, lo que brinda la mayor velocidad de acceso posible. Además, para aumentar aún más la velocidad de acceso y admitir cientos de miles de solicitudes por segundo, los datos se almacenan en un nuevo tipo de bucket: un bucket de directorio de Amazon S3. Para obtener más información, consulte S3 Express One Zone y Trabajar con buckets de de directorio.
Puede almacenar datos con patrones de acceso cambiantes o desconocidos en S3 Intelligent-Tiering, que optimiza los costos de almacenamiento moviendo automáticamente los datos entre cuatro niveles de acceso cuando cambian los patrones de acceso. Funciona con el almacenamiento de objetos en cuatro capas de acceso: dos de acceso de baja latencia optimizadas para el acceso frecuente y poco frecuente y dos de acceso a archivos opcionales diseñados para el acceso asíncrono, las cuales están optimizadas para accesos inusuales.
Para obtener más información, consulte Descripción y administración de clases de almacenamiento de Amazon S3.
Administrar el almacenamiento
Amazon S3 cuenta con funciones de gestión del almacenamiento que puede utilizar para gestionar los costes, cumplir los requisitos normativos, reducir la latencia y guardar varias copias distintas de sus datos para cumplir los requisitos de cumplimiento.
-
Ciclo de vida de S3: defina la configuración de ciclo de vida para administrar los objetos y almacenarlos de manera económica durante todo su ciclo de vida. Puede realizar la transición de objetos a otras clases de almacenamiento de S3 o caducar objetos que alcancen el final de su vida útil.
-
S3 Object Lock: evite que se eliminen o se sobreescriban objetos de Amazon S3 durante un período de tiempo determinado o de manera indefinida. Object Lock se puede utilizar para cumplir con los requisitos normativos que requieren almacenamiento de escritura única y lectura múltiple (WORM) o simplemente para agregar otra capa de protección para evitar cambios y eliminaciones de objetos.
-
Replicación de S3— Replique objetos y sus respectivos metadatos y etiquetas de objeto en uno o más buckets de destino en el mismo o en diferentesRegiones de AWSpara reducir la latencia, el cumplimiento normativo, la seguridad y otros casos de uso.
-
Operaciones por lotes de S3: gestione miles de millones de objetos a escala con una sola solicitud de API de S3 o con unos pocos clics en la consola de Amazon S3. Puede utilizar las operaciones por lotes para realizar operaciones tales como Copiar, Invocar función de AWS Lambda y Restaurar en millones o miles de millones de objetos.
Gestión de acceso y seguridad
Amazon S3 proporciona funciones para auditar y gestionar el acceso a sus buckets y objetos. De forma predeterminada, los buckets y los objetos de S3 son privados. Solo tiene acceso a los recursos de S3 que cree. Para conceder permisos de recursos detallados que admitan su caso de uso específico o para auditar los permisos de sus recursos de Amazon S3, puede utilizar las siguientes características.
-
S3 Block Public Access: bloquea el acceso público a los buckets y objetos de S3. De forma predeterminada, la configuración de bloqueo del acceso público se activa en el nivel de bucket. Le recomendamos que deje todas las configuraciones habilitadas a menos que sepa que necesita desactivar una o varias para su caso de uso concreto. Para obtener más información, consulte Establecer la configuración de Block Public Access para sus buckets de S3.
-
AWS Identity and Access Management (IAM): IAM es un servicio web que le ayuda a controlar de forma segura el acceso a los recursos de AWS, como los recursos de Amazon S3. Con IAM, se pueden administrar de forma centralizada los permisos que controlan a qué recursos de AWS pueden acceder los usuarios. Utilice IAM para controlar quién está autenticado (ha iniciado sesión) y autorizado (tiene permisos) para utilizar recursos.
-
Políticas de buckets: utilice el lenguaje de políticas basado en IAM para configurar permisos basados en recursos para los buckets de S3 y los objetos que hay en ellos.
-
Puntos de acceso de Amazon S3: configure los puntos de acceso de la red con nombre con políticas de acceso dedicadas para administrar el acceso a los datos a escala para los conjuntos de datos compartidos en Amazon S3.
-
Listas de control de acceso (ACL): conceder permisos de lectura y escritura para buckets y objetos individuales a usuarios autorizados. Como regla general, se recomienda utilizar políticas basadas en recursos de S3 (políticas de bucket y políticas de punto de acceso) o políticas de usuario de IAM para el control de acceso en lugar de las ACL. Las políticas son una opción de control de acceso simplificada y más flexible. Con las políticas de bucket y las políticas de puntos de acceso, puede definir reglas que se apliquen ampliamente a todas las solicitudes a sus recursos de Amazon S3. Para obtener más información acerca de casos específicos en que usaría ACL en lugar de políticas basadas en recursos o políticas de usuarios de IAM, consulte Administración de acceso con ACL.
-
S3 Object Ownership: tome posesión de cada objeto del bucket, lo que simplificará la administración del acceso a los datos almacenados en Amazon S3. S3 Object Ownership es una configuración en el nivel de bucket de Amazon S3 que puede usar para desactivar o activar las ACL. Las ACL están desactivadas de forma predeterminada. Cuando las ACL están desactivadas, el propietario del bucket posee todos los objetos del bucket y administra el acceso a los datos de forma exclusiva mediante políticas de administración de acceso.
-
Analizador de acceso de IAM para S3: evalúe y monitoree sus políticas de acceso al bucket de S3, asegurándose de que las políticas solo proporcionen el acceso previsto a sus recursos de S3.
Procesamiento de datos
Para transformar datos y activar flujos de trabajo para automatizar una variedad de otras actividades de procesamiento a escala, puede utilizar las siguientes características.
-
S3 Object Lambda: agregue su propio código a las solicitudes GET, HEAD y LIST de S3 para modificar y procesar los datos a medida que vuelven a una aplicación. Filtra filas, redimensiona dinámicamente las imágenes, redacta datos confidenciales y mucho más.
-
Notificaciones de eventos: active flujos de trabajo que utilizan Amazon Simple Notification Service (Amazon SNS), Amazon Simple Queue Service (Amazon SQS) yAWS Lambdacuando se realiza un cambio en los recursos de S3.
Registro y monitorización
Amazon S3 proporciona herramientas de registro y supervisión que puede utilizar para supervisar y controlar cómo se utilizan sus recursos de Amazon S3. Para obtener más información sobre la monitorización de , consulte .
Herramientas de supervisión automatizadas
-
Métricas de Amazon CloudWatch para Amazon S3: realice un seguimiento del estado operativo de sus recursos de S3 y configure alertas de facturación cuando los cargos estimados alcancen un umbral definido por el usuario.
-
AWS CloudTrail proporciona un registro de las medidas adoptadas por un usuario, un rol o un servicio de Servicio de AWS en Amazon S3. Los registros de CloudTrail le proporcionan un seguimiento detallado de la API para las operaciones a nivel de bucket y de objeto de Amazon S3.
Herramientas de supervisión manuales
-
Registro de acceso al servidor: brinda registros detallados para las solicitudes realizadas a un bucket. Puede utilizar los registros de acceso al servidor para auditorías de seguridad y acceso, obtener información sobre la base de clientes o comprender la factura de Amazon S3.
-
AWSTrusted Advisor— Evalúe su cuenta usandoAWScomprobaciones de prácticas recomendadas para identificar formas de optimizar suAWSinfraestructura, mejorar la seguridad y el rendimiento, reducir los costos y supervisar las cuotas de servicio. A continuación, puede seguir las recomendaciones para optimizar sus servicios y recursos.
Uso de análisis e información
Amazon S3 ofrece funciones que le ayudarán a obtener visibilidad del uso del almacenamiento, lo que le permite comprender mejor, analizar y optimizar su almacenamiento a escala.
-
Amazon S3 Storage Lens: comprenda, analice y optimice su almacenamiento. S3 Storage Lens proporciona más de 60 métricas de uso y actividad y paneles interactivos para añadir datos para toda su organización, cuentas específicas, Regiones de AWS, buckets o prefijos.
-
Análisis de clases de almacenamiento: analice los patrones de acceso al almacenamiento para decidir cuándo es el momento de mover los datos a una clase de almacenamiento más rentable.
-
Informes de inventario de S3 con informes de inventario: auditar e informar sobre los objetos y sus metadatos correspondientes y configurar otras funciones de Amazon S3 para tomar medidas en los informes de inventario. Por ejemplo, puede informar sobre el estado de replicación y cifrado de los objetos. Para obtener una lista de todos los metadatos disponibles para cada objeto en los informes de inventario, consulteLista de inventario de Amazon S3.
Consistencia sólida
Amazon S3 proporciona una sólida coherencia de lectura tras escritura para las operaciones PUT y DELETE de objetos del bucket de Amazon S3 en todas las Regiones de AWS. Esto se aplica tanto a las escrituras en objetos nuevos como a las solicitudes PUT que sobrescriben objetos existentes y las solicitudes DELETE. Además, las operaciones de lectura en Amazon S3 Select, las listas de control de acceso de Amazon S3, las etiquetas de objeto de Amazon S3 y los metadatos de objetos (p. ej., el objeto HEAD) son muy consistentes. Para obtener más información, consulte Modelo de consistencia de datos de Amazon S3.
Cómo funciona Amazon S3
Amazon S3 es un servicio de almacenamiento de objetos que almacena datos como objetos, datos jerárquicos o datos tabulares dentro de buckets. Un objeto es un archivo y cualquier metadato que describa ese archivo. Un bucket es un contenedor de objetos.
Para almacenar datos en Amazon S3, primero debe crear un bucket y especificar un nombre de bucket y Región de AWS. A continuación, cargue datos a ese bucket como objetos en Amazon S3. Cada objeto tiene unclave(oNombre de clave), que es el identificador único del objeto dentro del bucket.
S3 proporciona funciones que puede configurar para admitir su caso de uso específico. Puede utilizar S3 Versioning para mantener varias versiones de un objeto en un bucket y restaurar objetos que se eliminan o sobrescriben accidentalmente.
Los buckets y los objetos que contienen son privados y solo se puede acceder a ellos si concede explícitamente permisos de acceso. Puede utilizar políticas de bucket,AWS Identity and Access Management(IAM), listas de control de acceso (ACL) y puntos de acceso S3 para administrar el acceso.
Temas
Buckets
Amazon S3 admite cuatro tipos de buckets: buckets de uso general, buckets de directorio, buckets de tablas y buckets vectoriales. Cada tipo de bucket proporciona un conjunto único de características para diferentes casos de uso.
Buckets de uso general: se recomiendan para la mayoría de los casos de uso y patrones de acceso y son el tipo de buckets de S3 original. Un bucket de uso general es un contenedor para objetos almacenados en Amazon S3 y puede almacenar cualquier número de objetos en un bucket y en todas las clases de almacenamiento (excepto S3 Express One Zone), de forma que puede almacenar objetos de forma redundante en varias zonas de disponibilidad. Para obtener más información, consulte Creación, configuración y uso de buckets de uso general de Amazon S3.
Por defecto, los buckets de uso general se encuentran en un espacio de nombres global, lo que significa que el nombre de cada bucket debe ser único en todas las Cuentas de AWS de todas las Regiones de AWS dentro de una partición. Una partición es una agrupación de regiones. AWS actualmente tiene cuatro particiones: aws (regiones estándar), aws-cn (regiones de China) y aws-us-gov (AWS GovCloud (US)) y aws-eusc (nube soberana europea). Al crear un bucket de uso general, puede optar por crearlo en el espacio de nombres global compartido o en el espacio de nombres regional de su cuenta. El espacio de nombres regional de su cuenta es una subdivisión del espacio de nombres global en la que solo su cuenta puede crear buckets. Los nuevos buckets de uso general creados en el espacio de nombres regional de su cuenta son exclusivos de su cuenta y nunca podrán ser recreados por otra cuenta. Para obtener más información sobre los espacios de nombres de buckets, consulte Espacios de nombres para buckets de uso general.
nota
De forma predeterminada, todos los buckets de uso general son privados. Sin embargo, puede conceder acceso público a los buckets de uso general. Puede controlar el acceso a los buckets de uso general en el nivel de bucket, prefijo (carpeta) o etiqueta de objeto. Para obtener más información, consulte Control de acceso en Amazon S3.
Buckets de directorio: recomendados para casos de uso de baja latencia y casos de uso de residencia de datos. De forma predeterminada, puede crear hasta 100 buckets de directorio en la Cuenta de AWS, sin límite en cuanto al número de objetos que puede almacenar en un bucket de directorio. Los buckets de directorio organizan los objetos en directorios jerárquicos (prefijos), a diferencia de la estructura de almacenamiento plana de los buckets de uso general. Este tipo de bucket no tiene límites de prefijos y los directorios individuales pueden escalar horizontalmente. Para obtener más información, consulte Cómo trabajar con buckets de directorio.
-
Para casos de uso de baja latencia, puede crear un bucket de directorio en una única zona de disponibilidad de AWS para almacenar datos. Los buckets de directorio en las zonas de disponibilidad admiten la clase de almacenamiento S3 Express One Zone. Con S3 Express One Zone, sus datos se almacenan de forma redundante en varios dispositivos dentro de una única zona de disponibilidad. La clase de almacenamiento S3 Express One Zone se recomienda si la aplicación es sensible al rendimiento y se beneficia de latencias
PUTyGETde un solo dígito de milisegundos. Para obtener más información acerca de cómo crear buckets de directorio en zonas de disponibilidad, consulte Cargas de trabajo de alto rendimiento. -
Para los casos de uso de residencia de datos, puede crear un bucket de directorio en una única zona local dedicada (DLZ) de AWS para almacenar datos. En las zonas locales dedicadas, puede crear buckets de directorio de S3 para almacenar datos en un perímetro de datos específico, lo que a respaldar los casos de uso de residencia y aislamiento de datos. Los buckets de directorio de las zonas locales admiten la clase de almacenamiento Única zona - Almacenamiento de acceso poco frecuente de S3 (S3 One Zone-IA; Z-IA). Para obtener más información acerca de cómo crear buckets de directorio en zonas locales, consulte Cargas de trabajo de residencia de datos.
nota
Los buckets de directorio tienen todo el acceso público desactivado de forma predeterminada. Este comportamiento no se puede cambiar. No puede conceder acceso a objetos almacenados en buckets de directorio. Solo puede conceder acceso a sus buckets de directorio. Para obtener más información, consulte Autenticación y autorización de solicitudes.
Buckets de tablas: recomendadas para almacenar datos tabulares, como transacciones de compra diarias, datos de sensores de streaming o impresiones de anuncios. Los datos tabulares representan datos en columnas y filas, como en una tabla de base de datos. Los buckets de tablas proporcionan almacenamiento de S3 optimizado para cargas de trabajo de análisis y machine learning, con características diseñadas para mejorar continuamente el rendimiento de las consultas y reducir los costos de almacenamiento de las tablas. Las tablas de S3 están diseñadas específicamente para almacenar datos tabulares en formato de Apache Iceberg. Puede consultar datos tabulares en tablas de S3 con motores de consulta populares, incluidos Amazon Athena, Amazon Redshift y Apache Spark. De forma predeterminada, puede crear hasta 10 buckets de tabla por Cuenta de AWS por Región de AWS y hasta 10 000 tablas por bucket de tabla. Para obtener más información, consulte Cómo trabajar con tablas de S3 y buckets de tablas.
nota
Todos los buckets de tablas y las tablas son privados y no pueden hacerse públicos. Solo pueden acceder a estos recursos los usuarios a los que se les haya concedido acceso explícitamente. Para conceder acceso, puede utilizar políticas basadas en recursos de IAM para los buckets de tablas y las tablas, y políticas basadas en identidades de IAM para usuarios y roles. Para obtener más información, consulte Seguridad de tablas de S3.
Buckets vectoriales: los buckets vectoriales de S3 son un tipo de bucket de Amazon S3 personalizado para almacenar y consultar vectores. Los buckets vectoriales utilizan operaciones de la API dedicadas para escribir y consultar datos vectoriales de forma eficiente. Con los buckets vectoriales de S3, puede almacenar incrustaciones vectoriales para modelos de machine learning, realizar búsquedas por similitud y efectuar la integración con servicios como Amazon Bedrock y Amazon OpenSearch.
Los buckets vectoriales de S3 organizan los datos mediante índices vectoriales, que son recursos dentro de un bucket que almacenan y organizan datos vectoriales para realizar búsquedas de similitud eficientes. Cada índice vectorial se puede configurar con dimensiones específicas, métricas de distancia (como la similitud de coseno) y configuraciones de metadatos para optimizarlo según el caso de uso específico. Para obtener más información, consulte Uso de S3 Vectors y buckets vectoriales.
Información adicional sobre todos los tipos de buckets
Cuando crea un bucket, introduzca un nombre de bucket y elija la opción Región de AWS donde residirá el bucket. Después de crear un bucket, no se puede cambiar su nombre ni su región. Los nombres de los buckets deben seguir las reglas de nomenclatura del bucket siguientes:
Cucharones también:
-
Organizan el espacio de nombres de Amazon S3 al más alto nivel. Para los buckets de uso general, este espacio de nombres es
S3. Para los buckets de directorio, este espacio de nombres ess3express. Para los buckets de tabla, este espacio de nombres ess3tables. -
Identifican la cuenta responsable para los cargos de almacenamiento y transferencia de datos.
-
Sirven como la unidad de agregación para informes de uso.
Objetos
Los objetos son las entidades fundamentales almacenadas en Amazon S3. Los objetos se componen de datos de objetos y metadatos. Los metadatos son conjuntos de pares nombre-valor que describen el objeto. Incluyen algunos metadatos predeterminados, como la fecha de la última modificación y los metadatos HTTP estándar, como Content-Type. También puede especificar metadatos personalizados en el momento en que se almacena el objeto.
Cada objeto está almacenado en un bucket. Por ejemplo, si el objeto denominado photos/puppy.jpg se almacena en el bucket de uso general amzn-s3-demo-bucket en la región Oeste de EE. UU. (Oregón), se puede redirigir con la URL https://amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpg. Para obtener más información, consulte Acceso bucket.
Un objeto se identifica de forma exclusiva dentro de un bucket con una clave (nombre) y un ID de versión (si el control de versiones de S3 está habilitado en el bucket). Para obtener más información sobre los objetos, consulte Información general de los objetos de Amazon S3.
Claves
Una clave de objeto (o nombre de clave) es el identificador único de un objeto dentro de un bucket. Cada objeto de un bucket tiene exactamente una clave. La combinación de un bucket, clave de objeto y, opcionalmente, el ID de versión (si el control de versiones de S3 está habilitado para el bucket) identifica de forma única cada objeto. Por tanto, puede pensar en Amazon S3 como una asignación de datos básica entre "bucket + clave + versión" y el objeto en sí.
Se puede acceder a cada objeto de Amazon S3 de forma exclusiva a través de la combinación de punto de conexión de servicio web, nombre del bucket, clave, y de forma opcional, una versión. Por ejemplo, en la URL https://, amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpgamzn-s3-demo-bucketphotos/puppy.jpg es la clave.
Para obtener más información sobre las claves de objetos, consulte Denominación de objetos de Amazon S3.
Control de versiones de S3
Puede usar el control de versiones de S3 para conservar diversas variantes de un objeto en el mismo bucket. Puede utilizar el control de versiones de S3 para conservar, recuperar y restaurar todas las versiones de los objetos almacenados en su bucket de . Puede recuperarse fácilmente de acciones no deseadas del usuario y de errores de la aplicación.
Para obtener más información, consulte Retención de varias versiones de objetos con Control de versiones de S3.
ID de versión.
Si activa el control de versiones de S3 en un bucket, Amazon S3 genera un ID de versión único para cada objeto agregado al bucket. Los objetos que ya existían en el bucket en el momento en que habilita el control de versiones tienen un ID de versión de null. Si modifica estos objetos (o cualquier otro) con otras operaciones, como CopyObject y PutObject, los objetos nuevos obtienen un ID de versión único.
Para obtener más información, consulte Retención de varias versiones de objetos con Control de versiones de S3.
Política de bucket
Una política de bucket es una política AWS Identity and Access Management basada en recursos (IAM) que puede utilizar para conceder permisos de acceso al bucket y a los objetos que contiene. Solo el propietario del bucket puede asociar una política a un bucket. Los permisos asociados a un bucket se aplican a todos los objetos del bucket que son propiedad de la cuenta de propietario del bucket. Las políticas de bucket tienen un límite de tamaño de 20 KB.
Las políticas de buckets utilizan el lenguaje de políticas de acceso basado en JSON que es estándar en AWS. Puede utilizar directivas de bucket para agregar o denegar permisos para los objetos de un bucket. Las políticas de bucket permiten o deniegan solicitudes basadas en los elementos de la política, incluidos el solicitante, las acciones de S3, los recursos y los aspectos o condiciones de la solicitud (por ejemplo: la dirección IP utilizada para realizar la solicitud). Por ejemplo, puede crear una política de bucket que otorgue permisos entre cuentas para cargar objetos en un bucket de S3 y, al mismo tiempo, garantizar que el propietario del bucket tenga el control total de los objetos cargados. Para obtener más información, consulte Ejemplos de políticas de bucket de Amazon S3.
En su política de bucket, puede utilizar caracteres comodín en nombres de recursos de Amazon (ARN) y otros valores para otorgar permisos a un subconjunto de objetos. Por ejemplo, puede controlar el acceso a grupos de objetos que empiezan por unprefijoo terminar con una extensión dada, como.html.
Puntos de acceso de S3
Los puntos de acceso de Amazon S3 se denominan puntos de conexión de red con políticas de acceso dedicadas que describen cómo se puede acceder a los datos mediante ese punto de conexión. Los puntos de acceso se adjuntan a un origen de datos subyacente, como un bucket de uso general, un bucket de directorio o un volumen de FSx para OpenZFS, que puede utilizar para realizar operaciones con objetos de S3, como GetObject y PutObject. Los puntos de acceso simplifican la administración del acceso a los datos a escala para los conjuntos de datos compartidos en Amazon S3.
Cada punto de acceso tiene su propia política de puntos de acceso. Puede configurar los parámetros de Bloquear acceso público para cada punto de acceso adjunto a un bucket. Puede configurar cualquier punto de acceso para que acepte solo las solicitudes procedentes de una nube virtual privada (VPC) con el fin de restringir el acceso a los datos de Amazon S3 a una red privada.
Para obtener más información acerca de los puntos de acceso para los buckets de uso general, consulte Administración del acceso a conjuntos de datos compartidos con puntos de acceso. Para obtener más información acerca de los puntos de acceso para buckets de directorio, consulte Administración del acceso a conjuntos de datos compartidos en buckets de directorio con puntos de acceso.
Listas de control de acceso (ACL)
Puede utilizar las ACL para conceder permisos de lectura y escritura para buckets de uso general y objetos individuales a usuarios autorizados. Cada bucket de uso general y objeto tiene una ACL como un subrecurso. La ACL define qué Cuentas de AWS o grupos cuentan con acceso y el tipo de acceso que tienen. Las ACL son un mecanismo de control de acceso anterior a IAM. Para obtener más información acerca de las ACL, consulte lo siguiente Información general de las Listas de control de acceso (ACL).
S3 Object Ownership es una configuración de bucket de Amazon S3 que puede usar para controlar la propiedad de los objetos que se cargan en el bucket y para activar o desactivar las ACL. De forma predeterminada, la propiedad de objetos se establece en la configuración impuesta por el propietario del bucket. Además, todas las ACL están deshabilitadas. Cuando las ACL están deshabilitadas, el propietario del bucket posee todos los objetos del bucket y administra su acceso de forma exclusiva mediante políticas de administración de acceso.
La mayoría de los casos de uso modernos de Amazon S3 ya no requieren el uso de ACL. Le recomendamos desactivar las ACL, excepto en circunstancias en las que necesite controlar el acceso a cada objeto de manera individual. Si las ACL están desactivadas, puede usar políticas para controlar el acceso a todos los objetos del bucket, independientemente de quién haya subido los objetos al bucket. Para obtener más información, consulte Control de la propiedad de los objetos y desactivación de las ACL del bucket.
Regions
Puede elegir la Región de AWS geográfica donde Amazon S3 almacenará los buckets que usted cree. Puede elegir una región para optimizar la latencia, minimizar los costos o cumplir con requisitos legales. Los objetos almacenados en una Región de AWS nunca abandonan la región, a menos que se transfieran o repliquen expresamente a otra región. Por ejemplo, los objetos almacenados en la región UE (Irlanda) nunca salen de ella.
nota
Solo puede tener acceso a Amazon S3 y sus características en las Regiones de AWS que estén habilitadas para su cuenta. Para obtener más información acerca de cómo habilitar una región para crear y administrar recursos de AWS, consulte Administración de Regiones de AWS en la Referencia general de AWS.
Para ver una lista de las regiones y los puntos de conexión de Amazon S3, consulte Regiones y puntos de conexión en la Referencia general de AWS.
Modelo de consistencia de datos de Amazon S3
Amazon S3 proporciona una sólida coherencia de lectura tras escritura para las operaciones PUT y DELETE de objetos del bucket de Amazon S3 en todas las Regiones de AWS. Esto se aplica tanto a las escrituras en objetos nuevos como a las solicitudes PUT que sobrescriben objetos existentes y las solicitudes DELETE. Además, las operaciones de lectura en Amazon S3 Select, las listas de control de acceso de Amazon S3, las etiquetas de objeto de Amazon S3 y los metadatos de objetos (p. ej., el objeto HEAD) son muy consistentes.
Las actualizaciones en una sola clave son atómicas. Por ejemplo, si aplica PUT a una clave existente de un hilo y realiza una operación GET en la misma clave desde un segundo hilo simultáneamente, obtendrá los datos antiguos o los datos nuevos, pero nunca datos parciales o dañados.
Amazon S3 consigue una alta disponibilidad mediante la reproducción de los datos de varios servidores ubicados en los centros de datos de AWS. Si una solicitud PUT se realiza correctamente, sus datos se almacenan de forma segura. Cualquier lectura (solicitud GET o LIST) que se inicie después de recibir una respuesta PUT exitosa devolverá los datos escritos por la solicitud PUT. A continuación se muestran algunos ejemplos de este comportamiento:
-
Un proceso escribe un nuevo objeto en Amazon S3 y enumera inmediatamente claves dentro del bucket. El nuevo objeto aparece en la lista.
-
Un proceso reemplaza un objeto existente e inmediatamente intenta leerlo. Amazon S3 devuelve los datos nuevos.
-
Un proceso elimina un objeto existente e inmediatamente intenta leerlo. Amazon S3 no devuelve ningún dato ya que el objeto se ha eliminado.
-
Un proceso elimina un objeto existente y enumera inmediatamente claves dentro del bucket. El objeto no aparece en la lista.
nota
-
Amazon S3 no admite el bloqueo de objetos para escritores simultáneos. Si se realizan dos solicitudes PUT simultáneamente a la misma clave, prevalece la solicitud con la marca temporal más reciente. Si esto es un problema, debe crear un mecanismo de bloque de objeto en su aplicación.
-
Las actualizaciones se basan en claves. No se pueden realizar actualizaciones atómicas en las claves. Por ejemplo, no puede realizar la actualización de una clave que depende de la actualización de otra clave, a menos que diseñe esta funcionalidad en su aplicación.
Las configuraciones del bucket tienen un modelo de consistencia final. En concreto, esto significa que:
-
Si elimina un bucket e inmediatamente muestra todos los buckets, es posible que el bucket eliminado aún aparezca en la lista.
-
Si habilita el control de versiones en un bucket por primera vez, es posible que el cambio se propague por completo en un instante. Para emitir operaciones de escritura (solicitudes PUT o DELETE) en los objetos del bucket, se recomienda que espere 15 minutos después de habilitar el control de versiones.
Aplicaciones simultáneas
En esta sección se proporcionan ejemplos del comportamiento que se espera de Amazon S3 cuando varios clientes escriben en los mismos elementos.
En este ejemplo, tanto W1 (escritura 1) como W2 (escritura 2) se completan antes del inicio de R1 (lectura 1) y R2 (lectura 2). Debido a que S3 es altamente consistente, tanto R1 como R2 devuelven color = ruby.
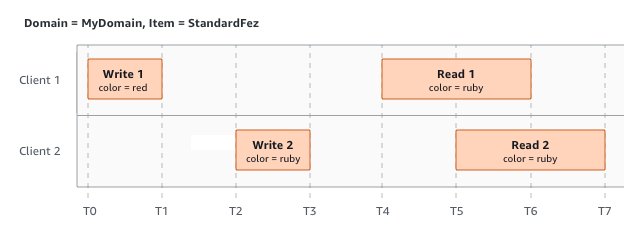
En el siguiente ejemplo, W2 no se completa antes del inicio de R1. Por lo tanto, R1 podría devolver color = ruby o color = garnet. Sin embargo, dado que W1 y W2 finalizan antes del inicio de R2, R2 devuelve color =
garnet.

En el último ejemplo, W2 se inicia antes de que W1 haya recibido una confirmación. Por lo tanto, estas escrituras se consideran simultáneas. Amazon S3 utiliza internamente la semántica “last-writer-wins” (el último en escribir gana) para determinar qué escritura tiene prioridad. Sin embargo, el orden en el que Amazon S3 recibe las solicitudes y el orden en el que las aplicaciones envían las confirmaciones no se puede predecir debido a factores como la latencia de la red. Por ejemplo, W2 puede ser iniciado por una instancia de Amazon EC2 en la misma región, mientras que W1 podría ser iniciado por un host que está más lejos. La mejor manera de determinar el valor final es realizar una lectura después de que se ha recibido la confirmación de ambas escrituras.

Servicios relacionados
Una vez que carga sus datos en Amazon S3, puede utilizarlos con otros servicios de AWS. Los siguientes servicios son los que puede utilizar con más frecuencia:
-
Amazon Elastic Compute Cloud (Amazon EC2)
: proporciona capacidad de computación escalable y segura en Nube de AWS. El uso de Amazon EC2 elimina la necesidad de invertir inicialmente en hardware, de manera que puede desarrollar e implementar aplicaciones en menos tiempo. Puede usar Amazon EC2 para lanzar tantos servidores virtuales como necesite, configurar la seguridad y las redes, y administrar el almacenamiento. -
Amazon EMR
: ayuda a las empresas, investigadores, analistas de datos y desarrolladores procesar de forma fácil y rentable grandes volúmenes de datos. Amazon EMR utiliza un marco Hadoop alojado que se ejecuta en la infraestructura basada en la web de Amazon EC2 y Amazon S3. -
AWSFamilia Snow
: ayuda a los clientes que necesitan ejecutar operaciones en entornos austeros, no pertenecientes al centro de datos, y en ubicaciones en las que no existe una conectividad de red coherente. Puede usar dispositivos de Snow Family AWS para acceder localmente y de manera rentable al almacenamiento y la potencia informática de Nube de AWS en lugares en los que posiblemente no haya una conexión a Internet. -
AWS Transfer Family
– proporciona compatibilidad totalmente administrada para transferencias de archivos directamente desde Amazon S3 o Amazon Elastic File System (Amazon EFS) mediante el protocolo de transferencia de archivos (SFTP) de Secure Shell (SSH), el protocolo de transferencia de archivos a través de SSL (FTPS) y el protocolo de transferencia de archivos (FTP).
Acceso a Amazon S3
Puede trabajar con Amazon S3 de cualquiera de las siguientes formas:
Consola de administración de AWS
La consola es una interfaz de usuario basada en la web para administrar Amazon S3 y los recursos de AWS. Si se ha registrado para Cuenta de AWS, puede acceder a la consola de Amazon S3 iniciando sesión en Consola de administración de AWS y eligiendo S3 en la página de inicio de Consola de administración de AWS.
AWS Command Line Interface
Puede utilizar elAWSHerramientas de línea de comandos para emitir comandos o compilar scripts en la línea de comandos de su sistema con el fin de ejecutarAWS(incluidas las tareas S3).
AWS Command Line Interface (AWS CLI)
AWSSDK de
AWS ofrece SDK (kits de desarrollo de software) que se componen de bibliotecas y código de muestra para diversos lenguajes de programación y plataformas (Java, Python, Ruby, .NET, iOS, Android, etc.). Los AWS SDK proporcionan una forma cómoda de crear acceso a S3 y AWS. Amazon S3 es un servicio de REST. Puede enviar solicitudes a Amazon S3 usando las bibliotecas de SDK de AWS, que envuelven la API de REST de Amazon S3 subyacentes y simplifican sus tareas de programación. Por ejemplo, los SDK se encargan de tareas como calcular firmas, firmar solicitudes criptográficamente, gestionar los errores y reintentar las solicitudes de forma automática. Para obtener información sobre los SDK de AWS (por ejemplo: cómo descargarlos e instalarlos), consulte Herramientas para AWS
Toda interacción con Amazon S3 es o autenticada o anónima. Si utiliza el SDK de AWS, las bibliotecas computan la firma para la autenticación a partir de las claves que usted proporciona. Para obtener más información acerca de cómo realizar solicitudes a Amazon S3, consulte Making requests.
API de REST de Amazon S3
La arquitectura de Amazon S3 está diseñada con un lenguaje de programación neutro y utiliza interfaces admitidas por AWS para almacenar y recuperar objetos. Puede acceder a S3 yAWSmediante programación mediante la API de REST de Amazon S3. La API de REST es una interfaz HTTP para Amazon S3. Con la API de REST, usted puede utilizar solicitudes HTTP estándar para crear, recuperar y eliminar buckets y objetos.
Puede utilizar cualquier conjunto de herramientas que admita HTTP para utilizar la API de REST. Incluso puede utilizar un navegador para recuperar objetos, siempre y cuando se puedan leer de forma anónima.
La API de REST utiliza códigos de estado y encabezados HTTP estándar, para que los conjuntos de herramientas y los navegadores estándar funcionen según lo previsto. En algunas áreas, hemos añadido una funcionalidad al HTTP (por ejemplo: añadimos encabezados para admitir el control de acceso). En estos casos, hicimos todo lo posible para añadir la nueva funcionalidad de manera que coincida con el estilo del uso de HTTP estándar.
Si realiza llamadas directas a la API de REST en su aplicación, debe escribir el código para computar la firma y añadirla a la solicitud. Para obtener más información acerca de cómo realizar solicitudes a Amazon S3, consulte Making requests en la Amazon S3 API Reference.
nota
La compatibilidad con la API de SOAP por HTTP está obsoleta, pero aún se encuentra disponible con HTTPS. Las características más recientes de Amazon S3 no son compatibles con SOAP. Le recomendamos que utilice la API de REST o los SDK de AWS.
Pago de Amazon S3
Los precios de Amazon S3 están diseñados de manera que no tenga que planificar los requisitos de almacenamiento de su aplicación. La mayoría de los proveedores de almacenamiento requieren que adquiera una cantidad predeterminada de almacenamiento y capacidad de transferencia de red. En este escenario, si excede esa capacidad, su servicio se cancela o usted debe pagar cargos excesivos. Si no excede esa capacidad, paga como si la hubiera utilizado toda.
Amazon S3 le cobra solo lo que realmente utiliza, sin costes ocultos ni cargos excesivos. Esto ofrece a los desarrolladores un servicio de costo variable que puede crecer junto con sus empresas mientras disfrutan de las ventajas de costos que ofrece la infraestructura de AWS. Para obtener más información, consulte Precios de Amazon S3
Cuando se registra en AWS, su Cuenta de AWS se registra automáticamente en todos los servicios de AWS, incluido Amazon S3. No obstante, solo se le cobrará por los servicios que utilice. Si es cliente nuevo de Amazon S3, puede comenzar con Amazon S3 de forma gratuita. Para obtener más información, consulte AWS capa gratuita
Para ver su factura, vaya al Panel de Billing and Cost Management en la consola de Administración de facturación y costos de AWS
Conformidad con DSS PCI
Amazon S3 admite el procesamiento, el almacenamiento y la transmisión de datos de tarjetas de crédito por parte de un comerciante o proveedor de servicios y se ha validado por estar conforme con el Estándar de Seguridad de Datos para la Industria de Tarjeta de Pago (PCI DSS). Para obtener más información acerca de PCI DSS, incluido cómo solicitar una copia del Paquete de conformidad con PCI de AWS, consulte PCI DSS Nivel 1
