Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Latih DeepRacer model AWS pertama Anda
Panduan ini menunjukkan cara melatih model pertama Anda menggunakan konsol AWS. DeepRacer
Latih model pembelajaran penguatan menggunakan DeepRacer konsol AWS
Pelajari di mana menemukan tombol Buat model di DeepRacer konsol AWS untuk memulai perjalanan pelatihan model Anda.
Untuk melatih model pembelajaran penguatan
-
Jika ini adalah pertama kalinya Anda menggunakan AWS DeepRacer, pilih Buat model dari halaman landing layanan atau pilih Memulai di bawah judul pembelajaran Penguatan di panel navigasi utama.
-
Pada halaman Memulai dengan pembelajaran penguatan, di bawah Langkah 2: Buat model, pilih Buat model.
Atau, pilih Model Anda di bawah judul Pembelajaran penguatan dari panel navigasi utama. Pada halaman Model Anda, pilih Buat model.
Tentukan nama model dan lingkungan
Beri nama model Anda dan pelajari cara memilih trek simulasi yang tepat untuk Anda.
Untuk menentukan nama model dan lingkungan
-
Pada halaman Buat model, di bawah Detail pelatihan, masukkan nama untuk model Anda.
-
Secara opsional, tambahkan deskripsi pekerjaan pelatihan.
-
Untuk mempelajari selengkapnya tentang menambahkan tag opsional, lihatPenandaan.
-
Dalam simulasi Lingkungan, pilih trek untuk dijadikan lingkungan pelatihan bagi DeepRacer agen AWS Anda. Di bawah Arah trek, pilih Searah jarum jam atau berlawanan arah jarum jam. Kemudian pilih Selanjutnya.
Untuk percobaan pertama Anda, pilih lintasan dengan bentuk sederhana dan belokan yang halus. Dalam pengulangan berikutnya, Anda dapat memilih lintasan yang lebih kompleks untuk lebih meningkatkan model Anda. Untuk melatih model untuk peristiwa balap tertentu, pilih lintasan yang paling mirip dengan lintasan peristiwa.
-
Pilih Berikutnya di bagian bawah halaman.
Pilih jenis balapan dan algoritma pelatihan
DeepRacer Konsol AWS memiliki tiga jenis balapan dan dua algoritma pelatihan untuk dipilih. Pelajari mana yang sesuai untuk tingkat keahlian dan tujuan pelatihan Anda.
Untuk memilih jenis balapan dan algoritma pelatihan
-
Pada halaman Buat model, di bawah Jenis ras, pilih Time trial, Object avoidance, atau H. ead-to-bot
Untuk menjalankan pertama Anda, kami sarankan memilih Time trial. Untuk panduan mengoptimalkan konfigurasi sensor agen Anda untuk jenis balapan ini, lihatSesuaikan DeepRacer pelatihan AWS untuk uji waktu.
-
Secara opsional, pada proses selanjutnya, pilih Penghindaran objek untuk mengelilingi rintangan stasioner yang ditempatkan di lokasi tetap atau acak di sepanjang trek yang dipilih. Untuk informasi selengkapnya, lihat DeepRacer Pelatihan AWS khusus untuk balapan penghindaran objek.
-
Pilih Lokasi tetap untuk menghasilkan kotak di lokasi tetap yang ditunjuk pengguna di dua jalur trek atau pilih Lokasi acak untuk menghasilkan objek yang didistribusikan secara acak di dua jalur di awal setiap episode simulasi pelatihan Anda.
-
Selanjutnya, pilih nilai untuk Jumlah objek di trek.
-
Jika Anda memilih Lokasi tetap, Anda dapat menyesuaikan penempatan setiap objek di trek. Untuk penempatan Lane, pilih antara jalur dalam dan jalur luar. Secara default, objek didistribusikan secara merata di seluruh trek. Untuk mengubah seberapa jauh antara garis awal dan garis akhir suatu objek, masukkan persentase jarak antara tujuh dan 90 pada Lokasi (%) antara bidang awal dan akhir.
-
-
Secara opsional, untuk lari yang lebih ambisius, pilih Head-to-bot balapan untuk berpacu melawan hingga empat kendaraan bot yang bergerak dengan kecepatan konstan. Untuk mempelajari selengkapnya, lihat DeepRacer Pelatihan AWS khusus untuk balapan head-to-bot.
-
Di bawah Pilih jumlah kendaraan bot, pilih dengan berapa banyak kendaraan bot yang Anda ingin agen Anda latih.
-
Selanjutnya, pilih kecepatan dalam milimeter per detik di mana Anda ingin kendaraan bot berkeliling trek.
-
Secara opsional, centang kotak Aktifkan perubahan jalur untuk memberi kendaraan bot kemampuan untuk mengubah jalur secara acak setiap 1-5 detik.
-
-
Di bawah algoritma Pelatihan dan hiperparameter, pilih algoritma Soft Actor Critic (SAC) atau Proximal Policy Optimization (PPO). Di DeepRacer konsol AWS, model SAC harus dilatih dalam ruang aksi berkelanjutan. Model PPO dapat dilatih baik dalam ruang aksi berkelanjutan atau terpisah.
-
Di bawah Algoritma pelatihan dan hiperparameter, gunakan nilai hyperparameter default apa adanya.
Kemudian, untuk meningkatkan performa pelatihan, perluas Hyperparameter dan modifikasi nilai default hyperparameter sebagai berikut:
-
Untuk Ukuran batch keturunan gradien, pilih opsi yang tersedia.
-
Untuk Jumlah epoch, atur nilai yang valid.
-
Untuk Tingkat pembelajaran, atur nilai yang valid.
-
Untuk Nilai alfa SAC (hanya algoritme SAC), atur nilai yang valid.
-
Untuk Entropi, atur nilai yang valid.
-
Untuk Faktor diskon, atur nilai yang valid.
-
Untuk Tipe kerugian, pilih opsi yang tersedia.
-
Untuk Jumlah episode pengalaman antara setiap iterasi pembaruan kebijakan, atur nilai yang valid.
Untuk informasi selengkapnya tentang hyperparameter, lihat Secara sistematis menyetel hiperparameter.
-
-
Pilih Berikutnya.
Tentukan ruang aksi
Pada halaman Tentukan ruang tindakan, jika Anda memilih untuk berlatih dengan algoritma Soft Actor Critic (SAC), ruang tindakan default Anda adalah ruang tindakan berkelanjutan. Jika Anda memilih untuk berlatih dengan algoritma Proximal Policy Optimization (PPO), pilih antara Continuous Action Space dan Discrete Action Space. Untuk mempelajari lebih lanjut tentang bagaimana setiap ruang aksi dan algoritme membentuk pengalaman pelatihan agen, lihatRuang DeepRacer aksi AWS dan fungsi reward.
-
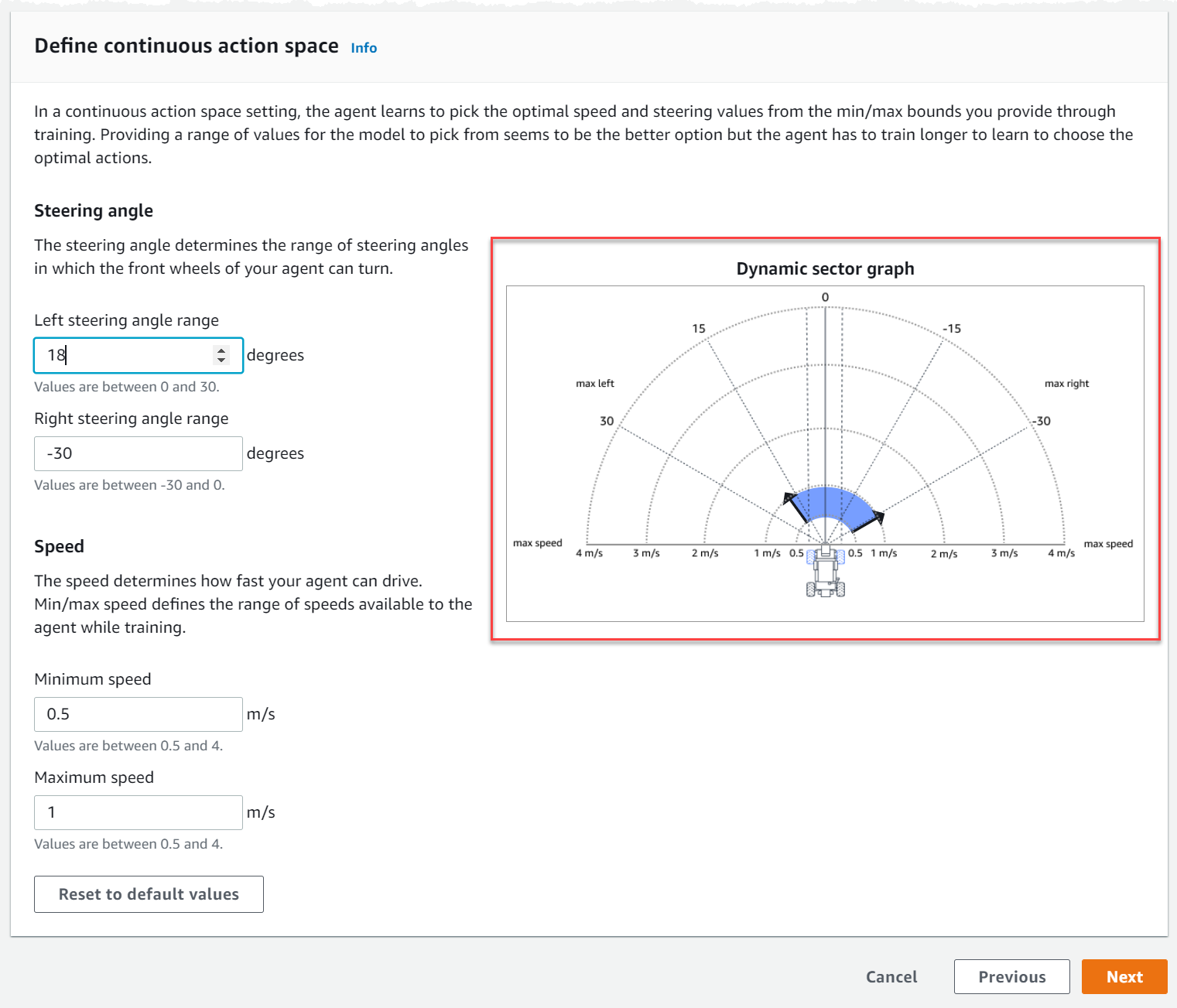
Di bawah Tentukan ruang aksi kontinu, pilih derajat rentang sudut kemudi kiri dan rentang sudut kemudi kanan Anda.
Coba masukkan derajat yang berbeda untuk setiap rentang sudut kemudi dan perhatikan visualisasi perubahan rentang Anda untuk mewakili pilihan Anda pada grafik sektor Dinamis.
-
Di bawah Kecepatan, masukkan kecepatan minimum dan maksimum untuk agen Anda dalam milimeter per detik.
Perhatikan bagaimana perubahan Anda tercermin pada grafik sektor Dinamis.
-
Secara opsional, pilih Reset ke nilai default untuk menghapus nilai yang tidak diinginkan. Kami mendorong mencoba nilai yang berbeda pada grafik untuk bereksperimen dan belajar.
-
Pilih Berikutnya.
-
Pilih nilai untuk granularitas sudut kemudi dari daftar dropdown.
-
Pilih nilai dalam derajat antara 1-30 untuk sudut kemudi Maksimum agen Anda.
-
Pilih nilai untuk granularitas Kecepatan dari daftar dropdown.
-
Pilih nilai dalam milimeter per detik antara 0,1-4 untuk kecepatan Maksimum agen Anda.
-
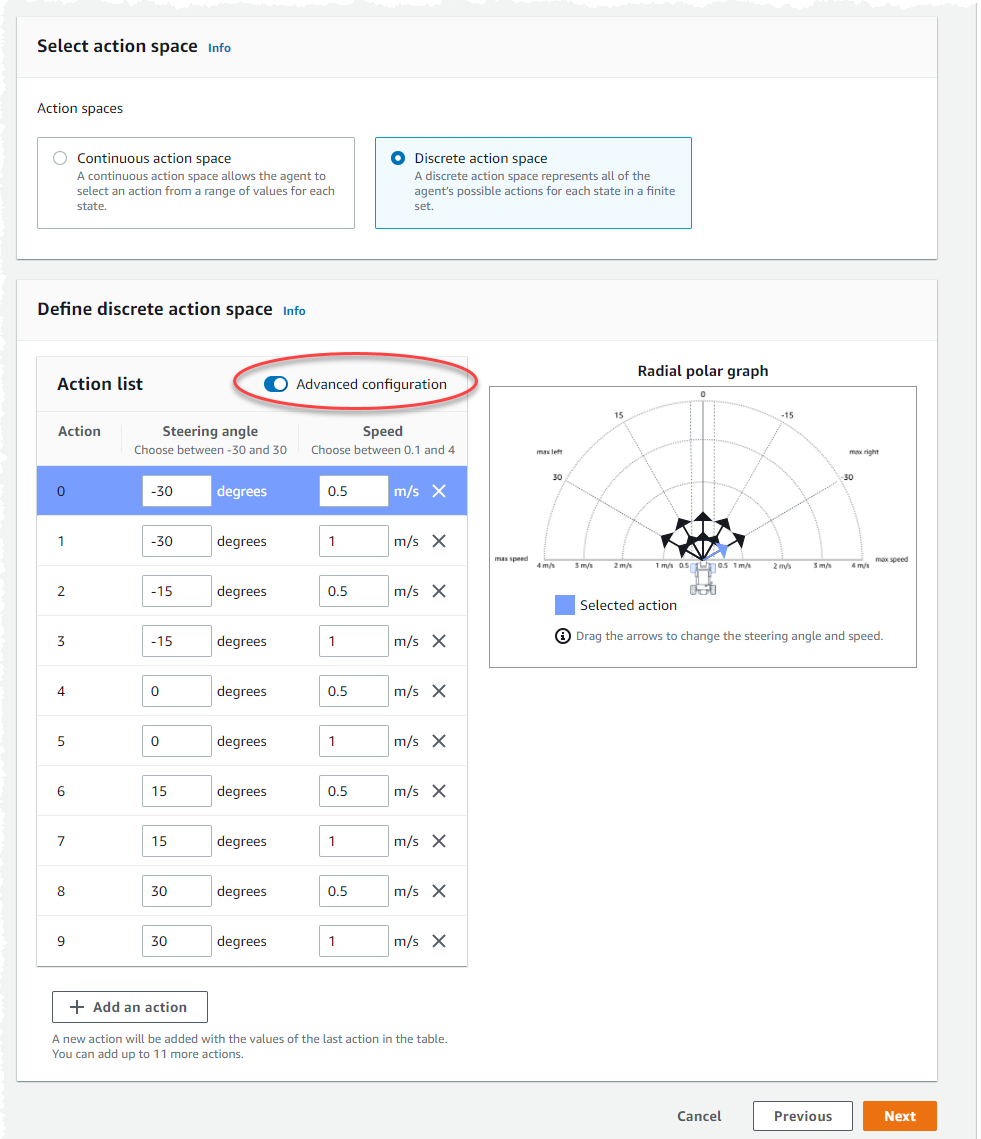
Gunakan pengaturan tindakan default pada daftar Tindakan atau, secara opsional, aktifkan Konfigurasi lanjutan untuk menyempurnakan pengaturan Anda. Jika Anda memilih Sebelumnya atau menonaktifkan Konfigurasi lanjutan setelah menyesuaikan nilai, Anda kehilangan perubahan.
-
Masukkan nilai dalam derajat antara -30 dan 30 di kolom sudut kemudi.
-
Masukkan nilai antara 0,1 dan 4 dalam milimeter per detik hingga sembilan tindakan di kolom Kecepatan.
-
Secara opsional, pilih Tambahkan tindakan untuk menambah jumlah baris dalam daftar tindakan.
-
Secara opsional, pilih X pada baris untuk menghapusnya.
-
-
Pilih Berikutnya.
Pilih mobil virtual
Pelajari cara memulai dengan mobil virtual. Dapatkan mobil kustom baru, pekerjaan cat, dan modifikasi dengan bersaing di Divisi Terbuka setiap bulan.
Untuk memilih mobil virtual
-
Pada halaman Pilih shell kendaraan dan konfigurasi sensor, pilih shell yang kompatibel dengan jenis balapan dan ruang aksi Anda. Jika Anda tidak memiliki mobil di garasi Anda yang cocok, pergi ke garasi Anda di bawah judul pembelajaran Penguatan di panel navigasi utama untuk membuatnya.
Untuk pelatihan Time trial, konfigurasi sensor default dan kamera lensa tunggal The Original DeepRacer adalah semua yang Anda butuhkan, tetapi semua shell dan konfigurasi sensor lainnya berfungsi selama ruang aksi cocok. Untuk informasi selengkapnya, lihat Sesuaikan DeepRacer pelatihan AWS untuk uji waktu.
Untuk pelatihan penghindaran Objek, kamera stereo sangat membantu, tetapi satu kamera juga dapat digunakan untuk menghindari hambatan stasioner di lokasi tetap. Sensor LiDAR bersifat opsional. Lihat Ruang DeepRacer aksi AWS dan fungsi reward.
Untuk ead-to-bot pelatihan H, selain kamera tunggal atau kamera stereo, unit LiDAR optimal untuk mendeteksi dan menghindari titik buta saat melewati kendaraan bergerak lainnya. Untuk mempelajari selengkapnya, lihat DeepRacer Pelatihan AWS khusus untuk balapan head-to-bot.
-
Pilih Berikutnya.
Sesuaikan fungsi hadiah Anda
Fungsi penghargaan adalah inti dari pembelajaran penguatan. Belajarlah untuk menggunakannya untuk memberi insentif pada mobil Anda (agen) untuk mengambil tindakan spesifik saat menjelajahi trek (lingkungan). Seperti mendorong dan mengecilkan perilaku tertentu pada hewan peliharaan, Anda dapat menggunakan alat ini untuk mendorong mobil Anda menyelesaikan putaran secepat mungkin dan mencegahnya keluar dari trek atau bertabrakan dengan benda.
Untuk menyesuaikan fungsi hadiah Anda
-
Pada halaman Buat model, di bawah Fungsi penghargaan, gunakan contoh fungsi penghargaan default sebagaimana adanya untuk model pertama Anda.
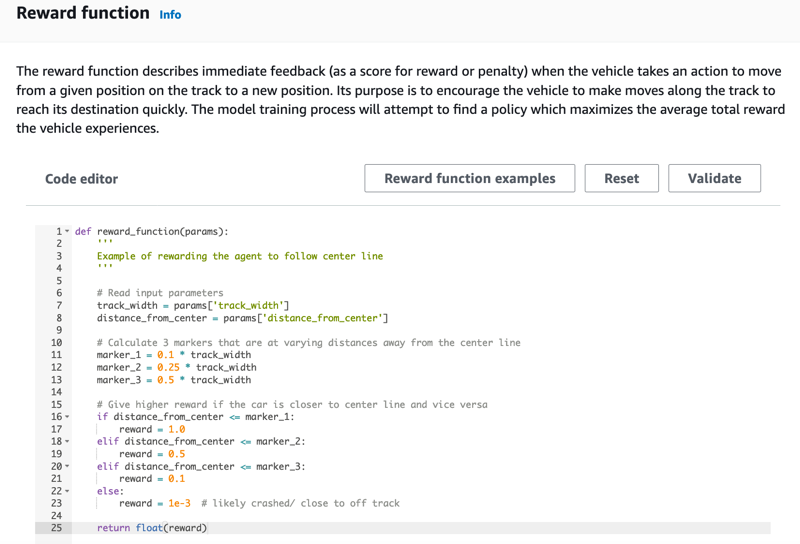
Nantinya, Anda bisa memilih Contoh fungsi penghargaan untuk memilih fungsi contoh yang lain kemudian pilih Gunakan kode untuk menerima fungsi penghargaan yang dipilih.
Ada empat contoh fungsi yang dapat Anda mulai. Mereka menggambarkan bagaimana mengikuti track center (default), bagaimana menjaga agen di dalam batas trek, bagaimana mencegah mengemudi zig-zag, dan bagaimana menghindari menabrak rintangan stasioner atau kendaraan bergerak lainnya.
Untuk mempelajari selengkapnya tentang fungsi penghargaan, lihat Referensi fungsi DeepRacer penghargaan AWS.
-
Dalam kondisi Stop, biarkan nilai waktu maksimum default apa adanya, atau tetapkan nilai baru untuk menghentikan pekerjaan pelatihan, untuk membantu mencegah pekerjaan pelatihan yang berjalan lama (dan kemungkinan lari).
Saat bereksperimen pada tahap awal pelatihan, Anda harus memulai dengan nilai kecil untuk parameter ini dan kemudian secara bertahap latih untuk jumlah waktu yang lebih lama.
-
Di bawah Kirim secara otomatis ke AWS DeepRacer, Kirim model ini ke AWS DeepRacer secara otomatis setelah pelatihan selesai dan mendapatkan kesempatan untuk memenangkan hadiah diperiksa secara default. Secara opsional, Anda dapat memilih untuk tidak memasukkan model Anda dengan memilih tanda centang.
-
Di bawah persyaratan Liga, pilih Negara tempat tinggal Anda dan setujui syarat dan ketentuan dengan mencentang kotak.
-
Pilih Buat model untuk mulai membuat model dan menyediakan instance pekerjaan pelatihan.
-
Setelah pengiriman, perhatikan tugas pelatihan Anda diinisialisasi lalu kemudian jalankan.
Proses inisialisasi membutuhkan waktu beberapa menit untuk berubah dari Inisialisasi menjadi Sedang berlangsung.
-
Perhatikan Grafik penghargaan dan Aliran video simulasi untuk mengamati kemajuan tugas pelatihan Anda. Anda dapat menekan tombol refresh di sebelah Grafik penghargaan secara berkala untuk menyegarkan Grafik penghargaan sampai tugas pelatihan selesai.
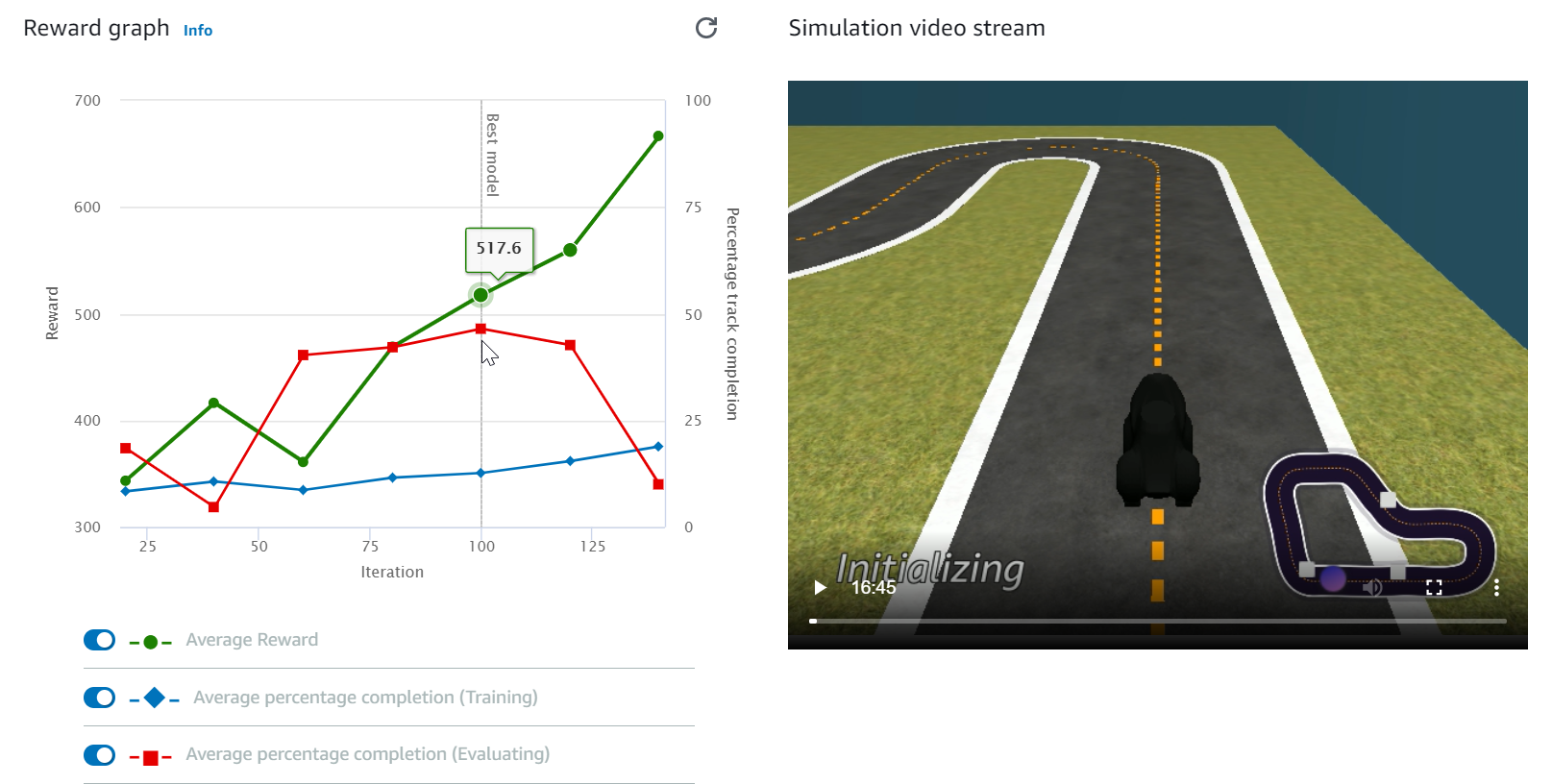
Pekerjaan pelatihan berjalan di AWS Cloud, jadi Anda tidak perlu membiarkan DeepRacer konsol AWS tetap terbuka. Anda selalu dapat kembali ke konsol untuk memeriksa model Anda kapan saja saat pekerjaan sedang berlangsung.
Jika jendela aliran video Simulasi atau tampilan grafik Reward menjadi tidak responsif, segarkan halaman browser untuk mendapatkan kemajuan pelatihan diperbarui.
