Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Praktik terbaik operasional untuk OpenSearch Layanan Amazon
Bab ini memberikan praktik terbaik untuk mengoperasikan domain OpenSearch Layanan Amazon dan menyertakan pedoman umum yang berlaku untuk banyak kasus penggunaan. Setiap beban kerja unik, dengan karakteristik unik, jadi tidak ada rekomendasi umum yang tepat untuk setiap kasus penggunaan. Praktik terbaik yang paling penting adalah menerapkan, menguji, dan menyetel domain Anda dalam siklus berkelanjutan untuk menemukan konfigurasi, stabilitas, dan biaya yang optimal untuk beban kerja Anda.
Topik
Pemantauan dan peringatan
Praktik terbaik berikut berlaku untuk memantau domain OpenSearch Layanan Anda.
Konfigurasikan CloudWatch alarm
OpenSearch Layanan memancarkan metrik kinerja ke Amazon. CloudWatch Tinjau metrik cluster dan instans Anda secara teratur dan konfigurasikan CloudWatch alarm yang direkomendasikan berdasarkan kinerja beban kerja Anda.
Aktifkan penerbitan log
OpenSearch Layanan mengekspos log OpenSearch kesalahan, mencari log lambat, mengindeks log lambat, dan log audit di Amazon CloudWatch Logs. Cari log lambat, pengindeksan log lambat, dan log kesalahan berguna untuk memecahkan masalah kinerja dan stabilitas. Log audit, yang hanya tersedia jika Anda mengaktifkan kontrol akses berbutir halus untuk melacak aktivitas pengguna. Untuk informasi selengkapnya, lihat Log
Cari log lambat dan pengindeksan log lambat adalah alat penting untuk memahami dan memecahkan masalah kinerja operasi pencarian dan pengindeksan Anda. Aktifkan pencarian dan indeks pengiriman log lambat untuk semua domain produksi. Anda juga harus mengonfigurasi ambang logging —jika tidak, tidak CloudWatch akan menangkap log.
Strategi pecahan
Pecahan mendistribusikan beban kerja Anda di seluruh node data di domain OpenSearch Layanan Anda. Indeks yang dikonfigurasi dengan benar dapat membantu meningkatkan kinerja domain secara keseluruhan.
Ketika Anda mengirim data ke OpenSearch Layanan, Anda mengirim data tersebut ke indeks. Indeks analog dengan tabel database, dengan dokumen sebagai baris, dan bidang sebagai kolom. Saat Anda membuat indeks, Anda memberi tahu OpenSearch berapa banyak pecahan utama yang ingin Anda buat. Pecahan utama adalah partisi independen dari kumpulan data lengkap. OpenSearch Layanan secara otomatis mendistribusikan data Anda di seluruh pecahan utama dalam indeks. Anda juga dapat mengkonfigurasi replika indeks. Setiap pecahan replika terdiri dari satu set lengkap salinan pecahan utama untuk indeks itu.
OpenSearch Layanan memetakan pecahan untuk setiap indeks di seluruh node data di cluster Anda. Ini memastikan bahwa pecahan primer dan replika untuk indeks berada pada node data yang berbeda. Replika pertama memastikan bahwa Anda memiliki dua salinan data dalam indeks. Anda harus selalu menggunakan setidaknya satu replika. Replika tambahan memberikan redundansi tambahan dan kapasitas baca.
OpenSearch mengirimkan permintaan pengindeksan ke semua node data yang berisi pecahan milik indeks. Ini mengirimkan permintaan pengindeksan pertama ke node data yang berisi pecahan primer, dan kemudian ke node data yang berisi pecahan replika. Permintaan pencarian dirutekan oleh node koordinator ke pecahan primer atau replika untuk semua pecahan milik indeks.
Misalnya, untuk indeks dengan lima pecahan utama dan satu replika, setiap permintaan pengindeksan menyentuh 10 pecahan. Sebaliknya, permintaan pencarian dikirim ke n pecahan, di mana n adalah jumlah pecahan primer. Untuk indeks dengan lima pecahan utama dan satu replika, setiap permintaan pencarian menyentuh lima pecahan (primer atau replika) dari indeks tersebut.
Tentukan jumlah pecahan dan simpul data
Gunakan praktik terbaik berikut untuk menentukan jumlah pecahan dan simpul data untuk domain Anda.
Ukuran pecahan — Ukuran data pada disk adalah hasil langsung dari ukuran data sumber Anda, dan itu berubah saat Anda mengindeks lebih banyak data. source-to-indexRasionya dapat sangat bervariasi, dari 1:10 hingga 10:1 atau lebih, tetapi biasanya sekitar 1:1,10. Anda dapat menggunakan rasio itu untuk memprediksi ukuran indeks pada disk. Anda juga dapat mengindeks beberapa data dan mengambil ukuran indeks aktual untuk menentukan rasio beban kerja Anda. Setelah Anda memiliki ukuran indeks yang diprediksi, tetapkan jumlah pecahan sehingga setiap pecahan akan berada di antara 10—30 GiB (untuk beban kerja pencarian), atau antara 30-50 GiB (untuk beban kerja log). 50 GiB harus maksimal — pastikan untuk merencanakan pertumbuhan.
Jumlah pecahan — Distribusi pecahan ke node data memiliki dampak besar pada kinerja domain. Ketika Anda memiliki indeks dengan beberapa pecahan, cobalah untuk membuat pecahan menghitung kelipatan dari jumlah node data. Ini membantu memastikan bahwa pecahan didistribusikan secara merata di seluruh node data, dan mencegah node panas. Misalnya, jika Anda memiliki 12 pecahan primer, jumlah node data Anda harus 2, 3, 4, 6, atau 12. Namun, jumlah pecahan adalah sekunder dari ukuran pecahan — jika Anda memiliki 5 GiB data, Anda tetap harus menggunakan pecahan tunggal.
Pecahan per node data — Jumlah total pecahan yang dapat dipegang oleh node sebanding dengan memori heap Java virtual machine (JVM) node. Bertujuan untuk 25 pecahan atau kurang per GiB memori heap. Misalnya, sebuah node dengan memori heap 32 GiB harus menampung tidak lebih dari 800 pecahan. Meskipun distribusi pecahan dapat bervariasi berdasarkan pola beban kerja Anda, ada batas 1.000 pecahan per node untuk Elasticsearch dan OpenSearch 1,1 hingga 2,15 dan 4.000 untuk 2,17 ke atas. OpenSearch API kucing/alokasi
Rasio pecahan terhadap CPU — Ketika pecahan terlibat dalam pengindeksan atau permintaan pencarian, ia menggunakan vCPU untuk memproses permintaan. Sebagai praktik terbaik, gunakan titik skala awal 1,5 vCPU per pecahan. Jika tipe instans Anda memiliki 8 vCPUs, atur jumlah node data Anda sehingga setiap node memiliki tidak lebih dari enam pecahan. Perhatikan bahwa ini adalah perkiraan. Pastikan untuk menguji beban kerja Anda dan skala klaster Anda sesuai dengan itu.
Untuk rekomendasi volume penyimpanan, ukuran pecahan, dan jenis instans, lihat sumber daya berikut:
Hindari kemiringan penyimpanan
Kemiringan penyimpanan terjadi ketika satu atau lebih node dalam sebuah cluster memegang proporsi penyimpanan yang lebih tinggi untuk satu atau lebih indeks daripada yang lain. Indikasi kemiringan penyimpanan termasuk pemanfaatan CPU yang tidak merata, latensi intermiten dan tidak merata, dan antrian yang tidak merata di seluruh node data. Untuk menentukan apakah Anda memiliki masalah miring, lihat bagian pemecahan masalah berikut:
Stabilitas
Praktik terbaik berikut berlaku untuk mempertahankan domain OpenSearch Layanan yang stabil dan sehat.
Tetap terkini dengan OpenSearch
Pembaruan perangkat lunak layanan
OpenSearch Layanan secara teratur merilis pembaruan perangkat lunak yang menambahkan fitur atau meningkatkan domain Anda. Pembaruan tidak mengubah versi mesin OpenSearch atau Elasticsearch. Kami menyarankan Anda menjadwalkan waktu berulang untuk menjalankan operasi DescribeDomainAPI, dan memulai pembaruan perangkat lunak layanan jika ada. UpdateStatus ELIGIBLE Jika Anda tidak memperbarui domain Anda dalam jangka waktu tertentu (biasanya dua minggu), OpenSearch Layanan akan melakukan pembaruan secara otomatis.
OpenSearch upgrade versi
OpenSearch Layanan secara teratur menambahkan dukungan untuk versi yang dikelola komunitas. OpenSearch Selalu tingkatkan ke OpenSearch versi terbaru saat tersedia.
OpenSearch Layanan secara bersamaan meningkatkan keduanya OpenSearch dan OpenSearch Dasbor (atau Elasticsearch dan Kibana jika domain Anda menjalankan mesin lama). Jika klaster memiliki simpul utama yang didedikasikan, peningkatan selesai tanpa waktu henti. Jika tidak, cluster mungkin tidak responsif selama beberapa detik pasca-peningkatan saat memilih node master. OpenSearch Dasbor mungkin tidak tersedia selama beberapa atau semua peningkatan.
Ada dua cara untuk meng-upgrade domain:
-
Upgrade di tempat - Opsi ini lebih mudah karena Anda menyimpan cluster yang sama.
-
Snapshot/restore upgrade - Opsi ini bagus untuk menguji versi baru pada cluster baru atau bermigrasi antar cluster.
Terlepas dari proses pemutakhiran yang Anda gunakan, kami menyarankan Anda mempertahankan domain yang semata-mata untuk pengembangan dan pengujian, dan memutakhirkannya ke versi baru sebelum Anda meningkatkan domain produksi Anda. Pilih Pengembangan dan pengujian untuk jenis penerapan saat Anda membuat domain pengujian. Pastikan untuk memutakhirkan semua klien ke versi yang kompatibel segera setelah peningkatan domain.
Tingkatkan kinerja snapshot
Untuk mencegah snapshot Anda macet dalam pemrosesan, jenis instance untuk node master khusus harus sesuai dengan jumlah pecahan. Untuk informasi selengkapnya, lihat Memilih jenis instance untuk node master khusus. Selain itu, setiap node harus memiliki tidak lebih dari 25 pecahan yang direkomendasikan per GiB memori heap Java. Untuk informasi selengkapnya, lihat Memilih jumlah serpihan.
Aktifkan node master khusus
Node master khusus meningkatkan stabilitas cluster. Master node khusus melakukan tugas manajemen klaster, tetapi tidak menyimpan data indeks atau menanggapi permintaan klien. Pembongkaran tugas manajemen klaster ini meningkatkan stabilitas domain Anda dan memungkinkan beberapa perubahan konfigurasi terjadi tanpa downtime.
Aktifkan dan gunakan tiga node master khusus untuk stabilitas domain optimal di tiga Availability Zone. Menerapkan dengan Multi-AZ dengan Standby mengonfigurasi tiga node master khusus untuk Anda. Misalnya jenis rekomendasi, lihatMemilih jenis instance untuk node master khusus.
Terapkan di beberapa Availability Zone
Untuk mencegah kehilangan data dan meminimalkan downtime cluster jika terjadi gangguan layanan, Anda dapat mendistribusikan node di dua atau tiga Availability Zone secara bersamaan. Wilayah AWS Praktik terbaik adalah menerapkan menggunakan Multi-AZ dengan Siaga, yang mengonfigurasi tiga Availability Zone, dengan dua zona aktif dan satu bertindak sebagai siaga, dan dengan dan dua pecahan replika per indeks. Konfigurasi ini memungkinkan OpenSearch Service mendistribusikan pecahan replika ke yang berbeda AZs dari pecahan primer yang sesuai. Tidak ada biaya transfer data lintas-AZ untuk komunikasi klaster antara Availability Zones.
Availability Zone adalah lokasi terisolasi di setiap Wilayah. Dengan konfigurasi dua-AZ, kehilangan satu Availability Zone berarti Anda kehilangan setengah dari semua kapasitas domain. Pindah ke tiga Availability Zone semakin mengurangi dampak kehilangan satu Availability Zone.
Kontrol aliran menelan dan buffering
Kami menyarankan Anda membatasi jumlah permintaan keseluruhan menggunakan operasi _bulk_bulk permintaan yang berisi 5.000 dokumen daripada mengirim 5.000 permintaan yang berisi satu dokumen.
Untuk stabilitas operasional yang optimal, terkadang perlu membatasi atau bahkan menjeda aliran hulu permintaan pengindeksan. Membatasi tingkat permintaan indeks adalah mekanisme penting untuk menangani lonjakan permintaan yang tidak terduga atau sesekali yang mungkin membanjiri klaster. Pertimbangkan untuk membangun mekanisme kontrol aliran ke dalam arsitektur hulu Anda.
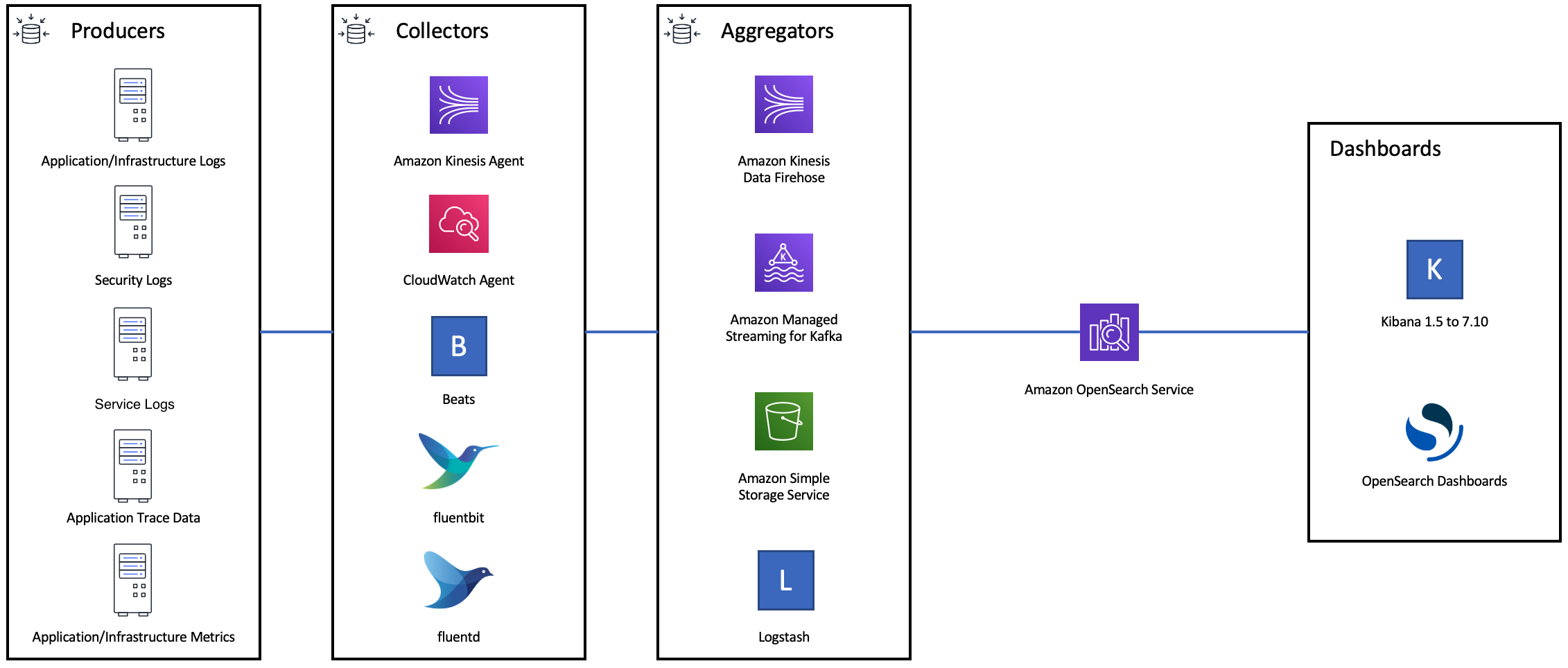
Diagram berikut menunjukkan beberapa opsi komponen untuk arsitektur log ingest. Konfigurasikan lapisan agregasi untuk memungkinkan ruang yang cukup untuk menyangga data yang masuk untuk lonjakan lalu lintas mendadak dan pemeliharaan domain singkat.
Membuat pemetaan untuk beban kerja pencarian
Untuk beban kerja penelusuran, buat pemetaandynamic ke strict untuk mencegah bidang baru ditambahkan secara tidak sengaja.
PUT my-index { "mappings": { "dynamic": "strict", "properties": { "title": { "type" : "text" }, "author": { "type" : "integer" }, "year": { "type" : "text" } } } }
Gunakan templat indeks
Anda dapat menggunakan templat indeks
Pengaturan berikut sangat membantu untuk mengkonfigurasi dalam template:
-
Jumlah pecahan primer dan replika
-
Interval penyegaran (seberapa sering menyegarkan dan membuat perubahan terbaru pada indeks yang tersedia untuk dicari)
-
Kontrol pemetaan dinamis
-
Pemetaan bidang eksplisit
Contoh template berikut berisi masing-masing pengaturan ini:
{ "index_patterns":[ "index-*" ], "order": 0, "settings": { "index": { "number_of_shards": 3, "number_of_replicas": 1, "refresh_interval": "60s" } }, "mappings": { "dynamic": false, "properties": { "field_name1": { "type": "keyword" } } } }
Bahkan jika mereka jarang berubah, memiliki pengaturan dan pemetaan yang ditentukan secara OpenSearch terpusat lebih sederhana untuk dikelola daripada memperbarui beberapa klien hulu.
Mengelola indeks dengan Index State Management
Jika Anda mengelola log atau data deret waktu, sebaiknya gunakan Index State Management (ISM). ISM memungkinkan Anda mengotomatiskan tugas manajemen siklus hidup indeks reguler. Dengan ISM, Anda dapat membuat kebijakan yang memanggil rollover alias indeks, mengambil snapshot indeks, memindahkan indeks antar tingkatan penyimpanan, dan menghapus indeks lama. Anda bahkan dapat menggunakan operasi rollover
Pertama, buat kebijakan ISM. Sebagai contoh, lihat Contoh kebijakan. Kemudian, lampirkan kebijakan ke satu atau lebih indeks. Jika Anda menyertakan bidang templat ISM dalam kebijakan, OpenSearch Layanan secara otomatis menerapkan kebijakan tersebut ke indeks apa pun yang cocok dengan pola yang ditentukan.
Hapus indeks yang tidak digunakan
Tinjau indeks di klaster Anda secara teratur dan identifikasi indeks apa pun yang tidak digunakan. Ambil snapshot dari indeks tersebut sehingga disimpan di S3, lalu hapus. Saat Anda menghapus indeks yang tidak digunakan, Anda mengurangi jumlah pecahan, dan memungkinkan distribusi penyimpanan dan pemanfaatan sumber daya yang lebih seimbang di seluruh node. Bahkan ketika mereka menganggur, indeks mengkonsumsi beberapa sumber daya selama kegiatan pemeliharaan indeks internal.
Daripada menghapus indeks yang tidak digunakan secara manual, Anda dapat menggunakan ISM untuk secara otomatis mengambil snapshot dan menghapus indeks setelah jangka waktu tertentu.
Gunakan beberapa domain untuk ketersediaan tinggi
Untuk mencapai ketersediaan tinggi di luar waktu aktif 99,9%
Arsitek aplikasi hulu dan hilir Anda dengan mempertimbangkan failover. Pastikan untuk menguji proses failover bersama dengan proses pemulihan bencana lainnya.
Performa
Praktik terbaik berikut berlaku untuk menyetel domain Anda untuk kinerja yang optimal.
Optimalkan ukuran dan kompresi permintaan massal
Ukuran massal tergantung pada data, analisis, dan konfigurasi cluster Anda, tetapi titik awal yang baik adalah 3—5 MiB per permintaan massal.
Kirim permintaan dan terima tanggapan dari OpenSearch domain Anda dengan menggunakan kompresi gzip untuk mengurangi ukuran payload permintaan dan tanggapan. Anda dapat menggunakan kompresi gzip dengan klien OpenSearch Python, atau dengan menyertakan header berikut dari sisi klien:
-
'Accept-Encoding': 'gzip' -
'Content-Encoding': 'gzip'
Untuk mengoptimalkan ukuran permintaan massal Anda, mulailah dengan ukuran permintaan massal 3 MiB. Kemudian, perlahan-lahan tingkatkan ukuran permintaan hingga kinerja pengindeksan berhenti membaik.
catatan
Untuk mengaktifkan kompresi gzip pada domain yang menjalankan Elasticsearch versi 6.x, Anda harus mengatur http_compression.enabled pada tingkat cluster. Pengaturan ini benar secara default di Elasticsearch versi 7.x dan semua versi. OpenSearch
Kurangi ukuran respons permintaan massal
Untuk mengurangi ukuran OpenSearch respons, kecualikan bidang yang tidak perlu dengan filter_path parameter. Pastikan Anda tidak memfilter bidang apa pun yang diperlukan untuk mengidentifikasi atau mencoba ulang permintaan yang gagal. Untuk informasi selengkapnya dan contoh tambahan, lihat Mengurangi ukuran respons.
Selaraskan interval penyegaran
OpenSearch indeks akhirnya memiliki konsistensi baca. Operasi penyegaran membuat semua pembaruan yang dilakukan pada indeks tersedia untuk pencarian. Interval penyegaran default adalah satu detik, yang berarti OpenSearch melakukan penyegaran setiap detik saat indeks sedang ditulis.
Semakin jarang Anda menyegarkan indeks (interval penyegaran yang lebih tinggi), semakin baik kinerja pengindeksan secara keseluruhan. Trade-off dari peningkatan interval penyegaran adalah bahwa ada penundaan yang lebih lama antara pembaruan indeks dan ketika data baru tersedia untuk pencarian. Atur interval penyegaran setinggi yang dapat Anda toleransi untuk meningkatkan kinerja secara keseluruhan.
Sebaiknya atur refresh_interval parameter untuk semua indeks Anda menjadi 30 detik atau lebih.
Aktifkan Auto-Tune
Auto-Tune menggunakan metrik kinerja dan penggunaan dari OpenSearch klaster Anda untuk menyarankan perubahan ukuran antrian, ukuran cache, dan pengaturan mesin virtual Java (JVM) pada node Anda. Perubahan opsional ini meningkatkan kecepatan dan stabilitas klaster. Anda dapat kembali ke pengaturan OpenSearch Layanan default kapan saja. Auto-Tune diaktifkan secara default pada domain baru kecuali Anda menonaktifkannya secara eksplisit.
Kami menyarankan Anda mengaktifkan Auto-Tune di semua domain, dan mengatur jendela pemeliharaan berulang atau meninjau rekomendasinya secara berkala.
Keamanan
Praktik terbaik berikut berlaku untuk mengamankan domain Anda.
Aktifkan kontrol akses berbutir halus
Kontrol akses berbutir halus memungkinkan Anda mengontrol siapa yang dapat mengakses data tertentu dalam domain Layanan. OpenSearch Dibandingkan dengan kontrol akses umum, kontrol akses berbutir halus memberikan setiap klaster, indeks, dokumen, dan bidang kebijakan yang ditentukan sendiri untuk akses. Kriteria akses dapat didasarkan pada sejumlah faktor, termasuk peran orang yang meminta akses dan tindakan yang ingin mereka lakukan pada data. Misalnya, Anda mungkin memberi satu pengguna akses untuk menulis ke indeks, dan akses pengguna lain hanya untuk membaca data pada indeks tanpa membuat perubahan apa pun.
Kontrol akses berbutir halus memungkinkan data dengan persyaratan akses yang berbeda ada di ruang penyimpanan yang sama tanpa mengalami masalah keamanan atau kepatuhan.
Sebaiknya aktifkan kontrol akses berbutir halus pada domain Anda.
Menyebarkan domain dalam VPC
Menempatkan domain OpenSearch Layanan Anda dalam virtual private cloud (VPC) membantu memungkinkan komunikasi yang aman antara OpenSearch Layanan dan layanan lain dalam VPC — tanpa memerlukan gateway internet, perangkat NAT, atau koneksi VPN. Semua lalu lintas tetap aman di dalam AWS Cloud. Karena isolasi logisnya, domain yang berada di dalam VPC memiliki lapisan keamanan ekstra dibandingkan dengan domain yang menggunakan titik akhir publik.
Kami menyarankan Anda membuat domain Anda dalam VPC.
Menerapkan kebijakan akses terbatas
Bahkan jika domain Anda digunakan dalam VPC, itu adalah praktik terbaik untuk menerapkan keamanan secara berlapis-lapis. Pastikan untuk memeriksa konfigurasi kebijakan akses Anda saat ini.
Terapkan kebijakan akses berbasis sumber daya terbatas ke domain Anda dan ikuti prinsip hak istimewa paling sedikit saat memberikan akses ke API konfigurasi dan operasi API. OpenSearch Sebagai aturan umum, hindari penggunaan prinsipal pengguna anonim "Principal": {"AWS": "*" } dalam kebijakan akses Anda.
Namun, ada beberapa situasi di mana penggunaan kebijakan akses terbuka dapat diterima, seperti saat Anda mengaktifkan kontrol akses berbutir halus. Kebijakan akses terbuka dapat memungkinkan Anda mengakses domain jika penandatanganan permintaan sulit atau tidak mungkin dilakukan, seperti dari klien dan alat tertentu.
Aktifkan enkripsi saat istirahat
OpenSearch Domain layanan menawarkan enkripsi data saat istirahat untuk membantu mencegah akses tidak sah ke data Anda. Enkripsi saat istirahat menggunakan AWS Key Management Service (AWS KMS) untuk menyimpan dan mengelola kunci enkripsi Anda, dan algoritma Advanced Encryption Standard dengan kunci 256-bit (AES-256) untuk melakukan enkripsi.
Jika domain Anda menyimpan data sensitif, aktifkan enkripsi data saat istirahat.
Aktifkan node-to-node enkripsi
Node-to-node enkripsi menyediakan lapisan keamanan tambahan di atas fitur keamanan default dalam OpenSearch Layanan. Ini mengimplementasikan Transport Layer Security (TLS) untuk semua komunikasi antara node yang disediakan di dalamnya. OpenSearch Node-to-nodeenkripsi, data apa pun yang dikirim ke domain OpenSearch Layanan Anda melalui HTTPS tetap dienkripsi dalam perjalanan saat sedang didistribusikan dan direplikasi antar node.
Jika domain Anda menyimpan data sensitif, aktifkan node-to-node enkripsi.
Monitor dengan AWS Security Hub
Pantau penggunaan OpenSearch Layanan Anda yang berkaitan dengan praktik terbaik keamanan dengan menggunakan AWS Security Hub. Hub Keamanan menggunakan kontrol keamanan untuk mengevaluasi konfigurasi sumber daya dan standar keamanan guna membantu Anda mematuhi berbagai kerangka kerja kepatuhan. Untuk informasi selengkapnya tentang penggunaan Security Hub guna mengevaluasi sumber daya OpenSearch Layanan, lihat Amazon OpenSearch Service kontrol di Panduan AWS Security Hub Pengguna.
Optimalisasi biaya
Praktik terbaik berikut berlaku untuk mengoptimalkan dan menghemat biaya OpenSearch Layanan Anda.
Gunakan jenis instans generasi terbaru
OpenSearch Layanan selalu mengadopsi jenis EC2 instans Amazon baru yang memberikan kinerja yang lebih baik dengan biaya lebih rendah. Kami merekomendasikan untuk selalu menggunakan instance generasi terbaru.
Hindari penggunaan T2 atau t3.small instance untuk domain produksi karena mereka dapat menjadi tidak stabil di bawah beban berat yang berkelanjutan. r6g.largeinstance adalah opsi untuk beban kerja produksi kecil (baik sebagai node data dan sebagai node master khusus).
Gunakan volume gp3 Amazon EBS terbaru
OpenSearch node data membutuhkan latensi rendah dan penyimpanan throughput tinggi untuk menyediakan pengindeksan dan kueri yang cepat. Dengan menggunakan volume Amazon EBS gp3, Anda mendapatkan kinerja baseline yang lebih tinggi (IOPS dan throughput) dengan biaya 9,6% lebih rendah dibandingkan dengan jenis volume Amazon EBS gp2 yang ditawarkan sebelumnya. Anda dapat menyediakan IOPS tambahan dan throughput independen dari ukuran volume menggunakan gp3. Volume ini juga lebih stabil daripada volume generasi sebelumnya karena tidak menggunakan kredit burst. Jenis volume gp3 juga menggandakan batas ukuran per-data-node volume tipe volume gp2. Dengan volume yang lebih besar ini, Anda dapat mengurangi biaya data pasif dengan meningkatkan jumlah penyimpanan per node data.
Penggunaan UltraWarm dan penyimpanan dingin untuk data log deret waktu
Jika Anda menggunakan OpenSearch analisis log, pindahkan data Anda ke UltraWarm atau penyimpanan dingin untuk mengurangi biaya. Gunakan Index State Management (ISM) untuk memigrasikan data antar tingkatan penyimpanan dan mengelola retensi data.
UltraWarmmenyediakan cara yang hemat biaya untuk menyimpan sejumlah besar data hanya-baca di Layanan. OpenSearch UltraWarm menggunakan Amazon S3 untuk penyimpanan, yang berarti bahwa data tidak dapat diubah dan hanya satu salinan yang diperlukan. Anda hanya membayar untuk penyimpanan yang setara dengan ukuran pecahan utama dalam indeks Anda. Latensi untuk UltraWarm kueri tumbuh dengan jumlah data S3 yang diperlukan untuk melayani kueri. Setelah data di-cache pada node, kueri ke UltraWarm indeks berkinerja mirip dengan kueri ke indeks panas.
Cold storage juga didukung oleh S3. Saat Anda perlu menanyakan data dingin, Anda dapat secara selektif melampirkannya ke UltraWarm node yang ada. Data dingin menimbulkan biaya penyimpanan terkelola yang sama seperti UltraWarm, tetapi objek dalam penyimpanan dingin tidak mengkonsumsi sumber daya UltraWarm node. Oleh karena itu, cold storage menyediakan sejumlah besar kapasitas penyimpanan tanpa mempengaruhi ukuran atau jumlah UltraWarm node.
UltraWarm menjadi hemat biaya ketika Anda memiliki sekitar 2,5 TiB data untuk bermigrasi dari penyimpanan panas. Pantau laju pengisian Anda dan rencanakan untuk memindahkan indeks UltraWarm sebelum Anda mencapai volume data tersebut.
Meninjau rekomendasi untuk Instans Cadangan
Pertimbangkan untuk membeli Instans Cadangan (RIs) setelah Anda memiliki dasar yang baik tentang kinerja dan konsumsi komputasi Anda. Diskon mulai dari sekitar 30% untuk reservasi 1 tahun tanpa di muka dan dapat meningkat hingga 50% untuk komitmen 3 tahun di muka.
Setelah Anda mengamati operasi yang stabil setidaknya selama 14 hari, tinjau Mengakses rekomendasi reservasi di Panduan AWS Cost Management Pengguna. Judul OpenSearch Layanan Amazon menampilkan rekomendasi pembelian RI spesifik dan penghematan yang diproyeksikan.
