Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Ciclo di vita del data lake
La creazione di un data lake prevede in genere cinque fasi:
-
Configurazione dello storage
-
Spostamento dei dati
-
Preparazione e catalogazione dei dati
-
Configurazione delle politiche di sicurezza
-
Rendere i dati disponibili per il consumo
La figura seguente è un diagramma di architettura di alto livello di un data lake di contact center Amazon Connect che si integra con i servizi di analisi e intelligenza artificiale/machine learning (AI/ML) di AWS. La sezione seguente illustra gli scenari e i servizi AWS mostrati in questa figura.
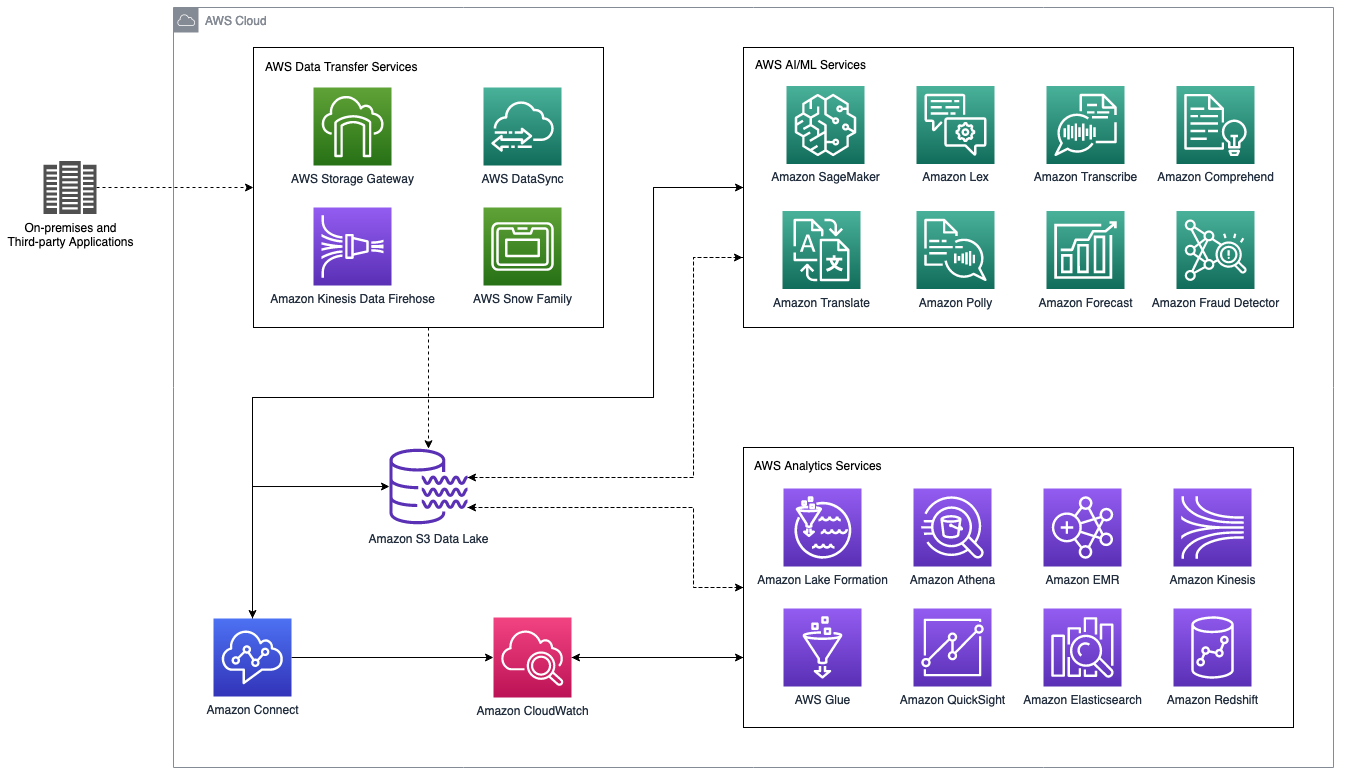
Data lake per contact center Amazon Connect con analisi AWS e servizi AI/ML
Storage
Amazon S3
I bucket e gli oggetti S3 sono privati e S3 Block Public Access è abilitato per impostazione predefinita in tutte le regioni a livello globale. Puoi configurare controlli di accesso centralizzati sulle risorse S3 utilizzando bucket policy, policy AWS Identity and Access Management
AWS CloudTrail
S3 Intelligent-Tiering
L'archiviazione dei dati in formati colonnari come Apache Parquet
Con S3 Select e S3 Glacier Select, è possibile interrogare i metadati degli oggetti utilizzando l'espressione SQL (Structured Query Language) senza spostare gli oggetti in un altro archivio dati.
S3 Batch Operations automatizza le operazioni
Gli access point S3 semplificano e aggregano l'accesso ai
S3 Transfer Acceleration
Man mano che il data lake cresce, S3 Storage Lens offre una visibilità a livello aziendale sull'utilizzo dello storage
Ingestione
AWS offre un portafoglio completo di servizi di trasferimento dati per spostare i dati esistenti in un data lake centralizzato. Amazon Storage Gateway
-
AWS Storage Gatewayestende gli ambienti locali allo storage AWS sostituendo le librerie a nastro con lo storage cloud, fornendo condivisioni di file supportate da storage cloud o creando una cache a bassa latenza per accedere ai dati in AWS da ambienti locali.
-
AWS Direct Connectstabilisce una connettività privata tra gli ambienti locali e AWS per ridurre i costi di rete, aumentare il throughput e fornire un'esperienza di rete coerente.
-
AWS DataSync può trasferire milioni di file in S3, Amazon Elastic File System
(Amazon EFS) o Amazon FSx for Windows File Server ottimizzando al contempo l'utilizzo della rete. -
Amazon Kinesis offre un modo sicuro per acquisire e caricare dati in streaming in S3. Amazon Data Firehose
è un servizio completamente gestito per la distribuzione di dati in streaming in tempo reale direttamente su S3. Firehose si ridimensiona automaticamente in base al volume e alla velocità di trasmissione dei dati in streaming e non richiede alcuna amministrazione continua. È possibile trasformare i dati in streaming utilizzando compressione, crittografia, data batching o AWS Lambda funzioni all'interno di Firehose prima di archiviare i dati in S3. La crittografia Firehose supporta la crittografia lato server S3 con (). AWS Key Management Service AWS KMS In alternativa, puoi crittografare i dati con la tua chiave personalizzata. Firehose è in grado di concatenare e fornire più record in entrata come un unico oggetto S3 per ridurre i costi e ottimizzare il throughput. AWS Snow Family fornisce un meccanismo di trasferimento dati offline. AWS Snowball Edge
offre un dispositivo di edge computing portatile e rinforzato per la raccolta, l'elaborazione e la migrazione dei dati. Per il trasferimento di dati su scala exabyte, puoi usare AWS Snowmobile per spostare enormi volumi di dati nel cloud. DistCp
fornisce una funzionalità di copia distribuita per spostare i dati nell'ecosistema Hadoop. S3 DisctCp è un'estensione DistCp ottimizzata per lo spostamento di dati tra Hadoop Distributed File System (HDFS) e S3. Questo blog fornisce informazioni su come spostare dati tra HDFS e S3 utilizzando S3. DistCp
Catalogazione
Una sfida comune con un'architettura data lake è la mancanza di supervisione sul contenuto dei dati grezzi archiviati nel data lake. Le organizzazioni hanno bisogno di governance, coerenza semantica e controlli degli accessi per evitare le insidie derivanti dalla creazione di una palude di dati senza alcuna cura.
AWS Lake Formation
AWS Glue DataBrew
Sicurezza
Amazon Connect separa i dati in base all'ID account AWS e all'ID dell'istanza Amazon Connect per garantire l'accesso autorizzato ai dati a livello di istanza Amazon Connect.
Amazon Connect crittografa i dati di contatto e i profili dei clienti inattivi (PII) utilizzando una chiave limitata nel tempo specifica per la tua istanza Amazon Connect. La crittografia lato server di S3 protegge le registrazioni vocali e di chat inattive utilizzando una chiave dati KMS unica per account AWS. Mantieni il controllo di sicurezza completo per configurare l'accesso degli utenti alle registrazioni delle chiamate nel tuo bucket S3, incluso il monitoraggio di chi ascolta o elimina le registrazioni delle chiamate. Amazon Connect crittografa le impronte vocali dei clienti con una chiave KMS di proprietà del servizio per proteggere l'identità del cliente. Tutti i dati scambiati tra Amazon Connect e altri servizi AWS o applicazioni esterne vengono sempre crittografati in transito utilizzando la crittografia TLS (Transport Layer Security) standard del settore.
La protezione di un data lake richiede controlli dettagliati per garantire l'accesso e l'uso autorizzati dei dati. Per impostazione predefinita, le risorse S3 sono private e accessibili solo dal proprietario delle risorse. Il proprietario della risorsa può creare una combinazione di policy IAM basate su risorse o sull'identità per concedere e gestire le autorizzazioni per i bucket e gli oggetti S3. Le politiche basate sulle risorse, come le bucket policy, sono collegate alle risorse. ACLs Al contrario, le policy basate sull'identità sono allegate agli utenti, ai gruppi o ai ruoli IAM nel tuo account AWS.
Consigliamo politiche basate sull'identità per la maggior parte degli ambienti di data lake per semplificare la gestione dell'accesso alle risorse e le autorizzazioni ai servizi per gli utenti dei data lake. Puoi creare utenti, gruppi e ruoli IAM negli account AWS e associarli a policy basate sull'identità che garantiscono l'accesso alle risorse S3.
Il modello di AWS Lake Formation autorizzazione funziona in combinazione con le autorizzazioni IAM per gestire l'accesso ai data lake. Il modello di autorizzazione di Lake Formation utilizza un meccanismo GRANT o REVOKE in stile DBMS (database management system). Le autorizzazioni IAM contengono politiche basate sull'identità. Ad esempio, un utente deve superare i controlli di autorizzazione sia con le autorizzazioni IAM che con quelle di Lake Formation prima di accedere a una risorsa data lake.
AWS CloudTrail tiene traccia delle chiamate API di Amazon Connect, inclusi l'indirizzo IP e l'identità del richiedente e la data e l'ora della richiesta nella Cronologia CloudTrail eventi. La creazione di un AWS CloudTrail trail consente la consegna continua dei AWS CloudTrail log al tuo bucket S3.
I gruppi di lavoro di Amazon Athena possono separare l'esecuzione delle query e controllare l'accesso da parte di utenti, team o applicazioni utilizzando politiche basate sulle risorse. Puoi applicare il controllo dei costi limitando l'utilizzo dei dati nei gruppi di lavoro.
Monitoraggio
L'osservabilità è essenziale per garantire la disponibilità, l'affidabilità e le prestazioni di un contact center e di un data lake. Amazon CloudWatch
Amazon Connect invia i dati di utilizzo dell'istanza come CloudWatch parametri Amazon a intervalli di un minuto. La conservazione dei dati per i CloudWatch parametri di Amazon è di due settimane. Definisci tempestivamente i requisiti di conservazione dei log e le politiche del ciclo di vita, assicurati la conformità normativa e risparmi sui costi per l'archiviazione dei dati a lungo termine.
Amazon CloudWatch Logs offre un modo semplice per filtrare i dati di log e identificare gli eventi di non conformità per le indagini sugli incidenti e accelerare le risoluzioni. Puoi personalizzare i flussi di contatto per rilevare chiamanti ad alto rischio o attività potenzialmente fraudolente. Ad esempio, puoi disconnettere tutti i contatti in entrata presenti nella tua lista di rifiuto predefinita.
Analisi
Un data lake per contact center basato su un portafoglio di analisi descrittivo, predittivo e in tempo reale consente di estrarre informazioni significative e rispondere a domande aziendali critiche.
Una volta che i dati arrivano nel data lake S3, puoi utilizzare qualsiasi servizio di analisi appositamente progettato come Amazon Athena e Amazon QuickSight
Per una soluzione di data warehousing altamente scalabile, puoi abilitare lo streaming di dati in Amazon Connect per trasmettere i record dei contatti in Amazon Redshift tramite Amazon Kinesis
Machine learning
La creazione di un data lake introduce un nuovo paradigma nell'architettura dei contact center, che consente alle aziende di fornire un servizio clienti migliorato e personalizzato utilizzando funzionalità di machine learning (ML).
Lo sviluppo del machine learning tradizionale è un processo complesso e costoso. AWS offre la profondità e l'ampiezza di un'infrastruttura scalabile, economica e ad alte prestazioni e servizi ML flessibili per qualsiasi progetto o carico di lavoro ML
Amazon SageMaker AI
Ridurre gli attriti nel percorso del cliente è essenziale per evitare il tasso di abbandono dei clienti. Per aggiungere intelligenza al tuo contact center, puoi creare chatbot conversazionali basati sull'intelligenza artificiale
Comprendere le dinamiche chiamante-agente è essenziale per migliorare la qualità complessiva del servizio. Consulta questo blog
Per le organizzazioni con una presenza internazionale, puoi creare un'esperienza vocale multilingue
Il software di pianificazione finanziaria tradizionale crea previsioni basate su dati storici di serie temporali senza correlare tendenze incoerenti e variabili rilevanti. Amazon Forecast
Amazon Connect fornisce gli attributi delle chiamate degli operatori di telefonia, come la posizione geografica delle apparecchiature vocali per mostrare da dove proviene la chiamata, i tipi di dispositivi telefonici come rete fissa o mobile, il numero di segmenti di rete attraversati dalla chiamata e altre informazioni sull'origine delle chiamate. Utilizzando Amazon Fraud Detector
