データレイクのライフサイクル
データレイクの構築には、通常、次の 5 つの段階があります。
-
ストレージのセットアップ
-
データ移動
-
データの準備とカタログ化
-
セキュリティポリシーの設定
-
消費可能なデータに加工
次の図は、AWS 分析および人工知能/機械学習 (AI/ML) サービスと統合された Amazon Connect コンタクトセンターのデータレイクアーキテクチャの概略図を示しています。次のセクションでは、この図に示されているシナリオと AWS サービスについて説明します。
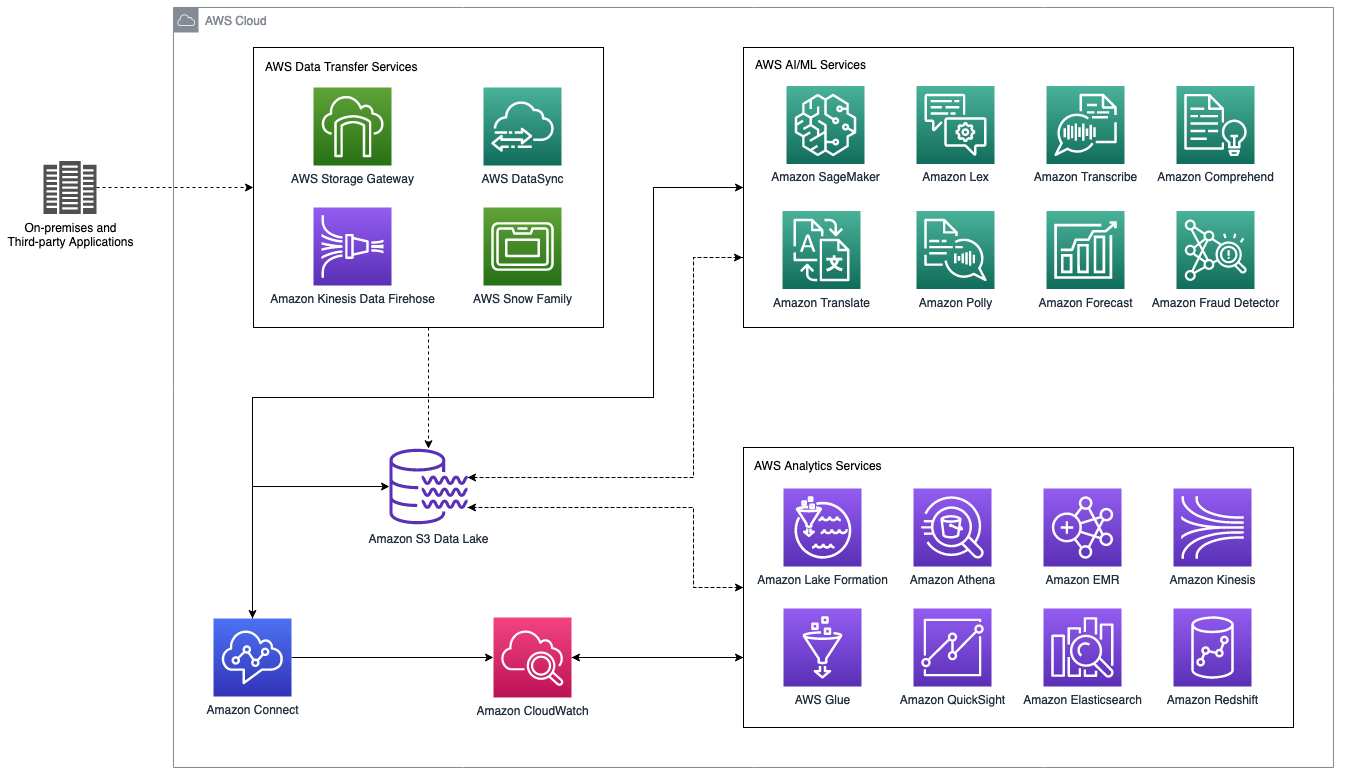
AWS 分析と AI/ML サービスを備えた Amazon Connect コンタクトセンターのデータレイク
ストレージ
Amazon S3
S3 バケットとオブジェクトはプライベートで、デフォルトではすべてのリージョンに対してグローバルに S3 Block Public Access が有効になっています。バケットポリシー、AWS Identity and Access Management
AWS CloudTrail
S3 Intelligent-Tiering
Apache Parquet
S3 Select と S3 Glacier Select を使用することで、オブジェクトを別のデータストアに移動することなく、構造化クエリ言語 (SQL) 式を使用してオブジェクトメタデータをクエリすることができます。
S3 バッチオペレーション
S3 アクセスポイント
S3 Transfer Acceleration
データレイクが拡大すると、S3 ストレージレンズ
取り込み
AWS では、既存のデータを一元化されたデータレイクに移行するための包括的なデータ転送サービスポートフォリオを提供しています。Amazon Storage Gateway
-
AWS Storage Gateway は、テープライブラリのクラウドストレージへの置換、クラウドストレージベースのファイル共有の提供、低レイテンシーのキャッシュの作成によるオンプレミス環境から AWS のデータアクセスにより、オンプレミス環境を AWS ストレージに拡張します。
-
AWS Direct Connect により、オンプレミス環境と AWS 間のプライベート接続を確立することで、ネットワークコストの削減、スループットの向上、一貫性のあるネットワークエクスペリエンスを利用できます。
-
AWS DataSync は、ネットワークの使用率を最適化しながら、何百万ものファイルを S3、Amazon Elastic File System
(Amazon EFS)、または Amazon FSx for Windows File Server に転送できます。 -
Amazon Kinesis により、安全な方法でストリーミングデータをキャプチャして S3 に読み込むことができます。Amazon Data Firehose
は、リアルタイムのストリーミングデータを S3 に直接配信する、フルマネージド型サービスです。Firehose は、ストリーミングデータの量とスループットに合わせて自動的にスケーリングするため、継続的な管理は不要です。S3 にデータを保存する前に、Firehose 内の圧縮、暗号化、データバッチ処理、または AWS Lambda 関数を使用してストリーミングデータを変換できます。Firehose の暗号化では、S3 サーバー側の暗号化を AWS Key Management Service (AWS KMS) でサポートします。または、カスタムキーを使用してデータを暗号化することもできます。Firehose では、複数の受信レコードを 1 つの S3 オブジェクトとして連結して配信できるため、コスト削減とスループットの最適化を実現できます。 AWS Snow Family では、オフラインのデータ転送メカニズムを提供します。AWS Snowball Edge
は、データ収集、処理、移行向けの、持ち運び可能で耐久性の高いエッジコンピューティングデバイスが利用できます。エクサバイトスケールのデータ転送の場合、AWS Snowmobile を使用して大量のデータをクラウドに移動できます。 DistCP
により、Hadoop エコシステム内のデータを移動するための分散コピー機能が利用できます。S3DiscTCP は、DistCp の拡張機能で、Hadoop Distributed File System (HDFS) と S3 間のデータ移動に最適化されています。このブログ では、S3DistCp を使用して HDFS と S3 の間でデータを移動する方法について説明します。
カタログ化
データレイクアーキテクチャに共通する課題の 1 つは、データレイクに保存されている未加工データの内容を監視できないことです。組織では、キュレーションを行わずに大量のデータを生み出すという問題を回避するために、ガバナンス、セマンティクスの一貫性、アクセス制御を必要としています。
AWS Lake Formation
AWS Glue DataBrew
セキュリティ
Amazon Connect は、Amazon Connect インスタンスレベルでのデータアクセスを許可するために、データを AWS アカウント ID と Amazon Connect インスタンス ID で分離します。
Amazon Connect は、Amazon Connect インスタンス固有の期限付きキーを使用して、保存中の個人を特定できる情報 (PII) の連絡先データと顧客プロファイルを暗号化します。S3 サーバー側の暗号化では、AWS アカウントごとに一意の KMS データキーを使用して、保存中の音声録音とチャット録音の両方を保護します。S3 バケット内の通話録音へのユーザーアクセスを設定し、録音を再生または削除したユーザーを追跡するなど、セキュリティ制御を確実に維持できます。Amazon Connect は、サービス所有の KMS キーで顧客の声紋を暗号化し、カスタマー ID を保護します。Amazon Connect と他の AWS サービス、または外部アプリケーションとの間で交換されるすべてのデータは、業界標準の Transport Layer Security (TLS) 暗号化を使用して、転送中は常時暗号化されます。
データレイクを保護するには、データアクセスの許可と使用を確実に行うためのきめ細かな制御が必要です。S3 リソースはプライベートで、デフォルトではリソース所有者のみがアクセスできます。リソース所有者は、リソースベースまたはアイデンティティベースの IAM ポリシーを組み合わせて作成し、S3 バケットとオブジェクトにアクセス権限を付与して管理できます。バケットポリシーや ACL などのリソースベースのポリシーは、リソースにアタッチされます。一方で、アイデンティティベースのポリシーは、AWS アカウントの IAM ユーザー、グループ、またはロールにアタッチされます。
ほとんどのデータレイク環境では、データレイクユーザーのリソースアクセス管理とサービス許可を簡素化するために、アイデンティティベースのポリシーを推奨しています。AWS アカウントで IAM ユーザー、グループ、ロールを作成し、それらを S3 リソースへのアクセスを許可するアイデンティティベースのポリシーに関連付けることができます。
AWS Lake Formation アクセス許可モデルは、IAM アクセス許可と連動してデータレイクアクセスを管理します。Lake Formation のアクセス許可モデルは、データベース管理システム (DBMS) スタイルの GRANT または REVOKE メカニズムを使用しています。アイデンティティベースのポリシーを含む IAM アクセス許可 例えば、ユーザーはデータレイクリソースにアクセスする前に、IAM と Lake Formation の両方のアクセス許可が付与される必要があります。
AWS CloudTrail は、CloudTrail イベント履歴にあるリクエスタの IP アドレスと ID、およびリクエストの日付と時刻が含む Amazon Connect API コールを追跡します。AWS CloudTrail 証跡を作成すると、S3 バケットに AWS CloudTrail ログを継続的に配信できます。
Amazon Athena ワークグループでは、リソースベースのポリシーを使用して、クエリの実行を分離し、ユーザー、チーム、またはアプリケーションごとにアクセスを制御できます。ワークグループのデータ使用量を制限することで、コスト管理を強化できます。
モニタリング
オブザーバビリティは、コンタクトセンターとデータレイクの可用性、信頼性、パフォーマンスを確保するために不可欠です。Amazon CloudWatch
Amazon Connect は、Amazon CloudWatch メトリクスとして、インスタンスの使用状況データを 1 分間隔で送信します。Amazon CloudWatch メトリクスのデータ保持期間は 2 週間です。ログの保持要件とライフサイクルポリシーを早期に定義し、規制コンプライアンスを確保して、長期的なデータアーカイブのためのコスト削減を実現します。
Amazon CloudWatch Logs を使用すると、簡単な方法でログデータをフィルタリングし、コンプライアンス違反イベントを特定してインシデント調査や迅速な解決を行うことができます。問い合わせフローをカスタマイズして、リスクの高い発信者や不正行為の可能性があるアクティビティを検出できます。例えば、事前定義済みの拒否リストに登録されている受信連絡先の接続を切断できます。
分析
記述的、予測的、リアルタイム分析ポートフォリオに基づいて構築されたコンタクトセンターのデータレイクは、有意義な洞察を引き出し、重要なビジネス上の質問に対応しやすくなります。
データが S3 データレイクに格納されると、Amazon Athena や Amazon QuickSight
拡張性の高いデータウェアハウスソリューションを実現するため、Amazon Connect でデータストリーミングを有効にして、Amazon Kinesis 経由で Amazon Redshift
機械学習
データレイクを構築すると、コンタクトセンターのアーキテクチャに新たなパラダイムをもたらし、機械学習 (ML) 機能を使用して、強化およびパーソナライズされたカスタマーサービスを提供できるようになります。
従来の ML 開発は、複雑で費用のかかるプロセスです。AWS では、あらゆる ML プロジェクトやワークロードに対応する、高性能で費用対効果の高い、スケーラブルなインフラストラクチャと柔軟な ML サービス
Amazon SageMaker AI
顧客離れを防ぐには、カスタマージャーニーにおける摩擦を減らすことが不可欠です。コンタクトセンターにインテリジェンスを加えるには、Amazon Lex
全体的なサービス品質を向上させるには、発信者とエージェントの会話パターンを理解することが不可欠です。Kinesis Video Stream 経由
海外展開している組織の場合、Amazon Polly
従来の財務計画ソフトウェアは、一貫性のない傾向や関連変数を相関させることなく、過去の時系列データに基づいて予測を作成します。Amazon Forecast
Amazon Connect は、通話の発信元を示す音声デバイスの地理的位置、固定電話や携帯電話などの電話機の種類、通話が経由したネットワークセグメントの数、その他の通話の発信情報など、通信会社からの通話属性を提供します。フルマネージド型の Amazon Fraud Detector
