As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Ciclo de vida do data lake
A criação de um data lake normalmente envolve cinco etapas:
-
Configuração do armazenamento
-
Movimentação de dados
-
Preparação e catalogação de dados
-
Configuração de políticas de segurança
-
Disponibilização do dados para consumo
A figura a seguir é um diagrama de arquitetura de alto nível de um data lake de central de atendimento do Amazon Connect que se integra aos serviços de análise e inteligência artificial/machine learning (IA/ML) da AWS. A seção a seguir aborda os cenários e os serviços da AWS mostrados nesta figura.
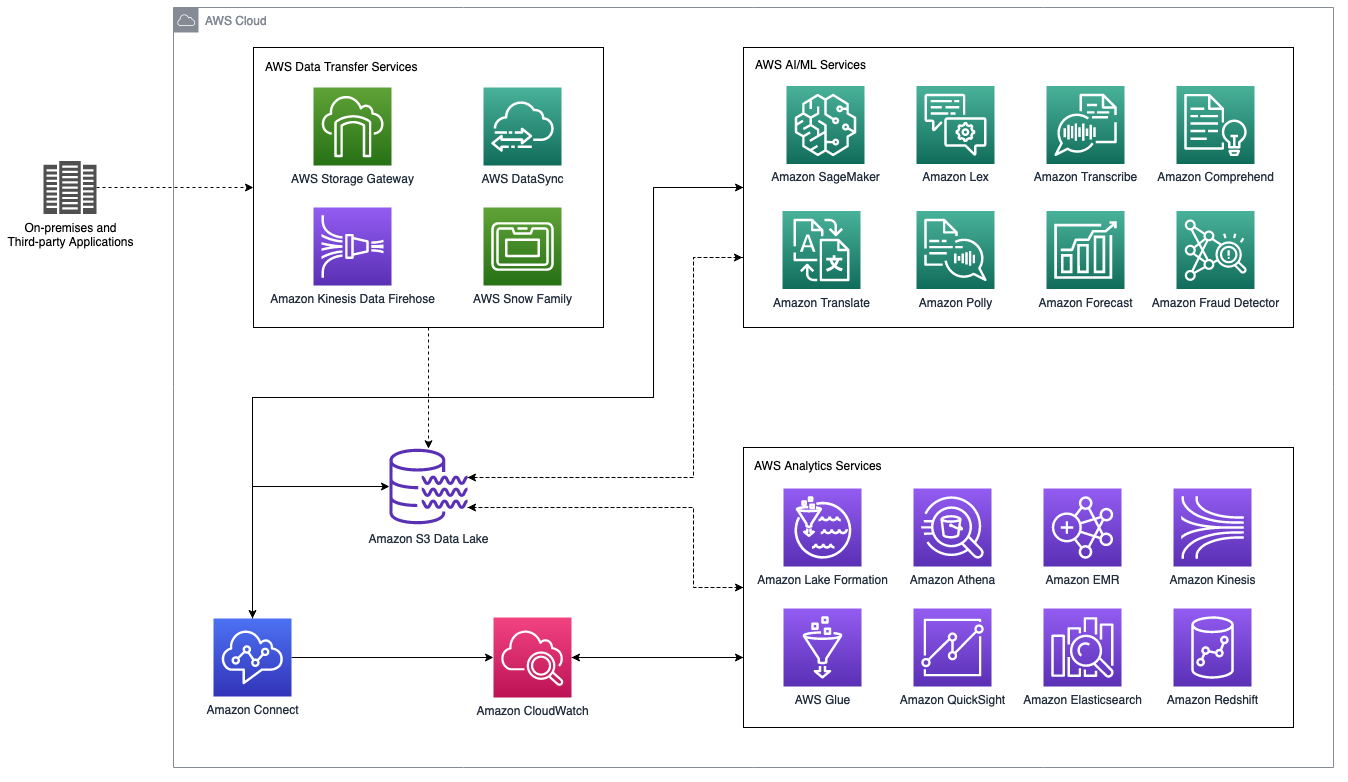
Data lake da central de atendimento do Amazon Connect com análises da AWS e serviços de IA/ML
Armazenamento
O Amazon S3
Com o Bloqueio de Acesso Público do S3 habilitado por padrão em todas as regiões do mundo, os buckets e objetos do S3 são privados. Você pode configurar controles de acesso centralizados nos recursos do S3 usando políticas de bucket, políticas AWS Identity and Access Management
O AWS CloudTrail
O S3 Intelligent-Tiering
O armazenamento de dados em formatos colunares, como Apache Parquet
Com o S3 Select e o S3 Glacier Select, você pode consultar metadados de objetos usando a expressão de linguagem de consulta estruturada (SQL) sem mover os objetos para outro armazenamento de dados.
O recurso Operações em Lote do S3
O recurso Pontos de Acesso do S3
O recurso Aceleração de Transferências do S3
À medida que o data lake cresce, o Lente de Armazenamento do S3
Ingestão
A AWS fornece um portfólio abrangente de serviços de transferência de dados para mover os dados existentes para um data lake centralizado. O Amazon Storage Gateway
-
O AWS Storage Gateway estende os ambientes on-premises para o armazenamento da AWS substituindo bibliotecas de fitas por armazenamento em nuvem, fornecendo compartilhamentos de arquivos baseados em armazenamento em nuvem ou criando um cache de baixa latência para você acessar dados na AWS em seus ambientes on-premises.
-
O AWS Direct Connect estabelece conectividade privada entre os ambientes on-premises e a AWS para reduzir os custos de rede, aumentar o throughput e fornecer uma experiência de rede consistente.
-
A AWS DataSync pode transferir milhões de arquivos para o S3, o Amazon Elastic File System
(Amazon EFS) ou o Amazon FSx for Windows File Server enquanto otimiza a utilização da rede. -
O Amazon Kinesis fornece uma maneira segura de capturar e carregar dados de streaming no S3. O Amazon Data Firehose
é um serviço totalmente gerenciado para fornecer dados de streaming em tempo real diretamente para o S3. O Firehose é escalado automaticamente para corresponder ao volume e à taxa de transferência dos dados de streaming e não requer administração contínua. Você pode transformar dados de streaming usando compressão, criptografia, agrupamento de dados em lotes ou AWS Lambda funções no Firehose antes de armazenar dados no S3. A criptografia Firehose oferece suporte à criptografia S3 do lado do servidor com (). AWS Key Management Service AWS KMSÉ também possível criptografar os dados com uma chave personalizada. O Firehose pode concatenar e entregar vários registros de entrada como um único objeto S3 para reduzir custos e otimizar a produtividade. A Família AWS Snow oferece um mecanismo de transferência de dados off-line. O AWS Snowball Edge
fornece um dispositivo de computação de borda portátil e robusto para coleta, processamento e migração de dados. Para transferência de dados em escala de exabytes, você pode usar o AWS Snowmobile para mover grandes volumes de dados para a nuvem. DistCp
fornece um recurso de cópia distribuída para mover dados no ecossistema Hadoop. O S3 DisctCp é uma extensão DistCp otimizada para mover dados entre o Hadoop Distributed File System (HDFS) e o S3. Este blog fornece informações sobre como mover dados entre o HDFS e o S3 usando o S3. DistCp
Catalogação
Um desafio comum em uma arquitetura de data lake é a falta de supervisão sobre o conteúdo dos dados brutos armazenados no data lake. As organizações precisam de governança, consistência semântica e controles de acesso para evitar as armadilhas de criar um pântano de dados sem seleção.
O AWS Lake Formation
AWS Glue DataBrew
Segurança
O Amazon Connect separa os dados por ID de conta da AWS e ID de instância do Amazon Connect para garantir o acesso autorizado aos dados em nível de instância do Amazon Connect.
O Amazon Connect criptografa informações de identificação pessoal (PII), dados de contato e perfis de clientes em repouso usando uma chave com tempo limitado específica para a instância do Amazon Connect. A criptografia do lado do servidor do S3 protege as gravações de voz e chat em repouso usando uma chave de dados do KMS que é exclusiva à cada conta da AWS. Você mantém total controle da segurança para configurar o acesso do usuário às gravações de chamadas no bucket do S3, como o rastreamento de quem escuta ou exclui as gravações de chamadas. O Amazon Connect criptografa as impressões de voz do cliente com uma chave do KMS de propriedade do serviço para proteger a identidade do cliente. Todos os dados trocados entre o Amazon Connect e outros serviços da AWS ou aplicações externas são sempre criptografados em trânsito usando a criptografia Transport Layer Security (TLS) padrão do setor.
A proteção de um data lake requer controles refinados para garantir o acesso e o uso autorizados dos dados. Por padrão, os recursos do S3 são privados e só podem ser acessados pelo proprietário do recurso. O proprietário do recurso pode criar uma combinação de políticas do IAM baseadas em recursos ou em identidade para conceder e gerenciar permissões para buckets e objetos do S3. Políticas baseadas em recursos, como políticas de bucket, e ACLs são anexadas aos recursos. Em contraposição, as políticas baseadas em identidade são anexadas a usuários, grupos ou perfis do IAM em sua conta da AWS.
Recomendamos políticas baseadas em identidade para a maioria dos ambientes de data lake com o objetivo de simplificar o gerenciamento de acesso a recursos e a permissão de serviços para os usuários de data lake. Você pode criar usuários, grupos e perfis do IAM em contas da AWS e associá-los a políticas baseadas em identidade que concedem acesso a recursos do S3.
O modelo de AWS Lake Formation permissão funciona em conjunto com as permissões do IAM para controlar o acesso ao data lake. O modelo de permissão do Lake Formation usa um mecanismo GRANT ou REVOKE no estilo do sistema de gerenciamento de banco de dados (DBMS). As permissões do IAM contêm políticas baseadas em identidade. Por exemplo, antes de acessar um recurso de data lake, o usuário precisa passar por verificações de permissão tanto do IAM quanto do Lake Formation.
AWS CloudTrail rastreia as chamadas da API Amazon Connect, incluindo o endereço IP e a identidade do solicitante e a data e hora da solicitação no Histórico de CloudTrail eventos. A criação de uma AWS CloudTrail trilha permite a entrega contínua de AWS CloudTrail registros para seu bucket do S3.
Os grupos de trabalho do Amazon Athena podem segmentar a execução de consultas e controlar o acesso de usuários, equipes ou aplicações usando políticas baseadas em recursos. Você pode impor o controle de custos limitando o uso de dados nos grupos de trabalho.
Monitoramento
A observabilidade é essencial para garantir a disponibilidade, a confiabilidade e o desempenho de uma central de atendimento e de um data lake. CloudWatchA Amazon
O Amazon Connect envia os dados de uso da instância como CloudWatch métricas da Amazon em um intervalo de um minuto. A retenção de dados para CloudWatch as métricas da Amazon é de duas semanas. Definir requisitos de retenção de logs e políticas de ciclo de vida logo no princípio garante a conformidade normativa e a redução de custos para arquivamento de dados a longo prazo.
O Amazon CloudWatch Logs fornece uma maneira simples de filtrar dados de log e identificar eventos de não conformidade para investigações de incidentes e agilizar as resoluções. É possível personalizar os fluxos de contato para detectar chamadas de alto risco ou atividades possivelmente fraudulentas. Por exemplo, você pode desconectar todos os contatos de entrada que estejam em sua lista de negação predefinida.
Analytics
Um data lake de central de atendimento criado com base em um portfólio de análises descritivas, preditivas e em tempo real ajuda você a extrair insights significativos e responder a questões de negócios essenciais.
Depois que seus dados chegarem ao data lake do S3, você poderá usar qualquer serviço de análise específico, como Amazon Athena e Amazon
Para uma solução de armazenamento de dados altamente escalável, você pode habilitar o streaming de dados no Amazon Connect para transmitir registros de contato para o Amazon Redshift por meio do Amazon
Machine learning
A criação de data lakes representa um novo paradigma para a arquitetura de central de atendimento, capacitando a empresa a oferecer um atendimento ao cliente aprimorado e personalizado por meio de recursos de machine learning (ML).
O desenvolvimento de ML tradicional é um processo complexo e caro. Além de uma infraestrutura abrangente e especializada que oferece alto desempenho, custo-benefício e escalabilidade, a AWS fornece serviços de ML
O Amazon SageMaker AI
Reduzir o atrito na jornada do cliente é essencial para evitar a rotatividade de clientes. Para adicionar inteligência à central de atendimento, você pode criar chatbots conversacionais habilitados por IA
Compreender a dinâmica entre chamador e atendente é essencial para melhorar a qualidade geral do serviço. Consulte este blog
Para organizações com presença internacional, você pode criar uma experiência de voz multilíngue
O software tradicional de planejamento financeiro cria previsões com base em dados históricos de séries temporais sem correlacionar tendências inconsistentes e variáveis relevantes. O Amazon Forecast
O Amazon Connect fornece recursos de chamada de operadoras de telefonia, como a localização geográfica do equipamento de voz para mostrar a origem da chamada, tipos de dispositivos telefônicos (por exemplo, telefone fixo ou móvel), número de segmentos de rede percorridos pela chamada e outras informações de origem das chamadas. Usando o Amazon Fraud Detector
