本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
个人数据 OU — PD 申请账户
我们很乐意听取你的意见。请通过简短的调查 |
个人数据 (PD) 应用程序账户是贵组织托管收集和处理个人数据的服务的地方。具体而言,您可以在此账户中存储您定义的个人数据。P AWS RA 通过多层无服务器 Web 架构演示了许多示例隐私配置。在跨 AWS 着陆区(Landing zone)操作工作负载时,不应将隐私配置视为 one-size-fits-all解决方案。例如,您的目标可能是了解基本概念,它们如何增强隐私,以及您的组织如何将解决方案应用于您的特定用例和架构。
对于 AWS 账户 在收集、存储或处理个人数据的组织中,您可以使用 AWS Organizations 和 AWS Control Tower 部署基础且可重复的护栏。为这些客户设立专门的组织单位 (OU) 至关重要。例如,您可能只想将数据驻留保护措施应用于以数据驻留为核心设计考虑因素的一部分客户。对于许多组织来说,这些账户用于存储和处理个人数据。
您的组织可能支持专用的数据帐户,您可以在该帐户中存储个人数据集的权威来源。权威数据源是您存储数据主版本的位置,该版本可能被认为是最可靠、最准确的数据版本。例如,您可以将数据从权威数据源复制到其他位置,例如 PD 应用程序账户中的 Amazon Simple Storage Service (Amazon S3) 存储桶,用于存储培训数据、客户数据子集和经过编辑的数据。通过采用这种多账户方法将数据账户中完整且明确的个人数据集与 PD Application 账户中的下游消费者工作负载分开,可以缩小账户遭到未经授权访问时的影响范围。
下图说明了在 PD 应用程序和数据帐户中配置 AWS 的安全和隐私服务。
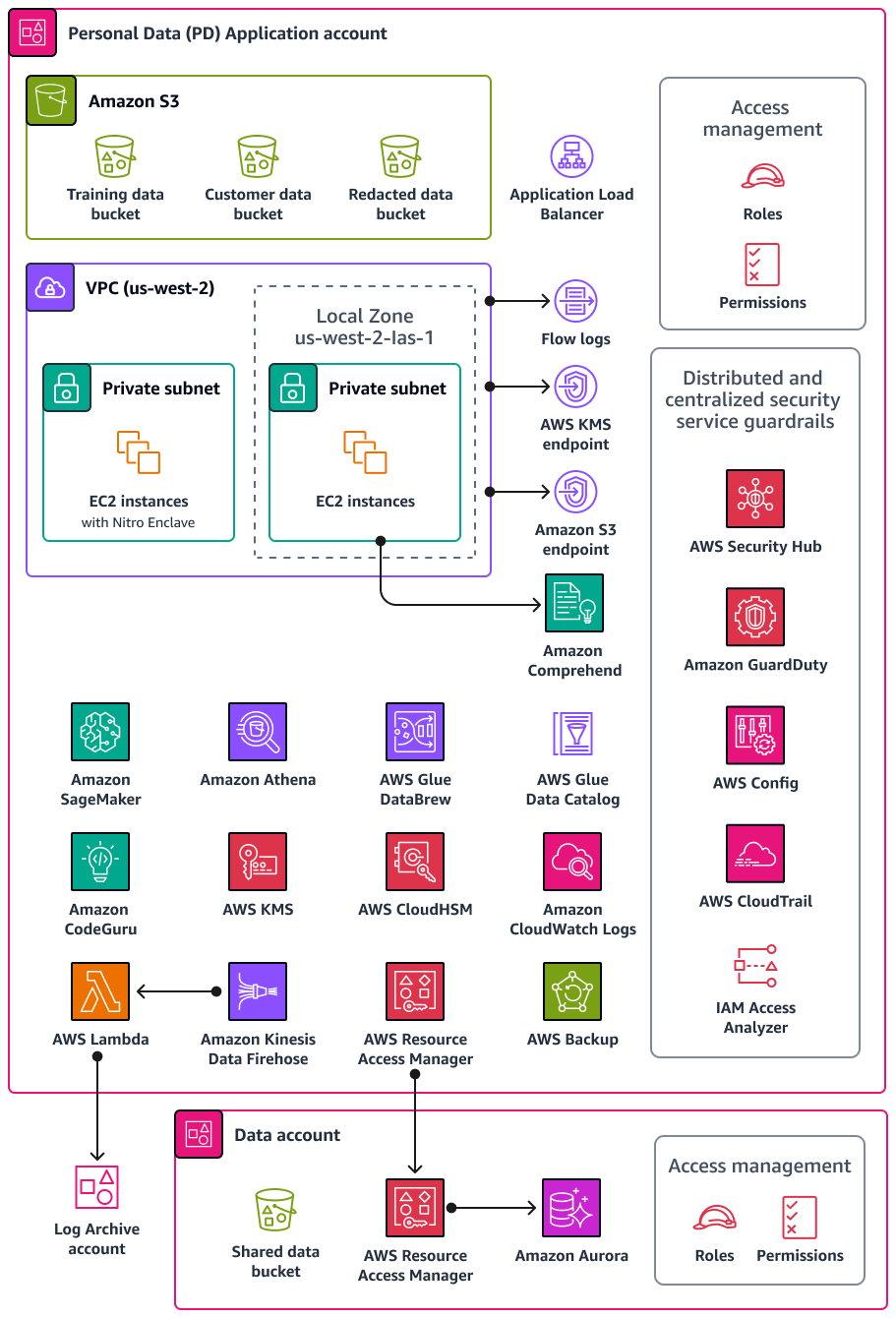
本节提供有关这些账户中 AWS 服务 使用的以下内容的更多详细信息:
Amazon Athena
您也可以考虑控制数据查询限制,以实现您的隐私目标。Amazon Athena 是一种交互式查询服务,可帮助您使用标准 SQL 直接在 Amazon S3 中分析数据。您不必将数据加载到 Athena;它可以直接处理存储在 S3 存储桶中的数据。
Athena 的一个常见用例是为数据分析团队提供量身定制和经过清理的数据集。如果数据集包含个人数据,则可以通过屏蔽对数据分析团队几乎没有价值的整列个人数据来对数据集进行消毒。有关更多信息,请参阅使用 A mazon AWS Lake Formation Athena AWS 对数据湖中的数据进行匿名化和管理
如果您的数据转换方法需要在 Athena 支持的函数之外获得额外的灵活性,则可以定义自定义函数,称为用户定义函数 (UDF)。你可以在提交给 Athena 的 SQL 查询 UDFs 中调用,然后它们就会继续运行。 AWS Lambda您可以 UDFs 在 in SELECT 和 quer FILTER
SQL ies 中使用,也可以在同一个查询 UDFs 中调用多个查询。为了保护隐私,您可以创建 UDFs 执行特定类型的数据屏蔽的内容,例如仅显示列中每个值的最后四个字符。
Amazon CloudWatch 日志
Amazon CloudWatch Lo gs 可帮助您集中所有系统和应用程序的日志, AWS 服务 这样您就可以监控它们并安全地将其存档。在 CloudWatch 日志中,您可以对新的或现有的日志组使用数据保护策略,以帮助最大限度地降低个人数据泄露的风险。数据保护策略可以检测日志中的敏感数据,例如个人数据。当用户通过访问日志时,数据保护策略可以屏蔽这些数据 AWS Management Console。当用户需要直接访问个人数据时,根据工作负载的总体目的规范,您可以为这些用户分配logs:Unmask权限。您还可以创建全账户的数据保护政策,并将该政策一致地应用于组织中的所有账户。默认情况下,这将为 Logs 中 CloudWatch 所有当前和将来的日志组配置屏蔽。我们还建议您启用审计报告并将其发送到另一个日志组、Amazon S3 存储桶或 Amazon Data Firehose。这些报告包含每个日志组中数据保护结果的详细记录。
Amazon CodeGuru Reviewer
对于隐私和安全而言,许多组织在部署和部署后阶段都必须支持持续的合规性,这一点至关重要。 AWS PRA 在部署管道中包括针对处理个人数据的应用程序的主动控制。Amazon CodeGuru Reviewer 可以检测可能泄露 Java 和 Python 代码中个人数据的潜在缺陷。 JavaScript它为开发人员提供了改进代码的建议。 CodeGuru Reviewer 可以识别各种安全、隐私和一般最佳实践中的缺陷。有关更多信息,请参阅 Amazon CodeGuru 探测器库。它旨在与多个来源提供商合作 AWS CodeCommit,包括Bitbucket和Amazon S3。 GitHub CodeGuru Reviewer 可以检测到的一些与隐私相关的缺陷包括:
-
SQL 注入
-
不安全的饼干
-
缺少授权
-
客户端重新 AWS KMS 加密
Amazon Comprehend
Amazon C omprehend 是一项自然语言处理 (NLP) 服务,它使用机器学习来发现英文文本文档中的宝贵见解和联系。Amazon Comprehend 可以检测和编辑结构化、半结构化或非结构化文本文档中的个人数据。有关更多信息,请参阅亚马逊 Comprehend 文档中的个人身份信息 (PII)。
您可以使用 AWS SDKs 和 Amazon Comprehend API 将 Amazon Comprehend 与许多应用程序集成。例如,使用 Amazon Comprehend 使用亚马逊 S3 Object Lambda 检测和编辑个人数据。组织可以使用 S3 Object Lambda 向 Amazon S3 GET 请求添加自定义代码,以便在数据返回到应用程序时对其进行修改和处理。S3 Object Lambda 可以筛选行、动态调整图像大小、编辑个人数据等。代码由 AWS Lambda 函数提供支持,在完全由管理的基础架构上运行 AWS,因此无需创建和存储数据的衍生副本或运行代理。您无需更改应用程序即可使用 S3 Object Lambda 转换对象。您可以使用中的 ComprehendPiiRedactionS3Object Lambda 函数 AWS Serverless Application Repository 来编辑个人数据。此功能使用 Amazon Comprehend 来检测个人数据实体,并通过用星号替换这些实体来对其进行编辑。有关更多信息,请参阅 Amaz on S3 文档中的使用 S3 对象 Lambda 和 Amazon Comprehend 检测和编辑 PII 数据。
由于 Amazon Comprehend 有许多通过 SDKs AWS 进行应用程序集成的选项,因此您可以使用 Amazon Comprehend 在收集、存储和处理数据的许多不同位置识别个人数据。您可以使用 Amazon Comprehend 机器学习功能来检测和编辑应用程序AWS 日志(博客文章)、客户电子邮件、支持票证等中的个人数据
-
REPLACE_WITH_PII_ENTITY_TYPE用其类型替换每个 PII 实体。例如,Jane Doe 将被替换为 NAM E。 -
MASK用您选择的角色替换 PII 实体中的字符 (! 、#、$、%、& 、或 @)。例如,Jane Doe 可以替换为 **** ***。
Amazon Data Firehose
Amazon Data Firehos e 可用于捕获、转换流数据并将其加载到下游服务,例如适用于 Apache Flink 的亚马逊托管服务或 Amazon S3。Firehose 通常用于传输大量流数据,例如应用程序日志,而不必从头开始构建处理管道。
在向下游发送数据之前,您可以使用 Lambda 函数执行自定义或内置处理。为了保护隐私,此功能支持数据最小化和跨境数据传输要求。例如,您可以使用 Lambda 和 Firehose 转换多区域日志数据,然后再将其集中到日志存档账户中。有关更多信息,请参阅 Biogen:多账户集中式日志解决方案
AWS Glue
维护包含个人数据的数据集是 “设计隐私
AWS Glue Data Catalog
AWS Glue Data Catalog帮助您建立可维护的数据集。数据目录包含对用作中提取、转换和加载 (ETL) 作业的源和目标的数据的 AWS Glue引用。数据目录中的信息存储为元数据表,每个表指定一个数据存储。您可以运行 AWS Glue
爬网程序来清点各种数据存储类型的数据。您将内置和自定义分类器添加到爬虫中,这些分类器会推断出个人数据的数据格式和架构。然后,爬网程序将元数据写入数据目录。集中式元数据表可以更轻松地响应数据主体请求(例如删除权),因为它可以增加环境中不同个人数据源的结构和可预测性。 AWS 有关如何使用数据目录自动响应这些请求的完整示例,请参阅使用 Amazon S3 Find and Forget 处理数据湖中的数据擦除请求(AWS 博
AWS Glue DataBrew
AWS Glue DataBrew帮助您清理和规范化数据,还可以对数据进行转换,例如删除或屏蔽个人身份信息以及加密数据管道中的敏感数据字段。您还可以直观地映射数据的谱系,以了解数据所经历的各种数据源和转换步骤。随着您的组织努力更好地了解和跟踪个人数据的来源,此功能变得越来越重要。 DataBrew 帮助您在数据准备期间屏蔽个人数据。作为数据分析工作的一部分,您可以检测个人数据并收集统计信息,例如可能包含个人数据的列数和潜在类别。然后,您可以使用内置的可逆或不可逆数据转换技术,包括替换、哈希、加密和解密,所有这些都无需编写任何代码。然后,您可以使用下游经过清理和屏蔽的数据集来执行分析、报告和机器学习任务。中可用的一些数据屏蔽技术 DataBrew 包括:
-
哈希-对列值应用哈希函数。
-
替换-用其他外观真实的值替换个人数据。
-
清空或删除-将特定字段替换为空值,或删除该列。
-
屏蔽-使用字符乱码,或屏蔽列中的某些部分。
以下是可用的加密技术:
-
确定性加密-对列值应用确定性加密算法。确定性加密总是为值生成相同的密文。
-
概率加密-对列值应用概率加密算法。概率加密每次应用时都会生成不同的密文。
有关中提供的个人数据转换方法的完整列表 DataBrew,请参阅个人身份信息 (PII) 配方步骤。
AWS Glue 数据质量
AWS Glue Data Q uality 可帮助您在将高质量数据交付给数据使用者之前,主动实现跨数据管道的交付并实现这些数据的交付。 AWS Glue Data Quality 可对您的数据管道中的数据质量问题进行统计分析,可以在 Amazon 中触发警报 EventBridge,并可以提出质量规则建议以进行补救。 AWS Glue Data Quality 还支持使用特定于域的语言创建规则,因此您可以创建自定义的数据质量规则。
AWS Key Management Service
AWS Key Management Service (AWS KMS) 可帮助您创建和控制加密密钥以帮助保护您的数据。 AWS KMS 使用硬件安全模块在 FIPS 140-2 加密模块验证计划 AWS KMS keys 下进行保护和验证。有关如何在安全环境中使用此服务的更多信息,请参阅AWS 安全参考架构。
AWS KMS 与大多数提供加密功能 AWS 服务 的软件集成,您可以在处理和存储个人数据的应用程序中使用 KMS 密钥。您可以使用 AWS KMS 来帮助支持您的各种隐私要求并保护个人数据,包括:
-
使用客户托管的密钥可以更好地控制强度、轮换、到期时间和其他选项。
-
使用专用的客户托管密钥来保护允许访问个人数据的个人数据和机密。
-
定义数据分类级别,并为每个级别指定至少一个专用的客户托管密钥。例如,您可能有一个用于加密操作数据的密钥和另一个用于加密个人数据的密钥。
-
防止跨账户意外访问 KMS 密钥。
-
将 KMS 密钥存储在 AWS 账户 与要加密的资源相同的位置。
-
对 KMS 密钥的管理和使用实行职责分离。有关更多信息,请参阅如何使用 KMS 和 IAM 为 S3 中的加密数据启用独立的安全控制
(AWS 博客文章)。 -
通过预防性和反应性护栏强制自动轮换密钥。
默认情况下,KMS 密钥是存储的,并且只能在创建密钥的区域中使用。如果您的组织对数据驻留和主权有特定要求,请考虑多区域 KMS 密钥是否适合您的用例。多区域密钥是不同用途的 KMS 密钥 AWS 区域 ,可以互换使用。创建多区域密钥的过程会将您的密钥材料跨越 AWS 区域 国界 AWS KMS,因此这种缺乏区域隔离可能与您组织的合规目标不符。解决这个问题的一种方法是使用不同类型的 KMS 密钥,例如特定于区域的客户托管密钥。
AWS Local Zones
如果您需要遵守数据驻留要求,则可以部署专门存储和处理个人数据的资源 AWS 区域 来支持这些要求。您还可以使用 L AWS ocal Zones,它可以帮助您将计算、存储、数据库和其他精选 AWS 资源放在靠近人口众多和工业中心的地方。局部区域是地理上靠近大型都市区的延伸。 AWS 区域 您可以将特定类型的资源放置在本地区域内,靠近本地区域对应的区域。当某个区域在同一法律管辖区内不可用时,Local Zones 可以帮助您满足数据驻留要求。使用 Local Zones 时,请考虑在组织内部署的数据驻留控制。例如,您可能需要一个控件来防止数据从特定的本地区域传输到另一个区域。有关 SCPs 如何使用维护跨境数据传输护栏的更多信息,请参阅使用着陆区控制管理 AWS 本地区域中数据驻留的最佳实践
AWS Nitro 飞地
从处理角度考虑您的数据分段策略,例如使用诸如亚马逊弹性计算云 (Amazon EC2) 之类的计算服务处理个人数据。作为更大架构策略一部分的机密计算可以帮助您将个人数据处理隔离在隔离、受保护和可信的 CPU 飞地中。Enclaves 是独立的、经过强化的、高度受限的虚拟机。AWS Nitro Enclaves 是 Amazon EC2 的一项功能,可以帮助您创建这些隔离的计算环境。有关更多信息,请参阅 AWS Nitro 系统的安全设计(AWS 白皮书)。
Nitro Enclaves 部署的内核与父实例的内核分开。父实例的内核无权访问安全区。用户无法通过 SSH 或远程访问安全区中的数据和应用程序。处理个人数据的应用程序可以嵌入到安全区中,并配置为使用安全区的 Vsock,该套接字可以促进安全区与父实例之间的通信。
Nitro Enclaves 可以发挥作用的一个用例是两个数据处理器之间的联合处理,这两个数据处理器彼此分开 AWS 区域 ,可能彼此不信任。下图显示了如何使用安全区进行中央处理、使用 KMS 密钥在将个人数据发送到安全区之前对其进行加密,以及用于验证请求解密的飞地在其认证文档中是否具有唯一测量值的 AWS KMS key 策略。有关更多信息和说明,请参阅使用加密认证。 AWS KMS有关密钥策略的示例,请参阅本指南需要认证才能使用密钥 AWS KMS中的。
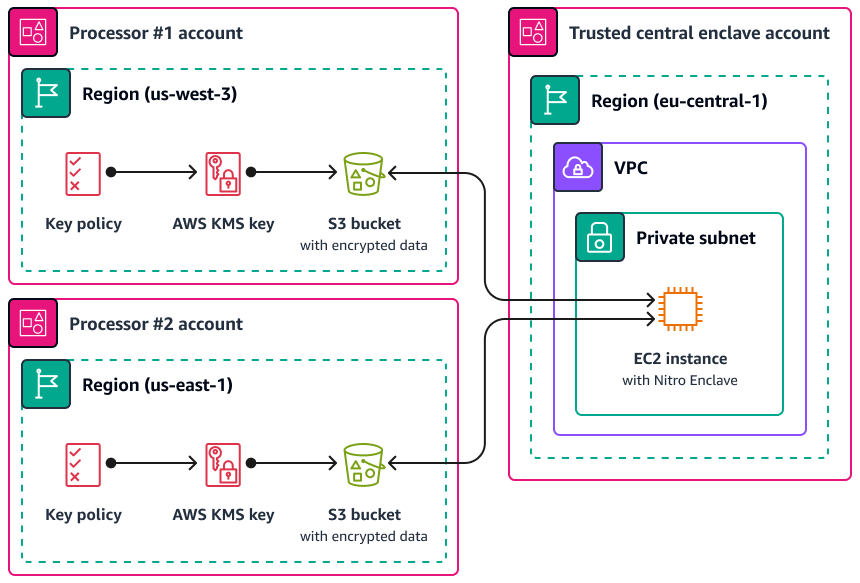
通过这种实现,只有相应的数据处理者和底层飞地才能访问纯文本个人数据。在相应数据处理器的环境之外,唯一暴露数据的位置是安全区本身,该安全区旨在防止访问和篡改。
AWS PrivateLink
许多组织都希望限制向不可信的网络泄露个人数据。例如,如果您想增强整体应用程序架构设计的隐私性,则可以根据数据敏感度对网络进行细分(类似于本有助于对数据进行细分的 AWS 服务和功能节中讨论的数据集的逻辑和物理分离)。 AWS PrivateLink帮助您创建从您的虚拟私有云 (VPCs) 到 VPC 外部服务的单向私有连接。使用 AWS PrivateLink,您可以与在您的环境中存储或处理个人数据的服务建立专用的私有连接;无需连接到公共端点并通过不受信任的公共网络传输这些数据。当您为范围内的 AWS PrivateLink 服务启用服务终端节点时,无需互联网网关、NAT 设备、公有 IP 地址、 AWS Direct Connect 连接或 AWS Site-to-Site VPN 连接即可进行通信。当您使用 AWS PrivateLink 连接到提供个人数据访问权限的服务时,您可以根据组织的数据边界
AWS Resource Access Manager
AWS Resource Access Manager (AWS RAM) 可帮助您安全地共享资源, AWS 账户 从而减少运营开销并提供可见性和可审计性。在规划多账户细分策略时,可以考虑使用 AWS RAM 来共享存储在单独的隔离账户中的个人数据存储。您可以与其他受信任的账户共享该个人数据以进行处理。在中 AWS RAM,您可以管理权限,这些权限定义可以对共享资源执行哪些操作。对的所有 API 调用 AWS RAM 均已登录 CloudTrail。此外,您还可以将 Amazon CloudWatch Events 配置为在中的 AWS RAM特定事件(例如资源共享发生更改时)自动通知您。
尽管您可以 AWS 账户 通过在 IAM 中使用基于 AWS 资源的策略或 Amazon S3 中的存储桶策略与其他人共享多种类型的资源,但这为隐私 AWS RAM 提供了一些额外的好处。 AWS 让数据所有者更清楚地了解在您之间共享数据的方式和与谁共享 AWS 账户,包括:
-
能够与整个 OU 共享资源,而不必手动更新账户列表 IDs
-
如果消费者账户不属于您的组织,则强制执行共享发起的邀请流程
-
了解哪些特定 IAM 委托人有权访问每个单独的资源
如果您之前曾使用基于资源的策略来管理资源共享,但想 AWS RAM 改用,请使用 PromoteResourceShareCreatedFromPolicyAPI 操作。
亚马逊 SageMaker AI
Amazon SageMaker AI 是一项托管机器学习 (ML) 服务,可帮助您构建和训练机器学习模型,然后将其部署到生产就绪的托管环境中。 SageMaker AI 旨在让准备训练数据和创建模型特征变得更加容易。
亚马逊 SageMaker AI 模型监视器
许多组织在训练机器学习模型时会考虑数据漂移。数据漂移是生产数据和用于训练机器学习模型的数据之间的有意义的差异,或者是输入数据随时间的推移而发生的有意义的变化。数据漂移可能降低机器学习模型预测的整体质量、准确性和公平性。如果机器学习模型在生产中接收的数据的统计性质偏离了其训练所依据的基线数据的性质,则预测的准确性可能会下降。Amazon SageMaker AI 模型监控器可以持续监控生产中亚马逊 SageMaker AI 机器学习模型的质量并监控数据质量。尽早主动检测数据漂移可以帮助您实施纠正措施,例如重新训练模型、审计上游系统或修复数据质量问题。Model Monitor 可以减少手动监控模型或构建其他工具的需求。
亚马逊 SageMaker AI 澄清
Amazon SageMaker AI C larify 提供了对模型偏差和可解释性的见解。 SageMaker AI Clarify 通常用于机器学习模型数据准备和整体开发阶段。开发人员可以指定感兴趣的属性,例如性别或年龄, SageMaker AI Clarify 会运行一组算法来检测这些属性中是否存在偏见。算法运行后, SageMaker AI Clarify 会提供一份可视化报告,其中描述了可能的偏见的来源和测量结果,以便您可以确定纠正偏差的步骤。例如,在仅包含向一个年龄组与其他年龄组相比向一个年龄组提供商业贷款的几个示例的财务数据集中, SageMaker 可以标记失衡,这样您就可以避免使用不利于该年龄组的模型。您还可以通过查看已训练模型的预测以及持续监控这些机器学习模型的偏差,来检查其是否存在偏差。最后, SageMaker AI Clarify 与 Amazon SageMaker AI Experiments 集成,提供了一个图表,解释了哪些功能对模型的整体预测过程贡献最大。这些信息对于实现可解释性结果可能很有用,它可以帮助您确定特定模型输入对模型整体行为的影响是否超过应有的影响力。
亚马逊 SageMaker 模型卡
Amazon SageMaker 模型卡可以帮助您记录机器学习模型的关键细节,以用于管理和报告目的。这些详细信息可能包括模型所有者、一般用途、预期用例、所做的假设、模型的风险评级、训练详细信息和指标以及评估结果。有关更多信息,请参阅利用 AWS 人工智能和 Machine Learning 解决方案实现模型可解释性(AWS 白皮书)。
AWS 有助于管理数据生命周期的功能
当不再需要个人数据时,您可以对许多不同数据存储中的数据使用生命周期和 time-to-live策略。配置数据保留策略时,请考虑以下可能包含个人数据的位置:
-
数据库,例如亚马逊 DynamoDB 和亚马逊关系数据库服务 (Amazon RDS)
-
Amazon S3 存储桶
-
来自 CloudWatch 和的日志 CloudTrail
-
缓存来自 AWS Database Migration Service (AWS DMS) 和 AWS Glue DataBrew 项目中迁移的数据
-
备份和快照
以下内容 AWS 服务 和功能可以帮助您在 AWS 环境中配置数据保留策略:
-
Amazon S3 生命周期 — 一组规则,用于定义 Amazon S3 应用于一组对象的操作。在 Amazon S3 生命周期配置中,您可以创建过期操作,这些操作定义了 Amazon S3 何时代表您删除过期对象。有关更多信息,请参阅管理存储生命周期。
-
Amazon Data Lifecycle Manager — 在亚马逊 EC2中,创建一项策略,自动创建、保留和删除亚马逊弹性区块存储 (Amazon EBS) 快照和 EBS 支持的亚马逊系统映像 ()。AMIs
-
DynamoDB 存活时间 (TTL)-定义每个项目的时间戳,该时间戳决定何时不再需要某个项目。在指定时间戳的日期和时间过后不久,DynamoDB 就会从您的表中删除该项目。
-
日志中的 CloudWatch 日志保留设置-您可以将每个日志组的保留策略调整为 1 天到 10 年之间的值。
-
AWS Backup— 集中部署数据保护策略,以配置、管理和控制各种 AWS 资源的备份活动,包括 S3 存储桶、RDS 数据库实例、DynamoDB 表、EBS 卷等。通过指定资源类型将备份策略应用于您的 AWS 资源,或者通过根据现有资源标签进行应用来提供额外的精度。通过集中式控制台审核和报告备份活动,以帮助满足备份合规性要求。
有助于对数据进行细分的 AWS 服务和功能
数据分段是将数据存储在单独的容器中的过程。这可以帮助您为每个数据集提供不同的安全性和身份验证措施,并缩小暴露对整个数据集的影响范围。例如,您可以将这些数据分成更小、更易于管理的组,而不是将所有客户数据存储在一个大型数据库中。
您可以使用物理和逻辑分离来分割个人数据:
-
物理分离 — 将数据存储在单独的数据存储中或将数据分发到单独的 AWS 资源中的行为。尽管数据在物理上是分开的,但相同的主体可能可以访问这两种资源。这就是为什么我们建议将物理分离与逻辑分离相结合。
-
逻辑分离-使用访问控制来隔离数据的行为。不同的工作职能要求对个人数据子集的访问权限各不相同。有关实现逻辑分离的策略示例,请参阅本指南授予对特定亚马逊 DynamoDB 属性的访问权限中的。
在编写基于身份和基于资源的策略以支持跨工作职能的差异访问权限时,逻辑和物理分离相结合,提供了灵活性、简单性和精细度。例如,在单个 S3 存储桶中创建在逻辑上分隔不同数据分类的策略在操作上可能很复杂。为每种数据分类使用专用 S3 存储桶可简化策略配置和管理。
