Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Importación
Puede utilizar Amazon SageMaker Data Wrangler para importar datos de las siguientes fuentes de datos: Amazon Simple Storage Service (Amazon S3), Amazon Athena, Amazon Redshift y Snowflake. El conjunto de datos que importe puede incluir un máximo de 1000 columnas.
Temas
- Importación de datos de Amazon S3
- Importación de datos de Athena
- Importación de datos de Amazon Redshift
- Importación de datos de Amazon EMR
- Importación de datos de Databricks (JDBC)
- Importación de datos de Salesforce Data Cloud.
- Importación de datos de Snowflake
- Importación de datos de plataformas de software como servicio (SaaS)
- Almacenamiento de datos importados
Algunos orígenes de datos permiten agregar varias conexiones de datos:
-
Puede conectarse a varios clústeres de Amazon Redshift. Cada clúster se convierte en un origen de datos.
-
Puede consultar cualquier base de datos de Athena de su cuenta para importar datos de esa base de datos.
Al importar un conjunto de datos de un origen de datos, aparece en el flujo de datos. Data Wrangler infiere automáticamente el tipo de datos de cada columna en su conjunto de datos. Para modificar estos tipos, seleccione el paso Tipos de datos y seleccione Editar tipos de datos.
Al importar datos de Athena o Amazon Redshift, los datos importados se almacenan automáticamente en el bucket de S3 SageMaker predeterminado de la región en AWS la que utilice Studio Classic. Además, Athena almacena los datos que previsualiza en Data Wrangler en este bucket. Para obtener más información, consulte Almacenamiento de datos importados.
importante
Es posible que el bucket de Amazon S3 predeterminado no tenga la configuración de seguridad menos permisiva, como la política de bucket y el cifrado del servidor (SSE). Se recomienda encarecidamente Agregar una política de bucket para restringir el acceso a los conjuntos de datos importados a Data Wrangler.
importante
Además, si utiliza la política administrada SageMaker, le recomendamos encarecidamente que la limite a la política más restrictiva que le permita llevar a cabo su caso de uso. Para obtener más información, consulte Conceder permiso a un rol de IAM para que utilice Data Wrangler.
Todas los orígenes de datos, excepto Amazon Simple Storage Service (Amazon S3), requieren que especifique una consulta SQL para importar los datos. Para cada consulta, debe especificar lo siguiente:
-
Catálogo de datos
-
Base de datos
-
Tabla
Puede especificar el nombre de la base de datos o del catálogo de datos en los menús desplegables o dentro de la consulta. A continuación, se muestran algunas consultas de ejemplo:
-
select * from: la consulta no utiliza nada especificado en los menús desplegables de la interfaz de usuario (UI) para ejecutarse. Realiza consultasexample-data-catalog-name.example-database-name.example-table-nameexample-table-namedentro deexample-database-namedentro deexample-data-catalog-name. -
select * from: la consulta utiliza el catálogo de datos que especificó en el menú desplegable Catálogo de datos para ejecutarse. Realiza consultasexample-database-name.example-table-nameexample-table-namedentro deexample-database-namedentro del catálogo de datos que haya especificado. -
select * from: la consulta requiere que seleccione campos para los menús desplegables Catálogo de datos y Nombre de la base de datos. Realiza consultasexample-table-nameexample-table-namedentro del catálogo de datos dentro de la base de datos y el catálogo de datos que haya especificado.
El enlace entre Data Wrangler y el origen de datos es una conexión. La conexión se utiliza para importar datos del origen de datos.
Existen los siguientes tipos de conexiones:
-
Directa
-
Catalogada
Data Wrangler siempre tiene acceso a los datos más recientes en una conexión directa. Si los datos del origen de datos se han actualizado, puede usar la conexión para importar los datos. Por ejemplo, si alguien agrega un archivo a uno de los buckets de Amazon S3, puede importar el archivo.
Una conexión catalogada es el resultado de una transferencia de datos. Los datos de la conexión catalogada no tienen necesariamente los datos más recientes. Por ejemplo, puede configurar una transferencia de datos entre Salesforce y Amazon S3. Si hay una actualización de los datos de Salesforce, debe volver a transferirlos. Puede automatizar el proceso de transferencia de datos. Para obtener más información sobre las transferencias de datos, consulte Importación de datos de plataformas de software como servicio (SaaS).
Importación de datos de Amazon S3
Puede usar Amazon Simple Storage Service (Amazon S3) para almacenar y recuperar cualquier cantidad de datos en cualquier momento y desde cualquier parte de la web. Puede realizar estas tareas mediante la AWS Management Console, que es una interfaz web sencilla e intuitiva, y la API Amazon S3. Si ha almacenado su conjunto de datos de forma local, se recomienda agregarlo a un bucket de S3 para importarlo a Data Wrangler. Para obtener instrucciones, consulte Cargar un objeto en el bucket en la Guía del usuario de Amazon Simple Storage Service.
Data Wrangler usa S3 Select
importante
Si planea exportar un flujo de datos y lanzar un trabajo de Data Wrangler, incorporar datos a una SageMaker feature store o crear un SageMaker pipeline, tenga en cuenta que estas integraciones requieren que los datos de entrada de Amazon S3 estén ubicados en la misma región. AWS
importante
Si va a importar un archivo CSV, asegúrese de que cumpla los siguientes requisitos:
-
Un registro de un conjunto de datos no puede tener más de una línea.
-
El único carácter de escape válido es una barra invertida,
\. -
El conjunto de datos debe utilizar uno de los siguientes delimitadores:
-
Coma:
, -
Dos puntos:
: -
Punto y coma:
; -
Barra:
| -
Tabulador:
[TAB]
-
Para ahorrar espacio, puede importar archivos CSV comprimidos.
Data Wrangler le permite importar todo el conjunto de datos o tomar una muestra de una parte del mismo. Para Amazon S3, proporciona las siguientes opciones de muestreo:
-
Ninguno: se importa todo el conjunto de datos.
-
Primeros K: toma una muestra de las primeras filas K del conjunto de datos, donde K es un número entero que especifique.
-
Aleatorio: toma una muestra aleatoria del tamaño que especifique.
-
Estratificado: toma una muestra aleatoria estratificada. Una muestra estratificada conserva la relación de valores de una columna.
Después de importar los datos, también puede usar el transformador de muestreo para tomar una o más muestras de todo el conjunto de datos. Para obtener más información sobre el transformador de muestreo, consulte Muestreo.
Puede utilizar uno de los siguientes identificadores de recursos para importar los datos:
-
Un URI de Amazon S3 que utiliza un bucket de Amazon S3 o un punto de acceso de Amazon S3
-
Un alias de punto de acceso de Amazon S3
-
Un nombre de recurso de Amazon (ARN) que utiliza un bucket de Amazon S3 o un punto de acceso de Amazon S3
Los puntos de acceso de Amazon S3 son puntos de conexión de red con nombre que están asociados a los buckets. Cada punto de acceso tiene permisos y controles de red distintos. Para obtener más información acerca de los puntos de acceso, consulte Administración del acceso a datos con puntos de acceso de Amazon S3.
importante
Si utiliza un nombre de recurso de Amazon (ARN) para importar los datos, debe ser para un recurso ubicado en el mismo lugar Región de AWS que utiliza para acceder a Amazon SageMaker Studio Classic.
Puede importar un solo archivo o varios archivos como un conjunto de datos. Puede utilizar la operación de importación de varios archivos si tiene un conjunto de datos que está particionado en archivos independientes. Toma todos los archivos de un directorio de Amazon S3 y los importa como un único conjunto de datos. Para obtener información sobre los tipos de archivos que puede importar y cómo importarlos, consulte las siguientes secciones.
También puede usar parámetros para importar un subconjunto de archivos que se correspondan con un patrón. Los parámetros le ayudan a seleccionar de forma más selectiva los archivos que va a importar. Para empezar a utilizar los parámetros, edite el origen de datos y aplíquelos a la ruta que va a utilizar para importar los datos. Para obtener más información, consulte Reutilización de flujos de datos para diferentes conjuntos de datos.
Importación de datos de Athena
Utilice Amazon Athena para importar los datos de Amazon Simple Storage Service (Amazon S3) a Data Wrangler. En Athena, escribe consultas SQL estándar para seleccionar los datos que va a importar de Amazon S3. Para obtener más información, consulte ¿Qué es Amazon Athena?
Puede utilizarla AWS Management Console para configurar Amazon Athena. Debe crear al menos una base de datos en Athena antes de comenzar a ejecutar consultas. Para obtener más información sobre cómo empezar a utilizar Athena, consulte Introducción.
Athena se integra directamente con Data Wrangler. Puede escribir consultas de Athena sin tener que salir de la interfaz de usuario de Data Wrangler.
Además de escribir consultas sencillas de Athena en Data Wrangler, también puede usar:
-
Grupos de trabajo de Athena para la administración de los resultados de las consultas. Para obtener información acerca de los grupos de trabajo, consulte Administración de resultados de las consultas.
-
Configuraciones del ciclo de vida para establecer los períodos de retención de datos. Para obtener más información acerca de la retención de datos, consulte Configuración de periodo de retención de datos .
Consulta a Athena en Data Wrangler
nota
Data Wrangler no admite consultas federadas.
Si lo usa AWS Lake Formation con Athena, asegúrese de que sus permisos de IAM de Lake Formation no anulen los permisos de IAM para la base de datos. sagemaker_data_wrangler
Data Wrangler le permite importar todo el conjunto de datos o tomar una muestra de una parte del mismo. Para Athena, proporciona las siguientes opciones de muestreo:
-
Ninguno: se importa todo el conjunto de datos.
-
Primeros K: toma una muestra de las primeras filas K del conjunto de datos, donde K es un número entero que especifique.
-
Aleatorio: toma una muestra aleatoria del tamaño que especifique.
-
Estratificado: toma una muestra aleatoria estratificada. Una muestra estratificada conserva la relación de valores de una columna.
En el procedimiento siguiente, se muestra cómo importar un conjunto de datos de Athena a Data Wrangler.
Para importar un conjunto de datos a Data Wrangler desde Athena
-
Inicia sesión en Amazon SageMaker Console
. -
Elija Studio.
-
Elija Lanzar aplicación.
-
En la lista desplegable, seleccione Studio.
-
Elija el icono Inicio.
-
Elija Datos.
-
Elija Data Wrangler.
-
Elija Importar datos.
-
En Disponible, seleccione Amazon Athena.
-
En Catálogo de datos, elija un catálogo de datos.
-
Utilice la lista desplegable Base de datos para seleccionar la base de datos que desea consultar. Al seleccionar una base de datos, puede obtener una vista previa de todas las tablas de la base de datos mediante las Tablas que aparecen en Detalles.
-
De forma opcional, elija Configuración avanzada.
-
Elija un Grupo de trabajo.
-
Si su grupo de trabajo no ha impuesto la ubicación de salida de Amazon S3 o si no utiliza un grupo de trabajo, especifique un valor para la Ubicación de Amazon S3 de los resultados de la consulta.
-
De forma opcional, para Período de retención de datos, seleccione la casilla de verificación para establecer un período de retención de datos y especifique el número de días que se almacenarán los datos antes de que se eliminen.
-
(Opcional) De forma predeterminada, Data Wrangler guarda la conexión. Puede optar por quitar la marca de selección de la casilla de verificación y no guardar la conexión.
-
-
En muestreo, elija un método de muestreo. Elija Ninguno para desactivar el muestreo.
-
Ingrese la consulta en el editor de consultas y utilice el botón Ejecutar para ejecutar la consulta. Una vez que la consulta se haya realizado correctamente, puede obtener una vista previa del resultado en el editor.
nota
Los datos de Salesforce utilizan el tipo
timestamptz. Si va a consultar la columna de fecha y hora que ha importado a Athena desde Salesforce, asigne los datos de la columna al tipotimestamp. La siguiente consulta convierte la columna de fecha y hora en el tipo correcto.# cast column timestamptz_col as timestamp type, and name it as timestamp_col select cast(timestamptz_col as timestamp) as timestamp_col from table -
Para importar los resultados de la consulta, seleccione Importar.
Tras completar el procedimiento anterior, el conjunto de datos que ha consultado e importado aparece en el flujo de Data Wrangler.
De forma predeterminada, Data Wrangler guarda la configuración de conexión como una conexión nueva. Al importar los datos, la consulta que ya especificó aparece como una conexión nueva. Las conexiones guardadas almacenan información sobre los grupos de trabajo de Athena y los buckets de Amazon S3 que utiliza. Cuando vuelva a conectarse al origen de datos, podrá elegir la conexión guardada.
Administración de resultados de las consultas
Data Wrangler admite el uso de grupos de trabajo de Athena para administrar los resultados de las consultas dentro de una cuenta de AWS . Puede especificar una ubicación de salida de Amazon S3 para cada grupo de trabajo. También puede especificar si el resultado de la consulta puede ir a diferentes ubicaciones de Amazon S3. Para obtener más información, consulte Uso de grupos de trabajo para controlar el acceso a las consultas y los costos.
Es posible que el grupo de trabajo esté configurado para aplicar la ubicación de salida de la consulta de Amazon S3. No puede cambiar la ubicación de salida de los resultados de la consulta para esos grupos de trabajo.
Si no utilizas un grupo de trabajo ni especificas una ubicación de salida para tus consultas, Data Wrangler utiliza el bucket predeterminado de Amazon S3 en la misma AWS región en la que se encuentra tu instancia de Studio Classic para almacenar los resultados de las consultas de Athena. Crea tablas temporales en esta base de datos para mover el resultado de la consulta a este bucket de Amazon S3. Elimina estas tablas después de importar los datos; sin embargo, la base de datos, sagemaker_data_wrangler, persiste. Para obtener más información, consulte Almacenamiento de datos importados.
Para usar los grupos de trabajo de Athena, configure la política de IAM que da acceso a los grupos de trabajo. Si utiliza un SageMaker-Execution-Role, se recomienda agregar la política al rol. Para obtener más información sobre las políticas de IAM para los grupos de trabajo, consulte Políticas de IAM para acceder a los grupos de trabajo. Para ver ejemplos de políticas de grupos de trabajo, consulte Ejemplos de políticas de grupos de trabajo.
Configuración de periodo de retención de datos
Data Wrangler establece automáticamente un período de retención de datos para los resultados de la consulta. Los resultados se eliminan una vez transcurrido el período de retención. Por ejemplo, el período de retención predeterminado es de cinco días. Los resultados de la consulta se eliminan al cabo de cinco días. Esta configuración está diseñada para ayudarle a limpiar los datos que ya no utiliza. La limpieza de los datos evita que usuarios no autorizados accedan a ellos. También ayuda a controlar los costos de almacenamiento de los datos en Amazon S3.
Si no establece un período de retención, la configuración del ciclo de vida de Amazon S3 determina el tiempo durante el que se almacenan los objetos. La política de retención de datos que especificó para la configuración del ciclo de vida elimina los resultados de las consultas que sean anteriores a la configuración del ciclo de vida que especificó. Para obtener más información, consulte Configurar el ciclo de vida de un bucket.
Data Wrangler utiliza las configuraciones del ciclo de vida de Amazon S3 para administrar la retención y el vencimiento de los datos. Debe conceder a su función de ejecución de IAM de Amazon SageMaker Studio Classic los permisos para gestionar las configuraciones del ciclo de vida de los buckets. Utilice el siguiente procedimiento para conceder permisos.
Para conceder permisos para administrar la configuración del ciclo de vida, haga lo siguiente.
-
Elija Roles.
-
En la barra de búsqueda, especifique la función de SageMaker ejecución de Amazon que utiliza Amazon SageMaker Studio Classic.
-
Elija el rol .
-
Elija Añadir permisos.
-
Elija Crear política insertada.
-
En Servicio, especifique S3 y elíjalo.
-
En la sección Leer, selecciona GetLifecycleConfiguration.
-
En la sección Escribir, selecciona PutLifecycleConfiguration.
-
En Recursos, elija Específico.
-
En Acciones, seleccione el icono de flecha situado junto a Administración de permisos.
-
Elige PutResourcePolicy.
-
En Recursos, elija Específico.
-
Elija la casilla de verificación situada junto a Cualquiera de esta cuenta.
-
Elija Revisar política.
-
En Nombre, especifique un nombre.
-
Elija Crear política.
Importación de datos de Amazon Redshift
Amazon Redshift es un servicio de almacenamiento de datos administrado a escala de petabytes en la nube . El primer paso para crear un almacenamiento de datos es el lanzamiento de un conjunto de nodos, llamado un clúster de Amazon Redshift. Después de aprovisionar el clúster, puede cargar su conjunto de datos y, luego, realizar consultas de análisis de datos.
Puede conectarse a uno o más clústeres de Amazon Redshift y consultarlos en Data Wrangler. Para utilizar esta opción de importación, debe crear al menos un clúster en Amazon Redshift. Para obtener información sobre cómo hacerlo, consulte Introducción a Amazon Redshift.
Puede enviar los resultados de la consulta de Amazon Redshift a una de las siguientes ubicaciones:
-
El bucket de Amazon S3 predeterminado
-
Una ubicación de salida de Amazon S3 que especifique
Puede importar todo el conjunto de datos o tomar una muestra de una parte del mismo. Para Amazon Redshift, proporciona las siguientes opciones de muestreo:
-
Ninguno: se importa todo el conjunto de datos.
-
Primeros K: toma una muestra de las primeras filas K del conjunto de datos, donde K es un número entero que especifique.
-
Aleatorio: toma una muestra aleatoria del tamaño que especifique.
-
Estratificado: toma una muestra aleatoria estratificada. Una muestra estratificada conserva la relación de valores de una columna.
El bucket de Amazon S3 predeterminado se encuentra en la misma AWS región en la que se encuentra la instancia de Studio Classic para almacenar los resultados de las consultas de Amazon Redshift. Para obtener más información, consulte Almacenamiento de datos importados.
Para el bucket de Amazon S3 predeterminado o para el bucket que especifique, dispone de las siguientes opciones de cifrado:
-
El cifrado predeterminado del AWS lado del servicio con una clave gestionada de Amazon S3 (SSE-S3)
-
Una clave AWS Key Management Service (AWS KMS) que especifique
Una AWS KMS clave es una clave de cifrado que usted crea y administra. Para obtener más información sobre claves de KMS, consulte AWS Key Management Service.
Puede especificar una AWS KMS clave mediante la clave ARN o el ARN de su cuenta. AWS
Si utiliza la política gestionada de IAMAmazonSageMakerFullAccess, para conceder a un rol permiso para usar Data Wrangler en Studio Classic, el nombre de usuario de la base de datos debe tener el prefijo. sagemaker_access
Utilice los siguientes procedimientos para obtener información sobre cómo agregar un nuevo clúster.
nota
Data Wrangler utiliza la API de datos de Amazon Redshift con credenciales temporales. Para obtener más información sobre esta API, consulte Uso de la API de datos de Amazon Redshift en la Guía de administración de Amazon Redshift.
Para conectarse a un clúster de Amazon Redshift
-
Inicia sesión en Amazon SageMaker Console
. -
Elija Studio.
-
Elija Lanzar aplicación.
-
En la lista desplegable, seleccione Studio.
-
Elija el icono Inicio.
-
Elija Datos.
-
Elija Data Wrangler.
-
Elija Importar datos.
-
En Disponible, seleccione Amazon Athena.
-
Elija Amazon Redshift.
-
Elija Credenciales temporales (IAM) como Tipo.
-
Introduce un nombre de conexión. Data Wrangler utiliza este nombre para identificar esta conexión.
-
Ingrese el Identificador del clúster para especificar a qué clúster desea conectarse. Nota: Ingrese solo el identificador del clúster y no el punto de conexión completo del clúster de Amazon Redshift.
-
Especifique el Nombre de la base de datos a la que desea conectarse.
-
Ingrese un Usuario de la base de datos para identificar el usuario que desea utilizar para conectarse a la base de datos.
-
En Rol de IAM UNLOAD, ingrese el ARN del rol de IAM del rol que debe asumir el clúster de Amazon Redshift para mover y escribir datos en Amazon S3. Para obtener más información sobre esta función, consulte Autorizar a Amazon Redshift a acceder a AWS otros servicios en su nombre en la Guía de administración de Amazon Redshift.
-
Elija Conectar.
-
De forma opcional, en Ubicación de salida de Amazon S3, especifique el URI de S3 en el que almacenar los resultados de la consulta.
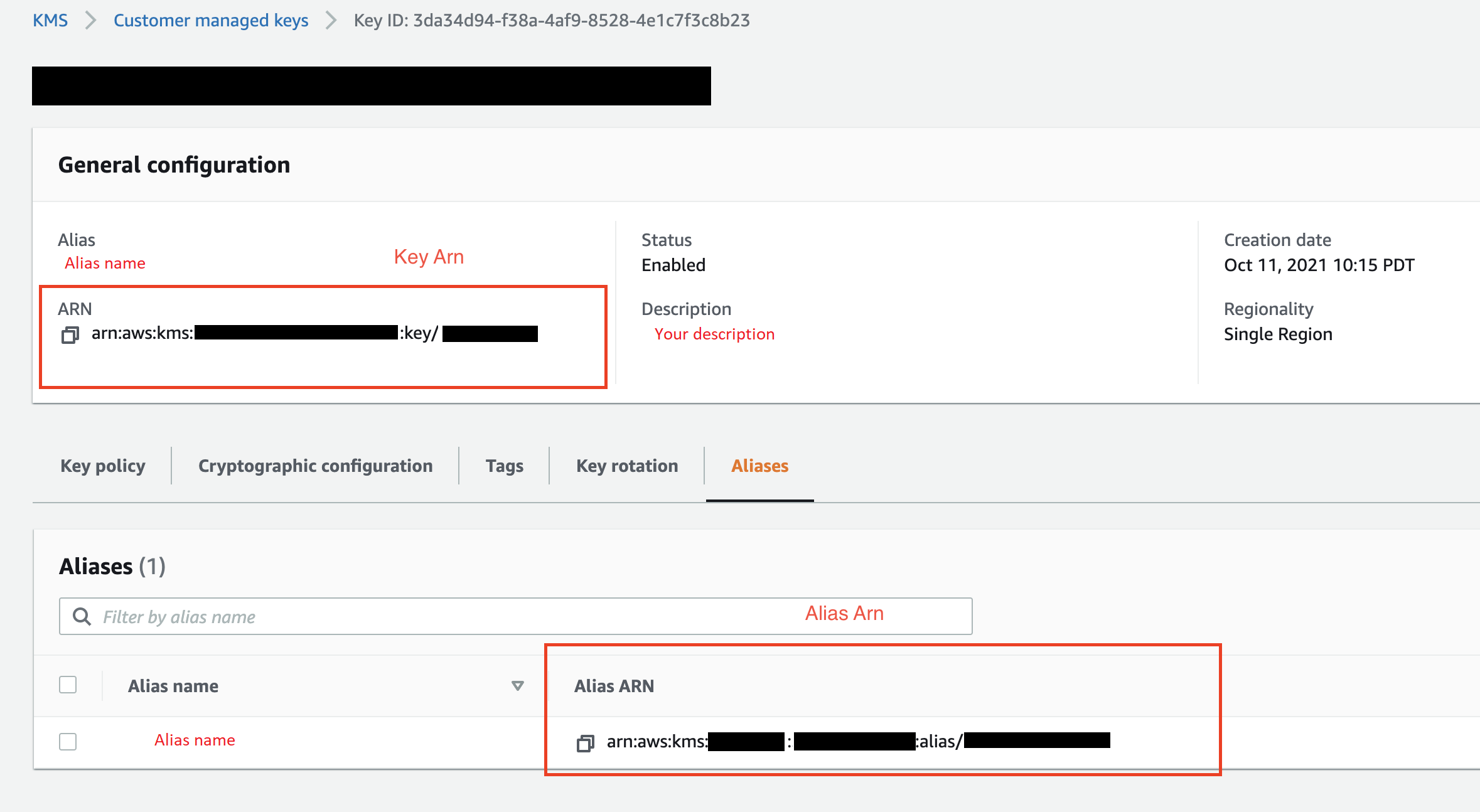
-
De forma opcional, en ID de clave de KMS, especifique el ARN de la clave de AWS KMS o el alias. La siguiente imagen muestra dónde se encuentra cada clave en la AWS Management Console.
La imagen siguiente muestra todos los campos del procedimiento anterior.
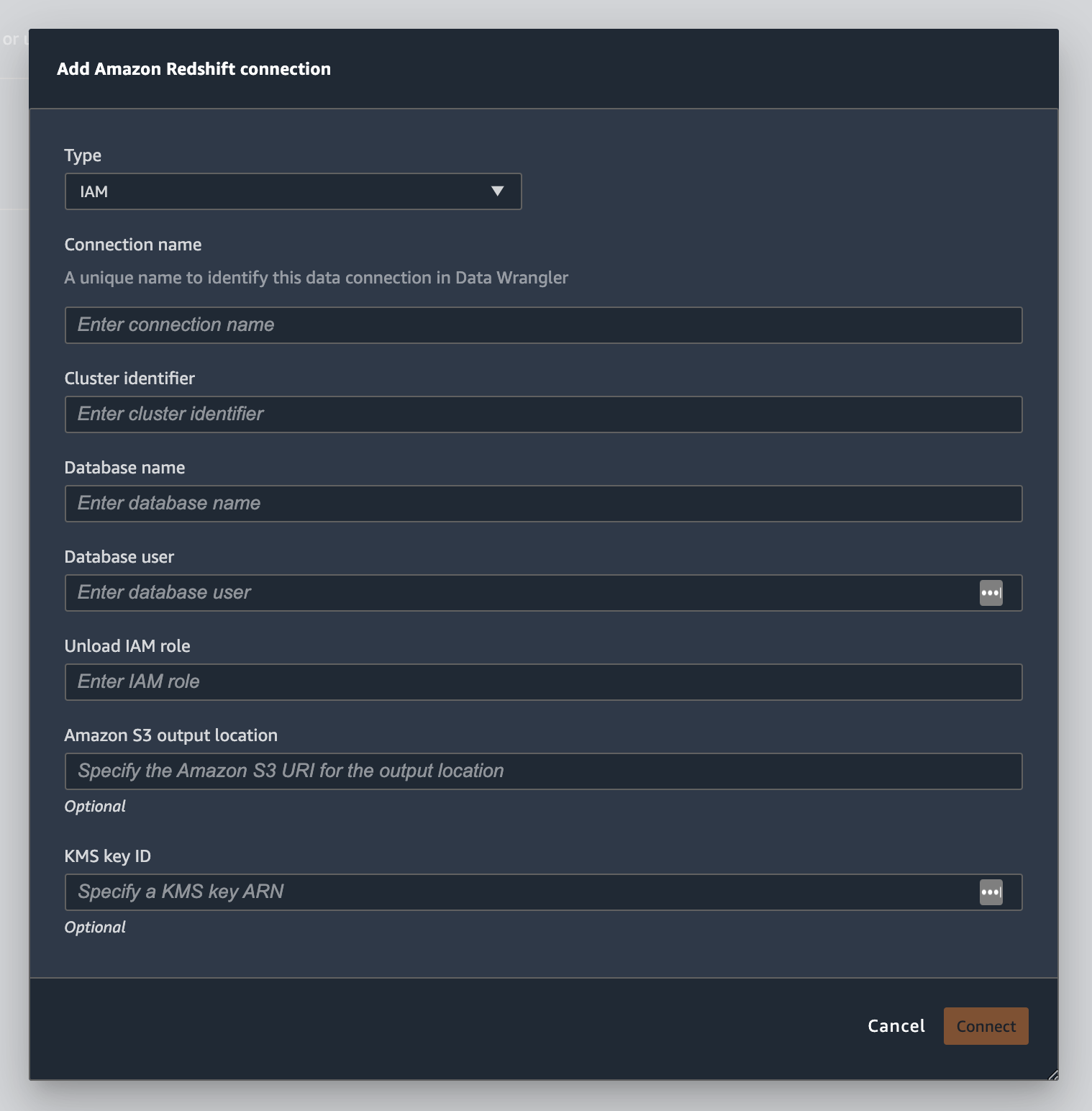
Cuando la conexión se haya establecido correctamente, aparecerá como origen de datos en la sección Importación de datos. Seleccione este origen de datos para consultar la base de datos e importar datos.
Para consultar e importar datos de Amazon Redshift
-
Seleccione la conexión que desee consultar de Orígenes de datos.
-
Seleccione un Esquema. Para obtener más información acerca de los esquemas de Amazon Redshift, consulte Esquemas en la Guía para desarrolladores de bases de datos de Amazon Redshift.
-
De forma opcional, en Configuración avanzada, especifique el método de Muestreo que desee utilizar.
-
Ingrese la consulta en el editor de consultas y elija Ejecutar para ejecutar la consulta. Una vez que la consulta se haya realizado correctamente, puede obtener una vista previa del resultado en el editor.
-
Seleccione Importar conjunto de datos para importar el conjunto de datos que se ha consultado.
-
Introduzca un Nombre del conjunto de datos. Si agrega un Nombre del conjunto de datos que contenga espacios, estos espacios se sustituirán por guiones bajos al importar el conjunto de datos.
-
Elija Añadir.
Para editar un conjunto de datos, haga lo siguiente.
-
Vaya a su flujo de Data Wrangler.
-
Elija el signo + situado junto a Origen: muestreado.
-
Cambie los datos que está importando.
-
Seleccione Apply (Aplicar)
Importación de datos de Amazon EMR
Puede utilizar Amazon EMR como fuente de datos para su flujo de Amazon SageMaker Data Wrangler. Amazon EMR es una plataforma de clúster administrada que puede utilizar para procesar y analizar grandes cantidades de datos. Para obtener más información sobre Amazon EMR, consulte ¿Qué es Amazon EMR? Para importar un conjunto de datos de EMR, debe conectarse a él y consultarlo.
importante
Debe cumplir los siguientes requisitos previos para conectarse a un clúster de Amazon EMR:
Requisitos previos
-
Configuraciones de red
-
Tiene una Amazon VPC en la región que utiliza para lanzar Amazon SageMaker Studio Classic y Amazon EMR.
-
Tanto Amazon EMR como Amazon SageMaker Studio Classic deben lanzarse en subredes privadas. Pueden estar en la misma subred o en subredes diferentes.
-
Amazon SageMaker Studio Classic debe estar en modo solo VPC.
Para obtener información acerca de la creación de una VPC, consulte Creación de una VPC.
Para obtener más información sobre la creación de una VPC, consulte Conectar los cuadernos clásicos de SageMaker Studio en una VPC a recursos externos.
-
Los clústeres de Amazon EMR que ejecuta deben estar en la misma Amazon VPC.
-
Los clústeres de Amazon EMR y la VPC de Amazon deben estar en la misma cuenta. AWS
-
Sus clústeres de Amazon EMR se ejecutan en Hive o Presto.
-
Los clústeres Hive deben permitir el tráfico entrante de los grupos de seguridad de Studio Classic en el puerto 10000.
-
Los clústeres de Presto deben permitir el tráfico entrante de los grupos de seguridad de Studio Classic en el puerto 8889.
nota
El número de puerto es diferente para los clústeres de Amazon EMR que utilizan roles de IAM. Vaya al final de la sección de requisitos previos para obtener más información.
-
-
-
SageMaker Studio Classic
-
Amazon SageMaker Studio Classic debe ejecutar la versión 3 de Jupyter Lab. Para obtener información sobre la actualización de la versión de Jupyter Lab, consulte Vea y actualice la JupyterLab versión de una aplicación desde la consola.
-
Amazon SageMaker Studio Classic tiene una función de IAM que controla el acceso de los usuarios. La función de IAM predeterminada que utiliza para ejecutar Amazon SageMaker Studio Classic no tiene políticas que le permitan acceder a los clústeres de Amazon EMR. Debe asociar la política que otorga permisos al rol de IAM. Para obtener más información, consulte Configurar la publicación de clústeres de Amazon EMR.
-
El rol de IAM también debe tener la siguiente política asociada:
secretsmanager:PutResourcePolicy. -
Si utilizas un dominio de Studio Classic que ya has creado, asegúrate de que
AppNetworkAccessTypeesté en modo solo VPC. Para obtener información sobre cómo actualizar un dominio para que utilice el modo solo VPC, consulte Cierre y actualice SageMaker Studio Classic.
-
-
Clústeres de Amazon EMR
-
Debe tener Hive o Presto instalados en el clúster.
-
La versión de Amazon EMR debe ser 5.5.0 o posterior.
nota
Amazon EMR admite la terminación automática. La terminación automática impide que los clústeres inactivos se ejecuten y evita que usted incurra en costos. Las siguientes versiones admiten la terminación automática:
-
Para las versiones 6.x, versión 6.1.0 o posterior.
-
Para las versiones 5.x, versión 5.30.0 o posterior.
-
-
-
Clústeres de Amazon EMR que utilizan roles de tiempo de ejecución de IAM
-
Utilice las siguientes páginas para configurar los roles de tiempo de ejecución de IAM para el clúster de Amazon EMR. Cuando utilice roles de tiempo de ejecución, debe habilitar el cifrado en tránsito:
-
Debe usar Lake Formation como herramienta de gobernanza para los datos de sus bases de datos. También debe utilizar un filtrado de datos externo para el control de acceso.
-
Para obtener más información sobre Lake Formation, consulte ¿Qué es AWS Lake Formation?
-
Para obtener más información sobre la integración de Lake Formation en Amazon EMR, consulte Integrating third-party services with Lake Formation.
-
-
La versión del clúster debe ser 6.9.0 o posterior.
-
Acceso a AWS Secrets Manager. Para obtener más información sobre Secrets Manager, consulte ¿Qué es AWS Secrets Manager Secrets Manager?
-
Los clústeres Hive deben permitir el tráfico entrante de los grupos de seguridad de Studio Classic en el puerto 10000.
-
Una Amazon VPC es una red virtual aislada de forma lógica de otras redes de la nube. AWS Amazon SageMaker Studio Classic y su clúster de Amazon EMR solo existen en la VPC de Amazon.
Utilice el siguiente procedimiento para lanzar Amazon SageMaker Studio Classic en una Amazon VPC.
Para iniciar Studio Classic en una VPC, haga lo siguiente.
-
Navegue hasta la SageMaker consola en https://console.aws.amazon.com/sagemaker/
. -
Elige Launch SageMaker Studio Classic.
-
Elija Configuración estándar.
-
En el rol de ejecución predeterminado, elija el rol de IAM para configurar Studio Classic.
-
Elija la VPC en la que lanzó los clústeres de Amazon EMR.
-
En Subred, elija una subred privada.
-
En Grupo(s) de seguridad, especifique los grupos de seguridad que utilizar para el control entre las VPC.
-
Elija Solo VPC.
-
(Opcional) AWS usa una clave de cifrado predeterminada. También puede especificar una clave de AWS Key Management Service para cifrar los datos.
-
Elija Siguiente.
-
En Configuración de Studio, elija las configuraciones que mejor se adapten a su caso.
-
Elija Siguiente para omitir la configuración de SageMaker Canvas.
-
Elija Siguiente para omitir los ajustes de RStudio.
Si no tiene un clúster de Amazon EMR listo, puede utilizar el siguiente procedimiento para crear uno. Para obtener más información sobre Amazon EMR, consulte ¿Qué es Amazon EMR?
Para crear un clúster, haga lo siguiente.
-
Vaya a AWS Management Console.
-
En la barra de búsqueda, especifique
Amazon EMR. -
Elija Create cluster.
-
En Nombre del clúster, ingrese el nombre del clúster.
-
En Versión, seleccione la versión de lanzamiento del clúster.
nota
Amazon EMR admite la terminación automática en las siguientes versiones:
-
Para las versiones 6.x, versión 6.1.0 o posterior
-
Para las versiones 5.x, versión 5.30.0 o posterior
La terminación automática impide que los clústeres inactivos se ejecuten y evita que usted incurra en costos.
-
-
De forma opcional, en Aplicaciones, elija Presto.
-
Elija la aplicación que está ejecutando en el clúster.
-
En Redes, para Configuración de hardware, especifique las opciones de configuración del hardware.
importante
Para redes, elija la VPC que ejecuta Amazon SageMaker Studio Classic y elija una subred privada.
-
En Seguridad y acceso, especifique la configuración de seguridad.
-
Seleccione Crear.
Para ver un tutorial sobre cómo crear un clúster de Amazon EMR, consulte Introducción a Amazon EMR. Para obtener información sobre las prácticas recomendadas para configurar un clúster, consulte Consideraciones y prácticas recomendadas.
nota
Por motivos de seguridad, Data Wrangler solo puede conectarse a VPC en subredes privadas. No puede conectarse al nodo principal a menos que lo utilice AWS Systems Manager para sus instancias de Amazon EMR. Para obtener más información, consulte Securing access to EMR clusters using AWS Systems Manager
Actualmente, puede utilizar los siguientes métodos para acceder a un clúster de Amazon EMR:
-
Sin autenticación
-
Protocolo ligero de acceso a directorios (LDAP)
-
IAM (rol de tiempo de ejecución)
Si no se utiliza la autenticación o si se usa un LDAP puede que sea necesario crear varios clústeres y perfiles de instancias de Amazon EC2. Si es un administrador, es posible que deba proporcionar a grupos de usuarios diferentes niveles de acceso a los datos. Estos métodos pueden generar una sobrecarga administrativa que dificulte la administración de los usuarios.
Se recomienda utilizar un rol de tiempo de ejecución de IAM que permita a varios usuarios conectarse al mismo clúster de Amazon EMR. Un rol de tiempo de ejecución es un rol de IAM que puede asignar a un usuario que se está conectando a un clúster de Amazon EMR. Puede configurar el rol de IAM en tiempo de ejecución para que tenga permisos concretos para cada grupo de usuarios.
Utilice las siguientes secciones para crear un clúster de Amazon EMR de Presto o Hive con el LDAP activado.
Utilice las siguientes secciones para utilizar la autenticación LDAP para los clústeres de Amazon EMR que ya haya creado.
Utilice el siguiente procedimiento para importar datos de un clúster.
Para importar datos de un clúster, haga lo siguiente.
-
Abra un flujo de Data Wrangler.
-
Elija Create Connection (Crear conexión).
-
Elija Amazon EMR.
-
Aplique alguna de las siguientes acciones.
-
De forma opcional, en el ARN del secreto, especifique el número de recurso de Amazon (ARN) de la base de datos del clúster. Los secretos proporcionan seguridad adicional. Para obtener más información sobre los secretos, consulte ¿Qué es AWS Secrets Manager? Para obtener más información acerca de la creación de un secreto para el clúster, consulte Crear un AWS Secrets Manager secreto para el clúster.
importante
Debe especificar un secreto si utiliza un rol de tiempo de ejecución de IAM para la autenticación.
-
Seleccione un clúster de la lista desplegable.
-
-
Elija Siguiente.
-
En Seleccione un punto final para el
example-cluster-nameclúster, elija un motor de consultas. -
De forma opcional, seleccione Guardar conexión.
-
Elija Siguiente, seleccione inicio de sesión y elija una de estas opciones:
-
Sin autenticación
-
LDAP
-
IAM
-
-
En Iniciar sesión en el
example-cluster-nameclúster, especifique el nombre de usuario y la contraseña del clúster. -
Elija Conectar.
-
En el editor de consultas, especifique una consulta SQL.
-
Elija Ejecutar.
-
Seleccione Importar.
Crear un AWS Secrets Manager secreto para el clúster
Si utiliza un rol de tiempo de ejecución de IAM para acceder a su clúster de Amazon EMR, debe almacenar las credenciales que utiliza para acceder a Amazon EMR como un secreto de Secrets Manager. Todas las credenciales que utiliza para acceder al clúster se almacenan en el secreto.
Debe almacenar la siguiente información en el secreto:
-
Punto de conexión de JDBC:
jdbc:hive2://. -
Nombre de DNS: el nombre de DNS de su clúster de Amazon EMR. Puede ser el punto de conexión del nodo principal o el nombre de host.
-
Puerto:
8446.
También puede almacenar la siguiente información adicional en el secreto:
-
Rol de IAM: el rol de IAM que utiliza para acceder al clúster. Data Wrangler usa tu rol de SageMaker ejecución de forma predeterminada.
-
Ruta del almacén de confianza: de forma predeterminada, Data Wrangler crea una ruta del almacén de confianza para usted. También puede utilizar su propia ruta del almacén de confianza. Para obtener más información sobre las rutas de los almacenes de confianza, consulte Cifrado en tránsito en 2. HiveServer
-
Contraseña del almacén de confianza: de forma predeterminada, Data Wrangler crea una contraseña del almacén de confianza para usted. También puede utilizar su propia ruta del almacén de confianza. Para obtener más información sobre las rutas de los almacenes de confianza, consulte Cifrado en tránsito en la sección 2. HiveServer
Utilice el siguiente procedimiento para almacenar las credenciales en un secreto de Secrets Manager.
Para almacenar las credenciales como un secreto, haga lo siguiente.
-
Vaya a AWS Management Console.
-
En la barra de búsqueda, especifique Secrets Manager.
-
Elija AWS Secrets Manager.
-
Elija Almacenar un secreto nuevo.
-
En Secret type (Tipo de secreto), elija Other type of secret (Otro tipo de secreto).
-
En pares clave-valor, seleccione Texto sin formato.
-
Para los clústeres que ejecutan Hive, puede utilizar la siguiente plantilla para la autenticación de IAM.
{"jdbcURL": "" "iam_auth": {"endpoint": "jdbc:hive2://", #required "dns": "ip-xx-x-xxx-xxx.ec2.internal", #required "port": "10000", #required "cluster_id": "j-xxxxxxxxx", #required "iam_role": "arn:aws:iam::xxxxxxxx:role/xxxxxxxxxxxx", #optional "truststore_path": "/etc/alternatives/jre/lib/security/cacerts", #optional "truststore_password": "changeit" #optional }}nota
Después de importar los datos, se les aplican transformaciones. A continuación, exporta los datos que ha transformado a una ubicación específica. Si utiliza un cuaderno de Jupyter para exportar los datos transformados a Amazon S3, debe utilizar la ruta del almacén de confianza especificada en el ejemplo anterior.
Un secreto de Secrets Manager almacena la URL de JDBC del clúster de Amazon EMR como un secreto. El uso de un secreto es más seguro que introducir directamente las credenciales.
Utilice el siguiente procedimiento para almacenar la URL de JDBC como un secreto.
Para almacenar la URL de JDBC como un secreto, haga lo siguiente.
-
Vaya a AWS Management Console.
-
En la barra de búsqueda, especifique Secrets Manager.
-
Elija AWS Secrets Manager.
-
Elija Almacenar un secreto nuevo.
-
En Secret type (Tipo de secreto), elija Other type of secret (Otro tipo de secreto).
-
Para Pares clave-valor, especifique
jdbcURLcomo clave y una URL de JDBC válida como valor.El formato de una URL de JDBC válida depende de si se utiliza la autenticación y de si se utiliza Hive o Presto como motor de consulta. La siguiente lista muestra los formatos de URL de JBDC válidos para las distintas configuraciones posibles.
-
Hive, sin autenticación:
jdbc:hive2://emr-cluster-master-public-dns:10000/; -
Hive, autenticación LDAP:
jdbc:hive2://emr-cluster-master-public-dns-name:10000/;AuthMech=3;UID=david;PWD=welcome123; -
En el caso de Hive con SSL habilitado, el formato de URL de JDBC depende de si se utiliza un archivo de almacén de claves de Java para la configuración de TLS. El archivo de almacén de claves de Java ayuda a verificar la identidad del nodo maestro del clúster de Amazon EMR. Para usar un archivo de almacén de claves de Java, genérelo en un clúster de EMR y cárguelo en Data Wrangler. Para generar un archivo, utilice el siguiente comando en el clúster de Amazon EMR:
keytool -genkey -alias hive -keyalg RSA -keysize 1024 -keystore hive.jks. Para obtener información sobre la ejecución de comandos en un clúster de Amazon EMR, consulte Securing access to EMR clusters using AWS Systems Manager. Para cargar un archivo, elija la flecha hacia arriba en la barra de navegación izquierda de la interfaz de usuario de Data Wrangler. Los siguientes son los formatos de URL de JDBC válidos para Hive con SSL habilitado:
-
Sin un archivo de almacén de claves de Java:
jdbc:hive2://emr-cluster-master-public-dns:10000/;AuthMech=3;UID=user-name;PWD=password;SSL=1;AllowSelfSignedCerts=1; -
Con un archivo de almacén de claves de Java:
jdbc:hive2://emr-cluster-master-public-dns:10000/;AuthMech=3;UID=user-name;PWD=password;SSL=1;SSLKeyStore=/home/sagemaker-user/data/Java-keystore-file-name;SSLKeyStorePwd=Java-keystore-file-passsword;
-
-
Listo, sin autenticación: jdbc:presto://-dns:8889/; emr-cluster-master-public -
En el caso de Presto con autenticación LDAP y SSL habilitado, el formato de URL de JDBC depende de si se utiliza un archivo de almacén de claves de Java para la configuración de TLS. El archivo de almacén de claves de Java ayuda a verificar la identidad del nodo maestro del clúster de Amazon EMR. Para usar un archivo de almacén de claves de Java, genérelo en un clúster de EMR y cárguelo en Data Wrangler. Para cargar un archivo, elija la flecha hacia arriba en la barra de navegación izquierda de la interfaz de usuario de Data Wrangler. Para obtener información sobre cómo crear un archivo de almacén de claves de Java para Presto, consulte Java Keystore File for TLS
. Para obtener información sobre la ejecución de comandos en un clúster de Amazon EMR, consulte Securing access to EMR clusters using AWS Systems Manager . -
Sin un archivo de almacén de claves de Java:
jdbc:presto://emr-cluster-master-public-dns:8889/;SSL=1;AuthenticationType=LDAP Authentication;UID=user-name;PWD=password;AllowSelfSignedServerCert=1;AllowHostNameCNMismatch=1; -
Con un archivo de almacén de claves de Java:
jdbc:presto://emr-cluster-master-public-dns:8889/;SSL=1;AuthenticationType=LDAP Authentication;SSLTrustStorePath=/home/sagemaker-user/data/Java-keystore-file-name;SSLTrustStorePwd=Java-keystore-file-passsword;UID=user-name;PWD=password;
-
-
Durante el proceso de importación de datos desde un clúster de Amazon EMR, podría tener problemas. Para obtener información acerca de la solución de problemas, consulte Solución de problemas con Amazon EMR.
Importación de datos de Databricks (JDBC)
Puede usar Databricks como fuente de datos para su flujo de Amazon SageMaker Data Wrangler. Para importar un conjunto de datos de Databricks, utilice la funcionalidad de importación de JDBC (Java Database Connectivity) para acceder a su base de datos de Databricks. Después de acceder a la base de datos, especifique una consulta SQL para obtener los datos e importarlos.
Suponemos que tiene un clúster de Databricks en ejecución y que ha configurado su controlador JDBC para él. Para obtener más información, consulte las siguientes páginas de documentación de Databricks.
Data Wrangler almacena su URL de JDBC. AWS Secrets Manager Debe conceder permisos a su función de ejecución de IAM de Amazon SageMaker Studio Classic para usar Secrets Manager. Utilice el siguiente procedimiento para conceder permisos.
Para conceder permisos a Secrets Manager, haga lo siguiente.
-
Elija Roles.
-
En la barra de búsqueda, especifique la función de SageMaker ejecución de Amazon que utiliza Amazon SageMaker Studio Classic.
-
Elija el rol .
-
Elija Añadir permisos.
-
Elija Crear política insertada.
-
En Servicio, especifique Secrets Manager y elíjalo.
-
En Acciones, seleccione el icono de flecha situado junto a Administración de permisos.
-
Elija PutResourcePolicy.
-
En Recursos, elija Específico.
-
Elija la casilla de verificación situada junto a Cualquiera de esta cuenta.
-
Elija Revisar política.
-
En Nombre, especifique un nombre.
-
Elija Crear política.
Puede usar particiones para importar los datos con mayor rapidez. Las particiones dan a Data Wrangler la capacidad de procesar los datos en paralelo. De forma predeterminada, Data Wrangler usa 2 particiones. Para la mayoría de los casos de uso, 2 particiones ofrecen velocidades de procesamiento de datos casi óptimas.
Si decide especificar más de 2 particiones, también puede especificar una columna para particionar los datos. El tipo de valores de la columna debe ser numérico o de fecha.
Se recomienda usar particiones solo si comprende la estructura de los datos y cómo se procesan.
Puede importar todo el conjunto de datos o tomar una muestra de una parte del mismo. Para una base de datos de Databricks, proporciona las siguientes opciones de muestreo:
-
Ninguno: se importa todo el conjunto de datos.
-
Primeros K: toma una muestra de las primeras filas K del conjunto de datos, donde K es un número entero que especifique.
-
Aleatorio: toma una muestra aleatoria del tamaño que especifique.
-
Estratificado: toma una muestra aleatoria estratificada. Una muestra estratificada conserva la relación de valores de una columna.
Utilice el siguiente procedimiento para importar datos de una base de datos de Databricks.
Para importar datos de Databricks, haga lo siguiente.
-
Inicia sesión en Amazon SageMaker Console
. -
Elija Studio.
-
Elija Lanzar aplicación.
-
En la lista desplegable, seleccione Studio.
-
En la pestaña Importar datos de su flujo de Data Wrangler, elija Databricks.
-
Especifique los siguientes campos:
-
Nombre del conjunto de datos: un nombre que desee usar para el conjunto de datos en el flujo de Data Wrangler.
-
Controlador: com.simba.spark.jdbc.Driver.
-
URL de JDBC: la URL de la base de datos de Databricks. El formato de la URL puede variar entre las instancias de Databricks. Para obtener información sobre cómo encontrar la URL y especificar los parámetros que contiene, consulte JDBC configuration and connection parameters
. El siguiente es un ejemplo de cómo se puede formatear una URL: jdbc:spark://aws-sagemaker-datawrangler.cloud.databricks.com:443/default; transportMode=http; ssl=1; httpPath=sql/protocolV1/O/3122619508517275/0909-200301-cut318; =3; UID= token; PWD=. AuthMechpersonal-access-tokennota
Puede especificar el ARN del secreto que contenga la URL de JDBC en lugar de especificar la propia URL de JDBC. El secreto debe contener un par clave-valor con el siguiente formato:
jdbcURL:. Para obtener más información, consulte ¿Qué es Secrets Manager?JDBC-URL
-
-
Especifique una instrucción SQL SELECT.
nota
Data Wrangler no admite expresiones de tabla común (CTE) ni tablas temporales dentro de una consulta.
-
En muestreo, elija un método de muestreo.
-
Elija Ejecutar.
-
De forma opcional, en VISTA PREVIA, elija el engranaje para abrir la Configuración de la partición.
-
Especifique el número de particiones. Puede particionar por columna si especifica el número de particiones:
-
Ingrese el número de particiones: especifique un valor superior a 2.
-
(Opcional) Partición por columna: especifique los siguientes campos. Solo puede particionar por una columna si ha especificado un valor para Ingresar número de particiones.
-
Seleccionar columna: seleccione la columna que va a utilizar para la partición de datos. El tipo de valores de la columna debe ser numérico o de fecha.
-
Límite superior: el límite superior de los valores de la columna que ha especificado es el valor que utiliza en la partición. El valor que especifique no cambia los datos que importe. Solo afecta a la velocidad de la importación. Para obtener el mejor rendimiento, especifique un límite superior cercano al máximo de la columna.
-
Límite inferior: el límite inferior de los valores de la columna que ha especificado es el valor que utiliza en la partición. El valor que especifique no cambia los datos que importe. Solo afecta a la velocidad de la importación. Para obtener el mejor rendimiento, especifique un límite inferior cercano al mínimo de la columna.
-
-
-
-
Seleccione Importar.
Importación de datos de Salesforce Data Cloud.
Puede utilizar Salesforce Data Cloud como fuente de datos en Amazon SageMaker Data Wrangler para preparar los datos de su Salesforce Data Cloud para el aprendizaje automático.
Con Salesforce Data Cloud como origen de datos en Data Wrangler, puede conectarse rápidamente a los datos de Salesforce sin necesidad de escribir una sola línea de código. Puede unir sus datos de Salesforce con datos de cualquier otro origen de datos en Data Wrangler.
Una vez que se conecte a la nube de datos, puede hacer lo siguiente:
-
Visualizar los datos con visualizaciones integradas
-
Comprender los datos e identificar posibles errores y valores extremos
-
Transformar los datos con más de 300 transformaciones integradas
-
Exportar los datos que ha transformado
Configuración de administrador
importante
Antes de empezar, asegúrese de que sus usuarios utilizan Amazon SageMaker Studio Classic versión 1.3.0 o posterior. Para obtener información sobre cómo comprobar la versión de Studio Classic y actualizarla, consultePrepare datos de aprendizaje automático con Amazon SageMaker Data Wrangler.
Al configurar el acceso a Salesforce Data Cloud, debe completar las siguientes tareas:
-
Obtener la URL del dominio de Salesforce. Salesforce también hace referencia a la URL del dominio como URL de la organización.
-
Obtener las credenciales de OAuth de Salesforce.
-
Obtener la URL de autorización y la URL del token del dominio de Salesforce.
-
Crear un AWS Secrets Manager secreto con la configuración de OAuth.
-
Crear una configuración de ciclo de vida que Data Wrangler utilizará para leer las credenciales del secreto.
-
Otorgar permisos a Data Wrangler para leer el secreto.
Tras realizar las tareas anteriores, los usuarios pueden iniciar sesión en Salesforce Data Cloud mediante OAuth.
nota
Es posible que sus usuarios tengan problemas una vez que haya configurado todo esto. Para obtener más información acerca de la solución de problemas, consulte Solución de problemas con Salesforce.
Utilice el siguiente procedimiento para obtener la URL del dominio.
-
Vaya a la página de inicio de sesión de Salesforce.
-
En Quick find, especifique My Domain.
-
Copie el valor de Current My Domain URL en un archivo de texto.
-
Agregue
https://al principio de la URL.
Tras obtener la URL del dominio de Salesforce, puede utilizar el siguiente procedimiento para obtener las credenciales de inicio de sesión de Salesforce y permitir que Data Wrangler acceda a los datos de Salesforce.
Para obtener las credenciales de inicio de sesión de Salesforce y proporcionar acceso a Data Wrangler, haga lo siguiente.
-
Vaya a la URL del dominio de Salesforce e inicie sesión en su cuenta.
-
Seleccione el icono de la rueda.
-
En la barra de búsqueda que aparece, especifique App Manager.
-
Seleccione New Connected App.
-
Especifique los siguientes campos:
-
Nombre de la aplicación conectada: puede especificar cualquier nombre, pero se recomienda elegir uno que incluya Data Wrangler. Por ejemplo, puede especificar Integración de Salesforce Data Cloud y Data Wrangler.
-
Nombre de la API: utilice el valor predeterminado.
-
Correo electrónico de contacto: especifique su dirección de correo electrónico.
-
En el API heading (Enable OAuth Settings), seleccione la casilla de verificación para activar la configuración de OAuth.
-
En la URL de devolución de llamada, especifique la URL de Amazon SageMaker Studio Classic. Para obtener la URL de Studio Classic, acceda a ella desde AWS Management Console y cópiela.
-
-
En Selected OAuth Scopes, mueva lo siguiente de Available OAuth Scopes a Selected OAuth Scopes:
-
Administrar los datos de los usuarios a través de las API (
api) -
Realizar solicitudes en cualquier momento (
refresh_token,offline_access) -
Realizar consultas SQL ANSI en los datos de Salesforce Data Cloud (
cdp_query_api) -
Administrar los datos de perfil de la plataforma de datos de clientes de Salesforce (
cdp_profile_api)
-
-
Seleccione Guardar. Tras guardar los cambios, Salesforce abre una página nueva.
-
Elija Continue
-
Vaya a Consumer Key and Secret.
-
Elija Manage Consumer Details. Salesforce lo redirige a una nueva página en la que puede que tendrá que superar una autenticación de dos factores.
-
importante
Copie la clave del consumidor y el secreto del consumidor en un editor de texto. Necesitará esta información para conectar la nube de datos a Data Wrangler.
-
Vuelva a Manage Connected Apps.
-
Vaya Connected App Name y el nombre de su aplicación.
-
Elija Administrar.
-
Seleccione Edit Policies.
-
Cambie IP Relaxation a Relax IP restrictions.
-
Seleccione Guardar.
-
Después de proporcionar acceso a su Salesforce Data Cloud, debe proporcionar permisos a sus usuarios. Utilice el siguiente procedimiento para concederles permisos.
Para proporcionar permisos a los usuarios, haga lo siguiente.
-
Diríjase a la página de inicio de configuración.
-
En la barra de navegación de la izquierda, busque Users y elija la opción de menú Users.
-
Elija el hipervínculo con su nombre de usuario.
-
Vaya a Permission Set Assignments.
-
Elija Edit Assignments.
-
Agregue los siguientes permisos:
-
Customer Data Platform Admin
-
Customer Data Platform Data Aware Specialist
-
-
Seleccione Guardar.
Tras obtener la información de su dominio de Salesforce, debe obtener la URL de autorización y la URL del token del AWS Secrets Manager secreto que va a crear.
Utilice el procedimiento siguiente para obtener la URL de autorización y la URL del token.
Para obtener la URL de autorización y la URL del token
-
Vaya a la URL de su dominio de Salesforce.
-
Utilice uno de los siguientes métodos para obtener las URL. Si utiliza una distribución de Linux con
curlyjqinstalados, se recomienda utilizar el método que solo funciona en Linux.-
Solo en Linux, especifique el siguiente comando en su terminal.
curlsalesforce-domain-URL/.well-known/openid-configuration | \ jq '. | { authorization_url: .authorization_endpoint, token_url: .token_endpoint }' | \ jq '. += { identity_provider: "SALESFORCE", client_id: "example-client-id", client_secret: "example-client-secret" }' -
-
Vaya a
URL-ejemplo-org/.well-known/openid-configuration -
Copie
authorization_endpointytoken_endpointa un editor de texto. -
Cree el siguiente objeto JSON:
{ "identity_provider": "SALESFORCE", "authorization_url": "example-authorization-endpoint", "token_url": "example-token-endpoint", "client_id": "example-consumer-key", "client_secret": "example-consumer-secret" }
-
-
Tras crear el objeto de configuración de OAuth, puedes crear un AWS Secrets Manager secreto que lo almacene. Utilice el siguiente procedimiento para crear el secreto.
Para crear un secreto, haga lo siguiente:
-
Vaya a la consola de AWS Secrets Manager
. -
Elija Almacenar un secreto.
-
Seleccione Otro tipo de secreto.
-
En pares clave-valor, seleccione Texto sin formato.
-
Sustituya el JSON vacío por los siguientes ajustes de configuración.
{ "identity_provider": "SALESFORCE", "authorization_url": "example-authorization-endpoint", "token_url": "example-token-endpoint", "client_id": "example-consumer-key", "client_secret": "example-consumer-secret" } -
Elija Siguiente.
-
En Nombre del secreto, especifique el nombre del secreto.
-
En Etiquetas, elija Agregar.
-
En Clave, especifique sagemaker:partner. En Valor, se recomienda especificar un valor que sea útil para su caso de uso. Sin embargo, puede especificar cualquier cosa.
importante
Tiene que crear la clave. No puede importar sus datos de Salesforce si no los ha creado.
-
-
Elija Siguiente.
-
Elija Almacenar.
-
Elija el secreto que ha creado.
-
Tome nota de los siguientes campos:
-
El número de recurso de Amazon (ARN) del secreto
-
El nombre del secreto.
-
Una vez creado el secreto, debe agregar permisos para que Data Wrangler lo lea. Utilice el siguiente procedimiento para agregar permisos.
Para agregar permisos de lectura a Data Wrangler, haga lo siguiente.
-
Ve a la SageMaker consola de Amazon
. -
Elige dominios.
-
Elija el dominio que utiliza para acceder a Data Wrangler.
-
Elija su Perfil de usuario.
-
En Detalles, busque el Rol de ejecución. El ARN tiene el siguiente formato:
arn:aws:iam::111122223333:role/. Anote la función de SageMaker ejecución. Dentro de la ARN, es todo lo que viene después deexample-rolerole/. -
Vaya a la consola de IAM
. -
En la barra de búsqueda de Search IAM, especifique el nombre de la función de SageMaker ejecución.
-
Elija el rol .
-
Elija Añadir permisos.
-
Elija Crear política insertada.
-
Seleccione la pestaña JSON.
-
Especifique la siguiente política en el editor.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "secretsmanager:GetSecretValue", "secretsmanager:PutSecretValue" ], "Resource": "arn:aws:secretsmanager:*:*:secret:*", "Condition": { "ForAnyValue:StringLike": { "aws:ResourceTag/sagemaker:partner": "*" } } }, { "Effect": "Allow", "Action": [ "secretsmanager:UpdateSecret" ], "Resource": "arn:aws:secretsmanager:*:*:secret:AmazonSageMaker-*" } ] } -
Elija Revisar la política.
-
En Nombre, especifique un nombre.
-
Elija Crear política.
Tras conceder a Data Wrangler los permisos para leer el secreto, debe añadir una configuración del ciclo de vida que utilice el secreto de Secrets Manager a su perfil de usuario de Amazon SageMaker Studio Classic.
Utilice el siguiente procedimiento para crear una configuración de ciclo de vida y añadirla al perfil de Studio Classic.
Para crear una configuración de ciclo de vida y añadirla al perfil de Studio Classic, haga lo siguiente.
-
Ve a la SageMaker consola de Amazon.
-
Elige dominios.
-
Elija el dominio que utiliza para acceder a Data Wrangler.
-
Elija su Perfil de usuario.
-
Si ve las siguientes aplicaciones, elimínelas:
-
KernelGateway
-
JupyterKernel
nota
Al eliminar las aplicaciones, Studio Classic se actualiza. Las actualizaciones pueden tardar un poco.
-
-
Mientras espera a que se produzcan las actualizaciones, elija las Configuraciones de ciclo de vida.
-
Asegúrese de que la página en la que se encuentra indique las configuraciones del ciclo de vida de Studio Classic.
-
Seleccione Crear configuración.
-
Asegúrese de que se haya seleccionado la Aplicación de servidor de Jupyter.
-
Elija Siguiente.
-
En Nombre, especifique un nombre para la configuración.
-
En Scripts, especifique el siguiente script:
#!/bin/bash set -eux cat > ~/.sfgenie_identity_provider_oauth_config <<EOL { "secret_arn": "secrets-arn-containing-salesforce-credentials" } EOL -
Seleccione Submit (Enviar).
-
En la barra de navegación de la izquierda, selecciona dominios.
-
Seleccione su dominio.
-
Seleccione Entorno.
-
En Configuraciones del ciclo de vida de las aplicaciones personales de Studio Classic, selecciona Adjuntar.
-
Seleccione Configuración existente.
-
En Configuraciones del ciclo de vida de Studio Classic, selecciona la configuración del ciclo de vida que has creado.
-
Elija Asociar al dominio.
-
Seleccione la casilla situada junto a la configuración del ciclo de vida que ha asociado.
-
Seleccione Establecer como predeterminado.
Podría tener problemas al configurar el ciclo de vida. Para obtener información para depurarlo, consulte Depuración de configuraciones del ciclo de vida.
Guía para científicos de datos
Utilice lo siguiente para conectarse a Salesforce Data Cloud y acceder a sus datos en Data Wrangler.
importante
Su administrador tiene que usar la información de las secciones anteriores para configurar Salesforce Data Cloud. Si tiene problemas, póngase en contacto con ellos para obtener ayuda con la solución de problemas.
Para abrir Studio Classic y comprobar su versión, consulte el siguiente procedimiento.
-
Sigue los pasos que se indican Requisitos previos a continuación para acceder a Data Wrangler a través de Amazon SageMaker Studio Classic.
-
Junto al usuario que quieres usar para iniciar Studio Classic, selecciona Iniciar aplicación.
-
Elija Studio.
Para crear un conjunto de datos en Data Wrangler con datos de Salesforce Data Cloud
-
Inicia sesión en Amazon SageMaker Console
. -
Elija Studio.
-
Elija Lanzar aplicación.
-
En la lista desplegable, seleccione Studio.
-
Elija el icono Inicio.
-
Elija Datos.
-
Elija Data Wrangler.
-
Elija Importar datos.
-
En Disponible, seleccione Salesforce Data Cloud.
-
En Nombre de la conexión, especifique un nombre para su conexión a Salesforce Data Cloud.
-
En URL de la organización, especifique la URL de la organización en su cuenta de Salesforce. Puede obtener la URL de sus administradores.
-
Elija Conectar.
-
Especifique sus credenciales para iniciar sesión en Salesforce.
Puede empezar a crear un conjunto de datos con datos de Salesforce Data Cloud después de conectarse.
Una vez que seleccione una tabla, puede escribir consultas y ejecutarlas. El resultado de la consulta se muestra en Resultados de la consulta.
Una vez que haya establecido el resultado de la consulta, puede importarlo a un flujo de Data Wrangler para realizar transformaciones de datos.
Una vez que haya creado un conjunto de datos, vaya a hasta la pantalla Flujo de datos para empezar a transformar los datos.
Importación de datos de Snowflake
Puedes usar Snowflake como fuente de datos en Data Wrangler para preparar SageMaker los datos de Snowflake para el aprendizaje automático.
Con Snowflake como origen de datos en Data Wrangler, puede conectarse rápidamente a Snowflake sin escribir una sola línea de código. Puede unir sus datos de Snowflake con datos de cualquier otro origen de datos en Data Wrangler.
Una vez conectado, puede consultar de forma interactiva los datos almacenados en Snowflake, transformarlos con más de 300 transformaciones de datos preconfiguradas, comprender los datos e identificar posibles errores y valores extremos con un conjunto de sólidas plantillas de visualización preconfiguradas, identificar rápidamente las incoherencias en el flujo de trabajo de preparación de datos y diagnosticar los problemas antes de implementar los modelos en producción. Por último, puede exportar su flujo de trabajo de preparación de datos a Amazon S3 para usarlo con otras SageMaker funciones, como Amazon SageMaker Autopilot, Amazon SageMaker Feature Store y Amazon SageMaker Model Building Pipelines.
Puede cifrar el resultado de sus consultas con una AWS Key Management Service clave que haya creado. Para obtener más información al respecto AWS KMS, consulte AWS Key Management Service.
Guía del administrador
importante
Para obtener más información sobre el control de acceso detallado y las prácticas recomendadas, consulte Security Access Control
Esta sección es para los administradores de Snowflake que están configurando el acceso a Snowflake desde Data Wrangler. SageMaker
importante
Usted es responsable de administrar y supervisar el control de acceso de Snowflake. Data Wrangler no agrega una capa de control de acceso con respecto a Snowflake.
El control de acceso incluye lo siguiente:
-
Los datos a los que accede un usuario
-
De forma opcional, la integración de almacenamiento que proporciona a Snowflake la capacidad de escribir los resultados de consultas en un bucket de Amazon S3
-
Las consultas que un usuario puede ejecutar
Configuración de permisos de importación de datos de Snowflake (opcional)
De forma predeterminada, Data Wrangler consulta los datos en Snowflake sin crear una copia de los mismos en una ubicación de Amazon S3. Utilice la siguiente información si va a configurar una integración de almacenamiento con Snowflake. Los usuarios pueden usar una integración de almacenamiento para almacenar los resultados de las consultas en una ubicación de Amazon S3.
Es posible que los usuarios tengan diferentes niveles de acceso a los datos confidenciales. Para lograr una seguridad de datos óptima, proporcione a cada usuario su propia integración de almacenamiento. Cada integración de almacenamiento debe tener su propia política de gobierno de datos.
Esta característica no está disponible actualmente en la región de suscripción voluntaria.
Snowflake necesita los siguientes permisos en un bucket y un directorio de S3 para poder acceder a los archivos del directorio:
-
s3:GetObject -
s3:GetObjectVersion -
s3:ListBucket -
s3:ListObjects -
s3:GetBucketLocation
Creación de una política de IAM
Tiene que crear una política de IAM para configurar los permisos de acceso para que Snowflake cargue y descargue datos de un bucket de Amazon S3.
A continuación, encontrará un documento de política de JSON que se utiliza para crear la política:
# Example policy for S3 write access # This needs to be updated { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:GetObjectVersion", "s3:DeleteObject", "s3:DeleteObjectVersion" ], "Resource": "arn:aws:s3:::bucket/prefix/*" }, { "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": "arn:aws:s3:::bucket/", "Condition": { "StringLike": { "s3:prefix": ["prefix/*"] } } } ] }
Para obtener información y procedimientos sobre la creación de políticas con documentos de políticas, consulte Crear políticas de IAM.
Para ver la documentación que proporciona una descripción general del uso de los permisos de IAM con Snowflake, consulte los siguientes recursos:
Para conceder al científico de datos el permiso de uso del rol de Snowflake para la integración del almacenamiento, debe ejecutar GRANT USAGE ON INTEGRATION
integration_name TO snowflake_role;.
-
integration_namees el nombre de la integración de almacenamiento. -
snowflake_rolees el nombre del rol de Snowflakepredeterminado que se asigna al científico de datos.
Configuración de acceso de OAuth de Snowflake
En lugar de hacer que los usuarios introduzcan directamente sus credenciales en Data Wrangler, puede hacer que usen un proveedor de identidades para acceder a Snowflake. Los siguientes son enlaces a la documentación de Snowflake para los proveedores de identidades compatibles con Data Wrangler.
Utilice la documentación de los enlaces anteriores para configurar el acceso a su proveedor de identidades. La información y los procedimientos de esta sección le ayudarán a entender cómo utilizar correctamente la documentación para acceder a Snowflake desde Data Wrangler.
El proveedor de identidades debe reconocer a Data Wrangler como una aplicación. Utilice el siguiente procedimiento para registrar Data Wrangler como una aplicación dentro del proveedor de identidades:
-
Seleccione la configuración que inicia el proceso de registro de Data Wrangler como aplicación.
-
Proporcione acceso a Data Wrangler a los usuarios del proveedor de identidades.
-
Active la autenticación del cliente de OAuth guardando las credenciales del cliente en secreto. AWS Secrets Manager
-
Especifica una URL de redireccionamiento con el siguiente formato: https://
Domain-ID.studio.Región de AWS.sagemaker.aws/jupyter/default/labimportante
Estás especificando el ID de SageMaker dominio de Amazon y el Región de AWS que estás utilizando para ejecutar Data Wrangler.
importante
Debes registrar una URL para cada SageMaker dominio de Amazon y para el Región de AWS lugar en el que ejecutes Data Wrangler. Los usuarios de un dominio Región de AWS que no tengan configuradas las URL de redireccionamiento no podrán autenticarse con el proveedor de identidad para acceder a la conexión de Snowflake.
-
Asegúrese de que los tipos de concesión de código de autorización y token de actualización estén permitidos para la aplicación Data Wrangler.
En el proveedor de identidades, tiene que configurar un servidor que envíe los tokens de OAuth a Data Wrangler a nivel de usuario. El servidor envía los tokens con Snowflake como público.
Snowflake utiliza el concepto de funciones que son funciones distintas a las que se utilizaban las funciones de IAM. AWS Debe configurar el proveedor de identidades para que utilice cualquier rol a fin de usar el rol predeterminado asociado a la cuenta de Snowflake. Por ejemplo, si un usuario tiene systems administrator como rol predeterminado en su perfil de Snowflake, la conexión de Data Wrangler a Snowflake utiliza systems administrator como rol.
Utilice el siguiente procedimiento para configurar el servidor.
Para configurar el servidor, haga lo siguiente: Trabajará en Snowflake en todos los pasos excepto en el último.
-
Comience a configurar el servidor o la API.
-
Configure el servidor de autorización para que utilice los tipos de concesión de código de autorización y token de actualización.
-
Especifique la duración del token de acceso.
-
Establezca el tiempo de espera de inactividad del token de actualización. El tiempo de espera de inactividad es el momento en que el token de actualización vence si no se utiliza.
nota
Si va a programar trabajos en Data Wrangler, se recomienda que el tiempo de espera de inactividad sea mayor que la frecuencia del trabajo de procesamiento. De lo contrario, algunos trabajos de procesamiento podrían producir un error porque el token de actualización vence antes de que pudieran ejecutarse. Cuando el token de actualización vence, el usuario debe volver a autenticarse accediendo a la conexión que ha establecido con Snowflake a través de Data Wrangler.
-
Especifique
session:role-anycomo nuevo ámbito.nota
En el caso de Azure AD, copie el identificador único del ámbito. Data Wrangler requiere que le proporcione el identificador.
-
importante
En la integración de seguridad de OAuth externa para Snowflake, habilite
external_oauth_any_role_mode.
importante
Data Wrangler no admite los tokens de actualización rotativos. El uso de tokens de actualización rotativos puede provocar errores de acceso o que los usuarios tengan que iniciar sesión con frecuencia.
importante
Si el token de actualización vence, los usuarios deben volver a autenticarse accediendo a la conexión que ha establecido con Snowflake a través de Data Wrangler.
Después de configurar el proveedor de OAuth, proporcione a Data Wrangler la información que necesita para conectarse con el proveedor. Puede usar la documentación de su proveedor de identidades para obtener los valores de los siguientes campos:
-
URL del token: la URL del token que el proveedor de identidades envía a Data Wrangler.
-
URL de autorización: la URL del servidor de autorización del proveedor de identidades.
-
ID de cliente: el ID del proveedor de identidades.
-
Secreto de cliente: el secreto que solo reconoce la API o el servidor de autorización.
-
Las credenciales del ámbito de OAuth que ha copiado (solo en Azure AD).
Los campos y valores se almacenan en AWS Secrets Manager secreto y se añaden a la configuración del ciclo de vida de Amazon SageMaker Studio Classic que se utiliza para Data Wrangler. Una configuración del ciclo de vida es un script de intérprete de comandos. Se utiliza para que Data Wrangler pueda acceder al nombre de recurso de Amazon (ARN) del secreto. Para obtener información sobre cómo crear secretos, consulte Mover secretos codificados a. AWS Secrets Manager Para obtener información sobre el uso de las configuraciones del ciclo de vida en Studio Classic, consulteUsa las configuraciones del ciclo de vida para personalizar Studio Classic.
importante
Antes de crear un secreto de Secrets Manager, asegúrese de que el rol de SageMaker ejecución que está utilizando para Amazon SageMaker Studio Classic tenga permisos para crear y actualizar secretos en Secrets Manager. Para obtener más información, consulte Ejemplo: permiso para crear secretos.
Para Okta y Ping Federate, el formato del secreto es el siguiente:
{ "token_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/token", "client_id":"example-client-id", "client_secret":"example-client-secret", "identity_provider":"OKTA"|"PING_FEDERATE", "authorization_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/authorize" }
Para Azure AD, el formato del secreto es el siguiente:
{ "token_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/token", "client_id":"example-client-id", "client_secret":"example-client-secret", "identity_provider":"AZURE_AD", "authorization_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/authorize", "datasource_oauth_scope":"api://appuri/session:role-any)" }
Debe tener una configuración de ciclo de vida que utilice el secreto de Secrets Manager que ha creado. Puede crear la configuración del ciclo de vida o modificar una que ya se haya creado. La configuración debe usar el siguiente script.
#!/bin/bash set -eux ## Script Body cat > ~/.snowflake_identity_provider_oauth_config <<EOL { "secret_arn": "example-secret-arn" } EOL
Para obtener información sobre la definición de las configuraciones de ciclo de vida, consulte Creación y asociación de una configuración del ciclo de vida. Cuando realice el proceso de configuración, haga lo siguiente:
-
Defina el tipo de aplicación de la configuración en
Jupyter Server. -
Adjunta la configuración al SageMaker dominio de Amazon que tiene tus usuarios.
-
Haga que la configuración se ejecute de forma predeterminada. Debe ejecutarse cada vez que un usuario inicie sesión en Studio Classic. De lo contrario, las credenciales guardadas en la configuración no estarán disponibles para sus usuarios cuando usen Data Wrangler.
-
La configuración del ciclo de vida crea un archivo con el nombre
snowflake_identity_provider_oauth_configen la carpeta principal del usuario. El archivo contiene el secreto de Secrets Manager. Asegúrese de que esté en la carpeta de inicio del usuario cada vez que se inicialice la instancia del servidor de Jupyter.
Conectividad privada entre Data Wrangler y Snowflake a través de AWS PrivateLink
En esta sección se explica cómo establecer una conexión privada entre Data Wrangler y Snowflake. AWS PrivateLink Los pasos se explican en las siguientes secciones.
Creación de una VPC
Si no tiene una VPC configurada, siga las instrucciones de Create a new VPC para crear una.
Una vez que haya elegido la VPC que desee utilizar para establecer una conexión privada, proporcione las siguientes credenciales al administrador de Snowflake para que habilite AWS PrivateLink:
-
ID de VPC
-
AWS ID de cuenta
-
La URL de la cuenta correspondiente que utiliza para acceder a Snowflake
importante
Como se describe en la documentación de Snowflake, la activación de la cuenta de Snowflake puede tardar hasta dos días laborables.
Configuración de la integración de AWS PrivateLink con Snowflake
Una vez AWS PrivateLink activado, recupere la AWS PrivateLink configuración de su región ejecutando el siguiente comando en una hoja de trabajo de Snowflake. Inicie sesión en la consola de Snowflake e introduzca lo siguiente en las Hojas de trabajo: select
SYSTEM$GET_PRIVATELINK_CONFIG();.
-
Recupere los valores de lo siguiente:
privatelink-account-name,privatelink_ocsp-url,privatelink-account-urlyprivatelink_ocsp-urldel objeto JSON resultante. En el siguiente fragmento de código se muestran ejemplos de cada valor. Guarde estos valores para usarlos más adelante.privatelink-account-name: xxxxxxxx.region.privatelink privatelink-vpce-id: com.amazonaws.vpce.region.vpce-svc-xxxxxxxxxxxxxxxxx privatelink-account-url: xxxxxxxx.region.privatelink.snowflakecomputing.com privatelink_ocsp-url: ocsp.xxxxxxxx.region.privatelink.snowflakecomputing.com -
Cambie a su AWS consola y navegue hasta el menú de la VPC.
-
En el panel lateral izquierdo, elija el enlace Puntos de conexión para ir a la configuración de Puntos de conexión de VPC.
Una vez allí, elija Crear punto de conexión.
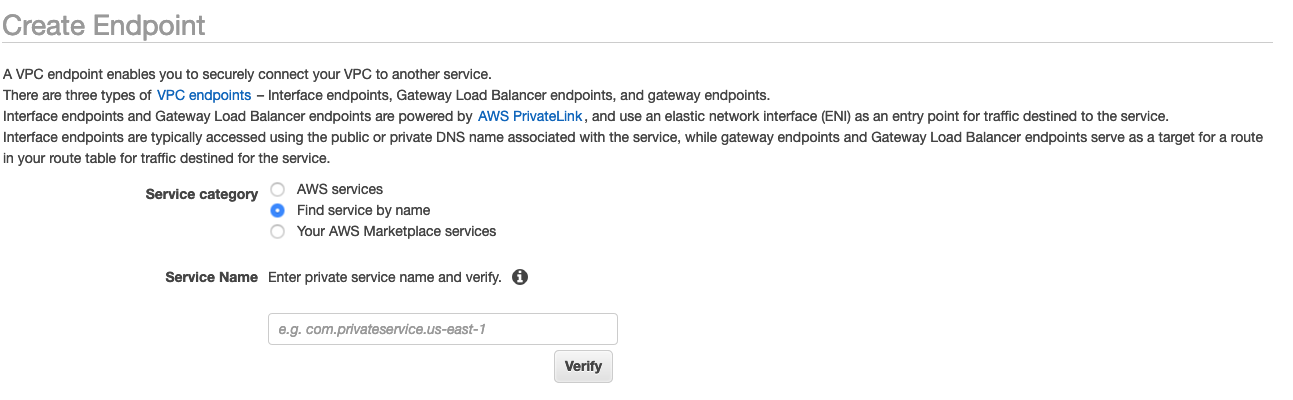
-
Seleccione el botón de opción para Buscar servicio por nombre, como se muestra en la siguiente captura de pantalla.
-
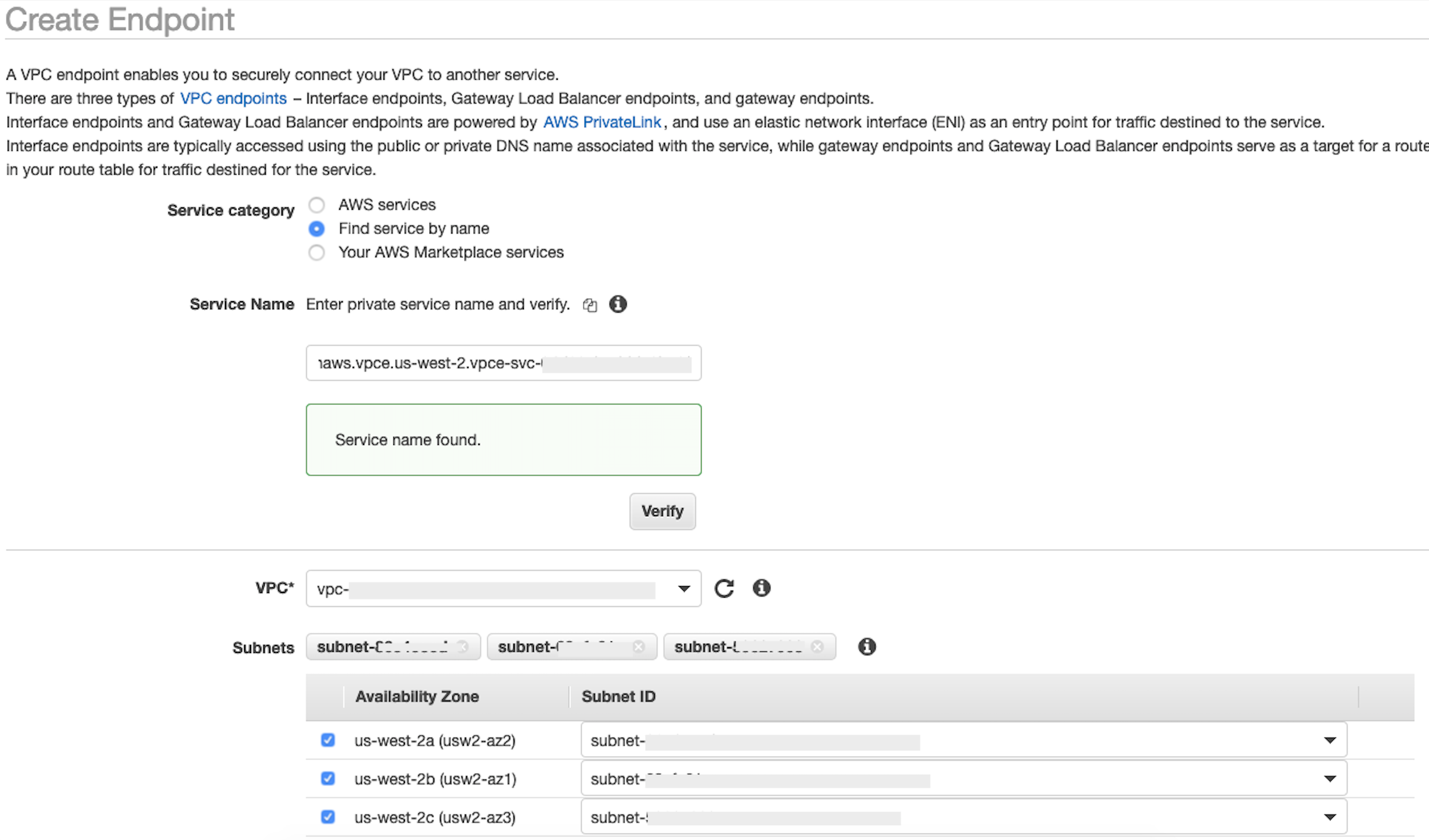
En el campo Nombre del servicio, pegue el valor de
privatelink-vpce-idque recuperó en el paso anterior y elija Verificar.Si la conexión se realiza correctamente, aparece en la pantalla una alerta verde que indica Nombre del servicio encontrado y las opciones VPC y Subred se expanden automáticamente, como se muestra en la siguiente captura de pantalla. En función de la región de destino, es posible que la pantalla resultante muestre el nombre de otra región de AWS .
-
Seleccione el mismo ID de VPC que envió a Snowflake en la lista desplegable VPC.
-
Si aún no ha creado una subred, siga el siguiente conjunto de instrucciones para crear una subred.
-
Seleccione Subredes en la lista desplegable VPC. A continuación, seleccione Crear subred y siga las instrucciones para crear un subconjunto en la VPC. Asegúrese de seleccionar el ID de VPC que envió a Snowflake.
-
En Configuración del grupo de seguridad, seleccione Crear un nuevo grupo de seguridad para abrir la pantalla del Grupo de seguridad predeterminado en una pestaña nueva. En esta nueva pestaña, seleccione Crear grupo de seguridad.
-
Escriba un nombre y una descripción para el nuevo grupo de seguridad (como
datawrangler-doc-snowflake-privatelink-connection). Asegúrese de seleccionar el ID de VPC que utilizó en los pasos anteriores. -
Agregue dos reglas para permitir el tráfico desde su VPC a este punto de conexión de VPC.
Vaya a su VPC en Sus VPC en una pestaña independiente y recupere el bloque CIDR para su VPC. Elija Agregar regla en la sección Reglas de entrada. Seleccione
HTTPSpara el tipo, deje el Origen como Personalizado en el formulario y pegue el valor recuperado de la llamadadescribe-vpcsanterior (como10.0.0.0/16). -
Elija Crear grupo de seguridad. Recupere el ID del grupo de seguridad del grupo de seguridad recién creado (como
sg-xxxxxxxxxxxxxxxxx). -
En la pantalla de configuración de Punto de conexión de VPC, elimine el grupo de seguridad predeterminado. Pegue el ID del grupo de seguridad en el campo de búsqueda y seleccione la casilla de verificación.
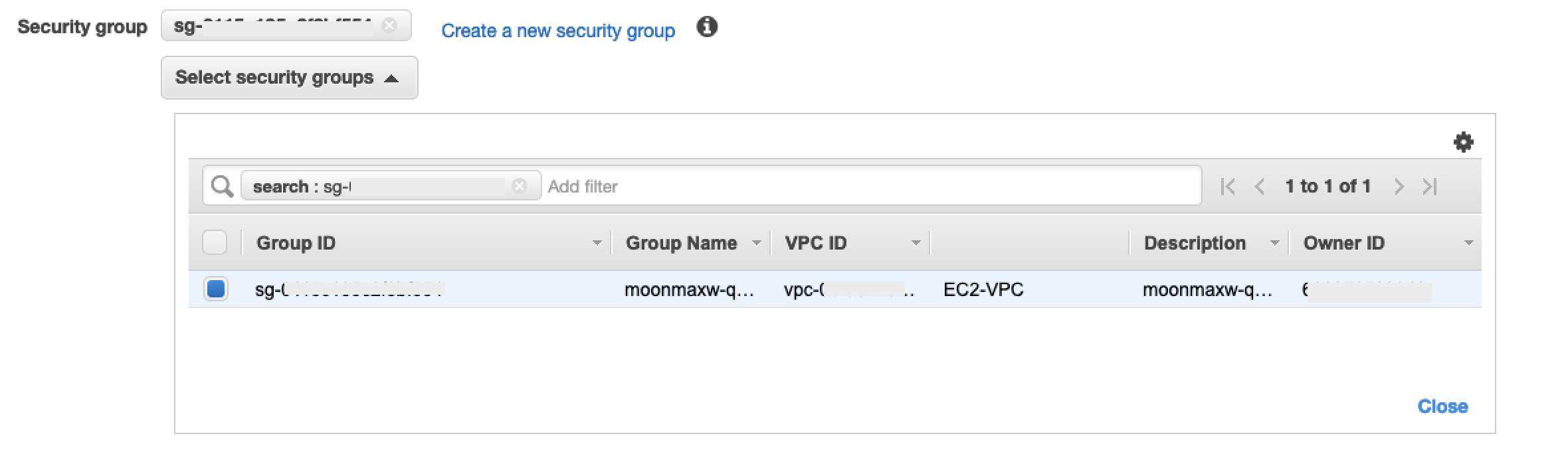
-
Seleccione Crear punto de conexión.
-
Si la creación del punto de conexión se realiza correctamente, verá una página con un enlace a la configuración del punto de conexión de VPC, especificado mediante el ID de la VPC. Seleccione el enlace para ver la configuración completa.
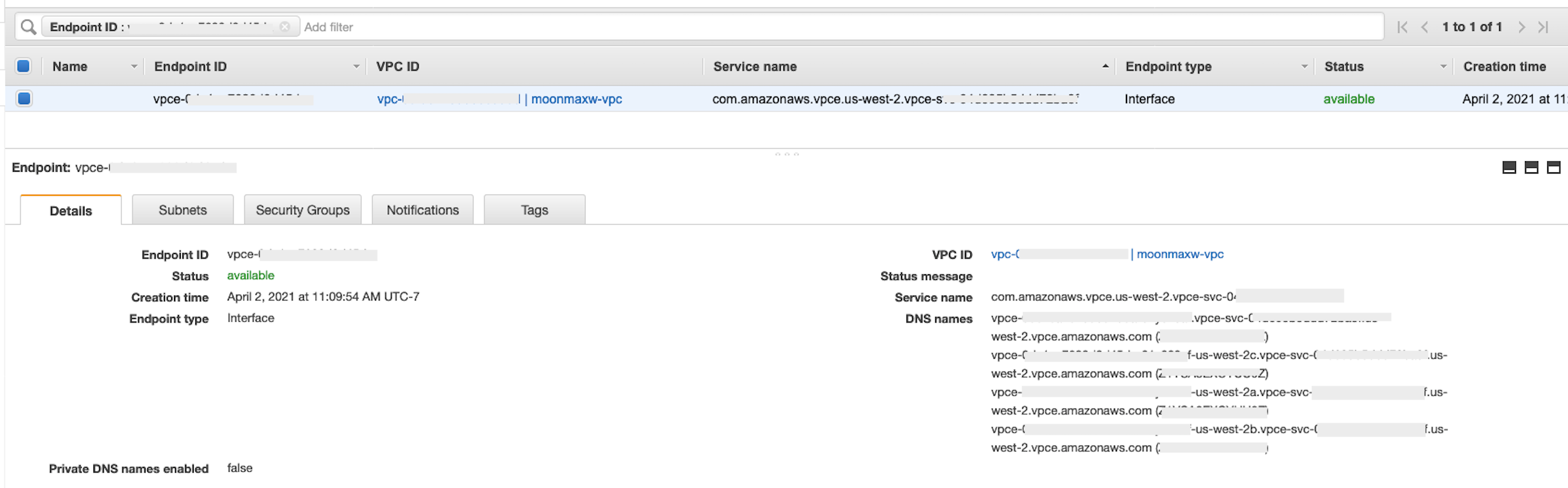
Tome el registro que encabeza la lista de nombres DNS. Se puede diferenciar de otros nombres de DNS porque solo incluye el nombre de la región (como
us-west-2) y no incluye ninguna notación con las letras de la zona de disponibilidad (comous-west-2a). Guarde esta información para utilizarla más adelante.
Configuración del DNS para los puntos de conexión de Snowflake en su VPC
En esta sección se explica cómo configurar el DNS para los puntos de conexión de Snowflake en su VPC. Esto permite que su VPC resuelva las solicitudes al punto de conexión AWS PrivateLink de Snowflake.
-
Navegue hasta el menú Route 53
de AWS la consola. -
Seleccione la opción Zonas alojadas (si es necesario, expanda el menú de la izquierda para encontrar esta opción).
-
Elija Create Hosted Zone (Crear zona alojada).
-
En el campo Nombre de dominio, haga referencia al valor que se almacenó para
privatelink-account-urlen los pasos anteriores. En este campo, el ID de su cuenta de Snowflake se elimina del nombre de DNS y solo usa el valor que comienza por el identificador de región. Más adelante, también se crea un Conjunto de registros de recursos para el subdominio, por ejemplo,region.privatelink.snowflakecomputing.com. -
Seleccione el botón de opción correspondiente a la Zona alojada privada en la sección Tipo. Es posible que el código de región no sea
us-west-2. Haga referencia al nombre de DNS que le devolvió Snowflake.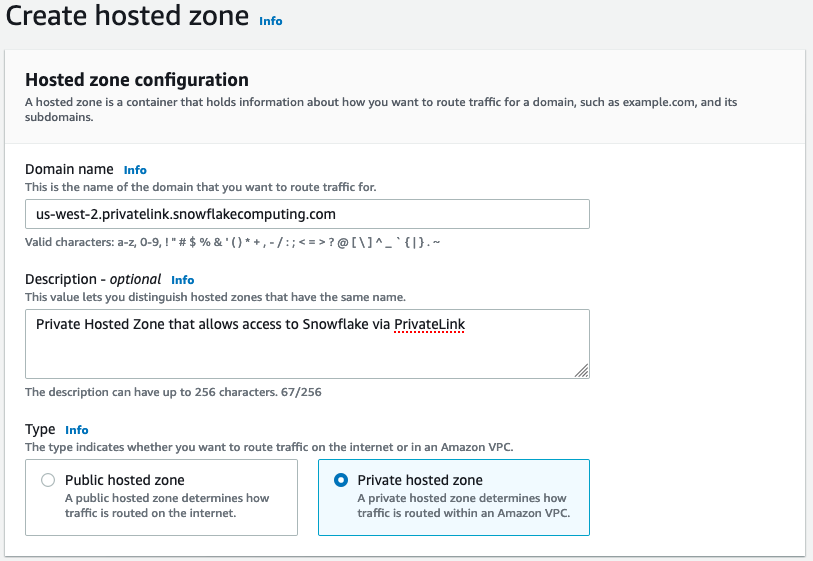
-
En la sección VPC para asociar con la zona alojada, seleccione la región en la que se encuentra la VPC y el ID de VPC utilizado en los pasos anteriores.
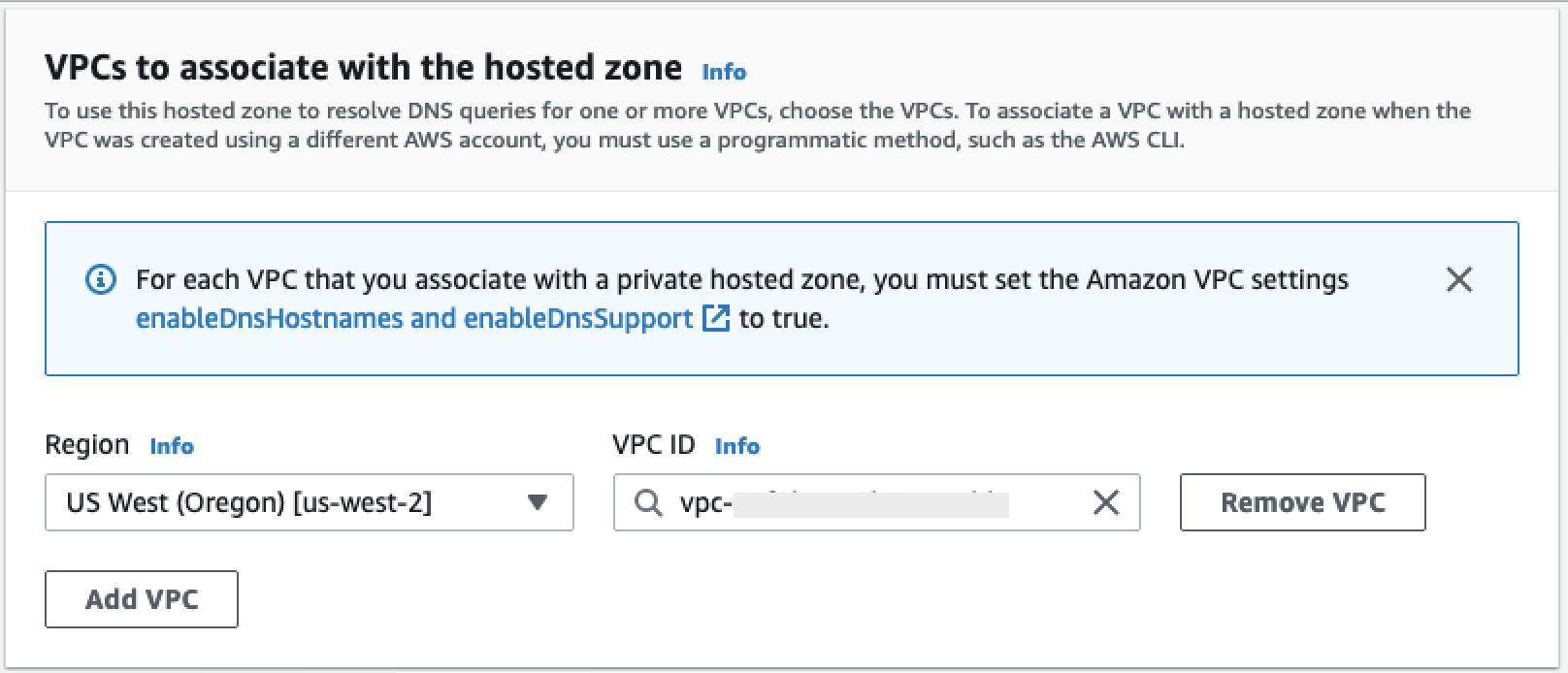
-
Elija Crear zona alojada.
-
-
A continuación, cree dos registros, uno para
privatelink-account-urly otro paraprivatelink_ocsp-url.-
En el menú Zona alojada, elija Crear un conjunto de registros.
-
En Nombre del registro, ingrese únicamente su ID de cuenta de Snowflake (los primeros 8 caracteres en
privatelink-account-url). -
En Tipo de registro, seleccione CNAME.
-
En Valor, ingrese el nombre de DNS del punto de conexión de VPC regional que ha recuperado en el último paso de la sección Configuración de la integración de AWS PrivateLink con Snowflake.

-
Elija Crear registros.
-
Repita los pasos anteriores para el registro OCSP del que tomó nota como
privatelink-ocsp-url, comenzando conocsphasta el ID de Snowflake de 8 caracteres para el nombre del registro (comoocsp.xxxxxxxx).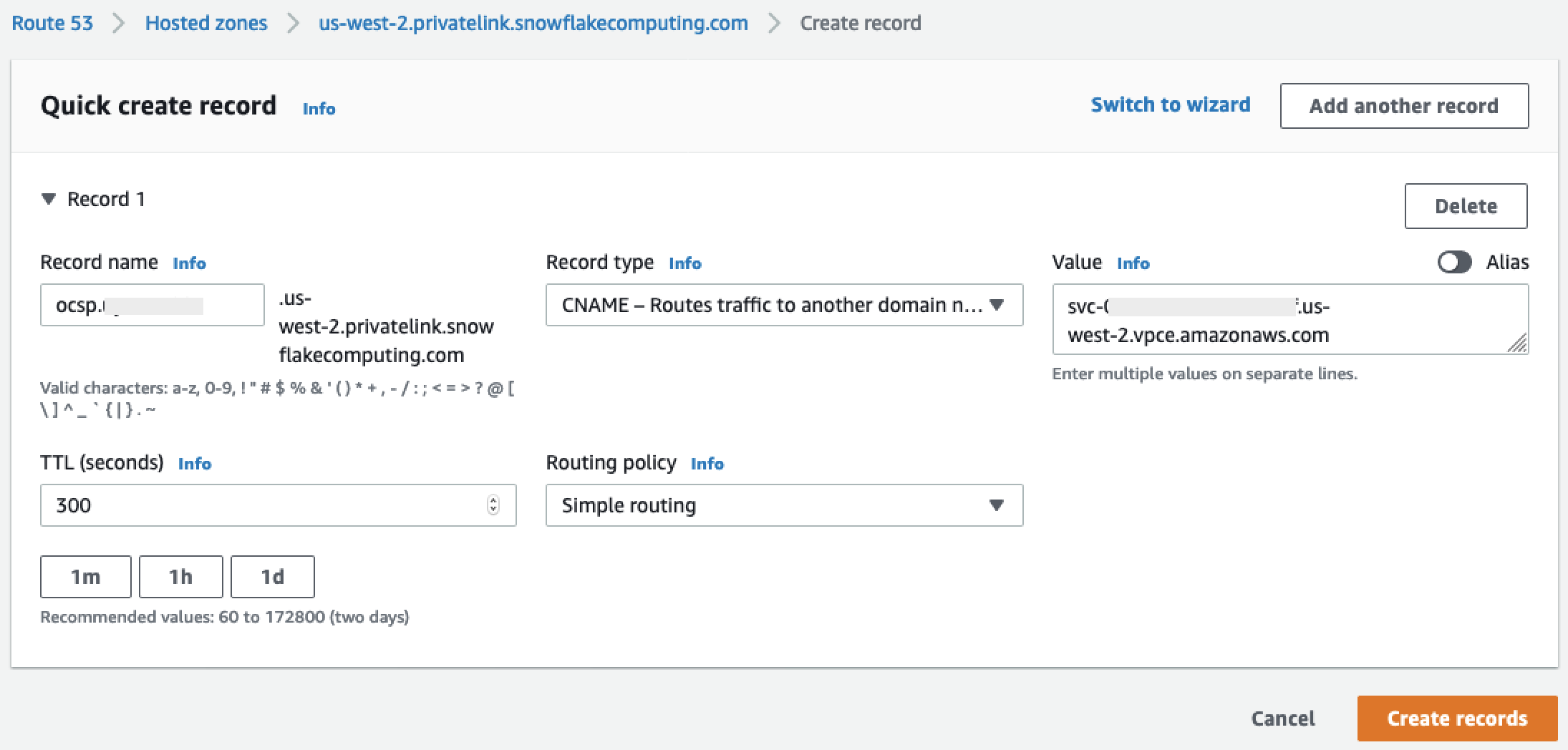
-
-
Configuración del punto de conexión entrante del solucionador de Route 53 para su VPC
En esta sección se explica cómo configurar el DNS para los puntos de conexión de los solucionadores de Route 53 en su VPC.
-
Navegue hasta el menú Route 53
de AWS la consola. -
En el panel izquierdo de la sección Seguridad, seleccione la opción Grupos de seguridad.
-
-
Elija Crear grupo de seguridad.
-
Escriba un nombre y una descripción para el grupo de seguridad (como
datawranger-doc-route53-resolver-sg). -
Seleccione el ID de VPC que utilizó en los pasos anteriores.
-
Cree reglas que permitan el DNS a través de UDP y TCP desde el bloque CIDR de la VPC.

-
Elija Crear grupo de seguridad. Tome nota del ID del grupo de seguridad porque agrega una regla para permitir el tráfico al grupo de seguridad del punto de conexión de VPC.
-
-
Navegue hasta el menú Route 53
de AWS la consola. -
En la sección Solucionador, seleccione la opción Punto de conexión de entrada.
-
-
Elija Crear un punto de conexión de entrada.
-
Proporcione un nombre para el punto de conexión.
-
En la lista desplegable VPC de la región, seleccione el ID de VPC que utilizó en todos los pasos anteriores.
-
En la lista desplegable Grupo de seguridad para este punto de conexión, seleccione el ID del grupo de seguridad del paso 2 de esta sección.
-
En la sección Dirección IP, seleccione una zona de disponibilidad, seleccione una subred y deje el selector de opción de Usar una dirección IP seleccionada automáticamente para cada dirección IP.

-
Seleccione Submit (Enviar).
-
-
Seleccione el Punto de conexión de entrada después de haberlo creado.
-
Una vez creado el punto de conexión de entrada, tome nota de las dos direcciones IP de los solucionadores.

SageMaker Puntos finales de VPC
En esta sección se explica cómo crear puntos de enlace de VPC para lo siguiente: Amazon SageMaker Studio Classic, SageMaker Notebooks, la SageMaker API, SageMaker Runtime Runtime y Amazon SageMaker Feature Store Runtime.
Creación de un grupo de seguridad que se aplique a todos los puntos de conexión
-
Navegue hasta el menú EC2 de
la consola. AWS -
En la sección Red y seguridad, seleccione la opción Grupos de seguridad.
-
Elija Crear grupo de seguridad.
-
Proporcione un nombre y una descripción para el grupo de seguridad (como
datawrangler-doc-sagemaker-vpce-sg). Más adelante se agrega una regla para permitir el tráfico SageMaker a través de HTTPS desde este grupo.
Creación de los puntos de conexión
-
Navegue hasta el menú de VPC
en la AWS consola. -
Seleccione la opción Puntos de conexión.
-
Seleccione Crear punto de conexión.
-
Para buscar el servicio, introduzca el nombre en el campo Buscar.
-
En la lista desplegable de VPC, seleccione la VPC en la que existe la conexión de Snowflake. AWS PrivateLink
-
En la sección Subredes, selecciona las subredes que tienen acceso a la conexión de Snowflake. PrivateLink
-
En Habilitar nombre de DNS, deje la casilla seleccionada.
-
En la sección Grupos de seguridad, seleccione el grupo de seguridad que creó en la sección anterior.
-
Seleccione Crear punto de conexión.
Configure Studio Classic y Data Wrangler
En esta sección se explica cómo configurar Studio Classic y Data Wrangler.
-
Configure el grupo de seguridad.
-
Navegue hasta el menú Amazon EC2 de la AWS consola.
-
Seleccione la opción Grupos de seguridad en la sección Red y seguridad.
-
Elija Crear grupo de seguridad.
-
Proporcione un nombre y una descripción para el grupo de seguridad (como
datawrangler-doc-sagemaker-studio). -
Cree las siguientes reglas de entrada.
-
La conexión HTTPS al grupo de seguridad que aprovisionó para la PrivateLink conexión con Snowflake que creó en el paso de configuración de la integración con Snowflake. PrivateLink
-
La conexión HTTP al grupo de seguridad que aprovisionó para la conexión de Snowflake que creó en el paso de configuración de la PrivateLink integración de Snowflake. PrivateLink
-
El grupo de seguridad UDP y TCP para DNS (puerto 53) al punto de conexión del solucionador de Route 53 que creó en el paso 2 de la Configuración del punto de conexión entrante del solucionador de Route 53 para su VPC.
-
-
Elija el botón Crear grupo de seguridad en la esquina inferior derecha.
-
-
Configure Studio Classic.
-
Navegue hasta el SageMaker menú de la AWS consola.
-
En la consola de la izquierda, selecciona la opción SageMakerStudio Classic.
-
Si no tiene ningún dominio configurado, aparecerá el menú Introducción.
-
Seleccione la opción Configuración estándar en el menú Introducción.
-
En Método de autenticación, elija AWS Identity and Access Management (IAM).
-
En el menú Permisos, puede crear un rol nuevo o usar un rol que ya exista, según su caso de uso.
-
Si elige Crear un nuevo rol, tendrá la opción de proporcionar un nombre de bucket de S3 y se generará una política en su nombre.
-
Si ya ha creado un rol con permisos para los buckets de S3 a los que necesita acceso, seleccione el rol en la lista desplegable. Este rol debe tener asociada la política de
AmazonSageMakerFullAccess.
-
-
Seleccione la lista desplegable Red y almacenamiento para configurar los usos de la VPC, la seguridad y SageMaker las subredes.
-
En VPC, seleccione la VPC en la que existe la conexión de Snowflake. PrivateLink
-
En Subredes, seleccione las subredes que tienen acceso a la conexión de Snowflake. PrivateLink
-
En Acceso a la red para Studio Classic, selecciona Solo VPC.
-
En Grupos de seguridad, seleccione el grupo de seguridad que creó en el paso 1.
-
-
Seleccione Submit (Enviar).
-
-
Edite el grupo SageMaker de seguridad.
-
Cree las siguientes reglas de entrada:
-
Puerto 2049 para los grupos de seguridad NFS entrantes y salientes creados automáticamente SageMaker en el paso 2 (los nombres de los grupos de seguridad contienen el ID de dominio de Studio Classic).
-
Acceso a todos los puertos TCP consigo mismo (necesario solo SageMaker para la VPC).
-
-
-
Edite los grupos de seguridad de puntos de conexión de VPC:
-
Navegue hasta el menú Amazon EC2 de la AWS consola.
-
Busque el grupo de seguridad que ha creado en un paso anterior.
-
Agregue una regla de entrada que permita el tráfico HTTPS desde el grupo de seguridad creado en el paso 1.
-
-
Cree un perfil de usuario.
-
En el panel de control de SageMaker Studio Classic, seleccione Añadir usuario.
-
Proporcione un nombre de usuario.
-
En Rol de ejecución, elija crear un nuevo rol o utilizar uno que ya exista.
-
Si elige Crear un nuevo rol, tendrá la opción de proporcionar un nombre de bucket de Amazon S3 y se generará una política en su nombre.
-
Si ya ha creado un rol con permisos para los buckets de Amazon S3 a los que necesita acceso, seleccione el rol en la lista desplegable. Este rol debe tener asociada la política de
AmazonSageMakerFullAccess.
-
-
Seleccione Submit (Enviar).
-
-
Cree un flujo de datos (siga la guía para científicos de datos descrita en la sección anterior).
-
Al añadir una conexión con Snowflake, introduzca el valor de
privatelink-account-name(del paso de configuración de la PrivateLink integración con Snowflake) en el campo del nombre de la cuenta de Snowflake (alfanumérico), en lugar del nombre simple de la cuenta de Snowflake. Todo lo demás permanece inalterado.
-
Proporcionar información al científico de datos
Proporcione al científico de datos la información que necesita para acceder a Snowflake desde Amazon SageMaker Data Wrangler.
importante
Sus usuarios deben ejecutar Amazon SageMaker Studio Classic, versión 1.3.0 o posterior. Para obtener información sobre cómo comprobar la versión de Studio Classic y actualizarla, consultePrepare datos de aprendizaje automático con Amazon SageMaker Data Wrangler.
-
Para que su científico de datos pueda acceder a Snowflake desde SageMaker Data Wrangler, bríndele una de las siguientes opciones:
-
Para la autenticación básica, un nombre de cuenta, un nombre de usuario y una contraseña de Snowflake.
-
Para OAuth, un nombre de usuario y una contraseña en el proveedor de identidades.
-
Para ARN, el nombre de recurso de Amazon (ARN) del secreto de Secrets Manager.
-
Un secreto creado con AWS Secrets Manager y el ARN del secreto. Utilice el siguiente procedimiento para crear el secreto de Snowflake si elige esta opción.
importante
Si los científicos de datos utilizan la opción Credenciales de Snowflake (nombre de usuario y contraseña) para conectarse a Snowflake, puede usar Secrets Manager para almacenar las credenciales en un secreto. Secrets Manager rota los secretos como parte de un plan de seguridad de prácticas recomendadas. Solo se puede acceder al secreto creado en Secrets Manager con el rol de Studio Classic configurado al configurar un perfil de usuario de Studio Classic. Esto requiere que añada este permiso,
secretsmanager:PutResourcePolicy, a la política asociada a su rol de Studio Classic.Le recomendamos encarecidamente que modifique la política de roles para usar diferentes roles para diferentes grupos de usuarios de Studio Classic. Puede agregar permisos adicionales basados en recursos para los secretos de Secrets Manager. Consulte Manage Secret Policy para ver las claves de condición que puede usar.
Para obtener información acerca de cómo crear un secreto, consulte Creación de un secreto. Se le cobrará por los secretos que cree.
-
-
De forma opcional, puede proporcionar al científico de datos el nombre de la integración de almacenamiento que creó mediante el siguiente procedimiento: Create a Cloud Storage Integration in Snowflake
. Este es el nombre de la nueva integración y se llama integration_nameen el comando SQLCREATE INTEGRATIONque ejecutó, que se muestra en el siguiente fragmento:CREATE STORAGE INTEGRATION integration_name TYPE = EXTERNAL_STAGE STORAGE_PROVIDER = S3 ENABLED = TRUE STORAGE_AWS_ROLE_ARN = 'iam_role' [ STORAGE_AWS_OBJECT_ACL = 'bucket-owner-full-control' ] STORAGE_ALLOWED_LOCATIONS = ('s3://bucket/path/', 's3://bucket/path/') [ STORAGE_BLOCKED_LOCATIONS = ('s3://bucket/path/', 's3://bucket/path/') ]
Guía para científicos de datos
Utilice lo siguiente para conectarse a Snowflake y acceder a sus datos en Data Wrangler.
importante
Su administrador tiene que usar la información de las secciones anteriores para configurar Snowflake. Si tiene problemas, póngase en contacto con ellos para obtener ayuda con la solución de problemas.
Puede conectarse a Snowflake de una de las siguientes formas:
-
Especifique sus credenciales de Snowflake (nombre de cuenta, nombre de usuario y contraseña) en Data Wrangler.
-
Proporcione un nombre de recurso de Amazon (ARN) de un secreto que contenga las credenciales.
-
Utilice un proveedor de estándar abierto (OAuth) para la delegación de acceso que se conecte a Snowflake. El administrador puede darle acceso a uno de los siguientes proveedores de OAuth:
Hable con su administrador sobre el método que debe utilizar para conectarse a Snowflake.
En las siguientes secciones se proporciona información acerca de la conexión a Snowflake mediante los métodos anteriores.
Puede iniciar el proceso de importación de los datos desde Snowflake una vez que se haya conectado.
En Data Wrangler, puede ver sus almacenamientos de datos, bases de datos y esquemas, junto con el icono en forma de ojo con el que puede obtener una vista previa de la tabla. Tras seleccionar el icono de Vista previa de la tabla, se genera la vista previa del esquema de esa tabla. Tiene que seleccionar un almacén para poder previsualizar una tabla.
importante
Si va a importar un conjunto de datos con columnas del tipo TIMESTAMP_TZ o TIMESTAMP_LTZ, agregue ::string a los nombres de las columnas de su consulta. Para obtener más información, consulte How To: Unload TIMESTAMP_TZ and TIMESTAMP_LTZ data to a Parquet file
Tras seleccionar un almacenamiento de datos, una base de datos y un esquema, ya puede escribir consultas y ejecutarlas. El resultado de la consulta se muestra en Resultados de la consulta.
Una vez que haya establecido el resultado de la consulta, puede importarlo a un flujo de Data Wrangler para realizar transformaciones de datos.
Después de importar los datos, vaya al flujo de Data Wrangler y comience a agregar transformaciones. Para ver la lista de transformaciones disponibles, consulte Datos de transformación.
Importación de datos de plataformas de software como servicio (SaaS)
Puede utilizar Data Wrangler para importar datos de más de cuarenta plataformas de software como servicio (SaaS). Para importar los datos de su plataforma SaaS, usted o su administrador deben utilizar Amazon AppFlow para transferir los datos de la plataforma a Amazon S3 o Amazon Redshift. Para obtener más información sobre Amazon AppFlow, consulta ¿Qué es Amazon AppFlow? Si no necesita usar Amazon Redshift, se recomienda transferir los datos a Amazon S3 para simplificar el proceso.
Data Wrangler admite la transferencia de datos desde las siguientes plataformas SaaS:
La lista anterior contiene enlaces a más información sobre la configuración del origen de datos. Usted o su administrador pueden consultar los enlaces anteriores después de leer la siguiente información.
Cuando vaya a la pestaña Importación de su flujo de Data Wrangler, verá los orígenes de datos en las siguientes secciones:
-
Disponible
-
Configurar orígenes de datos
Puede conectarse a los orígenes de datos en Disponible sin necesidad de una configuración adicional. Puede elegir el origen de datos e importar los datos.
Fuentes de datos en Configurar fuentes de datos, requiere que usted o su administrador utilicen Amazon AppFlow para transferir los datos de la plataforma SaaS a Amazon S3 o Amazon Redshift. Para obtener información sobre cómo realizar una transferencia, consulte Cómo usar Amazon AppFlow para transferir tus datos.
Tras realizar la transferencia de datos, la plataforma SaaS aparece como origen de datos en Disponible. Puede elegirla e importar los datos que ha transferido a Data Wrangler. Los datos que ha transferido aparecen en forma de tablas que puede consultar.
Cómo usar Amazon AppFlow para transferir tus datos
Amazon AppFlow es una plataforma que puede utilizar para transferir datos desde su plataforma SaaS a Amazon S3 o Amazon Redshift sin tener que escribir ningún código. Para realizar una transferencia de datos, utilice la AWS Management Console.
importante
Tiene que asegurarse de haber configurado los permisos para realizar una transferencia de datos. Para obtener más información, consulte AppFlow Permisos de Amazon.
Una vez que haya agregado los permisos, podrá transferir los datos. En Amazon AppFlow, se crea un flujo para transferir los datos. Un flujo es una serie de configuraciones. Sirve para especificar si va a ejecutar la transferencia de datos de forma programada o si va a particionar los datos en archivos independientes. Una vez configurado el flujo, lo ejecuta para transferir los datos.
Para obtener información sobre cómo crear un flujo, consulta Crear flujos en Amazon AppFlow. Para obtener información sobre cómo ejecutar un flujo, consulta Activar un AppFlow flujo de Amazon.
Una vez transferidos los datos, utilice el siguiente procedimiento para acceder a los datos en Data Wrangler.
importante
Antes de intentar acceder a los datos, asegúrese de que su rol de IAM tenga la siguiente política:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "glue:SearchTables", "Resource": [ "arn:aws:glue:*:*:table/*/*", "arn:aws:glue:*:*:database/*", "arn:aws:glue:*:*:catalog" ] } ] }
De forma predeterminada, el rol de IAM que utiliza para acceder a Data Wrangler es SageMakerExecutionRole. Para obtener más información acerca de la adición de políticas, consulte Adición de permisos de identidad de IAM (consola).
Para conectarse a un origen de datos, haga lo siguiente.
-
Inicia sesión en Amazon SageMaker Console
. -
Elija Studio.
-
Elija Lanzar aplicación.
-
En la lista desplegable, seleccione Studio.
-
Elija el icono Inicio.
-
Elija Datos.
-
Elija Data Wrangler.
-
Elija Importar datos.
-
En Disponible, elija el origen de datos.
-
En el campo Nombre, especifique el nombre de la conexión.
-
De forma opcional, elija Configuración avanzada.
-
Elija un Grupo de trabajo.
-
Si su grupo de trabajo no ha impuesto la ubicación de salida de Amazon S3 o si no utiliza un grupo de trabajo, especifique un valor para la Ubicación de Amazon S3 de los resultados de la consulta.
-
De forma opcional, para Período de retención de datos, seleccione la casilla de verificación para establecer un período de retención de datos y especifique el número de días que se almacenarán los datos antes de que se eliminen.
-
(Opcional) De forma predeterminada, Data Wrangler guarda la conexión. Puede optar por quitar la marca de selección de la casilla de verificación y no guardar la conexión.
-
-
Elija Conectar.
-
Especifique una consulta.
nota
Para ayudarle a especificar una consulta, puede elegir una tabla en el panel de navegación de la izquierda. Data Wrangler muestra el nombre de la tabla y una vista previa de la misma. Elija el icono situado junto al nombre de la tabla para copiarlo. Puede utilizar el nombre de la tabla en la consulta.
-
Elija Ejecutar.
-
Elija Importar consulta.
-
En Nombre del conjunto de datos, especifique el nombre del conjunto de datos.
-
Elija Añadir.
Cuando acceda a la pantalla importar datos, verá la conexión que ha creado. Puede usar la conexión para importar más datos.
Almacenamiento de datos importados
importante
Se recomienda encarecidamente seguir las prácticas recomendadas para proteger el bucket de Amazon S3 según las Prácticas recomendadas de seguridad.
Cuando consulta datos de Amazon Athena o Amazon Redshift, el conjunto de datos consultado se almacena automáticamente en Amazon S3. Los datos se almacenan en el depósito de SageMaker S3 predeterminado de la AWS región en la que se utiliza Studio Classic.
Los buckets de S3 predeterminados tienen la siguiente convención de nomenclatura: sagemaker-. Por ejemplo, si su número de cuenta es 111122223333 y utiliza Studio Classic enregion-account
numberus-east-1, los conjuntos de datos importados se almacenan en 111122223333. sagemaker-us-east-1-
Los flujos de Data Wrangler dependen de la ubicación de este conjunto de datos de Amazon S3, por lo que no debe modificar este conjunto de datos en Amazon S3 mientras utilice un flujo dependiente. Si modifica esta ubicación de S3 y desea seguir utilizando su flujo de datos, debe eliminar todos los objetos en trained_parameters en su archivo .flow. Para ello, descargue el archivo.flow de Studio Classic y, para cada instancia, elimine todas las entradas. trained_parameters Cuando termine, trained_parameters debería ser un objeto JSON vacío:
"trained_parameters": {}
Cuando exporta y utiliza su flujo de datos para procesar sus datos, el archivo .flow que exporta hace referencia a este conjunto de datos en Amazon S3. Consulte las siguientes secciones para obtener más información.
Almacenamiento de importación en Amazon Redshift
Data Wrangler almacena los conjuntos de datos que resultan de su consulta en un archivo Parquet en su bucket de S3 predeterminado. SageMaker
Este archivo se almacena con el siguiente prefijo (directorio): redshift/uuid/data/, donde uuid es un identificador único que se crea para cada consulta.
Por ejemplo, si su bucket predeterminado essagemaker-us-east-1-111122223333, un único conjunto de datos consultado desde Amazon Redshift se encuentra en s3:sagemaker-us-east//-1-111122223333/redshift/ uuid /data/.
Almacenamiento de importación de Amazon Athena
Cuando consulta una base de datos de Athena e importa un conjunto de datos, Data Wrangler almacena el conjunto de datos, así como un subconjunto de ese conjunto de datos, o archivos vista previa, en Amazon S3.
El conjunto de datos que importe al seleccionar Importar conjunto de datos se almacena en formato Parquet en Amazon S3.
Los archivos de vista previa se escriben en formato CSV al seleccionar Ejecutar en la pantalla de importación de Athena y contienen hasta 100 filas del conjunto de datos consultado.
El conjunto de datos que consulta se encuentra en el prefijo (directorio): athena/uuid/data/, donde uuid es un identificador único que se crea para cada consulta.
Por ejemplo, si el bucket predeterminado es sagemaker-us-east-1-111122223333, un único conjunto de datos consultado desde Athena se encuentra s3://sagemaker-us-east-1-111122223333 en /athena/uuid/data/ejemplo_conjunto_datos.parquet.
El subconjunto del conjunto de datos que se almacena para previsualizar los marcos de datos en Data Wrangler se almacena con el prefijo: athena/.
