Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Données personnelles OU — Compte d'application PDF
Nous aimerions avoir de vos nouvelles. Veuillez nous faire part de vos commentaires sur le AWS PRA en répondant à un court sondage |
Le compte d'application de données personnelles (DP) est l'endroit où votre organisation héberge les services qui collectent et traitent les données personnelles. Plus précisément, vous pouvez stocker ce que vous définissez comme des données personnelles dans ce compte. Le AWS PRA présente un certain nombre d'exemples de configurations de confidentialité via une architecture Web sans serveur à plusieurs niveaux. Lorsqu'il s'agit d'exploiter des charges de travail dans une zone d' AWS atterrissage, les configurations de confidentialité ne doivent pas être considérées comme one-size-fits-all des solutions. Par exemple, votre objectif peut être de comprendre les concepts sous-jacents, comment ils peuvent améliorer la confidentialité et comment votre organisation peut appliquer des solutions à vos cas d'utilisation et à vos architectures particuliers.
Comptes AWS En effet, au sein de votre organisation qui collecte, stocke ou traite des données personnelles, vous pouvez utiliser AWS Organizations et AWS Control Tower déployer des garde-fous fondamentaux et reproductibles. La mise en place d'une unité organisationnelle (UO) dédiée à ces comptes est essentielle. Par exemple, vous souhaiterez peut-être appliquer des mesures de protection relatives à la résidence des données uniquement à un sous-ensemble de comptes où la résidence des données est une considération de conception essentielle. Pour de nombreuses entreprises, il s'agit des comptes qui stockent et traitent les données personnelles.
Votre organisation peut proposer un compte de données dédié, dans lequel vous stockez la source officielle de vos ensembles de données personnels. Une source de données faisant autorité est un emplacement où vous stockez la version principale des données, qui peut être considérée comme la version la plus fiable et la plus précise des données. Par exemple, vous pouvez copier les données de la source de données officielle vers d'autres emplacements, tels que les compartiments Amazon Simple Storage Service (Amazon S3) du compte d'application DP qui sont utilisés pour stocker les données de formation, un sous-ensemble de données clients et des données expurgées. En adoptant cette approche multi-comptes pour séparer les ensembles de données personnelles complets et définitifs du compte Data des charges de travail des consommateurs en aval dans le compte d'application DP, vous pouvez réduire l'impact en cas d'accès non autorisé à vos comptes.
Le schéma suivant illustre les services AWS de sécurité et de confidentialité configurés dans les comptes DP Application et Data.
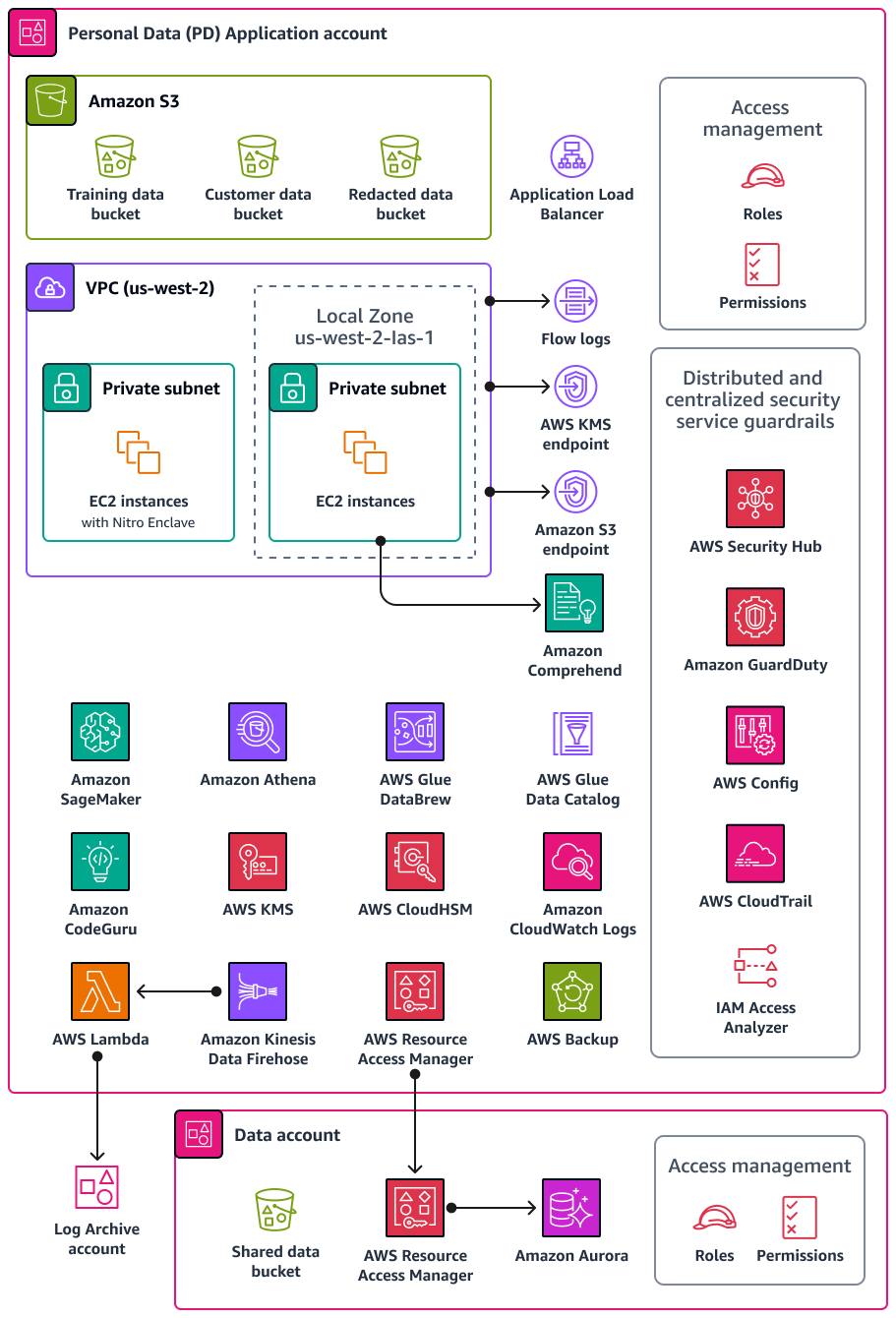
Cette section fournit des informations plus détaillées sur Services AWS les éléments suivants utilisés dans ces comptes :
Amazon Athena
Vous pouvez également envisager des contrôles de limitation des requêtes de données pour atteindre vos objectifs de confidentialité. Amazon Athena est un service de requête interactif qui vous permet d'analyser les données directement dans Amazon S3 à l'aide du SQL standard. Il n'est pas nécessaire de charger les données dans Athena ; cela fonctionne directement avec les données stockées dans des compartiments S3.
Un cas d'utilisation courant pour Athena consiste à fournir aux équipes d'analyse des données des ensembles de données personnalisés et nettoyés. Si les ensembles de données contiennent des données personnelles, vous pouvez les nettoyer en masquant des colonnes entières de données personnelles qui n'apportent que peu de valeur aux équipes d'analyse des données. Pour plus d'informations, consultez Anonymiser et gérer les données de votre lac de données avec Amazon Athena AWS Lake Formation
Si votre approche de transformation des données nécessite une flexibilité supplémentaire en dehors des fonctions prises en charge par Athena, vous pouvez définir des fonctions personnalisées, appelées fonctions définies par l'utilisateur (UDF). Vous pouvez les invoquer UDFs dans une requête SQL soumise à Athena, et elles s'exécutent. AWS Lambda Vous pouvez utiliser SELECT des FILTER
SQL requêtes UDFs in et vous pouvez en invoquer plusieurs UDFs dans la même requête. Pour des raisons de confidentialité, vous pouvez créer UDFs des types spécifiques de masquage des données, par exemple en n'affichant que les quatre derniers caractères de chaque valeur d'une colonne.
Amazon CloudWatch Logs
Amazon CloudWatch Logs vous aide à centraliser les journaux de tous vos systèmes et applications, Services AWS afin que vous puissiez les surveiller et les archiver en toute sécurité. Dans CloudWatch Logs, vous pouvez utiliser une politique de protection des données pour les groupes de journaux nouveaux ou existants afin de minimiser le risque de divulgation de données personnelles. Les politiques de protection des données peuvent détecter des données sensibles, telles que des données personnelles, dans vos journaux. La politique de protection des données peut masquer ces données lorsque les utilisateurs accèdent aux journaux via le AWS Management Console. Lorsque les utilisateurs ont besoin d'un accès direct aux données personnelles, conformément à l'objectif global de votre charge de travail, vous pouvez logs:Unmask leur attribuer des autorisations. Vous pouvez également créer une politique de protection des données à l'échelle du compte et appliquer cette politique de manière cohérente à tous les comptes de votre organisation. Cela permet de configurer le masquage par défaut pour tous les groupes de journaux actuels et futurs dans CloudWatch Logs. Nous vous recommandons également d'activer les rapports d'audit et de les envoyer à un autre groupe de journaux, à un compartiment Amazon S3 ou à Amazon Data Firehose. Ces rapports contiennent un enregistrement détaillé des résultats relatifs à la protection des données pour chaque groupe de journaux.
CodeGuru Réviseur Amazon
Pour des raisons de confidentialité et de sécurité, il est essentiel pour de nombreuses entreprises de garantir une conformité continue pendant et après le déploiement. Le AWS PRA inclut des contrôles proactifs dans les pipelines de déploiement pour les applications qui traitent des données personnelles. Amazon CodeGuru Reviewer peut détecter les défauts potentiels susceptibles d'exposer des données personnelles dans du code Java et Python. JavaScript Il propose des suggestions aux développeurs pour améliorer le code. CodeGuru Le réviseur peut identifier les défauts dans un large éventail de bonnes pratiques générales en matière de sécurité, de confidentialité et de bonnes pratiques générales. Pour plus d'informations, consultez la bibliothèque Amazon CodeGuru Detector. Il est conçu pour fonctionner avec plusieurs fournisseurs de sources AWS CodeCommit, notamment Bitbucket et Amazon S3. GitHub Parmi les défauts liés à la confidentialité que le CodeGuru réviseur peut détecter, citons :
-
injection de code SQL
-
Cookies non sécurisés
-
Autorisation manquante
-
Rechiffrement côté client AWS KMS
Amazon Comprehend
Amazon Comprehend est un service de traitement du langage naturel (NLP) qui utilise l'apprentissage automatique pour découvrir des informations et des connexions précieuses dans des documents texte en anglais. Amazon Comprehend peut détecter et supprimer des données personnelles dans des documents texte structurés, semi-structurés ou non structurés. Pour plus d'informations, consultez la section Informations personnelles identifiables (PII) dans la documentation Amazon Comprehend.
Vous pouvez utiliser l'AWS SDKs et l'API Amazon Comprehend pour intégrer Amazon Comprehend à de nombreuses applications. Par exemple, Amazon Comprehend permet de détecter et de supprimer des données personnelles avec Amazon S3 Object Lambda. Organisations peuvent utiliser S3 Object Lambda pour ajouter du code personnalisé aux requêtes GET d'Amazon S3 afin de modifier et de traiter les données lorsqu'elles sont renvoyées à une application. S3 Object Lambda peut filtrer les lignes, redimensionner les images de manière dynamique, supprimer des données personnelles, etc. Alimenté par AWS Lambda des fonctions, le code s'exécute sur une infrastructure entièrement gérée par AWS, ce qui élimine le besoin de créer et de stocker des copies dérivées de vos données ou d'exécuter des proxys. Vous n'avez pas besoin de modifier vos applications pour transformer des objets avec S3 Object Lambda. Vous pouvez utiliser la fonction ComprehendPiiRedactionS3Object Lambda AWS Serverless Application Repository pour supprimer des données personnelles. Cette fonction utilise Amazon Comprehend pour détecter les entités de données personnelles et les expédie en les remplaçant par des astérisques. Pour plus d'informations, consultez la section Détection et suppression de données personnelles avec S3 Object Lambda et Amazon Comprehend dans la documentation Amazon S3.
Amazon Comprehend propose de nombreuses options d'intégration d'applications via AWS. Vous pouvez SDKs donc utiliser Amazon Comprehend pour identifier les données personnelles dans de nombreux endroits où vous collectez, stockez et traitez des données. Vous pouvez utiliser les fonctionnalités d'Amazon Comprehend ML pour détecter et supprimer les données personnelles dans les journaux des applications
-
REPLACE_WITH_PII_ENTITY_TYPEremplace chaque entité PII par ses types. Par exemple, Jane Doe serait remplacée par NAME. -
MASKremplace les caractères des entités PII par un personnage de votre choix (! , #, $, %, &, ou @). Par exemple, Jane Doe pourrait être remplacée par **** ***.
Amazon Data Firehose
Amazon Data Firehose peut être utilisé pour capturer, transformer et charger des données de streaming dans des services en aval, tels qu'Amazon Managed Service pour Apache Flink ou Amazon S3. Firehose est souvent utilisé pour transporter de grandes quantités de données en streaming, telles que les journaux d'applications, sans avoir à créer des pipelines de traitement à partir de zéro.
Vous pouvez utiliser les fonctions Lambda pour effectuer un traitement personnalisé ou intégré avant que les données ne soient envoyées en aval. Pour des raisons de confidentialité, cette fonctionnalité prend en charge les exigences de minimisation des données et de transfert de données transfrontalier. Par exemple, vous pouvez utiliser Lambda et Firehose pour transformer les données de journaux multirégionales avant qu'elles ne soient centralisées dans le compte Log Archive. Pour plus d'informations, voir Biogen : solution de journalisation centralisée pour plusieurs comptes
AWS Glue
La gestion des ensembles de données contenant des données personnelles est un élément clé de la protection de la vie privée dès la conception
AWS Glue Data Catalog
AWS Glue Data Catalogvous aide à établir des ensembles de données maintenables. Le catalogue de données contient des références aux données utilisées comme sources et cibles pour les tâches d'extraction, de transformation et de chargement (ETL) dans AWS Glue. Les informations du catalogue de données sont stockées sous forme de tables de métadonnées, et chaque table indique un magasin de données unique. Vous exécutez un AWS Glue
robot d'exploration pour inventorier les données dans différents types de magasins de données. Vous ajoutez des classificateurs intégrés et personnalisés au robot d'exploration, et ces classificateurs déduisent le format des données et le schéma des données personnelles. Le robot d'exploration écrit ensuite les métadonnées dans le catalogue de données. Une table de métadonnées centralisée peut faciliter la réponse aux demandes des personnes concernées (telles que le droit à l'effacement), car elle ajoute de la structure et de la prévisibilité aux différentes sources de données personnelles de votre environnement. AWS Pour un exemple complet de la façon d'utiliser Data Catalog pour répondre automatiquement à ces demandes, consultez Gérer les demandes d'effacement de données dans votre lac de données avec Amazon S3 Find and Forget
AWS Glue DataBrew
AWS Glue DataBrewvous aide à nettoyer et à normaliser les données, et il peut effectuer des transformations sur les données, telles que la suppression ou le masquage d'informations personnelles identifiables et le chiffrement de champs de données sensibles dans des pipelines de données. Vous pouvez également cartographier visuellement le lignage de vos données afin de comprendre les différentes sources de données et les étapes de transformation par lesquelles les données ont été soumises. Cette fonctionnalité devient de plus en plus importante à mesure que votre organisation s'efforce de mieux comprendre et suivre la provenance des données personnelles. DataBrew vous aide à masquer les données personnelles lors de la préparation des données. Vous pouvez détecter les données personnelles dans le cadre d'un travail de profilage des données et recueillir des statistiques, telles que le nombre de colonnes susceptibles de contenir des données personnelles et les catégories potentielles. Vous pouvez ensuite utiliser des techniques intégrées de transformation des données réversibles ou irréversibles, notamment la substitution, le hachage, le chiffrement et le déchiffrement, le tout sans écrire de code. Vous pouvez ensuite utiliser les ensembles de données nettoyés et masqués en aval pour des tâches d'analyse, de reporting et d'apprentissage automatique. Certaines des techniques de masquage de données disponibles DataBrew incluent :
-
Hachage — Appliquez des fonctions de hachage aux valeurs des colonnes.
-
Substitution — Remplacez les données personnelles par d'autres valeurs d'apparence authentique.
-
Annulation ou suppression : remplacez un champ spécifique par une valeur nulle ou supprimez la colonne.
-
Masquage : utilisez le brouillage de caractères ou masquez certaines parties des colonnes.
Les techniques de chiffrement disponibles sont les suivantes :
-
Chiffrement déterministe : appliquez des algorithmes de chiffrement déterministes aux valeurs des colonnes. Le chiffrement déterministe produit toujours le même texte chiffré pour une valeur.
-
Chiffrement probabiliste : appliquez des algorithmes de chiffrement probabiliste aux valeurs des colonnes. Le chiffrement probabiliste produit un texte chiffré différent chaque fois qu'il est appliqué.
Pour une liste complète des recettes de transformation des données personnelles fournies dans DataBrew, voir Étapes de recette relatives aux informations personnelles identifiables (PII).
AWS Glue Qualité des données
AWS Glue Data Quality vous aide à automatiser et à opérationnaliser la diffusion de données de haute qualité dans les pipelines de données, de manière proactive, avant qu'elles ne soient livrées à vos consommateurs de données. AWS Glue Data Quality fournit une analyse statistique des problèmes de qualité des données dans l'ensemble de vos pipelines de données, peut déclencher des alertes sur Amazon EventBridge et peut recommander des règles de qualité pour y remédier. AWS Glue Data Quality prend également en charge la création de règles dans un langage spécifique au domaine afin que vous puissiez créer des règles de qualité des données personnalisées.
AWS Key Management Service
AWS Key Management Service (AWS KMS) vous aide à créer et à contrôler des clés cryptographiques pour protéger vos données. AWS KMS utilise des modules de sécurité matériels pour protéger et valider AWS KMS keys dans le cadre du programme de validation des modules cryptographiques FIPS 140-2. Pour plus d'informations sur la manière dont ce service est utilisé dans un contexte de sécurité, consultez l'architecture AWS de référence de sécurité.
AWS KMS s'intègre à la plupart Services AWS des solutions de chiffrement, et vous pouvez utiliser des clés KMS dans vos applications qui traitent et stockent des données personnelles. Vous pouvez AWS KMS les utiliser pour répondre à diverses exigences en matière de confidentialité et protéger les données personnelles, notamment :
-
Utilisation de clés gérées par le client pour un meilleur contrôle de la force, de la rotation, de l'expiration et d'autres options.
-
Utilisation de clés dédiées gérées par le client pour protéger les données personnelles et les secrets permettant d'accéder aux données personnelles.
-
Définition des niveaux de classification des données et désignation d'au moins une clé dédiée gérée par le client par niveau. Par exemple, vous pouvez avoir une clé pour chiffrer les données opérationnelles et une autre pour chiffrer les données personnelles.
-
Empêcher l'accès non intentionnel aux clés KMS entre comptes.
-
Stockage des clés KMS dans la même ressource Compte AWS que la ressource à chiffrer.
-
Mise en œuvre de la séparation des tâches pour l'administration et l'utilisation des clés KMS. Pour plus d'informations, consultez Comment utiliser KMS et IAM pour activer des contrôles de sécurité indépendants pour les données chiffrées dans S3
(article de AWS blog). -
Renforcer la rotation automatique des clés grâce à des glissières de sécurité préventives et réactives.
Par défaut, les clés KMS sont stockées et ne peuvent être utilisées que dans la région où elles ont été créées. Si votre organisation a des exigences spécifiques en matière de résidence et de souveraineté des données, déterminez si les clés KMS multirégionales sont adaptées à votre cas d'utilisation. Les clés multirégionales sont des clés KMS spécifiques, différentes, Régions AWS qui peuvent être utilisées de manière interchangeable. Le processus de création d'une clé multirégionale déplace votre matériel clé Région AWS au-delà des frontières internes AWS KMS, de sorte que cette absence d'isolement régional risque d'être incompatible avec les objectifs de conformité de votre organisation. L'un des moyens de résoudre ce problème consiste à utiliser un autre type de clé KMS, par exemple une clé gérée par le client spécifique à une région.
AWS Zones Locales
Si vous devez respecter les exigences relatives à la résidence des données, vous pouvez déployer des ressources qui stockent et traitent les données personnelles spécifiquement Régions AWS pour répondre à ces exigences. Vous pouvez également utiliser les Zones AWS Locales, qui vous permettent de placer le calcul, le stockage, les bases de données et d'autres AWS ressources sélectionnées à proximité de grands centres industriels et peuplés. Une zone locale est une extension d'une Région AWS zone située à proximité géographique d'une grande région métropolitaine. Vous pouvez placer des types spécifiques de ressources dans une zone locale, à proximité de la région à laquelle correspond la zone locale. Les Zones Locales peuvent vous aider à satisfaire aux exigences de résidence des données lorsqu'une région n'est pas disponible au sein de la même juridiction légale. Lorsque vous utilisez des Zones Locales, tenez compte des contrôles de résidence des données déployés au sein de votre organisation. Par exemple, vous pourriez avoir besoin d'un contrôle pour empêcher les transferts de données d'une zone locale spécifique vers une autre région. Pour plus d'informations sur la manière de SCPs maintenir des barrières de sécurité en matière de transfert de données transfrontalier, consultez Bonnes pratiques pour gérer la résidence des données dans les zones AWS locales à l'aide des contrôles de zone d'atterrissage
AWS Enclaves Nitro
Réfléchissez à votre stratégie de segmentation des données du point de vue du traitement, comme le traitement des données personnelles avec un service informatique tel qu'Amazon Elastic Compute Cloud (Amazon EC2). L'informatique confidentielle dans le cadre d'une stratégie d'architecture plus large peut vous aider à isoler le traitement des données personnelles dans une enclave CPU isolée, protégée et fiable. Les enclaves sont des machines virtuelles distinctes, renforcées et soumises à des contraintes élevées. AWS Nitro Enclaves est EC2 une fonctionnalité d'Amazon qui peut vous aider à créer ces environnements informatiques isolés. Pour plus d'informations, consultez La conception de la sécurité du système AWS Nitro (AWS livre blanc).
Les enclaves Nitro déploient un noyau séparé du noyau de l'instance parent. Le noyau de l'instance parent n'a pas accès à l'enclave. Les utilisateurs ne peuvent pas utiliser le protocole SSH ou accéder à distance aux données et aux applications de l'enclave. Les applications qui traitent des données personnelles peuvent être intégrées dans l'enclave et configurées pour utiliser le Vsock de l'enclave, le socket qui facilite la communication entre l'enclave et l'instance parent.
L'un des cas d'utilisation dans lesquels Nitro Enclaves peut être utile est le traitement conjoint entre deux processeurs de données distincts Régions AWS et susceptibles de ne pas se faire confiance. L'image suivante montre comment vous pouvez utiliser une enclave pour le traitement centralisé, une clé KMS pour chiffrer les données personnelles avant leur envoi à l'enclave et une AWS KMS key politique qui vérifie que l'enclave demandant le déchiffrement possède les mesures uniques indiquées dans son document d'attestation. Pour plus d'informations et d'instructions, consultez la section Utilisation d'une attestation cryptographique avec AWS KMS. Pour un exemple de politique clé, consultez Exiger une attestation pour utiliser une AWS KMS clé ce guide.
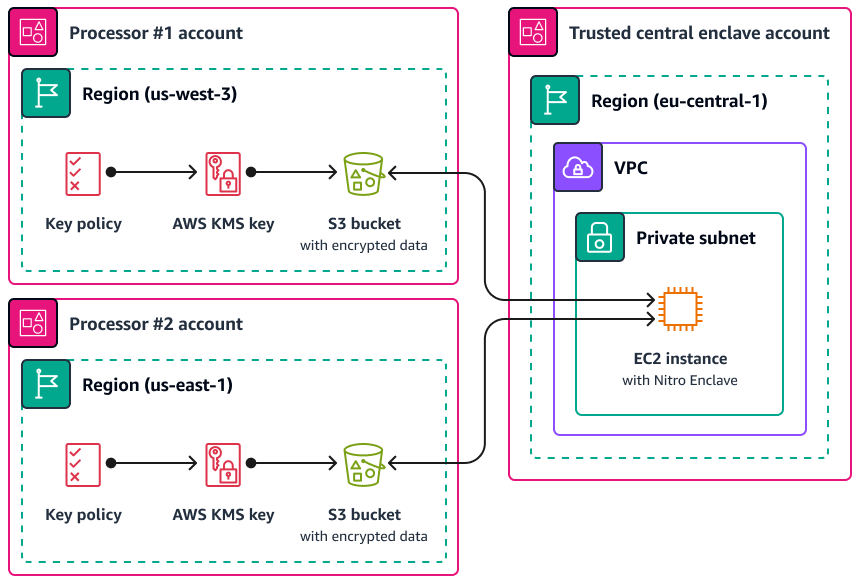
Avec cette implémentation, seuls les processeurs de données respectifs et l'enclave sous-jacente ont accès aux données personnelles en texte clair. Le seul endroit où les données sont exposées, en dehors de l'environnement des processeurs de données respectifs, est dans l'enclave elle-même, qui est conçue pour empêcher l'accès et la falsification.
AWS PrivateLink
De nombreuses entreprises souhaitent limiter l'exposition des données personnelles à des réseaux non fiables. Par exemple, si vous souhaitez améliorer la confidentialité de la conception globale de votre architecture d'application, vous pouvez segmenter les réseaux en fonction de la sensibilité des données (similaire à la séparation logique et physique des ensembles de données décrite dans la Services et fonctionnalités AWS qui aident à segmenter les données section). AWS PrivateLinkvous permet de créer des connexions privées unidirectionnelles entre vos clouds privés virtuels (VPCs) et des services extérieurs au VPC. Vous pouvez ainsi configurer des connexions privées dédiées aux services qui stockent ou traitent des données personnelles dans votre environnement ; il n'est pas nécessaire de vous connecter à des points de terminaison publics et de transférer ces données sur des réseaux publics non fiables. AWS PrivateLink Lorsque vous activez les points de terminaison de AWS PrivateLink service pour les services concernés, il n'est pas nécessaire de disposer d'une passerelle Internet, d'un périphérique NAT, d'une adresse IP publique, d'une AWS Direct Connect connexion ou d' AWS Site-to-Site VPN une connexion pour communiquer. Lorsque vous vous connectez AWS PrivateLink à un service qui fournit un accès aux données personnelles, vous pouvez utiliser des politiques de point de terminaison VPC et des groupes de sécurité pour contrôler l'accès, conformément à la définition du périmètre de données
AWS Resource Access Manager
AWS Resource Access Manager (AWS RAM) vous permet de partager vos ressources en toute sécurité afin Comptes AWS de réduire les frais opérationnels et de garantir visibilité et auditabilité. Lorsque vous planifiez votre stratégie de segmentation multi-comptes, pensez AWS RAM à partager les banques de données personnelles que vous stockez dans un compte distinct et isolé. Vous pouvez partager ces données personnelles avec d'autres comptes fiables à des fins de traitement. Dans AWS RAM, vous pouvez gérer les autorisations qui définissent les actions pouvant être effectuées sur les ressources partagées. Tous les appels d'API AWS RAM sont connectés CloudTrail. Vous pouvez également configurer Amazon CloudWatch Events pour qu'il vous avertisse automatiquement en cas d'événements spécifiques AWS RAM, par exemple lorsque des modifications sont apportées à un partage de ressources.
Bien que vous puissiez partager de nombreux types de AWS ressources avec d'autres personnes en Comptes AWS utilisant des politiques basées sur les ressources dans IAM ou des politiques de compartiment dans Amazon S3, cela AWS RAM offre plusieurs avantages supplémentaires en termes de confidentialité. AWS fournit aux propriétaires de données une visibilité supplémentaire sur la manière dont les données sont partagées et avec qui Comptes AWS, notamment :
-
Possibilité de partager une ressource avec une unité d'organisation complète au lieu de mettre à jour manuellement les listes de comptes IDs
-
Application du processus d'invitation pour l'initiation du partage si le compte client ne fait pas partie de votre organisation
-
Visibilité sur les principaux responsables de l'IAM ayant accès à chaque ressource individuelle
Si vous avez déjà utilisé une politique basée sur les ressources pour gérer un partage de ressources et que vous souhaitez l'utiliser à la AWS RAM place, utilisez l'opération PromoteResourceShareCreatedFromPolicyAPI.
Amazon SageMaker AI
Amazon SageMaker AI est un service géré d'apprentissage automatique (ML) qui vous aide à créer et à former des modèles de machine learning, puis à les déployer dans un environnement hébergé prêt pour la production. SageMaker L'IA est conçue pour faciliter la préparation des données d'entraînement et la création des fonctionnalités du modèle.
Moniteur de modèles Amazon SageMaker AI
De nombreuses entreprises prennent en compte la dérive des données lors de la formation de modèles de machine learning. La dérive des données est une variation significative entre les données de production et les données utilisées pour entraîner un modèle ML, ou une modification significative des données d'entrée au fil du temps. La dérive des données peut réduire la qualité, la précision et l'équité globales des prédictions des modèles ML. Si la nature statistique des données qu'un modèle ML reçoit en production s'éloigne de la nature des données de référence sur lesquelles il a été entraîné, la précision des prédictions peut diminuer. Amazon SageMaker AI Model Monitor peut surveiller en permanence la qualité des modèles d'apprentissage automatique Amazon SageMaker AI en production et surveiller la qualité des données. La détection précoce et proactive de la dérive des données peut vous aider à mettre en œuvre des mesures correctives, telles que la reconversion des modèles, l'audit des systèmes en amont ou la résolution des problèmes de qualité des données. Model Monitor peut réduire le besoin de surveiller manuellement les modèles ou de créer des outils supplémentaires.
Amazon SageMaker AI Clarifie
Amazon SageMaker AI Clarify fournit un aperçu du biais et de l'explicabilité du modèle. SageMaker AI Clarify est couramment utilisé lors de la préparation des données du modèle ML et de la phase globale de développement. Les développeurs peuvent spécifier des attributs intéressants, tels que le sexe ou l'âge, et SageMaker AI Clarify exécute un ensemble d'algorithmes pour détecter toute présence de biais dans ces attributs. Une fois l'algorithme exécuté, SageMaker AI Clarify fournit un rapport visuel avec une description des sources et des mesures du biais possible afin que vous puissiez identifier les étapes à suivre pour remédier au biais. Par exemple, dans un ensemble de données financières qui ne contient que quelques exemples de prêts commerciaux accordés à un groupe d'âge par rapport à d'autres, vous SageMaker pourriez détecter des déséquilibres afin d'éviter un modèle qui défavorise ce groupe d'âge. Vous pouvez également vérifier la présence de biais dans les modèles déjà entraînés en examinant leurs prévisions et en surveillant en permanence la présence de biais dans ces modèles de ML. Enfin, SageMaker AI Clarify est intégré à Amazon SageMaker AI Experiments pour fournir un graphique qui explique les caractéristiques qui ont le plus contribué au processus global de prévision d'un modèle. Ces informations peuvent être utiles pour obtenir des résultats d'explicabilité, et elles peuvent vous aider à déterminer si une entrée de modèle particulière a plus d'influence qu'elle ne le devrait sur le comportement global du modèle.
SageMaker Modèle de carte Amazon
Amazon SageMaker Model Card peut vous aider à documenter les détails essentiels de vos modèles de machine learning à des fins de gouvernance et de reporting. Ces informations peuvent inclure le propriétaire du modèle, l'objectif général, les cas d'utilisation prévus, les hypothèses formulées, l'évaluation du risque d'un modèle, les détails et les indicateurs de formation, ainsi que les résultats de l'évaluation. Pour plus d'informations, voir Explicabilité du modèle avec les solutions d'intelligence AWS artificielle et de Machine Learning (AWS livre blanc).
AWS fonctionnalités qui aident à gérer le cycle de vie des données
Lorsque les données personnelles ne sont plus nécessaires, vous pouvez utiliser le cycle de vie et time-to-live les politiques des données dans de nombreux magasins de données différents. Lors de la configuration des politiques de conservation des données, tenez compte des emplacements suivants susceptibles de contenir des données personnelles :
-
Bases de données, telles qu'Amazon DynamoDB et Amazon Relational Database Service (Amazon RDS)
-
Compartiments Amazon S3
-
Logs provenant de CloudWatch et CloudTrail
-
Données mises en cache provenant de migrations dans AWS Database Migration Service (AWS DMS) et AWS Glue DataBrew de projets
-
Sauvegardes et instantanés
Les fonctionnalités Services AWS et fonctionnalités suivantes peuvent vous aider à configurer les politiques de conservation des données dans vos AWS environnements :
-
Amazon S3 Lifecycle : ensemble de règles qui définissent les actions qu'Amazon S3 applique à un groupe d'objets. Dans la configuration du cycle de vie d'Amazon S3, vous pouvez créer des actions d'expiration qui définissent le moment où Amazon S3 supprime les objets expirés en votre nom. Pour plus d'informations, voir Gestion du cycle de vie de votre stockage.
-
Amazon Data Lifecycle Manager — Dans Amazon EC2, créez une politique qui automatise la création, la conservation et la suppression des instantanés Amazon Elastic Block Store (Amazon EBS) et des Amazon Machine Images () soutenues par EBS. AMIs
-
DynamoDB Time to Live (TTL) : définissez un horodatage par élément qui détermine le moment où un élément n'est plus nécessaire. Peu après la date et l'heure de l'horodatage spécifié, DynamoDB supprime l'élément de votre tableau.
-
Paramètres de conservation CloudWatch des journaux dans Logs : vous pouvez ajuster la politique de conservation pour chaque groupe de journaux à une valeur comprise entre 1 jour et 10 ans.
-
AWS Backup— Déployez de manière centralisée des politiques de protection des données pour configurer, gérer et gouverner votre activité de sauvegarde sur diverses AWS ressources, notamment les compartiments S3, les instances de base de données RDS, les tables DynamoDB, les volumes EBS, etc. Appliquez des politiques de sauvegarde à vos AWS ressources en spécifiant les types de ressources ou en fournissant une granularité supplémentaire en les appliquant en fonction des balises de ressources existantes. Auditez et générez des rapports sur les activités de sauvegarde à partir d'une console centralisée afin de répondre aux exigences de conformité en matière de sauvegarde.
Services et fonctionnalités AWS qui aident à segmenter les données
La segmentation des données est le processus par lequel vous stockez les données dans des conteneurs distincts. Cela peut vous aider à fournir des mesures de sécurité et d'authentification différenciées pour chaque ensemble de données et à réduire l'impact de l'exposition sur votre ensemble de données dans son ensemble de données. Par exemple, au lieu de stocker toutes les données clients dans une grande base de données, vous pouvez segmenter ces données en groupes plus petits et plus faciles à gérer.
Vous pouvez utiliser la séparation physique et logique pour segmenter les données personnelles :
-
Séparation physique — Le fait de stocker des données dans des magasins de données distincts ou de distribuer vos données dans AWS des ressources distinctes. Bien que les données soient physiquement séparées, les deux ressources peuvent être accessibles aux mêmes personnes. C'est pourquoi nous recommandons de combiner séparation physique et séparation logique.
-
Séparation logique — Action d'isoler des données à l'aide de contrôles d'accès. Les différentes fonctions professionnelles nécessitent différents niveaux d'accès à des sous-ensembles de données personnelles. Pour un exemple de politique qui implémente la séparation logique, consultez Accorder l'accès à des attributs Amazon DynamoDB spécifiques ce guide.
La combinaison d'une séparation logique et physique apporte flexibilité, simplicité et granularité lors de la rédaction de politiques basées sur l'identité et les ressources afin de permettre un accès différencié entre les fonctions professionnelles. Par exemple, il peut être complexe d'un point de vue opérationnel de créer les politiques qui séparent logiquement les différentes classifications de données dans un même compartiment S3. L'utilisation de compartiments S3 dédiés pour chaque classification de données simplifie la configuration et la gestion des politiques.
