Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Data Pribadi OU - Akun Aplikasi PD
Kami akan senang mendengar dari Anda. Harap berikan umpan balik tentang AWS PRA dengan mengikuti survei singkat |
Akun Aplikasi Data Pribadi (PD) adalah tempat organisasi Anda menyelenggarakan layanan yang mengumpulkan dan memproses data pribadi. Secara khusus, Anda dapat menyimpan apa yang Anda definisikan sebagai data pribadi di akun ini. AWS PRA menunjukkan sejumlah contoh konfigurasi privasi melalui arsitektur web tanpa server multi-tier. Ketika menyangkut beban kerja pengoperasian di seluruh AWS landing zone, konfigurasi privasi tidak boleh dianggap sebagai one-size-fits-all solusi. Misalnya, tujuan Anda mungkin untuk memahami konsep yang mendasarinya, bagaimana mereka dapat meningkatkan privasi, dan bagaimana organisasi Anda dapat menerapkan solusi untuk kasus penggunaan dan arsitektur khusus Anda.
Karena Akun AWS di organisasi Anda yang mengumpulkan, menyimpan, atau memproses data pribadi, Anda dapat menggunakan AWS Organizations dan AWS Control Tower menerapkan pagar pembatas dasar dan berulang. Menetapkan unit organisasi khusus (OU) untuk akun ini sangat penting. Misalnya, Anda mungkin ingin menerapkan pagar pembatas residensi data hanya pada sebagian akun di mana residensi data merupakan pertimbangan desain inti. Bagi banyak organisasi, ini adalah akun yang menyimpan dan memproses data pribadi.
Organisasi Anda mungkin mendukung akun Data khusus, tempat Anda menyimpan sumber otoritatif kumpulan data pribadi Anda. Sumber data otoritatif adalah lokasi tempat Anda menyimpan versi data utama, yang mungkin dianggap sebagai versi data yang paling andal dan akurat. Misalnya, Anda dapat menyalin data dari sumber data otoritatif ke lokasi lain, seperti bucket Amazon Simple Storage Service (Amazon S3) di akun Aplikasi PD yang digunakan untuk menyimpan data pelatihan, subset data pelanggan, dan data yang disunting. Dengan mengambil pendekatan multi-akun ini untuk memisahkan kumpulan data pribadi yang lengkap dan definitif di akun Data dari beban kerja konsumen hilir di akun Aplikasi PD, Anda dapat mengurangi cakupan dampak jika terjadi akses tidak sah ke akun Anda.
Diagram berikut menggambarkan layanan AWS keamanan dan privasi yang dikonfigurasi dalam akun Aplikasi dan Data PD.
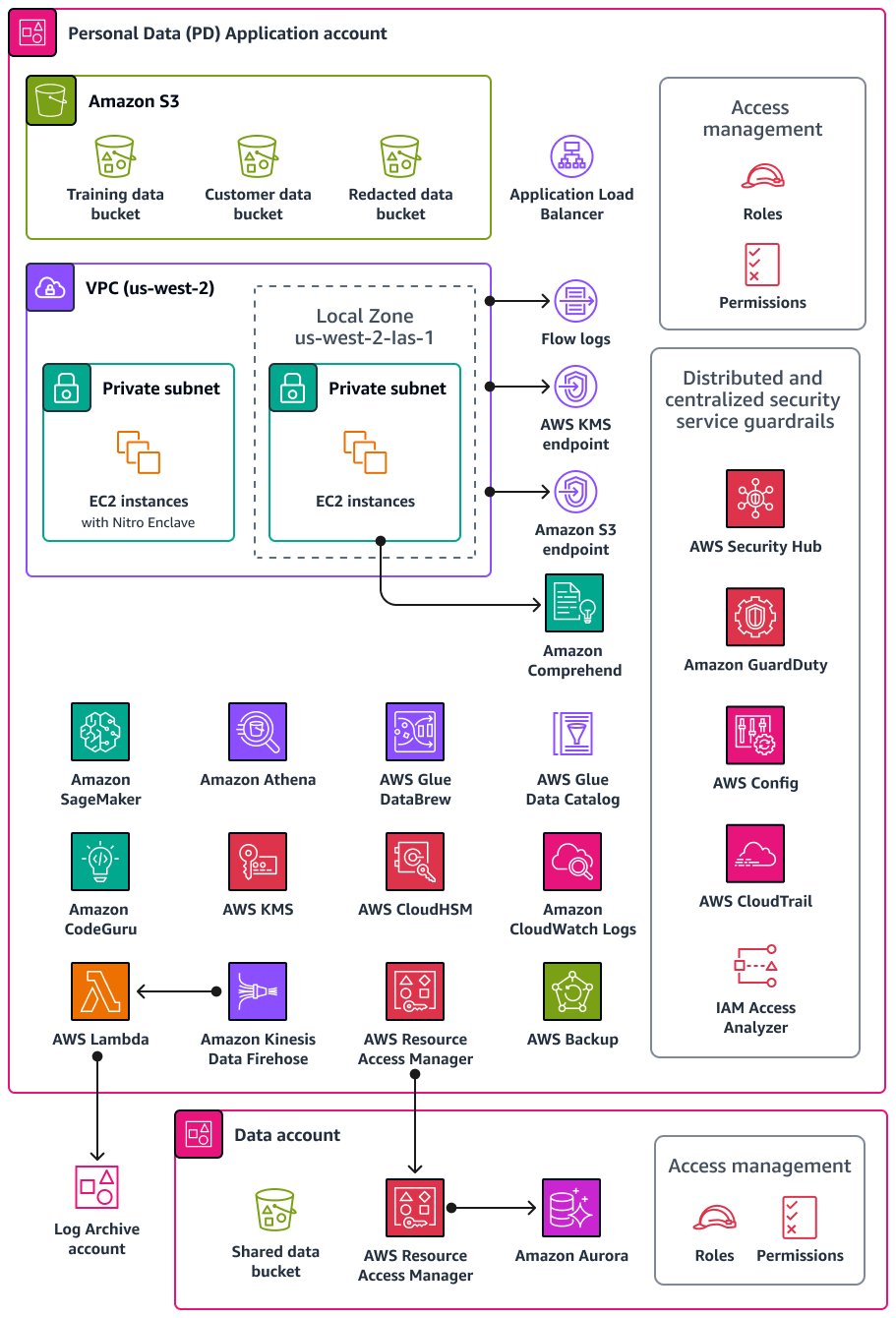
Bagian ini memberikan informasi lebih rinci tentang hal-hal berikut Layanan AWS yang digunakan dalam akun ini:
Amazon Athena
Anda juga dapat mempertimbangkan kontrol pembatasan kueri data untuk memenuhi tujuan privasi Anda. Amazon Athena adalah layanan kueri interaktif yang membantu Anda menganalisis data secara langsung di Amazon S3 dengan menggunakan SQL standar. Anda tidak perlu memuat data ke Athena; ini bekerja langsung dengan data yang disimpan dalam ember S3.
Kasus penggunaan umum untuk Athena adalah menyediakan kumpulan data yang disesuaikan dan disanitasi kepada tim analitik data. Jika kumpulan data berisi data pribadi, Anda dapat membersihkan kumpulan data dengan menutupi seluruh kolom data pribadi yang memberikan sedikit nilai bagi tim analitik data. Untuk informasi selengkapnya, lihat Menganonimkan dan mengelola data di danau data Anda dengan Amazon Athena dan AWS Lake Formation
Jika pendekatan transformasi data Anda memerlukan fleksibilitas tambahan di luar fungsi yang didukung di Athena, Anda dapat menentukan fungsi kustom, yang disebut fungsi yang ditentukan pengguna (UDF). Anda dapat memanggil UDFs dalam kueri SQL yang dikirimkan ke Athena, dan mereka berjalan. AWS Lambda Anda dapat menggunakan UDFs dalam SELECT dan FILTER
SQL kueri, dan Anda dapat memanggil beberapa UDFs dalam kueri yang sama. Untuk privasi, Anda dapat membuat UDFs yang melakukan jenis penyembunyian data tertentu, seperti hanya menampilkan empat karakter terakhir dari setiap nilai dalam kolom.
CloudWatch Log Amazon
Amazon CloudWatch Logs membantu Anda memusatkan log dari semua sistem, aplikasi, Layanan AWS sehingga Anda dapat memantau dan mengarsipkannya dengan aman. Di CloudWatch Log, Anda dapat menggunakan kebijakan perlindungan data untuk grup log baru atau yang sudah ada untuk membantu meminimalkan risiko pengungkapan data pribadi. Kebijakan perlindungan data dapat mendeteksi data sensitif, seperti data pribadi, di log Anda. Kebijakan perlindungan data dapat menutupi data tersebut ketika pengguna mengakses log melalui file AWS Management Console. Ketika pengguna memerlukan akses langsung ke data pribadi, sesuai dengan spesifikasi tujuan keseluruhan untuk beban kerja Anda, Anda dapat menetapkan logs:Unmask izin untuk pengguna tersebut. Anda juga dapat membuat kebijakan perlindungan data di seluruh akun dan menerapkan kebijakan ini secara konsisten di semua akun di organisasi Anda. Ini mengonfigurasi masking secara default untuk semua grup log saat ini dan masa depan di CloudWatch Log. Kami juga menyarankan Anda mengaktifkan laporan audit dan mengirimkannya ke grup log lain, bucket Amazon S3, atau Amazon Data Firehose. Laporan ini berisi catatan rinci temuan perlindungan data di setiap grup log.
CodeGuru Peninjau Amazon
Untuk privasi dan keamanan, sangat penting bagi banyak organisasi bahwa mereka mendukung kepatuhan berkelanjutan selama fase penerapan dan pasca-penyebaran. AWS PRA mencakup kontrol proaktif dalam pipeline penyebaran untuk aplikasi yang memproses data pribadi. Amazon CodeGuru Reviewer dapat mendeteksi potensi cacat yang mungkin mengekspos data pribadi di Jawa, JavaScript, dan kode Python. Ini menawarkan saran kepada pengembang untuk meningkatkan kode. CodeGuru Peninjau dapat mengidentifikasi cacat di berbagai keamanan, privasi, dan praktik terbaik umum. Untuk informasi selengkapnya, lihat Perpustakaan CodeGuru Detektor Amazon. Ini dirancang untuk bekerja dengan beberapa penyedia sumber, termasuk, Bitbucket AWS CodeCommit, GitHub, dan Amazon S3. Beberapa cacat terkait privasi yang dapat dideteksi oleh CodeGuru Reviewer meliputi:
-
Injeksi SQL
-
Cookie tanpa jaminan
-
Otorisasi hilang
-
Enkripsi ulang sisi klien AWS KMS
Amazon Comprehend
Amazon Comprehend adalah layanan pemrosesan bahasa alami (NLP) yang menggunakan pembelajaran mesin untuk mengungkap wawasan dan koneksi berharga dalam dokumen teks bahasa Inggris. Amazon Comprehend dapat mendeteksi dan menyunting data pribadi dalam dokumen teks terstruktur, semi-terstruktur, atau tidak terstruktur. Untuk informasi selengkapnya, lihat Informasi identitas pribadi (PII) di dokumentasi Amazon Comprehend.
Anda dapat menggunakan AWS SDKs dan Amazon Comprehend API untuk mengintegrasikan Amazon Comprehend dengan banyak aplikasi. Contohnya adalah menggunakan Amazon Comprehend untuk mendeteksi dan menyunting data pribadi dengan Amazon S3 Object Lambda. Organizations dapat menggunakan S3 Object Lambda untuk menambahkan kode kustom ke permintaan Amazon S3 GET untuk memodifikasi dan memproses data saat dikembalikan ke aplikasi. S3 Object Lambda dapat memfilter baris, mengubah ukuran gambar secara dinamis, menyunting data pribadi, dan banyak lagi. Didukung oleh AWS Lambda fungsi, kode berjalan pada infrastruktur yang sepenuhnya dikelola oleh AWS, yang menghilangkan kebutuhan untuk membuat dan menyimpan salinan turunan dari data Anda atau untuk menjalankan proxy. Anda tidak perlu mengubah aplikasi Anda untuk mengubah objek dengan S3 Object Lambda. Anda dapat menggunakan fungsi ComprehendPiiRedactionS3Object Lambda AWS Serverless Application Repository untuk menyunting data pribadi. Fungsi ini menggunakan Amazon Comprehend untuk mendeteksi entitas data pribadi dan menyunting entitas tersebut dengan menggantinya dengan tanda bintang. Untuk informasi selengkapnya, lihat Mendeteksi dan menyunting data PII dengan S3 Object Lambda dan Amazon Comprehend dalam dokumentasi Amazon S3.
Karena Amazon Comprehend memiliki banyak opsi untuk integrasi aplikasi melalui SDKs AWS, Anda dapat menggunakan Amazon Comprehend untuk mengidentifikasi data pribadi di berbagai tempat di mana Anda mengumpulkan, menyimpan, dan memproses data. Anda dapat menggunakan kemampuan Amazon Comprehend MLuntuk mendeteksi dan menyunting data pribadi di
-
REPLACE_WITH_PII_ENTITY_TYPEmenggantikan setiap entitas PII dengan tipenya. Misalnya, Jane Doe akan diganti dengan NAME. -
MASKmenggantikan karakter dalam entitas PII dengan karakter pilihan Anda (! , #, $,%, &,, atau @). Misalnya, Jane Doe dapat diganti dengan **** ***.
Amazon Data Firehose
Amazon Data Firehose dapat digunakan untuk menangkap, mengubah, dan memuat data streaming ke layanan hilir, seperti Amazon Managed Service untuk Apache Flink atau Amazon S3. Firehose sering digunakan untuk mengangkut data streaming dalam jumlah besar, seperti log aplikasi, tanpa harus membangun pipa pemrosesan dari bawah ke atas.
Anda dapat menggunakan fungsi Lambda untuk melakukan pemrosesan khusus atau bawaan sebelum data dikirim ke hilir. Untuk privasi, kemampuan ini mendukung minimalisasi data dan persyaratan transfer data lintas batas. Misalnya, Anda dapat menggunakan Lambda dan Firehose untuk mengubah data log Multi-wilayah sebelum terpusat di akun Arsip Log. Untuk informasi selengkapnya, lihat Biogen: Solusi Pencatatan Terpusat untuk Multi Akun
AWS Glue
Mempertahankan kumpulan data yang berisi data pribadi adalah komponen kunci dari Privacy by Design
AWS Glue Data Catalog
AWS Glue Data Catalogmembantu Anda membuat kumpulan data yang dapat dipelihara. Katalog Data berisi referensi ke data yang digunakan sebagai sumber dan target untuk mengekstrak, mengubah, dan memuat (ETL) pekerjaan di AWS Glue. Informasi dalam Katalog Data disimpan sebagai tabel metadata, dan setiap tabel menentukan penyimpanan data tunggal. Anda menjalankan AWS Glue
crawler untuk mengambil inventaris data dalam berbagai jenis penyimpanan data. Anda menambahkan pengklasifikasi bawaan dan kustom ke crawler, dan pengklasifikasi ini menyimpulkan format data dan skema data pribadi. Crawler kemudian menulis metadata ke Katalog Data. Tabel metadata terpusat dapat memudahkan untuk menanggapi permintaan subjek data (seperti hak untuk menghapus) karena menambahkan struktur dan prediktabilitas di berbagai sumber data pribadi di lingkungan Anda. AWS Untuk contoh komprehensif tentang cara menggunakan Katalog Data untuk merespons permintaan ini secara otomatis, lihat Menangani permintaan penghapusan data di data lake Anda dengan Amazon S3 Find and
AWS Glue DataBrew
AWS Glue DataBrewmembantu Anda membersihkan dan menormalkan data, dan dapat melakukan transformasi pada data, seperti menghapus atau menutupi informasi yang dapat diidentifikasi secara pribadi dan mengenkripsi bidang data sensitif dalam jaringan data. Anda juga dapat memetakan garis keturunan data Anda secara visual untuk memahami berbagai sumber data dan langkah-langkah transformasi yang telah dilalui data. Fitur ini menjadi semakin penting karena organisasi Anda bekerja untuk lebih memahami dan melacak asal data pribadi. DataBrew membantu Anda menutupi data pribadi selama persiapan data. Anda dapat mendeteksi data pribadi sebagai bagian dari pekerjaan pembuatan profil data dan mengumpulkan statistik, seperti jumlah kolom yang mungkin berisi data pribadi dan kategori potensial. Anda kemudian dapat menggunakan teknik transformasi data reversibel atau ireversibel bawaan, termasuk substitusi, hashing, enkripsi, dan dekripsi, semuanya tanpa menulis kode apa pun. Anda kemudian dapat menggunakan kumpulan data yang dibersihkan dan disamarkan di hilir untuk tugas analitik, pelaporan, dan pembelajaran mesin. Beberapa teknik masking data yang tersedia di DataBrew antaranya:
-
Hashing - Terapkan fungsi hash ke nilai kolom.
-
Substitusi — Ganti data pribadi dengan nilai lain yang tampak otentik.
-
Nulling out atau penghapusan - Ganti bidang tertentu dengan nilai null, atau hapus kolom.
-
Masking out — Gunakan karakter scrambling, atau menutupi bagian-bagian tertentu dalam kolom.
Berikut ini adalah teknik enkripsi yang tersedia:
-
Enkripsi deterministik — Menerapkan algoritma enkripsi deterministik ke nilai kolom. Enkripsi deterministik selalu menghasilkan ciphertext yang sama untuk suatu nilai.
-
Enkripsi probabilistik — Menerapkan algoritma enkripsi probabilistik ke nilai kolom. Enkripsi probabilistik menghasilkan ciphertext yang berbeda setiap kali diterapkan.
Untuk daftar lengkap resep transformasi data pribadi yang disediakan DataBrew, lihat langkah-langkah resep Informasi Identifikasi Pribadi (PII).
AWS Glue Kualitas Data
AWS Glue Kualitas Data membantu Anda mengotomatiskan dan mengoperasionalkan pengiriman data berkualitas tinggi di seluruh jalur data, secara proaktif, sebelum dikirimkan ke konsumen data Anda. AWS Glue Kualitas Data menyediakan analisis statistik masalah kualitas data di seluruh jalur data Anda, dapat memicu peringatan di Amazon EventBridge, dan dapat membuat rekomendasi aturan kualitas untuk perbaikan. AWS Glue Kualitas Data juga mendukung pembuatan aturan dengan bahasa khusus domain sehingga Anda dapat membuat aturan kualitas data kustom.
AWS Key Management Service
AWS Key Management Service (AWS KMS) membantu Anda membuat dan mengontrol kunci kriptografi untuk membantu melindungi data Anda. AWS KMS menggunakan modul keamanan perangkat keras untuk melindungi dan memvalidasi AWS KMS keys di bawah Program Validasi Modul Kriptografi FIPS 140-2. Untuk informasi selengkapnya tentang cara layanan ini digunakan dalam konteks keamanan, lihat Arsitektur Referensi AWS Keamanan.
AWS KMS terintegrasi dengan sebagian besar Layanan AWS yang menawarkan enkripsi, dan Anda dapat menggunakan kunci KMS dalam aplikasi Anda yang memproses dan menyimpan data pribadi. Anda dapat menggunakan AWS KMS untuk membantu mendukung berbagai persyaratan privasi Anda dan melindungi data pribadi, termasuk:
-
Menggunakan kunci yang dikelola pelanggan untuk kontrol yang lebih besar atas kekuatan, rotasi, kedaluwarsa, dan opsi lainnya.
-
Menggunakan kunci terkelola pelanggan khusus untuk melindungi data pribadi dan rahasia yang memungkinkan akses ke data pribadi.
-
Mendefinisikan tingkat klasifikasi data dan menunjuk setidaknya satu kunci yang dikelola pelanggan khusus per level. Misalnya, Anda mungkin memiliki satu kunci untuk mengenkripsi data operasional dan yang lain untuk mengenkripsi data pribadi.
-
Mencegah akses lintas akun yang tidak diinginkan ke kunci KMS.
-
Menyimpan kunci KMS dalam Akun AWS sama dengan sumber daya yang akan dienkripsi.
-
Menerapkan pemisahan tugas untuk administrasi dan penggunaan kunci KMS. Untuk informasi selengkapnya, lihat Cara menggunakan KMS dan IAM untuk mengaktifkan kontrol keamanan independen untuk data terenkripsi di S3
(posting blog).AWS -
Menegakkan rotasi kunci otomatis melalui pagar pembatas preventif dan reaktif.
Secara default, kunci KMS disimpan dan hanya dapat digunakan di Wilayah tempat mereka dibuat. Jika organisasi Anda memiliki persyaratan khusus untuk residensi dan kedaulatan data, pertimbangkan apakah kunci KMS Multi-wilayah sesuai untuk kasus penggunaan Anda. Tombol Multi-Region adalah kunci KMS tujuan khusus yang berbeda Wilayah AWS yang dapat digunakan secara bergantian. Proses pembuatan kunci Multi-wilayah memindahkan materi utama Anda melintasi Wilayah AWS batas-batas di dalamnya AWS KMS, sehingga kurangnya isolasi regional ini mungkin tidak sesuai dengan tujuan kepatuhan organisasi Anda. Salah satu cara untuk mengatasinya adalah dengan menggunakan jenis kunci KMS yang berbeda, seperti kunci yang dikelola pelanggan khusus Wilayah.
AWS Local Zones
Jika Anda perlu mematuhi persyaratan residensi data, Anda dapat menyebarkan sumber daya yang menyimpan dan memproses data pribadi secara khusus Wilayah AWS untuk mendukung persyaratan ini. Anda juga dapat menggunakan AWS Local Zones, yang membantu Anda menempatkan komputasi, penyimpanan, database, dan AWS sumber daya pilihan lainnya yang dekat dengan populasi besar dan pusat industri. Zona Lokal adalah perpanjangan dari Wilayah AWS yang berada dalam kedekatan geografis dengan wilayah metropolitan yang besar. Anda dapat menempatkan jenis sumber daya tertentu dalam Zona Lokal, di dekat Wilayah yang sesuai dengan Zona Lokal. Local Zones dapat membantu Anda memenuhi persyaratan residensi data ketika suatu Wilayah tidak tersedia dalam yurisdiksi hukum yang sama. Saat Anda menggunakan Local Zones, pertimbangkan kontrol residensi data yang diterapkan dalam organisasi Anda. Misalnya, Anda mungkin memerlukan kontrol untuk mencegah transfer data dari Zona Lokal tertentu ke Wilayah lain. Untuk informasi selengkapnya tentang cara menggunakan SCPs untuk memelihara pagar pembatas transfer data lintas batas, lihat Praktik Terbaik untuk mengelola residensi data di Local Zones AWS menggunakan kontrol landing zone
AWS Enklaf Nitro
Pertimbangkan strategi segmentasi data Anda dari perspektif pemrosesan, seperti memproses data pribadi dengan layanan komputasi seperti Amazon Elastic Compute Cloud (Amazon). EC2 Komputasi rahasia sebagai bagian dari strategi arsitektur yang lebih besar dapat membantu Anda mengisolasi pemrosesan data pribadi dalam kantong CPU yang terisolasi, terlindungi, dan tepercaya. Enklave adalah mesin virtual yang terpisah, mengeras, dan sangat dibatasi. AWS Nitro Enclave adalah EC2 fitur Amazon yang dapat membantu Anda membuat lingkungan komputasi yang terisolasi ini. Untuk informasi selengkapnya, lihat Desain Keamanan Sistem AWS Nitro (AWS whitepaper).
Nitro Enclave menyebarkan kernel yang dipisahkan dari kernel instance induk. Kernel instance induk tidak memiliki akses ke enklave. Pengguna tidak dapat SSH atau mengakses data dan aplikasi dari jarak jauh di enclave. Aplikasi yang memproses data pribadi dapat disematkan di kantong dan dikonfigurasi untuk menggunakan Vsock enklave, soket yang memfasilitasi komunikasi antara enclave dan instance induk.
Salah satu kasus penggunaan di mana Nitro Enclave dapat berguna adalah pemrosesan bersama antara dua prosesor data yang terpisah Wilayah AWS dan yang mungkin tidak saling percaya. Gambar berikut menunjukkan bagaimana Anda dapat menggunakan enklaf untuk pemrosesan pusat, kunci KMS untuk mengenkripsi data pribadi sebelum dikirim ke enklaf, dan AWS KMS key kebijakan yang memverifikasi bahwa enklaf yang meminta dekripsi memiliki pengukuran unik dalam dokumen pengesahan. Untuk informasi dan petunjuk selengkapnya, lihat Menggunakan pengesahan kriptografi dengan. AWS KMS Untuk contoh kebijakan kunci, lihat Memerlukan pengesahan untuk menggunakan kunci AWS KMS di panduan ini.
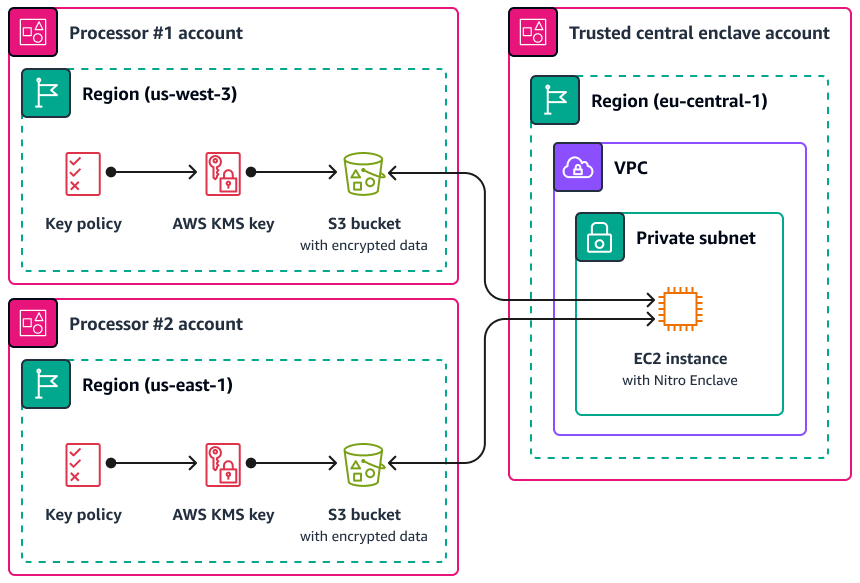
Dengan implementasi ini, hanya pengolah data masing-masing dan enklave yang mendasarinya yang memiliki akses ke data pribadi plaintext. Satu-satunya tempat data diekspos, di luar lingkungan masing-masing prosesor data, adalah di kantong itu sendiri, yang dirancang untuk mencegah akses dan gangguan.
AWS PrivateLink
Banyak organisasi ingin membatasi paparan data pribadi ke jaringan yang tidak tepercaya. Misalnya, jika Anda ingin meningkatkan privasi desain arsitektur aplikasi Anda secara keseluruhan, Anda dapat mengelompokkan jaringan berdasarkan sensitivitas data (mirip dengan pemisahan logis dan fisik kumpulan data yang dibahas di Layanan dan fitur AWS yang membantu mengelompokkan data bagian ini). AWS PrivateLinkmembantu Anda membuat koneksi pribadi searah dari cloud pribadi virtual Anda (VPCs) ke layanan di luar VPC. Dengan menggunakan AWS PrivateLink, Anda dapat mengatur koneksi pribadi khusus ke layanan yang menyimpan atau memproses data pribadi di lingkungan Anda; tidak perlu terhubung ke titik akhir publik dan mentransfer data ini melalui jaringan publik yang tidak tepercaya. Saat Anda mengaktifkan titik akhir AWS PrivateLink layanan untuk layanan dalam lingkup, tidak perlu gateway internet, perangkat NAT, alamat IP publik, AWS Direct Connect koneksi, atau AWS Site-to-Site VPN koneksi untuk berkomunikasi. Saat Anda menggunakan AWS PrivateLink untuk menyambung ke layanan yang menyediakan akses ke data pribadi, Anda dapat menggunakan kebijakan titik akhir VPC dan grup keamanan untuk mengontrol akses, sesuai dengan definisi perimeter data
AWS Resource Access Manager
AWS Resource Access Manager (AWS RAM) membantu Anda berbagi sumber daya dengan aman Akun AWS untuk mengurangi overhead operasional dan memberikan visibilitas dan auditabilitas. Saat Anda merencanakan strategi segmentasi multi-akun Anda, pertimbangkan AWS RAM untuk menggunakan untuk berbagi penyimpanan data pribadi yang Anda simpan di akun terpisah dan terisolasi. Anda dapat membagikan data pribadi tersebut dengan akun tepercaya lainnya untuk keperluan pemrosesan. Di AWS RAM, Anda dapat mengelola izin yang menentukan tindakan apa yang dapat dilakukan pada sumber daya bersama. Semua panggilan API ke AWS RAM login CloudTrail. Selain itu, Anda dapat mengonfigurasi CloudWatch Acara Amazon untuk memberi tahu Anda secara otomatis tentang peristiwa tertentu AWS RAM, seperti saat perubahan dilakukan pada pembagian sumber daya.
Meskipun Anda dapat berbagi banyak jenis AWS sumber daya dengan orang lain Akun AWS dengan menggunakan kebijakan berbasis sumber daya di IAM atau kebijakan bucket di Amazon S3, AWS RAM memberikan beberapa manfaat tambahan untuk privasi. AWS memberi pemilik data visibilitas tambahan tentang bagaimana dan dengan siapa data dibagikan di seluruh Anda Akun AWS, termasuk:
-
Mampu berbagi sumber daya dengan seluruh OU alih-alih memperbarui daftar akun secara manual IDs
-
Penegakan proses undangan untuk inisiasi berbagi jika akun konsumen bukan bagian dari organisasi Anda
-
Visibilitas ke mana prinsipal IAM tertentu memiliki akses ke setiap sumber daya individu
Jika sebelumnya Anda telah menggunakan kebijakan berbasis sumber daya untuk mengelola pembagian sumber daya dan ingin menggunakannya, AWS RAM gunakan operasi API. PromoteResourceShareCreatedFromPolicy
Amazon SageMaker AI
Amazon SageMaker AI adalah layanan pembelajaran mesin terkelola (ML) yang membantu Anda membuat dan melatih model ML, lalu menerapkannya ke lingkungan host yang siap produksi. SageMaker AI dirancang untuk mempermudah persiapan data pelatihan dan membuat fitur model.
Monitor Model SageMaker AI Amazon
Banyak organisasi mempertimbangkan penyimpangan data saat melatih model ML. Data drift adalah variasi yang berarti antara data produksi dan data yang digunakan untuk melatih model ML, atau perubahan yang berarti dalam data input dari waktu ke waktu. Penyimpangan data dapat mengurangi kualitas, akurasi, dan keadilan keseluruhan dalam prediksi model ML. Jika sifat statistik dari data yang diterima model ML dalam produksi menjauh dari sifat data dasar yang dilatihnya, keakuratan prediksi mungkin menurun. Amazon SageMaker AI Model Monitor dapat terus memantau kualitas model pembelajaran mesin Amazon SageMaker AI dalam produksi dan memantau kualitas data. Deteksi drift data secara dini dan proaktif dapat membantu Anda menerapkan tindakan korektif, seperti melatih ulang model, mengaudit sistem hulu, atau memperbaiki masalah kualitas data. Model Monitor dapat meringankan kebutuhan untuk memantau model secara manual atau membangun perkakas tambahan.
Amazon SageMaker AI Klarifikasi
Amazon SageMaker AI Clarify memberikan wawasan tentang bias model dan penjelasan. SageMaker AI Clarify biasanya digunakan selama persiapan data model ML dan fase pengembangan secara keseluruhan. Pengembang dapat menentukan atribut yang menarik, seperti jenis kelamin atau usia, dan SageMaker AI Clarify menjalankan serangkaian algoritme untuk mendeteksi adanya bias pada atribut tersebut. Setelah algoritme berjalan, SageMaker AI Clarify memberikan laporan visual dengan deskripsi sumber dan pengukuran kemungkinan bias sehingga Anda dapat mengidentifikasi langkah-langkah untuk memulihkan bias. Misalnya, dalam kumpulan data keuangan yang hanya berisi beberapa contoh pinjaman bisnis untuk satu kelompok umur dibandingkan dengan yang lain, SageMaker dapat menandai ketidakseimbangan sehingga Anda dapat menghindari model yang tidak menyukai kelompok usia tersebut. Anda juga dapat memeriksa model bias yang sudah terlatih dengan meninjau prediksinya dan dengan terus memantau model MLnya untuk bias. Terakhir, SageMaker AI Clarify terintegrasi dengan Amazon SageMaker AI Experiments untuk memberikan grafik yang menjelaskan fitur mana yang paling berkontribusi pada proses pembuatan prediksi model secara keseluruhan. Informasi ini dapat berguna untuk memenuhi hasil penjelasan, dan ini dapat membantu Anda menentukan apakah input model tertentu memiliki pengaruh lebih besar daripada yang seharusnya pada perilaku model secara keseluruhan.
Kartu SageMaker Model Amazon
Kartu SageMaker Model Amazon dapat membantu Anda mendokumentasikan detail penting tentang model ML Anda untuk tujuan tata kelola dan pelaporan. Rincian ini dapat mencakup pemilik model, tujuan umum, kasus penggunaan yang dimaksudkan, asumsi yang dibuat, peringkat risiko model, detail dan metrik pelatihan, dan hasil evaluasi. Untuk informasi lebih lanjut, lihat Model Explainability with AWS Artificial Intelligence and Machine Learning Solutions (AWS whitepaper).
AWS fitur yang membantu mengelola siklus hidup data
Ketika data pribadi tidak lagi diperlukan, Anda dapat menggunakan siklus hidup dan time-to-live kebijakan untuk data di banyak penyimpanan data yang berbeda. Saat mengonfigurasi kebijakan penyimpanan data, pertimbangkan lokasi berikut yang mungkin berisi data pribadi:
-
Database, seperti Amazon DynamoDB dan Amazon Relational Database Service (Amazon RDS)
-
Bucket Amazon S3
-
Log dari CloudWatch dan CloudTrail
-
Data cache dari migrasi di AWS Database Migration Service (AWS DMS) dan proyek AWS Glue DataBrew
-
Cadangan dan snapshot
Fitur Layanan AWS dan fitur berikut dapat membantu Anda mengonfigurasi kebijakan penyimpanan data di AWS lingkungan Anda:
-
Siklus Hidup Amazon S3 — Seperangkat aturan yang menentukan tindakan yang diterapkan Amazon S3 pada sekelompok objek. Dalam konfigurasi Amazon S3 Lifecyle, Anda dapat membuat tindakan kedaluwarsa, yang menentukan kapan Amazon S3 menghapus objek kedaluwarsa atas nama Anda. Untuk informasi selengkapnya, lihat Mengelola siklus hidup penyimpanan Anda.
-
Amazon Data Lifecycle Manager — Di Amazon EC2, buat kebijakan yang mengotomatiskan pembuatan, penyimpanan, dan penghapusan Amazon Elastic Block Store (Amazon EBS) snapshot dan Amazon Machine Images () yang didukung EBS (). AMIs
-
DynamoDB Time to Live (TTL) - Tentukan stempel waktu per item yang menentukan kapan item tidak lagi diperlukan. Tak lama setelah tanggal dan waktu stempel waktu yang ditentukan, DynamoDB menghapus item dari tabel Anda.
-
Pengaturan penyimpanan CloudWatch log di Log — Anda dapat menyesuaikan kebijakan penyimpanan untuk setiap grup log dengan nilai antara 1 hari dan 10 tahun.
-
AWS Backup— Terapkan kebijakan perlindungan data secara terpusat untuk mengonfigurasi, mengelola, dan mengatur aktivitas pencadangan Anda di berbagai AWS sumber daya, termasuk bucket S3, instance database RDS, tabel DynamoDB, volume EBS, dan banyak lagi. Terapkan kebijakan pencadangan ke AWS sumber daya Anda dengan menentukan jenis sumber daya atau memberikan perincian tambahan dengan menerapkan berdasarkan tag sumber daya yang ada. Audit dan laporkan aktivitas pencadangan dari konsol terpusat untuk membantu memenuhi persyaratan kepatuhan cadangan.
Layanan dan fitur AWS yang membantu mengelompokkan data
Segmentasi data adalah proses dimana Anda menyimpan data dalam wadah terpisah. Ini dapat membantu Anda memberikan langkah-langkah keamanan dan otentikasi yang berbeda untuk setiap kumpulan data dan untuk mengurangi cakupan dampak paparan untuk kumpulan data Anda secara keseluruhan. Misalnya, alih-alih menyimpan semua data pelanggan dalam satu database besar, Anda dapat mengelompokkan data ini menjadi grup yang lebih kecil dan lebih mudah dikelola.
Anda dapat menggunakan pemisahan fisik dan logis untuk mengelompokkan data pribadi:
-
Pemisahan fisik — Tindakan menyimpan data di penyimpanan data terpisah atau mendistribusikan data Anda ke AWS sumber daya yang terpisah. Meskipun data dipisahkan secara fisik, kedua sumber daya mungkin dapat diakses oleh prinsip yang sama. Inilah sebabnya mengapa kami merekomendasikan menggabungkan pemisahan fisik dengan pemisahan logis.
-
Pemisahan logis — Tindakan mengisolasi data dengan menggunakan kontrol akses. Fungsi pekerjaan yang berbeda memerlukan tingkat akses yang berbeda ke himpunan bagian data pribadi. Untuk contoh kebijakan yang menerapkan pemisahan logis, lihat Berikan akses ke atribut Amazon DynamoDB tertentu di panduan ini.
Kombinasi pemisahan logis dan fisik memberikan fleksibilitas, kesederhanaan, dan perincian saat menulis kebijakan berbasis identitas dan sumber daya untuk mendukung akses yang berbeda di seluruh fungsi pekerjaan. Misalnya, dapat menjadi kompleks secara operasional untuk membuat kebijakan yang secara logis memisahkan klasifikasi data yang berbeda dalam satu bucket S3. Menggunakan bucket S3 khusus untuk setiap klasifikasi data menyederhanakan konfigurasi dan manajemen kebijakan.
