Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Dati personali OU — Account dell'applicazione PD
Ci piacerebbe sentire la tua opinione. Fornisci un feedback sul AWS PRA rispondendo a un breve sondaggio |
L'account dell'applicazione per i dati personali (PD) è il luogo in cui la tua organizzazione ospita servizi che raccolgono ed elaborano dati personali. In particolare, potresti archiviare quelli che definisci come dati personali in questo account. Il AWS PRA illustra una serie di esempi di configurazioni di privacy attraverso un'architettura web serverless a più livelli. Quando si tratta di gestire carichi di lavoro in una AWS landing zone, le configurazioni di privacy non dovrebbero essere considerate one-size-fits-all soluzioni. Ad esempio, l'obiettivo potrebbe essere quello di comprendere i concetti di base, come possono migliorare la privacy e come l'organizzazione può applicare soluzioni a casi d'uso e architetture particolari.
Account AWS Nell'organizzazione che raccoglie, archivia o elabora dati personali, è possibile utilizzare AWS Organizations e AWS Control Tower implementare barriere di base e ripetibili. La creazione di un'unità organizzativa (OU) dedicata per questi account è fondamentale. Ad esempio, potresti voler applicare i limiti di residenza dei dati solo a un sottoinsieme di account in cui la residenza dei dati è una considerazione di progettazione fondamentale. Per molte organizzazioni, questi sono gli account che archiviano ed elaborano i dati personali.
La tua organizzazione potrebbe supportare un account Data dedicato, che è il luogo in cui archivi la fonte autorevole dei tuoi set di dati personali. Una fonte di dati autorevole è un luogo in cui è archiviata la versione principale dei dati, che potrebbe essere considerata la versione più affidabile e accurata dei dati. Ad esempio, puoi copiare i dati dalla fonte di dati autorevole in altre posizioni, come i bucket Amazon Simple Storage Service (Amazon S3) nell'account PD Application, utilizzati per archiviare dati di formazione, un sottoinsieme di dati dei clienti e dati oscurati. Adottando questo approccio multi-account per separare i set di dati personali completi e definitivi nell'account Data dai carichi di lavoro dei consumatori a valle nell'account PD Application, puoi ridurre l'ambito di impatto in caso di accesso non autorizzato ai tuoi account.
Il diagramma seguente illustra i servizi di AWS sicurezza e privacy configurati negli account PD Application and Data.
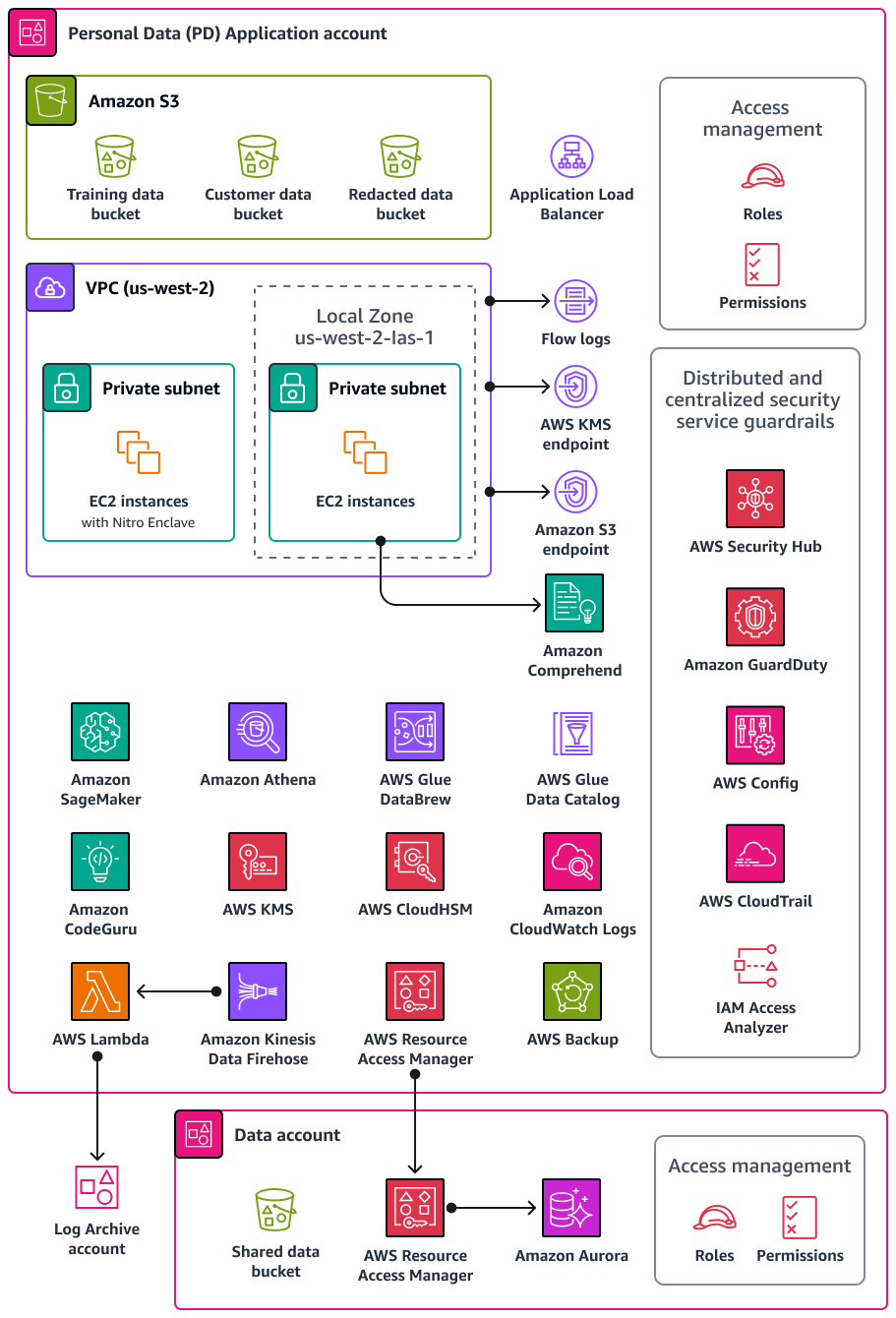
Questa sezione fornisce informazioni più dettagliate sui seguenti elementi Servizi AWS utilizzati in questi account:
Amazon Athena
Puoi anche prendere in considerazione i controlli di limitazione delle interrogazioni sui dati per raggiungere i tuoi obiettivi di privacy. Amazon Athena è un servizio di query interattivo che ti aiuta ad analizzare i dati direttamente in Amazon S3 utilizzando SQL standard. Non è necessario caricare i dati in Athena; funziona direttamente con i dati archiviati nei bucket S3.
Un caso d'uso comune per Athena è fornire ai team di analisi dei dati set di dati personalizzati e sanificati. Se i set di dati contengono dati personali, puoi disinfettare il set di dati mascherando intere colonne di dati personali che forniscono poco valore ai team di analisi dei dati. Per ulteriori informazioni, consulta Rendere anonimi e gestire i dati nel tuo data lake con Amazon Athena AWS Lake Formation
Se il tuo approccio alla trasformazione dei dati richiede una flessibilità aggiuntiva oltre alle funzioni supportate in Athena, puoi definire funzioni personalizzate, chiamate funzioni definite dall'utente (UDF). È possibile richiamarle UDFs in una query SQL inviata ad Athena ed eseguirle. AWS LambdaÈ possibile utilizzare UDFs le FILTER
SQL query SELECT e richiamarne più di una UDFs nella stessa query. Per motivi di privacy, è possibile creare UDFs sistemi che eseguano tipi specifici di mascheramento dei dati, ad esempio mostrando solo gli ultimi quattro caratteri di ogni valore in una colonna.
CloudWatch Registri Amazon
Amazon CloudWatch Logs ti aiuta a centralizzare i log di tutti i tuoi sistemi e applicazioni, Servizi AWS così puoi monitorarli e archiviarli in modo sicuro. In CloudWatch Logs, puoi utilizzare una politica di protezione dei dati per gruppi di log nuovi o esistenti per ridurre al minimo il rischio di divulgazione di dati personali. Le politiche di protezione dei dati possono rilevare dati sensibili, come i dati personali, nei registri. La politica di protezione dei dati può mascherare tali dati quando gli utenti accedono ai registri tramite. AWS Management Console Quando gli utenti richiedono l'accesso diretto ai dati personali, in base alle specifiche generali dello scopo del carico di lavoro, è possibile assegnare logs:Unmask le autorizzazioni a tali utenti. Puoi anche creare una politica di protezione dei dati a livello di account e applicarla in modo coerente a tutti gli account della tua organizzazione. Questo configura il mascheramento per impostazione predefinita per tutti i gruppi di log attuali e futuri in CloudWatch Logs. Ti consigliamo inoltre di abilitare i report di controllo e di inviarli a un altro gruppo di log, a un bucket Amazon S3 o Amazon Data Firehose. Questi report contengono un registro dettagliato dei risultati sulla protezione dei dati in ogni gruppo di log.
CodeGuru Revisore Amazon
Sia per la privacy che per la sicurezza, è fondamentale per molte organizzazioni supportare la conformità continua durante le fasi di implementazione e post-implementazione. Il AWS PRA include controlli proattivi nelle pipeline di implementazione per le applicazioni che elaborano dati personali. Amazon CodeGuru Reviewer è in grado di rilevare potenziali difetti che potrebbero esporre i dati personali nel codice Java e Python. JavaScript Offre suggerimenti agli sviluppatori per migliorare il codice. CodeGuru Reviewer è in grado di identificare i difetti relativi a un'ampia gamma di procedure consigliate in materia di sicurezza, privacy e generali. Per ulteriori informazioni, consulta Amazon CodeGuru Detector Library. È progettato per funzionare con più provider di sorgenti AWS CodeCommit, tra cui Bitbucket e Amazon GitHub S3. Alcuni dei difetti relativi alla privacy che Reviewer è in grado di rilevare includono: CodeGuru
-
iniezione SQL
-
Cookie non protetti
-
Autorizzazione mancante
-
Ricrittografia lato client AWS KMS
Amazon Comprehend
Amazon Comprehend è un servizio di elaborazione del linguaggio naturale (NLP) che utilizza l'apprendimento automatico per scoprire informazioni e connessioni preziose nei documenti di testo in inglese. Amazon Comprehend è in grado di rilevare e redigere dati personali in documenti di testo strutturati, semistrutturati o non strutturati. Per ulteriori informazioni, consulta Informazioni di identificazione personale (PII) nella documentazione di Amazon Comprehend.
Puoi utilizzare l'API AWS SDKs e Amazon Comprehend per integrare Amazon Comprehend con molte applicazioni. Un esempio è l'utilizzo di Amazon Comprehend per rilevare e redigere dati personali con Amazon S3 Object Lambda. Le organizzazioni possono utilizzare S3 Object Lambda per aggiungere codice personalizzato alle richieste Amazon S3 GET per modificare ed elaborare i dati non appena vengono restituiti a un'applicazione. S3 Object Lambda può filtrare le righe, ridimensionare dinamicamente le immagini, oscurare i dati personali e altro ancora. Basato sulle AWS Lambda funzioni, il codice viene eseguito su un'infrastruttura completamente gestita da AWS, il che elimina la necessità di creare e archiviare copie derivate dei dati o di eseguire proxy. Non è necessario modificare le applicazioni per trasformare gli oggetti con S3 Object Lambda. Puoi utilizzare la funzione ComprehendPiiRedactionS3Object Lambda per AWS Serverless Application Repository oscurare i dati personali. Questa funzione utilizza Amazon Comprehend per rilevare le entità di dati personali e oscura tali entità sostituendole con asterischi. Per ulteriori informazioni, consulta Rilevamento e redazione dei dati PII con S3 Object Lambda e Amazon Comprehend nella documentazione di Amazon S3.
Poiché Amazon Comprehend offre molte opzioni per l'integrazione delle applicazioni tramite AWS SDKs, puoi utilizzare Amazon Comprehend per identificare i dati personali in molti luoghi diversi in cui li raccogli, archivia ed elabora. Puoi utilizzare le funzionalità di Amazon Comprehend ML per rilevare e redigere i dati personali nei log delle applicazioni
-
REPLACE_WITH_PII_ENTITY_TYPEsostituisce ogni entità PII con i relativi tipi. Ad esempio, Jane Doe verrebbe sostituita da NAME. -
MASKsostituisce i caratteri delle entità PII con un carattere a tua scelta (! , #, $,%, &, o @). Ad esempio, Jane Doe potrebbe essere sostituita con **** ***.
Amazon Data Firehose
Amazon Data Firehose può essere utilizzato per acquisire, trasformare e caricare dati di streaming in servizi downstream, come Amazon Managed Service per Apache Flink o Amazon S3. Firehose viene spesso utilizzato per trasportare grandi quantità di dati in streaming, come i log delle applicazioni, senza dover creare pipeline di elaborazione da zero.
È possibile utilizzare le funzioni Lambda per eseguire elaborazioni personalizzate o integrate prima che i dati vengano inviati a valle. Per quanto riguarda la privacy, questa funzionalità supporta la riduzione al minimo dei dati e i requisiti di trasferimento transfrontaliero dei dati. Ad esempio, è possibile utilizzare Lambda e Firehose per trasformare i dati di registro multiregione prima che siano centralizzati nell'account Log Archive. Per ulteriori informazioni, vedete Biogen: soluzione di registrazione centralizzata per più account (video
AWS Glue
La manutenzione dei set di dati che contengono dati personali è un componente chiave di Privacy by Design
AWS Glue Data Catalog
AWS Glue Data Catalogti aiuta a stabilire set di dati gestibili. Il Data Catalog contiene riferimenti ai dati utilizzati come fonti e destinazioni per i processi di estrazione, trasformazione e caricamento (ETL). AWS Glue Le informazioni nel Data Catalog vengono archiviate come tabelle di metadati e ogni tabella specifica un singolo archivio dati. Esegui un AWS Glue
crawler per fare l'inventario dei dati in una varietà di tipi di data store. Si aggiungono classificatori incorporati e personalizzati al crawler e questi classificatori deducono il formato e lo schema dei dati personali. Il crawler scrive quindi i metadati nel Data Catalog. Una tabella di metadati centralizzata può semplificare la risposta alle richieste degli interessati (ad esempio il diritto alla cancellazione) perché aggiunge struttura e prevedibilità tra le diverse fonti di dati personali presenti nell'ambiente. AWS Per un esempio completo di come utilizzare Data Catalog per rispondere automaticamente a queste richieste, consulta Gestione delle richieste di cancellazione dei dati nel tuo data lake con Amazon S3 Find and
AWS Glue DataBrew
AWS Glue DataBrewti aiuta a pulire e normalizzare i dati e può eseguire trasformazioni sui dati, come rimuovere o mascherare le informazioni di identificazione personale e crittografare i campi di dati sensibili nelle pipeline di dati. Puoi anche mappare visivamente la provenienza dei tuoi dati per comprendere le varie fonti di dati e le fasi di trasformazione che i dati hanno subito. Questa funzionalità diventa sempre più importante man mano che l'organizzazione lavora per comprendere e tracciare meglio la provenienza dei dati personali. DataBrew ti aiuta a mascherare i dati personali durante la preparazione dei dati. È possibile rilevare i dati personali nell'ambito di un processo di profilazione dei dati e raccogliere statistiche, come il numero di colonne che potrebbero contenere dati personali e potenziali categorie. È quindi possibile utilizzare le tecniche integrate di trasformazione dei dati reversibili o irreversibili, tra cui la sostituzione, l'hashing, la crittografia e la decrittografia, il tutto senza scrivere alcun codice. È quindi possibile utilizzare i set di dati puliti e mascherati a valle per attività di analisi, reportistica e apprendimento automatico. Alcune delle tecniche di mascheramento dei dati disponibili includono: DataBrew
-
Hashing: applica le funzioni di hash ai valori delle colonne.
-
Sostituzione: sostituisci i dati personali con altri valori dall'aspetto autentico.
-
Annullamento o eliminazione: sostituisci un campo particolare con un valore nullo o elimina la colonna.
-
Mascheratura: usa il rimescolamento dei caratteri o maschera determinate parti delle colonne.
Le seguenti sono le tecniche di crittografia disponibili:
-
Crittografia deterministica: applica algoritmi di crittografia deterministica ai valori delle colonne. La crittografia deterministica produce sempre lo stesso testo cifrato per un valore.
-
Crittografia probabilistica: applica algoritmi di crittografia probabilistica ai valori delle colonne. La crittografia probabilistica produce un testo cifrato diverso ogni volta che viene applicata.
Per un elenco completo delle ricette di trasformazione dei dati personali fornite in DataBrew, consulta Procedure introduttive relative alle informazioni di identificazione personale (PII).
AWS Glue Qualità dei dati
AWS Glue Data Quality ti aiuta ad automatizzare e rendere operativa la distribuzione di dati di alta qualità attraverso le pipeline di dati, in modo proattivo, prima che vengano consegnati ai tuoi consumatori di dati. AWS Glue Data Quality fornisce un'analisi statistica dei problemi di qualità dei dati nelle tue pipeline di dati, può attivare avvisi in Amazon EventBridge e può formulare raccomandazioni sulle regole di qualità per la correzione. AWS Glue Data Quality supporta anche la creazione di regole con un linguaggio specifico del dominio in modo da poter creare regole di qualità dei dati personalizzate.
AWS Key Management Service
AWS Key Management Service (AWS KMS) consente di creare e controllare chiavi crittografiche per proteggere i dati. AWS KMS utilizza moduli di sicurezza hardware per proteggere e convalidare AWS KMS keys nell'ambito del programma di convalida dei moduli crittografici FIPS 140-2. Per ulteriori informazioni su come questo servizio viene utilizzato in un contesto di sicurezza, vedere Security Reference Architecture.AWS
AWS KMS si integra con la maggior parte delle aziende Servizi AWS che offrono la crittografia e consente di utilizzare le chiavi KMS nelle applicazioni che elaborano e archiviano dati personali. Puoi utilizzarle AWS KMS per supportare una serie di requisiti di privacy e salvaguardare i dati personali, tra cui:
-
Utilizzo di chiavi gestite dal cliente per un maggiore controllo su forza, rotazione, scadenza e altre opzioni.
-
Utilizzo di chiavi dedicate gestite dal cliente per proteggere i dati personali e i segreti che consentono l'accesso ai dati personali.
-
Definizione dei livelli di classificazione dei dati e designazione di almeno una chiave dedicata gestita dal cliente per livello. Ad esempio, potresti avere una chiave per crittografare i dati operativi e un'altra per crittografare i dati personali.
-
Impedire l'accesso involontario tra account alle chiavi KMS.
-
Archiviazione delle chiavi KMS all'interno della Account AWS stessa risorsa da crittografare.
-
Implementazione della separazione dei compiti per l'amministrazione e l'utilizzo delle chiavi KMS. Per ulteriori informazioni, consulta Come usare KMS e IAM per abilitare controlli di sicurezza indipendenti per i dati crittografati in S3
(AWS post del blog). -
Imposizione della rotazione automatica delle chiavi attraverso barriere preventive e reattive.
Per impostazione predefinita, le chiavi KMS vengono archiviate e possono essere utilizzate solo nella regione in cui sono state create. Se la tua organizzazione ha requisiti specifici per la residenza e la sovranità dei dati, valuta se le chiavi KMS multiregionali sono appropriate per il tuo caso d'uso. Le chiavi multiregionali sono chiavi KMS per scopi speciali, diverse tra loro, che possono essere utilizzate in modo intercambiabile. Regioni AWS Il processo di creazione di una chiave multiregionale sposta il materiale chiave oltre Regione AWS i confini interni AWS KMS, quindi questa mancanza di isolamento regionale potrebbe non essere compatibile con gli obiettivi di conformità dell'organizzazione. Un modo per risolvere questo problema consiste nell'utilizzare un tipo diverso di chiave KMS, ad esempio una chiave gestita dal cliente specifica per regione.
AWS Local Zones
Se è necessario rispettare i requisiti di residenza dei dati, è possibile implementare risorse che archiviano ed elaborano i dati personali specificamente Regioni AWS per supportare tali requisiti. Puoi anche utilizzare AWS Local Zones, che ti aiuta a collocare risorse di elaborazione, storage, database e altre AWS risorse selezionate vicino a grandi centri abitati e industriali. Una zona locale è un'estensione di una zona Regione AWS che si trova in prossimità geografica di una grande area metropolitana. È possibile collocare tipi specifici di risorse all'interno di una zona locale, vicino alla regione a cui corrisponde la zona locale. Le Local Zones possono aiutarti a soddisfare i requisiti di residenza dei dati quando una regione non è disponibile all'interno della stessa giurisdizione legale. Quando utilizzi Local Zones, prendi in considerazione i controlli di residenza dei dati implementati all'interno della tua organizzazione. Ad esempio, potrebbe essere necessario un controllo per impedire il trasferimento di dati da una zona locale specifica a un'altra regione. Per ulteriori informazioni su come utilizzare per mantenere le barriere SCPs per il trasferimento transfrontaliero dei dati, consulta Best Practices for managing data residency in Local Zones AWS using landing zone control
AWS Enclavi Nitro
Considera la tua strategia di segmentazione dei dati dal punto di vista dell'elaborazione, ad esempio l'elaborazione dei dati personali con un servizio di elaborazione come Amazon Elastic Compute Cloud (Amazon). EC2 L'elaborazione riservata come parte di una strategia di architettura più ampia può aiutarti a isolare l'elaborazione dei dati personali in un'enclave di CPU isolata, protetta e affidabile. Le enclavi sono macchine virtuali separate, rinforzate e altamente vincolate. AWS Nitro Enclaves è una EC2 funzionalità di Amazon che può aiutarti a creare questi ambienti di elaborazione isolati. Per ulteriori informazioni, consulta The Security Design of the AWS Nitro System (white paper).AWS
Nitro Enclaves distribuisce un kernel separato dal kernel dell'istanza principale. Il kernel dell'istanza principale non ha accesso all'enclave. Gli utenti non possono utilizzare SSH o accedere in remoto ai dati e alle applicazioni nell'enclave. Le applicazioni che elaborano dati personali possono essere incorporate nell'enclave e configurate per utilizzare il Vsock dell'enclave, il socket che facilita la comunicazione tra l'enclave e l'istanza principale.
Un caso d'uso in cui Nitro Enclaves può essere utile è l'elaborazione congiunta tra due processori di dati separati e che potrebbero non fidarsi l'uno dell'altro. Regioni AWS L'immagine seguente mostra come utilizzare un'enclave per l'elaborazione centralizzata, una chiave KMS per crittografare i dati personali prima che vengano inviati all'enclave e una AWS KMS key politica che verifica che l'enclave che richiede la decrittografia abbia le misure uniche nel documento di attestazione. Per AWS KMS ulteriori informazioni e istruzioni, consulta Utilizzo dell'attestazione crittografica con. Per un esempio di policy chiave, consulta questa Richiedi l'attestazione per utilizzare una chiave AWS KMS guida.
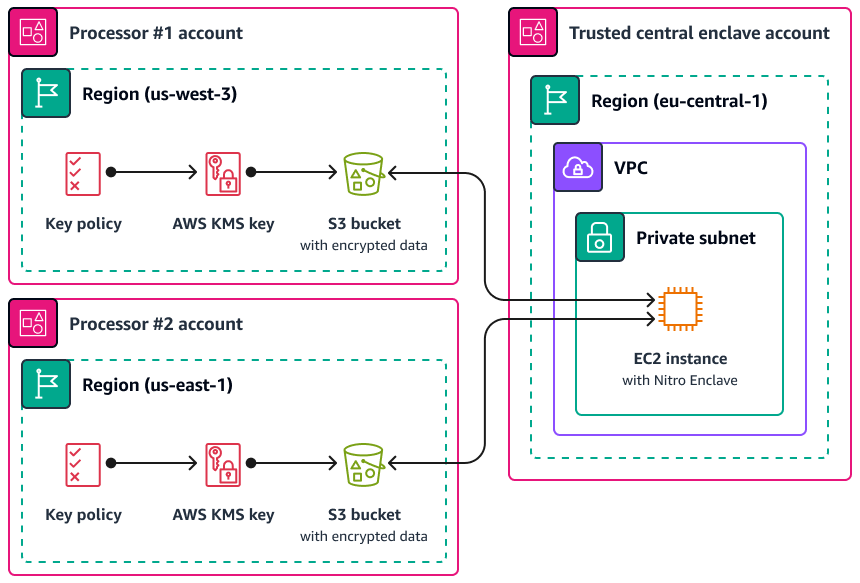
Con questa implementazione, solo i rispettivi processori di dati e l'enclave sottostante hanno accesso ai dati personali in chiaro. L'unico luogo in cui i dati sono esposti, al di fuori degli ambienti dei rispettivi processori di dati, è nell'enclave stessa, progettata per impedire l'accesso e la manomissione.
AWS PrivateLink
Molte organizzazioni vogliono limitare l'esposizione dei dati personali a reti non affidabili. Ad esempio, se si desidera migliorare la privacy della progettazione complessiva dell'architettura applicativa, è possibile segmentare le reti in base alla sensibilità dei dati (in modo analogo alla separazione logica e fisica dei set di dati descritta nella Servizi e funzionalità AWS che aiutano a segmentare i dati sezione). AWS PrivateLinkti aiuta a creare connessioni private unidirezionali dai tuoi cloud privati virtuali (VPCs) a servizi esterni al VPC. Utilizzando AWS PrivateLink, è possibile configurare connessioni private dedicate ai servizi che archiviano o elaborano dati personali nel proprio ambiente; non è necessario connettersi a endpoint pubblici e trasferire questi dati su reti pubbliche non affidabili. Quando si abilitano gli endpoint di AWS PrivateLink servizio per i servizi inclusi, non è necessario un gateway Internet, un dispositivo NAT, un indirizzo IP pubblico, una connessione o AWS Direct Connect AWS Site-to-Site VPN una connessione per comunicare. Quando si utilizza AWS PrivateLink per connettersi a un servizio che fornisce l'accesso ai dati personali, è possibile utilizzare le policy degli endpoint VPC e i gruppi di sicurezza per controllare l'accesso, in base alla definizione del perimetro dei dati
AWS Resource Access Manager
AWS Resource Access Manager (AWS RAM) ti aiuta a condividere in modo sicuro le tue risorse Account AWS per ridurre il sovraccarico operativo e fornire visibilità e verificabilità. Mentre pianifichi la tua strategia di segmentazione multi-account, valuta la possibilità di AWS RAM condividere gli archivi di dati personali archiviati in un account separato e isolato. Puoi condividere tali dati personali con altri account affidabili ai fini del trattamento. In AWS RAM, puoi gestire le autorizzazioni che definiscono quali azioni possono essere eseguite su risorse condivise. Tutte le chiamate API a AWS RAM sono registrate. CloudTrail Inoltre, puoi configurare Amazon CloudWatch Events in modo che ti invii automaticamente notifiche per eventi specifici in AWS RAM, ad esempio quando vengono apportate modifiche a una condivisione di risorse.
Sebbene sia possibile condividere molti tipi di AWS risorse con altri utenti Account AWS utilizzando policy basate su risorse in IAM o bucket policy in Amazon S3, AWS RAM offre diversi vantaggi aggiuntivi per la privacy. AWS offre ai proprietari dei dati una visibilità aggiuntiva su come e con chi i dati vengono condivisi tra di loro, tra cui: Account AWS
-
Poter condividere una risorsa con un'intera unità organizzativa anziché aggiornare manualmente gli elenchi di account IDs
-
Applicazione della procedura di invito per l'avvio della condivisione se l'account consumatore non fa parte dell'organizzazione
-
Visibilità su quali responsabili IAM specifici hanno accesso a ogni singola risorsa
Se in precedenza hai utilizzato una policy basata sulle risorse per gestire una condivisione di risorse e desideri utilizzarla al suo AWS RAM posto, utilizza l'operazione API. PromoteResourceShareCreatedFromPolicy
Amazon SageMaker AI
Amazon SageMaker AI è un servizio di machine learning (ML) gestito che ti aiuta a creare e addestrare modelli di machine learning per poi distribuirli in un ambiente ospitato pronto per la produzione. SageMaker L'intelligenza artificiale è progettata per semplificare la preparazione dei dati di addestramento e la creazione di funzionalità del modello.
Monitoraggio del modello Amazon SageMaker AI
Molte organizzazioni considerano la deriva dei dati durante l'addestramento dei modelli di machine learning. La deriva dei dati è una variazione significativa tra i dati di produzione e i dati utilizzati per addestrare un modello di machine learning o una modifica significativa dei dati di input nel tempo. La deriva dei dati può ridurre la qualità, l'accuratezza e l'equità complessive nelle previsioni dei modelli di machine learning. Se la natura statistica dei dati che un modello di machine learning riceve durante la produzione si discosta dalla natura dei dati di base su cui è stato addestrato, l'accuratezza delle previsioni potrebbe diminuire. Amazon SageMaker AI Model Monitor può monitorare continuamente la qualità dei modelli di machine learning di Amazon SageMaker AI in produzione e monitorare la qualità dei dati. Il rilevamento precoce e proattivo della deriva dei dati può aiutarti a implementare azioni correttive, come la riqualificazione dei modelli, il controllo dei sistemi a monte o la risoluzione di problemi di qualità dei dati. Model Monitor può ridurre la necessità di monitorare manualmente i modelli o creare strumenti aggiuntivi.
Amazon SageMaker AI Clarify
Amazon SageMaker AI Clarify fornisce informazioni sulla distorsione e sulla spiegabilità del modello. SageMaker AI Clarify è comunemente usato durante la preparazione dei dati dei modelli ML e la fase di sviluppo generale. Gli sviluppatori possono specificare gli attributi di interesse, come il sesso o l'età, e SageMaker AI Clarify esegue una serie di algoritmi per rilevare qualsiasi presenza di distorsioni in tali attributi. Dopo l'esecuzione dell'algoritmo, SageMaker AI Clarify fornisce un report visivo con una descrizione delle fonti e delle misurazioni dei possibili pregiudizi in modo da poter identificare i passaggi per rimediare al pregiudizio. Ad esempio, in un set di dati finanziari che contiene solo alcuni esempi di prestiti commerciali concessi a una fascia di età rispetto ad altre, è SageMaker possibile segnalare gli squilibri in modo da evitare un modello che sfavorisce quella fascia di età. È inoltre possibile verificare la presenza di pregiudizi nei modelli già addestrati esaminandone le previsioni e monitorando continuamente l'eventuale presenza di pregiudizi nei modelli di machine learning. Infine, SageMaker AI Clarify è integrato con Amazon SageMaker AI Experiments per fornire un grafico che spiega quali funzionalità hanno contribuito maggiormente al processo di previsione complessivo di un modello. Queste informazioni potrebbero essere utili per raggiungere i risultati di spiegabilità e potrebbero aiutarti a determinare se un particolare input del modello ha più influenza di quanto dovrebbe sul comportamento generale del modello.
SageMaker Scheda modello Amazon
Amazon SageMaker Model Card può aiutarti a documentare dettagli critici sui tuoi modelli di machine learning per scopi di governance e reporting. Questi dettagli possono includere il proprietario del modello, lo scopo generale, i casi d'uso previsti, le ipotesi formulate, la valutazione del rischio di un modello, i dettagli e le metriche della formazione e i risultati della valutazione. Per ulteriori informazioni, vedere Model Explainability with AWS Artificial Intelligence and Machine Learning Solutions (AWS white paper).
AWS funzionalità che aiutano a gestire il ciclo di vita dei dati
Quando i dati personali non sono più necessari, puoi utilizzare il ciclo di vita e le time-to-live policy per i dati in molti archivi di dati diversi. Quando configuri le politiche di conservazione dei dati, considera le seguenti posizioni che potrebbero contenere dati personali:
-
Database, come Amazon DynamoDB e Amazon Relational Database Service (Amazon RDS)
-
Bucket Amazon S3
-
Registri da e CloudWatch CloudTrail
-
Dati memorizzati nella cache provenienti da migrazioni in AWS Database Migration Service ()AWS DMS e progetti AWS Glue DataBrew
-
Backup e istantanee
Le seguenti Servizi AWS funzionalità possono aiutarti a configurare le politiche di conservazione dei dati nei tuoi AWS ambienti:
-
Ciclo di vita di Amazon S3: un insieme di regole che definiscono le azioni che Amazon S3 applica a un gruppo di oggetti. Nella configurazione Amazon S3 Lifecyle, puoi creare azioni di scadenza, che definiscono quando Amazon S3 elimina gli oggetti scaduti per tuo conto. Per ulteriori informazioni, consulta Gestione del ciclo di vita dell’archiviazione.
-
Amazon Data Lifecycle Manager: in Amazon EC2, crea una policy che automatizzi la creazione, la conservazione e l'eliminazione di snapshot di Amazon Elastic Block Store (Amazon EBS) e Amazon Machine Images () supportate da EBS. AMIs
-
DynamoDB Time to Live (TTL): definisce un timestamp per elemento che determina quando un elemento non è più necessario. Poco dopo la data e l'ora del timestamp specificato, DynamoDB elimina l'elemento dalla tabella.
-
Impostazioni di conservazione dei log nei CloudWatch log: è possibile regolare la politica di conservazione per ogni gruppo di log su un valore compreso tra 1 giorno e 10 anni.
-
AWS Backup— Implementazione centralizzata di policy di protezione dei dati per configurare, gestire e governare l'attività di backup su una varietà di AWS risorse, tra cui bucket S3, istanze di database RDS, tabelle DynamoDB, volumi EBS e molte altre. Applica le policy di backup alle tue AWS risorse specificando i tipi di risorse o fornisci ulteriore granularità applicando in base ai tag di risorsa esistenti. Verifica e crea report sulle attività di backup da una console centralizzata per contribuire a soddisfare i requisiti di conformità del backup.
Servizi e funzionalità AWS che aiutano a segmentare i dati
La segmentazione dei dati è il processo mediante il quale si archiviano i dati in contenitori separati. Questo può aiutarvi a fornire misure di sicurezza e autenticazione differenziate per ogni set di dati e a ridurre l'ambito di impatto dell'esposizione per l'intero set di dati. Ad esempio, anziché archiviare tutti i dati dei clienti in un unico database di grandi dimensioni, è possibile segmentarli in gruppi più piccoli e più gestibili.
Puoi utilizzare la separazione fisica e logica per segmentare i dati personali:
-
Separazione fisica: l'atto di archiviare i dati in archivi di dati separati o di distribuirli in AWS risorse separate. Sebbene i dati siano fisicamente separati, entrambe le risorse potrebbero essere accessibili agli stessi responsabili. Questo è il motivo per cui consigliamo di combinare la separazione fisica con la separazione logica.
-
Separazione logica: l'atto di isolare i dati utilizzando i controlli di accesso. Diverse funzioni lavorative richiedono diversi livelli di accesso a sottoinsiemi di dati personali. Per un esempio di policy che implementa la separazione logica, consulta questa Concedi l'accesso a specifici attributi di Amazon DynamoDB guida.
La combinazione di separazione logica e fisica offre flessibilità, semplicità e granularità nella stesura di politiche basate sull'identità e sulle risorse per supportare l'accesso differenziato tra le funzioni lavorative. Ad esempio, può essere complesso dal punto di vista operativo creare le policy che separano logicamente diverse classificazioni dei dati in un unico bucket S3. L'utilizzo di bucket S3 dedicati per ogni classificazione dei dati semplifica la configurazione e la gestione delle policy.
