翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
個人データ OU – PD アプリケーションアカウント
アンケート
皆様からのご意見をお待ちしています。簡単なアンケート
個人データ (PD) アプリケーションアカウントは、組織が個人データを収集および処理するサービスをホストする場所です。具体的には、個人データとして定義したものをこのアカウントに保存できます。 AWS PRA は、多層サーバーレスウェブアーキテクチャによるプライバシー設定の例を多数示しています。 AWS ランディングゾーン全体でワークロードを運用する場合、プライバシー設定をone-size-fits-allソリューションと見なすべきではありません。例えば、基礎となる概念、プライバシーを強化する方法、組織が特定のユースケースやアーキテクチャにソリューションを適用できる方法を理解することが目的の場合があります。
個人データを収集、保存、または処理する組織 AWS アカウント 内の では、 AWS Organizations と を使用して、基盤となる反復可能なガードレール AWS Control Tower をデプロイできます。これらのアカウント専用の組織単位 (OU) を確立することが重要です。例えば、データレジデンシーガードレールを、データレジデンシーが設計上の重要な考慮事項であるアカウントのサブセットにのみ適用する必要が生じる場合があります。多くの組織では、これらは個人データを保存および処理するアカウントです。
組織は、個人用データセットの信頼できるソースを保存する専用のデータアカウントのサポートを検討する場合があります。信頼できるデータソースは、データのプライマリバージョンを保存する場所であり、データの最も信頼性が高く正確なバージョンと見なされる可能性があります。例えば、信頼できるデータソースから、トレーニングデータ、顧客データのサブセット、秘匿化データの保存に使用される PD アプリケーションアカウントの Amazon Simple Storage Service (Amazon S3) バケットなどの他の場所にデータをコピーできます。このマルチアカウントアプローチを使用して、データアカウントの完全かつ最終的な個人データセットを PD アプリケーションアカウントのダウンストリームコンシューマーワークロードから分離することで、アカウントへの不正アクセスが発生した場合の影響範囲を減らすことができます。
次の図は、PD アプリケーションアカウントとデータアカウントで設定されている AWS セキュリティサービスとプライバシーサービスを示しています。
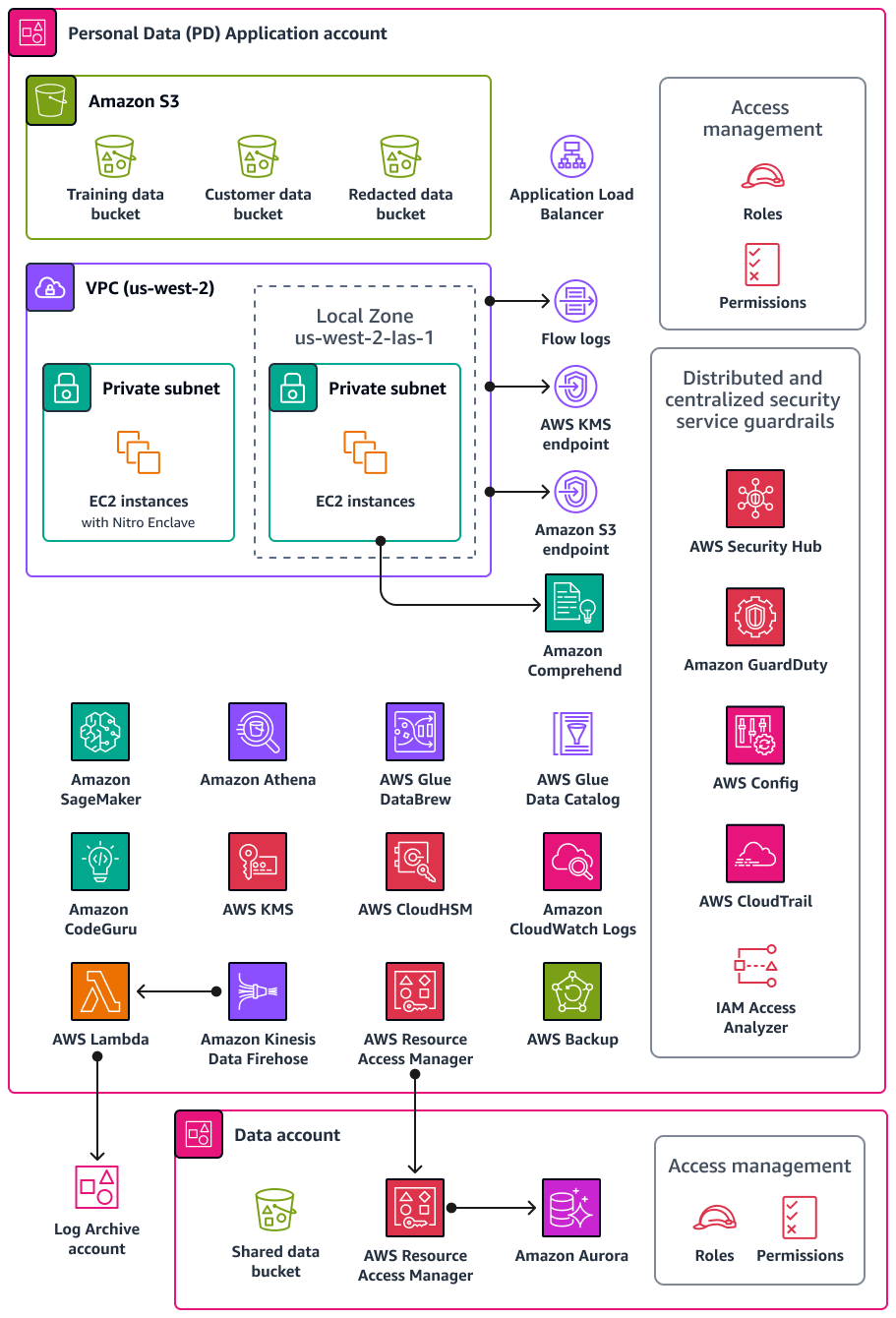
このセクションでは、以下のアカウントで使用される以下の AWS のサービス に関する詳細情報について説明します。
Amazon Athena
プライバシー目標を達成するために、データクエリ制限の制御について検討できます。Amazon Athena は、標準 SQL を使用して Amazon S3 でデータを直接分析するのに役立つ対話型のクエリサービスです。Athena にデータをロードする必要はありません。S3 バケットに保存されているデータと直接連携します。
Athena の一般的なユースケースは、データ分析チームに、カスタマイズされサニタイズされたデータセットを提供することです。データセットに個人データが含まれている場合は、データ分析チームにとってほとんど価値のない個人データの列全体をマスクすることで、データセットをサニタイズできます。詳細については、Amazon Athena によるデータレイク内のデータの匿名化と管理 AWS Lake Formation
データ変換アプローチで、Athena でサポートされている関数以外の柔軟性が追加で必要になった場合は、ユーザー定義関数 (UDF) と呼ばれるカスタム関数を定義できます。Athena に送信された SQL クエリで UDF を呼び出すことができ、 AWS Lambdaで実行されます。SELECT および FILTER
SQL クエリで UDF を使用し、同じクエリで複数の UDF を呼び出すことができます。プライバシーのために、列内のすべての値の末尾 4 文字のみを表示するなど、特殊なデータマスキングを実行する UDF を作成できます。
Amazon Bedrock
Amazon Bedrock は、AI21 Labs、Anthropic、Meta、Mistral AI、Amazon など主要な AI 企業からの基盤モデルへのアクセスを提供するフルマネージドサービスです。これは、組織が生成 AI アプリケーションを構築およびスケールするのに役立ちます。どのプラットフォームが使用されていても、生成 AI を使用すると、組織は個人データ漏洩の可能性、不正なデータアクセス、その他のコンプライアンス違反などのプライバシー関連のリスクにさらされる可能性があります。
Amazon Bedrock ガードレールは、Amazon Bedrock の生成 AI ワークロード全体にセキュリティとコンプライアンスのベストプラクティスを適用することで、これらのリスクを軽減するように設計されています。AI リソースのデプロイと使用は、必ずしも組織のプライバシー要件とコンプライアンス要件に合致するとは限りません。組織は生成 AI モデルを使用する際にデータプライバシーの維持に苦労する可能性があります。これは、これらのモデルが機密情報を記憶または再現する可能性があるためです。Amazon Bedrock ガードレールは、ユーザー入力とモデルレスポンスを評価することでプライバシーを保護することができます。全体として、入力データに個人データが含まれている場合、この情報がモデルの出力で公開されるリスクがあります。
Amazon Bedrock ガードレールは、データ保護ポリシーを適用し、不正なデータ漏洩を防ぐメカニズムを提供します。入力内の個人データを検出してブロックするコンテンツフィルタリング機能、不適切またはリスクのある対象領域へのアクセスを防ぐためのトピック制限、モデルプロンプトとレスポンスの機密用語をマスクまたは編集するワードフィルターを提供します。これらの機能は、バイアスのかかったレスポンスや顧客の信頼低下など、プライバシー違反につながる可能性のあるイベントを防止するのに役立ちます。これらの機能により、個人データが AI モデルによって誤って処理または開示されないようにできます。Amazon Bedrock ガードレールでは、Amazon Bedrock 以外での入力とレスポンスの評価についてもサポートしています。詳細については、「Implement model-independent safety measures with Amazon Bedrock Guardrails
Amazon Bedrock ガードレールでは、根拠とレスポンスの関連性を評価するコンテキストグラウンディングチェックを使用して、モデルハルシネーションのリスクを制限できます。例えば、検索拡張生成 (RAG)
AWS Clean Rooms
組織は、機密性の高いデータセットを交差または重複させる分析を通じて相互に連携させる方法を模索しているため、その共有データのセキュリティとプライバシーを維持することが懸念事項となります。AWS Clean Rooms によって、組織が未加工データ自体を共有するのではなく、結合されたデータセットを分析できる安全で中立的な環境であるデータクリーンルームをデプロイできるようになります。また、自分のアカウントからデータを移動またはコピーしたり、基盤となるデータセットを公開 AWS したりすることなく、 で他の組織にアクセスできるようにすることで、独自のインサイトを生成できます。すべてのデータはソースの場所に残ります。組み込みの分析ルールで、出力を抑制し、SQL クエリを制限します。すべてのクエリがログに記録され、コラボレーションメンバーはデータのクエリ方法を表示できます。
AWS Clean Rooms コラボレーションを作成し、他の AWS 顧客をそのコラボレーションのメンバーに招待できます。メンバーデータセットをクエリする機能を 1 人のメンバーに付与し、追加のメンバーを選択してそれらのクエリ結果を受け取れるようにできます。複数のメンバーがデータセットをクエリする必要がある場合は、同じデータソースと異なるメンバー設定を使用して追加のコラボレーションを作成できます。各メンバーは、コラボレーションメンバーと共有されているデータをフィルタリングできます。また、カスタム分析ルールを使用して、コラボレーションに提供するデータの分析方法に関する制限事項を設定できます。
は、コラボレーションに提示されるデータと他のメンバーによる使用方法を制限するだけでなく、プライバシーの保護に役立つ以下の機能 AWS Clean Rooms を提供します。
-
差分プライバシーは、慎重に調整されたノイズ量をデータに追加することでユーザーのプライバシーを強化する数学的な手法です。これにより、目的の値を隠すことなく、データセット内の個々のユーザーを再識別するリスクを軽減できます。AWS Clean Rooms 差分プライバシーの使用には、差分プライバシーの専門知識は必要ありません。
-
AWS Clean Rooms ML により、データを相互に直接共有しなくても、複数の関係者がデータ内で類似したユーザーを識別できます。これにより、コラボレーションのメンバーによって他のメンバーのデータセット内の個人を特定できる、メンバーシップ推論攻撃のリスクが軽減されます。類似モデルを作成し、類似セグメントを生成することで、 AWS Clean Rooms ML は元のデータを公開せずにデータセットを比較するのに役立ちます。これには、メンバーに ML の専門知識を持たせたり、外部で作業を実行したりする必要はありません AWS Clean Rooms。トレーニング済みモデルのフルコントロールと所有権は保持されます。
-
クリーンルームの暗号コンピューティング (C3R) は、分析ルールで使用して、機密データからインサイトを引き出すことができます。これにより、コラボレーションの相手が学習できる内容が暗号的に制限されます。C3R 暗号化クライアントを使用すると、データはクライアントで暗号化されてから提供されます AWS Clean Rooms。データテーブルは Amazon S3 にアップロードされる前にクライアント側の暗号化ツールを使用して暗号化されるため、データは暗号化されたままになり、処理中も保持されます。
AWS PRA では、データアカウントで AWS Clean Rooms コラボレーションを作成することをお勧めします。これらのコラボレーションを使用して、暗号化された顧客データをサードパーティーと共有できます。コラボレーションは、提供されたデータセットに重複がある場合にのみ使用してください。重複を判断する方法の詳細については、 AWS Clean Rooms ドキュメントの「分析ルールを一覧表示する」を参照してください。
Amazon CloudWatch Logs
Amazon CloudWatch Logs は、すべてのシステム、アプリケーション、 AWS のサービス からのログを一元化するのに役立ちます。一元化により、ログを監視して安全にアーカイブできます。CloudWatch Logs では、新規または既存のロググループのデータ保護ポリシーを使用して、個人データの開示リスクを最小限に抑えることができます。データ保護ポリシーにより、個人データなどログ内の機密データを検出できます。データ保護ポリシーでは、ユーザーが AWS マネジメントコンソールを介してログにアクセスするときに、そのデータをマスクできます。ユーザーが個人データに直接アクセスする必要がある場合は、ワークロードの全体的な目的仕様に従って、それらのユーザーに logs:Unmask のアクセス許可を割り当てることができます。また、アカウント全体のデータ保護ポリシーを作成し、このポリシーを組織内のすべてのアカウントに一貫して適用することもできます。これにより、CloudWatch Logs の現在および将来のすべてのロググループに対して、デフォルトでマスキングが設定されます。また、監査レポートを有効にし、別のロググループ、Amazon S3 バケット、または Amazon Data Firehose に送信することをお勧めします。これらのレポートには、各ロググループに対するデータ保護検出結果の詳細な記録が含まれています。
Amazon CodeGuru Reviewer
プライバシーとセキュリティの両方において、多くの組織が、デプロイフェーズとデプロイ後のフェーズの両方で継続的なコンプライアンスをサポートすることが重要です。 AWS PRA には、個人データを処理するアプリケーションのデプロイパイプラインにプロアクティブコントロールが含まれています。Amazon CodeGuru Reviewer は、Java、JavaScript、Python コード内の個人データを漏洩する可能性がある潜在的な欠陥を検出できます。コードを改善するための提案を開発者に提供します。CodeGuru Reviewer は、さまざまなセキュリティ、プライバシー、一般的な推奨プラクティスにおける欠陥を特定できます。 AWS CodeCommit、Bitbucket、GitHub、Amazon S3 など、複数のソースプロバイダーと連携するように設計されています。CodeGuru Reviewer が検出できるプライバシー関連の欠陥には、次のようなものがあります。
-
SQL インジェクション
-
セキュリティで保護されていない Cookie
-
認可の欠落
-
クライアント側の AWS KMS 再暗号化
CodeGuru Reviewer で検出できる内容の完全なリストについては、「Amazon CodeGuru Detector Library」を参照してください。
Amazon Comprehend
Amazon Comprehend は、機械学習を使用して英語のテキスト内で貴重なインサイトや接続を検出する自然言語処理 (NLP) サービスです。Amazon Comprehend は、構造化、半構造化、または非構造化テキストドキュメント内の個人データを検出して編集できます。詳細については、Amazon Comprehend ドキュメントの「個人を特定できる情報 (PII)」を参照してください。
Amazon Comprehend には AWS SDKs を介したアプリケーション統合のオプションが多数あるため、Amazon Comprehend を使用して、データを収集、保存、処理するさまざまな場所で個人データを識別できます。Amazon Comprehend ML 機能を使用すると、アプリケーションログ
-
REPLACE_WITH_PII_ENTITY_TYPEは、各 PII エンティティをそのタイプに置き換えます。例えば、Jane Doe は NAME に置き換えられます。 -
MASKは、PII エンティティの文字を任意の文字 (!、#、$、%、&、、@) に置き換えます。例えば、Jane Doe は **** *** に置き換えることができます。
Amazon Data Firehose
Amazon Data Firehose は、ストリーミングデータをキャプチャして変換し、Amazon Managed Service for Apache Flink や Amazon S3 などのダウンストリーム サービスにロードします。Firehose は、処理パイプラインをゼロから構築することなく、アプリケーションログなどの大量のストリーミングデータを転送するために使用されることが多くあります。
Lambda 関数を使用して、データがダウンストリームに送信される前に、カスタマイズされた処理または組み込み処理を実行できます。プライバシーについて、この機能はデータの最小化と海外へのデータ転送に関する要件をサポートします。例えば、Lambda と Firehose を使用して、ログアーカイブアカウントに一元化される前にマルチリージョンログデータを変換できます。詳細については、「Biogen: Centralized Logging Solution for Multi Accounts
Amazon DataZone
組織が AWS のサービス などの を通じてデータを共有するアプローチをスケールするにつれて AWS Lake Formation、差分アクセスがデータに最も精通しているユーザー、つまりデータ所有者によって制御されるようにしたいと考えています。ただし、こうしたデータ所有者は、同意や海外へのデータ転送に関する考慮事項などのプライバシー要件を認識している可能性があります。Amazon DataZone を使用すれば、データ所有者とデータガバナンスチームが、データガバナンスポリシーに従い組織全体でデータを共有および使用できるようになります。Amazon DataZone では、事業部門 (LOB) が独自のデータを管理し、カタログでこの所有権を追跡します。利害関係者は、ビジネスタスクの一環としてデータを検索し、アクセスをリクエストできます。データパブリッシャーによって確立されたポリシーに従っている限り、データ所有者は、管理者を必要とせず、またデータを移動することなく、基盤となるテーブルへのアクセスを付与できます。
プライバシーのコンテキストにおいて、Amazon DataZone は次のユースケースの例で役立ちます。
-
顧客向けアプリケーションで、別のマーケティング LOB と共有できる使用状況データを生成します。マーケティングにオプトインした顧客のデータのみがカタログに公開されていることを確認する必要があります。
-
欧州の顧客データは公開されますが、欧州経済地域 (EEA) のローカル LOB のみがサブスクライブできます。詳細については、「Amazon DataZone の細かな粒度のアクセス制御によるデータセキュリティの強化
」を参照してください。
AWS PRA では、共有 Amazon S3 バケット内のデータをデータプロデューサーとして Amazon DataZone に接続できます。
AWS Glue
個人データを含むデータセットの維持は、プライバシーバイデザインの主要なコンポーネントです。組織のデータは、構造化、半構造化、または非構造化の形式で存在する場合があります。構造化されていない個人用データセットでは、データ最小化、データ主体要求の一部として単一のデータ主体に起因するデータの追跡、一貫したデータ品質の確保、データセットの全体的なセグメンテーションなど、プライバシーを強化するオペレーションを多数実行することが困難になる可能性があります。AWS Glue はフルマネージドの抽出、変換、ロード (ETL) サービスです。データストアとデータストリーム間でデータを分類、クリーンアップ、強化、移動するのに役立ちます。 AWS Glue 機能は、分析、機械学習、アプリケーション開発用のデータセットを検出、準備、構造化、結合するのに役立ちます。 AWS Glue を使用して、既存のデータセット上に予測可能で共通の構造を作成できます。 AWS Glue Data Catalog、 AWS Glue DataBrew、および AWS Glue Data Quality は、組織のプライバシー要件をサポートするのに役立つ AWS Glue 機能です。
AWS Glue Data Catalog
AWS Glue Data Catalog を使用して、メンテナンス可能なデータセットを確立できます。データカタログには、抽出、変換、ロード (ETL) ジョブのソースおよびターゲットとして使用されるデータへの参照が含まれています AWS Glue。Data Catalog の情報はメタデータテーブルとして保存され、各テーブルが 1 つのデータストアを指定します。 AWS Glue
クローラーを実行して、さまざまなデータストアタイプのデータを調査します。組み込み分類子とカスタム分類子をクローラーに追加すると、これらの分類子によって個人データのデータ形式とスキーマが推測されます。次に、クローラーによってメタデータが Data Catalog に書き込まれます。一元化されたメタデータテーブルを使用すると、 AWS 環境内の個人データのさまざまなソースに構造と予測可能性が追加されるため、データセットリクエスト (消去する権利など) への対応が容易になります。Data Catalog を使用してこれらのリクエストに自動的に応答する方法の包括的な例については、Amazon S3 Find and Forget によるデータレイク内のデータ消去リクエストの処理
AWS Glue DataBrew
AWS Glue DataBrew は、データのクリーンアップと正規化に役立ち、個人を特定できる情報の削除やマスキング、データパイプライン内の機密データフィールドの暗号化など、データ上で変換を実行できます。また、データの系統を視覚的にマッピングして、データが通過したさまざまなデータソースと変換ステップを理解することもできます。この機能は、組織が個人データの出所をよりよく理解して追跡するにつれて、ますます重要になっています。DataBrew は、データの準備中に個人データをマスクするのに役立ちます。データプロファイリングジョブの一部として個人データを検出し、個人データを含む可能性のある列の数やカテゴリなどの統計情報を収集できます。また、置換、ハッシュ、暗号化、復号など、組み込みの可逆的または不可逆的なデータ変換手法を、コードを記述することなく使用できます。さらに、クリーンアップ済みデータセットやマスク済みデータセットのダウンストリームを分析、報告、機械学習タスクに使用できます。DataBrew で使用できるデータマスキング手法には、次のようなものがあります。
-
ハッシュ — ハッシュ関数を列値に適用します。
-
置換 – 個人データを他の、本物そっくりの値に置き換えます。
-
Null 化または削除 – 特定のフィールドを null 値に置き換えるか、列を削除します。
-
マスキング — 文字スクランブルを使用するか、列内の特定の部分をマスクします。
使用可能な暗号化手法は、次のとおりです。
-
確定的暗号化 – 確定的暗号化アルゴリズムを列値に適用します。確定的暗号化では、値に対して常に同じ暗号文が生成されます。
-
確率的暗号化 – 確率的暗号化アルゴリズムを列値に適用します。確率的暗号化は、適用されるたびに異なる暗号文が生成されます。
DataBrew で提供される個人データ変換レシピの完全なリストについては、「Personally identifiable information (PII) recipe steps」を参照してください。
AWS Glue データ品質
AWS Glue Data Quality は、データパイプラインがデータコンシューマーに配信される前に、データパイプライン間の高品質のデータの配信をプロアクティブに自動化および運用するのに役立ちます。 AWS Glue Data Quality は、データパイプライン全体のデータ品質問題の統計分析を提供し、Amazon EventBridge でアラートをトリガーし、修復のための品質ルールのレコメンデーションを行うことができます。 AWS Glue Data Quality は、カスタムデータ品質ルールを作成できるように、ドメイン固有の言語でのルールの作成もサポートします。
AWS Key Management Service
AWS Key Management Service (AWS KMS) は、データの保護に役立つ暗号化キーの作成と制御に役立ちます。 は、ハードウェアセキュリティモジュール AWS KMS を使用して、FIPS 140-2 暗号化モジュール検証プログラム AWS KMS keys で保護と検証を行います。セキュリティコンテキストでのこのサービスの使用方法についての詳細は、「AWS セキュリティリファレンスアーキテクチャ」を参照してください。
AWS KMS は、暗号化 AWS のサービス を提供するほとんどの と統合されており、個人データを処理して保存するアプリケーションで KMS キーを使用できます。 AWS KMS を使用して、次のようなさまざまなプライバシー要件をサポートし、個人データを保護することができます。
-
カスタマーマネージドキーを使用して、強度、ローテーション、有効期限、その他のオプションをより詳細に制御できます。
-
専用のカスタマーマネージドキーを使用すると、個人データや、個人データへのアクセスを許可するシークレットを保護できます。
-
データ分類レベルを定義し、レベルごとに少なくとも 1 つの専用カスタマーマネージドキーを指定します。例えば、運用データを暗号化する 1 つのキーと、個人データを暗号化する別のキーがあるとします。
-
KMS キーへの意図しないクロスアカウントアクセスを防止します。
-
暗号化するリソース AWS アカウント と同じ 内に KMS キーを保存します。
-
KMS キーの管理と使用に対して権限の分離を実装します。詳細については、「KMS と IAM を使用して S3 で暗号化されたデータの独立したセキュリティコントロールを有効にする方法
」(AWS ブログ記事) を参照してください。 -
予防的ガードレールと事後対応ガードレールによる自動キーローテーションの適用。
デフォルトでは、KMS キーは保存され、作成されたリージョンでのみ使用できます。組織にデータレジデンシーと主権に関する特定の要件がある場合は、マルチリージョン KMS キーがユースケースに適しているかどうかを検討してください。マルチリージョンキーは、異なる の専用 KMS キー AWS リージョン で、同じ意味で使用できます。マルチリージョンキーを作成するプロセスは、キーマテリアルを内部の AWS リージョン 境界を越えて移動するため AWS KMS、このリージョン分離の欠如は、組織の主権とレジデンシーの目標と互換性がない可能性があります。これを解決する 1 つの方法は、リージョン固有のカスタマーマネージドキーなど、別のタイプの KMS キーを使用することです。
外部キーストア
多くの組織では、 のデフォルト AWS KMS キーストアは、データ主権と一般的な規制要件を満たす AWS クラウド ことができます。ただし、中には暗号化キーがクラウド環境の外部で作成および管理され、独立した認可パスと監査パスがあることが必要になる場合があります。の外部キーストアを使用すると AWS KMS、組織が の外部で所有および管理するキーマテリアルを使用して個人データを暗号化できます AWS クラウド。 AWS KMS API は通常どおり操作しますが、指定した外部キーストアプロキシ (XKS プロキシ) ソフトウェアとのみ AWS KMS 操作します。その後、外部キーストアプロキシは、 AWS KMS と外部キーマネージャーとの間のすべての通信を仲介します。
データ暗号化に外部キーストアを使用する場合は、 AWS KMSでキーを維持する場合と比較して、追加の運用オーバーヘッドを考慮することが重要です。外部キーストアを使用して、外部キーストアを作成、設定、維持する必要があります。また、XKS プロキシなど、維持する必要がある追加のインフラストラクチャでエラーが発生し、接続が失われた場合、ユーザーは一時的にデータの復号やアクセスができなくなる可能性があります。コンプライアンスおよび規制関係者と緊密に連携し、個人データの暗号化に関する法的および契約上の義務と、可用性と回復性に関するサービスレベル契約について理解します。
AWS Lake Formation
構造化メタデータカタログを介してデータセットをカタログ化および分類する多くの組織が、それらのデータセットを組織全体で共有したいと考えています。 AWS Identity and Access Management (IAM) アクセス許可ポリシーを使用してデータセット全体へのアクセスを制御できますが、さまざまな機密性の個人データを含むデータセットには、より詳細な制御が必要になることがよくあります。例えば、目的仕様と使用制限
データレイク
Lake Formation でタグベースのアクセスコントロール機能を使用できます。タグベースのアクセスコントロールは、属性に基づいて許可を定義する認可戦略です。これらの属性は、Lake Formation で LF タグと呼ばれています。LF タグを使用すると、これらのタグを Data Catalog データベース、テーブル、列にアタッチし、IAM プリンシパルに同じタグを付与できます。Lake Formation は、プリンシパルでリソースのタグ値と一致するタグ値にアクセス許可が付与されたときに、それらのリソースに対する操作を許可します。次の図は、LF タグとアクセス許可を割り当てて、個人データへの差別化されたアクセスを提供する方法を示しています。

この例では、タグの階層的な性質を使用します。どちらのデータベースにも個人を特定できる情報 (PII:true) が含まれていますが、列レベルのタグによって特定の列が異なるチームに制限されます。この例では、LF タグを持つ IAM PII:true プリンシパルは、このタグを持つ AWS Glue データベースリソースにアクセスできます。LOB:DataScience LF タグを持つプリンシパルは、このタグを持つ特定の列にアクセスでき、LOB:Marketing LF タグを持つプリンシパルは、このタグを持つ列にのみアクセスできます。マーケティングは、マーケティングユースケースに関連する PII にのみアクセスでき、データサイエンスチームは、データサイエンスユースケースに関連する PII にのみアクセスできます。
AWS ローカルゾーン
データレジデンシー要件に準拠する必要がある場合は、これらの要件をサポートするために、特定の に個人データを保存および処理するリソース AWS リージョン をデプロイできます。また、 を使用することもできます。これはAWS ローカルゾーン、コンピューティング、ストレージ、データベース、その他の一部の AWS リソースを大規模な人口や業界の中心の近くに配置するのに役立ちます。ローカルゾーンは、大都市圏に地理的に近い AWS リージョン の拡張子です。ローカルゾーンが対応するリージョンの近くで、特定のタイプのリソースをローカルゾーン内に配置できます。ローカルゾーンは、同じ法的管轄区域内でリージョンが利用できない場合に、データレジデンシー要件を満たすのに役立ちます。ローカルゾーンを使用する場合は、組織内にデプロイされているデータレジデンシーコントロールを検討してください。例えば、特定のローカルゾーンから別のリージョンへのデータ転送を防ぐためにコントロールが必要となる場合があります。SCPs「ランディングゾーンコントロール AWS ローカルゾーン を使用して のデータレジデンシーを管理するためのベストプラクティス
AWS Nitro Enclaves
Amazon Elastic Compute Cloud (Amazon EC2) などのコンピューティングサービスを使用して個人データを処理するなど、処理の観点からデータセグメンテーション戦略を検討してください。大規模なアーキテクチャ戦略の一環としての機密コンピューティングは、隔離され、保護され、信頼できる CPU エンクレーブで個人データの処理を分離するのに役立ちます。エンクレーブは、分離され、強化され、制約の厳しい仮想マシンです。AWS Nitro Enclaves は、これらの分離されたコンピューティング環境の作成に役立つ Amazon EC2 の機能です。詳細については、「The Security Design of the AWS Nitro System」(AWS ホワイトペーパー) を参照してください。
Nitro Enclaves は、親インスタンスのカーネルから分離されたカーネルをデプロイします。親インスタンスのカーネルは、エンクレーブにアクセスできません。ユーザーは、エンクレーブ内のデータやアプリケーションに SSH またはリモートでアクセスすることはできません。個人データを処理するアプリケーションはエンクレーブに埋め込み、エンクレーブの Vsock を使用するように設定できます。これは、エンクレーブと親インスタンス間の通信を促進するソケットです。
Nitro Enclaves が役立つユースケースの 1 つは、別々の 2 つのデータプロセッサ間のジョイント処理 AWS リージョン であり、相互に信頼しない可能性があります。次の図は、エンクレーブを中央処理に使用する方法、エンクレーブに送信される前に個人データを暗号化するための KMS キー、および復号をリクエストするエンクレーブが認証ドキュメントで一意の測定値を持っていることを確認する AWS KMS key ポリシーについて示しています。詳細と手順については、「 での暗号化認証の使用 AWS KMS」を参照してください。サンプルキーポリシーについては、このガイドの「AWS KMS キーを使用するには認証が必要です」を参照してください。
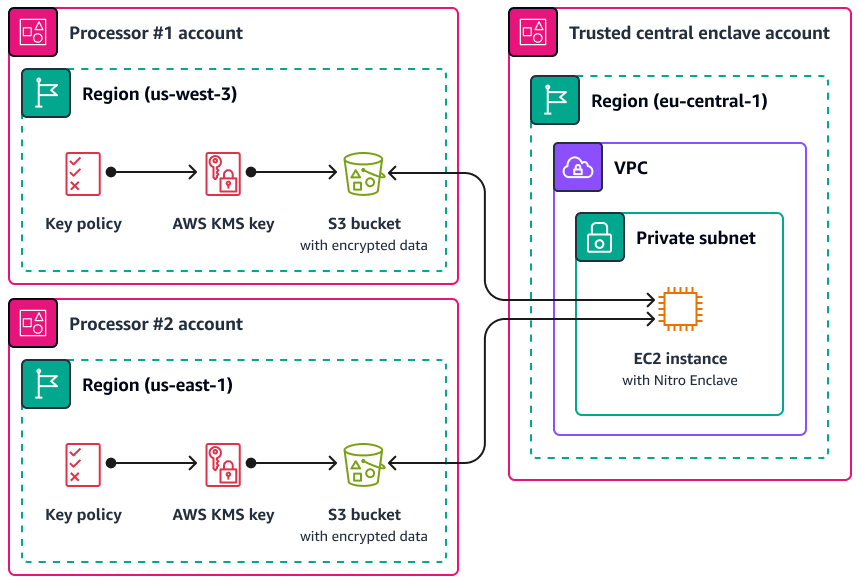
この実装では、それぞれのデータ処理者と基盤となるエンクレーブのみがプレーンテキストの個人データにアクセスできます。それぞれのデータ処理者の環境外でデータが公開される唯一の場所は、エンクレーブ自体にあります。エンクレーブ自体は、アクセスや改ざんを防ぐように設計されています。
AWS PrivateLink
多くの組織は、信頼できないネットワークへの個人データの公開を制限したいと考えています。例えば、アプリケーションアーキテクチャ設計全体のプライバシーを強化する場合、データの機密性に基づいてネットワークをセグメント化できます (「AWS のサービス データのセグメント化に役立つ および の機能」セクションで説明されているデータセットの論理的および物理的な分離に似ています)。AWS PrivateLink は、仮想プライベートクラウド (VPC) から VPC 外のサービスへの一方向のプライベート接続を作成するのに役立ちます。 AWS PrivateLinkを使用すると、お使いの環境に個人データを保存または処理するサービスへの専用プライベート接続を設定できます。パブリックエンドポイントに接続する必要も、信頼できないパブリックネットワークを介してこのデータを転送する必要もありません。対象範囲内 AWS PrivateLink のサービスのサービスエンドポイントを有効にすると、通信にインターネットゲートウェイ、NAT デバイス、パブリック IP アドレス、 AWS Direct Connect 接続、または AWS Site-to-Site VPN 接続は必要ありません。 AWS PrivateLink を使用して個人データへのアクセスを提供するサービスに接続する場合、VPC エンドポイントポリシーとセキュリティグループを使用して、組織のデータ境界
AWS Resource Access Manager
AWS Resource Access Manager (AWS RAM) は、 間でリソースを安全に共有 AWS アカウント し、運用オーバーヘッドを削減し、可視性と監査性を提供します。マルチアカウントセグメンテーション戦略を計画する際には、 AWS RAM を使用して、分離された別のアカウントに保存されている個人データストアを共有することを検討してください。その個人データは、処理を目的として他の信頼されたアカウントと共有できます。では AWS RAM、共有リソースに対して実行できるアクションを定義するアクセス許可を管理できます。へのすべての API コール AWS RAM は CloudTrail に記録されます。また、リソース共有に変更が加えられたときなど AWS RAM、 の特定のイベントについて自動的に通知するように Amazon CloudWatch Events を設定できます。
Amazon S3 の IAM またはバケットポリシーでリソースベースのポリシー AWS アカウント を使用することで、他の と多くのタイプの AWS リソースを共有できますが、 AWS RAM にはプライバシーに関するいくつかの追加の利点があります。 は、データ所有者が 間でデータを共有する方法とユーザーについて、次のような追加の可視性 AWS を提供します AWS アカウント。
-
アカウント ID のリストを手動で更新するのではなく、OU 全体とリソースを共有できるようにする
-
コンシューマーアカウントが組織に含まれていない場合に、共有を開始するための招待プロセスの適用
-
特定の IAM プリンシパルが個々のリソースにアクセスできる可視性
以前にリソースベースのポリシーを使用してリソース共有を管理し、 AWS RAM 代わりに を使用する場合は、PromoteResourceShareCreatedFromPolicy API オペレーションを使用します。
Amazon SageMaker AI
Amazon SageMaker AI
Amazon SageMaker Model Monitor
多くの組織は、ML モデルのトレーニング時にデータドリフトを検討しています。データドリフトとは、実稼働データと ML モデルのトレーニングに使用されたデータとの間に有意な差異が生じたり、入力データが時間の経過と共に有意に変化したりすることです。データドリフトは、ML モデル予測の全体的な品質、精度、公平性を低下させる可能性があります。本番稼働中に ML モデルが受け取るデータの統計的性質が、トレーニングに使用されたベースラインデータの性質からドリフトすると、モデルの予測精度が低下していきます。Amazon SageMaker Model Monitor は本番稼働中の Amazon SageMaker AI 機械学習モデルの品質およびデータ品質を継続的に監視します。データドリフトを早期かつプロアクティブに検出することで、モデルの再トレーニング、アップストリームシステムの監査、データ品質の問題の修正などの是正措置を実装できます。Model Monitor を使用すると、モデルを手動で監視したり、追加のツールを構築したりする必要性を軽減できます。
Amazon SageMaker Clarify
Amazon SageMaker Clarify は、モデルのバイアスと説明可能性に関するインサイトを提供します。SageMaker Clarify は、ML モデルデータの準備と全体的な開発フェーズで一般的に使用されます。開発者が性別や年齢などの関心のある属性を指定すると、SageMaker Clarify は一連のアルゴリズムを実行して、これらの属性にバイアスがあるかどうかを検出します。アルゴリズムの実行後、SageMaker Clarify は、バイアスの可能性のある発生源と測定値に関する説明を含むビジュアルレポートを提供するため、バイアスを軽減するステップを計画できます。例えば、ある年齢グループに対するビジネスローンの例が、他の年齢グループと比較して少ない財務データセットで、SageMaker は不均衡にフラグを立てて、その年齢グループに不利なモデルを回避できます。また、その予測を確認し、それらの ML モデルにバイアスがないか継続的に監視することで、トレーニング済みのモデルにバイアスがないかを確認することもできます。最後に、SageMaker Clarify は Amazon SageMaker AI Experiments と統合され、モデルの全体的な予測プロセスに最も寄与した機能について説明するグラフを提供します。この情報は、説明可能性の結果を満たすのに役立ちます。また、特定のモデル入力がモデル動作全体に与える影響よりも大きいかどうかを判断することもできます。
Amazon SageMaker Model Card
Amazon SageMaker Model Card を使用すると、機械学習 (ML) モデルに関する重要な詳細を文書化して、ガバナンスとレポート作成に役立てることができます。これらの詳細には、モデル所有者、汎用、意図したユースケース、実施された仮定、モデルのリスク評価、トレーニングの詳細とメトリクス、評価結果が含まれます。詳細については、AWS 「人工知能とMachine Learningソリューションによるモデルの説明可能性」(AWS ホワイトペーパー) を参照してください。
Amazon SageMaker Data Wrangler
Amazon SageMaker Data Wrangler
Data Wrangler は、 AWS PRA のデータ準備および機能エンジニアリングプロセスの一部として使用できます。を使用して保管中および転送中のデータ暗号化をサポートし AWS KMS、IAM ロールとポリシーを使用してデータやリソースへのアクセスを制御します。 AWS Glue または Amazon SageMaker Feature Store によるデータマスキングをサポートしています。Data Wrangler を と統合すると AWS Lake Formation、きめ細かなデータアクセスコントロールとアクセス許可を適用できます。Amazon Comprehend で Data Wrangler を使用して、より広範な ML Ops ワークフローの一部として表形式データから個人データを自動的に編集することもできます。詳細については、Amazon SageMaker Data Wrangler を使用して機械学習用の PII を自動的に編集
Data Wrangler の汎用性により、アカウント番号、クレジットカード番号、社会保障番号、患者名、医療記録や軍事記録など、多くの業界の機密データをマスクできます。機密データへのアクセスを制限するか、編集することを選択できます。
AWS データライフサイクルの管理に役立つ 機能
個人データが不要になった場合は、さまざまなデータストアのデータにライフサイクルポリシーと有効期限ポリシーを使用できます。データ保持ポリシーを設定するときは、個人データが含まれている可能性のある以下の場所を考慮してください。
-
Amazon DynamoDB や Amazon Relational Database Service (Amazon RDS) などのデータベース
-
Amazon S3 バケット
-
CloudWatch および CloudTrail のログ
-
AWS Database Migration Service (AWS DMS) および AWS Glue DataBrew プロジェクトの移行からのキャッシュされたデータ
-
バックアップとスナップショット
以下の AWS のサービス および 機能は、 AWS 環境でデータ保持ポリシーを設定するのに役立ちます。
-
Amazon S3 ライフサイクル - Amazon S3 がオブジェクトのグループに適用するアクションを定義するルールセット。Amazon S3 ライフサイクル設定では、Amazon S3 がお客様に代わって期限切れのオブジェクトを削除するタイミングを定義する有効期限アクションを作成できます。詳細については、「ストレージのライフサイクルの管理」を参照してください。
-
Amazon Data Lifecycle Manager – Amazon EC2 で、Amazon Elastic Block Store (Amazon EBS) スナップショットと EBS-backed Amazon マシンイメージ (AMI) の作成、保持、削除を自動化するポリシーを作成します。
-
DynamoDB の有効期限 (TTL) – 項目ごとのタイムスタンプを定義して、項目が不要になる時期を特定できます。指定されたタイムスタンプの日付と時刻の直後に、DynamoDB によってテーブルから項目が削除されます。
-
CloudWatch Logs のログ保持期間の設定 – 各ロググループの保持ポリシーを 1 日から 10 年の値で調整できます。
-
AWS Backup – データ保護ポリシーを一元的にデプロイして、S3 バケット、RDS データベースインスタンス、DynamoDB テーブル、EBS ボリュームなど、さまざまな AWS リソース間でバックアップアクティビティを設定、管理、管理します。バックアップポリシーを AWS リソースに適用するには、リソースタイプを指定するか、既存のリソースタグに基づいて を適用します。一元化されたコンソールからバックアップアクティビティを監査して報告し、バックアップコンプライアンス要件を満たすことができます。
AWS のサービス データのセグメント化に役立つ および の機能
データセグメンテーションは、データを別々のコンテナに保存するためのプロセスです。これにより、各データセットに差別化されたセキュリティと認証措置を提供し、データセット全体に対して公開する影響の範囲を減らすことができます。例えば、すべての顧客データを 1 つの大きなデータベースに保存する代わりに、このデータをより小さく管理しやすいグループにセグメント化できます。
物理的および論理的な分離を使用して、個人データをセグメント化できます。
-
物理的な分離 – データを別々のデータストアに保存するか、データを別々の AWS リソースに分散する行為。データは物理的に分離されますが、両方のリソースから同じプリンシパルにアクセスできる可能性があります。そのため、物理的な分離と論理的な分離を組み合わせることをお勧めします。
-
論理的な分離 – アクセスコントロールを使用してデータを分離する行為。職務機能に応じて、個人データのサブセットへのさまざまなレベルのアクセスが必要となります。論理的な分離を実装するサンプルポリシーについては、このガイドの「特定の Amazon DynamoDB 属性へのアクセス権の付与」を参照してください。
論理的な分離と物理的な分離を組み合わせることで、アイデンティティベースのポリシーとリソースベースのポリシーを記述する際の柔軟性、シンプルさ、詳細度を提供し、職務機能間で区別されたアクセスをサポートします。例えば、1 つの S3 バケットで異なるデータ分類を論理的に分離するポリシーを作成するのは、運用上複雑な場合があります。各データ分類に専用の S3 バケットを使用すると、ポリシーの設定と管理が簡単になります。
AWS のサービス データの検出、分類、カタログ化に役立つ および の機能
一部の組織は、データをプロアクティブにカタログ化するための、環境での抽出、ロード、変換 (ELT) ツールの使用を開始していません。これらのお客様は、保存および処理するデータと、その構造化 AWS および分類方法をよりよく理解したいという、データ検出の初期段階にいるかもしれません。Amazon Macie を使用すると、Amazon S3 の PII データをよりよく理解できます。ただし、Amazon Macie は、Amazon Relational Database Service (Amazon RDS) や Amazon Redshift などの他のデータソースの分析には役立ちません。次の 2 つのアプローチを使用すると、大規模なデータマッピング演習
-
手動アプローチ – 2 つの列と必要な数の行を含むテーブルを作成します。最初の列には、ネットワークパケットのヘッダーまたは本文、または指定した任意のサービスに含まれるデータ特性 (ユーザー名、住所、性別など) を記述します。2 番目の列については、コンプライアンスチームに入力を依頼します。データが個人用と見なされる場合は、2 番目の列に「はい」と入力し、そうでない場合は「いいえ」と入力します。宗教的な分位数や健康データなど、特に機密性が高いと見なされる個人データのタイプを示します。
-
自動アプローチ – AWS Marketplaceを通じて提供されるツールを使用します。このようなツールの 1 つが、Securiti
です。これらのソリューションでは、複数の AWS リソースタイプにわたるデータや、他のクラウドサービスプラットフォームのアセットをスキャンおよび検出できる統合機能を提供します。これらの同じソリューションの多くで、一元化されたデータカタログ内のデータアセットとデータ処理アクティビティのインベントリを継続的に収集および維持できます。自動分類を実行するツールに依存している場合、組織内の個人データの定義に合わせて検出および分類ルールを調整する必要が生じる場合があります。
