As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Dados pessoais OU — Conta de aplicativo PD
Gostaríamos muito de ouvir de você. Forneça feedback sobre o AWS PRA respondendo a uma breve pesquisa |
A conta do aplicativo de dados pessoais (PD) é onde sua organização hospeda serviços que coletam e processam dados pessoais. Especificamente, você pode armazenar o que você define como dados pessoais nessa conta. O AWS PRA demonstra vários exemplos de configurações de privacidade por meio de uma arquitetura web sem servidor de várias camadas. Quando se trata de operar cargas de trabalho em um AWS landing zone, as configurações de privacidade não devem ser consideradas one-size-fits-all soluções. Por exemplo, seu objetivo pode ser entender os conceitos subjacentes, como eles podem melhorar a privacidade e como sua organização pode aplicar soluções aos seus casos de uso e arquiteturas específicos.
Pois Contas da AWS em sua organização que coleta, armazena ou processa dados pessoais, você pode usar AWS Organizations e AWS Control Tower implantar proteções básicas e reproduzíveis. Estabelecer uma unidade organizacional (OU) dedicada para essas contas é fundamental. Por exemplo, talvez você queira aplicar barreiras de residência de dados somente a um subconjunto de contas em que a residência de dados é uma consideração fundamental do design. Para muitas organizações, essas são as contas que armazenam e processam dados pessoais.
Sua organização pode oferecer suporte a uma conta de dados dedicada, que é onde você armazena a fonte autorizada de seus conjuntos de dados pessoais. Uma fonte de dados autorizada é um local onde você armazena a versão principal dos dados, que pode ser considerada a versão mais confiável e precisa dos dados. Por exemplo, você pode copiar os dados da fonte de dados autorizada para outros locais, como buckets do Amazon Simple Storage Service (Amazon S3) na conta do aplicativo PD que são usados para armazenar dados de treinamento, um subconjunto de dados do cliente e dados editados. Ao adotar essa abordagem de várias contas para separar conjuntos de dados pessoais completos e definitivos na conta de dados das cargas de trabalho posteriores do consumidor na conta do aplicativo PD, você pode reduzir o escopo do impacto no caso de acesso não autorizado às suas contas.
O diagrama a seguir ilustra os serviços de AWS segurança e privacidade configurados nas contas de aplicativos e dados do PD.
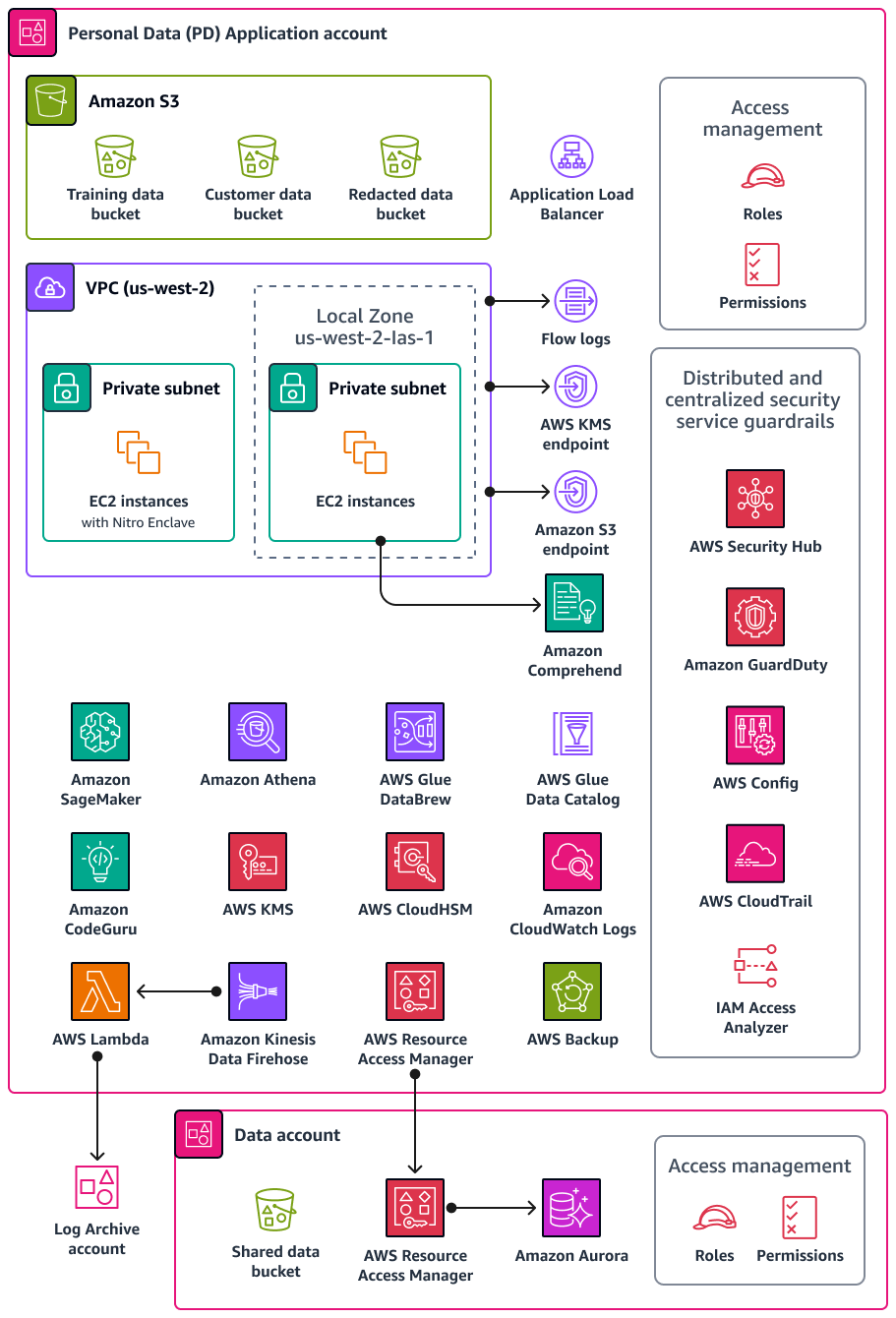
Esta seção fornece informações mais detalhadas sobre o seguinte Serviços da AWS que é usado nessas contas:
Amazon Athena
Você também pode considerar os controles de limitação de consultas de dados para atender às suas metas de privacidade. O Amazon Athena é um serviço de consultas interativas que facilita a análise de dados diretamente no Amazon S3 usando SQL padrão. Você não precisa carregar os dados no Athena; ele funciona diretamente com os dados armazenados nos buckets do S3.
Um caso de uso comum do Athena é fornecer às equipes de análise de dados conjuntos de dados personalizados e higienizados. Se os conjuntos de dados contiverem dados pessoais, você poderá limpar o conjunto de dados mascarando colunas inteiras de dados pessoais que fornecem pouco valor às equipes de análise de dados. Para obter mais informações, consulte Anonimizar e gerenciar dados em seu data lake com o Amazon Athena AWS Lake Formation
Se sua abordagem de transformação de dados exigir flexibilidade adicional fora das funções suportadas no Athena, você poderá definir funções personalizadas, chamadas de funções definidas pelo usuário (UDF). Você pode invocar UDFs em uma consulta SQL enviada ao Athena e elas são executadas em. AWS Lambda Você pode usar FILTER
SQL consultas UDFs in SELECT e pode invocar várias UDFs na mesma consulta. Para fins de privacidade, você pode criar UDFs tipos específicos de mascaramento de dados, como mostrar somente os últimos quatro caracteres de cada valor em uma coluna.
CloudWatch Registros da Amazon
O Amazon CloudWatch Logs ajuda você a centralizar os registros de todos os seus sistemas e aplicativos, Serviços da AWS para que você possa monitorá-los e arquivá-los com segurança. Em CloudWatch Registros, você pode usar uma política de proteção de dados para grupos de registros novos ou existentes para ajudar a minimizar o risco de divulgação de dados pessoais. As políticas de proteção de dados podem detectar dados confidenciais, como dados pessoais, em seus registros. A política de proteção de dados pode mascarar esses dados quando os usuários acessam os registros por meio do AWS Management Console. Quando os usuários precisam de acesso direto aos dados pessoais, de acordo com a especificação geral da finalidade da sua carga de trabalho, você pode atribuir logs:Unmask permissões para esses usuários. Você também pode criar uma política de proteção de dados para toda a conta e aplicar essa política de forma consistente em todas as contas da sua organização. Isso configura o mascaramento por padrão para todos os grupos de registros atuais e futuros no CloudWatch Logs. Também recomendamos que você habilite os relatórios de auditoria e os envie para outro grupo de logs, um bucket do Amazon S3 ou o Amazon Data Firehose. Esses relatórios contêm um registro detalhado das descobertas de proteção de dados em cada grupo de registros.
CodeGuru Revisor da Amazon
Tanto para a privacidade quanto para a segurança, é vital para muitas organizações que elas ofereçam suporte à conformidade contínua durante as fases de implantação e pós-implantação. O AWS PRA inclui controles proativos nos pipelines de implantação de aplicativos que processam dados pessoais. O Amazon CodeGuru Reviewer pode detectar possíveis defeitos que possam expor dados pessoais em código Java e JavaScript Python. Ele oferece sugestões aos desenvolvedores para melhorar o código. CodeGuru O revisor pode identificar defeitos em uma ampla variedade de práticas recomendadas gerais, de segurança e privacidade. Para obter mais informações, consulte a Amazon CodeGuru Detector Library. Ele foi projetado para funcionar com vários provedores de origem AWS CodeCommit, incluindo Bitbucket e Amazon S3. GitHub Alguns dos defeitos relacionados à privacidade que o CodeGuru Revisor pode detectar incluem:
-
Injeção de SQL
-
Cookies não seguros
-
Autorização ausente
-
Recriptografia do lado do cliente AWS KMS
Amazon Comprehend
O Amazon Comprehend é um serviço de processamento de linguagem natural (NLP) que usa aprendizado de máquina para descobrir informações e conexões valiosas em documentos de texto em inglês. O Amazon Comprehend pode detectar e redigir dados pessoais em documentos de texto estruturados, semiestruturados ou não estruturados. Para obter mais informações, consulte Informações de identificação pessoal (PII) na documentação do Amazon Comprehend.
Você pode usar a AWS SDKs e a API do Amazon Comprehend para integrar o Amazon Comprehend a vários aplicativos. Um exemplo é usar o Amazon Comprehend para detectar e editar dados pessoais com o Amazon S3 Object Lambda. As organizações podem usar o S3 Object Lambda para adicionar código personalizado às solicitações GET do Amazon S3 para modificar e processar dados à medida que eles são devolvidos a um aplicativo. O S3 Object Lambda pode filtrar linhas, redimensionar imagens dinamicamente, redigir dados pessoais e muito mais. Alimentado por AWS Lambda funções, o código é executado em uma infraestrutura totalmente gerenciada AWS, o que elimina a necessidade de criar e armazenar cópias derivadas de seus dados ou executar proxies. Você não precisa alterar seus aplicativos para transformar objetos com o S3 Object Lambda. Você pode usar a função ComprehendPiiRedactionS3Object Lambda para AWS Serverless Application Repository redigir dados pessoais. Essa função usa o Amazon Comprehend para detectar entidades de dados pessoais e redige essas entidades substituindo-as por asteriscos. Para obter mais informações, consulte Detecção e redação de dados de PII com o S3 Object Lambda e o Amazon Comprehend na documentação do Amazon S3.
Como o Amazon Comprehend tem muitas opções de integração de aplicativos por meio da SDKs AWS, você pode usar o Amazon Comprehend para identificar dados pessoais em vários lugares diferentes onde você coleta, armazena e processa dados. Você pode usar os recursos do Amazon Comprehend ML para detectar e editar dados pessoais em registros de aplicativos AWS (publicação no
-
REPLACE_WITH_PII_ENTITY_TYPEsubstitui cada entidade de PII por seus tipos. Por exemplo, Jane Doe seria substituída por NAME. -
MASKsubstitui os caracteres em entidades de PII por um personagem de sua escolha (! , #, $,%, &, ou @). Por exemplo, Jane Doe pode ser substituída por **** ***.
Amazon Data Firehose
O Amazon Data Firehose pode ser usado para capturar, transformar e carregar dados de streaming em serviços downstream, como o Amazon Managed Service para Apache Flink ou o Amazon S3. O Firehose costuma ser usado para transportar grandes quantidades de dados de streaming, como registros de aplicativos, sem precisar criar pipelines de processamento do zero.
Você pode usar as funções do Lambda para realizar um processamento personalizado ou incorporado antes que os dados sejam enviados para o downstream. Para privacidade, esse recurso oferece suporte aos requisitos de minimização de dados e transferência de dados entre fronteiras. Por exemplo, você pode usar o Lambda e o Firehose para transformar dados de log de várias regiões antes de serem centralizados na conta do Log Archive. Para obter mais informações, consulte Biogen: solução de registro centralizada para várias contas
AWS Glue
A manutenção de conjuntos de dados que contêm dados pessoais é um componente essencial do Privacy by Design
AWS Glue Data Catalog
AWS Glue Data Catalogajuda você a estabelecer conjuntos de dados sustentáveis. O Catálogo de Dados contém referências a dados que são usados como fontes e destinos para trabalhos de extração, transformação e carregamento (ETL) em AWS Glue. As informações no Catálogo de Dados são armazenadas como tabelas de metadados, e cada tabela especifica um único armazenamento de dados. Você executa um AWS Glue
rastreador para fazer um inventário dos dados em vários tipos de armazenamento de dados. Você adiciona classificadores integrados e personalizados ao rastreador, e esses classificadores inferem o formato e o esquema dos dados pessoais. Em seguida, o rastreador grava os metadados no Catálogo de Dados. Uma tabela de metadados centralizada pode facilitar a resposta às solicitações dos titulares dos dados (como o direito ao apagamento), pois agrega estrutura e previsibilidade em diferentes fontes de dados pessoais em seu ambiente. AWS Para obter um exemplo abrangente de como usar o catálogo de dados para responder automaticamente a essas solicitações, consulte Como lidar com solicitações de eliminação de dados em seu data lake com o Amazon S3 Find and
AWS Glue DataBrew
AWS Glue DataBrewajuda você a limpar e normalizar dados e pode realizar transformações nos dados, como remover ou mascarar informações de identificação pessoal e criptografar campos de dados confidenciais em pipelines de dados. Você também pode mapear visualmente a linhagem dos seus dados para entender as várias fontes de dados e as etapas de transformação pelas quais os dados passaram. Esse recurso se torna cada vez mais importante à medida que sua organização trabalha para entender e rastrear melhor a proveniência dos dados pessoais. DataBrew ajuda você a mascarar dados pessoais durante a preparação dos dados. Você pode detectar dados pessoais como parte de um trabalho de criação de perfil de dados e coletar estatísticas, como o número de colunas que podem conter dados pessoais e categorias em potencial. Em seguida, você pode usar técnicas integradas de transformação de dados reversíveis ou irreversíveis, incluindo substituição, hashing, criptografia e decodificação, tudo isso sem escrever nenhum código. Em seguida, você pode usar os conjuntos de dados limpos e mascarados a jusante para tarefas de análise, relatórios e aprendizado de máquina. Algumas das técnicas de mascaramento de dados disponíveis em DataBrew incluem:
-
Hash — Aplique funções de hash aos valores da coluna.
-
Substituição — substitua dados pessoais por outros valores que pareçam autênticos.
-
Anulação ou exclusão — substitua um campo específico por um valor nulo ou exclua a coluna.
-
Mascaramento — Use a mistura de caracteres ou mascare certas partes nas colunas.
A seguir estão as técnicas de criptografia disponíveis:
-
Criptografia determinística — aplique algoritmos de criptografia determinística aos valores da coluna. A criptografia determinística sempre produz o mesmo texto cifrado para um valor.
-
Criptografia probabilística — aplique algoritmos de criptografia probabilística aos valores da coluna. A criptografia probabilística produz texto cifrado diferente cada vez que é aplicada.
Para obter uma lista completa das receitas de transformação de dados pessoais fornecidas em DataBrew, consulte Etapas da receita de informações de identificação pessoal (PII).
AWS Glue Qualidade de dados
AWS Glue A qualidade de dados ajuda você a automatizar e operacionalizar a entrega de dados de alta qualidade em todos os pipelines de dados, de forma proativa, antes de serem entregues aos consumidores de dados. AWS Glue O Data Quality fornece análise estatística de problemas de qualidade de dados em seus pipelines de dados, pode acionar alertas na Amazon EventBridge e fazer recomendações de regras de qualidade para remediação. AWS Glue A qualidade de dados também oferece suporte à criação de regras com uma linguagem específica do domínio para que você possa criar regras personalizadas de qualidade de dados.
AWS Key Management Service
AWS Key Management Service (AWS KMS) ajuda você a criar e controlar chaves criptográficas para ajudar a proteger seus dados. AWS KMS usa módulos de segurança de hardware para proteger e validar AWS KMS keys sob o Programa de Validação de Módulos Criptográficos FIPS 140-2. Para obter mais informações sobre como esse serviço é usado em um contexto de segurança, consulte a Arquitetura AWS de referência de segurança.
AWS KMS se integra à maioria dos Serviços da AWS que oferecem criptografia, e você pode usar chaves KMS em seus aplicativos que processam e armazenam dados pessoais. Você pode usar AWS KMS para ajudar a atender a uma variedade de seus requisitos de privacidade e proteger dados pessoais, incluindo:
-
Usando chaves gerenciadas pelo cliente para maior controle sobre força, rotação, expiração e outras opções.
-
Usando chaves dedicadas gerenciadas pelo cliente para proteger dados pessoais e segredos que permitem acesso a dados pessoais.
-
Definir níveis de classificação de dados e designar pelo menos uma chave dedicada gerenciada pelo cliente por nível. Por exemplo, você pode ter uma chave para criptografar dados operacionais e outra para criptografar dados pessoais.
-
Impedindo o acesso não intencional entre contas às chaves do KMS.
-
Armazenar chaves KMS dentro do Conta da AWS mesmo recurso a ser criptografado.
-
Implementando a separação de tarefas para administração e uso de chaves KMS. Para obter mais informações, consulte Como usar o KMS e o IAM para habilitar controles de segurança independentes para dados criptografados no S3
(postagem do AWS blog). -
Impondo a rotação automática de chaves por meio de grades de proteção preventivas e reativas.
Por padrão, as chaves KMS são armazenadas e só podem ser usadas na região em que foram criadas. Se sua organização tem requisitos específicos de residência e soberania de dados, considere se as chaves KMS multirregionais são apropriadas para seu caso de uso. As chaves multirregionais são chaves KMS para fins especiais Regiões da AWS que podem ser usadas de forma intercambiável. O processo de criação de uma chave multirregional move seu material de chave Região da AWS além das fronteiras internas AWS KMS, portanto, essa falta de isolamento regional pode não ser compatível com as metas de conformidade da sua organização. Uma forma de resolver isso é usar um tipo diferente de chave KMS, como uma chave gerenciada pelo cliente específica da região.
AWS Zonas Locais
Se precisar cumprir os requisitos de residência de dados, você pode implantar recursos que armazenam e processam dados pessoais de forma específica Regiões da AWS para dar suporte a esses requisitos. Você também pode usar as Zonas AWS Locais, que ajudam a colocar computação, armazenamento, banco de dados e outros AWS recursos selecionados perto de grandes centros populacionais e setoriais. Uma zona local é uma extensão de uma Região da AWS área geográfica próxima a uma grande área metropolitana. Você pode colocar tipos específicos de recursos em uma zona local, perto da região à qual a zona local corresponde. As Zonas Locais podem ajudar você a atender aos requisitos de residência de dados quando uma região não está disponível na mesma jurisdição legal. Ao usar Zonas Locais, considere os controles de residência de dados implantados em sua organização. Por exemplo, você pode precisar de um controle para evitar transferências de dados de uma zona local específica para outra região. Para obter mais informações sobre como usar SCPs para manter as grades de proteção de transferência de dados transfronteiriças, consulte Melhores práticas para gerenciar a residência de dados em Zonas AWS Locais usando controles de landing zone
AWS Enclaves Nitro
Considere sua estratégia de segmentação de dados a partir de uma perspectiva de processamento, como o processamento de dados pessoais com um serviço de computação, como o Amazon Elastic Compute Cloud (Amazon). EC2 A computação confidencial como parte de uma estratégia de arquitetura maior pode ajudá-lo a isolar o processamento de dados pessoais em um enclave de CPU isolado, protegido e confiável. Os enclaves são máquinas virtuais separadas, reforçadas e altamente restritas.AWS O Nitro Enclaves é um EC2 recurso da Amazon que pode ajudar você a criar esses ambientes computacionais isolados. Para obter mais informações, consulte O design de segurança do sistema AWS Nitro (AWS white paper).
O Nitro Enclaves implementa um kernel separado do kernel da instância principal. O kernel da instância principal não tem acesso ao enclave. Os usuários não podem usar SSH ou acessar remotamente os dados e aplicativos no enclave. Os aplicativos que processam dados pessoais podem ser incorporados ao enclave e configurados para usar o Vsock do enclave, o soquete que facilita a comunicação entre o enclave e a instância principal.
Um caso de uso em que o Nitro Enclaves pode ser útil é o processamento conjunto entre dois processadores de dados que estão separados Regiões da AWS e que podem não confiar um no outro. A imagem a seguir mostra como você pode usar um enclave para processamento central, uma chave KMS para criptografar os dados pessoais antes de serem enviados ao enclave e uma AWS KMS key política que verifica se o enclave que está solicitando a decodificação tem as medidas exclusivas em seu documento de atestado. Para obter mais informações e instruções, consulte Usando o atestado criptográfico com. AWS KMS Para ver um exemplo de política de chaves, consulte Exigir atestado para usar uma chave AWS KMS este guia.
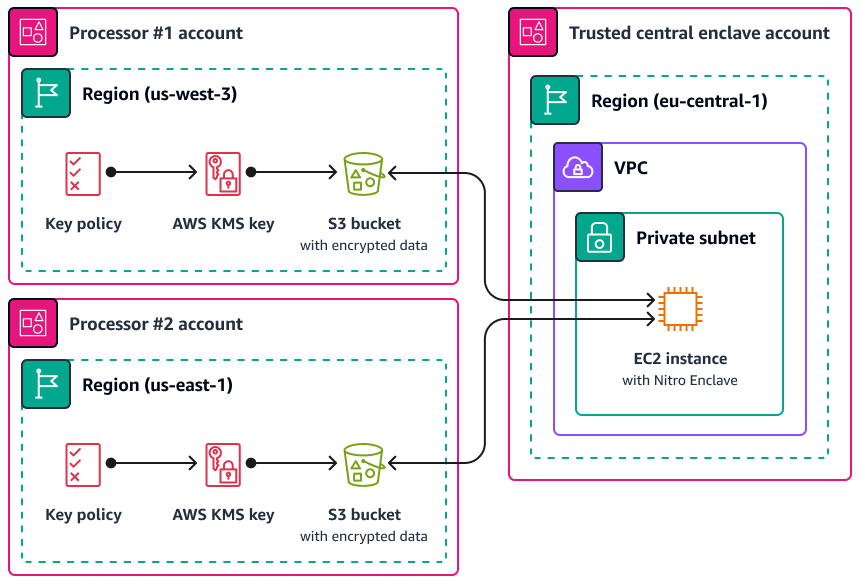
Com essa implementação, somente os respectivos processadores de dados e o enclave subjacente têm acesso aos dados pessoais em texto simples. O único lugar onde os dados são expostos, fora dos ambientes dos respectivos processadores de dados, é no próprio enclave, projetado para impedir o acesso e a adulteração.
AWS PrivateLink
Muitas organizações querem limitar a exposição de dados pessoais a redes não confiáveis. Por exemplo, se você quiser aprimorar a privacidade do design geral da arquitetura do aplicativo, poderá segmentar redes com base na sensibilidade dos dados (semelhante à separação lógica e física dos conjuntos de dados discutida na Serviços e recursos da AWS que ajudam a segmentar dados seção). AWS PrivateLinkajuda você a criar conexões unidirecionais e privadas de suas nuvens privadas virtuais (VPCs) para serviços fora da VPC. Usando AWS PrivateLink, você pode configurar conexões privadas dedicadas aos serviços que armazenam ou processam dados pessoais em seu ambiente; não há necessidade de se conectar a endpoints públicos e transferir esses dados por redes públicas não confiáveis. Quando você ativa pontos de extremidade de AWS PrivateLink serviço para os serviços dentro do escopo, não há necessidade de um gateway de internet, dispositivo NAT, endereço IP público, AWS Direct Connect conexão ou AWS Site-to-Site VPN conexão para se comunicar. Ao se conectar AWS PrivateLink a um serviço que fornece acesso a dados pessoais, você pode usar políticas de endpoint de VPC e grupos de segurança para controlar o acesso, de acordo com a definição do perímetro de dados
AWS Resource Access Manager
AWS Resource Access Manager (AWS RAM) ajuda você a compartilhar seus recursos com segurança Contas da AWS para reduzir a sobrecarga operacional e fornecer visibilidade e auditabilidade. Ao planejar sua estratégia de segmentação de várias contas, considere usar AWS RAM para compartilhar os armazenamentos de dados pessoais que você armazena em uma conta separada e isolada. Você pode compartilhar esses dados pessoais com outras contas confiáveis para fins de processamento. Em AWS RAM, você pode gerenciar permissões que definem quais ações podem ser executadas em recursos compartilhados. Todas as chamadas de API para AWS RAM estão logadas CloudTrail. Além disso, você pode configurar o Amazon CloudWatch Events para notificá-lo automaticamente sobre eventos específicos AWS RAM, como quando são feitas alterações em um compartilhamento de recursos.
Embora você possa compartilhar muitos tipos de AWS recursos com outras pessoas Contas da AWS usando políticas baseadas em recursos no IAM ou políticas de bucket no Amazon S3 AWS RAM , oferece vários benefícios adicionais para a privacidade. AWS fornece aos proprietários de dados visibilidade adicional sobre como e com quem os dados são compartilhados entre você Contas da AWS, incluindo:
-
Ser capaz de compartilhar um recurso com uma OU inteira em vez de atualizar manualmente as listas de contas IDs
-
Aplicação do processo de convite para iniciar o compartilhamento se a conta do consumidor não fizer parte da sua organização
-
Visibilidade de quais diretores específicos do IAM têm acesso a cada recurso individual
Se você já usou uma política baseada em recursos para gerenciar um compartilhamento de recursos e quiser usá-la AWS RAM em vez disso, use a operação da PromoteResourceShareCreatedFromPolicyAPI.
SageMaker Inteligência Artificial da Amazon
O Amazon SageMaker AI é um serviço gerenciado de aprendizado de máquina (ML) que ajuda você a criar e treinar modelos de ML e depois implantá-los em um ambiente hospedado pronto para produção. SageMaker A IA foi projetada para facilitar a preparação de dados de treinamento e a criação de recursos de modelo.
Monitor de modelos de SageMaker IA da Amazon
Muitas organizações consideram a deriva de dados ao treinar modelos de ML. O desvio de dados é uma variação significativa entre os dados de produção e os dados usados para treinar um modelo de ML ou uma mudança significativa nos dados de entrada ao longo do tempo. O desvio de dados pode reduzir a qualidade geral, a precisão e a imparcialidade das previsões do modelo de ML. Se a natureza estatística dos dados que um modelo de ML recebe na produção se afastar da natureza dos dados básicos nos quais ele foi treinado, a precisão das previsões poderá diminuir. O Amazon SageMaker AI Model Monitor pode monitorar continuamente a qualidade dos modelos de aprendizado de máquina Amazon SageMaker AI em produção e monitorar a qualidade dos dados. A detecção precoce e proativa do desvio de dados pode ajudá-lo a implementar ações corretivas, como modelos de reciclagem, auditoria de sistemas upstream ou correção de problemas de qualidade de dados. O Model Monitor pode aliviar a necessidade de monitorar modelos manualmente ou criar ferramentas adicionais.
Esclareça a Amazon SageMaker AI
O Amazon SageMaker AI Clarify fornece uma visão sobre o viés e a explicabilidade do modelo. SageMaker O AI Clarify é comumente usado durante a preparação dos dados do modelo de ML e na fase geral de desenvolvimento. Os desenvolvedores podem especificar atributos de interesse, como sexo ou idade, e o SageMaker AI Clarify executa um conjunto de algoritmos para detectar qualquer presença de viés nesses atributos. Depois que o algoritmo é executado, o SageMaker AI Clarify fornece um relatório visual com uma descrição das fontes e medidas de possíveis distorções para que você possa identificar as etapas para remediar a distorção. Por exemplo, em um conjunto de dados financeiros que contém apenas alguns exemplos de empréstimos comerciais para uma faixa etária em comparação com outras, SageMaker poderia sinalizar desequilíbrios para que você possa evitar um modelo que desfavoreça essa faixa etária. Você também pode verificar se há viés em modelos já treinados revisando suas previsões e monitorando continuamente esses modelos de ML em busca de viés. Por fim, o SageMaker AI Clarify é integrado ao Amazon SageMaker AI Experiments para fornecer um gráfico que explica quais recursos contribuíram mais para o processo geral de previsão de um modelo. Essas informações podem ser úteis para obter resultados de explicabilidade e podem ajudar a determinar se uma entrada específica do modelo tem mais influência do que deveria no comportamento geral do modelo.
Cartão SageMaker modelo Amazon
O Amazon SageMaker Model Card pode ajudá-lo a documentar detalhes críticos sobre seus modelos de ML para fins de governança e emissão de relatórios. Esses detalhes podem incluir o proprietário do modelo, o propósito geral, os casos de uso pretendidos, as suposições feitas, a classificação de risco de um modelo, os detalhes e métricas do treinamento e os resultados da avaliação. Para obter mais informações, consulte Explicabilidade do modelo com soluções de inteligência AWS artificial e aprendizado de máquina (AWS whitepaper).
AWS recursos que ajudam a gerenciar o ciclo de vida dos dados
Quando os dados pessoais não são mais necessários, você pode usar o ciclo de vida e as time-to-live políticas para dados em vários armazenamentos de dados diferentes. Ao configurar políticas de retenção de dados, considere os seguintes locais que podem conter dados pessoais:
-
Bancos de dados, como Amazon DynamoDB e Amazon Relational Database Service (Amazon RDS)
-
Buckets do Amazon S3
-
Registros de CloudWatch e CloudTrail
-
Dados em cache de migrações em AWS Database Migration Service (AWS DMS) e projetos AWS Glue DataBrew
-
Backups e instantâneos
O seguinte Serviços da AWS e os recursos a seguir podem ajudá-lo a configurar políticas de retenção de dados em seus AWS ambientes:
-
Ciclo de vida do Amazon S3 — Um conjunto de regras que define ações que o Amazon S3 aplica a um grupo de objetos. Na configuração do Amazon S3 Lifecyle, você pode criar ações de expiração, que definem quando o Amazon S3 exclui objetos expirados em seu nome. Para obter mais informações, consulte Gerenciar seu ciclo de vida de armazenamento.
-
Amazon Data Lifecycle Manager — Na Amazon EC2, crie uma política que automatize a criação, retenção e exclusão de snapshots do Amazon Elastic Block Store (Amazon EBS) e Amazon Machine Images () apoiados pelo EBS. AMIs
-
DynamoDB Time to Live (TTL) — Defina um timestamp por item que determine quando um item não é mais necessário. Logo após a data e a hora do timestamp especificado, o DynamoDB exclui o item da sua tabela.
-
Configurações de retenção de CloudWatch registros em Registros — Você pode ajustar a política de retenção de cada grupo de registros para um valor entre 1 dia e 10 anos.
-
AWS Backup— implante centralmente políticas de proteção de dados para configurar, gerenciar e governar sua atividade de backup em uma variedade de AWS recursos, incluindo buckets S3, instâncias de banco de dados RDS, tabelas do DynamoDB, volumes do EBS e muito mais. Aplique políticas de backup aos seus AWS recursos especificando os tipos de recursos ou forneça granularidade adicional aplicando com base nas tags de recursos existentes. Audite e emita relatórios sobre a atividade de backup em um console centralizado para ajudar a atender aos requisitos de conformidade de backup.
Serviços e recursos da AWS que ajudam a segmentar dados
A segmentação de dados é o processo pelo qual você armazena dados em contêineres separados. Isso pode ajudá-lo a fornecer medidas diferenciadas de segurança e autenticação para cada conjunto de dados e a reduzir o escopo do impacto da exposição em seu conjunto de dados geral. Por exemplo, em vez de armazenar todos os dados do cliente em um grande banco de dados, você pode segmentar esses dados em grupos menores e mais gerenciáveis.
Você pode usar a separação física e lógica para segmentar dados pessoais:
-
Separação física — O ato de armazenar dados em armazenamentos de dados separados ou distribuí-los em AWS recursos separados. Embora os dados estejam fisicamente separados, os dois recursos podem estar acessíveis aos mesmos diretores. É por isso que recomendamos combinar a separação física com a separação lógica.
-
Separação lógica — O ato de isolar dados usando controles de acesso. Diferentes funções de trabalho exigem diferentes níveis de acesso a subconjuntos de dados pessoais. Para ver um exemplo de política que implementa a separação lógica, consulte Conceda acesso a atributos específicos do Amazon DynamoDB este guia.
A combinação de uma separação lógica e física fornece flexibilidade, simplicidade e granularidade ao escrever políticas baseadas em identidade e recursos para oferecer suporte ao acesso diferenciado em todas as funções de trabalho. Por exemplo, pode ser operacionalmente complexo criar políticas que separem logicamente diferentes classificações de dados em um único bucket do S3. O uso de buckets S3 dedicados para cada classificação de dados simplifica a configuração e o gerenciamento de políticas.
