本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
個人資料 OU – PD 應用程式帳戶
我們希望聽到您的意見。請進行簡短的問卷 |
個人資料 (PD) 應用程式帳戶是您的組織託管收集和處理個人資料的服務。具體而言,您可能會將定義為個人資料的內容存放在此帳戶中。 AWS PRA 透過多層無伺服器 Web 架構示範許多隱私權組態範例。涉及到跨 AWS 登陸區域的操作工作負載時,隱私權組態不應視為one-size-fits-all解決方案。例如,您的目標是了解基礎概念、它們如何增強隱私權,以及您的組織如何將解決方案套用至您的特定使用案例和架構。
對於 AWS 帳戶 組織中收集、存放或處理個人資料的 ,您可以使用 AWS Organizations 和 AWS Control Tower 部署基礎和可重複的護欄。為這些帳戶建立專用組織單位 (OU) 至關重要。例如,您可能想要將資料駐留護欄套用至資料駐留是核心設計考量的 帳戶子集。對於許多組織,這些是存放和處理個人資料的帳戶。
您的組織可能支援專用資料帳戶,您可以在此存放個人資料集的權威來源。權威性資料來源是您存放主要資料版本的位置,這可能會被視為最可靠且準確的資料版本。例如,您可以將授權資料來源中的資料複製到其他位置,例如 PD Application 帳戶中的 Amazon Simple Storage Service (Amazon S3) 儲存貯體,這些儲存貯體用於存放訓練資料、一部分客戶資料和已修訂的資料。透過採取這種多帳戶方法,將資料帳戶中的完整和確定性個人資料集與 PD 應用程式帳戶中的下游消費者工作負載分開,您可以減少未經授權存取您的帳戶時的影響範圍。
下圖說明在 PD Application and Data 帳戶中設定 AWS 的安全性和隱私權服務。
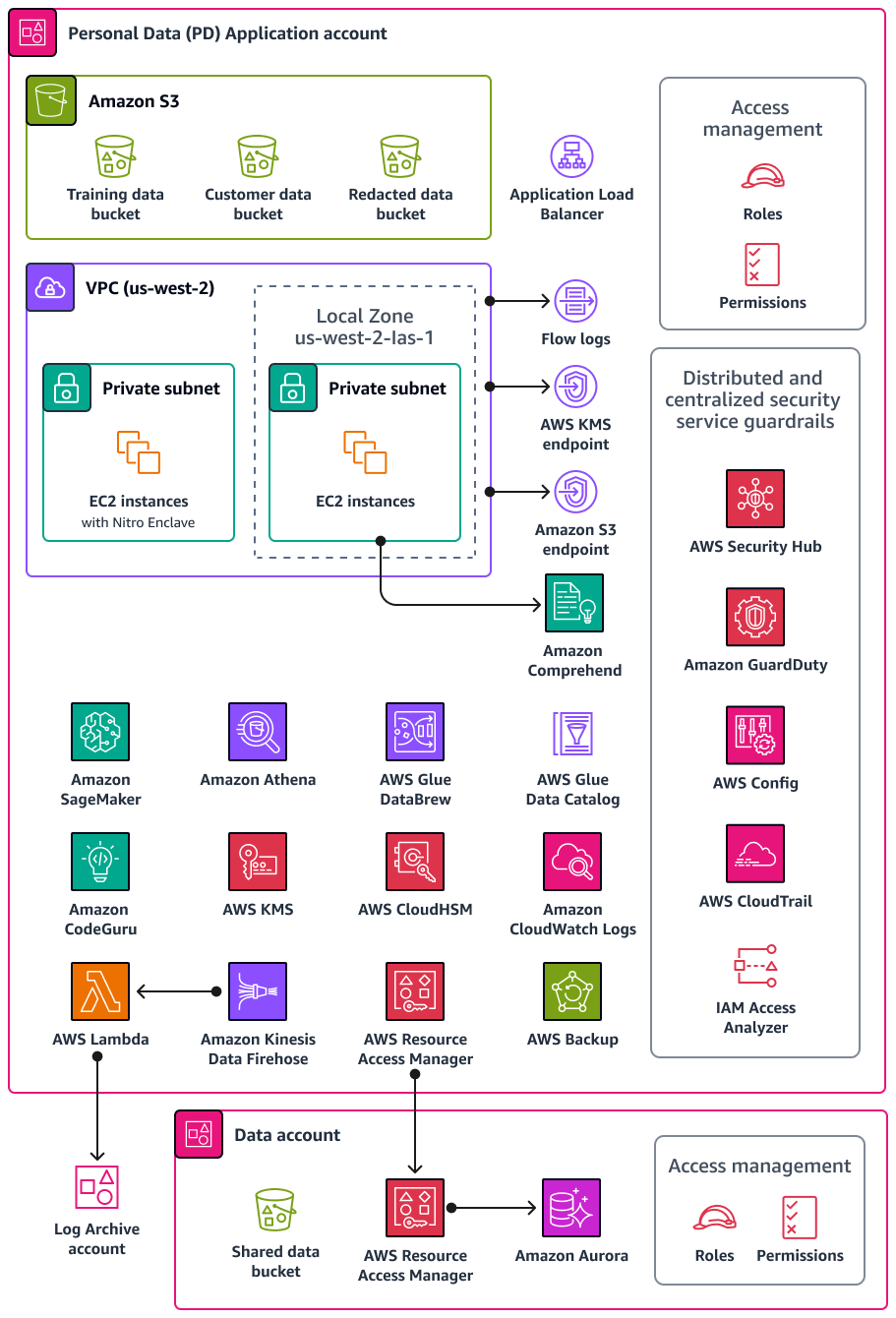
本節提供有關這些帳戶中所用下列項目 AWS 服務 的更多詳細資訊:
Amazon Athena
您也可以考慮資料查詢限制控制,以符合您的隱私權目標。Amazon Athena 是一種互動式查詢服務,可協助您使用標準 SQL 直接在 Amazon S3 中分析資料。您不需要將資料載入 Athena;它可直接處理存放在 S3 儲存貯體中的資料。
Athena 的常見使用案例是為資料分析團隊提供量身訂做且已消毒的資料集。如果資料集包含個人資料,您可以透過遮罩整個資料欄來清理資料集,而這些資料欄對資料分析團隊提供很少的價值。如需詳細資訊,請參閱使用 Amazon Athena 和 (部落格文章) 匿名和管理資料湖中的資料 AWS Lake Formation
如果您的資料轉換方法在 Athena 支援的函數之外需要額外的彈性,您可以定義自訂函數,稱為使用者定義的函數 (UDF)。您可以在提交至 Athena UDFs,並在其中執行 AWS Lambda。您可以在 SELECT和 FILTER SQL查詢中使用 UDFs,也可以在相同的查詢中叫用多個 UDFs。為了隱私權,您可以建立執行特定類型資料遮罩的 UDFs,例如只顯示資料欄中每個值的最後四個字元。
Amazon CloudWatch Logs
Amazon CloudWatch Logs 可協助您集中所有系統、應用程式和 AWS 服務 的日誌,以便您可以對其進行監控並安全地進行封存。在 CloudWatch Logs 中,您可以針對新的或現有的日誌群組使用資料保護政策,以協助將個人資料的揭露風險降至最低。資料保護政策可以偵測日誌中的敏感資料,例如個人資料。當使用者透過 存取日誌時,資料保護政策可以遮罩該資料 AWS Management Console。當使用者需要直接存取個人資料時,根據您的工作負載的整體用途規格,您可以為這些使用者指派logs:Unmask許可。您也可以建立全帳戶資料保護政策,並一致地將此政策套用至組織中的所有帳戶。這預設會為 CloudWatch Logs 中的所有目前和未來日誌群組設定遮罩。我們也建議您啟用稽核報告,並將其傳送至另一個日誌群組、Amazon S3 儲存貯體或 Amazon Data Firehose。這些報告包含每個日誌群組中資料保護問題清單的詳細記錄。
Amazon CodeGuru Reviewer
對於隱私權和安全性而言,許多組織在部署和部署後階段都支援持續合規至關重要。PRA AWS 會在處理個人資料之應用程式的部署管道中包含主動控制。Amazon CodeGuru Reviewer 可以偵測可能公開 Java、JavaScript 和 Python 程式碼中個人資料的潛在瑕疵。它為開發人員提供改善程式碼的建議。CodeGuru Reviewer 可以識別各種安全性、隱私權和一般最佳實務的瑕疵。如需詳細資訊,請參閱 Amazon CodeGuru 偵測器程式庫。它旨在與多個來源提供者合作,包括 Bitbucket AWS CodeCommit、GitHub 和 Amazon S3。CodeGuru Reviewer 可以偵測的一些隱私權相關瑕疵包括:
-
SQL 注入
-
不安全的 Cookie
-
缺少授權
-
用戶端 AWS KMS 重新加密
Amazon Comprehend
Amazon Comprehend 是一種自然語言處理 (NLP) 服務,使用機器學習在英文文字文件中發現寶貴的洞見和連線。Amazon Comprehend 可以偵測和修訂結構化、半結構化或非結構化文字文件中的個人資料。如需詳細資訊,請參閱《Amazon Comprehend 文件》中的個人身分識別資訊 (PII)。
您可以使用 AWS SDKs和 Amazon Comprehend API,將 Amazon Comprehend 與許多應用程式整合。例如,使用 Amazon Comprehend 來偵測和編輯 Amazon S3 Object Lambda 的個人資料。組織可以使用 S3 Object Lambda 將自訂程式碼新增至 Amazon S3 GET 請求,以修改和處理傳回應用程式的資料。S3 Object Lambda 可以篩選資料列、動態調整影像大小、修訂個人資料等。由 AWS Lambda 函數提供支援的程式碼會在由 完全管理的基礎設施上執行 AWS,因此不需要建立和存放資料的衍生複本或執行代理。您不需要變更應用程式,即可使用 S3 Object Lambda 轉換物件。您可以使用 中的 ComprehendPiiRedactionS3Object Lambda 函數 AWS Serverless Application Repository 來編輯個人資料。此函數使用 Amazon Comprehend 來偵測個人資料實體,並以星號取代這些實體。如需詳細資訊,請參閱《Amazon S3 S3 文件》中的使用 S3 Object Lambda 和 Amazon Comprehend 偵測和修訂 PII 資料。
由於 Amazon Comprehend 有許多透過 AWS SDKs進行應用程式整合的選項,因此您可以使用 Amazon Comprehend 來識別您收集、存放和處理資料之許多不同位置的個人資料。您可以使用 Amazon Comprehend ML 功能來偵測和編輯應用程式日誌
-
REPLACE_WITH_PII_ENTITY_TYPE會將每個 PII 實體取代為其類型。例如,Jane Doe 將被取代為 NAME。 -
MASK會以您選擇的字元 (!、#、$、%、&、 或 @) 取代 PII 實體中的字元。例如,Jane Doe 可以取代為 **** ***。
Amazon Data Firehose
Amazon Data Firehose 可用來擷取、轉換串流資料,並將資料載入下游服務,例如 Amazon Managed Service for Apache Flink 或 Amazon S3。Firehose 通常用於傳輸大量串流資料,例如應用程式日誌,而無需從頭開始建置處理管道。
您可以使用 Lambda 函數,在資料傳送至下游之前執行自訂或內建處理。為了隱私權,此功能支援資料最小化和跨邊界資料傳輸需求。例如,您可以使用 Lambda 和 Firehose 在多區域日誌資料集中於 Log Archive 帳戶中之前進行轉換。如需詳細資訊,請參閱 Biogen:多帳戶集中記錄解決方案
AWS Glue
維護包含個人資料的資料集是設計隱私
AWS Glue Data Catalog
AWS Glue Data Catalog 可協助您建立可維護的資料集。Data Catalog 包含資料參考,做為擷取、轉換和載入 (ETL) 任務的來源和目標 AWS Glue。Data Catalog 中的資訊會儲存為中繼資料資料表,而每個資料表都會指定單一資料存放區。您可以執行 AWS Glue 爬蟲程式,以清查各種資料存放區類型中的資料。您可以將內建和自訂分類器新增至爬蟲程式,這些分類器會推斷個人資料的資料格式和結構描述。爬蟲程式接著會將中繼資料寫入 Data Catalog。集中式中繼資料資料表可以更輕鬆地回應資料主體請求 (例如刪除權),因為它可新增環境中不同資料來源的結構和可預測性 AWS 。如需如何使用 Data Catalog 自動回應這些請求的完整範例,請參閱使用 Amazon S3 Find and Forget 處理資料湖中的資料清除請求
AWS Glue DataBrew
AWS Glue DataBrew 可協助您清理和標準化資料,並對資料執行轉換,例如移除或遮罩個人識別資訊,以及加密資料管道中的敏感資料欄位。您也可以視覺化地映射資料的譜系,以了解資料經過的各種資料來源和轉換步驟。隨著您的組織努力更好地了解和追蹤個人資料來源,此功能變得越來越重要。DataBrew 可協助您在資料準備期間遮罩個人資料。您可以在資料分析任務中偵測個人資料,並收集統計資料,例如可能包含個人資料和潛在類別的資料欄數。然後,您可以使用內建的可逆或不可逆資料轉換技術,包括替換、雜湊、加密和解密,而不需要撰寫任何程式碼。然後,您可以使用下游已清理和遮罩的資料集進行分析、報告和機器學習任務。DataBrew 中提供的一些資料遮罩技術包括:
-
雜湊:將雜湊函數套用至資料欄值。
-
替代 - 將個人資料取代為其他看起來真實的值。
-
剔除或刪除 – 將特定欄位取代為 null 值,或刪除資料欄。
-
遮罩 – 使用角色雜亂,或遮罩欄中的某些部分。
以下是可用的加密技術:
-
確定性加密 – 將確定性加密演算法套用至資料欄值。決定性加密一律會為值產生相同的加密文字。
-
概率加密 – 將概率加密演算法套用至資料欄值。機率式加密每次套用都會產生不同的加密文字。
如需 DataBrew 中提供的個人資料轉換配方的完整清單,請參閱個人識別資訊 (PII) 配方步驟。
AWS Glue 資料品質
AWS Glue Data Quality 可協助您主動自動化和操作跨資料管道交付的高品質資料,然後再交付給資料消費者。 AWS Glue Data Quality 提供跨資料管道的資料品質問題的統計分析,可在 Amazon EventBridge 中觸發警示,並提出品質規則的修補建議。 AWS Glue Data Quality 也支援使用網域特定語言建立規則,以便您可以建立自訂資料品質規則。
AWS Key Management Service
AWS Key Management Service (AWS KMS) 可協助您建立和控制密碼編譯金鑰,以協助保護您的資料。 AWS KMS 會使用硬體安全模組,根據 AWS KMS keys FIPS 140-2 密碼編譯模組驗證計畫來保護和驗證。如需如何在安全內容中使用此服務的詳細資訊,請參閱AWS 安全參考架構。
AWS KMS 與大多數提供加密 AWS 服務 的 整合,您可以在處理和儲存個人資料的應用程式中使用 KMS 金鑰。您可以使用 AWS KMS 來協助支援各種隱私權要求,並保護個人資料,包括:
-
使用客戶受管金鑰來更好地控制強度、輪換、過期和其他選項。
-
使用專用的客戶受管金鑰來保護允許存取個人資料的個人資料和秘密。
-
定義資料分類層級,並為每個層級指定至少一個專用客戶受管金鑰。例如,您可能有一個金鑰用於加密操作資料,另一個用於加密個人資料。
-
防止意外跨帳戶存取 KMS 金鑰。
-
將 KMS 金鑰存放在與要加密之資源 AWS 帳戶 相同的 內。
-
實作 KMS 金鑰管理和使用的責任分離。如需詳細資訊,請參閱如何使用 KMS 和 IAM 來啟用 S3 中加密資料的獨立安全控制
(AWS 部落格文章)。 -
透過預防性和被動護欄強制執行自動金鑰輪換。
根據預設,KMS 金鑰會存放,且只能在建立金鑰的區域中使用。如果您的組織對資料駐留和主權有特定要求,請考慮多區域 KMS 金鑰是否適合您的使用案例。多區域金鑰是不同 中的特殊用途 KMS 金鑰 AWS 區域 ,可互換使用。建立多區域金鑰的程序會將您的金鑰材料移至內部的 AWS 區域 邊界 AWS KMS,因此缺乏區域隔離可能與您組織的合規目標不相容。解決此問題的方法之一是使用不同類型的 KMS 金鑰,例如區域特定的客戶受管金鑰。
AWS 本機區域
如果您需要遵守資料駐留要求,您可以部署資源來存放和處理特定 的個人資料 AWS 區域 ,以支援這些要求。您也可以使用 AWS Local Zones,這可協助您將運算、儲存、資料庫和其他特定 AWS 資源放在接近大型人口和產業中心的位置。Local Zone 是 的延伸 AWS 區域 ,其地理位置接近大型都會區。您可以在 Local Zone 所對應的區域附近,將特定類型的資源放在 Local Zone 內。當區域在相同的法律司法管轄區內無法使用時,Local Zones 可協助您滿足資料駐留要求。當您使用 Local Zones 時,請考慮在您的組織中部署的資料駐留控制。例如,您可能需要 控制項,以防止從特定 Local Zone 傳輸資料到另一個區域。如需如何使用 SCPs 維護跨邊界資料傳輸護欄的詳細資訊,請參閱使用登陸區域控制管理 AWS 本機區域中資料駐留的最佳實務
AWS Nitro Enclaves
從處理角度考慮您的資料分割策略,例如使用 Amazon Elastic Compute Cloud (Amazon EC2) 等運算服務處理個人資料。作為較大架構策略的一部分,機密運算可協助您在隔離、受保護且信任的 CPU 環境中隔離個人資料處理。Enclaves 是獨立、強化且受到高度限制的虛擬機器。AWS Nitro Enclaves 是一種 Amazon EC2 功能,可協助您建立這些隔離的運算環境。如需詳細資訊,請參閱 AWS Nitro 系統的安全設計 (AWS 白皮書)。
Nitro Enclaves 部署與父執行個體核心分開的核心。父執行個體的核心無法存取 enclave。使用者無法 SSH 或遠端存取 enclave 中的資料和應用程式。處理個人資料的應用程式可以內嵌在 enclave 中,並設定為使用 enclave 的 Vsock,這是促進 enclave 與父執行個體之間通訊的通訊端。
Nitro Enclaves 可發揮用意的一個使用案例是,兩個資料處理器之間的聯合處理是分開的, AWS 區域 而這些資料處理器可能不信任彼此。下圖顯示如何使用 enclave 進行集中處理、在傳送至 enclave 之前加密個人資料的 KMS 金鑰,以及驗證請求解密的 enclave 在其認證文件中具有唯一測量 AWS KMS key 的政策。如需詳細資訊和說明,請參閱搭配 使用密碼編譯證明 AWS KMS。如需範例金鑰政策,請參閱本指南需要證明才能使用 AWS KMS 金鑰中的 。
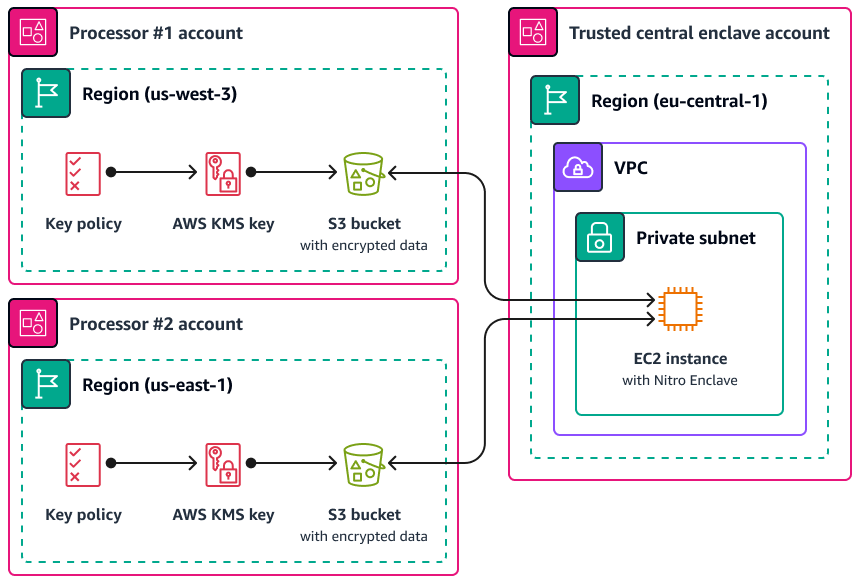
透過此實作,只有個別的資料處理者和基礎 enclave 可以存取純文字個人資料。資料暴露在各自資料處理者環境之外的唯一位置,是在 enclave 本身,其設計可防止存取和竄改。
AWS PrivateLink
許多組織想要限制對不受信任網路的暴露。例如,如果您想要增強整體應用程式架構設計的隱私權,您可以根據資料敏感度來分割網路 (類似於AWS 服務和功能,可協助將資料分段一節中討論的資料集邏輯和實體分離)。 AWS PrivateLink可協助您建立從虛擬私有雲端 (VPCs) 到 VPC 外部服務的單向私有連線。使用 AWS PrivateLink,您可以設定專屬私有連線,以連線至 服務,以存放或處理環境中的個人資料;不需要連線至公有端點,並透過不受信任的公有網路傳輸此資料。當您為範圍內 AWS PrivateLink 服務啟用服務端點時,不需要網際網路閘道、NAT 裝置、公有 IP 地址、 AWS Direct Connect 連線或 AWS Site-to-Site VPN 連線即可進行通訊。當您使用 AWS PrivateLink 連線到提供個人資料存取權的服務時,您可以根據您組織的資料周邊
AWS Resource Access Manager
AWS Resource Access Manager (AWS RAM) 可協助您安全地跨 共用資源 AWS 帳戶 ,以減少營運開銷並提供可見性和可稽核性。當您規劃多帳戶分割策略時,請考慮使用 AWS RAM 來共用存放在個別隔離帳戶中的個人資料存放區。您可以與其他可信任的帳戶共用該個人資料,以便處理。在 中 AWS RAM,您可以管理許可,以定義可以在共用資源上執行的動作。所有對 的 API 呼叫 AWS RAM 都會記錄在 CloudTrail 中。此外,您可以設定 Amazon CloudWatch Events 自動通知您 中的特定事件 AWS RAM,例如變更資源共享的時間。
雖然您可以透過在 IAM AWS 帳戶 中使用以資源為基礎的政策或 Amazon S3 中的儲存貯體政策,與其他 共用許多類型的 AWS 資源,但 為隱私權 AWS RAM 提供額外的優點。 為資料擁有者 AWS 提供如何和與誰共用資料的更多可見性 AWS 帳戶,包括:
-
能夠與整個 OU 共用資源,而不是手動更新帳戶 IDs清單
-
如果消費者帳戶不是您組織的一部分,則強制執行共用啟動的邀請程序
-
特定 IAM 主體可存取每個個別資源的可見性
如果您先前已使用以資源為基礎的政策來管理資源共享,並想要 AWS RAM 改用 ,請使用 PromoteResourceShareCreatedFromPolicy API 操作。
Amazon SageMaker AI
Amazon SageMaker AI 是一項受管機器學習 (ML) 服務,可協助您建置和訓練 ML 模型,然後將模型部署到生產就緒的託管環境中。SageMaker AI 旨在讓您更輕鬆地準備訓練資料和建立模型功能。
Amazon SageMaker AI 模型監控
許多組織在訓練 ML 模型時考慮資料偏離。資料偏離是生產資料與用於訓練 ML 模型的資料之間的有意義的變化,或輸入資料隨時間有意義的變更。資料偏離可以降低 ML 模型預測的整體品質、準確性和公平性。如果 ML 模型在生產環境中接收的資料統計性質偏離訓練的基準資料性質,預測的準確性可能會下降。Amazon SageMaker AI Model Monitor 可以持續監控生產環境中 Amazon SageMaker AI 機器學習模型的品質,並監控資料品質。及早主動偵測資料偏離可協助您實作修正動作,例如重新訓練模型、稽核上游系統或修正資料品質問題。模型監控可以減輕手動監控模型或建置其他工具的需求。
Amazon SageMaker AI Clarify
Amazon SageMaker AI Clarify 提供模型偏差和可解釋性的洞見。SageMaker AI Clarify 常用於 ML 模型資料準備和整體開發階段。開發人員可以指定感興趣的屬性,例如性別或年齡,而 SageMaker AI Clarify 會執行一組演算法來偵測這些屬性中是否有任何偏差。演算法執行後,SageMaker AI Clarify 會提供視覺報告,其中包含可能偏差的來源和測量說明,讓您可以識別修復偏差的步驟。例如,在只包含幾個商業貸款範例的金融資料集中,SageMaker 可以標記不平衡,以便您避免不利於該年齡群組的模型。您也可以透過檢閱其預測,以及持續監控這些 ML 模型是否有偏差,來檢查已訓練的模型是否有偏差。最後,SageMaker AI Clarify 已與 Amazon SageMaker AI Experiments 整合,以提供圖形說明哪些功能對模型的整體預測過程貢獻最大。此資訊可能有助於滿足可解釋性結果,而且可協助您判斷特定模型輸入是否比對整體模型行為的影響更大。
Amazon SageMaker 模型卡
Amazon SageMaker 模型卡可協助您記錄 ML 模型的重要詳細資訊,以供控管和報告之用。這些詳細資訊可能包括模型擁有者、一般用途、預期使用案例、所做的假設、模型的風險評分、訓練詳細資訊和指標,以及評估結果。如需詳細資訊,請參閱使用 AWS 人工智慧和Machine Learning解決方案的模型解釋能力 (AWS 白皮書)。
AWS 有助於管理資料生命週期的功能
當不再需要個人資料時,您可以針對許多不同資料存放區中的資料使用生命週期和time-to-live政策。設定資料保留政策時,請考慮下列可能包含個人資料的位置:
-
資料庫,例如 Amazon DynamoDB 和 Amazon Relational Database Service (Amazon RDS)
-
Amazon S3 儲存貯體
-
來自 CloudWatch 和 CloudTrail 的日誌
-
AWS Database Migration Service (AWS DMS) 和 AWS Glue DataBrew 專案中遷移的快取資料
-
備份和快照
下列 AWS 服務 和 功能可協助您在 AWS 環境中設定資料保留政策:
-
Amazon S3 生命週期 – 定義 Amazon S3 套用至一組物件之動作的一組規則。在 Amazon S3 Lifecyle 組態中,您可以建立過期動作,定義 Amazon S3 何時代表您刪除過期的物件。如需詳細資訊,請參閱管理儲存生命週期。
-
Amazon Data Lifecycle Manager – 在 Amazon EC2 中,建立可自動建立、保留和刪除 Amazon Elastic Block Store (Amazon EBS) 快照和 EBS 支援的 Amazon Machine Image (AMIs) 的政策。
-
DynamoDB 存留時間 (TTL) – 定義每個項目時間戳記,以決定何時不再需要項目。在指定時間戳記的日期和時間之後不久,DynamoDB 會從資料表中刪除項目。
-
CloudWatch Logs 中的日誌保留設定 – 您可以將每個日誌群組的保留政策調整為介於 1 天到 10 年之間的值。
-
AWS Backup – 集中部署資料保護政策,以設定、管理和管理各種 AWS 資源的備份活動,包括 S3 儲存貯體、RDS 資料庫執行個體、DynamoDB 資料表、EBS 磁碟區等。指定 AWS 資源類型,或根據現有的資源標籤套用,藉此將備份政策套用至您的資源。從集中式主控台稽核和報告備份活動,以協助滿足備份合規要求。
AWS 服務和功能,可協助將資料分段
資料分割是您將資料存放在不同容器中的程序。這可協助您為每個資料集提供差異化的安全性和身分驗證措施,並減少整體資料集的暴露影響範圍。例如,您可以將此資料分割為更小、更易於管理的群組,而不是將所有客戶資料儲存在一個大型資料庫中。
您可以使用實體和邏輯分隔來分割個人資料:
-
實體分離 – 將資料儲存在個別資料存放區中,或將資料分散至個別 AWS 資源的行為。雖然資料是實體分隔的,但兩個資源都可以由相同的主體存取。這就是為什麼我們建議將物理分離與邏輯分離結合。
-
邏輯分離 – 使用存取控制隔離資料的行為。不同的任務函數需要對個人資料子集的不同層級存取權。如需實作邏輯分離的範例政策,請參閱本指南授予特定 Amazon DynamoDB 屬性的存取權中的 。
在撰寫以身分為基礎的和資源為基礎的政策時,邏輯和物理分隔的組合可提供靈活性、簡單性和精細性,以支援跨任務職能的差異化存取。例如,建立在邏輯上將不同資料分類分開到單一 S3 儲存貯體的政策,在操作上可能很複雜。針對每個資料分類使用專用 S3 儲存貯體,可簡化政策組態和管理。
