What is Amazon S3?
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. Customers of all sizes and industries can use Amazon S3 to store and protect any amount of data for a range of use cases, such as data lakes, websites, mobile applications, backup and restore, archive, enterprise applications, IoT devices, and big data analytics. Amazon S3 provides management features so that you can optimize, organize, and configure access to your data to meet your specific business, organizational, and compliance requirements.
Note
For more information about using the Amazon S3 Express One Zone storage class with directory buckets, see S3 Express One Zone and Working with directory buckets.
Topics
Features of Amazon S3
Storage classes
Amazon S3 offers a range of storage classes designed for different use cases. For example, you can store mission-critical production data in S3 Standard or S3 Express One Zone for frequent access, save costs by storing infrequently accessed data in S3 Standard-IA or S3 One Zone-IA, and archive data at the lowest costs in S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval, and S3 Glacier Deep Archive.
Amazon S3 Express One Zone is a high-performance, single-zone Amazon S3 storage class that is purpose-built to deliver consistent, single-digit millisecond data access for your most latency-sensitive applications. S3 Express One Zone is the lowest latency cloud object storage class available today, with data access speeds up to 10x faster and with request costs 50 percent lower than S3 Standard. S3 Express One Zone is the first S3 storage class where you can select a single Availability Zone with the option to co-locate your object storage with your compute resources, which provides the highest possible access speed. Additionally, to further increase access speed and support hundreds of thousands of requests per second, data is stored in a new bucket type: an Amazon S3 directory bucket. For more information, see S3 Express One Zone and Working with directory buckets.
You can store data with changing or unknown access patterns in S3 Intelligent-Tiering, which optimizes storage costs by automatically moving your data between four access tiers when your access patterns change. These four access tiers include two low-latency access tiers optimized for frequent and infrequent access, and two opt-in archive access tiers designed for asynchronous access for rarely accessed data.
For more information, see Understanding and managing Amazon S3 storage classes.
Storage management
Amazon S3 has storage management features that you can use to manage costs, meet regulatory requirements, reduce latency, and save multiple distinct copies of your data for compliance requirements.
-
S3 Lifecycle – Configure a lifecycle configuration to manage your objects and store them cost effectively throughout their lifecycle. You can transition objects to other S3 storage classes or expire objects that reach the end of their lifetimes.
-
S3 Object Lock – Prevent Amazon S3 objects from being deleted or overwritten for a fixed amount of time or indefinitely. You can use Object Lock to help meet regulatory requirements that require write-once-read-many (WORM) storage or to simply add another layer of protection against object changes and deletions.
-
S3 Replication – Replicate objects and their respective metadata and object tags to one or more destination buckets in the same or different AWS Regions for reduced latency, compliance, security, and other use cases.
-
S3 Batch Operations – Manage billions of objects at scale with a single S3 API request or a few clicks in the Amazon S3 console. You can use Batch Operations to perform operations such as Copy, Invoke AWS Lambda function, and Restore on millions or billions of objects.
Access management and security
Amazon S3 provides features for auditing and managing access to your buckets and objects. By default, S3 buckets and the objects in them are private. You have access only to the S3 resources that you create. To grant granular resource permissions that support your specific use case or to audit the permissions of your Amazon S3 resources, you can use the following features.
-
S3 Block Public Access – Block public access to S3 buckets and objects. By default, Block Public Access settings are turned on at the bucket level. We recommend that you keep all Block Public Access settings enabled unless you know that you need to turn off one or more of them for your specific use case. For more information, see Configuring block public access settings for your S3 buckets.
-
AWS Identity and Access Management (IAM) – IAM is a web service that helps you securely control access to AWS resources, including your Amazon S3 resources. With IAM, you can centrally manage permissions that control which AWS resources users can access. You use IAM to control who is authenticated (signed in) and authorized (has permissions) to use resources.
-
Bucket policies – Use IAM-based policy language to configure resource-based permissions for your S3 buckets and the objects in them.
-
Amazon S3 access points – Configure named network endpoints with dedicated access policies to manage data access at scale for shared datasets in Amazon S3.
-
Access control lists (ACLs) – Grant read and write permissions for individual buckets and objects to authorized users. As a general rule, we recommend using S3 resource-based policies (bucket policies and access point policies) or IAM user policies for access control instead of ACLs. Policies are a simplified and more flexible access control option. With bucket policies and access point policies, you can define rules that apply broadly across all requests to your Amazon S3 resources. For more information about the specific cases when you'd use ACLs instead of resource-based policies or IAM user policies, see Managing access with ACLs.
-
S3 Object Ownership – Take ownership of every object in your bucket, simplifying access management for data stored in Amazon S3. S3 Object Ownership is an Amazon S3 bucket-level setting that you can use to disable or enable ACLs. By default, ACLs are disabled. With ACLs disabled, the bucket owner owns all the objects in the bucket and manages access to data exclusively by using access-management policies.
-
IAM Access Analyzer for S3 – Evaluate and monitor your S3 bucket access policies, ensuring that the policies provide only the intended access to your S3 resources.
Data processing
To transform data and trigger workflows to automate a variety of other processing activities at scale, you can use the following features.
-
S3 Object Lambda – Add your own code to S3 GET, HEAD, and LIST requests to modify and process data as it is returned to an application. Filter rows, dynamically resize images, redact confidential data, and much more.
-
Event notifications – Trigger workflows that use Amazon Simple Notification Service (Amazon SNS), Amazon Simple Queue Service (Amazon SQS), and AWS Lambda when a change is made to your S3 resources.
Storage logging and monitoring
Amazon S3 provides logging and monitoring tools that you can use to monitor and control how your Amazon S3 resources are being used. For more information, see Monitoring tools.
Automated monitoring tools
-
Amazon CloudWatch metrics for Amazon S3 – Track the operational health of your S3 resources and configure billing alerts when estimated charges reach a user-defined threshold.
-
AWS CloudTrail – Record actions taken by a user, a role, or an AWS service in Amazon S3. CloudTrail logs provide you with detailed API tracking for S3 bucket-level and object-level operations.
Manual monitoring tools
-
Server access logging – Get detailed records for the requests that are made to a bucket. You can use server access logs for many use cases, such as conducting security and access audits, learning about your customer base, and understanding your Amazon S3 bill.
-
AWS Trusted Advisor – Evaluate your account by using AWS best practice checks to identify ways to optimize your AWS infrastructure, improve security and performance, reduce costs, and monitor service quotas. You can then follow the recommendations to optimize your services and resources.
Analytics and insights
Amazon S3 offers features to help you gain visibility into your storage usage, which empowers you to better understand, analyze, and optimize your storage at scale.
-
Amazon S3 Storage Lens – Understand, analyze, and optimize your storage. S3 Storage Lens provides 60+ usage and activity metrics and interactive dashboards to aggregate data for your entire organization, specific accounts, AWS Regions, buckets, or prefixes.
-
Storage Class Analysis – Analyze storage access patterns to decide when it's time to move data to a more cost-effective storage class.
-
S3 Inventory with Inventory reports – Audit and report on objects and their corresponding metadata and configure other Amazon S3 features to take action in Inventory reports. For example, you can report on the replication and encryption status of your objects. For a list of all the metadata available for each object in Inventory reports, see Amazon S3 Inventory list.
Strong consistency
Amazon S3 provides strong read-after-write consistency for PUT and DELETE requests of objects in your Amazon S3 bucket in all AWS Regions. This behavior applies to both writes of new objects as well as PUT requests that overwrite existing objects and DELETE requests. In addition, read operations on Amazon S3 Select, Amazon S3 access control lists (ACLs), Amazon S3 Object Tags, and object metadata (for example, the HEAD object) are strongly consistent. For more information, see Amazon S3 data consistency model.
How Amazon S3 works
Amazon S3 is an object storage service that stores data as objects, hierarchical data, or tabular data within buckets. An object is a file and any metadata that describes the file. A bucket is a container for objects.
To store your data in Amazon S3, you first create a bucket and specify a bucket name and AWS Region. Then, you upload your data to that bucket as objects in Amazon S3. Each object has a key (or key name), which is the unique identifier for the object within the bucket.
S3 provides features that you can configure to support your specific use case. For example, you can use S3 Versioning to keep multiple versions of an object in the same bucket, which allows you to restore objects that are accidentally deleted or overwritten.
Buckets and the objects in them are private and can be accessed only if you explicitly grant access permissions. You can use bucket policies, AWS Identity and Access Management (IAM) policies, access control lists (ACLs), and S3 Access Points to manage access.
Topics
Buckets
Amazon S3 supports four types of buckets—general purpose buckets, directory buckets, table buckets, and vector buckets. Each type of bucket provides a unique set of features for different use cases.
General purpose buckets – General purpose buckets are recommended for most use cases and access patterns and are the original S3 bucket type. A general purpose bucket is a container for objects stored in Amazon S3, and you can store any number of objects in a bucket and across all storage classes (except for S3 Express One Zone), so you can redundantly store objects across multiple Availability Zones. For more information, see Creating, configuring, and working with Amazon S3 general purpose buckets.
By default, general purpose buckets exist in a global namespace, which means that each bucket name must be unique across all AWS accounts in all the AWS Regions within a partition. A partition is a grouping of Regions. AWS currently has four partitions: aws (Standard Regions), aws-cn (China Regions), aws-us-gov (AWS GovCloud (US)), and aws-eusc (European Sovereign Cloud). When you create a general purpose bucket, you can choose to create a bucket in the shared global namespace or you can choose to create a bucket in your account regional namespace. Your account regional namespace is a subdivision of the global namespace that only your account can create buckets in. New general purpose buckets created in your account regional namespace are unique to your account and can never be re-created by another account. For more information on bucket namespaces, see Namespaces for general purpose buckets.
Note
By default, all general purpose buckets are private. However, you can grant public access to general purpose buckets. You can control access to general purpose buckets at the bucket, prefix (folder), or object tag level. For more information, see Access control in Amazon S3.
Directory buckets – Recommended for low-latency use cases and data-residency use cases. By default, you can create up to 100 directory buckets in your AWS account, with no limit on the number of objects that you can store in a directory bucket. Directory buckets organize objects into hierarchical directories (prefixes) instead of the flat storage structure of general purpose buckets. This bucket type has no prefix limits and individual directories can scale horizontally. For more information, see Working with directory buckets.
-
For low-latency use cases, you can create a directory bucket in a single AWS Availability Zone to store data. Directory buckets in Availability Zones support the S3 Express One Zone storage class. With S3 Express One Zone, your data is redundantly stored on multiple devices within a single Availability Zone. The S3 Express One Zone storage class is recommended if your application is performance sensitive and benefits from single-digit millisecond
PUTandGETlatencies. To learn more about creating directory buckets in Availability Zones, see High performance workloads. -
For data-residency use cases, you can create a directory bucket in a single AWS Dedicated Local Zone (DLZ) to store data. In Dedicated Local Zones, you can create S3 directory buckets to store data in a specific data perimeter, which helps support your data residency and isolation use cases. Directory buckets in Local Zones support the S3 One Zone-Infrequent Access (S3 One Zone-IA; Z-IA) storage class. To learn more about creating directory buckets in Local Zones, see Data residency workloads.
Note
Directory buckets have all public access disabled by default. This behavior can't be changed. You can't grant access to objects stored in directory buckets. You can grant access only to your directory buckets. For more information, see Authenticating and authorizing requests.
Table buckets – Recommended for storing tabular data, such as daily purchase transactions, streaming sensor data, or ad impressions. Tabular data represents data in columns and rows, like in a database table. Table buckets provide S3 storage that's optimized for analytics and machine learning workloads, with features designed to continuously improve query performance and reduce storage costs for tables. S3 Tables are purpose-built for storing tabular data in the Apache Iceberg format. You can query tabular data in S3 Tables with popular query engines, including Amazon Athena, Amazon Redshift, and Apache Spark. By default, you can create up to 10 table buckets per AWS account per AWS Region and up to 10,000 tables per table bucket. For more information, see Working with S3 Tables and table buckets.
Note
All table buckets and tables are private and can't be made public. These resources can only be accessed by users who are explicitly granted access. To grant access, you can use IAM resource-based policies for table buckets and tables, and IAM identity-based policies for users and roles. For more information, see Security for S3 Tables.
Vector buckets – S3 vector buckets are a type of Amazon S3 bucket that are purpose-built to store and query vectors. Vector buckets use dedicated API operations to write and query vector data efficiently. With S3 vector buckets, you can store vector embeddings for machine learning models, perform similarity searches, and integrate with services like Amazon Bedrock and Amazon OpenSearch.
S3 vector buckets organize data using vector indexes, which are resources within a bucket that store and organize vector data for efficient similarity search. Each vector index can be configured with specific dimensions, distance metrics (like cosine similarity), and metadata configurations to optimize for your specific use case. For more information, see Working with S3 Vectors and vector buckets.
Additional information about all bucket types
When you create a bucket, you enter a bucket name and choose the AWS Region where the bucket will reside. After you create a bucket, you cannot change the name of the bucket or its Region. Bucket names must follow the following bucket naming rules:
Buckets also:
-
Organize the Amazon S3 namespace at the highest level. For general purpose buckets, this namespace is
S3. For directory buckets, this namespace iss3express. For table buckets, this namespace iss3tables. -
Identify the account responsible for storage and data transfer charges.
-
Serve as the unit of aggregation for usage reporting.
Objects
Objects are the fundamental entities stored in Amazon S3. Objects consist of object
data and metadata. The metadata is a set of name-value pairs that describe the
object. These pairs include some default metadata, such as the date last modified,
and standard HTTP metadata, such as Content-Type. You can also specify
custom metadata at the time that the object is stored.
Every object is contained in a bucket. For example, if the object named
photos/puppy.jpg is stored in the
amzn-s3-demo-bucket general purpose bucket in the US West (Oregon)
Region, then it is addressable by using the URL
https://amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpg.
For more information, see Accessing a
Bucket.
An object is uniquely identified within a bucket by a key (name) and a version ID (if S3 Versioning is enabled on the bucket). For more information about objects, see Amazon S3 objects overview.
Keys
An object key (or key name) is the unique identifier for an object within a bucket. Every object in a bucket has exactly one key. The combination of a bucket, object key, and optionally, version ID (if S3 Versioning is enabled for the bucket) uniquely identify each object. So you can think of Amazon S3 as a basic data map between "bucket + key + version" and the object itself.
Every object in Amazon S3 can be uniquely addressed through the combination of the web service
endpoint, bucket name, key, and optionally, a version. For example, in the URL
https://,
amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpgamzn-s3-demo-bucketphotos/puppy.jpg is the key.
For more information about object keys, see Naming Amazon S3 objects.
S3 Versioning
You can use S3 Versioning to keep multiple variants of an object in the same bucket. With S3 Versioning, you can preserve, retrieve, and restore every version of every object stored in your buckets. You can easily recover from both unintended user actions and application failures.
For more information, see Retaining multiple versions of objects with S3 Versioning.
Version ID
When you enable S3 Versioning in a bucket, Amazon S3 generates a unique version ID for
each object added to the bucket. Objects that already existed in the bucket at the
time that you enable versioning have a version ID of null. If you
modify these (or any other) objects with other operations, such as CopyObject and PutObject, the new objects
get a unique version ID.
For more information, see Retaining multiple versions of objects with S3 Versioning.
Bucket policy
A bucket policy is a resource-based AWS Identity and Access Management (IAM) policy that you can use to grant access permissions to your bucket and the objects in it. Only the bucket owner can associate a policy with a bucket. The permissions attached to the bucket apply to all of the objects in the bucket that are owned by the bucket owner. Bucket policies are limited to 20 KB in size.
Bucket policies use JSON-based access policy language that is standard across AWS. You can use bucket policies to add or deny permissions for the objects in a bucket. Bucket policies allow or deny requests based on the elements in the policy, including the requester, S3 actions, resources, and aspects or conditions of the request (for example, the IP address used to make the request). For example, you can create a bucket policy that grants cross-account permissions to upload objects to an S3 bucket while ensuring that the bucket owner has full control of the uploaded objects. For more information, see Examples of Amazon S3 bucket policies.
In your bucket policy, you can use wildcard characters on Amazon Resource Names
(ARNs) and other values to grant permissions to a subset of objects. For example,
you can control access to groups of objects that begin with a common prefix or end with a given extension, such as
.html.
S3 access points
Amazon S3 access points are named network endpoints with dedicated access policies that
describe how data can be accessed using that endpoint. Access points are attached to an
underlying data source, such as a general purpose bucket, directory bucket, or a FSx for OpenZFS volume, that you can use to
perform S3 object operations, such as GetObject and
PutObject. Access points simplify managing data access at scale for
shared datasets in Amazon S3.
Each access point has its own access point policy. You can configure Block Public Access settings for each access point attached to a bucket. To restrict Amazon S3 data access to a private network, you can also configure any access point to accept requests only from a virtual private cloud (VPC).
For more information about access points for general purpose buckets, see Managing access to shared datasets with access points. For more information about access points for directory buckets, see Managing access to shared datasets in directory buckets with access points.
Access control lists (ACLs)
You can use ACLs to grant read and write permissions to authorized users for individual general purpose buckets and objects. Each general purpose bucket and object has an ACL attached to it as a subresource. The ACL defines which AWS accounts or groups are granted access and the type of access. ACLs are an access control mechanism that predates IAM. For more information about ACLs, see Access control list (ACL) overview.
S3 Object Ownership is an Amazon S3 bucket-level setting that you can use to both control ownership of the objects that are uploaded to your bucket and to disable or enable ACLs. By default, Object Ownership is set to the Bucket owner enforced setting, and all ACLs are disabled. When ACLs are disabled, the bucket owner owns all the objects in the bucket and manages access to them exclusively by using access-management policies.
A majority of modern use cases in Amazon S3 no longer require the use of ACLs. We recommend that you keep ACLs disabled, except in circumstances where you need to control access for each object individually. With ACLs disabled, you can use policies to control access to all objects in your bucket, regardless of who uploaded the objects to your bucket. For more information, see Controlling ownership of objects and disabling ACLs for your bucket.
Regions
You can choose the geographical AWS Region where Amazon S3 stores the buckets that you create. You might choose a Region to optimize latency, minimize costs, or address regulatory requirements. Objects stored in an AWS Region never leave the Region unless you explicitly transfer or replicate them to another Region. For example, objects stored in the Europe (Ireland) Region never leave it.
Note
You can access Amazon S3 and its features only in the AWS Regions that are enabled for your account. For more information about enabling a Region to create and manage AWS resources, see Managing AWS Regions in the AWS General Reference.
For a list of Amazon S3 Regions and endpoints, see Regions and endpoints in the AWS General Reference.
Amazon S3 data consistency model
Amazon S3 provides strong read-after-write consistency for PUT and DELETE requests of objects in your Amazon S3 bucket in all AWS Regions. This behavior applies to both writes to new objects as well as PUT requests that overwrite existing objects and DELETE requests. In addition, read operations on Amazon S3 Select, Amazon S3 access controls lists (ACLs), Amazon S3 Object Tags, and object metadata (for example, the HEAD object) are strongly consistent.
Updates to a single key are atomic. For example, if you make a PUT request to an existing key from one thread and perform a GET request on the same key from a second thread concurrently, you will get either the old data or the new data, but never partial or corrupt data.
Amazon S3 achieves high availability by replicating data across multiple servers within AWS data centers. If a PUT request is successful, your data is safely stored. Any read (GET or LIST request) that is initiated following the receipt of a successful PUT response will return the data written by the PUT request. Here are examples of this behavior:
-
A process writes a new object to Amazon S3 and immediately lists keys within its bucket. The new object appears in the list.
-
A process replaces an existing object and immediately tries to read it. Amazon S3 returns the new data.
-
A process deletes an existing object and immediately tries to read it. Amazon S3 does not return any data because the object has been deleted.
-
A process deletes an existing object and immediately lists keys within its bucket. The object does not appear in the listing.
Note
-
Amazon S3 does not support object locking for concurrent writers. If two PUT requests are simultaneously made to the same key, the request with the latest timestamp wins. If this is an issue, you must build an object-locking mechanism into your application.
-
Updates are key-based. There is no way to make atomic updates across keys. For example, you cannot make the update of one key dependent on the update of another key unless you design this functionality into your application.
Bucket configurations have an eventual consistency model. Specifically, this means that:
-
If you delete a bucket and immediately list all buckets, the deleted bucket might still appear in the list.
-
If you enable versioning on a bucket for the first time, it might take a short amount of time for the change to be fully propagated. We recommend that you wait for 15 minutes after enabling versioning before issuing write operations (PUT or DELETE requests) on objects in the bucket.
Concurrent applications
This section provides examples of behavior to be expected from Amazon S3 when multiple clients are writing to the same items.
In this example, both W1 (write 1) and W2 (write 2) finish before the start of R1
(read 1) and R2 (read 2). Because S3 is strongly consistent, R1 and R2 both return
color = ruby.
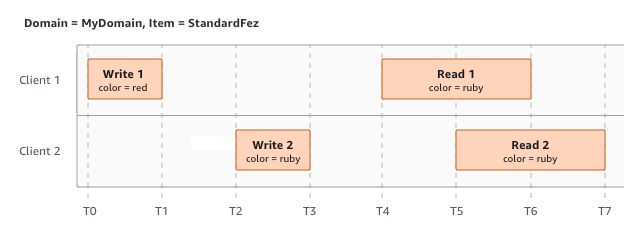
In the next example, W2 does not finish before the start of R1. Therefore, R1
might return color = ruby or color = garnet. However,
because W1 and W2 finish before the start of R2, R2 returns color =
garnet.
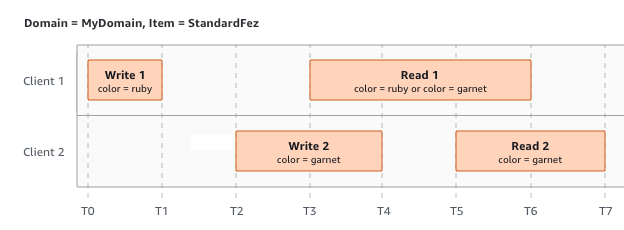
In the last example, W2 begins before W1 has received an acknowledgment. Therefore, these writes are considered concurrent. Amazon S3 internally uses last-writer-wins semantics to determine which write takes precedence. However, the order in which Amazon S3 receives the requests and the order in which applications receive acknowledgments cannot be predicted because of various factors, such as network latency. For example, W2 might be initiated by an Amazon EC2 instance in the same Region, while W1 might be initiated by a host that is farther away. The best way to determine the final value is to perform a read after both writes have been acknowledged.

Related services
After you load your data into Amazon S3, you can use it with other AWS services. The following are the services that you might use most frequently:
-
Amazon Elastic Compute Cloud (Amazon EC2)
– Provides secure and scalable computing capacity in the AWS Cloud. Using Amazon EC2 eliminates your need to invest in hardware upfront, so you can develop and deploy applications faster. You can use Amazon EC2 to launch as many or as few virtual servers as you need, configure security and networking, and manage storage. -
Amazon EMR
– Helps businesses, researchers, data analysts, and developers easily and cost-effectively process vast amounts of data. Amazon EMR uses a hosted Hadoop framework running on the web-scale infrastructure of Amazon EC2 and Amazon S3. -
AWS Transfer Family
– Provides fully managed support for file transfers directly into and out of Amazon S3 or Amazon Elastic File System (Amazon EFS) using Secure Shell (SSH) File Transfer Protocol (SFTP), File Transfer Protocol over SSL (FTPS), and File Transfer Protocol (FTP).
Accessing Amazon S3
You can work with Amazon S3 in any of the following ways:
AWS Management Console
The console is a web-based user interface for managing Amazon S3 and AWS resources. If you've signed up for an AWS account, you can access the Amazon S3 console by signing into the AWS Management Console and choosing S3 from the AWS Management Console home page.
AWS Command Line Interface
You can use the AWS command line tools to issue commands or build scripts at your system's command line to perform AWS (including S3) tasks.
The AWS Command Line Interface (AWS CLI)
AWS SDKs
AWS provides SDKs (software development kits) that consist of libraries and sample code
for various programming languages and platforms (Java, Python, Ruby, .NET, iOS,
Android, and so on). The AWS SDKs provide a convenient way to create programmatic
access to S3 and AWS. Amazon S3 is a REST service. You can send requests to Amazon S3 using
the AWS SDK libraries, which wrap the underlying Amazon S3 REST API and simplify your
programming tasks. For example, the SDKs take care of tasks such as calculating
signatures, cryptographically signing requests, managing errors, and retrying
requests automatically. For information about the AWS SDKs, including how to
download and install them, see Tools for
AWS
Every interaction with Amazon S3 is either authenticated or anonymous. If you are using the AWS SDKs, the libraries compute the signature for authentication from the keys that you provide. For more information about how to make requests to Amazon S3, see Making requests .
Amazon S3 REST API
The architecture of Amazon S3 is designed to be programming language-neutral, using AWS-supported interfaces to store and retrieve objects. You can access S3 and AWS programmatically by using the Amazon S3 REST API. The REST API is an HTTP interface to Amazon S3. With the REST API, you use standard HTTP requests to create, fetch, and delete buckets and objects.
To use the REST API, you can use any toolkit that supports HTTP. You can even use a browser to fetch objects, as long as they are anonymously readable.
The REST API uses standard HTTP headers and status codes, so that standard browsers and toolkits work as expected. In some areas, we have added functionality to HTTP (for example, we added headers to support access control). In these cases, we have done our best to add the new functionality in a way that matches the style of standard HTTP usage.
If you make direct REST API calls in your application, you must write the code to compute the signature and add it to the request. For more information about how to make requests to Amazon S3, see Making requests in the Amazon S3 API Reference.
Note
SOAP API support over HTTP is deprecated, but it is still available over HTTPS. Newer Amazon S3 features are not supported for SOAP. We recommend that you use either the REST API or the AWS SDKs.
Paying for Amazon S3
Pricing for Amazon S3 is designed so that you don't have to plan for the storage requirements of your application. Most storage providers require you to purchase a predetermined amount of storage and network transfer capacity. In this scenario, if you exceed that capacity, your service is shut off or you are charged high overage fees. If you do not exceed that capacity, you pay as though you used it all.
Amazon S3 charges you only for what you actually use, with no hidden fees and no overage
charges. This model gives you a variable-cost service that can grow with your business
while giving you the cost advantages of the AWS infrastructure. For more information,
see Amazon S3 Pricing
When you sign up for AWS, your AWS account is automatically signed up for all
services in AWS, including Amazon S3. However, you are charged only for the services that
you use. If you are a new Amazon S3 customer, you can get started with Amazon S3 for free. For
more information, see AWS free tier
To see your bill, go to the Billing and Cost Management Dashboard in the AWS Billing and Cost Management console
PCI DSS compliance
Amazon S3 supports the processing, storage, and transmission
of credit card data by a merchant or service provider, and has been
validated as being compliant with Payment Card Industry (PCI) Data Security Standard (DSS).
For more information about PCI DSS, including how to request a copy of the AWS PCI Compliance Package,
see PCI DSS Level 1
