Amazon S3 とは
Amazon Simple Storage Service (Amazon S3) は、業界をリードするスケーラビリティ、データ可用性、セキュリティ、およびパフォーマンスを提供するオブジェクトストレージサービスです。あらゆる規模や業界のお客様が、Amazon S3 を使用して、データレイク、ウェブサイト、モバイルアプリケーション、バックアップおよび復元、アーカイブ、エンタープライズアプリケーション、IoT デバイス、ビッグデータ分析など、広範なユースケースのデータを容量にかかわらず、保存して保護することができます。Amazon S3 には、特定のビジネス、組織、コンプライアンスの要件を満たすために、データへのアクセスを最適化、整理、設定できる管理機能があります。
注記
Amazon S3 Express One Zone ストレージクラスをディレクトリバケットで使用する方法の詳細については、「S3 Express One Zone」と「ディレクトリバケットの使用」を参照してください。
トピック
Amazon S3 の機能
ストレージクラス
Amazon S3 では、さまざまなユースケース向けに、幅広いストレージクラスが提供されています。例えば、ミッションクリティカルな本番環境のデータを S3 Standard または S3 Express One Zone に保存して頻繁にアクセスしたり、アクセス頻度の低いデータを S3 標準 – IA または S3 One Zone-IA に保存してコストを節約したり、S3 Glacier Instant Retrieval、S3 Glacier Flexible Retrieval、S3 Glacier Deep Archive に最も低いコストでデータをアーカイブしたりできます。
Amazon S3 Express One Zone は、最もレイテンシーの影響を受けやすいアプリケーションに 1 桁のミリ秒単位で一貫したデータアクセスを提供することを目的として構築された、高パフォーマンスのシングルアベイラビリティーゾーンの Amazon S3 ストレージ クラスです。S3 Express One Zone は、現在入手可能なレイテンシーが最も低いクラウドオブジェクトストレージクラスで、データアクセス速度は最大 10 倍速く、リクエストコストは S3 スタンダードよりも 50% 低減されます。S3 Express One Zone は、オブジェクトストレージをコンピュートリソースと同じ場所に配置するオプションを備えた単一のアベイラビリティーゾーンを選択できる最初の S3 ストレージクラスです。これにより、最高レベルのアクセス速度を実現できます。アクセス速度をさらに向上させ、1 秒あたり数十万ものリクエストをサポートするために、データは新しいバケットタイプ、つまり Amazon S3 ディレクトリバケットに保存されます。詳細については、「S3 Express One Zone」および「ディレクトリバケットの使用」を参照してください。
S3 Intelligent-Tiering では、変更する、または不明なアクセスパターンを持つデータを保存できます。これにより、アクセスパターンが変更されたときに 4 つのアクセス層間でデータを自動的に移動することで、ストレージコストを最適化できます。4 つのアクセス階層にある、高頻度のアクセスと低頻度のアクセス用に最適化された 2 つの低レイテンシーのアクセス階層と、稀にしかアクセスされないデータ向けに設計された非同期アクセス用の 2 つのオプトインアーカイブアクセス階層があります。
詳細については、「Amazon S3 ストレージクラスの理解と管理」を参照してください。
ストレージ管理
Amazon S3 には、コストの管理、規制要件への対応、レイテンシーの削減、コンプライアンス要件のためのデータの複数の個別コピーの保存で使用できるストレージ管理機能があります。
-
S3 ライフサイクル – オブジェクトを管理し、ライフサイクルを通じてコスト効率の高い方法で保存できるようにライフサイクル設定を使用します。オブジェクトを他の S3 ストレージクラスに移行したり、ライフタイムが終了したオブジェクトを期限切れにすることができます。
-
S3 オブジェクトロック – Amazon S3 オブジェクトが固定期間または無期限に削除または上書きされるのを防止します。オブジェクトロックを使用して、write-once-read-many (WORM) ストレージを必要とする規制要件を満たしたり、オブジェクトの変更や削除に対する保護レイヤーを追加したりできます。
-
S3 レプリケーション – オブジェクトおよびそれぞれのメタデータタグとオブジェクトタグを、同じまたは異なる AWS リージョン にある 1 つまたは複数のレプリケーション先バケットにレプリケートして、レイテンシーの削減、コンプライアンス、セキュリティ、その他のユースケースで活用できます。
-
S3 バッチ操作 – 1 つの S3 API リクエストまたは Amazon S3 コンソールで数回クリックするだけで、数十億のオブジェクトを大規模に管理できます。バッチ操作を使用すると、次のようなオペレーションを実行できます。コピー、AWS Lambda 関数の呼び出し、数百万または数十億のオブジェクトの復元。
アクセス管理とセキュリティ
Amazon S3 には、バケットとオブジェクトへのアクセスを監査および管理する機能があります。デフォルトでは、S3 バケットとオブジェクトはプライベートです。作成した S3 リソースにのみアクセスできます。以下の機能を使用して、特定のユースケースをサポートする詳細なリソース許可を付与したり、Amazon S3 リソースの許可を監査したりできます。
-
S3 ブロックパブリックアクセス – S3 バケットおよびオブジェクトへのパブリックアクセスをブロックします。デフォルトでは、[パブリックアクセスをブロック] 設定はバケットレベルで有効になっています。ユースケースでオフにする必要のある設定が 1 つ以上あることがわかっている場合を除き、すべての [パブリックアクセスをブロック] 設定を有効にしておくことをお勧めします。詳細については、「S3 バケットへのパブリックアクセスブロック設定の構成」を参照してください。
-
AWS Identity and Access Management (IAM) — IAM は、AWS リソース (Amazon S3 リソースなど) へのアクセスを安全に管理するためのウェブサービスです。IAM を使用すると、ユーザーがアクセスできる AWS のリソースを制御するアクセス許可を集中管理できます。IAM を使用して、誰を認証 (サインイン) し、誰にリソースの使用を認可する (アクセス許可を付与する) かを制御します。
-
バケットポリシー – IAM ベースのポリシー言語を使用して、S3 バケットとその中のオブジェクトに対するリソースベースの許可を設定します。
-
Amazon S3 アクセスポイント — 専用アクセスポリシーを持つ名前付きネットワークエンドポイントを設定して、Amazon S3 の共有データセットへの大規模なデータアクセスを管理します。
-
アクセスコントロールリスト (ACL) – 個々のバケットおよびオブジェクトに対する読み取りおよび書き込みの許可を、承認されたユーザーに付与します。原則として、アクセスコントロールには ACL ではなく S3 リソースベースのポリシー (バケットポリシーとアクセスポイントポリシー) または IAM ユーザーポリシーを使用することをお勧めします。ポリシーとは、よりシンプルで柔軟なアクセス制御のオプションです。バケットポリシーとアクセスポイントポリシーを使用すると、Amazon S3 リソースに対するすべてのリクエストに広く適用されるルールを定義できます。リソースベースのポリシーまたは IAM ユーザーポリシーの代わりに ACL を使用する場合の特定のケースの詳細については、「ACL によるアクセス管理」を参照してください。
-
S3 オブジェクト所有権 - バケット内のすべてのオブジェクトの所有権を取得し、Amazon S3 に保存されているデータのアクセス管理を簡素化します。S3 オブジェクト所有権は、Amazon S3 バケットレベルの設定で、ACL を無効または有効にするのに使用できます。デフォルトでは、ACL は無効になっています。ACL を無効にすると、バケット所有者はバケット内のすべてのオブジェクトを所有し、アクセス管理ポリシーのみを使用してデータへのアクセスを管理します。
-
IAM Access Analyzer for S3 – S3 バケットアクセスポリシーを評価およびモニタリングし、ポリシーが S3 リソースへの意図したアクセスのみを提供することを確認します。
データ処理
データを変換し、ワークフローをトリガーして、他のさまざまな処理アクティビティを大規模に自動化するには、次の機能を使用できます。
-
S3 Object Lambda – S3 GET、HEAD、LIST リクエストに独自のコードを追加して、データがアプリケーションに返されるときにそのデータを変更および処理できます。行のフィルタリング、画像の動的なサイズ変更、機密データの編集などを行います。
-
イベント通知 – S3 リソースに変更が加えられると、Amazon Simple Notification Service (Amazon SNS)、Amazon Simple Queue Service (Amazon SQS)、および AWS Lambda を使用するワークフローをトリガーします。
ストレージのログ記録とモニタリング
Amazon S3 には、Amazon S3 リソースの使用状況をモニタリングおよびコントロールするために使用できるロギングおよびモニタリングツールが用意されています。詳細については、「モニタリングツール 」を参照してください。
自動モニタリングツール
-
Amazon S3 の Amazon CloudWatch メトリクス – TS3 リソースのオペレーション状態を追跡し、推定請求額がユーザー定義のしきい値に達したときに請求アラートを設定します。
-
AWS CloudTrail – ユーザー、ロール、またはAmazon S3 で AWS のサービス によって行われるアクションを記録します。CloudTrail ログを使用すると、S3 バケットレベルおよびオブジェクトレベルのオペレーションの詳細な API 追跡が可能になります。
手動モニタリングツール
-
サーバーアクセスログ – バケットに対するリクエストの詳細が記録されます。サーバーアクセスのログ記録を使用して、セキュリティとアクセスの監査、カスタマーベースに関するラーニング、Amazon S3 請求書の把握などの多くのユースケースに対応できます。
-
AWSTrusted Advisor – AWS ベストプラクティスチェックを使用してアカウントを評価し、AWS インフラストラクチャを最適化し、セキュリティとパフォーマンスを向上させ、コストを削減し、サービスクォータを監視する方法を特定します。その後、推奨事項に従って、サービスとリソースを最適化できます。
分析とインサイト
Amazon S3 には、ストレージの使用状況を可視化するための機能が用意されています。これにより、ストレージを大規模に理解、分析し、最適化することができます。
-
Amazon S3 Storage Lens – ストレージを理解、分析し、最適化します。S3 ストレージレンズは、使用状況およびアクティビティに関する 60 以上のメトリクスとインタラクティブなダッシュボードを提供し、組織全体、特定のアカウント、AWS リージョン、バケット、またはプレフィックスに関するデータを集約します。
-
ストレージクラス分析 – ストレージアクセスパターンを分析して、よりコスト効果の高いストレージクラスにデータを移動するタイミングを決定します。
-
インベントリ付き S3 インベントリレポート – オブジェクトとそれに対応するメタデータを監査してレポートし、インベントリレポートでアクションを実行するように他の Amazon S3 機能を設定します。例えば、オブジェクトのレプリケーションと暗号化のステータスをレポートできます。インベントリレポートの各オブジェクトで使用できるすべてのメタデータのリストについては、「Amazon S3 インベントリリスト」を参照してください。
強力な整合性
Amazon S3 には、すべての AWS リージョン にある Amazon S3 バケットの、オブジェクトの PUT と DELETE に関する、書き込み後読み取りの強力な整合性があります。この動作は、新しいオブジェクトへの書き込みと、既存のオブジェクトを上書きする PUT、そして DELETE リクエストにも適用されます。さらに、Amazon S3 Select、Amazon S3 アクセスコントロールリスト (ACL)、Amazon S3 オブジェクトタグ、オブジェクトメタデータ (HEAD オブジェクトなど) での読み込みオペレーションには、強力な整合性があります。詳細については、「Amazon S3 のデータ整合性モデル」を参照してください。
Amazon S3 の仕組み
Amazon S3 は、データをオブジェクト、階層データ、または表形式データとしてバケット内に保存するオブジェクトストレージサービスです。オブジェクトとは、ファイルと、そのファイルを記述している任意のメタデータのことです。バケット とは、オブジェクトのコンテナのことです。
Amazon S3 にデータを保存するには、まずバケットを作成し、バケット名および AWS リージョン を指定します。次に、Amazon S3 のオブジェクトとしてそのバケットにデータをアップロードします。各オブジェクトには、キー(またはキー名) があります。これは、バケット内のオブジェクトの一意の識別子です。
S3 には、特定のユースケースをサポートするように設定できる機能があります。例えば、S3 Versioning を使用すると、オブジェクトの複数のバージョンを同じバケットに保持し、誤って削除または上書きされたオブジェクトを復元することができます。
バケットとその中のオブジェクトはプライベートであり、アクセス許可を明示的に付与した場合にのみアクセスできます。バケットポリシー、AWS Identity and Access Management(IAM) ポリシー、アクセスコントロールリスト (ACL)、および S3 アクセスポイントを使用して、アクセスを管理できます。
バケット
Amazon S3 は、汎用バケット、ディレクトリバケット、テーブルバケット、ベクトルバケットという 4 つのバケットタイプをサポートしています。バケットタイプごとに固有の機能セットが、さまざまなユースケース向けに用意されています。
汎用バケット は、ほとんどのユースケースやアクセスパターンに推奨される、オリジナルの S3 バケットタイプです。汎用バケットは、Amazon S3 に保存されているオブジェクトのコンテナであり、バケット内およびすべてのストレージクラス (S3 Express One Zone を除く) に任意の数のオブジェクトを保存できるため、複数のアベイラビリティーゾーンにオブジェクトを冗長的に保存できます。詳細については、「Amazon S3 汎用バケットの作成、設定、操作」を参照してください。
デフォルトでは、汎用バケットは名前空間に存在します。このため、各バケット名は、パーティション内のすべての AWS リージョンのすべての AWS アカウントにわたって一意である必要があります。パーティションは、リージョンのグループです。AWS には、現在、aws (標準リージョン)、aws-cn (中国リージョン)、aws-us-gov (AWS GovCloud (US))、aws-eusc (欧州ソブリンクラウド) の 4 つのパーティションがあります。汎用バケットを作成するときは、共有グローバル名前空間にバケットを作成するか、アカウントのリージョン名前空間にバケットを作成するかを選択できます。アカウントのリージョン名前空間は、アカウントのみがバケットを作成できるグローバル名前空間のサブディビジョンです。アカウントのリージョン名前空間で作成された新しい汎用バケットは、ご使用のアカウントに固有であり、別のアカウントで再作成することはできません。バケット名前空間の詳細については、「汎用バケットの名前空間」を参照してください。
注記
デフォルトでは、すべての汎用バケットはプライベートです。ただし、汎用バケットへのパブリックアクセスは許可できます。汎用バケットへのアクセスは、バケット、プレフィックス (フォルダ)、またはオブジェクトタグの各レベルで制御できます。詳細については、「Amazon S3 でのアクセスコントロール」を参照してください。
ディレクトリバケット – 低レイテンシーのユースケースとデータレジデンシーのユースケースに推奨されます。デフォルトでは、最大 100 個のディレクトリバケットを AWS アカウントに作成できます。ディレクトリバケット内に保存できるオブジェクトの数に制限はありません。ディレクトリバケットは、汎用バケットのフラットなストレージ構造の代わりに、オブジェクトを階層ディレクトリ (プレフィックス) に整理します。このバケットタイプにはプレフィックス制限がなく、個々のディレクトリを水平にスケールできます。詳細については、「ディレクトリバケットの使用」を参照してください。
-
低レイテンシーのユースケースでは、ディレクトリバケットを単一の AWS アベイラビリティーゾーンに作成してデータを保存できます。アベイラビリティーゾーンのディレクトリバケットは、S3 Express One Zone ストレージクラスをサポートしています。S3 Express One Zone では、データは単一のアベイラビリティーゾーン内で冗長的に複数のデバイスに保存されます。S3 Express One Zone ストレージクラスは、アプリケーションがパフォーマンスの影響を受けやすく、1 桁ミリ秒の
PUTおよびGETのレイテンシーから利点が得られる場合にお勧めします。アベイラビリティーゾーンでのディレクトリバケットの作成の詳細については、「高性能ワークロード」を参照してください。 -
データレジデンシーのユースケースでは、ディレクトリバケットを単一の AWS 専有ローカルゾーン (DLZ) に作成してデータを保存できます。専有ローカルゾーンでは、S3 ディレクトリバケットを作成して特定のデータ境界にデータを保存できるため、データレジデンシーと分離のユースケースをサポートするのに役立ちます。Local Zones のディレクトリバケットは、S3 One Zone-Infrequent Access (S3 One Zone-IA、Z-IA) ストレージクラスをサポートしています。ローカルゾーンでのディレクトリバケットの作成の詳細については、「データレジデンシーワークロード」を参照してください。
注記
ディレクトリバケットでは、すべてのパブリックアクセスがデフォルトで無効になります。この動作は変更できません。ディレクトリバケットに保存されているオブジェクトへのアクセスは付与できません。アクセスは、ディレクトリバケットにたいしてのみ付与できます。詳細については、「リクエストの認証と承認」を参照してください。
テーブルバケット – 毎日の購入トランザクション、ストリーミングセンサーデータ、広告インプレッションなどの表形式データの保存に推奨されます。表形式データは、データベーステーブルのように列と行のデータを表します。テーブルバケットは、分析ワークロードと機械学習ワークロード向けに最適化された S3 ストレージを提供し、クエリのパフォーマンスの向上とテーブルのストレージコストの削減を継続的に行うように設計された機能を備えています。S3 Tables は、表形式データを Apache Iceberg 形式で保存するための専用サービスです。S3 Tables の表形式データは、Amazon Athena、Amazon Redshift、Apache Spark などの一般的なクエリエンジンを使用してクエリできます。デフォルトでは、AWS リージョンごとに AWS アカウントあたり最大 10 個のテーブルバケットと、テーブルバケットごとに最大 10,000 個のテーブルを作成できます。詳細については、「S3 Tables とテーブルバケットの使用」を参照してください。
注記
すべてのテーブルバケットとテーブルはプライベートであり、公開することはできません。これらのリソースにアクセスできるのは、明示的にアクセス許可が与えられているユーザーのみです。アクセスを許可するには、テーブルバケットとテーブルには IAM リソースベースのポリシーを使用し、ユーザーとロールには IAM アイデンティティベースのポリシーを使用します。詳細については、「S3 Tables のセキュリティ」を参照してください。
ベクトルバケット – S3 ベクトルバケットは、ベクトルの保存とクエリ専用に構築された Amazon S3 バケットの一種です。ベクトルバケットは、専用 API オペレーションを使用してベクトルデータを効率的に書き込み、クエリします。S3 ベクトルバケットを使用すると、機械学習モデルのベクトル埋め込みを保存し、類似検索を実行し、Amazon Bedrock や Amazon OpenSearch などのサービスと統合できます。
S3 ベクトルバケットは、ベクトルインデックスを使用してデータを整理します。ベクトルインデックスは、効率的な類似検索のためにベクトルデータを保存および整理するバケット内のリソースです。各ベクトルインデックスは、特定のディメンション、距離メトリクス (コサイン類似度など)、メタデータ設定を構成して、特定のユースケースに合わせて最適化できます。詳細については、「S3 Vectors とベクトルバケットの操作」を参照してください。
すべてのバケットタイプに関する追加情報
バケットを作成するときは、バケット名を入力し、バケットが存在する AWS リージョン を選択します。一度バケットを作成したら、そのバケット名またはリージョンを変更することはできません。バケット名は、以下のバケット命名規則に従う必要があります。
バケットは、以下も行います。
-
最も高いレベルで Amazon S3 名前空間を編成します。汎用バケットの場合、この名前空間は
S3です。ディレクトリバケットの場合、この名前空間はs3expressです。テーブルバケットの場合、この名前空間はs3tablesです。 -
ストレージおよびデータ転送料金が課金されるアカウントを特定します。
-
使用状況レポートの集計単位として機能します。
オブジェクト
オブジェクトとは、Amazon S3 に保存される基本エンティティです。オブジェクトは、オブジェクトデータとメタデータで構成されます。メタデータは、オブジェクトを表現する名前と値のペアのセットです。これには最終更新日などのデフォルトメタデータや、Content-Type などの標準 HTTP メタデータが含まれます。また、オブジェクトの保存時にカスタムメタデータを指定することもできます。
すべてのオブジェクトはバケット内に保存されます。例えば、photos/puppy.jpg という名前のオブジェクトが米国西部 (オレゴン) リージョンの amzn-s3-demo-bucket 汎用バケットに保存されている場合、URL https://amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpg を使用してアドレス可能です。詳細については、「バケットへのアクセス」を参照してください。
オブジェクトは、バケット内でキー (名前)とバージョン ID(バケットで S3 バージョニングが有効になっている場合)によって一意に特定されます。オブジェクトの詳細については、Amazon S3 オブジェクトの概要 を参照してください。
キー
オブジェクトキー (または キー名) は、バケット内のオブジェクトの固有の識別子です。バケット内のすべてのオブジェクトは、厳密に 1 個のキーを持ちます。バケット、オブジェクトキー、およびオプションでバージョン ID(バケットで S3 バージョニングが有効になっている場合)の組み合わせによって、各オブジェクトが一意に識別されます。そのため、Amazon S3 を「バケット + キー + バージョン」とオブジェクト自体の間での基本データマップと考えることができます。
Amazon S3 内の各オブジェクトは、ウェブサービスエンドポイント、バケット名、キー、およびオプションでバージョンを組み合わせることで一意にアドレスを指定できます。例えば、https:// という URL で、「amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpgamzn-s3-demo-bucketphotos/puppy.jpg」がキーです。
オブジェクトキーの詳細については、「Amazon S3 オブジェクトに命名する」を参照してください。
S3 バージョニング
同じバケット内でオブジェクトの複数のバリアントを保持するには、S3 バージョニングを使用します。S3 バージョニングを使用すると、 バケットに保存されたあらゆるオブジェクトのあらゆるバージョンを保存、取得、復元することができます。バージョニングを使用すれば、意図しないユーザーアクションからもアプリケーション障害からも、簡単に復旧できます。
詳細については、「S3 バージョニングによる複数のバージョンのオブジェクトの保持」を参照してください。
バージョン ID
バケットで S3 バージョニングを有効にすると、Amazon S3 はバケットに追加されたすべてのオブジェクトに一意のバージョン ID を与えます。バージョニングを有効にした時点でバケットにすでに存在していたオブジェクトのバージョン ID は null です。これらの (またはその他の) オブジェクトを他のオペレーション (CopyObject および PutObject) で変更すると、新しいオブジェクトは一意のバージョン ID を取得します。
詳細については、「S3 バージョニングによる複数のバージョンのオブジェクトの保持」を参照してください。
バケットポリシー
バケットポリシーは、リソースベースの AWS Identity and Access Management (IAM) ポリシーを使用して、バケットとその中のオブジェクトへのアクセス許可を付与できます。バケット所有者のみが、ポリシーをバケットに関連付けることができます。バケットに添付された許可は、バケット所有者が所有するバケットのすべてのオブジェクトに適用されます。バケットポリシーのサイズは 20 KB に制限されています。
バケットポリシーは、AWS で標準である JSON ベースのアクセスポリシー言語を使用しています。バケットポリシーを使用して、バケット内のオブジェクトに対する許可を追加または拒否できます。バケットポリシーは、リクエスタ、S3 アクション、リソース、リクエストの側面または条件(リクエストの作成に使用された IP アドレスなど)など、ポリシー内のエレメントに基づいてリクエストを許可または拒否します。例えば、バケット所有者がアップロードされたオブジェクトを完全にコントロールできるように、S3 バケットにオブジェクトをアップロードするクロスアカウント許可を付与するバケットポリシーを作成できます。詳細については、Amazon S3 バケットポリシーの例 を参照してください。
バケットポリシーでは、Amazon リソースネーム (ARN) やその他の値に対してワイルドカード文字を使用して、オブジェクトのサブセットに対する許可を付与できます。例えば、共通のプレフィックスで始まるか、.html などの特定の拡張子で終わるオブジェクトのグループへのアクセスをコントロールできます。
S3 アクセスポイント
Amazon S3 アクセスポイントは、そのエンドポイントを使用してデータにアクセスする方法を説明する専用のアクセスポリシーを持つ名前付きネットワークエンドポイントです。アクセスポイントは、汎用バケット、ディレクトリバケット、FSx for OpenZFS ボリュームなどの基盤となるデータソースにアタッチされ、S3 オブジェクト操作 (GetObject や PutObject など) の実行に使用できます。アクセスポイントは、Amazon S3 の共有データセットへの大規模なデータアクセスの管理を簡素化します。
各アクセスポイントには独自のアクセスポイントポリシーがあります。バケットにアタッチされたアクセスポイントごとにブロックパブリックアクセス設定を設定できます。仮想プライベートクラウド (VPC) からのリクエストだけを受け入れるようにアクセスポイントを設定することで、プライベートネットワークへの Amazon S3 データアクセスを制限できます。
汎用バケットのアクセスポイントの詳細については、「アクセスポイントを使用した共有データセットへのアクセスの管理」を参照してください。ディレクトリバケットのアクセスポイントの詳細については、「アクセスポイントを使用したディレクトリバケット内の共有データセットへのアクセスの管理」を参照してください。
アクセスコントロールリスト (ACL)
ACL を使用して、個々の汎用バケットとオブジェクトの読み取りと書き込みのアクセス許可を認証ユーザーに付与できます。各汎用バケットとオブジェクトには、サブリソースとして ACL がアタッチされています。ACL は、アクセスを付与する先の AWS アカウントまたはグループと、アクセスのタイプを定義します。ACL は IAM よりも優先されるアクセスコントロールメカニズムです。ACL の詳細については、「アクセスコントロールリスト (ACL) の概要」を参照してください。
S3 オブジェクト所有権は、Amazon S3 バケットレベルの設定で、バケットにアップロードされる新しいオブジェクト所有権を制御し、ACL を無効にするのに使用できます。デフォルトでは、オブジェクト所有権はバケット所有者の強制設定に設定され、すべての ACL は無効になります。ACL を無効にすると、バケット所有者はバケット内のすべてのオブジェクトを所有し、アクセス管理ポリシーのみを使用してデータへのアクセスを管理します。
Amazon S3 の最新のユースケースの大部分では ACL を使用する必要がなくなっています。オブジェクトごとに個別にアクセスを制御する必要がある状況を除き、ACL は無効にしておくことをお勧めします。ACL を無効にすると、誰がオブジェクトをバケットにアップロードしたかに関係なく、ポリシーを使用してバケット内のすべてのオブジェクトへのアクセスを制御できます。詳細については、「オブジェクトの所有権の制御とバケットの ACL の無効化。」を参照してください。
Regions
作成したバケットを Amazon S3 が保存する地理的な AWS リージョン を選択できます。レイテンシーを最適化し、コストを最小限に抑えて規制用件に対応できるリージョンを選ぶとよいでしょう。明示的に別のリージョンに移動またはレプリケートする場合を除き、AWS リージョン に保存されたオブジェクトは、そのリージョンから移動されることはありません。例えば、欧州 (アイルランド) リージョンに保存されたオブジェクトは、ずっとそのリージョンに置かれたままです。
注記
自分のアカウントで有効になっている AWS リージョン では、Amazon S3 とその機能にのみアクセスできます。リージョンで AWS リソースを作成および管理できるようにする方法の詳細については、「AWS 全般のリファレンス」の「AWS リージョン の管理」を参照してください。
Amazon S3 のリージョンとエンドポイントのリストについては、「AWS 全般のリファレンス」の「リージョンとエンドポイント」を参照してください。
Amazon S3 のデータ整合性モデル
Amazon S3 には、すべての AWS リージョン にある Amazon S3 バケットの、オブジェクトの PUT と DELETE に関する、書き込み後読み取りの強力な整合性があります。この動作は、新しいオブジェクトへの書き込みと、既存のオブジェクトを上書きする PUT リクエスト、そして DELETE リクエストにも適用されます。さらに、Amazon S3 Select、Amazon S3 アクセスコントロールリスト (ACL)、Amazon S3 オブジェクトタグ、オブジェクトメタデータ (HEAD オブジェクトなど) での読み込みオペレーションには、強力な整合性があります。
単一のキーに対する更新はアトミックです。例えば、あるスレッドから既存のキーに PUT リクエストを実行し、同時に同じキーに対して別のスレッドから GET リクエストを実行すると、古いデータまたは新しいデータを取得できますが、データの一部分だけが取得されることも、破損することもありません。
Amazon S3 は、AWS データセンターに配置された複数のサーバー間でデータを複製することにより、高可用性を実現します。PUT リクエストが成功した場合、データは安全に保存されています。成功した PUT 応答の受信後に開始された読み取り (GET または LIST) は、PUT リクエストによって書き込まれたデータを返します。この動作の例を示します。
-
新しいオブジェクトを Amazon S3 に書き込み、すぐにバケット内のキーを一覧表示します。新しいオブジェクトがリストに表示されます。
-
既存のオブジェクトを置換し、すぐにそのオブジェクトの読み取りを試みます。Amazon S3 が新しいデータを返します。
-
既存のオブジェクトを削除し、すぐにそのオブジェクトの読み取りを試みます。オブジェクトが削除されたため、Amazon S3 はデータを返しません。
-
既存のオブジェクトを削除し、すぐにバケット内のキーのリストを表示します。オブジェクトはリストに表示されません。
注記
-
Amazon S3 は、同時書き込みのオブジェクトロックをサポートしていません。同じキーに対して 2 つの PUT リクエストが同時に行われた場合、最新のタイムスタンプを持つリクエストが優先されます。これが問題になる場合は、アプリケーション内にオブジェクトロックメカニズムを構築する必要があります。
-
更新はキーベースです。複数キーにまたがるアトミックな更新を行う方法はありません。たとえば、ご自分で機能をアプリケーション設計に組み込まない限り、別のキーの更新に依存してキーを更新することはできません。
バケット設定には、結果整合性モデルがあります。具体的には、次のように処理されます。
-
バケットを削除してすぐにすべてのバケットを一覧表示しても、削除されたバケットは引き続きリストに表示されます。
-
バケットで初めてバージョニングを有効にしたときは、変更が完全に反映されるまでに、少し時間がかかることがあります。バケットへのオブジェクトの書き込みオペレーション (PUT または DELETE リクエスト) は、バージョニングを有効にして 15 分待ってから発行することをお勧めします。
アプリケーションの同時実行
このセクションでは、同じアイテムに複数のクライアントから書き込むときに、Amazon S3 で予想される動作の例を示します。
次の例では、R1 (読み取り 1) と R2 (読み取り 2) の開始前に W1 (書き込み 1) と W2 (書き込み 2) が完了しています。S3 には強固な整合性があるため、R1 と R2 はどちらも color = ruby を返します。
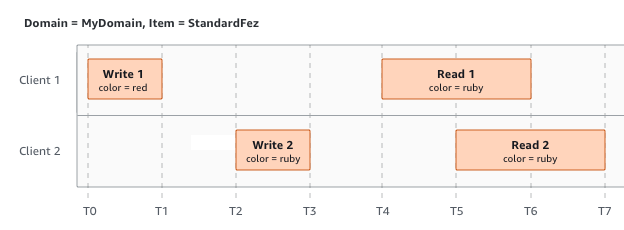
次の例では、R1 の開始前に、W2 は完了していません。したがって、R1 は color = ruby または color = garnet を返す可能性があります。ただし、R2 が開始する前に W1 と W2 が終了するため、R2 は color =
garnet を返します。
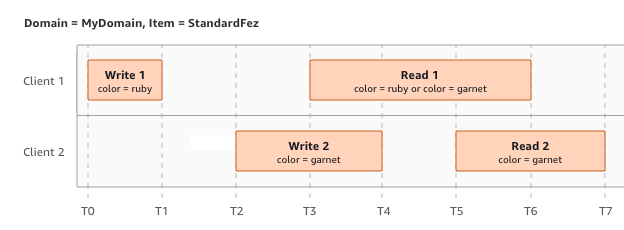
最後の例では、W1 が受信確認を受け取る前に、W2 が開始します。したがって、これらは同時の書き込みとみなされます。どの書き込みを優先するのかを決定するにあたり、Amazon S3 は内部的に last-writer-wins セマンティクスを使用します。しかし、ネットワークレイテンシーなどのさまざまな要因により、Amazon S3 がリクエストを受信する順序や、アプリケーションが受信確認を受け取る順序を予測することはできません。例えば、W2 が同じリージョンにある Amazon EC2 インスタンスによって開始される一方で、W1 は遠くにあるホストによって開始されるかもしれません。両方の書き込みの受信確認を受け取った後に、読み込みを実行することが、最終的な値を決定する最善の方法です。

関連サービス
Amazon S3 にロードしたデータは、他の AWS のサービスでも利用できます。よく使用すると思われるサービスは次のとおりです。
-
Amazon Elastic Compute Cloud (Amazon EC2)
– AWS クラウド でスケーラブルなコンピューティングキャパシティーを提供します。Amazon EC2 の使用により、ハードウェアに事前投資する必要がなくなり、アプリケーションをより速く開発およびデプロイできます。Amazon EC2 を使用すると、必要な数 (またはそれ以下) の仮想サーバーの起動、セキュリティおよびネットワーキングの構成、ストレージの管理ができます。 -
Amazon EMR
– ビジネス、研究者、データアナリスト、およびデベロッパーが、簡単かつ費用対効果の高い方法で、莫大な量のデータを処理できます。Amazon EMR は、Amazon EC2 および Amazon S3 のウェブスケールのインフラストラクチャ上で稼動するホストされた Hadoop フレームワークを使用しています。 -
AWSSnow ファミリー
– 厳しいデータセンター以外の環境や、一貫性のあるネットワーク接続がない場所で運用を実行する必要があるお客様を支援します。AWS Snow ファミリーデバイスを使用して、インターネットに接続できない環境で、ローカルでコスト効果の高い方法で AWS クラウド のストレージおよび処理能力にアクセスできます。 -
AWS Transfer Family
– セキュアシェル (SSH) ファイル転送プロトコル(SFTP)、SSL 経由ファイル転送プロトコル(FTPS)、およびファイル転送プロトコル(FTP)を使用して、Amazon S3 または Amazon Elastic File System(Amazon EFS)との間で直接ファイル転送を行う完全マネージドサポートを提供します。
Amazon S3 へのアクセス
Amazon S3 は次のいずれかの方法で使用できます。
AWS マネジメントコンソール
コンソールは、Amazon S3 と AWS リソースを管理するためのウェブベースのユーザーインターフェイスです。AWS アカウント にサインアップ済みの場合は、AWS マネジメントコンソール にサインインし、AWS マネジメントコンソール ホームページから [S3] を選択することで、Amazon S3 コンソールにアクセスできます。
AWS Command Line Interface
AWS コマンドラインツールを使用して、コマンドを発行するか、システムのコマンドラインでスクリプトを作成して AWS (S3 を含む) タスクを実行します。
AWS Command Line Interface (AWS CLI)
AWS SDK
AWS には、さまざまなプログラミング言語およびプラットフォーム (Java、Python、Ruby、.NET、iOS、Android など) のライブラリとサンプルコードで構成された SDK (ソフトウェア開発キット) が用意されています。AWS SDK は、S3 や AWS へのプログラムによるアクセスを作成するのに役立ちます。Amazon S3 は REST サービスです。AWS SDK ライブラリを使用して Amazon S3 にリクエストを送信できます。これは、基盤となる Amazon S3 REST API をラップし、プログラミングタスクを簡素化します。例えば、SDK は署名の計算、リクエストの暗号化による署名、エラーの管理、リクエストの自動再試行などのタスクを処理します。AWS SDK のダウンロードやインストールなどの詳細については、「AWS のツール
Amazon S3 とのすべてのやり取りは認証されるか匿名で行われます。AWS SDK を使用している場合、指定したキーから、ライブラリによって認証のための署名が計算されます。Amazon S3 へのリクエストの作成方法の詳細については、「Making requests」を参照してください。
Amazon S3 REST API
Amazon S3 は、プログラミング言語に依存しないアーキテクチャとして設計されており、AWS がサポートされているインターフェイスを使用してオブジェクトを保存、取得します。Amazon S3 REST API を使用して、プログラムによって S3 や AWS にアクセスすることができます。REST API は、Amazon S3 に対する HTTP インターフェイスです。REST API では、標準 HTTP リクエストを使用してバケットとオブジェクトを作成、取得、削除できます。
REST API を使用する場合、HTTP をサポートする任意のツールキットを使用できます。匿名で読み取り可能なオブジェクトであれば、ブラウザを使用して取得することもできます。
REST API は標準の HTTP ヘッダーとステータスコードを使用するため、標準のブラウザとツールキットが予期したとおりに機能します。一部のエリアでは、HTTP に機能が追加されています (たとえば、アクセスコントロールをサポートするヘッダーを追加しました)。このように新機能を追加する場合、できるだけ標準 HTTP 書式の使用法に合致するように最善を尽くしました。
ただし、アプリケーションで直接 REST API を呼び出す場合、署名を計算するコードを作成し、それをリクエストに追加する必要があります。Amazon S3 にリクエストを行う方法の詳細については、「Amazon S3 リファレンス」の「Making requests」を参照してください。
注記
SOAP API のサポートは HTTP 経由では廃止されましたが、HTTPS 経由では引き続き利用可能です。新しい Amazon S3 機能は、SOAP ではサポートされません。REST API か AWS SDK を使用することをお勧めします。
Amazon S3 の支払い
Amazon S3 の料金は、アプリケーションのストレージ要件を考慮しなくてすむように設定されています。ほとんどのストレージプロバイダーでは、あらかじめ決められた量のストレージおよびネットワーク転送容量を購入する必要があります。このシナリオでは、その容量を超えると、サービスが停止されるか、高額な超過料金を支払う必要があります。その容量を超えない場合でも、全量を使用したものとして支払うことになります。
Amazon S3 では、実際に使用した分だけが請求されます。隠れた料金や超過料金はありません。このモデルでは、AWS インフラストラクチャのコスト面のメリットを得ながら、ビジネスの成長に応じた可変コストのサービスを利用することができます。詳細については、Amazon S3 の料金
AWS にサインアップすると、Amazon S3 を含む AWS のすべてのサービスに対して AWS アカウント が自動的にサインアップされます。ただし、料金が発生するのは実際に使用したサービスの分だけです。Amazon S3 の新規のお客様は、Amazon S3 を無料で使い始めることができます。詳細については、「AWS 無料利用枠
請求を表示するには、AWS Billing and Cost Management コンソール
PCI DSS コンプライアンス
Amazon S3 は、マーチャントまたはサービスプロバイダーによるクレジットカードデータの処理、ストレージ、および伝送をサポートしており、Payment Card Industry (PCI) Data Security Standard (DSS) に準拠していることが確認されています。PCI DSS の詳細 (AWS PCI Compliance Package のコピーをリクエストする方法など) については、「PCI DSS レベル 1
