As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Treinamento de modelos
O estágio de treinamento do ciclo de vida completo de machine learning (ML) abrange desde o acesso ao conjunto de dados de treinamento até a geração de um modelo final e a seleção do modelo com melhor desempenho para implantação. As seções a seguir fornecem uma visão geral dos recursos e recursos de SageMaker treinamento disponíveis, com informações técnicas detalhadas sobre cada um.
A arquitetura básica do SageMaker treinamento
Se você estiver usando SageMaker IA pela primeira vez e quiser encontrar uma solução rápida de ML para treinar um modelo em seu conjunto de dados, considere usar uma solução sem código ou com pouco código, como o SageMaker Canvas, JumpStartno SageMaker Studio Classic ou no Autopilot. SageMaker
Para experiências de codificação intermediárias, considere usar um notebook SageMaker Studio Classic ou instâncias de SageMaker notebook. Para começar, siga as instruções Treinar um modelo do guia de introdução à SageMaker IA. Recomendamos isso para casos de uso nos quais você cria seu próprio modelo e script de treinamento usando um framework de machine learning.
O núcleo dos trabalhos de SageMaker IA é a conteinerização das cargas de trabalho de ML e a capacidade de gerenciar recursos computacionais. A plataforma de SageMaker treinamento cuida do trabalho pesado associado à configuração e gerenciamento da infraestrutura para cargas de trabalho de treinamento de ML. Com o SageMaker treinamento, você pode se concentrar em desenvolver, treinar e ajustar seu modelo.
O diagrama de arquitetura a seguir mostra como a SageMaker IA gerencia trabalhos de treinamento de ML e provisiona EC2 instâncias da Amazon em nome dos usuários de SageMaker IA. Você, como usuário de SageMaker IA, pode trazer seu próprio conjunto de dados de treinamento, salvando-o no Amazon S3. Você pode escolher um modelo de treinamento de ML a partir dos algoritmos integrados de SageMaker IA disponíveis ou trazer seu próprio script de treinamento com um modelo criado com estruturas populares de aprendizado de máquina.
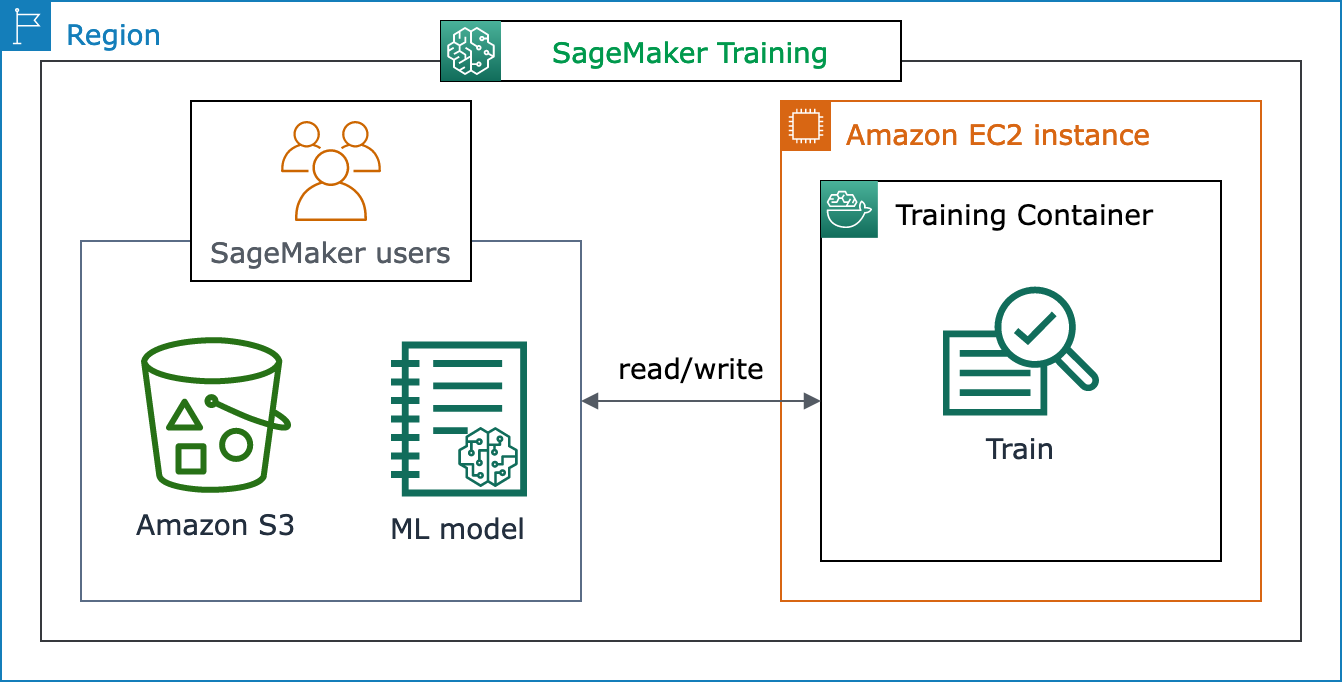
Visão completa do fluxo de trabalho e dos recursos do SageMaker treinamento
A jornada completa do treinamento de machine learning envolve tarefas além da ingestão de dados para modelos de machine learning, incluindo o treinamento de modelos em instâncias de computação e a obtenção de artefatos e saídas do modelo. Você precisa avaliar cada fase antes, durante e após o treinamento para garantir que seu modelo seja treinado adequadamente para atingir a precisão desejada para seus objetivos.
O fluxograma a seguir mostra uma visão geral de alto nível de suas ações (em caixas azuis) e dos recursos de SageMaker treinamento disponíveis (em caixas azuis claras) durante toda a fase de treinamento do ciclo de vida do ML.
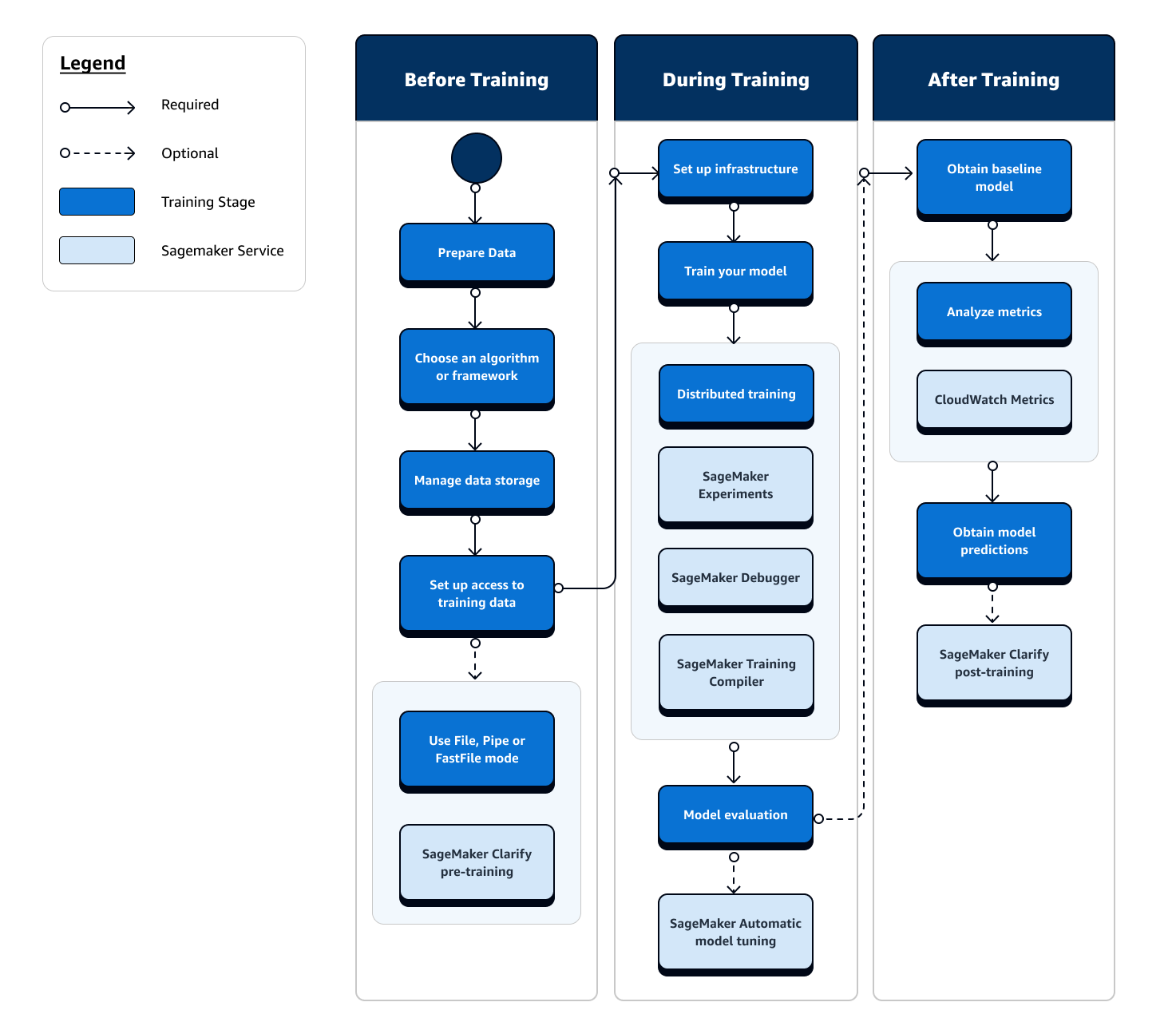
As seções a seguir explicam cada fase do treinamento descrita no fluxograma anterior e os recursos úteis oferecidos pela SageMaker IA nos três subestágios do treinamento de ML.
Antes do treinamento
Há vários cenários de configuração de atributos de dados e acesso que você precisa considerar antes do treinamento. Consulte o diagrama a seguir e os detalhes de cada estágio antes do treinamento para ter uma ideia das decisões que você precisa tomar.
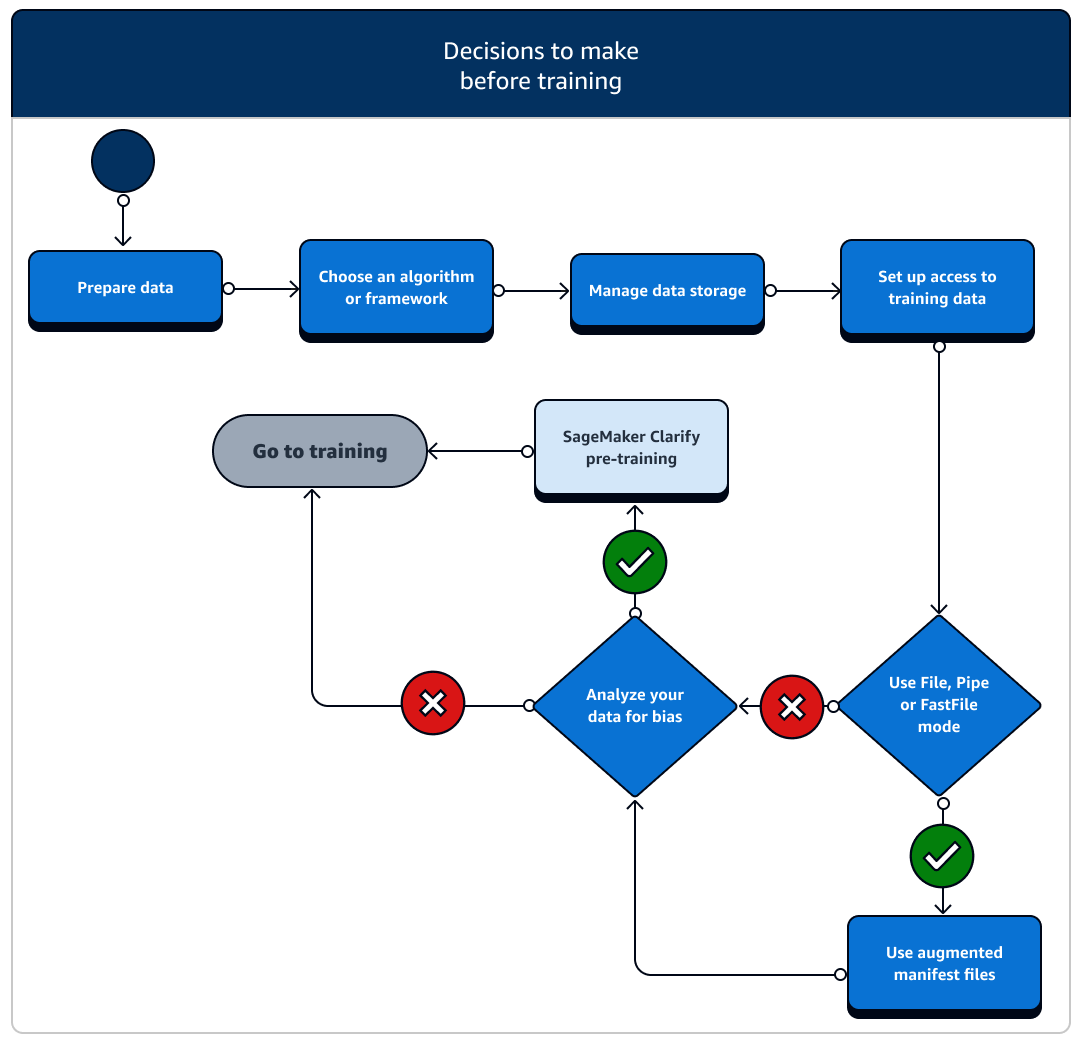
-
Prepare os dados: antes do treinamento, você deve ter concluído a limpeza dos dados e a engenharia de recursos durante o estágio de preparação dos dados. SageMaker A IA tem várias ferramentas de rotulagem e engenharia de recursos para ajudá-lo. Consulte Rotular dados, Preparar e analisar conjuntos de dados, Processar dados e Criar, armazenar e compartilhar atributos para obter mais informações.
-
Escolha um algoritmo ou framework: dependendo da quantidade de personalização necessária, há diferentes opções de algoritmos e frameworks.
-
Se você preferir uma implementação low-code de um algoritmo pré-criado, use um dos algoritmos integrados oferecidos pela SageMaker IA. Para obter mais informações, consulte Escolher um algoritmo.
-
Se você precisar de mais flexibilidade para personalizar seu modelo, execute seu script de treinamento usando suas estruturas e kits de ferramentas preferidos dentro da SageMaker IA. Para obter mais informações, consulte Frameworks e kits de ferramentas de ML.
-
Para estender imagens pré-criadas do SageMaker AI Docker como a imagem base do seu próprio contêiner, consulte Usar imagens pré-criadas do SageMaker AI Docker.
-
Para trazer seu contêiner Docker personalizado para a SageMaker IA, consulte Adaptação de seu próprio contêiner Docker para trabalhar com IA. SageMaker Você precisa instalar o sagemaker-training-toolkit
em seu contêiner.
-
-
Gerencie o armazenamento de dados: entenda o mapeamento entre o armazenamento de dados (como Amazon S3, Amazon EFS ou Amazon FSx) e o contêiner de treinamento executado na instância de EC2 computação da Amazon. SageMaker A IA ajuda a mapear os caminhos de armazenamento e os caminhos locais no contêiner de treinamento. Você também pode especificá-los manualmente. Depois que o mapeamento estiver concluído, considere usar um dos modos de transmissão de dados: Arquivo, Pipe e FastFile modo. Para saber como a SageMaker IA mapeia os caminhos de armazenamento, consulte Treinamento de pastas de armazenamento.
-
Configure o acesso aos dados de treinamento: use o domínio Amazon SageMaker AI, um perfil de usuário do domínio, IAM, Amazon VPC e AWS KMS para atender aos requisitos das organizações mais sensíveis à segurança.
-
Para administração da conta, consulte o domínio Amazon SageMaker AI.
-
Para obter uma referência completa sobre políticas e segurança do IAM, consulte Segurança na Amazon SageMaker AI.
-
-
Transmita seus dados de entrada: a SageMaker IA fornece três modos de entrada de dados: Arquivo, Tubo FastFilee. O modo de entrada padrão é o modo File, que carrega o conjunto de dados inteiro durante a inicialização do trabalho de treinamento. Para saber mais sobre as práticas recomendadas gerais para transmitir dados do seu armazenamento de dados para o contêiner de treinamento, consulte Acessar os dados do treinamento.
No caso do modo Pipe, você também pode considerar o uso de um arquivo manifesto aumentado para transmitir seus dados diretamente do Amazon Simple Storage Service (Amazon S3) e treinar seu modelo. O uso do modo pipe reduz o espaço em disco porque o Amazon Elastic Block Store só precisa armazenar os artefatos do modelo final, em vez de armazenar todo o conjunto de dados de treinamento. Para obter mais informações, consulte Fornecer metadados do conjunto de dados para trabalhos de treinamento com um arquivo de manifesto aprimorado.
-
Analise seus dados em busca de viés: antes do treinamento, você pode analisar seu conjunto de dados e modelo em busca de viés em relação a um grupo desfavorecido para verificar se seu modelo aprende um conjunto de dados imparcial usando o Clarify. SageMaker
-
Escolha qual SageMaker SDK usar: há duas maneiras de iniciar um trabalho de treinamento em SageMaker IA: usando o SDK AI SageMaker Python de alto nível ou usando o de baixo nível SageMaker APIs para o SDK for Python (Boto3) ou o. AWS CLI O SDK do SageMaker Python abstrai a SageMaker API de baixo nível para fornecer ferramentas convenientes. Conforme mencionado acimaA arquitetura básica do SageMaker treinamento, você também pode buscar opções sem código ou com código mínimo usando o SageMaker Canvas, JumpStart no SageMaker Studio Classic ou no AI Autopilot. SageMaker
Durante o treinamento
Durante o treinamento, você precisa melhorar continuamente a estabilidade, a velocidade e a eficiência do treinamento e, ao mesmo tempo, escalar os recursos de computação, a otimização de custos e, o mais importante, o desempenho do modelo. Continue lendo para obter mais informações sobre os estágios de treinamento e os recursos de SageMaker treinamento relevantes.
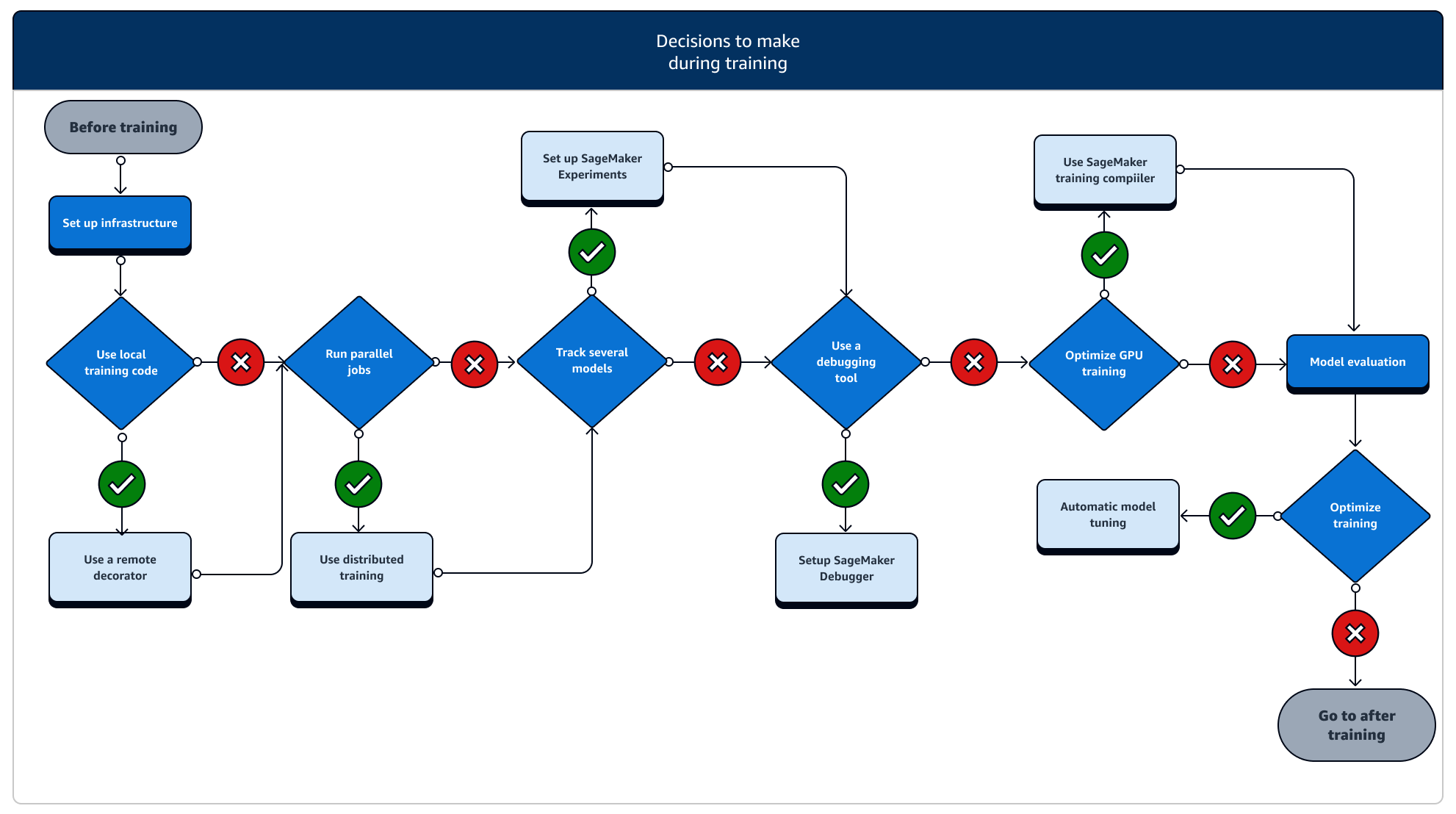
-
Configure a infraestrutura: escolha o tipo de instância e as ferramentas de gerenciamento de infraestrutura corretos para seu caso de uso. Você pode começar com uma pequena instância e aumentar a escala de acordo com sua workload. Para treinar um modelo em um conjunto de dados tabular, comece com a menor instância de CPU das famílias de instâncias C4 ou C5. Para treinar um modelo grande para visão computacional ou processamento de linguagem natural, comece com a menor instância de GPU das famílias de instâncias P2, P3, G4dn ou G5. Você também pode misturar diferentes tipos de instância em um cluster ou manter as instâncias em pools aquecidos usando as seguintes ferramentas de gerenciamento de instâncias oferecidas pela SageMaker IA. Você também pode usar o cache persistente para reduzir a latência e o tempo faturável em tarefas de treinamento iterativo, em vez da redução da latência apenas de grupos de aquecimento. Para saber mais, consulte os tópicos a seguir.
Você deve ter cota suficiente para executar um trabalho de treinamento. Se você executar seu trabalho de treinamento em uma instância em que não tem cota suficiente, receberá um erro
ResourceLimitExceeded. Para verificar as cotas atualmente disponíveis em sua conta, use o console do Service Quotas. Para saber como solicitar um aumento de cota, consulte Regiões e Cotas compatíveis. Além disso, para encontrar informações sobre preços e tipos de instância disponíveis, dependendo do Regiões da AWS, consulte as tabelas na página de SageMaker preços da Amazon . -
Execute um trabalho de treinamento a partir de um código local: você pode anotar seu código local com um decorador remoto para executá-lo como um trabalho de SageMaker treinamento de dentro do Amazon SageMaker Studio Classic, de um SageMaker notebook da Amazon ou de seu ambiente de desenvolvimento integrado local. Para obter mais informações, consulte Execute seu código local como um trabalho SageMaker de treinamento.
-
Monitore trabalhos de treinamento: monitore e acompanhe seus trabalhos de treinamento usando SageMaker Experiments, SageMaker Debugger ou Amazon. CloudWatch Você pode observar o desempenho do modelo em termos de precisão e convergência e executar análises comparativas de métricas entre vários trabalhos de treinamento usando experimentos de SageMaker IA. Você pode observar a taxa de utilização dos recursos computacionais usando as ferramentas de criação de perfil do SageMaker Debugger ou a Amazon. CloudWatch Para saber mais, consulte os tópicos a seguir.
Além disso, para tarefas de aprendizado profundo, use as ferramentas de depuração de modelos do Amazon SageMaker Debugger e as regras incorporadas para identificar problemas mais complexos nos processos de convergência de modelos e atualização de peso.
-
Treinamento distribuído: se seu trabalho de treinamento estiver em um estágio estável sem interrupções devido à configuração incorreta da infraestrutura de treinamento ou a out-of-memory problemas, talvez você queira encontrar mais opções para escalar seu trabalho e executá-lo por um longo período de dias e até meses. Quando você estiver pronto para expandir, considere o treinamento distribuído. SageMaker A IA fornece várias opções para computação distribuída, desde cargas de trabalho leves de ML até cargas de trabalho pesadas de aprendizado profundo.
Para tarefas de aprendizado profundo que envolvam o treinamento de modelos muito grandes em conjuntos de dados muito grandes, considere usar uma das estratégias de treinamento distribuído de SageMaker IA para ampliar e alcançar o paralelismo de dados, o paralelismo de modelos ou uma combinação dos dois. Você também pode usar o SageMaker Training Compiler para compilar e otimizar gráficos de modelos em instâncias de GPU. Esses recursos de SageMaker IA oferecem suporte a estruturas de aprendizado profundo PyTorch, como TensorFlow, e Hugging Face Transformers.
-
Ajuste de hiperparâmetros do modelo: ajuste os hiperparâmetros do seu modelo usando o ajuste automático de modelos com SageMaker IA. SageMaker A IA fornece métodos de ajuste de hiperparâmetros, como pesquisa em grade e pesquisa bayesiana, lançando trabalhos paralelos de ajuste de hiperparâmetros com funcionalidade de interrupção antecipada para trabalhos de ajuste de hiperparâmetros que não melhoram.
-
Verificação e economia de custos com instâncias spot: se o tempo de treinamento não for uma grande preocupação, considere otimizar os custos de treinamento de Modelos com instâncias spot gerenciadas. Observe que você deve ativar o ponto de verificação para o treinamento Spot para continuar restaurando após pausas intermitentes no trabalho devido à substituição de instâncias do Spot. Você também pode usar a funcionalidade de ponto de verificação para fazer backup de seus modelos em caso de término inesperado do trabalho de treinamento. Para saber mais, consulte os tópicos a seguir.
Após o treinamento
Após o treinamento, você obtém um artefato do modelo final para usar na implantação e inferência do modelo. Há ações adicionais envolvidas na fase de pós-treinamento, conforme mostrado no diagrama a seguir.
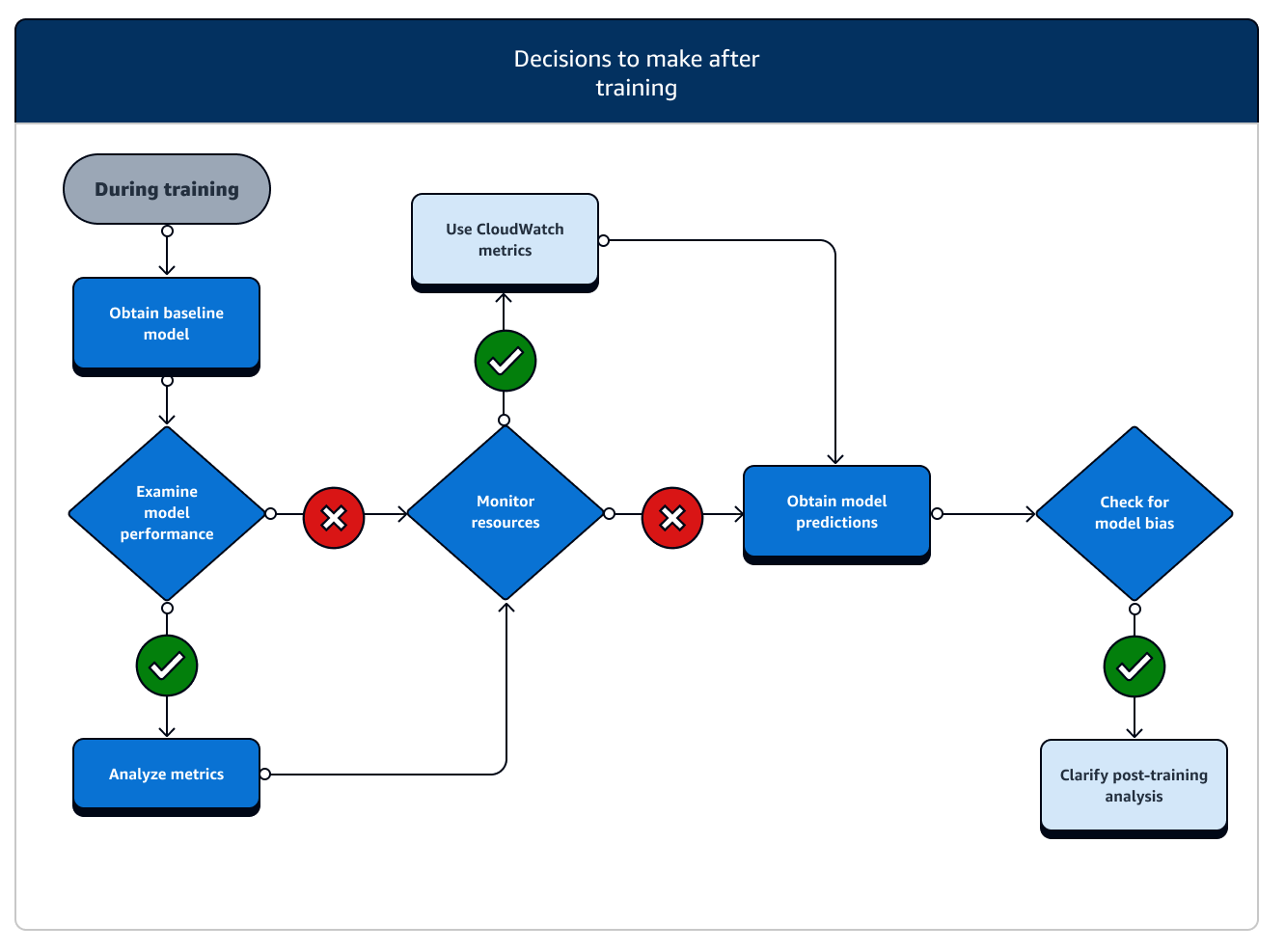
-
Obter modelo de linha de base: depois de ter o artefato do modelo, você pode defini-lo como um modelo de linha de base. Considere as seguintes ações de pós-treinamento e o uso de recursos de SageMaker IA antes de passar para a implantação do modelo na produção.
-
Examine o desempenho do modelo e verifique o viés: use o Amazon CloudWatch Metrics e o SageMaker Clarify para detectar qualquer viés pós-treinamento para detectar qualquer viés nos dados recebidos e modelar ao longo do tempo em relação à linha de base. Você precisa avaliar seus novos dados e modelar as predições em relação aos novos dados regularmente ou em tempo real. Usando esses atributos, você pode receber alertas sobre quaisquer alterações ou anomalias agudas, bem como alterações ou oscilações graduais nos dados e no modelo.
-
Você também pode usar a funcionalidade de treinamento incremental da SageMaker IA para carregar e atualizar seu modelo (ou ajustar) com um conjunto de dados expandido.
-
Você pode registrar o treinamento de modelos como uma etapa em seu pipeline de SageMaker IA ou como parte de outros recursos de fluxo de trabalho oferecidos pela SageMaker IA para orquestrar todo o ciclo de vida do ML.
