As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Importar
Você pode usar o Amazon SageMaker Data Wrangler para importar dados das seguintes fontes de dados: Amazon Simple Storage Service (Amazon S3), Amazon Athena, Amazon Redshift e Snowflake. O conjunto de dados que você importa pode incluir até 1.000 colunas.
Algumas fontes de dados permitem que você adicione várias conexões de dados:
-
Você pode se conectar a vários clusters do Amazon Redshift. Cada cluster se torna uma fonte de dados.
-
Você pode consultar qualquer banco de dados do Athena em sua conta para importar dados desse banco de dados.
Quando você importa um conjunto de dados de uma fonte de dados, ele aparece no seu fluxo de dados. O Data Wrangler infere automaticamente o tipo de dados de cada coluna em seu conjunto de dados. Para modificar esses tipos, selecione a etapa Tipos de dados e selecione Editar tipos de dados.
Quando você importa dados do Athena ou do Amazon Redshift, os dados importados são armazenados automaticamente no bucket AI S3 SageMaker padrão para a região na qual você está AWS usando o Studio Classic. Além disso, o Athena armazena os dados que você visualiza no Data Wrangler neste bucket. Para saber mais, consulte Armazenamento de dados importados.
Importante
O bucket padrão do Amazon S3 pode não ter as configurações de segurança menos permissivas, como política de bucket e criptografia do lado do servidor (SSE). É altamente recomendável que você Adicione uma política de bucket para restringir o acesso aos conjuntos de dados importados para o Data Wrangler.
Importante
Além disso, se você usa a política gerenciada para SageMaker IA, é altamente recomendável que você a reduza até a política mais restritiva que permita realizar seu caso de uso. Para obter mais informações, consulte Conceder permissão a um perfil do IAM para usar o Data Wrangler.
Todas as fontes de dados, exceto o Amazon Simple Storage Service (Amazon S3), exigem que você especifique uma consulta SQL para importar seus dados. Para cada consulta, você deve especificar o seguinte:
-
Catálogo de dados
-
Banco de dados
-
Tabela
Você pode especificar o nome do banco de dados ou do catálogo de dados nos menus suspensos ou na consulta. Veja os exemplos de consultas:
-
select * from- A consulta não usa nada especificado nos menus suspensos da interface do usuário (UI) para ser executada. Ele consultaexample-data-catalog-name.example-database-name.example-table-nameexample-table-namedentro deexample-database-namedentro deexample-data-catalog-name. -
select * from- A consulta usa o catálogo de dados que você especificou no menu suspenso Catálogo de dados para ser executada. Ele consultaexample-database-name.example-table-nameexample-table-namedentro deexample-database-namedo catálogo de dados que você especificou. -
select * from: a consulta exige que você selecione campos para os menus suspensos Catálogo de dados e Nome do banco de dados. Faz consultas emexample-table-nameexample-table-namedentro do catálogo de dados dentro do banco de dados e catálogo de dados que você especificou.
O link entre o Data Wrangler e a fonte de dados é uma conexão. Você usa a conexão para importar dados da sua fonte de dados.
Existem os seguintes tipos de conexões:
-
Direta
-
Catalogado
O Data Wrangler sempre tem acesso aos dados mais recentes em uma conexão direta. Se os dados na fonte de dados foram atualizados, você pode usar a conexão para importar os dados. Por exemplo, se alguém adicionar um arquivo a um dos seus buckets do Amazon S3, você poderá importar o arquivo.
Uma conexão catalogada é o resultado de uma transferência de dados. Os dados na conexão catalogada não têm necessariamente os dados mais recentes. Por exemplo, você pode configurar uma transferência de dados entre o Salesforce e o Amazon S3. Se houver uma atualização nos dados do Salesforce, você deverá transferir os dados novamente. Você pode automatizar o processo de transferência de dados. Para obter mais informações sobre transferências de dados, consulte Importar dados de plataformas de software como serviço (SaaS).
Importar dados do Amazon S3
Você pode usar o Amazon Simple Storage Service (Amazon S3) para armazenar e recuperar qualquer volume de dados, a qualquer momento, de qualquer lugar na web. Você pode realizar essas tarefas usando a AWS Management Console, que é uma interface web simples e intuitiva, e a API do Amazon S3. Se você armazenou seu conjunto de dados localmente, recomendamos que você o adicione a um bucket do S3 para importação no Data Wrangler. Para aprender como fazer isso, consulte Fazer upload de um objeto para um bucket no Guia do Usuário do Amazon Simple Storage Service.
O Data Wrangler usa o S3 Select
Importante
Se você planeja exportar um fluxo de dados e iniciar um trabalho do Data Wrangler, ingerir dados em uma SageMaker loja de recursos de IA ou criar um pipeline de SageMaker IA, saiba que essas integrações exigem que os dados de entrada do Amazon S3 estejam localizados na mesma região. AWS
Importante
Se você estiver importando um arquivo CSV, verifique se ele cumpre os requisitos a seguir:
-
Um registro no seu conjunto de dados não pode ser maior que uma linha.
-
Uma barra invertida,
\, é o único caractere de escape válido. -
Seu conjunto de dados deve usar um dos seguintes delimitadores:
-
Vírgula -
, -
Dois pontos -
: -
Ponto e vírgula -
; -
Barra vertical -
| -
Aba -
[TAB]
-
Para economizar espaço, você pode importar arquivos CSV compactados.
O Data Wrangler permite importar todo o conjunto de dados ou amostrar uma parte dele. Para o Amazon S3, ele fornece as seguintes opções de amostragem:
-
Nenhum: Importar todo o conjunto de dados.
-
Primeiro K: Fazer uma amostra das primeiras K linhas do conjunto de dados, em que K é um número inteiro que você especifica.
-
Aleatório - obtém uma amostra aleatória de um tamanho especificado por você.
-
Estratificado - obtém uma amostra aleatória estratificada. Uma amostra estratificada preserva proporção de valores em uma coluna.
Depois de importar seus dados, você também pode usar o transformador de amostragem para obter uma ou mais amostras de todo o seu conjunto de dados. Para obter mais informações sobre a transformação de amostra, consulte Amostragem.
É possível usar um dos seguintes identificadores de recurso para importar seus dados:
-
Um URI do Amazon S3 que usa um bucket do Amazon S3 ou pontos de acesso Amazon S3
-
Um alias de ponto de acesso Amazon S3.
-
Um nome do recurso da Amazon (ARN) que usa um bucket do Amazon S3 ou pontos de acesso Amazon S3
Os pontos de Acesso Amazon S3 são endpoints de rede anexados a buckets. Cada ponto de acesso possui permissões distintas e controles de rede que você pode configurar. Para obter mais informações sobre pontos de acesso, consulte Como gerenciar o acesso a dados com os pontos de acesso Amazon S3.
Importante
Se você estiver usando um Amazon Resource Name (ARN) para importar seus dados, ele deve ser para um recurso localizado no mesmo Região da AWS que você está usando para acessar o Amazon SageMaker Studio Classic.
Você pode importar um único arquivo ou vários arquivos como um conjunto de dados. É possível usar a operação de importação de vários arquivos quando você tem um conjunto de dados que é particionado em arquivos separados. Pega todos os arquivos de um diretório do Amazon S3 e os importa como um único conjunto de dados. Para obter informações sobre os tipos de arquivos que você pode importar e como importá-los, consulte as seções a seguir.
Você também pode usar parâmetros para importar um subconjunto de arquivos que correspondam a um padrão. Os parâmetros ajudam você a escolher de forma mais seletiva os arquivos que você está importando. Para começar a utilizar parâmetros, edite a fonte de dados e aplique-os ao caminho que você está utilizando para importar os dados. Para obter mais informações, consulte Reutilização de fluxos de dados para diferentes conjuntos de dados.
Importar dados do Athena
Use o Amazon Athena para importar dados do Amazon Simple Storage Service (Amazon S3) para o Data Wrangler. No Athena, você escreve consultas SQL padrão para selecionar os dados que você está importando do Amazon S3. Para obter mais informações, consulte O que é o Amazon Athena?
Você pode usar o AWS Management Console para configurar o Amazon Athena. Você deve criar pelo menos um banco de dados no Athena antes de começar a executar consultas. Para obter mais informações sobre como começar com o Athena, consulte Conceitos básicos.
O Athena está diretamente integrado ao Data Wrangler. Você pode escrever consultas no Athena sem precisar sair da interface do Data Wrangler.
Além de escrever consultas simples no Athena no Data Wrangler, você também pode usar:
-
Grupos de trabalho do Athena para gerenciamento de resultados de consultas. Para obter mais informações sobre grupos de trabalho, consulte Como gerenciar os resultados da consulta.
-
Configurações de duração para definir períodos de retenção de dados. Para obter mais informações sobre a retenção de dados, consulte Definir os períodos de retenção de dados.
Consulte Athena no Data Wrangler
nota
O Data Wrangler não oferece apoio a consultas federadas.
Se você usa AWS Lake Formation com o Athena, certifique-se de que suas permissões do IAM do Lake Formation não substituam as permissões do IAM para o banco de dados. sagemaker_data_wrangler
O Data Wrangler permite importar todo o conjunto de dados ou amostrar uma parte dele. Para o Athena, ele oferece as seguintes opções de amostragem:
-
Nenhum: Importar todo o conjunto de dados.
-
Primeiro K: Fazer uma amostra das primeiras K linhas do conjunto de dados, em que K é um número inteiro que você especifica.
-
Aleatório - obtém uma amostra aleatória de um tamanho especificado por você.
-
Estratificado - obtém uma amostra aleatória estratificada. Uma amostra estratificada preserva proporção de valores em uma coluna.
O procedimento a seguir mostra como importar um conjunto de dados do Athena para o Data Wrangler.
Para importar um conjunto de dados do Athena para o Data Wrangler
-
Faça login no Amazon SageMaker AI Console
. -
Escolha Studio.
-
Escolha Iniciar aplicação.
-
Na lista suspensa, selecione Studio.
-
Escolha o ícone Início.
-
Escolha Dados.
-
Escolha Data Wrangler.
-
Escolha Importar dados.
-
Em Disponível, escolha Amazon Athena.
-
Para Catálogo de dados, escolha um catálogo de dados.
-
Use a lista suspensa Banco de dados para selecionar o banco de dados que deseja consultar. Ao selecionar um banco de dados, você pode visualizar todas as tabelas em seu banco de dados usando as Tabelas listadas em Detalhes.
-
(Opcional) Escolha Configuração avançada.
-
Escolha um Grupo de trabalho.
-
Se seu grupo de trabalho não impôs o local de saída do Amazon S3 ou se você não usa um grupo de trabalho, especifique um valor para a localização dos resultados da consulta no Amazon S3.
-
(Opcional) Em Período de retenção de dados, marque a caixa de seleção para definir um período de retenção de dados e especificar o número de dias para armazenar os dados antes de serem excluídos.
-
(Opcional) Por padrão, o Data Wrangler salva a conexão. Você pode optar por desmarcar a caixa de seleção e não salvar a conexão.
-
-
Para Amostragem, escolha um método de amostragem. Escolha Nenhum para desativar a amostragem.
-
Digite sua consulta no editor de consultas e escolha Executar para executar a consulta. Após uma consulta bem-sucedida, você pode visualizar seu resultado abaixo do editor.
nota
Os dados do Salesforce usam o tipo
timestamptz. Se você estiver consultando a coluna de timestamp que importou do Salesforce para o Athena, converta os dados na coluna para o tipotimestamp. A seguinte consulta converte a coluna de timestamp para o tipo correto:# cast column timestamptz_col as timestamp type, and name it as timestamp_col select cast(timestamptz_col as timestamp) as timestamp_col from table -
Para importar os resultados da sua consulta, selecione Importar.
Depois de concluir o procedimento anterior, o conjunto de dados que você consultou e importou aparece no fluxo do Data Wrangler.
Por padrão, o Data Wrangler salva as configurações de conexão como uma nova conexão. Quando você importa seus dados, a consulta que você já especificou aparece como uma nova conexão. As conexões salvas armazenam informações sobre os grupos de trabalho do Athena e os buckets do Amazon S3 que você está usando. Ao se conectar novamente à fonte de dados, você pode escolher a conexão salva.
Como gerenciar os resultados da consulta
O Data Wrangler oferece apoio ao uso de grupos de trabalho do Athena para gerenciar os resultados da consulta em uma conta AWS . Você pode especificar um local de saída do Amazon S3 para cada grupo de trabalho. Você também pode especificar se a saída da consulta pode ser direcionada para diferentes locais no Amazon S3. Para obter mais informações, consulte Como usar os grupos de trabalho para controlar o acesso a consultas e custos.
Seu grupo de trabalho pode estar configurado para impor o local de saída da consulta do Amazon S3. Você não pode alterar a localização de saída dos resultados da consulta para esses grupos de trabalho.
Se você não usa um grupo de trabalho nem especifica um local de saída para suas consultas, o Data Wrangler usa o bucket padrão do Amazon S3 na mesma AWS região em que sua instância do Studio Classic está localizada para armazenar os resultados da consulta do Athena. Ele cria tabelas temporárias neste banco de dados para transferir a saída da consulta para este bucket do Amazon S3. Ele exclui essas tabelas após a importação dos dados; no entanto, o banco de dados, sagemaker_data_wrangler, persiste. Para saber mais, consulte Armazenamento de dados importados.
Para usar grupos de trabalho no Athena, configure a política do IAM que concede acesso aos grupos de trabalho. Se você estiver usando um SageMaker AI-Execution-Role, recomendamos adicionar a política à função. Para obter mais informações sobre as políticas do IAM para grupos de trabalho, consulte Políticas do IAM para acessar grupos de trabalho. Por exemplo, para políticas do grupo de trabalho, consulte Políticas de exemplo do grupo de trabalho.
Definir os períodos de retenção de dados
O Data Wrangler define automaticamente um período de retenção de dados para os resultados da consulta. Os resultados são excluídos após o término do período de retenção. Por exemplo, o período de retenção padrão é de cinco dias. Os resultados da consulta são excluídos após cinco dias. Essa configuração é projetada para ajudar na limpeza de dados que você não está mais utilizando. Limpar seus dados impede que usuários não autorizados tenham acesso. Também ajuda a controlar os custos de armazenamento de seus dados no Amazon S3.
Se você não definir um período de retenção, a configuração do duração do Amazon S3 determinará a duração em que os objetos serão armazenados. A política de retenção de dados que você especificou para a configuração de duração remove quaisquer resultados de consulta que sejam mais antigos do que a configuração de duração que você especificou. Para obter mais informações, consulte Definir configuração da duração de um bucket.
O Data Wrangler usa as configurações de duração do Amazon S3 para gerenciar a expiração e retenção de dados. Você deve conceder à sua função de execução do Amazon SageMaker Studio Classic IAM permissões para gerenciar as configurações do ciclo de vida do bucket. Use o seguinte procedimento para conceder permissões:
Para conceder permissões para gerenciar a configuração de duração, siga os seguintes passos:
-
Faça login no AWS Management Console e abra o console do IAM em https://console.aws.amazon.com/iam/
. -
Escolha Perfis.
-
Na barra de pesquisa, especifique a função de execução do Amazon SageMaker AI que o Amazon SageMaker Studio Classic está usando.
-
Selecione o perfil de .
-
Escolha Adicionar permissões.
-
Escolha Criar política em linha.
-
Para Serviço, especifique S3 e escolha-o.
-
Na seção Ler, escolha GetLifecycleConfiguration.
-
Na seção Escrever, escolha PutLifecycleConfiguration.
-
Em Recursos, selecione Específico.
-
Em Ações, selecione o ícone de seta ao lado de Gerenciamento de permissões.
-
Selecione PutResourcePolicy.
-
Em Recursos, selecione Específico.
-
Escolha a caixa de seleção ao lado de Qualquer nesta conta.
-
Selecione Revisar política.
-
Em Nome, especifique um nome.
-
Selecione Criar política.
Importar dados do Amazon Redshift
O Amazon Redshift é um serviço de data warehouse totalmente gerenciado e em escala de petabytes na Nuvem . A primeira etapa para criar um data warehouse é executar um conjunto de nós, chamado cluster do Amazon Redshift. Depois de provisionar seu cluster, você pode fazer o upload do seu conjunto de dados e, em seguida, realizar consultas de análise de dados.
Você pode se conectar e consultar um ou mais clusters do Amazon Redshift no Data Wrangler. Para usar essa opção de importação, você deve criar pelo menos um cluster no Amazon Redshift. Para saber como, consulte Conceitos básicos do Amazon Redshift.
Você pode gerar os resultados da sua consulta do Amazon Redshift em um dos seguintes locais:
-
O bucket padrão do Amazon S3
-
Um local de saída do Amazon S3 que você especifica
Você pode importar o conjunto de dados inteiro ou fazer uma amostra de uma parte dele. Para o Amazon Redshift, ele fornece as seguintes opções de amostragem:
-
Nenhum: Importar todo o conjunto de dados.
-
Primeiro K: Fazer uma amostra das primeiras K linhas do conjunto de dados, em que K é um número inteiro que você especifica.
-
Aleatório - obtém uma amostra aleatória de um tamanho especificado por você.
-
Estratificado - obtém uma amostra aleatória estratificada. Uma amostra estratificada preserva proporção de valores em uma coluna.
O bucket padrão do Amazon S3 está na mesma AWS região em que sua instância do Studio Classic está localizada para armazenar os resultados da consulta do Amazon Redshift. Para obter mais informações, consulte Armazenamento de dados importados.
Para o bucket padrão do Amazon S3 ou para o bucket que você especificar, você tem as seguintes opções de criptografia:
-
A criptografia padrão do AWS lado do serviço com uma chave gerenciada do Amazon S3 (SSE-S3)
-
Uma chave AWS Key Management Service (AWS KMS) que você especifica
Uma AWS KMS chave é uma chave de criptografia que você cria e gerencia. Para obter mais informações sobre as chaves do KMS, consulte AWS Key Management Service.
Você pode especificar uma AWS KMS chave usando o ARN da chave ou o ARN da sua conta. AWS
Se você usar a política gerenciada do IAM, AmazonSageMakerFullAccess, para conceder permissão à uma função para usar o Data Wrangler no Studio Classic, o nome de usuário do banco de dados deverá ter o prefixo sagemaker_access.
Utilize os procedimentos a seguir para aprender como adicionar um novo cluster.
nota
O Data Wrangler usa a API de dados do Amazon Redshift com credenciais temporárias. Para saber mais sobre essa API, consulte Como usar a API de dados do Amazon Redshift no Guia de gerenciamento do Amazon Redshift.
Como se conectar a um cluster do Amazon Redshift
-
Faça login no Amazon SageMaker AI Console
. -
Escolha Studio.
-
Escolha Iniciar aplicação.
-
Na lista suspensa, selecione Studio.
-
Escolha o ícone Início.
-
Escolha Dados.
-
Escolha Data Wrangler.
-
Escolha Importar dados.
-
Em Disponível, escolha Amazon Athena.
-
Escolha Amazon Redshift.
-
Escolha Credenciais temporárias (IAM) para Tipo.
-
Insira um Nome de conexão. Isso é um nome usado pelo Data Wrangler para identificar esta conexão.
-
Insira o Identificador de cluster para especificar a qual cluster você deseja se conectar. Observação: insira somente o identificador do cluster e não o endpoint completo do cluster do Amazon Redshift.
-
Insira o Nome do banco de dados ao qual deseja se conectar.
-
Insira um Usuário do banco de dados para identificar o usuário que você deseja usar para se conectar ao banco de dados.
-
Para a DESCARREGAR perfil do IAM, insira o ARN do perfil do IAM da função que o cluster do Amazon Redshift deve assumir para mover e gravar dados no Amazon S3. Para obter mais informações sobre essa função, consulte Autorizar o Amazon Redshift a acessar AWS outros serviços em seu nome no Guia de gerenciamento do Amazon Redshift.
-
Selecione Conectar.
-
(Opcional) Para o local de saída do Amazon S3, especifique o URI do S3 para armazenar os resultados da consulta.
-
(Opcional) Para ID da chave KMS, especifique o ARN da chave ou AWS KMS alias. A imagem a seguir mostra onde você pode encontrar qualquer chave no AWS Management Console.
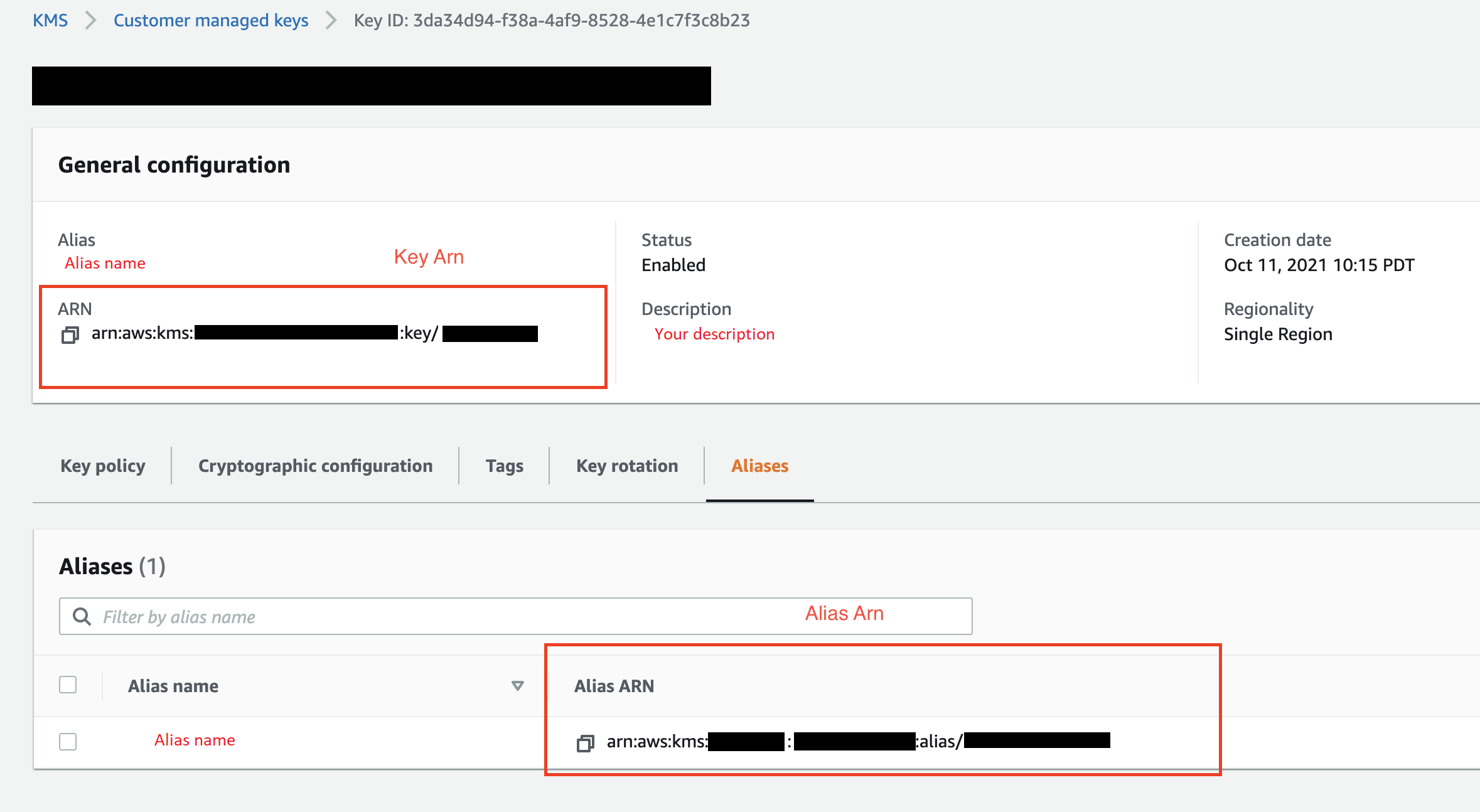
A imagem a seguir mostra todos os campos do procedimento anterior.
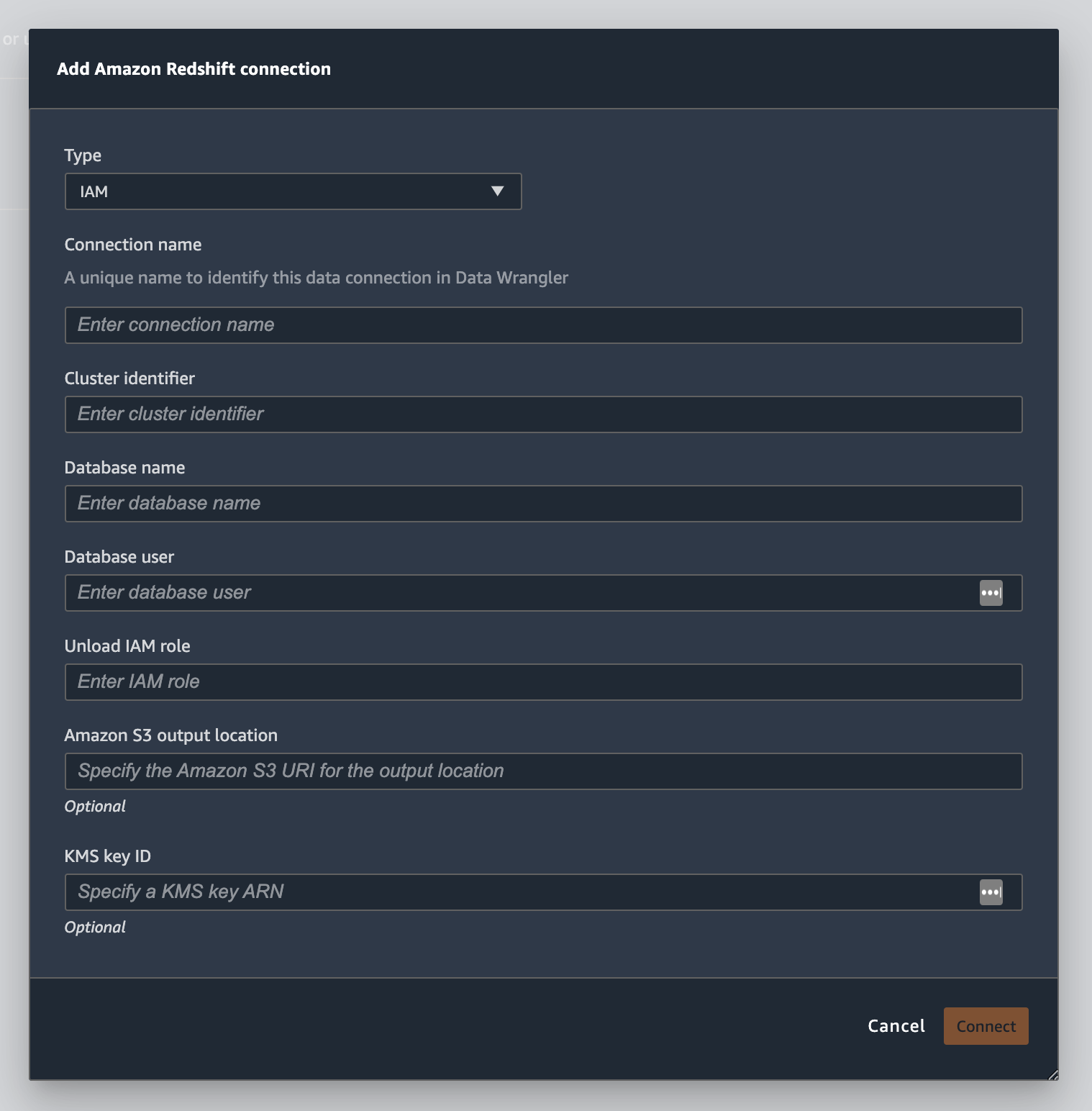
Depois que sua conexão for estabelecida com sucesso, ela aparecerá como uma fonte de dados em Importação de dados. Selecione essa fonte de dados para consultar seu banco de dados e importar dados.
Para consultar e importar dados do Amazon Redshift:
-
Selecione a conexão que você deseja consultar nas Fontes de dados.
-
Selecione um Esquema. Para saber mais sobre esquemas do Amazon Redshift, consulte Esquemas no Guia do desenvolvedor de banco de dados do Amazon Redshift.
-
(Opcional) Em Configuração avançada, especifique o método de Amostragem que você gostaria de usar.
-
Digite sua consulta no editor de consultas e escolha Executar para executar a consulta. Após uma consulta bem-sucedida, você pode visualizar seu resultado abaixo do editor.
-
Selecione Importar conjunto de dados para importar o conjunto de dados que foi consultado.
-
Insira um nome de conjunto de dados. Se você adicionar um Nome de conjunto de dados que contém espaços, esses espaços serão substituídos por underscores quando o conjunto de dados for importado.
-
Escolha Adicionar.
Para editar um conjunto de dados, siga os seguintes passos:
-
Navegue até o fluxo do Data Wrangler.
-
Escolha o + ao lado de Fonte - Amostragem.
-
Alterar os dados que você está importando.
-
Escolha Aplicar
Importar dados do Amazon EMR
Você pode usar o Amazon EMR como fonte de dados para seu fluxo do Amazon SageMaker Data Wrangler. O Amazon EMR é uma plataforma de cluster gerenciada que você pode usar para processar e analisar grandes quantidades de dados. Para obter mais informações sobre o Amazon EMR, consulte O que é o Amazon EMR?. Para importar um conjunto de dados do EMR, você se conecta a ele e o consulta.
Importante
É necessário cumprir os seguintes pré-requisitos para se conectar a um cluster do Amazon EMR:
Pré-requisitos
-
Configurações de rede
-
Você tem uma Amazon VPC na região que está usando para iniciar o Amazon SageMaker Studio Classic e o Amazon EMR.
-
Tanto o Amazon EMR quanto o Amazon SageMaker Studio Classic devem ser lançados em sub-redes privadas. Podem estar na mesma sub-rede ou em sub-redes diferentes.
-
O Amazon SageMaker Studio Classic deve estar no modo somente VPC.
Para obter mais informações sobre como criar uma VPC, consulte Criar uma VPC.
Para obter mais informações sobre a criação de uma VPC, consulte Connect SageMaker Studio Classic Notebooks em uma VPC a recursos externos.
-
Os clusters do Amazon EMR que você está executando devem estar na mesma Amazon VPC.
-
Os clusters do Amazon EMR e o Amazon VPC devem estar na mesma conta. AWS
-
Seus clusters do Amazon EMR estão executando o Hive ou o Presto.
-
Os clusters do Hive devem permitir o tráfego de entrada dos grupos de segurança do Studio Classic na porta 10000.
-
Os clusters do Presto devem permitir tráfego de entrada dos grupos de segurança do Studio Classic na porta 8889.
nota
O número da porta é diferente para clusters do Amazon EMR que usam funções do IAM. Navegue até o final da seção de pré-requisitos para obter mais informações.
-
-
-
SageMaker Estúdio clássico
-
O Amazon SageMaker Studio Classic deve executar o Jupyter Lab versão 3. Para obter informações sobre como atualizar a versão do Jupyter Lab, consulte Visualize e atualize a JupyterLab versão de um aplicativo no console.
-
O Amazon SageMaker Studio Classic tem uma função do IAM que controla o acesso do usuário. A função padrão do IAM que você está usando para executar o Amazon SageMaker Studio Classic não tem políticas que possam lhe dar acesso aos clusters do Amazon EMR. É necessário anexar a política que concede permissões ao perfil do IAM. Para obter mais informações, consulte Configurar a listagem de clusters do Amazon EMR.
-
O perfil do IAM também deve ter a seguinte política anexada
secretsmanager:PutResourcePolicy: -
Se estiver utilizando um domínio do Studio Classic que já foi criado, certifique-se de que
AppNetworkAccessTypeestá no modo de somente VPC. Para obter informações sobre como atualizar um domínio para usar o modo somente VPC, consulte Desligue e atualize o SageMaker Studio Classic.
-
-
Clusters do Amazon EMR
-
Você deve ter o Hive ou o Presto instalados em seu cluster.
-
A versão do Amazon EMR deve ser da versão 5.5.0 ou posterior.
nota
O Amazon EMR oferece apoio à terminação automática. A terminação automática impede a execução de clusters ociosos e evita que você incorra em custos. A seguir estão as versões que são compatíveis com a terminação automática:
-
Para versões 6.x, versão 6.1.0 ou posterior.
-
Para versões 5.x, versão 5.30.0 ou posterior.
-
-
-
Clusters do Amazon EMR usando funções de runtime do IAM
-
Use as páginas a seguir para configurar perfis de runtime do IAM para o cluster do Amazon EMR. É necessário habilitar a criptografia em trânsito ao usar funções de runtime:
-
Você deve usar o Lake Formation como uma ferramenta de governança para os dados em seus bancos de dados. Você também deve usar a filtragem de dados externa para controle de acesso.
-
Para obter mais informações sobre Lake Formation, consulte O que é AWS Lake Formation?
-
Para obter mais informações sobre a integração do Lake Formation ao Amazon EMR, consulte Integração de serviços de terceiros com o Lake Formation.
-
-
A versão do seu cluster deve ser 6.9.0 ou posterior.
-
Acesso AWS Secrets Manager a. Para obter mais informações sobre o Secrets Manager, consulte O que é o AWS Secrets Manager?
-
Os clusters do Hive devem permitir o tráfego de entrada dos grupos de segurança do Studio Classic na porta 10000.
-
Uma Amazon VPC é uma rede virtual que está logicamente isolada de outras redes na nuvem. AWS O Amazon SageMaker Studio Classic e seu cluster do Amazon EMR só existem dentro da Amazon VPC.
Use o procedimento a seguir para iniciar o Amazon SageMaker Studio Classic em uma Amazon VPC.
Para executar o Studio Classic em uma VPC, siga os seguintes passos:
-
Navegue até o console de SageMaker IA em https://console.aws.amazon.com/sagemaker/
. -
Escolha Launch SageMaker Studio Classic.
-
Escolha Configuração padrão.
-
Em Perfil de execução padrão, escolha o perfil do IAM para configurar o Studio Classic.
-
Escolha a VPC em que você lançou os clusters do Amazon EMR.
-
Em Sub-rede, escolha a sub-rede privada.
-
Para Grupos de segurança, especifique os grupos de segurança que você está usando para controlar entre sua VPC.
-
Escolha Somente VPC.
-
(Opcional) AWS usa uma chave de criptografia padrão. Você também pode especificar outra chave do AWS Key Management Service para criptografar os dados.
-
Escolha Próximo.
-
Em Configurações do Studio, selecione as configurações mais adequadas para suas necessidades.
-
Escolha Avançar para pular as configurações do SageMaker Canvas.
-
Escolha Avançar para ignorar as RStudio configurações.
Se você não tiver um cluster do Amazon EMR pronto, você pode seguir o procedimento abaixo para criar um. Para obter mais informações sobre o Amazon EMR, consulte O que é o Amazon EMR?.
Para criar um cluster, siga os seguintes passos:
-
Navegue até o AWS Management Console.
-
Na barra de pesquisa, especifique
Amazon EMR. -
Selecione Criar cluster.
-
Em Nome do cluster, especifique o nome do seu cluster.
-
Em Lançar, selecione a versão de lançamento do cluster.
nota
O Amazon EMR oferece apoio à terminação automática para as seguintes versões:
-
Para versões 6.x, versão 6.1.0 ou posterior.
-
Para versões 5.x, versão 5.30.0 ou posterior.
A terminação automática impede a execução de clusters ociosos e evita que você incorra em custos.
-
-
(Opcional) Para Aplicativos, escolha Presto.
-
Escolha a aplicação que você está executando no cluster.
-
Em Redes, para Configuração de hardware, especifique as configurações de hardware.
Importante
Em Rede, escolha a VPC que está executando o Amazon SageMaker Studio Classic e escolha uma sub-rede privada.
-
Em Segurança e acesso, especifique as configurações de segurança.
-
Escolha Criar.
Para ver um tutorial sobre a criação de um cluster do Amazon EMR, consulte Conceitos básicos do Amazon EMR. Para obter informações sobre as melhores práticas para configurar um cluster, consulte Considerações e melhores práticas.
nota
Para as melhores práticas de segurança, o Data Wrangler só pode se conectar VPCs em sub-redes privadas. Você não pode se conectar ao nó principal, a menos que use AWS Systems Manager para suas instâncias do Amazon EMR. Para obter mais informações, consulte Protegendo o acesso aos clusters do EMR usando AWS Systems Manager
Atualmente, você pode usar os seguintes métodos para acessar um cluster do Amazon EMR:
-
Sem autenticação
-
Lightweight Directory Access Protocol (LDAP)
-
IAM (função de runtime)
Não usar a autenticação ou usar o LDAP pode exigir que você crie vários clusters e perfis de EC2 instância da Amazon. Se você for um administrador, talvez seja necessário fornecer a grupos de usuários diferentes níveis de acesso aos dados. Esses métodos podem resultar em sobrecarga administrativa que dificulta o gerenciamento de seus usuários.
Recomendamos usar uma função de runtime do IAM que ofereça a vários usuários a capacidade de se conectar ao mesmo cluster do Amazon EMR. Uma função de runtime é um perfil do IAM que você pode atribuir a um usuário que está se conectando a um cluster do Amazon EMR. Você pode configurar o perfil do IAM em runtime para ter permissões específicas para cada grupo de usuários.
Use as seções a seguir para criar um cluster Presto ou Hive Amazon EMR com o LDAP ativado.
Use as seções a seguir para usar a autenticação LDAP para clusters do Amazon EMR que você já criou.
Use o procedimento a seguir para importar dados de um cluster.
Para importar dados de um cluster, siga os seguintes passos:
-
Abra um fluxo do Data Wrangler.
-
Escolha Criar conexão.
-
Escolha Amazon EMR.
-
Execute um destes procedimentos:
-
(Opcional) Para Secrets ARN, especifique o Amazon Resource Number (ARN) do banco de dados dentro do cluster. Os segredos fornecem segurança adicional. Para obter mais informações sobre segredos, consulte O que é AWS Secrets Manager? Para obter informações sobre como criar um segredo para seu cluster, consulte Criando um AWS Secrets Manager segredo para seu cluster.
Importante
Você deve especificar um segredo se estiver usando uma função de runtime do IAM para autenticação.
-
Na tabela suspensa, escolha um cluster.
-
-
Escolha Próximo.
-
Em Selecionar um endpoint para
example-cluster-namecluster, escolha um mecanismo de consulta. -
(Opcional) Selecione Salvar conexão.
-
Escolha Avançar, selecione login e escolha uma das seguintes regras:
-
Sem autenticação
-
LDAP
-
IAM
-
-
Em Login no
example-cluster-namecluster, especifique o nome de usuário e a senha do cluster. -
Selecione Conectar.
-
No editor de consultas, especifique uma consulta SQL.
-
Escolha Executar.
-
Escolha Importar.
Criando um AWS Secrets Manager segredo para seu cluster
Se estiver usando uma função de runtime do IAM para acessar seu cluster Amazon EMR, você deve armazenar as credenciais que está usando para acessar o Amazon EMR como um segredo no Secrets Manager. Você armazena todas as credenciais que usa para acessar o cluster dentro do segredo.
Você deve armazenar as seguintes informações em segredo:
-
Endpoint JDBC:
jdbc:hive2:// -
Nome do DNS: o nome DNS do seu cluster do Amazon EMR. É o endpoint do nó primário ou o nome do host.
-
Porta -
8446
Você também pode armazenar as seguintes informações adicionais dentro do segredo:
-
Perfil do IAM: O perfil do IAM que você está usando para acessar o cluster. O Data Wrangler usa sua função de execução de SageMaker IA por padrão.
-
Caminho do armazenamento confiável: Por padrão, o Data Wrangler cria um caminho do armazenamento confiável para você. Também é possível usar seu próprio caminho de armazenamento de confiança. Para obter mais informações sobre caminhos de armazenamento confiável, consulte Criptografia em trânsito em 2. HiveServer
-
Senha do Truststore: Por padrão, o Data Wrangler cria uma senha do Truststore para você. Também é possível usar seu próprio caminho de armazenamento de confiança. Para obter mais informações sobre caminhos de armazenamento confiável, consulte Criptografia em trânsito em 2. HiveServer
Use o procedimento a seguir para armazenar as credenciais em um segredo do Secrets Manager.
Para armazenar suas credenciais como um segredo, siga os seguintes passos:
-
Navegue até o AWS Management Console.
-
Na barra de pesquisa, especifique Secrets Manager.
-
Selecione AWS Secrets Manager.
-
Selecione Armazenar um novo segredo.
-
Em Tipo de segredo, escolha Outro tipo de segredo.
-
Em Pares de chave/valor, selecione Texto sem formatação.
-
Para clusters que executam o Hive, você pode usar o modelo a seguir para autenticação do IAM.
{"jdbcURL": "" "iam_auth": {"endpoint": "jdbc:hive2://", #required "dns": "ip-xx-x-xxx-xxx.ec2.internal", #required "port": "10000", #required "cluster_id": "j-xxxxxxxxx", #required "iam_role": "arn:aws:iam::xxxxxxxx:role/xxxxxxxxxxxx", #optional "truststore_path": "/etc/alternatives/jre/lib/security/cacerts", #optional "truststore_password": "changeit" #optional }}nota
Depois de importar seus dados, você aplica transformações a eles. Em seguida, você exporta os dados que transformou para um local específico. Se você estiver utilizando um caderno Jupyter para exportar seus dados transformados para o Amazon S3, é necessário usar o caminho do truststore especificado no exemplo anterior.
Um segredo do Secrets Manager armazena a URL do JDBC do cluster Amazon EMR como um segredo. Usar um segredo é mais seguro do que inserir diretamente suas credenciais.
Use o procedimento a seguir para armazenar o URL do JDBC como um segredo.
Para armazenar o URL do JDBC como um segredo, siga os seguintes passos:
-
Navegue até o AWS Management Console.
-
Na barra de pesquisa, especifique Secrets Manager.
-
Selecione AWS Secrets Manager.
-
Selecione Armazenar um novo segredo.
-
Em Tipo de segredo, escolha Outro tipo de segredo.
-
Para pares de chave/valor, especifique
jdbcURLcomo chave e uma URL JDBC válida como valor.O formato de um URL JDBC válido depende do uso da autenticação e do uso do Hive ou do Presto como mecanismo de consulta. A lista a seguir mostra os formatos de URL JBDC válidos para as diferentes configurações possíveis.
-
Hive, sem autenticação -
jdbc:hive2://emr-cluster-master-public-dns:10000/; -
Hive, autenticação LDAP:
jdbc:hive2://emr-cluster-master-public-dns-name:10000/;AuthMech=3;UID=david;PWD=welcome123; -
Para o Hive com SSL ativado, o formato de URL do JDBC depende se você usa um arquivo Java Keystore para a configuração do TLS. O Java Keystore File ajuda a verificar a identidade do nó principal do cluster Amazon EMR. Para usar um arquivo Java Keystore, gere-o em um cluster do EMR e carregue-o no Data Wrangler. Para gerar um arquivo, use o seguinte comando no cluster do Amazon EMR:
keytool -genkey -alias hive -keyalg RSA -keysize 1024 -keystore hive.jks. Para obter informações sobre a execução de comandos em um cluster do Amazon EMR, consulte Protegendo o acesso aos clusters do EMRusando. AWS Systems Manager Para carregar um arquivo, escolha a seta para cima na navegação à esquerda da interface do usuário do Data Wrangler. A seguir estão os formatos de URL JDBC válidos para o Hive com SSL ativado:
-
Sem um arquivo Java Keystore:
jdbc:hive2://emr-cluster-master-public-dns:10000/;AuthMech=3;UID=user-name;PWD=password;SSL=1;AllowSelfSignedCerts=1; -
Com um arquivo Java Keystore:
jdbc:hive2://emr-cluster-master-public-dns:10000/;AuthMech=3;UID=user-name;PWD=password;SSL=1;SSLKeyStore=/home/sagemaker-user/data/Java-keystore-file-name;SSLKeyStorePwd=Java-keystore-file-passsword;
-
-
Pronto, sem autenticação — jdbc:presto: //:8889/;
emr-cluster-master-public-dns -
Para o Presto com autenticação LDAP e SSL habilitado, o formato da URL JDBC depende se você está utilizando um arquivo Java Keystore para a configuração do TLS. O Java Keystore File ajuda a verificar a identidade do nó principal do cluster Amazon EMR. Para usar um arquivo Java Keystore, gere-o em um cluster do EMR e carregue-o no Data Wrangler. Para carregar um arquivo, escolha a seta para cima na navegação à esquerda da interface do usuário do Data Wrangler. Para obter informações sobre como criar um arquivo de armazenamento de chaves Java para o Presto, consulte Arquivo de armazenamento de chaves Java
para TLS. Para obter informações sobre a execução de comandos em um cluster do Amazon EMR, consulte Protegendo o acesso aos clusters do EMR usando. AWS Systems Manager -
Sem um arquivo Java Keystore:
jdbc:presto://emr-cluster-master-public-dns:8889/;SSL=1;AuthenticationType=LDAP Authentication;UID=user-name;PWD=password;AllowSelfSignedServerCert=1;AllowHostNameCNMismatch=1; -
Com um arquivo Java Keystore:
jdbc:presto://emr-cluster-master-public-dns:8889/;SSL=1;AuthenticationType=LDAP Authentication;SSLTrustStorePath=/home/sagemaker-user/data/Java-keystore-file-name;SSLTrustStorePwd=Java-keystore-file-passsword;UID=user-name;PWD=password;
-
-
Durante o processo de importação de dados de um cluster do Amazon EMR, você pode ter problemas. Para obter informações sobre resolução de problemas, consulte Solucionar problemas com o Amazon EMR.
Importar dados do Databricks (JDBC)
Você pode usar o Databricks como fonte de dados para seu fluxo do Amazon SageMaker Data Wrangler. Para importar um conjunto de dados do Databricks, utilize a funcionalidade de importação JDBC (Java Database Connectivity) para acessar o seu banco de dados Databricks. Depois de acessar o banco de dados, especifique uma consulta SQL para obter os dados e importá-los.
Presumimos que você tenha um cluster do Databricks em execução e que tenha configurado seu driver JDBC para ele. Para mais informações, consulte as seguintes páginas de documentação do Databricks:
O Data Wrangler armazena seu URL JDBC em. AWS Secrets Manager Você deve dar à sua função de execução do Amazon SageMaker Studio Classic IAM permissões para usar o Secrets Manager. Use o seguinte procedimento para conceder permissões:
Para conceder permissões ao Secrets Manager, siga os seguintes passos:
-
Faça login no AWS Management Console e abra o console do IAM em https://console.aws.amazon.com/iam/
. -
Escolha Perfis.
-
Na barra de pesquisa, especifique a função de execução do Amazon SageMaker AI que o Amazon SageMaker Studio Classic está usando.
-
Selecione o perfil de .
-
Escolha Adicionar permissões.
-
Escolha Criar política em linha.
-
Para Serviço, especifique Secrets Manager e escolha-o.
-
Em Ações, selecione o ícone de seta ao lado de Gerenciamento de permissões.
-
Selecione PutResourcePolicy.
-
Em Recursos, selecione Específico.
-
Escolha a caixa de seleção ao lado de Qualquer nesta conta.
-
Selecione Revisar política.
-
Em Nome, especifique um nome.
-
Selecione Criar política.
Você pode usar partições para importar seus dados mais rapidamente. As partições dão ao Data Wrangler a capacidade de processar os dados em paralelo. Por padrão, o Data Wrangler usa 2 partições. Para a maioria dos casos de uso, duas partições oferecem velocidades de processamento de dados quase ideais.
Se você optar por especificar mais de duas partições, também poderá especificar uma coluna para particionar os dados. O tipo dos valores na coluna deve ser numérico ou de data.
Recomendamos usar partições somente se você entender a estrutura dos dados e como eles são processados.
Você pode importar o conjunto de dados inteiro ou fazer uma amostra de uma parte dele. Para um banco de dados Databricks, ele fornece as seguintes opções de amostragem:
-
Nenhum: Importar todo o conjunto de dados.
-
Primeiro K: Fazer uma amostra das primeiras K linhas do conjunto de dados, em que K é um número inteiro que você especifica.
-
Aleatório - obtém uma amostra aleatória de um tamanho especificado por você.
-
Estratificado - obtém uma amostra aleatória estratificada. Uma amostra estratificada preserva proporção de valores em uma coluna.
Use o procedimento a seguir para importar seus dados de um banco de dados do Databricks.
Para importar dados do Databricks, siga os seguintes passos:
-
Faça login no Amazon SageMaker AI Console
. -
Escolha Studio.
-
Escolha Iniciar aplicação.
-
Na lista suspensa, selecione Studio.
-
Na guia Importar dados do seu fluxo do Data Wrangler, escolha Databricks.
-
Especifique os seguintes campos:
-
Nome do conjunto de dados: Um nome que você deseja usar para o conjunto de dados em seu fluxo do Data Wrangler.
-
Driver: com.simba.spark.jdbc.Driver.
-
URL do JDBC: O URL do banco de dados Databricks. A formatação do URL pode variar entre as instâncias do Databricks. Para obter informações sobre como encontrar a URL e especificar os parâmetros dentro dela, consulte Parâmetros de configuração e conexão do JDBC
. Veja a seguir um exemplo de como um URL pode ser formatado: jdbc:spark://aws-sagemaker-datawrangler.cloud.databricks.com:443/default; transportMode=http; ssl=1; httpPath= /3122619508517275/0909-200301-cut318; =3; UID=; PWD=. sql/protocolv1/o AuthMech tokenpersonal-access-tokennota
Você pode especificar um ARN secreto que contenha a URL do JDBC em vez de especificar a própria URL do JDBC. O segredo deve conter um par de valores-chave com o seguinte formato:
jdbcURL:. Para obter mais informações, consulte O que é o Secrets Manager?JDBC-URL
-
-
Especifique uma instrução SQL SELECT.
nota
O Data Wrangler não oferece apoio a expressões de tabela comuns (CTE) ou tabelas temporárias em uma consulta.
-
Para Amostragem, escolha um método de amostragem.
-
Escolha Executar.
-
(Opcional) Para o VISUALIZAÇÃO, escolha a engrenagem para abrir as configurações de partição.
-
Especifique o número de partições. Você pode particionar por coluna se especificar o número de partições:
-
Insira o número de partições: Especifique um valor maior que 2.
-
(Opcional) Partição por coluna: Especifique os seguintes campos: Você só pode particionar por uma coluna se tiver especificado um valor para Inserir número de partições.
-
Selecionar coluna: Selecione a coluna que você está usando para a partição de dados. O tipo de dados da coluna deve ser numérico ou de data.
-
Limite superior: Dos valores na coluna que você especificou, o limite superior é o valor que você está usando na partição. O valor que você especifica não altera os dados que você está importando. Isso afeta apenas a velocidade da importação. Para obter o melhor desempenho, especifique um limite superior próximo do máximo da coluna.
-
Limite inferior: Dos valores na coluna que você especificou, o limite inferior é o valor que você está usando na partição. O valor que você especifica não altera os dados que você está importando. Isso afeta apenas a velocidade da importação. Para obter o melhor desempenho, especifique um limite inferior próximo ao mínimo da coluna.
-
-
-
-
Escolha Importar.
Importar dados do Salesforce Data Cloud
Você pode usar o Salesforce Data Cloud como fonte de dados no Amazon Data Wrangler para preparar SageMaker os dados em seu Salesforce Data Cloud para aprendizado de máquina.
Com o Salesforce Data Cloud como fonte de dados no Data Wrangler, você pode conectar-se rapidamente aos dados do Salesforce sem escrever uma única linha de código. Você pode unir seus dados do Salesforce com dados de qualquer outra fonte de dados no Data Wrangler.
Depois de se conectar à nuvem de dados, você pode fazer o seguinte:
-
Visualize seus dados com visualizações integradas
-
Entenda os dados e identifique possíveis erros e valores extremos
-
Dados da transformação com mais de 300 transformações integradas
-
Exporte os dados que você transformou
Configuração do administrador
Importante
Antes de começar, certifique-se de que seus usuários estejam executando a versão 1.3.0 ou posterior do Amazon SageMaker Studio Classic. Para obter informações sobre como verificar a versão do Studio Classic e atualizá-la, consulte Prepare dados de ML com o Amazon SageMaker Data Wrangler.
Ao configurar o acesso ao Salesforce Data Cloud, você deve concluir as seguintes tarefas:
-
Obter seu URL de domínio do Salesforce. O Salesforce também se refere ao URL do domínio como o URL da sua organização.
-
Obter OAuth credenciais da Salesforce.
-
Obter o URL de autorização e o URL do token para seu domínio do Salesforce.
-
Criando um AWS Secrets Manager segredo com a OAuth configuração.
-
Criar uma configuração de duração que o Data Wrangler usa para ler as credenciais do segredo.
-
Conceder ao Data Wrangler permissões para ler o segredo.
Depois de realizar as tarefas anteriores, seus usuários podem fazer login no Salesforce Data Cloud usando. OAuth
nota
Seus usuários podem ter problemas depois de configurar tudo. Para obter informações sobre resolução de problemas, consulte Solução de problemas com o Salesforce.
Siga o procedimento abaixo para obter o URL do domínio.
-
Navegue até a página de login do Salesforce.
-
Em Busca rápida, especifique Meu domínio.
-
Copie o valor da URL atual do meu domínio em um arquivo de texto.
-
Adicione
https://ao início do URL.
Depois de obter o URL do domínio do Salesforce, você pode usar o procedimento a seguir para obter as credenciais de login do Salesforce e permitir que o Data Wrangler acesse seus dados do Salesforce.
Para obter as credenciais de login do Salesforce e fornecer acesso ao Data Wrangler, siga os seguintes passos:
-
Navegue até o URL do seu domínio do Salesforce e faça login na sua conta.
-
Escolha o ícone de engrenagem.
-
Na barra de pesquisa exibida, especifique Gerenciador de aplicação.
-
Selecione Nova aplicação conectado.
-
Especifique os seguintes campos:
-
Nome da aplicação conectado: Você pode especificar qualquer nome, mas recomendamos escolher um nome que inclua Data Wrangler. Por exemplo, você pode especificar a integração do Salesforce Data Cloud Data Wrangler.
-
Nome da API: use o valor padrão.
-
E-mail de contato: Especifique seu endereço de e-mail.
-
No título API (Ativar OAuth configurações), marque a caixa de seleção para ativar OAuth as configurações.
-
Para URL de retorno de chamada, especifique a URL do Amazon SageMaker Studio Classic. Para obter a URL do Studio Classic, acesse-a a partir do AWS Management Console e copie a URL.
-
-
Em OAuth Escopos selecionados, mova o seguinte dos Escopos disponíveis para OAuth Escopos selecionados OAuth:
-
Gerenciar dados do usuário via APIs (
api) -
Execute solicitações a qualquer momento (
refresh_token,offline_access) -
Execute consultas ANSI SQL em dados do Salesforce Data Cloud (
cdp_query_api) -
Gerenciar dados de perfil da Salesforce Customer Data Platform (
cdp_profile_api)
-
-
Escolha Salvar. Depois de salvar suas alterações, o Salesforce abre uma nova página.
-
Escolha Continue
-
Navegue até Chave e segredo do consumidor.
-
Escolha Gerenciar detalhes do consumidor. O Salesforce redireciona você para uma nova página na qual talvez você precise passar pela autenticação de dois fatores.
-
Importante
Copie a chave do consumidor e o segredo do consumidor em um editor de texto. Você precisa dessas informações para conectar a nuvem de dados ao Data Wrangler.
-
Navegue de volta para Gerenciar aplicações conectados.
-
Navegue até Nome da aplicação conectado e o nome da sua aplicação.
-
Escolha Gerenciar.
-
Selecione Editar políticas.
-
Altere o Relaxamento de IP para relaxar as restrições de IP.
-
Escolha Salvar.
-
Depois de fornecer acesso à sua Salesforce Data Cloud, você precisa fornecer permissões para seus usuários. Siga o procedimento abaixo para fornecer permissões.
Para fornecer permissões aos seus usuários, siga os seguintes passos:
-
Navegue até a página inicial de configuração.
-
Na navegação à esquerda, pesquise Usuários e escolha o item de menu Usuários.
-
Escolha o hiperlink com seu nome de usuário.
-
Navegue até Atribuições do conjunto de permissões.
-
Escolha Editar exercícios.
-
Adicione as seguintes permissões:
-
Administrador da plataforma de dados do cliente
-
Especialista em reconhecimento de dados da plataforma de dados do cliente
-
-
Escolha Salvar.
Depois de obter as informações do seu domínio do Salesforce, você deve obter a URL de autorização e a URL do token para o AWS Secrets Manager segredo que está criando.
Use o procedimento a seguir para obter o URL de autorização e o URL do token.
Para obter o URL de autorização e o URL do token
-
Navegue até o URL do seu domínio do Salesforce.
-
Use um dos métodos a seguir para obter URLs o. Se você estiver em uma distribuição Linux com
curlejqinstalada, recomendamos usar o método que só funciona no Linux.-
(Somente Linux) Especifique o seguinte comando em seu terminal:
curlsalesforce-domain-URL/.well-known/openid-configuration | \ jq '. | { authorization_url: .authorization_endpoint, token_url: .token_endpoint }' | \ jq '. += { identity_provider: "SALESFORCE", client_id: "example-client-id", client_secret: "example-client-secret" }' -
-
Navegue até
example-org-URL/.well-known/openid-configuration -
Copie o
authorization_endpointetoken_endpointpara um editor de texto. -
Crie o seguinte objeto JSON:
{ "identity_provider": "SALESFORCE", "authorization_url": "example-authorization-endpoint", "token_url": "example-token-endpoint", "client_id": "example-consumer-key", "client_secret": "example-consumer-secret" }
-
-
Depois de criar o objeto OAuth de configuração, você pode criar um AWS Secrets Manager segredo que o armazene. Use o procedimento a seguir para criar o segredo.
Para criar um segredo, siga os seguintes passos:
-
Navegue até o console do AWS Secrets Manager
. -
Selecione Armazenar um segredo.
-
Selecione Outro tipo de segredo.
-
Em Pares de chave/valor, selecione Texto sem formatação.
-
Substitua o JSON vazio pelas seguintes configurações:
{ "identity_provider": "SALESFORCE", "authorization_url": "example-authorization-endpoint", "token_url": "example-token-endpoint", "client_id": "example-consumer-key", "client_secret": "example-consumer-secret" } -
Escolha Próximo.
-
Em Nome secreto, especifique o nome do segredo.
-
Em Abas, escolha Adicionar.
-
Para a Chave, especifique sagemaker:partner. Para Valor, recomendamos especificar um valor que possa ser útil para seu caso de uso. Porém, você não pode especificar qualquer coisa.
Importante
Você deve criar a chave. Você não pode importar seus dados do Salesforce se não os criar.
-
-
Escolha Próximo.
-
Escolha Armazenar.
-
Escolha o segredo que você criou.
-
Anote sobre os seguintes campos:
-
O Amazon Resource Number (ARN) do segredo.
-
O nome do segredo
-
Depois de criar o segredo, você deverá adicionar permissões para que o Data Wrangler leia o segredo. Use o seguinte procedimento para adicionar permissões:
Para adicionar permissões de leitura ao Data Wrangler, siga os seguintes passos:
-
Navegue até o console do Amazon SageMaker AI
. -
Escolha Domínios.
-
Escolha o domínio que você está usando para acessar o Data Wrangler.
-
Escolha seu Perfil de usuário.
-
Em Detalhes, encontre a Função de execução. O ARN está no seguinte formato:
arn:aws:iam::111122223333:role/. Anote a função de execução da SageMaker IA. Dentro do ARN, é tudo o que vem depois doexample-rolerole/. -
Navegue até o console do IAM
. -
Na barra de pesquisa do Search IAM, especifique o nome da função de execução da SageMaker IA.
-
Selecione o perfil de .
-
Escolha Adicionar permissões.
-
Escolha Criar política em linha.
-
Selecione a guia JSON.
-
Especifique a política a seguir no editor.
-
Escolha Revisar política.
-
Em Nome, especifique um nome.
-
Selecione Criar política.
Depois de conceder permissões ao Data Wrangler para ler o segredo, você deve adicionar uma configuração de ciclo de vida que usa seu segredo do Secrets Manager ao seu perfil de usuário do Amazon SageMaker Studio Classic.
Use o seguinte procedimento para criar uma configuração de ciclo de vida e adicioná-la ao perfil do Studio Classic:
Para criar uma configuração de clico de vida e adicioná-la ao perfil do Studio Classic, faça o seguinte:
-
Navegue até o console do Amazon SageMaker AI.
-
Escolha Domínios.
-
Escolha o domínio que você está usando para acessar o Data Wrangler.
-
Escolha seu Perfil de usuário.
-
Se você ver os seguintes aplicações, exclua-os:
-
KernelGateway
-
JupyterKernel
nota
A exclusão das aplicações atualiza o Studio Classic. Pode demorar um pouco para que as atualizações aconteçam.
-
-
Enquanto você espera que as atualizações aconteçam, escolha as configurações do duração.
-
Verifique se a página em que você está diz Configurações de ciclo de vida do Studio.
-
Escolha Criar configuração.
-
Certifique-se de que a aplicação do servidor Jupyter tenha sido selecionado.
-
Escolha Próximo.
-
Em Nome, especifique um nome para a configuração.
-
Para Scripts, especifique o seguinte script:
#!/bin/bash set -eux cat > ~/.sfgenie_identity_provider_oauth_config <<EOL { "secret_arn": "secrets-arn-containing-salesforce-credentials" } EOL -
Selecione Enviar.
-
No painel de navegação à esquerda, escolha Domínios.
-
Escolha o seu domínio.
-
Escolha Ambiente.
-
Em Configurações de ciclo de vida para aplicações pessoais do Studio Classic, escolha Anexar.
-
Selecione Configuração existente.
-
Em Configurações de ciclo de vida do Studio Classic, selecione a configuração de duração que você criou.
-
Escolha Anexar ao domínio.
-
Marque a caixa de seleção ao lado da configuração de duração que você anexou.
-
Selecione Definir como padrão.
Você pode encontrar problemas ao configurar sua configuração de ciclo de duração. Para obter informações sobre como depurá-los, consulte Configuração de depuração do ciclo de vida.
Guia do cientista de dados
Use o seguinte para conectar o Salesforce Data Cloud e acessar seus dados no Data Wrangler:
Importante
Seu administrador precisa usar as informações nas seções anteriores para configurar o Salesforce Data Cloud. Se você estiver enfrentando problemas, entre em contato com eles para obter ajuda na solução de problemas.
Para abrir o Studio Classic e verificar sua versão, consulte o procedimento a seguir.
-
Use as etapas Pré-requisitos para acessar o Data Wrangler por meio do Amazon SageMaker Studio Classic.
-
Ao lado do usuário que você deseja usar para executar o Studio Classic, selecione Executar aplicação.
-
Escolha Studio.
Para criar um conjunto de dados no Data Wrangler com dados do Salesforce Data Cloud
-
Faça login no Amazon SageMaker AI Console
. -
Escolha Studio.
-
Escolha Iniciar aplicação.
-
Na lista suspensa, selecione Studio.
-
Escolha o ícone Início.
-
Escolha Dados.
-
Escolha Data Wrangler.
-
Escolha Importar dados.
-
Em Disponível, escolha Salesforce Data Cloud.
-
Em Nome da conexão, especifique um nome para sua conexão com o Salesforce Data Cloud.
-
Para URL da organização, especifique a URL da organização em sua conta do Salesforce. Você pode obter o URL dos seus administradores.
-
Selecione Conectar.
-
Especifique suas credenciais para fazer login no Salesforce.
Você pode começar a criar um conjunto de dados usando dados do Salesforce Data Cloud depois de se conectar a ele.
Depois de selecionar uma tabela, você pode escrever consultas e executá-las. A saída da sua consulta é exibida em Resultados da consulta.
Depois de definir a saída da sua consulta, você poderá importar a saída da sua consulta para um fluxo do Data Wrangler para realizar transformações de dados.
Depois de criar um conjunto de dados, navegue até a tela de Fluxo de dados para começar a transformar seus dados.
Importar dados do Snowflake
Você pode usar o Snowflake como fonte de dados no Data Wrangler para preparar SageMaker dados no Snowflake para aprendizado de máquina.
Com o Snowflake como fonte de dados no Data Wrangler, você pode conectar-se rapidamente ao Snowflake sem escrever uma única linha de código. Você pode unir seus dados no Snowflake com dados de qualquer outra fonte de dados no Data Wrangler.
Uma vez conectado, você pode consultar interativamente os dados armazenados no Snowflake, transformar dados com mais de 300 transformações de dados pré-configuradas, entender os dados e identificar possíveis erros e valores extremos com um conjunto de modelos de visualização pré-configurados robustos, identificar rapidamente inconsistências em seu fluxo de trabalho de preparação de dados e diagnosticar problemas antes que os modelos sejam implantados na produção. Por fim, você pode exportar seu fluxo de trabalho de preparação de dados para o Amazon S3 para uso com outros recursos de SageMaker IA, como Amazon SageMaker Autopilot, Amazon SageMaker Feature Store e Amazon Pipelines. SageMaker
Você pode criptografar a saída de suas consultas usando uma AWS Key Management Service chave que você criou. Para obter mais informações sobre AWS KMS, consulte AWS Key Management Service.
Guia do administrador
Importante
Para saber mais sobre controle de acesso granular e melhores práticas, consulte Controle de acesso de segurança
Esta seção é para administradores do Snowflake que estão configurando o acesso ao Snowflake a partir do Data Wrangler. SageMaker
Importante
Você é responsável por gerenciar e monitorar o controle de acesso no Snowflake. O Data Wrangler não adiciona uma camada de controle de acesso em relação ao Snowflake.
O controle de acesso inclui o seguinte:
-
Os dados que um usuário acessa
-
(Opcional) A integração de armazenamento que fornece ao Snowflake a capacidade de gravar resultados de consulta em um bucket do Amazon S3
-
As consultas que um usuário pode executar
(Opcional) Configurar as permissões de importação de dados do Snowflake
Por padrão, o Data Wrangler consulta os dados no Snowflake sem criar uma cópia deles em um local do Amazon S3. Use as informações a seguir se estiver configurando uma integração de armazenamento com o Snowflake. Seus usuários podem usar uma integração de armazenamento para armazenar os resultados da consulta em um local do Amazon S3.
Seus usuários podem ter diferentes níveis de acesso a dados confidenciais. Para obter segurança de dados ideal, forneça a cada usuário sua própria integração de armazenamento. Cada integração de armazenamento deve ter a sua própria política de governação de dados.
Esse atributo não está atualmente disponível nas Regiões que optaram por não participar.
O Snowflake requer as seguintes permissões em um bucket e diretório S3 para poder acessar os arquivos no diretório:
-
s3:GetObject -
s3:GetObjectVersion -
s3:ListBucket -
s3:ListObjects -
s3:GetBucketLocation
Criar uma política do IAM
Você deve criar uma política do IAM para configurar permissões de acesso para o Snowflake carregar e descarregar dados de um bucket do Amazon S3.
A seguir está o documento de política JSON que você usa para criar a política:
# Example policy for S3 write access # This needs to be updated { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:GetObjectVersion", "s3:DeleteObject", "s3:DeleteObjectVersion" ], "Resource": "arn:aws:s3:::bucket/prefix/*" }, { "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": "arn:aws:s3:::bucket/", "Condition": { "StringLike": { "s3:prefix": ["prefix/*"] } } } ] }
Para obter informações e procedimentos sobre a criação de políticas com documentos de políticas, consulte Criar políticas do IAM.
Para obter documentação que fornece uma visão geral do uso de permissões do IAM com Snowflake, consulte os seguintes recursos:
Para conceder permissão de uso da função Snowflake do cientista de dados para a integração de armazenamento, você deve executar GRANT USAGE ON INTEGRATION
integration_name TO snowflake_role;.
-
integration_nameé o nome da sua integração de armazenamento. -
snowflake_roleé o nome da função padrão do Snowflake atribuídaao usuário cientista de dados.
Configurando o Snowflake Access OAuth
Em vez de fazer com que seus usuários insiram suas credenciais diretamente no Data Wrangler, você pode fazer com que eles usem um provedor de identidade para acessar o Snowflake. A seguir estão links para a documentação do Snowflake para os provedores de identidade compatíveis com o Data Wrangler.
Use a documentação dos links anteriores para configurar o acesso ao seu provedor de identidade. As informações e procedimentos nesta seção ajudam você a entender como usar corretamente a documentação para acessar o Snowflake no Data Wrangler.
Seu provedor de identidade precisa reconhecer o Data Wrangler como uma aplicação. Use o seguinte procedimento para registrar o Data Wrangler como uma aplicação no provedor de identidade:
-
Selecione a configuração que inicia o processo de registro do Data Wrangler como uma aplicação.
-
Forneça aos usuários do provedor de identidade acesso ao Data Wrangler.
-
Ative a autenticação OAuth do cliente armazenando as credenciais do cliente como um AWS Secrets Manager segredo.
-
Especifique um URL de redirecionamento usando o seguinte formato: https://
domain-ID.studio.Região da AWS.sagemaker. aws/jupyter/default/labImportante
Você está especificando o ID de domínio do Amazon SageMaker AI e Região da AWS que está usando para executar o Data Wrangler.
Importante
Você deve registrar uma URL para cada domínio do Amazon SageMaker AI e Região da AWS onde você está executando o Data Wrangler. Usuários de um domínio e Região da AWS que não tenham o redirecionamento URLs configurado para eles não conseguirão se autenticar com o provedor de identidade para acessar a conexão do Snowflake.
-
Certifique-se de que o código de autorização e os tipos de concessão de token de atualização sejam permitidos para a aplicação Data Wrangler.
Em seu provedor de identidade, você deve configurar um servidor que envie OAuth tokens para o Data Wrangler no nível do usuário. O servidor envia os tokens com Snowflake como público.
O Snowflake usa o conceito de papéis que são papéis distintos dos papéis do IAM usados. AWS Você deve configurar o provedor de identidade para usar qualquer função para usar a função padrão associada à conta Snowflake. Por exemplo, se um usuário tiver systems administrator o perfil padrão em seu perfil do Snowflake, a conexão do Data Wrangler com o Snowflake será usada como perfil systems administrator.
Use o seguinte procedimento para configurar o servidor:
Para configurar o servidor, siga os seguintes passos: Você está trabalhando no Snowflake em todas as etapas, exceto na última.
-
Comece configurando o servidor ou a API.
-
Configure o servidor de autorização para usar o código de autorização e os tipos de concessão do token de atualização.
-
Especifique a vida útil do token de acesso.
-
Defina o tempo limite de inatividade do token de atualização. O tempo limite de inatividade é o tempo em que o token de atualização expira se não for usado.
nota
Se você estiver agendando trabalhos no Data Wrangler, recomendamos que o tempo limite de inatividade seja maior que a frequência do trabalho de processamento. Caso contrário, alguns trabalhos de processamento poderão falhar porque o token de atualização expirou antes que pudessem ser executados. Quando o token de atualização expirar, o usuário deverá autenticar novamente acessando a conexão que fez com o Snowflake por meio do Data Wrangler.
-
Especifique
session:role-anycomo o novo escopo.nota
Para o Azure AD, copie o identificador exclusivo do escopo. O Data Wrangler exige que você forneça o identificador.
-
Importante
Na Integração de OAuth Segurança Externa do Snowflake, habilite.
external_oauth_any_role_mode
Importante
O Data Wrangler não oferece apoio a tokens de atualização rotativos. O uso de tokens de atualização rotativos pode resultar em falhas de acesso ou na necessidade de login frequente dos usuários.
Importante
Se o token de atualização expirar, seus usuários deverão se autenticar novamente acessando a conexão que fizeram com o Snowflake por meio do Data Wrangler.
Depois de configurar o OAuth provedor, você fornece ao Data Wrangler as informações necessárias para se conectar ao provedor. Você pode usar a documentação do seu provedor de identidade para obter valores para os seguintes campos:
-
URL do token: A URL do token que o provedor de identidade envia ao Data Wrangler.
-
URL de autorização: A URL do servidor de autorização do provedor de identidade.
-
ID do cliente: O ID do provedor de identidade.
-
Segredo do cliente: O segredo que somente o servidor de autorização ou a API reconhecem.
-
(Somente Azure AD) As credenciais do OAuth escopo que você copiou.
Você armazena os campos e valores em um AWS Secrets Manager segredo e os adiciona à configuração do ciclo de vida do Amazon SageMaker Studio Classic que você está usando para o Data Wrangler. Uma configuração de duração é um script de shell. Use-o para tornar o nome do recurso da Amazon (ARN) do segredo acessível ao Data Wrangler. Para obter informações sobre a criação de segredos, consulte Mover segredos codificados para. AWS Secrets Manager Para obter informações sobre como usar as configurações de ciclo de vida no Studio Classic, consulte Use configurações de ciclo de vida para personalizar o Studio Classic .
Importante
Antes de criar um segredo do Secrets Manager, certifique-se de que a função de execução de SageMaker IA que você está usando para o Amazon SageMaker Studio Classic tenha permissões para criar e atualizar segredos no Secrets Manager. Para obter mais informações sobre como adicionar permissões, consulte Exemplo: permissão para criar segredos.
Para Okta e Ping Federate, o seguinte é o formato do segredo:
{ "token_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/token", "client_id":"example-client-id", "client_secret":"example-client-secret", "identity_provider":"OKTA"|"PING_FEDERATE", "authorization_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/authorize" }
Para o Azure AD, o formato do segredo é o seguinte:
{ "token_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/token", "client_id":"example-client-id", "client_secret":"example-client-secret", "identity_provider":"AZURE_AD", "authorization_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/authorize", "datasource_oauth_scope":"api://appuri/session:role-any)" }
Você deve ter uma configuração de duração que use o segredo do Secrets Manager que você criou. Você pode criar a configuração de duração ou modificar uma que já tenha sido criada. A configuração deve usar o script a seguir.
#!/bin/bash set -eux ## Script Body cat > ~/.snowflake_identity_provider_oauth_config <<EOL { "secret_arn": "example-secret-arn" } EOL
Para obter informações sobre como criar configurações de duração, consulte Criar e associar uma configuração de ciclo de vida. Quando estiver passando pelo processo de configuração, siga as seguintes instruções:
-
Defina o tipo de aplicação da configuração como
Jupyter Server. -
Anexe a configuração ao domínio Amazon SageMaker AI que tem seus usuários.
-
Faça com que a configuração seja executada por padrão. Ela deve ser executada sempre que um usuário fizer login no Studio Classic. Caso contrário, as credenciais salvas na configuração não estarão disponíveis para seus usuários quando eles estiverem usando o Data Wrangler.
-
A configuração de duração cria um arquivo com o nome,
snowflake_identity_provider_oauth_configna pasta inicial do usuário. O arquivo contém o segredo do Secrets Manager. Certifique-se de que ele esteja na pasta inicial do usuário toda vez que a instância do Jupyter Server for inicializada.
Conectividade privada entre o Data Wrangler e o Snowflake via AWS PrivateLink
Esta seção explica como usar AWS PrivateLink para estabelecer uma conexão privada entre o Data Wrangler e o Snowflake. As etapas são explicadas nas seguintes seções:
Crie uma VPC
Se você não tiver uma VPC configurada, siga as instruções Criar uma nova VPC para criar uma.
Depois de escolher uma VPC que você gostaria de usar para estabelecer uma conexão privada, forneça as seguintes credenciais ao administrador do Snowflake para habilitar AWS PrivateLink:
-
ID da VPC
-
AWS ID da conta
-
O URL da sua conta correspondente que você usa para acessar o Snowflake
Importante
Conforme descrito na documentação do Snowflake, habilitar sua conta do Snowflake pode levar até dois dias úteis.
Configurar a integração com o Snowflake AWS PrivateLink
Depois de AWS PrivateLink ativado, recupere a AWS PrivateLink configuração da sua região executando o comando a seguir em uma planilha do Snowflake. Faça login no console do Snowflake e insira o seguinte em Planilhas: select
SYSTEM$GET_PRIVATELINK_CONFIG();
-
Recupere os valores para o seguinte:
privatelink-account-name,privatelink_ocsp-url,privatelink-account-urleprivatelink_ocsp-urldo objeto JSON resultante. O seguinte trecho mostra exemplos de cada valor: Armazene esses valores para uso posterior.privatelink-account-name: xxxxxxxx.region.privatelink privatelink-vpce-id: com.amazonaws.vpce.region.vpce-svc-xxxxxxxxxxxxxxxxx privatelink-account-url: xxxxxxxx.region.privatelink.snowflakecomputing.com privatelink_ocsp-url: ocsp.xxxxxxxx.region.privatelink.snowflakecomputing.com -
Mude para o AWS console e navegue até o menu VPC.
-
No painel do lado esquerdo, escolha o link Endpoints para navegar até a configuração dos endpoints da VPC.
Uma vez lá, escolha Criar endpoint.
-
Selecione o botão de rádio para Localizar serviço por nome, conforme mostrado na captura de tela a seguir.
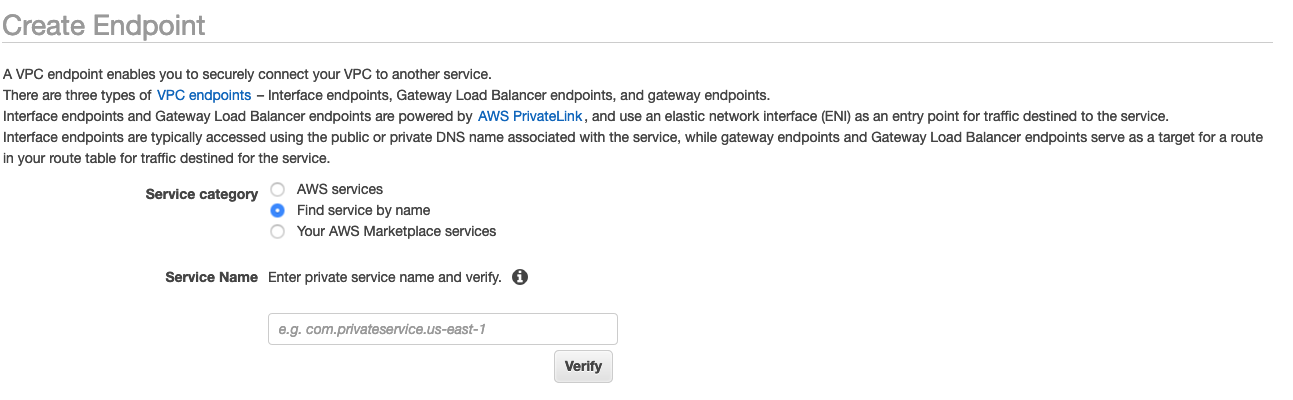
-
No campo Nome do serviço, cole o valor
privatelink-vpce-idque você recuperou na etapa anterior e escolha Verificar.Se a conexão for bem-sucedida, um alerta verde dizendo Nome do serviço encontrado aparecerá na tela e as opções de VPC e Sub-rede se expandirão automaticamente, conforme mostrado na captura de tela a seguir. Dependendo da região de destino, a tela resultante pode mostrar o nome de outra região AWS .
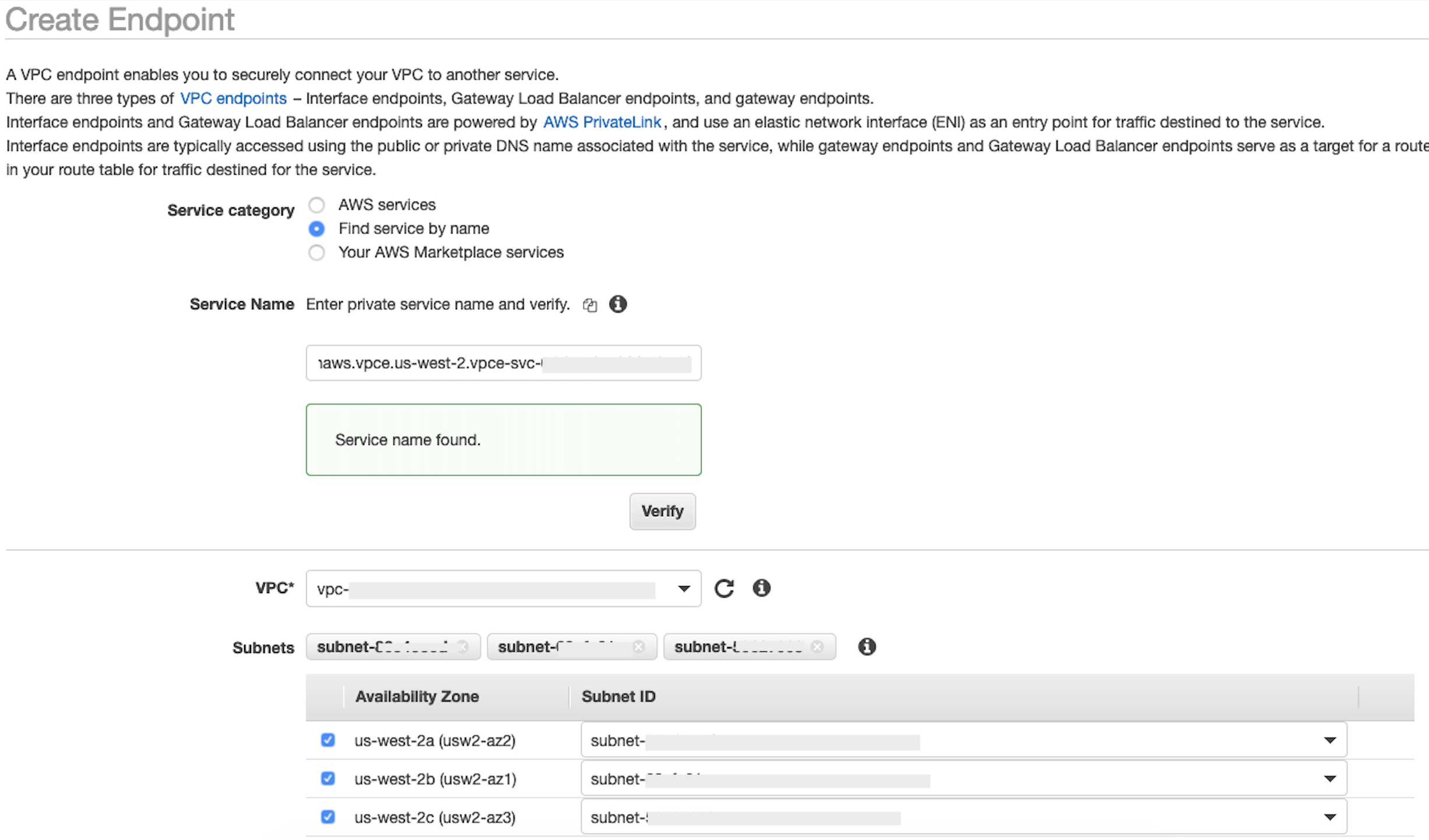
-
Selecione a mesma ID da VPC que você enviou para o Snowflake na lista suspensa da VPC.
-
Se você ainda não criou uma sub-rede, execute o seguinte conjunto de instruções sobre como criar uma sub-rede:
-
Selecione Sub-redes na lista suspensa da VPC. Em seguida, selecione Criar sub-rede e siga as instruções para criar um subconjunto na sua VPC. Certifique-se de selecionar a VPC ID que você enviou ao Snowflake.
-
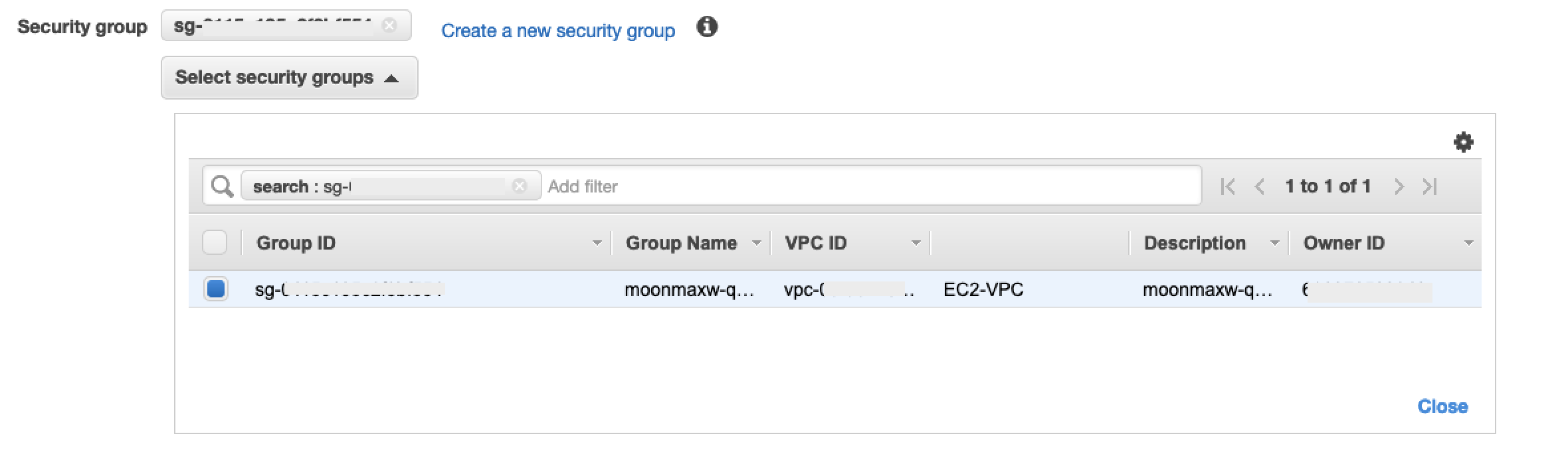
Em Configuração do grupo de segurança, selecione Criar novo grupo de segurança para abrir a tela padrão do grupo de segurança em uma nova guia. Nessa nova guia, selecione Criar grupo de segurança.
-
Forneça um nome para o novo grupo de segurança (como por exemplo,
datawrangler-doc-snowflake-privatelink-connection) e uma descrição. Certifique-se de selecionar a VPC ID que você usou nas etapas anteriores. -
Adicione duas regras para permitir o tráfego de dentro da sua VPC para esse endpoint da VPC.
Navegue até sua VPC VPCs em Seu em uma guia separada e recupere seu bloco CIDR para sua VPC. Depois, escolha Adicionar regras na seção Regras de entrda. Selecione
HTTPSo tipo, deixe a Fonte como Personalizada no formulário e cole o valor recuperado dadescribe-vpcschamada anterior (como10.0.0.0/16). -
Escolha Criar grupo de segurança. Recupere a ID do Grupo de Segurança do grupo de segurança recém-criado (como
sg-xxxxxxxxxxxxxxxxx). -
Na tela de configuração do endpoint da VPC, remova o grupo de segurança padrão. Cole o ID do grupo de segurança no campo de pesquisa e marque a caixa de seleção.
-
Selecione Criar endpoint.
-
Se a criação do endpoint for bem-sucedida, você verá uma página com um link para a configuração do seu endpoint da VPC, especificado pelo ID da VPC. Selecione o link para ver a configuração completa.
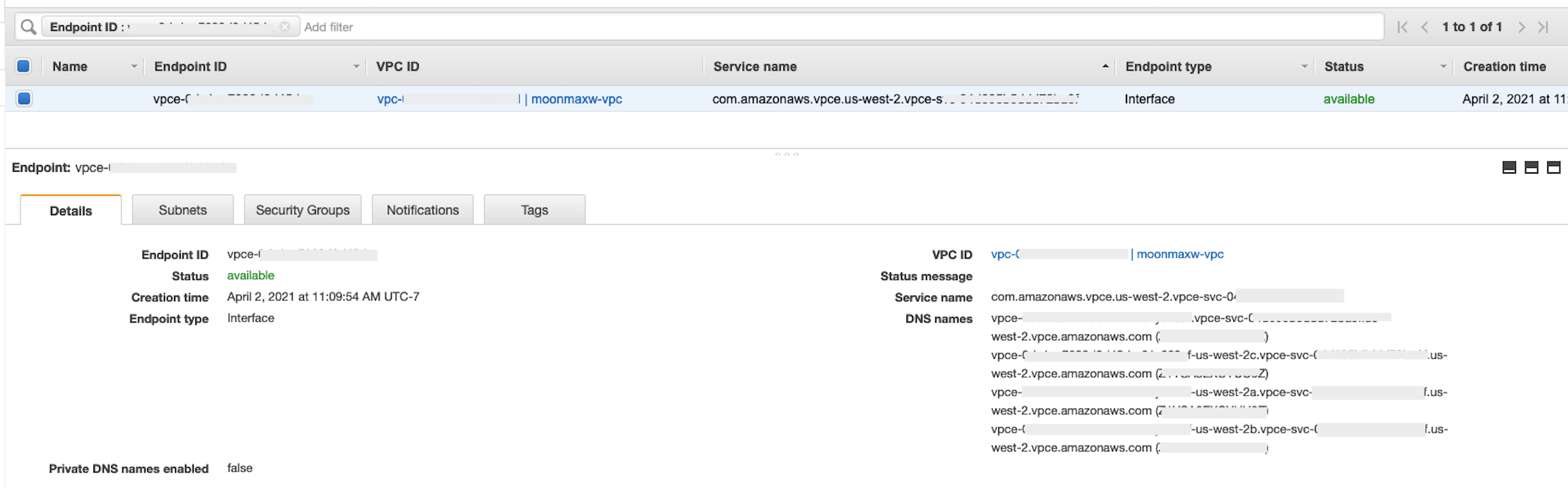
Recupere o registro mais alto na lista de nomes DNS. Isso pode ser diferenciado de outros nomes de DNS porque inclui apenas o nome da região (como
us-west-2) e nenhuma notação de letra da zona de disponibilidade (comous-west-2a). Armazene essas informações para uso posterior.
Configure o DNS para endpoints do Snowflake em sua VPC
Esta seção explica como configurar o DNS para os endpoints do Snowflake em sua VPC. Isso permite que sua VPC resolva solicitações para o endpoint do AWS PrivateLink Snowflake.
-
Navegue até o menu Route 53
em seu AWS console. -
Selecione a opção Zonas hospedadas (se necessário, expanda o menu à esquerda para encontrar essa opção).
-
Escolha Criar zona hospedada.
-
No campo Nome do domínio, faça referência ao valor armazenado
privatelink-account-urlnas etapas anteriores. Nesse campo, o ID da sua conta do Snowflake é removido do nome DNS e usa somente o valor que começa com o identificador da região. Um conjunto de registros de recursos também é criado posteriormente para o subdomínio, comoregion.privatelink.snowflakecomputing.com. -
Selecione o botão de rádio para Zona Hospedada Privada na seção Tipo. Seu código de região pode não ser
us-west-2. Faça referência ao nome DNS devolvido a você pelo Snowflake.
-
Na seção VPCs Para associar à zona hospedada, selecione a região na qual sua VPC está localizada e o ID da VPC usado nas etapas anteriores.
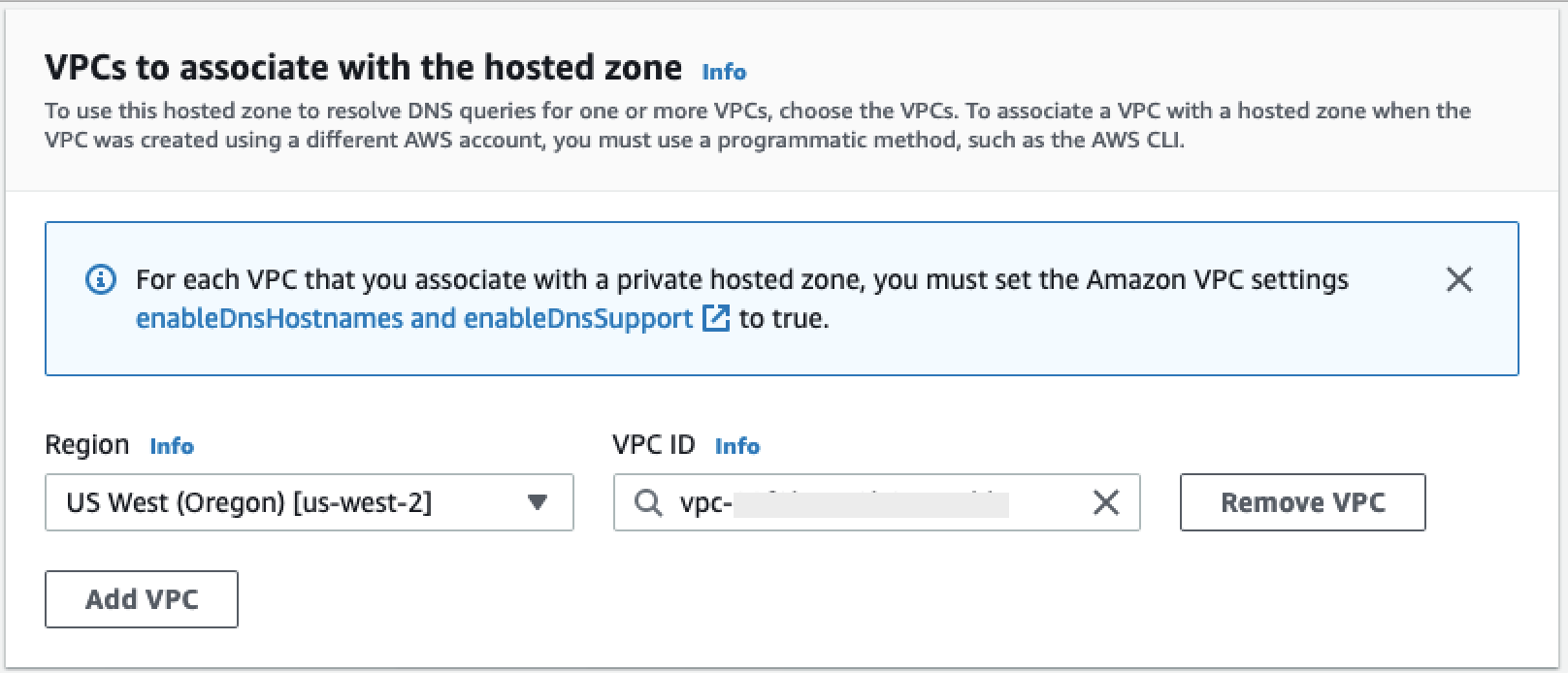
-
Escolha Criar zona hospedada.
-
-
Em seguida, crie dois registros, um para
privatelink-account-urle outro paraprivatelink_ocsp-url.-
No menu Zona hospedada, escolha Criar conjunto de registros.
-
Em Nome do registro, insira somente o ID da sua conta Snowflake (os primeiros 8 caracteres)
privatelink-account-url. -
Em Tipo de registro, selecione CNAME.
-
Em Valor, insira o nome DNS do endpoint da VPC regional que você recuperou na última etapa da seção Configurar a integração AWS PrivateLink com o Snowflake.
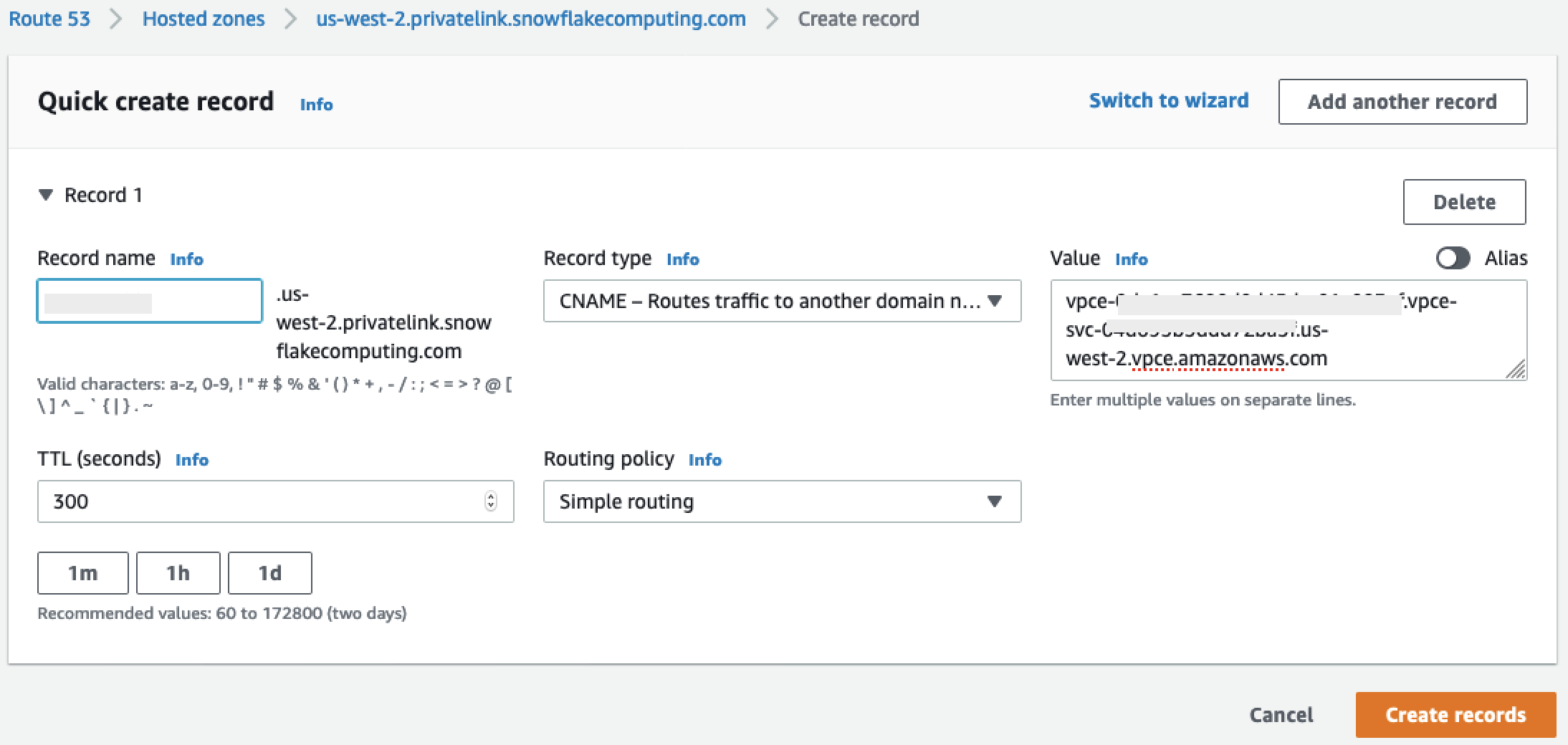
-
Escolha Criar registros.
-
Repita as etapas anteriores para o registro OCSP como anotamos
privatelink-ocsp-url, começando comocspo ID do Snowflake de 8 caracteres para o nome do registro (como)ocsp.xxxxxxxx.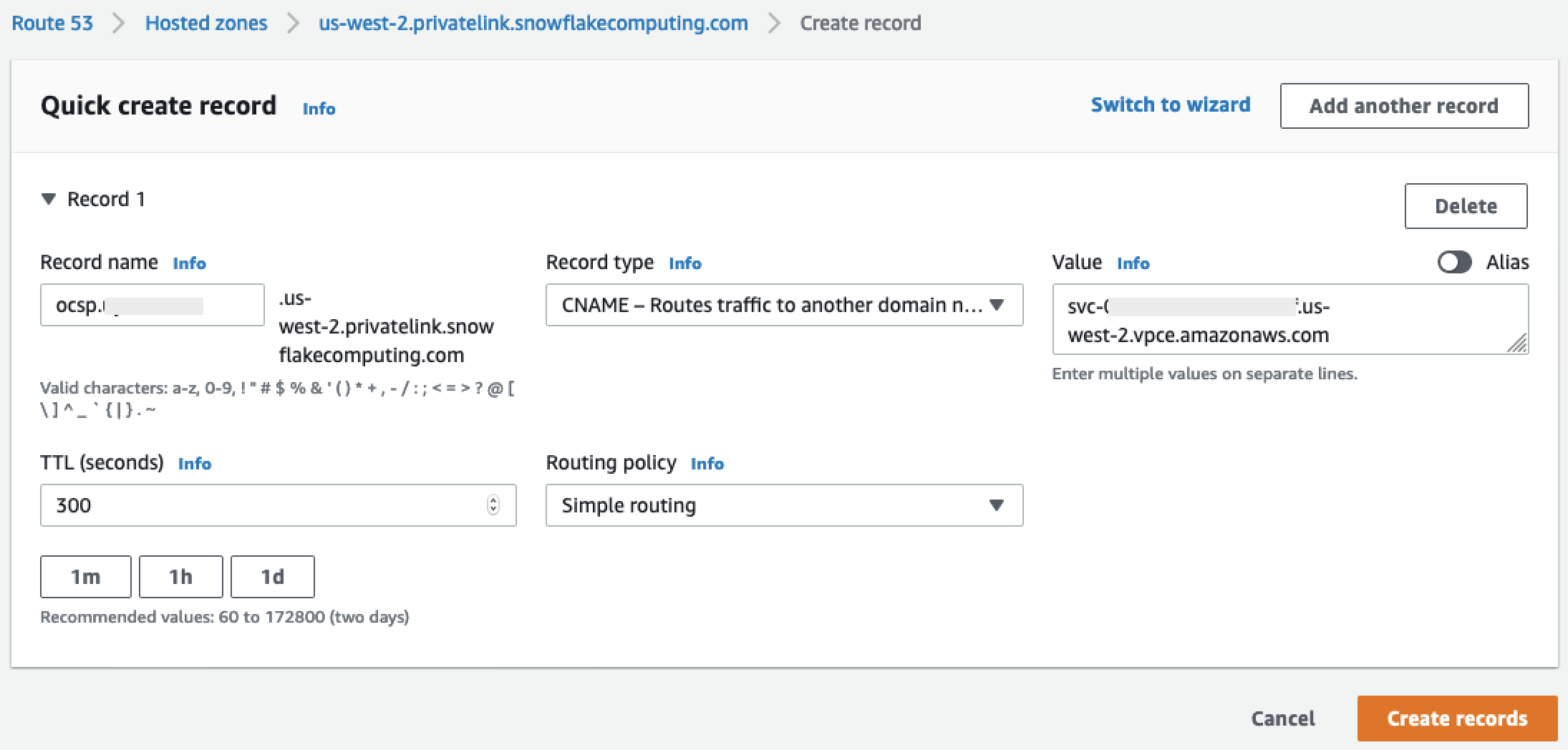
-
-
Configurar o endpoint de entrada do Route 53 Resolver para sua VPC
Esta seção explica como configurar os endpoints dos pontos de entrada dos resolvedores do Route 53 para sua VPC.
-
Navegue até o menu Route 53
em seu AWS console. -
No painel esquerdo da seção Segurança, selecione a opção Grupos de segurança.
-
-
Escolha Criar grupo de segurança.
-
Forneça um nome para o seu grupo de segurança (como por exemplo,
datawranger-doc-route53-resolver-sg) e uma descrição. -
Selecione o ID da VPC usado nas etapas anteriores.
-
Crie regras que permitam o DNS sobre UDP e TCP de dentro do bloco CIDR da VPC.

-
Escolha Criar grupo de segurança. Observe o ID do grupo de segurança porque adiciona uma regra para permitir o tráfego para o grupo de segurança do endpoint da VPC.
-
-
Navegue até o menu Route 53
em seu AWS console. -
Na seção Resolver, selecione a opção Endpoint de entrada.
-
-
Escolha Criar endpoint de entrada.
-
Forneça um nome do endpoint.
-
Na lista suspensa VPC na região, selecione a ID da VPC que você usou em todas as etapas anteriores.
-
Na lista suspensa Grupo de segurança para este endpoint, selecione o ID do grupo de segurança na Etapa 2 desta seção.
-
Na seção Endereço IP, selecione uma zona de disponibilidade, selecione uma sub-rede e deixe o seletor de rádio para Usar um endereço IP selecionado automaticamente para cada endereço IP.
-
Selecione Enviar.
-
-
Selecione o endpoint de entrada após sua criação.
-
Depois que o endpoint de entrada for criado, anote os dois endereços IP dos resolvedores.

SageMaker Endpoints de VPC com IA
Esta seção explica como criar VPC endpoints para o seguinte: Amazon SageMaker Studio Classic, SageMaker Notebooks, a SageMaker API, SageMaker Runtime Runtime e Amazon SageMaker Feature Store Runtime.
Crie um grupo de segurança que seja aplicado a todos os endpoints.
-
Navegue até o EC2 menu
no AWS console. -
Na seção Rede e Segurança, selecione a opção Grupos de segurança.
-
Escolha Criar grupo de segurança.
-
Forneça um nome e descrição do grupo de segurança (como por exemplo,
datawrangler-doc-sagemaker-vpce-sg). Uma regra é adicionada posteriormente para permitir o tráfego via HTTPS da SageMaker IA para esse grupo.
Como criar os endpoints
-
Navegue até o menu VPC
no AWS console. -
Selecione a opção Endpoints.
-
Escolha Criar endpoint.
-
Pesquise o serviço inserindo seu nome no campo Pesquisar.
-
Na lista suspensa VPC, selecione a VPC na qual sua conexão com o Snowflake existe. AWS PrivateLink
-
Na seção Sub-redes, selecione as sub-redes que têm acesso à conexão do Snowflake. PrivateLink
-
Deixe a caixa de seleção Habilitar nome DNS marcada.
-
Na seção Grupos de segurança, selecione o grupo de segurança que você criou na seção anterior.
-
Escolha Criar endpoint.
Configurar o Studio Classic e o Data Wrangler
Esta seção explica como configurar o Studio Classic e o Data Wrangler.
-
Configure o grupo de segurança.
-
Navegue até o EC2 menu da Amazon no AWS console.
-
Selecione a opção Grupos de segurança na seção Rede e segurança.
-
Escolha Criar grupo de segurança.
-
Forneça um nome e descrição do seu grupo de segurança (como por exemplo,
datawrangler-doc-sagemaker-studio). -
Crie as seguintes regras de entrada:
-
A conexão HTTPS com o grupo de segurança que você provisionou para a PrivateLink conexão do Snowflake que você criou na etapa Configurar a integração do Snowflake. PrivateLink
-
A conexão HTTP com o grupo de segurança que você provisionou para a PrivateLink conexão do Snowflake que você criou na etapa Configurar a integração do Snowflake. PrivateLink
-
O grupo de segurança UDP e TCP para DNS (porta 53) para o Route 53 Resolver Inbound Endpoint que você cria na etapa 2 de Configurar o Route 53 Resolver Inbound Endpoint para sua VPC.
-
-
Escolha o botão Criar grupo de segurança no canto inferior direito.
-
-
Configure o Studio Classic.
-
Navegue até o menu SageMaker AI no AWS console.
-
No console esquerdo, selecione a opção SageMaker AI Studio Classic.
-
Se você não tiver nenhum domínio configurado, o menu Conceitos básicos estará presente.
-
Selecione a opção Configuração padrão no menu Conceitos básicos.
-
No Método de autenticação, escolha AWS Identity and Access Management (IAM).
-
No menu Permissões, você pode criar uma nova função ou usar uma função preexistente, dependendo do seu caso de uso.
-
Se você escolher Criar um novo perfil, você terá a opção de fornecer um nome de bucket do S3 e uma política será gerada para você.
-
Se você já tiver um papel criado com permissões para os buckets do S3 aos quais você precisa de acesso, selecione o papel na lista suspensa. Esse cargo deve ter a política
AmazonSageMakerFullAccessassociada a ele.
-
-
Selecione a lista suspensa Rede e Armazenamento para configurar a VPC, a segurança e as sub-redes que a AI usa. SageMaker
-
Em VPC, selecione a VPC na qual sua conexão com o Snowflake existe. PrivateLink
-
Em Sub-rede (s), selecione as sub-redes que têm acesso à conexão do Snowflake. PrivateLink
-
Em Acesso à rede para o Studio Classic, selecione Somente VPC.
-
Em Grupo(s) de segurança, selecione o grupo de segurança que você criou na etapa 1.
-
-
Selecione Enviar.
-
-
Edite o grupo de segurança de SageMaker IA.
-
Crie as seguintes regras de entrada:
-
Porta 2049 para os grupos de segurança NFS de entrada e saída criados automaticamente pela SageMaker AI na etapa 2 (os nomes dos grupos de segurança contêm o ID de domínio do Studio Classic).
-
Acesso exclusivo a todas as portas TCP (necessário somente para SageMaker IA para VPC).
-
-
-
Edite os grupos de segurança do endpoint da VPC:
-
Navegue até o EC2 menu da Amazon no AWS console.
-
Localize o grupo de segurança que você criou na etapa anterior.
-
Adicione uma regra de entrada que permita o tráfego HTTPS do grupo de segurança criado na etapa 1.
-
-
Crie um perfil de usuário.
-
No Painel de controle do SageMaker Studio Classic, escolha Adicionar usuário.
-
Forneça um nome de usuário.
-
EmFunção de execução, escolha criar uma nova função ou usar uma função pré-existente.
-
Se você escolher Criar um novo perfil, você terá a opção de fornecer um nome de bucket do Amazon S3 e uma política será gerada para você.
-
Se você já tem uma função criada com permissões para os buckets do Amazon S3 aos quais você precisa de acesso, selecione a função na lista suspensa. Esse cargo deve ter a política
AmazonSageMakerFullAccessassociada a ele.
-
-
Selecione Enviar.
-
-
Crie um fluxo de dados (siga o guia do cientista de dados descrito na seção anterior).
-
Ao adicionar uma conexão com o Snowflake, insira o valor de
privatelink-account-name(na etapa Configurar PrivateLink integração com o Snowflake) no campo Nome da conta do Snowflake (alfanumérico), em vez do nome simples da conta do Snowflake. Todo o resto permanece inalterado.
-
Fornecer informações ao cientista de dados
Forneça ao cientista de dados as informações de que ele precisa para acessar o Snowflake a partir do Amazon SageMaker AI Data Wrangler.
Importante
Seus usuários precisam executar o Amazon SageMaker Studio Classic versão 1.3.0 ou posterior. Para obter informações sobre como verificar a versão do Studio Classic e atualizá-la, consulte Prepare dados de ML com o Amazon SageMaker Data Wrangler.
-
Para permitir que seu cientista de dados acesse o Snowflake a partir do SageMaker Data Wrangler, forneça a ele uma das seguintes opções:
-
Para Autenticação básica, é necessário um nome de conta Snowflake, um nome de usuário e uma senha.
-
Para OAuth, um nome de usuário e senha no provedor de identidade.
-
Para ARN, trata-se do Nome do Recurso da Amazon (ARN) do segredo no Secrets Manager.
-
Um segredo criado com o Secrets Manager AWS e o ARN do segredo. Use o procedimento abaixo para criar o segredo (secret) para o Snowflake, caso opte por esta opção.
Importante
Se seus cientistas de dados usarem a opção Snowflake Credentials (nome de usuário e senha) para se conectar ao Snowflake, você poderá usar o Secrets Manager para armazenar as credenciais em segredo. O Secrets Manager alterna os segredos como parte de um plano de segurança de práticas recomendadas. O segredo criado no Secrets Manager só é acessível com a função do Studio Classic configurada quando você definiu um perfil de usuário do Studio Classic. Isso exige que você adicione a permissão,
secretsmanager:PutResourcePolicy, à política anexada à sua função no Studio Classic.É altamente recomendável que você delimite a política de função para usar funções diferentes para diferentes grupos de usuários do Studio Classic. Você pode adicionar permissões adicionais baseadas em recursos para os segredos do Secrets Manager. Consulte Gerenciar política do segredo para ver as chaves de condição que você pode usar.
Para obter informações sobre como criar um segredo, consulte Criar um segredo. Você é cobrado pelos segredos que você cria.
-
-
(Opcional) Forneça ao cientista de dados o nome da integração de armazenamento que você criou usando o seguinte procedimento: Criar uma integração de armazenamento em nuvem no Snowflake
. Esse é o nome da nova integração e é chamado integration_nameno comando SQL doCREATE INTEGRATIONque você executou, que é mostrado no seguinte trecho:CREATE STORAGE INTEGRATION integration_name TYPE = EXTERNAL_STAGE STORAGE_PROVIDER = S3 ENABLED = TRUE STORAGE_AWS_ROLE_ARN = 'iam_role' [ STORAGE_AWS_OBJECT_ACL = 'bucket-owner-full-control' ] STORAGE_ALLOWED_LOCATIONS = ('s3://bucket/path/', 's3://bucket/path/') [ STORAGE_BLOCKED_LOCATIONS = ('s3://bucket/path/', 's3://bucket/path/') ]
Guia do cientista de dados
Utilize o seguinte para conectar ao Snowflake e acessar seus dados no Data Wrangler:
Importante
Seu administrador precisa usar as informações nas seções anteriores para configurar o Snowflake. Se você estiver enfrentando problemas, entre em contato com eles para obter ajuda na solução de problemas.
Você pode se conectar ao Snowflake de uma das seguintes maneiras:
-
Especificar suas credenciais do Snowflake (nome da conta, nome de usuário e senha) no Data Wrangler.
-
Fornecer um nome do recurso da Amazon (ARN) de um segredo que contém as credenciais.
-
Usando um padrão aberto para o provedor de delegação de acesso (OAuth) que se conecta ao Snowflake. Seu administrador pode lhe dar acesso a um dos seguintes OAuth provedores:
Converse com seu administrador sobre o método que você precisa usar para se conectar ao Snowflake.
As seguintes seções contêm informações sobre como você pode se conectar ao Snowflake usando os métodos mencionados anteriormente:
Você pode iniciar o processo de importação dos seus dados do Snowflake depois de ter se conectado a ele.
Dentro do Data Wrangler, você pode visualizar seus data warehouses, bancos de dados e esquemas, juntamente com o ícone de olho com o qual você pode visualizar a tabela. Depois de selecionar o ícone Visualizar tabela, a visualização do esquema dessa tabela é gerada. Você deve selecionar um depósito antes de poder visualizar uma tabela.
Importante
Se você estiver importando um conjunto de dados com colunas do tipo TIMESTAMP_TZ ou TIMESTAMP_LTZ, adicione ::string aos nomes das colunas da sua consulta. Para obter mais informações, consulte Como descarregar dados TIMESTAMP_TZ e TIMESTAMP_LTZ em um arquivo Parquet
Após selecionar um data warehouse, banco de dados e esquema, agora você pode escrever consultas e executá-las. A saída da sua consulta é exibida em Resultados da consulta.
Depois de definir a saída da sua consulta, você poderá importar a saída da sua consulta para um fluxo do Data Wrangler para realizar transformações de dados.
Depois de importar seus dados, navegue até o fluxo do Data Wrangler e comece a adicionar transformações a ele. Para ver uma lista das transformações disponíveis, consulte Transformar dados.
Importar dados de plataformas de software como serviço (SaaS)
Você pode usar o Data Wrangler para importar dados de mais de quarenta plataformas de software como serviço (SaaS). Para importar seus dados da sua plataforma SaaS, você ou seu administrador devem usar AppFlow a Amazon para transferir os dados da plataforma para o Amazon S3 ou o Amazon Redshift. Para obter mais informações sobre a Amazon AppFlow, consulte O que é a Amazon AppFlow? Se você não precisar usar o Amazon Redshift, recomendamos transferir os dados para o Amazon S3 para simplificar o processo.
O Data Wrangler é compatível com a transferência de dados das seguintes plataformas SaaS:
A lista anterior tem links para mais informações sobre como configurar sua fonte de dados. Você ou seu administrador podem consultar os links anteriores depois de terem lido as informações a seguir.
Ao navegar até a guia Importar do seu fluxo do Data Wrangler, você vê as fontes de dados nas seguintes seções:
-
Disponível
-
Configure as fontes de dados
Você pode se conectar às fontes de dados em Disponível sem precisar de configuração adicional. Você pode escolher a fonte de dados e importar seus dados.
As fontes de dados, em Configurar fontes de dados, exigem que você ou seu administrador usem AppFlow a Amazon para transferir os dados da plataforma SaaS para o Amazon S3 ou o Amazon Redshift. Para obter informações sobre como realizar uma transferência, consulte Usando AppFlow a Amazon para transferir seus dados.
Depois de realizar a transferência de dados, a plataforma SaaS aparece como uma fonte de dados em Disponível. Você pode escolhê-lo e importar os dados que você transferiu para o Data Wrangler. Os dados que você transferiu aparecem como tabelas que você pode consultar.
Usando AppFlow a Amazon para transferir seus dados
AppFlow A Amazon é uma plataforma que você pode usar para transferir dados da sua plataforma SaaS para o Amazon S3 ou o Amazon Redshift sem precisar escrever nenhum código. Para realizar uma transferência de dados, você usa o AWS Management Console.
Importante
Você deve se certificar de que configurou as permissões para realizar uma transferência de dados. Para obter mais informações, consulte AppFlow Permissões da Amazon.
Depois de adicionar as permissões, você pode transferir os dados. Na Amazon AppFlow, você cria um fluxo para transferir os dados. Um fluxo é uma série de configurações. Você pode usá-lo para especificar se está executando a transferência de dados em um cronograma ou se está particionando os dados em arquivos separados. Após ter configurado o fluxo, você o executa para transferir os dados.
Para obter informações sobre a criação de um fluxo, consulte Criação de fluxos na Amazon AppFlow. Para obter informações sobre como executar um fluxo, consulte Ativar um AppFlow fluxo da Amazon.
Depois que os dados forem transferidos, use o seguinte procedimento para acessar os dados no Data Wrangler:
Importante
Antes de tentar acessar seus dados, certifique-se de que seu perfil do IAM tenha a seguinte política:
Por padrão, o perfil do IAM que você usa para acessar o Data Wrangler é o SageMakerExecutionRole. Para obter mais informações sobre a adição de políticas, consulte Adicionar permissões de identidades do IAM (console).
Para estabelecer conexão com uma fonte de dados, siga os seguintes passos:
-
Faça login no Amazon SageMaker AI Console
. -
Escolha Studio.
-
Escolha Iniciar aplicação.
-
Na lista suspensa, selecione Studio.
-
Escolha o ícone Início.
-
Escolha Dados.
-
Escolha Data Wrangler.
-
Escolha Importar dados.
-
Em Disponível, escolha a fonte de dados.
-
Para o campo Nome, especifique o nome da conexão.
-
(Opcional) Escolha Configuração avançada.
-
Escolha um Grupo de trabalho.
-
Se seu grupo de trabalho não impôs o local de saída do Amazon S3 ou se você não usa um grupo de trabalho, especifique um valor para a localização dos resultados da consulta no Amazon S3.
-
(Opcional) Em Período de retenção de dados, marque a caixa de seleção para definir um período de retenção de dados e especificar o número de dias para armazenar os dados antes de serem excluídos.
-
(Opcional) Por padrão, o Data Wrangler salva a conexão. Você pode optar por desmarcar a caixa de seleção e não salvar a conexão.
-
-
Selecione Conectar.
-
Especifique uma consulta.
nota
Para ajudá-lo a especificar uma consulta, você pode escolher uma tabela no painel de navegação esquerdo. O Data Wrangler mostra o nome da tabela e uma visualização prévia da tabela. Clique no ícone ao lado do nome da tabela para copiá-lo. Você pode usar o nome da tabela na consulta.
-
Escolha Executar.
-
Escolha Importar consulta.
-
Em nome do conjunto de dados, especifique o nome do conjunto de dados.
-
Escolha Adicionar.
Ao navegar até a tela Importar dados, você pode ver a conexão que você criou. Você pode usar a conexão para importar mais dados.
Armazenamento de dados importados
Importante
É altamente recomendável que você siga as melhores práticas para proteger seu bucket do Amazon S3 seguindo as melhores práticas de segurança.
Quando você consulta dados do Amazon Athena ou do Amazon Redshift, o conjunto de dados consultado é automaticamente armazenado no Amazon S3. Os dados são armazenados no bucket padrão do SageMaker AI S3 para a AWS região na qual você está usando o Studio Classic.
Os buckets do S3 padrão têm a seguinte convenção de nomenclatura: sagemaker-. Por exemplo, se o número da sua conta for 111122223333 e você estiver usando o Studio Classic em region-account
numberus-east-1, seus conjuntos de dados importados serão armazenados em 111122223333 sagemaker-us-east-1-.
Os fluxos do Data Wrangler dependem desta localização de conjunto de dados no Amazon S3, portanto, você não deve modificar este conjunto de dados no Amazon S3 enquanto estiver usando um fluxo dependente. Se você modificar esta localização no S3 e desejar continuar usando seu fluxo de dados, será necessário remover todos os objetos em trained_parameters no seu arquivo .flow. Para fazer isso, baixe o arquivo .flow do Studio Classic e, para cada instância do trained_parameters, exclua todas as entradas. Quando terminar, o trained_parameters deve ser um objeto JSON vazio:
"trained_parameters": {}
Quando você exporta e utiliza seu fluxo de dados para processar seus dados, o arquivo .flow que você exporta faz referência a este conjunto de dados no Amazon S3. Consulte as seguintes seções para saber mais:
Armazenamento de importação do Amazon Redshift
O Data Wrangler armazena os conjuntos de dados resultantes da sua consulta em um arquivo Parquet em seu bucket AI S3 padrão SageMaker .
Esse arquivo é armazenado sob o seguinte prefixo (diretório): redshift/ uuid /data/, onde uuid é um identificador exclusivo criado para cada consulta.
Por exemplo, se seu bucket padrão forsagemaker-us-east-1-111122223333, um único conjunto de dados consultado no Amazon Redshift está localizado em s3://-1-111122223333/redshift/ /data/. sagemaker-us-east uuid
Importar e armazenar do Amazon Athena
Quando você consulta um banco de dados do Athena e importa um conjunto de dados, o Data Wrangler armazena o conjunto de dados, bem como um subconjunto desse conjunto de dados, ou arquivos de pré-visualização, no Amazon S3.
O conjunto de dados que você importa ao selecionar Importar conjunto de dados é armazenado no formato Parquet no Amazon S3.
Os arquivos de visualização são gravados no formato CSV quando você seleciona Executar na tela de importação do Athena e contêm até 100 linhas do conjunto de dados consultado.
O conjunto de dados que você consulta está localizado sob o prefixo (diretório): athena/ uuid /data/, onde uuid está um identificador exclusivo criado para cada consulta.
Por exemplo, se seu bucket padrão forsagemaker-us-east-1-111122223333, um único conjunto de dados consultado do Athena está localizado em /athena/ /data/. s3://sagemaker-us-east-1-111122223333 uuid example_dataset.parquet
O subconjunto do conjunto de dados armazenado para visualizar dataframes no Data Wrangler é armazenado sob o prefixo: athena/.
