As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Prepare dados de ML com o Amazon SageMaker Data Wrangler
Importante
O Amazon SageMaker Data Wrangler foi integrado ao Amazon SageMaker Canvas. Na nova experiência do Data Wrangler no SageMaker Canvas, você pode usar uma interface de linguagem natural para explorar e transformar seus dados, além da interface visual. Para obter mais informações sobre o Data Wrangler no SageMaker Canvas, consulte. preparação de dados
O Amazon SageMaker Data Wrangler (Data Wrangler) é um recurso do Amazon SageMaker Studio Classic que fornece uma end-to-end solução para importar, preparar, transformar, caracterizar e analisar dados. Você pode integrar um fluxo de preparação de dados do Data Wrangler aos seus fluxos de trabalho de machine learning (ML) para simplificar e agilizar o pré-processamento de dados e a engenharia de atributos usando pouca ou nenhuma codificação. Você também pode adicionar seus próprios scripts e transformações em Python para personalizar os fluxos de trabalho.
O Data Wrangler fornece as seguintes funcionalidades principais para ajudá-lo a analisar e preparar dados para aplicações de machine learning:
-
Importar — Conecte-se e importe dados do Amazon Simple Storage Service (Amazon S3), Amazon Athena (Athena), Amazon Redshift, Snowflake e Databricks.
-
Fluxo de dados: crie um fluxo de dados para definir uma série de etapas de preparação de dados de ML. Você pode usar um fluxo para combinar conjuntos de dados de diferentes fontes de dados, identificar o número e os tipos de transformações que você deseja aplicar aos conjuntos de dados e definir um fluxo de trabalho de preparação de dados que possa ser integrado a um pipeline de ML.
-
Transforme: limpe e transforme seu conjunto de dados usando transformações padrão, como ferramentas de formatação de dados numéricos, vetoriais e de sequência de caracteres. Destaque seus dados usando transformações como texto, date/time incorporação e codificação categórica.
-
Gere insights de dados: verifique automaticamente a qualidade dos dados e detecte anomalias em seus dados com o Data Wrangler Data Insights e o Quality Report.
-
Analise: analise os atributos do seu conjunto de dados em qualquer ponto do fluxo. O Data Wrangler inclui ferramentas de visualização de dados integradas, como gráficos de dispersão e histogramas, bem como ferramentas de análise de dados, como análise de vazamento de alvos e modelagem rápida para entender a correlação de atributos.
-
Exportar: exporte seu fluxo de trabalho de preparação de dados para um local diferente. Estes são locais de exemplo:
-
Bucket do Amazon Simple Storage Service (Amazon S3)
-
Amazon SageMaker Pipelines — Use Pipelines para automatizar a implantação do modelo. Você pode exportar os dados que você transformou diretamente para os pipelines.
-
Amazon SageMaker Feature Store — Armazene os recursos e seus dados em uma loja centralizada.
-
Script Python: armazene os dados e suas transformações em um script Python para seus fluxos de trabalho personalizados.
-
Para começar a usar o Data Wrangler, consulte Conceitos básicos do Data Wrangler.
Importante
O Data Wrangler não é mais compatível com a versão 1 do Jupyter Lab (). JL1 Para acessar os atributos e atualizações mais recentes, atualize para a versão 3 do Jupyter Lab. Para obter mais informações sobre a atualização, consulte Visualize e atualize a JupyterLab versão de um aplicativo no console.
Importante
As informações e os procedimentos neste guia usam a versão mais recente do Amazon SageMaker Studio Classic. Para obter mais informações sobre como atualizar o Studio Classic para a versão mais recente, consulte Visão geral da interface do usuário do Amazon SageMaker Studio Classic.
Você deve usar a versão 1.3.0 ou posterior do Studio Classic. Use o procedimento a seguir para abrir o Amazon SageMaker Studio Classic e ver qual versão você está executando.
Para abrir o Studio Classic e verificar sua versão, consulte o procedimento a seguir.
-
Use as etapas Pré-requisitos para acessar o Data Wrangler por meio do Amazon SageMaker Studio Classic.
-
Ao lado do usuário que você deseja usar para executar o Studio Classic, selecione Executar aplicação.
-
Escolha Studio.
-
Assim que o Studio Classic for carregado, selecione Arquivo e, em seguida, Novo e, depois, Terminal.
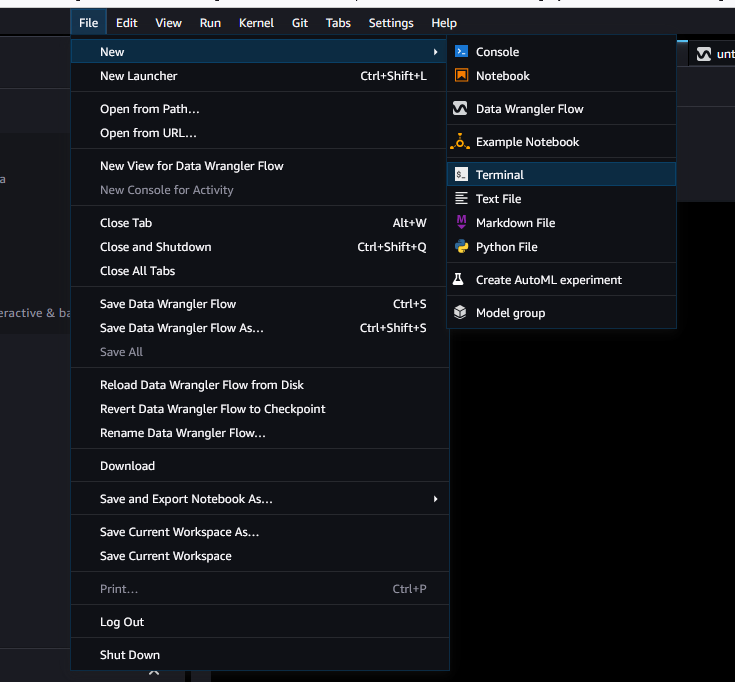
-
Após a inicialização do Studio Classic, selecione Arquivo, depois Novo e, em seguida, Terminal.
-
Digite
cat /opt/conda/share/jupyter/lab/staging/yarn.lock | grep -A 1 "@amzn/sagemaker-ui-data-prep-plugin@"para registrar a versão da sua instância do Studio Classic. Você deve ter a versão 1.3.0 do Studio Classic para usar o Snowflake.
Você pode atualizar o Amazon SageMaker Studio Classic de dentro do AWS Management Console. Para obter mais informações sobre como atualizar o Studio Classic, consulte Visão geral da interface do usuário do Amazon SageMaker Studio Classic.
