Personal Data OU – PD Application account
Survey
We would love to hear from you. Please provide feedback on the AWS PRA by taking a short survey
The Personal Data (PD) Application account is where your organization hosts services that collect and process personal data. Specifically, you might store what you define as personal data in this account. The AWS PRA demonstrates a number of example privacy configurations through a multi-tier serverless web architecture. When it comes to operating workloads across an AWS landing zone, privacy configurations should not be considered one-size-fits-all solutions. For example, your goal might be to understand the underlying concepts, how they can enhance privacy, and how your organization can apply solutions to your particular use cases and architectures.
For AWS accounts in your organization that collect, store, or process personal data, you can use AWS Organizations and AWS Control Tower to deploy foundational and repeatable guardrails. Establishing a dedicated organizational unit (OU) for these accounts is critical. For example, you might want to apply data residency guardrails to only a subset of accounts where data residency is a core design consideration. For many organizations, these are the accounts that store and process personal data.
Your organization might consider supporting a dedicated Data account, which is where you store the authoritative source of your personal datasets. An authoritative data source is a location where you store the primary version of data, which might be considered the most reliable and accurate version of the data. For example, you might copy the data from the authoritative data source to other locations, such as Amazon Simple Storage Service (Amazon S3) buckets in the PD Application account that are used to store training data, a subset of customer data, and redacted data. By taking this multi-account approach to separate complete and definitive personal datasets in the Data account from the downstream consumer workloads in the PD Application account, you can reduce the scope of impact in the event of unauthorized access to your accounts.
The following diagram illustrates the AWS security and privacy services that are configured in the PD Application and Data accounts.
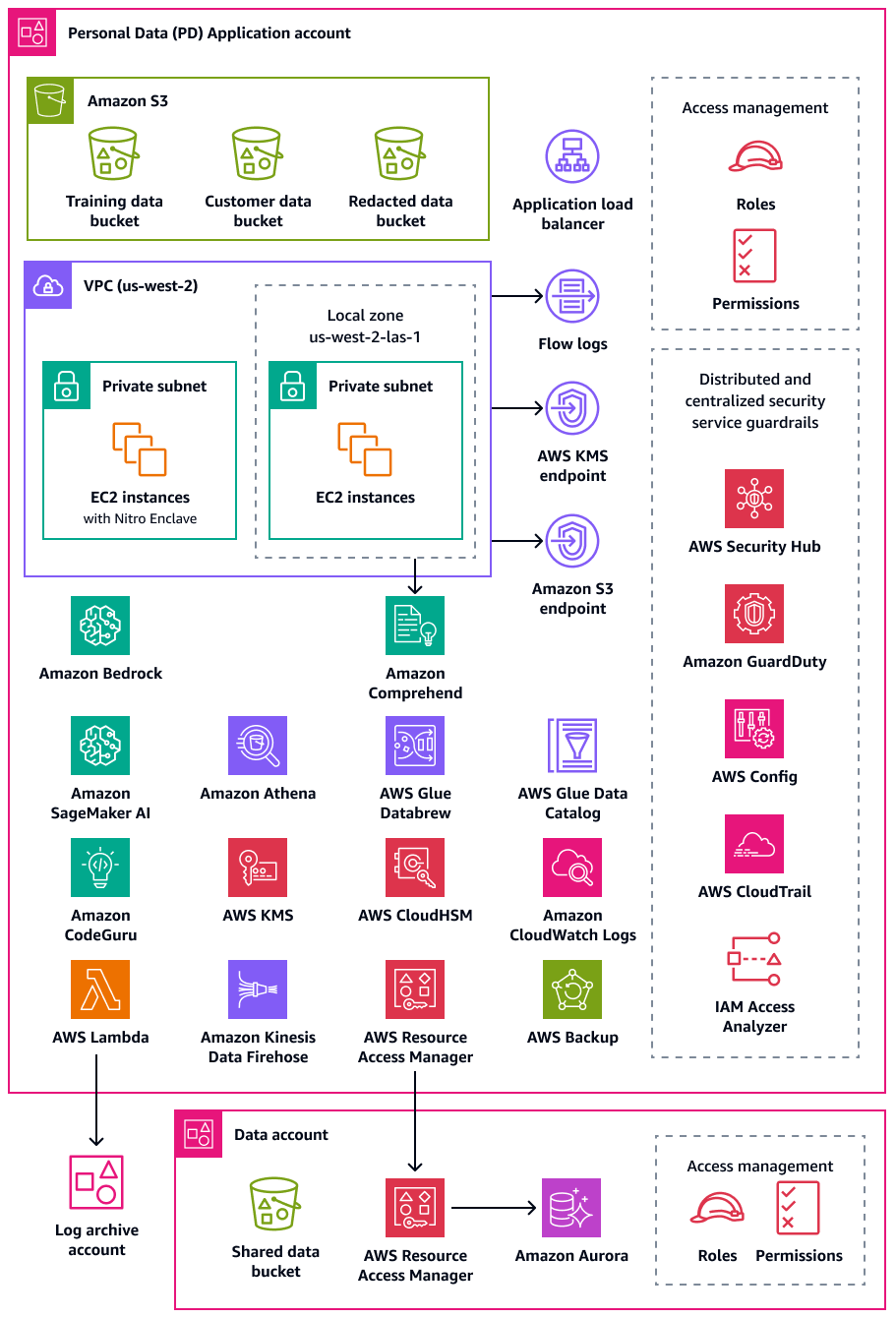
This section provides more detailed information about the following AWS services that are used in these accounts:
Amazon Athena
You can consider data query limitation controls to meet your privacy goals. Amazon Athena is an interactive query service that helps you analyze data directly in Amazon S3 by using standard SQL. You don't have to load the data into Athena; it works directly with the data stored in S3 buckets.
A common use case for Athena is providing data analytics teams with tailored and
sanitized datasets. If the datasets contain personal data, you can sanitize the
dataset by masking entire columns of personal data that provide little value to the
data analytics teams. For more information, see Anonymize and manage data in your data lake with Amazon Athena and AWS Lake Formation
If your data transformation approach requires additional flexibility outside of
the supported
functions in Athena, you can define custom functions, called user-defined
functions (UDF). You can invoke UDFs in a SQL query submitted to Athena,
and they run on AWS Lambda. You can use UDFs in SELECT and FILTER
SQL queries, and you can invoke multiple UDFs in the same query. For
privacy, you can create UDFs that perform specific types of data masking, such as
showing only the last four characters of every value in a column.
Amazon Bedrock
Amazon Bedrock is a fully managed service that provides access to foundation models from leading AI companies like AI21 Labs, Anthropic, Meta, Mistral AI, and Amazon. It helps organizations to build and scale generative AI applications. No matter what platform is used, when using generative AI, organizations could face privacy risks, including the potential exposure of personal data, unauthorized data access, and other compliance violations.
Amazon Bedrock Guardrails is designed to help mitigate these risks by enforcing security and compliance best practices across your generative AI workloads in Amazon Bedrock. The deployment and use of AI resources might not always align with an organization's privacy and compliance requirements. Organizations can struggle with maintaining data privacy when using generative AI models because these models can potentially memorize or reproduce sensitive information. Amazon Bedrock Guardrails helps protect privacy by evaluating user inputs and model responses. Overall, if the input data contains personal data, there can be a risk of this information being exposed in the model's output.
Amazon Bedrock Guardrails provides mechanisms to enforce data protection policies and help
prevent unauthorized data exposure. It offers content-filtering capabilities to detect and block personal data in
inputs, topic
restrictions to help prevent access to inappropriate or risky subject
matter, and word filters
to mask or redact sensitive terms in model prompts and responses. These capabilities
help prevent events that could lead to privacy violations, such as biased responses,
or erosion of customer trust. These features can help you make sure that personal
data is not inadvertently processed or disclosed by your AI models. Amazon Bedrock Guardrails
supports the evaluation of inputs and responses outside of Amazon Bedrock as well. For more
information, see Implement model-independent safety measures with Amazon Bedrock Guardrails
With Amazon Bedrock Guardrails, you can limit the risk of model hallucinations by using
contextual grounding checks, which evaluate factual grounding and the
relevance of responses. An example is deploying a generative AI customer-facing
application that is uses third-party data sources in a Retrieval Augmented Generation
(RAG)
AWS Clean Rooms
As organizations look for ways to collaborate with one another through analysis of intersecting or overlapping sensitive datasets, maintaining the security and privacy of that shared data is a concern. AWS Clean Rooms helps you deploy data clean rooms, which are secure, neutral environments where organizations can analyze combined datasets without sharing the raw data itself. It also can generate unique insights by providing access to other organizations on AWS without moving or copying data out of their own accounts and without revealing the underlying dataset. All data remains in the source location. Built-in analysis rules constrain the output and restrict the SQL queries. All queries are logged, and collaboration members can view how their data is being queried.
You can create an AWS Clean Rooms collaboration and invite other AWS customers to be members of that collaboration. You grant one member the ability to query the member datasets, and you can choose additional members to receive the results of those queries. If more than one member needs to query the datasets, you can create additional collaborations with the same data sources and different member settings. Each member can filter the data that is shared with the collaboration members, and you can use custom analysis rules to set limitations on how the data they provide to the collaboration can be analyzed.
In addition to restricting the data presented to the collaboration and how it can be used by other members, AWS Clean Rooms provides the following capabilities that can help you protect privacy:
-
Differential privacy is a mathematic technique that enhances user privacy through adding a carefully calibrated amount of noise to the data. This helps reduce the risk of individual user reidentification within the dataset without obscuring the values of interest. Using AWS Clean Rooms Differential Privacy doesn't require differential privacy expertise.
-
AWS Clean Rooms ML allows two or more parties to identify similar users in their data without directly sharing the data with each other. This reduces the risk of membership inference attacks, where a member of the collaboration can identify individuals in the other member's dataset. By creating a lookalike model and generating a lookalike segment, AWS Clean Rooms ML helps you compare datasets without exposing the original data. This does not require either member to have ML expertise or perform any work outside of AWS Clean Rooms. You retain full control and ownership of the trained model.
-
Cryptographic Computing for Clean Rooms (C3R) can be used with analysis rules to derive insights from sensitive data. It cryptographically limits what any other party to the collaboration can learn. Using the C3R encryption client, the data is encrypted at the client before being provided to AWS Clean Rooms. Because the data tables are encrypted using a client-side encryption tool before being uploaded to Amazon S3, the data stays encrypted and persists through processing.
In the AWS PRA, we recommend that you create AWS Clean Rooms collaborations in the Data account. You can use them to share encrypted customer data with third parties. Use them only when there is an overlap in the provided datasets. For more information about how to determine overlap, see List analysis rule in the AWS Clean Rooms documentation.
Amazon CloudWatch Logs
Amazon CloudWatch Logs
helps you centralize the logs from all your systems, applications, and
AWS services so you can monitor them and archive them securely. In CloudWatch Logs, you can
use a data protection policy for new or existing log groups to help minimize
the risk of disclosure of personal data. Data protection policies can detect
sensitive data, such as personal data, in your logs. The data protection policy can
mask that data when users access the logs through the AWS Management Console. When users
require direct access to the personal data, according to the overall purpose
specification for your workload, you can assign logs:Unmask permissions
for those users. You can also create an account-wide data protection policy and
apply this policy consistently across all accounts in your organization. This
configures masking by default for all current and future log groups in CloudWatch Logs. We
also recommend that you enable audit reports and send them to another log group, an
Amazon S3 bucket, or Amazon Data Firehose. These reports contain a detailed record of data
protection findings across each log group.
Amazon CodeGuru Reviewer
For both privacy and security, it's vital to many organizations that they support continuous compliance during both deployment and post-deployment phases. The AWS PRA includes proactive controls in deployment pipelines for applications that process personal data. Amazon CodeGuru Reviewer can detect potential defects that might expose personal data in Java, JavaScript, and Python code. It offers suggestions to developers for improving the code. CodeGuru Reviewer can identify defects across a wide range of security, privacy, and general recommended practices. It's designed to work with multiple source providers, including AWS CodeCommit, Bitbucket, GitHub, and Amazon S3. Some of the privacy-related defects that CodeGuru Reviewer can detect include:
-
SQL injection
-
Unsecured cookies
-
Missing authorization
-
Client-side AWS KMS re-encryption
For a complete list of what CodeGuru Reviewer can detect, see the Amazon CodeGuru Detector Library.
Amazon Comprehend
Amazon Comprehend is a natural-language processing (NLP) service that uses machine learning to uncover valuable insights and connections in English text documents. Amazon Comprehend can detect and redact personal data in structured, semi-structured, or unstructured text documents. For more information, see Personally identifiable information (PII) in the Amazon Comprehend documentation.
You can use the AWS SDKs and Amazon Comprehend API to integrate Amazon Comprehend with many applications.
An example is using Amazon Comprehend to detect and redact personal data with Amazon S3 Object
Lambda. Organizations can use S3 Object Lambda to add custom code to Amazon S3 GET
requests to modify and process data as it's returned to an application. S3 Object
Lambda can filter rows, dynamically resize images, redact personal data, and more.
Powered by AWS Lambda functions, the code runs on infrastructure that is fully
managed by AWS, which eliminates the need to create and store derivative copies of
your data or to run proxies. You don't need to change your applications to transform
objects with S3 Object Lambda. You can use the
ComprehendPiiRedactionS3Object Lambda function in AWS Serverless Application Repository to
redact personal data. This function uses Amazon Comprehend to detect personal data entities and
redacts those entities by replacing them with asterisks. For more information, see
Detecting and redacting PII data with S3 Object Lambda and Amazon Comprehend in the
Amazon S3 documentation.
Because Amazon Comprehend has many options for application integration through AWS SDKs, you
can use Amazon Comprehend to identify personal data in many different places where you collect,
store, and process data. You can use Amazon Comprehend ML capabilities to detect and redact
personal data in application logs
-
REPLACE_WITH_PII_ENTITY_TYPEreplaces each PII entity with its types. For example, Jane Doe would be replaced with NAME. -
MASKreplaces the characters in PII entities with a character of your choice (!, #, $, %, &, , or @). For example, Jane Doe could be replaced with **** ***.
Amazon Data Firehose
Amazon Data Firehose can be used to capture, transform, and load streaming data into downstream services, such as Amazon Managed Service for Apache Flink or Amazon S3. Firehose is often used to transport large quantities of streaming data, such as application logs, without having to build processing pipelines from the ground up.
You can use Lambda functions to perform customized or built-in processing before
the data is sent downstream. For privacy, this capability supports data minimization
and cross-border data transfer requirements. For example, you can use Lambda and
Firehose to transform multi-Region log data before it's centralized in the Log Archive
account. For more information, see Biogen: Centralized Logging
Solution for Multi Accounts
Amazon DataZone
As organizations scale their approach to sharing data through AWS services such as AWS Lake Formation, they want to make sure that differential access is controlled by those who are most familiar with the data: the data owners. However, these data owners might be aware of privacy requirements, such as consent or cross-border data transfer considerations. Amazon DataZone helps the data owners and the data governance team share and consume data across an organization according to your data governance policies. In Amazon DataZone, lines of business (LOBs) manage their own data, and a catalog tracks this ownership. Interested parties can find and request access to data as part of their business tasks. As long as it adheres to the policies established by the data publishers, the data owner can grant access to the underlying tables, without an administrator or moving the data.
In a privacy context, Amazon DataZone can be helpful in the following example use cases:
-
A customer-facing application generates usage data that can be shared with a separate marketing LOB. You need to make sure that only data for customers that have opted in to marketing is published to the catalog.
-
European customer data is published but may only be subscribed to by LOBs local to the European Economic Area (EEA). For more information, see Enhance data security with fine-grained access controls in Amazon DataZone
.
In the AWS PRA, you can connect the data in the shared Amazon S3 bucket to Amazon DataZone as a data producer.
AWS Glue
Maintaining datasets that contain personal data is a key component of Privacy by
Design
AWS Glue Data Catalog
AWS Glue Data Catalog helps you establish maintainable datasets. The Data Catalog
contains references to data that is used as sources and targets for extract,
transform, and load (ETL) jobs in AWS Glue. Information in the Data Catalog is stored as
metadata tables, and each table specifies a single data store. You run an AWS Glue
crawler to take inventory of the data in a variety of data store types. You add
built-in and custom classifiers to the crawler, and these
classifiers infer the data format and schema of the personal data. The crawler
then writes the metadata to the Data Catalog. A centralized metadata table can make
it easier to respond to data subject requests (such as right to erasure) because
it adds structure and predictability across disparate sources of personal data
in your AWS environment. For a comprehensive example of how to use Data Catalog to
automatically respond to these requests, see Handling data erasure requests in your data lake with Amazon S3 Find and
Forget
AWS Glue DataBrew
AWS Glue DataBrew helps you clean and normalize data, and it can perform transformations on the data, such as removing or masking personally identifiable information and encrypting sensitive data fields in data pipelines. You can also visually map the lineage of your data to understand the various data sources and transformation steps that the data has been through. This feature becomes increasingly important as your organization works to better understand and track personal data provenance. DataBrew helps you mask personal data during data preparation. You can detect personal data as part of a data profiling job and gather statistics, such as the number of columns that might contain personal data and potential categories. You can then use built-in reversible or irreversible data transformation techniques, including substitution, hashing, encryption, and decryption, all without writing any code. You can then use the cleaned and masked datasets downstream for analytics, reporting, and machine learning tasks. Some of the data masking techniques available in DataBrew include:
-
Hashing – Apply hash functions to the column values.
-
Substitution – Replace personal data with other, authentic-looking values.
-
Nulling out or deletion – Replace a particular field with a null value, or delete the column.
-
Masking out – Use character scrambling, or mask certain portions in the columns.
The following are the available encryption techniques:
-
Deterministic encryption – Apply deterministic encryption algorithms to the column values. Deterministic encryption always produces the same ciphertext for a value.
-
Probabilistic encryption – Apply probabilistic encryption algorithms to the column values. Probabilistic encryption produces different ciphertext each time that it's applied.
For a complete list of provided personal data transformation recipes in DataBrew, see Personally identifiable information (PII) recipe steps.
AWS Glue Data Quality
AWS Glue Data Quality helps you automate and operationalize the delivery of high-quality data across data pipelines, proactively, before they are delivered to your data consumers. AWS Glue Data Quality provides statistical analysis of data quality issues across your data pipelines, can trigger alerts in Amazon EventBridge, and can make quality rule recommendations for remediation. AWS Glue Data Quality also supports rules creation with a domain-specific language so that you can create custom data quality rules.
AWS Key Management Service
AWS Key Management Service (AWS KMS) helps you create and control cryptographic keys to help protect your data. AWS KMS uses hardware security modules to protect and validate AWS KMS keys under the FIPS 140-2 Cryptographic Module Validation Program. For more information about how this service is used in a security context, see the AWS Security Reference Architecture.
AWS KMS integrates with most AWS services that offer encryption, and you can use KMS keys in your applications that process and store personal data. You can use AWS KMS to help support a variety of your privacy requirements and safeguard personal data, including:
-
Using customer managed keys for greater control over strength, rotation, expiration, and other options.
-
Using dedicated customer managed keys to protect personal data and secrets that allow access to personal data.
-
Defining data classification levels and designating at least one dedicated customer managed key per level. For example, you might have one key to encrypt operational data and another to encrypt personal data.
-
Preventing unintended cross-account access to KMS keys.
-
Storing KMS keys within the same AWS account as the resource to be encrypted.
-
Implementing separation of duties for KMS key administration and usage. For more information, see How to use KMS and IAM to enable independent security controls for encrypted data in S3
(AWS blog post). -
Enforcing automatic key rotation through preventative and reactive guardrails.
By default, KMS keys are stored and can be used only in the Region where they were created. If your organization has specific requirements for data residency and sovereignty, consider whether multi-Region KMS keys are appropriate for your use case. Multi-Region keys are special-purpose KMS keys in different AWS Regions that can be used interchangeably. The process of creating a multi-Region key moves your key material across AWS Region boundaries within AWS KMS, so this lack of regional isolation might not be compatible with your organization's sovereignty and residency goals. One way to solve for this is to use a different type of KMS key, such as a Region-specific customer managed key.
External key stores
For many organizations, the default AWS KMS key store in the AWS Cloud can fulfill their data sovereignty and general regulatory requirements. But a few might require that encryption keys are created and maintained outside of a cloud environment and that you have independent authorization and audit paths. With external key stores in AWS KMS, you can encrypt personal data with key material that your organization owns and controls outside of the AWS Cloud. You still interact with the AWS KMS API as usual, but AWS KMS interacts only with external key store proxy (XKS proxy) software that you provide. Your external key store proxy then mediates all communication between AWS KMS and your external key manager.
When using an external key store for data encryption, it is important that you consider the additional operational overhead compared to maintaining keys in AWS KMS. With an external key store, you must create, configure, and maintain the external key store. Also, if there are errors in the additional infrastructure you must maintain, such as the XKS proxy, and connectivity is lost, users might be temporarily unable to decrypt and access the data. Work closely with your compliance and regulatory stakeholders to understand the legal and contractual obligations for personal data encryption and your service level agreements for availability and resiliency.
AWS Lake Formation
Many organizations that catalog and categorize their datasets though structured
metadata catalogues want to share those datasets across their organization. You can
use AWS Identity and Access Management (IAM) permission policies to control access to entire datasets, but
more granular control is often required for datasets that contain personal data of
varying sensitivity. For example, the purpose specification and use
limitation
There are also privacy challenges associated with data lakes
You can use the tag-based access control feature in Lake Formation. Tag-based access control is an authorization strategy that defines permissions based on attributes. In Lake Formation, these attributes are called LF-Tags. Using an LF-Tag, you can attach these tags to Data Catalog databases, tables, and columns and grant the same tags to IAM principals. Lake Formation allows operations on those resources when the principal has been granted access to a tag value that matches the resource tag value. The following image shows how you can assign LF-Tags and permissions to provide differentiated access to personal data.

This example uses the hierarchal nature of tags. Both databases contain personally
identifiable information (PII:true), but tags at the columnar level
limits specific columns to different teams. In this example, IAM principals who
have the PII:true LF-Tag can access the AWS Glue database resources that
have this tag. Principals with the LOB:DataScience LF-Tag can access
specific columns that have this tag, and principals with the
LOB:Marketing LF-Tag can access only columns that have this tag.
The marketing can access only PII that is relevant to marketing use cases, and the
data science team can access only PII that is relevant to their use cases.
AWS Local Zones
If you need to comply with data residency requirements, you can deploy resources
that store and process personal data in specific AWS Regions to support these
requirements. You can also use AWS Local Zones,
which helps you place compute, storage, database, and other select AWS resources
close to large population and industry centers. A Local Zone is an extension of an
AWS Region that is in geographic proximity to a large metropolitan area. You can
place specific types of resources within a Local Zone, near the Region to which the
Local Zone corresponds. Local Zones can help you meet data residency requirements when a
Region is unavailable within the same legal jurisdiction. When you use Local Zones,
consider the data residency controls that are deployed within your organization. For
example, you might need a control to prevent data transfers from a specific Local
Zone to another Region. For more information about how to use SCPs to maintain
cross-border data transfer guardrails, see Best Practices for managing data residency in AWS Local Zones using landing zone
controls
AWS Nitro Enclaves
Consider your data segmentation strategy from a processing perspective, such as processing personal data with a compute service such as Amazon Elastic Compute Cloud (Amazon EC2). Confidential computing as a part of a larger architecture strategy can help you isolate personal data processing in an isolated, protected, and trusted CPU enclave. Enclaves are separate, hardened, and highly-constrained virtual machines. AWS Nitro Enclaves is an Amazon EC2 feature that can help you create these isolated compute environments. For more information, see The Security Design of the AWS Nitro System (AWS whitepaper).
Nitro Enclaves deploy a kernel that is separated from the parent instance's kernel. The parent instance's kernel doesn't have access to the enclave. Users can't SSH or remotely access the data and applications in the enclave. Applications that process personal data can be embedded in the enclave and configured to use the enclave's Vsock, the socket that facilitates communication between the enclave and the parent instance.
One use case where Nitro Enclaves can be useful is joint processing between two data processors that are in separate AWS Regions and that might not trust each other. The following image shows how you can use an enclave for central processing, a KMS key for encrypting the personal data before it's sent to the enclave, and an AWS KMS key policy that verifies that the enclave requesting decryption has the unique measurements in its attestation document. For more information and instructions, see Using cryptographic attestation with AWS KMS. For a sample key policy, see Require attestation to use an AWS KMS key in this guide.

With this implementation, only the respective data processors and the underlying enclave have access to the plaintext personal data. The only place the data is exposed, outside of the respective data processors' environments, is in the enclave itself, which is designed to prevent access and tampering.
AWS PrivateLink
Many organizations want to limit the exposure of personal data to untrusted
networks. For example, if you want to enhance the privacy of your overall
application architecture design, you can segment networks based on data sensitivity
(similar to the logical and physical separation of datasets that is discussed in the
AWS services and features that help segment
data section). AWS PrivateLink helps you create unidirectional, private connections from
your virtual private clouds (VPCs) to services outside of the VPC. Using
AWS PrivateLink, you can set up dedicated private connections to the services that
store or process personal data in your environment; there is no need to connect to
public endpoints and transfer this data over untrusted public networks. When you
enable AWS PrivateLink service endpoints for the in-scope services, there is no need
for an internet gateway, NAT device, public IP address, AWS Direct Connect connection, or
AWS Site-to-Site VPN connection in order to communicate. When you use AWS PrivateLink to connect
to a service that provides access to personal data, you can use VPC endpoint
policies and security groups to control access, according to your organization's
data
perimeter
AWS Resource Access Manager
AWS Resource Access Manager (AWS RAM) helps you securely share your resources across AWS accounts to reduce operational overhead and provide visibility and auditability. As you plan your multi-account segmentation strategy, consider using AWS RAM to share the personal data stores that you store in a separate, isolated account. You can share that personal data with other, trusted accounts for the purposes of processing. In AWS RAM, you can manage permissions that define what actions can be performed on shared resources. All API calls to AWS RAM are logged in CloudTrail. Also, you can configure Amazon CloudWatch Events to automatically notify you for specific events in AWS RAM, such as when changes are made to a resource share.
Though you can share many types of AWS resources with other AWS accounts by using resource-based policies in IAM or bucket policies in Amazon S3, AWS RAM provides several additional benefits for privacy. AWS provides data owners with additional visibility over how and with whom the data is shared across your AWS accounts, including:
-
Being able to share a resource with an entire OU instead of manually updating lists of account IDs
-
Enforcement of the invitation process for share initiation if the consumer account isn't part of your organization
-
Visibility into which specific IAM principals have access to each individual resource
If you've previously used a resource-based policy to manage a resource share and want to use AWS RAM instead, use the PromoteResourceShareCreatedFromPolicy API operation.
Amazon SageMaker AI
Amazon SageMaker AI
Amazon SageMaker Model Monitor
Many organizations consider data drift when training ML models. Data drift is a meaningful variation between the production data and the data that was used to train an ML model, or a meaningful change in the input data over time. Data drift can reduce the overall quality, accuracy, and fairness in ML model predictions. If the statistical nature of the data that a ML model receives in production drifts away from the nature of the baseline data it was trained on, the accuracy of the predictions might decline. Amazon SageMaker Model Monitor can continuously monitor the quality of Amazon SageMaker AI machine learning models in production and monitor data quality. Early and proactive detection of data drift can help you implement corrective actions, such as retraining models, auditing upstream systems, or fixing data quality issues. Model Monitor can alleviate the need to manually monitor models or build additional tooling.
Amazon SageMaker Clarify
Amazon SageMaker Clarify provides insight into model bias and explainability. SageMaker Clarify is commonly used during ML model data preparation and the overall development phase. Developers can specify attributes of interest, such as gender or age, and SageMaker Clarify runs a set of algorithms to detect any presence of bias in those attributes. After the algorithm runs, SageMaker Clarify provides a visual report with a description of the sources and measurements of possible bias so that you can identify steps to remediate the bias. For example, in a financial dataset that contains only a few examples of business loans to one age group as compared to others, SageMaker could flag imbalances so that you can avoid a model that disfavors that age group. You can also check already trained models for bias by reviewing its predictions and by continuously monitoring those ML models for bias. Finally, SageMaker Clarify is integrated with Amazon SageMaker AI Experiments to provide a graph that explains which features contributed most to a model's overall prediction-making process. This information could be useful to meet explainability outcomes, and it could help you determine if a particular model input has more influence than it should on the overall model behavior.
Amazon SageMaker Model Card
Amazon SageMaker Model Card can help you document critical details about your ML models for governance and reporting purposes. These details can include the model owner, general purpose, intended use cases, assumptions made, risk rating of a model, training details and metrics, and evaluation results. For more information, see Model Explainability with AWS Artificial Intelligence and Machine Learning Solutions (AWS whitepaper).
Amazon SageMaker Data Wrangler
Amazon SageMaker Data
Wrangler
Data Wrangler can be used as part of the data preparation and feature
engineering process in the AWS PRA. It supports data encryption at rest and in
transit by using AWS KMS, and it uses IAM roles and policies to control access
to data and resources. It supports data masking through AWS Glue or Amazon SageMaker
Feature Store. If you integrate Data Wrangler with AWS Lake Formation, you can
enforce fine-grained data access controls and permissions. You can even use Data
Wrangler with Amazon Comprehend to automatically redact personal data from tabular data as a
part of your broader ML Ops workflow. For more information, see Automatically redact PII for machine learning using Amazon SageMaker Data
Wrangler
The versatility of Data Wrangler helps you mask sensitive data for many industries, such as account numbers, credit card numbers, social security numbers, patient names, and medical and military records. You can limit access to any sensitive data or choose to redact it.
AWS features that help manage the data lifecycle
When personal data is no longer required, you can use lifecycle and time-to-live polices for data in many different data stores. When configuring data retention policies, consider the following locations that might contain personal data:
-
Databases, such as Amazon DynamoDB and Amazon Relational Database Service (Amazon RDS)
-
Amazon S3 buckets
-
Logs from CloudWatch and CloudTrail
-
Cached data from migrations in AWS Database Migration Service (AWS DMS) and AWS Glue DataBrew projects
-
Backups and snapshots
The following AWS services and features can help you configure data retention policies in your AWS environments:
-
Amazon S3 Lifecycle – A set of rules that define actions that Amazon S3 applies to a group of objects. In the Amazon S3 Lifecyle configuration, you can create expiration actions, which define when Amazon S3 deletes expired objects on your behalf. For more information, see Managing your storage lifecycle.
-
Amazon Data Lifecycle Manager – In Amazon EC2, create a policy that automates the creation, retention, and deletion of Amazon Elastic Block Store (Amazon EBS) snapshots and EBS-backed Amazon Machine Images (AMIs).
-
DynamoDB Time to Live (TTL) – Define a per-item timestamp that determines when an item is no longer needed. Shortly after the date and time of the specified timestamp, DynamoDB deletes the item from your table.
-
Log retention settings in CloudWatch Logs – You can adjust the retention policy for each log group to a value between 1 day and 10 years.
-
AWS Backup – Centrally deploy data protection policies to configure, manage, and govern your backup activity across a variety of AWS resources, including S3 buckets, RDS database instances, DynamoDB tables, EBS volumes, and many more. Apply backup policies to your AWS resources by either specifying resource types or provide additional granularity by applying based on existing resource tags. Audit and report on backup activity from a centralized console to help meet backup compliance requirements.
AWS services and features that help segment data
Data segmentation is the process by which you store data in separate containers. This can help you to provide differentiated security and authentication measures to each dataset and to reduce the scope of impact of exposure for your overall dataset. For example, instead of storing all customer data in one large database, you may segment this data into smaller, more manageable groups.
You can use physical and logical separation to segment personal data:
-
Physical separation – The act of storing data in separate data stores or distributing your data into separate AWS resources. Though the data is physically separated, both resources might be accessible to the same principals. This is why we recommend combining physical separation with logical separation.
-
Logical separation – The act of isolating data by using access controls. Different job functions require different levels of access to subsets of personal data. For a sample policy that implements logical separation, see Grant access to specific Amazon DynamoDB attributes in this guide.
The combination of a logical and physical separation provides flexibility, simplicity, and granularity when writing identity-based and resource-based policies to support differentiated access across job functions. For example, it can be operationally complex to create the policies that logically separate different data classifications in a single S3 bucket. Using dedicated S3 buckets for each data classification simplifies policy configuration and management.
AWS services and features that help discover, classify, or catalog data
Some organizations have not started to use extract, load, and transform (ELT)
tools in their environment to proactively catalog their data. These customers might
be at an early data discovery stage, where they want to better understand the data
that they store and process in AWS and how it's structured and classified. You can
use Amazon Macie to better understand your PII data in Amazon S3. However,
Amazon Macie cannot help you analyze other data sources, such as Amazon Relational Database Service (Amazon RDS) and
Amazon Redshift. You can use two approaches to accelerate the initial discovery at the
beginning of a larger data mapping
exercise
-
Manual approach – Make a table with two columns and as many rows as you need. In the first column, write a data characterization (such as user name, address, or gender) that might be in the header or body of a network packet or in any service that you provide. Ask your compliance team to complete the second column. In the second column, enter a "yes" if the data is considered personal and "no" if it isn't. Indicate any type of personal data that is deemed particularly sensitive, such as religious denomination or health data.
-
Automated approach – Use tooling provided through AWS Marketplace. One such tool is Securiti
. These solutions offer integrations that allow them to scan and discover data across multiple AWS resource types, as well as assets in other cloud service platforms. Many of these same solutions can continually collect and maintain an inventory of data assets and data processing activities in a centralized data catalog. If you rely on a tool to perform automated classification, it might require tuning discovery and classification rules in order to align to your organization's definition of personal data.
