Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Tal y como se describe en Capacidades de Neptune ML, Neptune ML admite modelos de entrenamiento que pueden realizar los siguientes tipos de tareas de inferencia:
Clasificación de nodos: predice la característica categórica de una propiedad de vértice.
Regresión de nodos: predice una propiedad numérica de un vértice.
Clasificación de bordes: predice la característica categórica de una propiedad de borde.
Regresión de bordes: predice una propiedad numérica de un borde.
Predicción de enlaces: predice los nodos de destino con un nodo de origen y un borde de salida, o los nodos de origen con un nodo de destino y un borde de entrada.
Podemos ilustrar estas diferentes tareas con ejemplos que utilizan el conjunto de datos de MovieLens 100 000
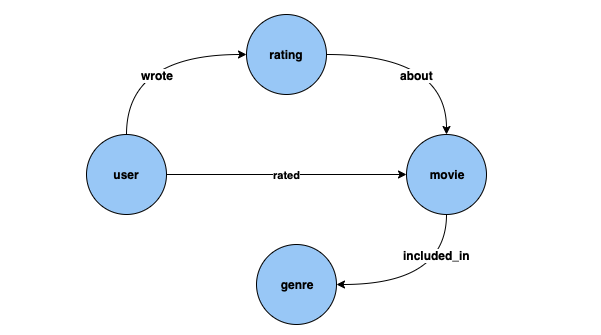
Clasificación de nodos: en el conjunto de datos anterior, Genre es un tipo de vértice que está conectado al tipo de vértice Movie mediante el borde included_in. Sin embargo, si retocamos el conjunto de datos para que Genre sea una característica categóricaMovie, el problema de inferir Genre para las nuevas películas que se añadan a nuestro gráfico de conocimientos se puede resolver mediante modelos de clasificación de nodos.
Regresión de nodos: si tenemos en cuenta el tipo de vértice Rating, que tiene propiedades como timestamp y score, el problema de inferir el valor numérico Score para una Rating se puede resolver mediante modelos de regresión de nodos.
Clasificación de bordes: del mismo modo, en el caso de un borde Rated, si tenemos una propiedad Scale que puede tener uno de los valores Love, Like, Dislike, Neutral o Hate, el problema de inferir Scale del borde Rated para nuevas películas o clasificaciones se puede resolver mediante modelos de clasificación de bordes.
Regresión de bordes: del mismo modo, para el mismo borde Rated, si tenemos una propiedad Score que incluye un valor numérico para la clasificación, esto se puede inferir de los modelos de regresión de bordes.
Predicción de enlaces: problemas, como encontrar los diez principales usuarios que tienen más probabilidades de puntuar una determinada película o encontrar las diez principales películas que un determinado usuario tiene más probabilidades de valorar, se consideran parte de la predicción de enlaces.
nota
Para los casos de uso de Neptune ML, tenemos un conjunto muy completo de cuadernos diseñados para proporcionarle una comprensión práctica de cada caso de uso. Puede crear estos cuadernos junto con su clúster de Neptuno cuando utilice la plantilla Neptune AWS CloudFormation ML para crear un clúster de Neptune ML. Estos cuadernos también están disponibles en github
Temas
