Notas de la versión
Describe las características, mejoras y correcciones de errores de Amazon Athena por fecha de lanzamiento.
Notas de la versión de Athena para 2025
15 de agosto de 2025
Publicado el 15/08/2025
Athena anuncia las siguientes características y mejoras.
Consultas CREATE TABLE AS SELECT (CTAS) para tablas de S3: Athena ahora admite consultas CREATE TABLE AS SELECT (CTAS) para tablas de S3. Para obtener más información, consulte Creación de tablas de S3 en Athena.
Eliminación de la compatibilidad con las estadísticas heredadas de tablas de Iceberg: hemos retirado la compatibilidad con el seguimiento de las estadísticas de tablas de Iceberg heredadas en Athena. Si tiene tablas que se escribieron antes del 7 de mayo de 2023, debe volver a analizarlas.
11 de agosto de 2025
Publicado el 11/08/2025
Athena anuncia las siguientes correcciones y mejoras:
-
Hemos cambiado el comportamiento de
lead()ylag()con respecto al manejo de desplazamientosNULL. Antes de este cambio, transferir un desplazamientoNULLa las funcioneslead()ylag()producíaNULLcomo resultado. Ahora, Athena devuelve el error: El desplazamiento no puede ser nulo.Esto se hace para que el comportamiento cumpla con los estándares SQL y para evitar valores
NULLinesperados en la salida, al impedirlos de forma proactiva en la entrada. Con este cambio, se recomienda no transferir un desplazamientoNULLa las funcioneslead()ylag(). Aunque no se recomienda, puede conservar el comportamiento anterior si lo reescribe como se muestra en el siguiente ejemplo:Patrón de consulta original
lead(column1, column_containing_nulls) OVER (...) as transformedPatrón de consulta actualizado
CASE WHEN column_containing_nulls IS NULL THEN NULL ELSE (lead(column1, coalesce(column_containing_nulls, 1)) OVER (...)) END as transformed
17 de julio de 2025
Publicado el 17/07/2025
Athena lanza la versión 3.5.1 del controlador JDBC. Para obtener más información sobre esta versión del controlador, consulte Notas de la versión de JDBC 3.x de Amazon Athena. Para descargar el controlador JDBC más reciente, consulte Descarga del controlador JDBC 3.x.
30 de junio de 2025
Publicado el 30/06/2025
Amazon Athena anuncia la disponibilidad de Athena SQL en la región Asia-Pacífico (Taipéi).
Para obtener una lista completa de los Servicios de AWS disponibles en cada Región de AWS, consulte Servicios de AWS por región
17 de junio de 2025
Publicado el 17/06/2024
Athena lanza la versión 2.0.4.0 del controlador ODBC. Para obtener más información sobre esta versión del controlador, consulte Notas de la versión de ODBC 2.x de Amazon Athena. Para descargar el controlador ODBC 2.x, consulte Descarga del controlador ODBC 2.x.
3 de junio de 2025
Publicado el 3/06/2025
Athena presenta los resultados de consultas administrados, una nueva característica que almacena, protege y gestiona automáticamente los datos de los resultados de las consultas sin costos. Los resultados de consultas administrados ayudan a empezar con menos pasos, ya que eliminan la necesidad de tener buckets de Amazon S3 para almacenar los resultados de las consultas y limpian los procesos para eliminar los resultados de las consultas que ya no se necesitan. Los resultados de las consultas administrados están generalmente disponibles en todas las regiones en las que Athena está disponible, excepto en
Al utilizar los resultados de consultas administrados, se puede seguir accediendo a los resultados de las consultas a través de las mismas interfaces que con el almacenamiento en buckets de S3 tradicional. Para empezar, utilice la AWS Management Console, AWS SDK o la AWS CLI para configurar grupos de trabajo nuevos o existentes para utilizar los resultados de las consultas administrados. Para obtener más información, consulte Resultados de consultas administrados.
27 de mayo de 2025
Publicado el 27/05/2025
Athena anuncia las siguientes correcciones y mejoras:
Mensajes de error mejorados para las tablas de metadatos de Delta Lake: hemos mejorado los mensajes de error para las tablas de metadatos de Delta Lake y ahora ofrecemos una respuesta más clara cuando se intenta consultar estas tablas no compatibles.
14 de mayo de 2025
Publicado el 14/05/2025
Athena anuncia las siguientes correcciones y mejoras:
Hemos resuelto un problema que podía provocar que los archivos ORC se crearan con un tamaño de archivo superior al previsto.
-
Se ha mejorado el rendimiento de los análisis en las tablas de Delta Lake que utilizan puntos de comprobación v2.
18 de abril de 2025
Publicado el 18/04/2025
Athena anuncia las siguientes correcciones y mejoras:
Seguimiento de reservas de capacidad: resolvimos un problema en nuestro sistema de seguimiento de reservas de capacidad por el que las reservas no se liberaban correctamente durante los escenarios de cancelación de consultas, específicamente después de planificar la consulta y antes de que Athena adquiriera trabajadores para la ejecución de las consultas. La solución permite al motor de consultas Athena liberar explícitamente la reserva de capacidad cuando se produce la situación anterior.
16 de abril de 2025
Publicado el 16/04/2025
Amazon Athena anuncia la disponibilidad de Athena SQL en las regiones de Asia Pacífico (Tailandia) y México (Centro).
Para obtener una lista completa de los Servicios de AWS disponibles en cada Región de AWS, consulte Servicios de AWS por región
09 de abril de 2025
Publicado el 09/04/2025
Athena anuncia las siguientes características y mejoras.
Controlador JDBC 2.2.1
Lanzamiento de los controladores JDBC 2.2.1 para Athena.
Actualizaciones y mejoras:
-
Se actualizaron las bibliotecas Logback para usar la versión 1.3.15.
Para obtener más información y descargar el controlador JDBC 2.x, las notas de la versión y la documentación, consulte Controlador JDBC 2.x de Athena.
18 de marzo de 2025
Publicado el 18/03/2025
Athena lanza la versión 3.5.0 del controlador JDBC. Para obtener más información sobre esta versión del controlador, consulte Notas de la versión de JDBC 3.x de Amazon Athena. Para descargar el controlador JDBC más reciente, consulte Descarga del controlador JDBC 3.x.
14 de marzo de 2025
Publicado el 14 de marzo de 2025
Amazon Athena lanza capacidades para crear y consultar operaciones de tablas directamente desde la consola de S3.
Para obtener más información, consulte Registro de catálogos de buckets de tabla de S3 y consulta de tablas desde Athena.
7 de marzo de 2025
Publicado el 7 de marzo de 2025
La capacidad aprovisionada ahora está disponible de forma general en la región Asia-Pacífico (Bombay). La capacidad aprovisionada permite ejecutar consultas SQL en capacidad de computación completamente administrada y ofrece funciones de administración de cargas de trabajo que ayudan a priorizar, controlar y escalar las cargas de trabajo interactivas más importantes. Puede agregar capacidad en cualquier momento para aumentar la cantidad de consultas que ejecuta en simultáneo, controlar qué cargas de trabajo utilizan la capacidad y compartir la capacidad entre las cargas de trabajo.
Para obtener más información, consulte Administración de la capacidad de procesamiento de consultas. Para obtener información sobre los precios, consulte la página de Precios de Amazon Athena
18 de febrero de 2025
Publicado el 18/02/2025
Athena lanza la versión 3.4.0 del controlador JDBC. Para obtener más información sobre esta versión del controlador, consulte Notas de la versión de JDBC 3.x de Amazon Athena. Para descargar el controlador JDBC más reciente, consulte Descarga del controlador JDBC 3.x.
22 de enero de 2025
Publicado el 22/01/2025
Athena ahora admite consultas federadas a través de Lambda y cifrado de resultados de consultas mediante KMS en grupos de trabajo habilitados para TIP. Para obtener más información, consulte Uso de grupos de trabajo de Athena habilitados para IAM Identity Center.
Notas de la versión de Athena para 2024
17 de diciembre de 2024
Publicado el 17/12/2024
Amazon Athena anuncia la disponibilidad de Athena SQL en la región Asia-Pacífico (Malasia).
Para obtener una lista completa de los Servicios de AWS disponibles en cada Región de AWS, consulte Servicios de AWS por región
16 de diciembre de 2024
Publicado el 16/12/2024
Corrección de vectores de eliminación: se ha corregido un problema con los vectores de eliminación que provocaba que las tablas con particiones arrojaran resultados incorrectos en el conector Delta Lake.
3 de diciembre de 2024
Publicado el 3/12/2024
Athena anuncia las siguientes características y mejoras.
-
Conexiones a orígenes de datos: Amazon Athena anuncia una consola y un flujo de trabajo de API simplificados para crear conexiones de origen de datos. Ahora puede crear y administrar las conexiones de datos de Athena completamente dentro de la consola de Athena, y las propiedades de las conexiones se almacenan ahora de forma centralizada en el AWS Glue Data Catalog.
Al almacenar las propiedades de las conexiones en AWS Glue, podrá volver a utilizar las conexiones en otros servicios de AWS. Por ejemplo, después de configurar un conector de Athena a Amazon DynamoDB, podrá reutilizar las propiedades y los permisos que especificó para la conexión para un trabajo de ETL de AWS Glue que obtenga acceso a los datos en DynamoDB. Para obtener más información, consulte Uso de la consola de Athena para conectarse a un origen de datos en la Guía del usuario de Amazon Athena y CreateDataCatalog en la Referencia de la API de Amazon Athena.
-
Consulta de datos de Redshift registrados en AWS Glue Data Catalog: Athena ahora permite leer y escribir en tablas de Redshift registradas en Glue Data Catalog. Para obtener más información, consulte Registrar catálogos de datos de Redshift en Athena.
-
Consulta de tablas de S3 desde Athena: los buckets de tabla de S3 son un tipo de bucket de Amazon S3 diseñado específicamente para almacenar datos tabulares en tablas de Apache Iceberg. Athena ahora admite consultas DQL y DML en tablas de S3. Para obtener más información, consulte Registro de catálogos de buckets de tabla de S3 y consulta de tablas desde Athena.
30 de octubre de 2024
Publicado el 30/10/2024
Athena lanza la versión 3.3.0 del controlador JDBC. Para obtener más información sobre esta versión del controlador, consulte Notas de la versión de JDBC 3.x de Amazon Athena. Para descargar el controlador JDBC 3.x, consulte Descarga del controlador JDBC 3.x.
23 de agosto de 2024
Publicado el 05/09/2024
Athena anuncia lo siguiente:
-
Consulta de vistas federadas con consultas de acceso directo: ahora se admiten consultas de acceso directo federadas para las vistas. Para obtener más información, consulte Consulta de vistas federadas.
-
Consultas de acceso directo múltiples: ahora puede ejecutar más de una consulta de acceso directo federada en la misma ejecución de consulta. Para obtener más información, consulte Uso de consultas de acceso directo federadas.
-
Corrección de OPTIMIZE en tablas Iceberg: se solucionó un problema en el que ejecutar
OPTIMIZEen una tabla Iceberg no eliminaba los archivos con indicación "borrar" al reescribir archivos de datos que tenían un archivo con indicación "borrar" asociado. Para obtener más información, consulte OPTIMIZE. -
Soporte de escritura de Parquet LZ4 y LZO: Athena ya no admite la escritura de archivos Parquet comprimidos con los formatos LZ4 o LZO. La lectura de estos formatos de compresión sigue siendo compatible. Para obtener información sobre los formatos de compresión en Athena, consulte Uso de la compresión en Athena.
29 de julio de 2024
Publicado el 29/07/2024
Athena lanza la versión 3.2.2 del controlador JDBC. Para obtener más información sobre esta versión del controlador, consulte Notas de la versión de JDBC 3.x de Amazon Athena. Para descargar el controlador JDBC 3.x, consulte Descarga del controlador JDBC 3.x.
26 de julio de 2024
Publicado el 01/08/2024
Athena anuncia la siguiente mejora.
-
Compatibilidad con vectores de eliminación de tablas de Delta Lake: Athena ahora admite la lectura de tablas de Delta Lake con vectores de eliminación
. Para obtener más información, consulte Consulta de las tablas de Linux Foundation Delta Lake.
3 de julio de 2024
Publicado el 3/07/2024
Athena lanza la versión 3.2.1 del controlador JDBC. Para obtener más información sobre esta versión del controlador, consulte Notas de la versión de JDBC 3.x de Amazon Athena. Para descargar el controlador JDBC 3.x, consulte Descarga del controlador JDBC 3.x.
26 de junio de 2024
Publicado el 26/06/2024
La capacidad aprovisionada ya se encuentra disponible de forma general en las regiones de América del Sur (São Paulo) y Europa (España). La capacidad aprovisionada permite ejecutar consultas SQL en capacidad de computación completamente administrada y ofrece funciones de administración de cargas de trabajo que ayudan a priorizar, controlar y escalar las cargas de trabajo interactivas más importantes. Puede agregar capacidad en cualquier momento para aumentar la cantidad de consultas que ejecuta en simultáneo, controlar qué cargas de trabajo utilizan la capacidad y compartir la capacidad entre las cargas de trabajo.
Para obtener más información, consulte Administración de la capacidad de procesamiento de consultas. Para obtener información sobre los precios, consulte la página de Precios de Amazon Athena
10 de mayo de 2024
Publicado el 15/07/2024
Athena anuncia las siguientes características y mejoras.
-
Delta Lake: Athena agregó optimizaciones que filtran las entradas que no son necesarias de los archivos de puntos de control. Estas optimizaciones habilitan un rendimiento con una mejora importante para las consultas con archivos de puntos de control de gran tamaño que hacen referencia a muchos archivos de datos de Parquet.
Para obtener más información acerca del uso de tablas de Linux Foundation Delta Lake con Athena, consulte Consulta de las tablas de Linux Foundation Delta Lake.
26 de abril de 2024
Publicado el 26/04/2024
Athena lanza la versión 3.2.0 del controlador JDBC. Para obtener más información sobre esta versión del controlador, consulte Notas de la versión de JDBC 3.x de Amazon Athena. Para descargar el controlador JDBC 3.x, consulte Descarga del controlador JDBC 3.x.
24 de abril de 2024
Publicado el 24/04/2024
Athena anuncia las siguientes correcciones y mejoras.
-
Parquet: Athena ahora admite lecturas compatibles con versiones anteriores en Parquet para campos primitivos repetidos y sin anotaciones que no estén incluidos en una lista o grupo de asignaciones. Este cambio evita que se devuelvan resultados incorrectos sin previo aviso y mejora los mensajes de error en caso de discrepancias en el esquema.
Para obtener más información, consulte Support backwards compatible reads for unannotated repeated primitive fields in Parquet
en GitHub.com. -
Iceberg OPTIMIZE: se resolvió un problema con las consultas de
OPTIMIZEque provocaban la pérdida de datos cuando se utilizaba un filtro de clave que no era de partición en una cláusulaWHERE. Para obtener más información, consulte OPTIMIZE.
16 de abril de 2024
Publicado el 16/04/2024
Utilice la nueva característica de consultas de acceso directo federadas de Amazon Athena para ejecutar consultas completas directamente en el origen de datos subyacente. Las consultas de acceso directo federadas le ayudan a aprovechar las funciones únicas, el lenguaje de consulta y las capacidades de rendimiento del origen de datos original. Por ejemplo, puede ejecutar consultas de Athena en DynamoDB con el lenguaje PartiQL. Las consultas de acceso directo federadas también son útiles cuando desea ejecutar consultas SELECT que agreguen, unan o invoquen funciones del origen de datos que no están disponibles en Athena. El uso de consultas de acceso directo puede reducir la cantidad de datos que procesa Athena y reducir los tiempos de consulta.
Para obtener más información, consulte Uso de consultas de acceso directo federadas. Para obtener la última versión de los conectores que utiliza hoy, consulte Actualización de un conector de origen de datos.
10 de abril de 2024
Publicado el 10/04/2024
Athena anuncia las siguientes características y mejoras.
Controlador ODBC 1.2.3.1000
Controlador ODBC 1.2.3.1000 para Athena.
Problemas resueltos:
-
Problema de conexión con el servidor proxy: cuando se utilizaba un servidor proxy sin el certificado raíz, el conector no podía establecer una conexión.
Para obtener más información y descargar el controlador ODBC 1.x, las notas de la versión y la documentación, consulte Controlador ODBC 1.x de Athena.
Controlador JDBC 2.1.5
Lanzamiento del controlador JDBC 2.1.5 para Athena.
Actualizaciones y mejoras:
-
Se actualizó el SDK de AWS para Java a la versión 1.12.687.
-
Se actualizaron las bibliotecas Jackson para usar la versión 2.16.0.
-
Se actualizaron las bibliotecas Logback para usar la versión 1.3.14.
Para obtener más información y descargar el controlador JDBC 2.x, las notas de la versión y la documentación, consulte Controlador JDBC 2.x de Athena.
8 de abril de 2024
Publicado el 08/04/2024
Athena anuncia el controlador ODBC versión 2.0.3.0. Para obtener más información, consulte las notas de la versión 2.0.3.0. Para descargar el nuevo controlador ODBC v2, consulte Descarga del controlador ODBC 2.x. Para obtener información sobre la conexión, consulte el ODBC 2.x de Amazon Athena.
15 de marzo de 2024
Publicado el 18/03/2024
Amazon Athena anuncia la disponibilidad de Athena SQL en la región Oeste de Canadá (Calgary).
Para obtener una lista completa de los Servicios de AWS disponibles en cada Región de AWS, consulte Servicios de AWS por región
15 de febrero de 2024
Publicado el 15/02/2024
Athena lanza la versión 3.1.0 del controlador JDBC.
La versión 3.1.0 del controlador JDBC de Amazon Athena agrega compatibilidad con la autenticación integrada de Windows y la autenticación basada en formularios de Microsoft Active Directory Federation Services (AD FS). Esta versión 3.1.0 también incluye mejoras generales de rendimiento y correcciones de errores.
Para descargar el controlador JDBC v3, consulte Descarga del controlador JDBC 3.x.
31 de enero de 2024
Publicado el 31/01/2024
Athena anuncia las siguientes características y mejoras.
-
Hudi upgrade: ahora puede utilizar Athena SQL para consultar tablas Hudi 0.14.0. Para obtener más información acerca de la utilización de Athena SQL para consultar tablas Hudi, consulte Consulta de los conjuntos de datos de Apache Hudi.
Notas de la versión de Athena para 2023
14 de diciembre de 2023
Publicado el 14/12/2023
Athena anuncia las siguientes correcciones y mejoras.
Athena lanza la versión 2.1.3 del controlador JDBC. El controlador resuelve los siguientes problemas:
-
Se mejoró el registro para evitar conflictos con el registro de aplicaciones de Spring Boot y Gradle.
-
Al utilizar el método
executeBatch()de JDBC para insertar registros, el controlador insertó incorrectamente un solo registro. Como Athena no admite la ejecución por lotes de consultas, el controlador ahora informa de un error cuando utilizaexecuteBatch(). Para evitar esta limitación, puede enviar consultas individuales en un bucle.
Para descargar el nuevo controlador JDBC, las notas de la versión y la documentación, consulte Controlador JDBC 2.x de Athena.
9 de diciembre de 2023
Publicado el 09/12/2023
Se lanzó el controlador ODBC 1.2.1.1000 para Athena.
Características y mejoras:
-
Se actualizó la compatibilidad con RStudio: el controlador ODBC ahora es compatible con RStudio en macOS.
-
Compatibilidad con un único catálogo y esquema: el conector ahora puede devolver un único catálogo y esquema. Para obtener más información, consulte la guía de instalación y configuración descargable.
Problemas resueltos:
-
Instrucciones preparadas: cuando se ejecutaban instrucciones preparadas con una matriz de parámetros mediante un esquema por columnas, el conector devolvía un resultado de consulta incorrecto.
-
Tamaño de columna: al seleccionar la columna
$file_modified_timedel sistema, el conector devolvía un tamaño de columna incorrecto. -
SQLPrepare: al vincular los parámetros relacionados con las consultas de
SQLPrepareenSELECT, el conector devolvía un error.
Para obtener más información y descargar los nuevos controladores, las notas de la versión y la documentación, consulte Controlador ODBC 1.x de Athena.
7 de diciembre de 2023
Publicado el 07/12/2023
Athena anuncia la versión 2.0.2.1 del controlador ODBC. Para obtener más información, consulte las notas de la versión 2.0.2.1. Para descargar el nuevo controlador ODBC v2, consulte Descarga del controlador ODBC 2.x. Para obtener información sobre la conexión, consulte el ODBC 2.x de Amazon Athena.
5 de diciembre de 2023
Publicado el 05/12/2023
Ahora puede crear grupos de trabajo de Athena SQL que utilicen el modo de autenticación de AWS IAM Identity Center. Estos grupos de trabajo admiten la característica de propagación de identidad de confianza del IAM Identity Center. La propagación de identidad de confianza permite que las identidades se utilicen en los servicios de análisis de AWS, como Amazon Athena y Amazon EMR Studio.
Para obtener más información, consulte Uso de grupos de trabajo de Athena habilitados para IAM Identity Center.
28 de noviembre de 2023
Publicado el 28/11/2023
Ahora puede consultar datos en la clase de almacenamiento Amazon S3 Express One Zone
Para obtener más información, consulte Consulta de datos de S3 Express One Zone.
27 de noviembre de 2023
Publicado el 27/11/2023
Athena anuncia las siguientes características y mejoras.
-
Vistas del catálogo de datos de Glue: las vistas del catálogo de datos de Glue proporcionan una única vista común de todos los servicios de AWS, como Amazon Athena y Amazon Redshift. En las vistas del catálogo de datos de Glue, los permisos de acceso los define el usuario que creó la vista y no el usuario que consulta la vista. Estas vistas proporcionan un mayor control de acceso, ayudan a garantizar registros completos, ofrecen una mayor seguridad y pueden impedir el acceso a las tablas subyacentes.
Para obtener más información, consulte Uso de vistas del Catálogo de datos en Athena.
-
Compatibilidad con CloudTrail Lake: ahora puede usar Amazon Athena para analizar datos en AWS CloudTrail Lake. AWS CloudTrail Lake es un lago de datos administrado para CloudTrail que puede utilizar para agregar, almacenar de forma inmutable y analizar los registros de actividad para investigaciones de auditoría, seguridad y operaciones. Para consultar los registros de actividad de CloudTrail Lake desde Athena, no es necesario mover datos ni crear canalizaciones de procesamiento de datos independientes. No se requieren operaciones de ETL.
Para empezar, habilite la federación de datos en CloudTrail Lake. Al compartir los metadatos del almacén de datos de eventos de CloudTrail Lake con AWS Glue Data Catalog, CloudTrail crea los recursos necesarios de AWS Glue Data Catalog y registra los datos con AWS Lake Formation. En Lake Formation, puede especificar los usuarios y roles que puede utilizar Athena para consultar el almacén de datos de sus eventos.
Para obtener más información, consulte Habilitar la federación de consultas de Lake en la Guía del usuario de AWS CloudTrail.
17 de noviembre de 2023
Publicado el 17/11/2023
Athena anuncia las siguientes características y mejoras.
Características
-
Optimizador basado en costes: Athena anuncia la disponibilidad general de la optimización basada en costos utilizando estadísticas de AWS Glue. Para optimizar sus consultas en Athena SQL, puede solicitar que Athena recopile estadísticas a nivel de tabla o columna para sus tablas en AWS Glue. Si todas las tablas de la consulta tienen estadísticas, Athena las utiliza para examinar planes de ejecución alternativos y seleccionar el que tenga más probabilidades de ser el más rápido.
Para obtener más información, consulte Uso del optimizador basado en costos.
-
Integración con Amazon EMR Studio: ahora puede usar Athena en un Amazon EMR Studio sin tener que usar la consola Athena directamente. Con la integración de Athena en Amazon EMR, puede llevar a cabo las siguientes tareas:
-
Realizar consultas SQL de Athena
-
Visualización de los resultados de la consulta
-
Visualizar el historial de consultas
-
Visualizar las consultas guardadas
-
Realizar consultas parametrizadas
-
Ver bases de datos, tablas y vistas de un catálogo de datos
Para más información, consulte Amazon EMR Studio en el tema Integraciones de los Servicio de AWS con Athena.
-
-
Control de acceso anidado: Athena anuncia su compatibilidad con el control de acceso de Lake Formation para datos anidados. En Lake Formation, puede definir y aplicar filtros de datos en columnas anidadas que tengan tipos de datos
struct. Puede utilizar el filtrado de datos para restringir el acceso de los usuarios a las subestructuras de las columnas anidadas. Para obtener más información acerca de cómo crear un filtro de datos, consulte Creación de un filtro de datos en la Guía para desarrolladores de AWS Lake Formation. -
Métricas de uso de la capacidad aprovisionada: Athena anuncia nuevas métricas de CloudWatch para las reservas de capacidad. Puede usar las nuevas métricas para realizar un seguimiento del número de DPU que ha aprovisionado y del número de DPU que utilizan sus consultas. Cuando finalicen las consultas, también podrá ver la cantidad de DPU consumidas por la consulta.
Para obtener más información, consulte Supervisión de las métricas de consultas de Athena con CloudWatch.
Mejoras
-
Cambio de mensaje de error: el mensaje de error
Insufficient Lake Formation permissionsahora diceTable not foundoSchema not found. Este cambio se realizó para evitar que actores malintencionados dedujeran la existencia de recursos de tablas o bases de datos a partir del mensaje de error.
16 de noviembre de 2023
Publicado el 16/11/2023
Athena ha lanzado un controlador JDBC nuevo que mejora la experiencia de conexión, consulta y visualización de datos desde aplicaciones de inteligencia empresarial y desarrollo de SQL compatibles. El nuevo controlador es fácil de actualizar. Este controlador puede leer los resultados de las consultas directamente desde Amazon S3, lo que permite que estos resultados se encuentren disponibles con mayor rapidez.
Para obtener más información, consulte Controlador JDBC 3.x de Athena.
31 de octubre de 2023
Publicado el 31/10/2023
Amazon Athena anuncia reservas de 1 hora para la capacidad aprovisionada. A partir de hoy, puede reservar y liberar la capacidad aprovisionada después de una hora. Este cambio simplifica la optimización de los costes de las cargas de trabajo cuya demanda cambia con el tiempo.
La capacidad aprovisionada es una características de Athena que brinda funciones de administración de la carga de trabajo que lo ayudan a priorizar, controlar y escalar sus cargas de trabajo interactivas más importantes. Puede agregar capacidad en cualquier momento para aumentar la cantidad de consultas que ejecuta en simultáneo, controlar qué cargas de trabajo utilizan la capacidad y compartir la capacidad entre las cargas de trabajo.
Para obtener más información, consulte Administración de la capacidad de procesamiento de consultas. Para obtener información sobre los precios, consulte la página de Precios de Amazon Athena
25 de octubre de 2023
Publicado el 26/10/2023
Athena anuncia las siguientes correcciones y mejoras.
Paquete jackson-core: el texto JSON con un valor numérico superior a 1000 caracteres ahora fallará. Esta corrección soluciona el problema de seguridad sonatype-2022-6438
17 de octubre de 2023
Publicado el 17/10/2023
Athena anuncia el controlador ODBC versión 2.0.2.0. Para obtener más información, consulte las notas de la versión 2.0.2.0. Para descargar el nuevo controlador ODBC v2, consulte Descarga del controlador ODBC 2.x. Para obtener información sobre la conexión, consulte la ODBC 2.x de Amazon Athena.
26 de septiembre de 2023
Publicado el 26/09/2023
Athena anuncia las siguientes características y mejoras.
-
Soporte de lectura de Lake Formation para tablas de Delta Lake. Para obtener más información acerca del uso de tablas de Delta Lake con Athena, consulte Consulta de las tablas de Linux Foundation Delta Lake.
23 de agosto de 2023
Publicado el 23/08/2023
Amazon Athena anuncia la disponibilidad de Athena SQL en la región de Israel (Tel Aviv).
Para obtener una lista completa de los Servicios de AWS disponibles en cada Región de AWS, consulte Servicios de AWS por región
10 de agosto de 2023
Publicado el 10/08/2023
Athena anuncia las siguientes correcciones y mejoras.
Controlador ODBC versión 2.0.1.1
Athena anuncia el controlador ODBC versión 2.0.1.1. Para obtener más información, consulte las notas de la versión 2.0.1.1. Para descargar el nuevo controlador ODBC v2, consulte Descarga del controlador ODBC 2.x. Para obtener información sobre la conexión, consulte el ODBC 2.x de Amazon Athena.
Controlador JDBC versión 2.1.1
Athena lanza la versión 2.1.1 del controlador JDBC. El controlador resuelve los siguientes problemas:
-
Error que se producía al crear una tabla con una instrucción que contenía una expresión regular.
-
Problema que provocaba que el parámetro de conexión
ApplicationNamese aplicara de forma incorrecta.
Para descargar el nuevo controlador JDBC, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con JDBC.
31 de julio de 2023
Publicado el 31/07/2023
Amazon Athena anuncia la disponibilidad de Athena SQL en Regiones de AWS adicionales.
Esta versión amplía la disponibilidad de Athena SQL en las regiones de Asia-Pacífico (Hyderabad), Asia-Pacífico (Melbourne), Europa (España) y Europa (Zúrich).
Para obtener una lista completa de los Servicios de AWS disponibles en cada Región de AWS, consulte Servicios de AWS por región
27 de julio de 2023
Publicado el 27/07/2023
Athena lanza la versión 2023.30.1 del conector de Google BigQuery. Esta versión del conector reduce el tiempo de ejecución de las consultas y agrega soporte para realizar consultas en puntos de conexión privados de BigQuery.
Para obtener información sobre el conector de Google BigQuery, consulte Conector Google BigQuery de Amazon Athena. Para obtener información sobre la actualización de los conectores de orígenes de datos existentes, consulte Actualización de un conector de origen de datos.
24 de julio de 2023
Publicado el 24/07/2023
Athena anuncia las siguientes correcciones y mejoras.
-
Consultas con uniones: se ha mejorado el rendimiento de determinadas consultas con uniones.
-
Combinaciones con comparaciones de tipos: se ha corregido un posible error en la consulta de las instrucciones
JOINque incluían una comparación entre dos tipos diferentes. -
Subconsultas en columnas anidadas: se ha corregido un problema relacionado con los errores de consulta que se producían cuando las subconsultas se correlacionaban en columnas anidadas.
-
Vistas de Iceberg: se ha corregido un problema de compatibilidad con la precisión de las columnas de marcas de tiempo en las vistas de Apache Iceberg. Las vistas de Iceberg que contienen columnas de tipo marca de tiempo ahora son legibles, independientemente de si dichas columnas fueron creadas en versiones anteriores del motor o en la versión 3 del motor de Athena.
20 de julio de 2023
Publicado el 20/07/2023
Athena lanza la versión 2.1.0 del controlador JDBC. El controlador incluye mejoras nuevas y se ha resuelto un problema.
Mejoras
Se actualizaron las siguientes bibliotecas de analizadores JSON de Jackson
-
jackson-annotations 2.15.2 (anteriormente 2.14.0)
-
jackson-core 2.15.2 (anteriormente 2.14.0)
-
jackson-databind 2.15.2 (anteriormente 2.14.0)
Problemas resueltos
-
Se ha corregido un problema relacionado con la transmisión de parámetros de matriz cuando se utilizaba la biblioteca sql2o
.
Para obtener más información y descargar los nuevos controladores, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con JDBC.
13 de julio de 2023
Publicado el 19/09/2023
Athena anuncia las siguientes características y mejoras.
-
EXPLAIN ANALYZE: se agregó soporte para el tiempo de espera, análisis, planificación y ejecución al resultado de
EXPLAIN ANALYZE. -
EXPLAIN: el resultado de
EXPLAINahora muestra estadísticas cuando la consulta contiene agregaciones. -
Parquet Hive SerDe: se agregó la propiedad
parquet.ignore.statisticspara permitir ignorar las estadísticas de procesamiento al leer los datos de Parquet. Para obtener más información, consulta Omisión de las estadísticas de Parquet.
Para obtener más información sobre EXPLAIN y EXPLAIN ANALYZE, consulte Uso de EXPLAIN y EXPLAIN ANALYZE en Athena. Para obtener más información sobre Parquet Hive SerDe, consulte El SerDe de Parquet.
3 de julio de 2023
Publicado el 25/07/2023
El 3 de julio de 2023, Athena comenzó a redactar las cadenas de consulta de los registros de CloudTrail. Ahora, la cadena de consulta tiene el valor ***OMITTED***. Este cambio se ha realizado para evitar que se divulguen de forma involuntaria nombres de tablas o valores de filtro que puedan incluir información confidencial. Si anteriormente dependía de los registros de CloudTrail para acceder a las cadenas de consulta completas, le recomendamos que utilice la API Athena::GetQueryExecution y transfiera el valor responseElements.queryExecutionId del registro de CloudTrail. Para obtener más información, consulte la acción GetQueryExecution en la Referencia de la API de Amazon Athena.
30 de junio de 2023
Publicado el 30/06/2023
Ahora, el editor de consultas de Athena admite sugerencias de código de escritura anticipada para una experiencia de creación de consultas más rápida. Ahora puede escribir consultas de SQL con mayor precisión y eficiencia gracias a las siguientes características:
-
A medida que escribe, aparecen sugerencias en tiempo real para palabras clave, variables locales, fragmentos y elementos del catálogo.
-
Al escribir el nombre de una base de datos o de una tabla seguido de un punto, el editor muestra de forma oportuna una lista de tablas o columnas entre las que puede elegir.
-
Al pasar el ratón por encima de una sugerencia de fragmento, aparece una sinopsis que muestra un breve resumen de la sintaxis y del uso del fragmento.
-
Para mejorar la legibilidad del código, también se actualizaron las palabras clave y sus reglas de resaltado a fin de adaptarlas a la sintaxis más reciente de Trino y Hive.
Esta característica está habilitada de forma predeterminada. Puede habilitar o deshabilitar la característica mediante la configuración de las preferencias del editor de código.
Para probar las sugerencias de código de escritura anticipada en el editor de consultas de Athena, visite la consola de Athena en https://console.aws.amazon.com/athena/
29 de junio de 2023
Publicado el 29/06/2023
-
Athena anuncia el controlador ODBC versión 2.0.1.0. Para obtener más información, consulte las notas de la versión 2.0.1.0. Para descargar el nuevo controlador ODBC v2, consulte Descarga del controlador ODBC 2.x. Para obtener información sobre la conexión, consulte la ODBC 2.x de Amazon Athena.
-
Athena y sus características
ya se encuentran disponibles en la región de Medio Oriente (Emiratos Árabes Unidos). Para obtener una lista completa de los Servicios de AWS disponibles en cada Región de AWS, consulte Servicios de AWS por región .
28 de junio de 2023
Publicado el 28/06/2023
Ahora puede utilizar Amazon Athena para consultar objetos restaurados de las clases de almacenamiento de Amazon S3 S3 Glacier Flexible Retrieval (anteriormente Glacier) y S3 Glacier Deep Archive. Esta capacidad se configura por tabla. La característica solo se admite para las tablas de Apache Hive en la versión 3 del motor de Athena.
Para obtener más información, consulte Consulta de objetos de Amazon S3 Glacier restaurados.
12 de junio de 2023
Publicado el 12/06/2023
Athena anuncia las siguientes correcciones y mejoras.
-
Marcas de tiempo de Parquet Reader: se agregó soporte a fin de leer las marcas de tiempo en forma de
bigint(milisegundos) para Parquet Reader. Esta actualización garantiza paridad con la compatibilidad ofrecida en versiones anteriores del motor. -
EXPLAIN ANALYZE: se agregó el tiempo de lectura de la entrada física a las estadísticas de la consulta y al resultado de
EXPLAIN ANALYZE. Para obtener más información sobreEXPLAIN ANALYZE, consulte Uso de EXPLAIN y EXPLAIN ANALYZE en Athena. -
INSERT: se mejoró el rendimiento de las consultas en las tablas en las que se escribe con
INSERT. Para obtener más información sobreINSERT, consulte INSERT INTO. -
Tablas de Delta Lake: se corrigió un problema con
DROP TABLEen las tablas de Delta Lake que impedía que se eliminaran por completo cuando estaban sujetas a modificaciones simultáneas.
8 de junio de 2023
Publicado el 08/06/2023
Amazon Athena para Apache Spark anuncia las siguientes características nuevas.
-
Soporte para bibliotecas y configuraciones de Java personalizadas: ahora puede utilizar sus propios paquetes y configuraciones personalizadas de Java para sus sesiones de Apache Spark en Athena. Utilice las propiedades de Spark para especificar archivos
.jar, paquetes u otra configuración personalizada con la consola de Athena, la AWS CLI y la API de Athena. Para obtener más información, consulte Uso de las propiedades de Spark para especificar una configuración personalizada. -
Soporte para tablas de Apache Hudi, Apache Iceberg y Delta Lake: Athena para Spark ahora es compatible con los formatos de tablas de almacenamiento de lagos de datos de código abierto de Apache Iceberg, Apache Hudi y Linux Foundation Delta Lake. Para obtener más información, consulte Uso de formatos de tabla que no sean Hive en Athena para Spark y los temas individuales a fin de utilizar las tablas Uso de tablas de Apache Iceberg en Athena para Spark, Uso de tablas de Apache Hudi en Athena para Spark y Uso de las tablas de Delta Lake de Linux Foundation en Athena para Spark de Athena para Spark.
-
Soporte de cifrado para Apache Spark: en Athena para Spark, ahora puede habilitar el cifrado de los datos en tránsito entre los nodos de Spark y en los datos en reposo locales almacenados en el disco por Spark. Para habilitar el cifrado de Spark, puede usar la consola, la AWS CLI o la API de Athena. Para obtener más información, consulte Habilitación del cifrado de Apache Spark.
A fin de obtener más información sobre Amazon Athena para Apache Spark, consulte Uso de Apache Spark en Amazon Athena.
2 de junio de 2023
Publicado el 02/06/2023
Ahora puede eliminar las reservas de capacidad en Athena y utilizar plantillas de AWS CloudFormation para especificar las reservas de capacidad de Athena.
-
Eliminar reservas de capacidad: ahora puede eliminar las reservas de capacidad canceladas en Athena. Se debe cancelar una reserva antes de que esta pueda eliminarse. Al eliminar una reserva de capacidad, la reserva se elimina de su cuenta de inmediato. Ya no se puede hacer referencia a la reserva eliminada, ni siquiera mediante su ARN. Para eliminar una reserva, puede utilizar la consola o la API de Athena. Para obtener más información, consulte Eliminación de una reserva de capacidad en la Guía del usuario de Amazon Athena y DeleteCapacityReservation en la Referencia de la API de Amazon Athena.
-
Utilizar plantillas de AWS CloudFormation para reservas de capacidad: ahora puede utilizar plantillas de AWS CloudFormation para especificar las reservas de capacidad de Athena mediante el recurso
AWS::Athena::CapacityReservation. Para obtener más información, consulte AWS::Athena::CapacityReservation en la Guía del usuario de AWS CloudFormation.
Para obtener más información sobre el uso de las reservas de capacidad a fin de aprovisionar su capacidad en Athena, consulte Administración de la capacidad de procesamiento de consultas.
25 de mayo de 2023
Publicado el 25/05/2023
Athena ha publicado actualizaciones de conectores de orígenes de datos que mejoran el rendimiento de las consultas federadas. Las optimizaciones de inserción y el filtrado dinámico nuevos permiten realizar más operaciones en la base de datos de origen que en Athena. Estas optimizaciones reducen el tiempo de ejecución de las consultas y la cantidad de datos que se analizan. Estas mejoras requieren la versión 3 del motor de Athena.
Se actualizaron los siguientes conectores:
Para obtener información sobre la actualización de los conectores de orígenes de datos, consulte Actualización de un conector de origen de datos.
18 de mayo de 2023
Publicado el 18/05/2023
Ahora puede utilizar AWS PrivateLink para las conexiones entrantes de IPv6 a Amazon Athena.
Amazon Athena ha ampliado su compatibilidad con las conexiones entrantes a través de los puntos de conexión del Protocolo de Internet versión 6 (IPv6) para incluir AWS PrivateLink
El crecimiento rápido de Internet agota la disponibilidad de las direcciones del Protocolo de Internet de versión 4 (IPv4). El IPv6 multiplica varias veces el número de direcciones disponibles, por lo que ya no es necesario administrar los espacios de direcciones superpuestos en las VPC. Con esta versión, ahora puede combinar los beneficios del direccionamiento de IPv6 con las ventajas de seguridad y rendimiento de AWS PrivateLink.
Para conectarse mediante programación a un servicio de AWS, puede utilizar la AWS CLI
15 de mayo de 2023
Publicado el 15/05/2023
Athena anuncia el lanzamiento de los conectores de Apache Spark DataSourceV2 (DSV2) para DynamoDB, Registros de CloudWatch, Métricas de CloudWatch y CMDB de AWS. Utilice los conectores DSV2 nuevos para consultar estos orígenes de datos mediante Spark. Los conectores DSV2 utilizan los mismos parámetros que sus conectores federados de Athena correspondientes. Los conectores DSV2 se ejecutan directamente en los trabajos de Spark y no requieren que implemente una función de Lambda para utilizarlos.
Para obtener más información, consulte Uso de conectores de orígenes de datos de Athena para Apache Spark.
10 de mayo de 2023
Publicado el 10/05/2023
Se lanzó el controlador ODBC 1.1.20 para Athena.
Características y mejoras:
-
Soporte para la anulación de puntos de conexión de Lake Formation.
-
El complemento de autenticación de ADFS tiene un parámetro nuevo para configurar el valor de relación de confianza (
LoginToRP). -
Actualizaciones de la biblioteca de AWS.
Correcciones de errores:
-
Error de desasignación de la instrucción preparada cuando el método
SQLPrepare()no se podía enviar. -
Error al vincular los parámetros de una instrucción preparada al convertir un tipo C en un tipo de SQL.
-
Error de devolución de los datos cuando las consultas
EXPLAINyEXPLAIN ANALYZEutilizabanSQLPrepare()ySQLExecute().
Para obtener más información y descargar los nuevos controladores, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con ODBC.
8 de mayo de 2023
Publicado el 08/05/2023
Athena anuncia las siguientes correcciones y mejoras.
-
Integración de Hudi actualizada: Athena ha actualizado su integración con Apache Hudi. Ahora puede utilizar Athena para consultar las tablas de Hudi 0.12.2, y también se admite la lista de metadatos de Hudi para las tablas de Hudi. Para obtener más información, consulte Consulta de los conjuntos de datos de Apache Hudi y Uso de los metadatos de Hudi para mejorar el rendimiento.
-
Corrección de la conversión de marcas de tiempo: se ha corregido la gestión de las conversiones de marcas de tiempo a un tipo de datos de menor precisión. Anteriormente, la versión 3 del motor de Athena redondeaba de forma incorrecta el valor al tipo objetivo en lugar de truncarlo durante la conversión.
En los siguientes ejemplos se ilustra la gestión incorrecta antes de la corrección.
Ejemplo 1: conversión de una marca de tiempo en microsegundos a milisegundos
Datos de ejemplo
A, 2020-06-10 15:55:23.383 B, 2020-06-10 15:55:23.382 C, 2020-06-10 15:55:23.383345 D, 2020-06-10 15:55:23.383945 E, 2020-06-10 15:55:23.383345734 F, 2020-06-10 15:55:23.383945278La siguiente consulta intenta recuperar las marcas de tiempo que coinciden con un valor específico.
SELECT * FROM table WHERE timestamps.col = timestamp'2020-06-10 15:55:23.383'La consulta arrojó los siguientes resultados.
A, 2020-06-10 15:55:23.383 C, 2020-06-10 15:55:23.383 E, 2020-06-10 15:55:23.383Antes de la corrección, Athena no incluía los valores
2020-06-10 15:55:23.383945o2020-06-10 15:55:23.383945278porque se redondeaban a2020-06-10 15:55:23.384.Ejemplo 2: conversión de una marca de tiempo a una fecha
La siguiente consulta arrojó un resultado erróneo.
SELECT date(timestamp '2020-12-31 23:59:59.999')Resultado
2021-01-01Antes de la corrección, Athena redondeaba el valor para arriba, por lo tanto, adelantaba el día. Estos valores ahora se truncan en lugar de redondearse para arriba.
28 de abril de 2023
Publicado el 28/04/2023
Ahora puede utilizar las reservas de capacidad en Amazon Athena para ejecutar consultas SQL en una capacidad de procesamiento totalmente administrada.
La capacidad aprovisionada brinda funciones de administración de la carga de trabajo que lo ayudan a priorizar, controlar y escalar sus cargas de trabajo interactivas más importantes. Puede agregar capacidad en cualquier momento para aumentar la cantidad de consultas que ejecuta en simultáneo, controlar qué cargas de trabajo utilizan la capacidad y compartir la capacidad entre las cargas de trabajo.
Para obtener más información, consulte Administración de la capacidad de procesamiento de consultas. Para obtener información sobre los precios, consulte la página de Precios de Amazon Athena
17 de abril de 2023
Publicado el 17/04/2023
Athena lanza la versión 2.0.36 del controlador JDBC. El controlador incluye características nuevas y se ha resuelto un problema.
Nuevas características
-
Ahora puede utilizar identificadores de relación de confianza personalizables con la autenticación de AD FS.
-
Ahora puede agregar el nombre de la aplicación que utiliza el conector a la cadena del agente de usuario.
Problemas resueltos
-
Se ha corregido un error que se producía cuando se utilizaba
getSchema()para recuperar un esquema inexistente.
Para obtener más información y descargar los nuevos controladores, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con JDBC.
14 de abril de 2023
Publicado el 20/06/2023
Athena anuncia las siguientes correcciones y mejoras.
-
Al convertir una cadena en una marca de tiempo, se requiere un espacio entre el día y la hora o la zona horaria. Para obtener más información, consulte Se requiere espacio entre los valores de fecha y hora al convertir una cadena en una marca de tiempo.
-
Se ha eliminado un cambio sustancial en la forma en que se gestionaba la precisión de la marca de tiempo. Para mantener la coherencia entre las versiones anteriores del motor y la versión 3 del motor de Athena, la precisión de las marcas de tiempo ahora se establece de forma predeterminada en milisegundos en lugar de microsegundos.
-
Ahora, Athena impone de forma coherente el acceso al bucket de resultados de consultas cuando ejecuta consultas. Asegúrese de que todas las entidades principales de IAM que ejecutan la acción StartQueryExecution tengan el permiso S3:GetBucketLocation en el bucket de resultados de consultas.
4 de abril de 2023
Publicado el 04/04/2023
Ahora puede utilizar Amazon Athena para crear y consultar vistas en los orígenes de datos federados. Utilice una vista federada única para consultar varias tablas o subconjuntos de datos externos. Esto simplifica el SQL necesario y le brinda la flexibilidad de ocultar los orígenes de datos de los usuarios finales que deben utilizar SQL para consultar los datos.
Para obtener más información, consulte Trabajo con vistas y Ejecución de consultas federadas.
30 de marzo de 2023
Publicado el 30/03/2023
Amazon Athena anuncia la disponibilidad de Amazon Athena para Apache Spark en Regiones de AWS adicionales.
Esta versión amplía la disponibilidad de Amazon Athena para Apache Spark en las regiones de Asia-Pacífico (Bombay), Asia-Pacífico (Singapur), Asia-Pacífico (Sídney) y Europa (Fráncfort).
A fin de obtener más información sobre Amazon Athena para Apache Spark, consulte Uso de Apache Spark en Amazon Athena.
28 de marzo de 2023
Publicado el 28/03/2023
Athena anuncia las siguientes correcciones y mejoras.
-
En las respuestas a las acciones de la API de Athena
GetQueryExecutionyBatchGetQueryExecution, el camposubStatementTypenuevo muestra el tipo de consulta que se ejecutó (por ejemplo,SELECT,INSERT,UNLOAD,CREATE_TABLEoCREATE_TABLE_AS_SELECT). -
Se ha corregido un error que provocaba que los archivos de manifiesto no se cifraran de forma correcta para las operaciones de escritura de Apache Hive.
-
La versión 3 del motor de Athena ahora gestiona los valores
NaNyInfinityde forma correcta en la funciónapprox_percentile. La funciónapprox_percentiledevuelve el percentil aproximado de un conjunto de datos en el porcentaje indicado.La versión 2 del motor de Athena trata de forma incorrecta
NaNcomo un valor superior aInfinity. La versión 3 del motor de Athena ahora gestionaNaNyInfinityde acuerdo con el tratamiento de estos valores en otras funciones analíticas y estadísticas. En los siguientes puntos se describe el comportamiento nuevo con mayor detalle.-
Si
NaNse encuentra presente en el conjunto de datos, Athena devuelveNaN. -
Si
NaNno se encuentra presente, peroInfinitysí lo está, Athena trata aInfinitycomo un número muy grande. -
Si hay varios valores
Infinity, Athena los trata como un mismo número muy grande. Si es necesario, Athena produceInfinity. -
Si un único conjunto de datos tiene ambos (
Infinityy-Double.MAX_VALUE) y el resultado percentil es-Double.MAX_VALUE, Athena devuelve-Infinity. -
Si un único conjunto de datos tiene
InfinityyDouble.MAX_VALUE, y el resultado percentil esDouble.MAX_VALUE, Athena devuelveInfinity. -
Para excluir
InfinityyNaNde un cálculo, utilice la funciónis_finite(), como en el siguiente ejemplo.approx_percentile(x, 0.5) FILTER (WHERE is_finite(x))
-
27 de marzo de 2023
Publicado el 27/03/2023
Ahora puede especificar un nivel mínimo de cifrado para los grupos de trabajo de Athena SQL en Amazon Athena. Esta característica garantiza que los resultados de todas las consultas del grupo de trabajo de Athena SQL se encuentren cifrados al nivel de cifrado que especifique o supere. Puede elegir entre varios niveles de seguridad de cifrado para proteger los datos. Para configurar el nivel mínimo de cifrado que desee, puede utilizar la consola, la AWS CLI, la API o el SDK de Athena.
La característica de cifrado mínimo no se encuentra disponible para los grupos de trabajo habilitados para Apache Spark. Para obtener más información, consulte Configuración del cifrado mínimo para un grupo de trabajo.
17 de marzo de 2023
Publicado el 17/03/2023
Athena anuncia las siguientes correcciones y mejoras.
-
Se ha corregido un problema con el conector DynamoDB de Amazon Athena que provocaba que las consultas fallaran con el mensaje de error
KeyConditionExpressions solo debe contener una condición por clave.Este problema se produce porque la versión 3 del motor de Athena reconoce la oportunidad de introducir más tipos de predicados que la versión 2 del motor de Athena. En la versión 3 del motor de Athena, cláusulas como
some_column LIKE 'someprefix%se introducen como predicados de filtro que aplican un límite inferior y superior a una columna determinada. La versión 2 del motor de Athena no introducía estos predicados. En la versión 3 del motor de Athena, cuandosome_columnes una columna de clave de clasificación, el motor inserta el predicado de filtro en el conector DynamoDB. Luego, el predicado de filtro se inserta más en el servicio de DynamoDB. Debido a que DynamoDB no admite más de una condición de filtro en una clave de clasificación, DynamoDB devuelve el error.Para corregir este problema, actualice su conector DynamoDB de Amazon Athena a la versión 2023.11.1. Para obtener instrucciones sobre cómo actualizar el conector, consulte Actualización de un conector de origen de datos.
8 de marzo de 2023
Publicado el 08/03/2023
Athena anuncia las siguientes correcciones y mejoras.
-
Se ha corregido un problema con las consultas federadas que provocaba que los valores de los predicados de marca de tiempo se enviaran en microsegundos en lugar de milisegundos.
15 de febrero de 2023
Publicado el 15/02/2023
Athena anuncia las siguientes correcciones y mejoras.
-
Ahora puede utilizar el cifrado del cliente a fin de cifrar los datos en Amazon S3 para las operaciones de escritura de Iceberg.
-
Se ha corregido un problema que afectaba al cifrado del servidor en Amazon S3 para las operaciones de escritura de Iceberg.
31 de enero de 2023
Publicado el 31/01/2023
Ahora puede utilizar Amazon Athena para consultar datos en Google Cloud Storage. Al igual que Amazon S3, Google Cloud Storage es un servicio administrado que almacena los datos en buckets. Utilice el conector de Athena para Google Cloud Storage para ejecutar consultas federadas interactivas en datos externos.
Para obtener más información, consulte Conector de Google Cloud Storage para Amazon Athena.
20 de enero de 2023
Publicado el 20/01/2023
Ahora puede ver documentación ampliada sobre la compatibilidad de compresión de Athena. Se añadieron temas individuales para Compresión de tablas de Hive, Compresión de tablas de Iceberg y Niveles de compresión ZSTD.
Para obtener más información, consulte Uso de la compresión en Athena.
3 de enero de 2023
Publicado el 03/01/2023
Athena anuncia las siguientes actualizaciones:
-
Comandos adicionales para los metaalmacenes de Hive: puede utilizar Athena para conectarse a su almacén autoadministrado de Apache Hive como catálogo de metadatos y consultar los datos almacenados en Amazon S3. Con esta versión, puede usar
CREATE TABLE AS(CTAS),INSERT INTOy 12 comandos adicionales de lenguaje de definición de datos (DDL) para interactuar con el metaalmacén de Apache Hive. Puede administrar sus esquemas de metaalmacén de Hive directamente desde Athena mediante este conjunto ampliado de capacidades SQL.Para obtener más información, consulte Uso de un metastore de Hive externo.
-
Controlador JDBC versión 2.0.35: Athena lanza el controlador JDBC versión 2.0.35. El controlador JDBC 2.0.35 contiene las siguientes actualizaciones:
-
El controlador ahora usa las siguientes bibliotecas para el analizador JSON de Jackson.
-
jackson-annotations 2.14.0 (anteriormente 2.13.2)
-
jackson-core 2.14.0 (anteriormente 2.13.2)
-
jackson-databind 2.14.0 (anteriormente 2.13.2.2)
-
-
Se ha interrumpido el soporte para la versión 4.1 de JDBC.
Para obtener más información y descargar el nuevo controlador, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con JDBC.
-
Notas de la versión de Athena para 2022
14 de diciembre de 2022
Publicado el 14/12/2022
Ahora puede utilizar el conector de Amazon Athena para que Kafka ejecute consultas SQL en datos de transmisión. Por ejemplo, puede ejecutar consultas analíticas sobre datos de transmisión en tiempo real en Amazon Managed Streaming para Apache Kafka (Amazon MSK) y unirlos a los datos históricos de su lago de datos de Amazon S3.
El conector de Amazon Athena para Kafka admite consultas en varios motores de transmisión. Puede utilizar Athena para ejecutar consultas SQL en clústeres aprovisionados y sin servidor de Amazon MSK, en implementaciones de Kafka autoadministrado y en datos de transmisión en Confluent Cloud.
Para obtener más información, consulte Conector para MSK de Amazon Athena.
2 de diciembre de 2022
Publicado el 02/12/2022
Athena lanza la versión 2.0.34 del controlador JDBC. El controlador JDBC 2.0.34 incluye las siguientes características y problemas resueltos:
-
Reutilización de resultados de consultas: ahora puede reutilizar los resultados de consultas ejecutadas anteriormente hasta un límite de tiempo especificado, en lugar de que Athena vuelva a calcular los resultados cada vez que se ejecuta la consulta. Para obtener más información, consulte la guía de instalación y configuración, disponible en la página de descargas de JDBC y Reutilización de resultados de las consultas en Athena.
-
Compatibilidad con Ec2InstanceMetadata: el controlador JDBC ahora es compatible con el método de autenticación Ec2InstanceMetadata mediante perfiles de instancia de IAM.
-
Corrección de excepciones basadas en caracteres: se ha corregido una excepción que se producía con consultas que contenían determinados caracteres de idioma.
-
Corrección de vulnerabilidad: se corrigió una vulnerabilidad relacionada con las dependencias de AWS empaquetadas con el conector.
Para obtener más información y descargar los nuevos controladores, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con JDBC.
30 de noviembre de 2022
Publicado el 30/11/2022
Ahora puede crear y ejecutar aplicaciones de Apache Spark y cuadernos compatibles con Jupyter de forma interactiva en Athena. Ejecute análisis de datos en Athena con Spark sin tener que planificar, configurar ni administrar los recursos. Envíe el código Spark para su procesamiento y reciba los resultados directamente. Utilice la experiencia simplificada de cuadernos de la consola de Amazon Athena para desarrollar aplicaciones de Apache Spark mediante Python o Uso de las API de cuadernos de Athena.
Apache Spark en Amazon Athena no requiere servidor y proporciona un escalado automático y bajo demanda que ofrece computación instantánea para cumplir con los cambios en los volúmenes de datos y los requisitos de procesamiento.
Para obtener más información, consulte Uso de Apache Spark en Amazon Athena.
18 de noviembre de 2022
Publicado el 18/11/2022
Ahora puede utilizar el conector de Amazon Athena para IBM Db2 para realizar consultas de Db2 desde Athena. Por ejemplo, puede ejecutar consultas analíticas a través de un almacenamiento de datos en Db2 y un lago de datos en Amazon S3.
El conector para Db2 de Amazon Athena expone varias opciones de configuración a través de variables de entorno de Lambda. Para obtener información sobre las opciones de configuración, los parámetros, las cadenas de conexión, la implementación y las limitaciones, consulte Conector para IBM Db2 de Amazon Athena.
17 de noviembre de 2022
Publicado el 17/11/2022
La compatibilidad de Apache Iceberg en la versión 3 del motor de Athena ofrece ahora las siguientes características mejoradas de transacciones ACID:
-
Compatibilidad con ORC y Avro: cree tablas de Iceberg con los formatos de archivo basados en filas y columnas de Apache Avro
y Apache ORC . La compatibilidad con estos formatos se suma a la compatibilidad existente con Parquet. -
MERGE INTO: utilice el comando
MERGE INTOpara combinar datos a escala de manera eficiente.MERGE INTOcombina las operacionesINSERT,UPDATEyDELETEen una sola transacción. Esto reduce la sobrecarga de procesamiento en su canalización de datos y requiere menos SQL para escribir. Para obtener más información, consulte Actualización de los datos de las tablas de Iceberg y MERGE INTO. -
Compatibilidad con CTAS y VIEW: utilice
CREATE TABLE AS SELECT(CTAS) y las instruccionesCREATE VIEWcon tablas de Iceberg. Para obtener más información, consulte CREATE TABLE AS y CREATE VIEW y CREATE PROTECTED MULTI DIALECT VIEW. -
Compatibilidad con VACUUM: puede utilizar la instrucción
VACUUMpara optimizar su lago de datos al eliminar las instantáneas y los datos que ya no sean necesarios. Puede utilizar esta característica para mejorar el rendimiento de la lectura y cumplir con los requisitos reglamentarios, como el RGPD. Para obtener más información, consulte Optimización de las tablas de Iceberg y VACUUM.
Estas nuevas características requieren la versión 3 del motor de Athena y están disponibles en todas las regiones en las que se admite Athena. Puede utilizarlos con la consola de Athena
Para obtener información acerca del uso de Iceberg en Athena, consulte Consulta de tablas de Apache Iceberg.
14 de noviembre de 2022
Publicado el 14/11/2022
Amazon Athena ahora admite puntos de conexión IPv6 para las conexiones entrantes que puede utilizar para invocar funciones de Athena a través de IPv6. Puede utilizar esta característica para cumplir con los requisitos de cumplimiento de IPv6. También elimina la necesidad de equipos de red adicionales para gestionar la traducción de direcciones entre IPv4 e IPv6.
Para utilizar esta característica, configure sus aplicaciones para que utilicen los nuevos puntos de conexión de doble pila de Athena, que admiten IPv4 e IPv6. Los puntos de conexión de doble pila utilizan el formato athena.. Por ejemplo, el punto de conexión de doble pila en la región Este de EE. UU. (Norte de Virginia) es region.api.awsathena.us-east-1.api.aws.
Cuando realiza una solicitud a un punto de conexión de doble pila de Athena, el punto de conexión resuelve a una dirección IPv6 o IPv4, según el protocolo que utilicen la red y el cliente. Para conectarse mediante programación a un servicio de AWS, puede utilizar la AWS CLI
Para obtener más información sobre los puntos de conexión de servicios, consulte Puntos de conexión de servicios de AWS. Para obtener más información sobre los puntos de conexión del servicio de Athena, consulte Puntos de conexión y cuotas de Amazon Athena en la documentación de AWS.
Puede utilizar los nuevos puntos de conexión de doble pila de Athena para las conexiones entrantes sin costo adicional. Los puntos de conexión de doble pila suelen estar disponibles en todas las Regiones de AWS.
11 de noviembre de 2022
Publicado el 11/11/2022
Athena anuncia las siguientes correcciones y mejoras.
-
Control de acceso detallado ampliado de Lake Formation: ahora puede utilizar políticas de control de acceso detallado de AWS Lake Formation
en las consultas de Athena para los datos almacenados en cualquier formato de archivo o tabla compatible. Puede utilizar un control de acceso detallado en Lake Formation para restringir el acceso a los datos de los resultados de las consultas mediante filtros de datos para lograr una seguridad de nivel de columna, fila y celda. Los formatos de tabla admitidos en Athena incluyen Apache Iceberg, Apache Hudi y Apache Hive. El control de acceso detallado ampliado está disponible en todas las regiones compatibles con Athena. La compatibilidad ampliada con formatos de tablas y archivos requiere la Versión 3 del motor Athena, que ofrece nuevas características y un mejor rendimiento de las consultas , pero no cambia la forma en que se configuran políticas de control de acceso detallado en Lake Formation. El uso de este control de acceso detallado ampliado en Athena tiene las siguientes consideraciones:
-
EXPLAIN: la información de filtrado de filas o celdas definida en Lake Formation y la información de estadísticas de consultas no se muestra en la salida de
EXPLAINniEXPLAIN ANALYZE. Para obtener información acerca deEXPLAINpara Athena, consulte Uso de EXPLAIN y EXPLAIN ANALYZE en Athena. -
Metaalmacenes de Hive externos: las columnas ocultas de Apache Hive no se pueden utilizar para filtrar el control de acceso con precisión, y el control de acceso detallado no admite las tablas ocultas del sistema de Apache Hive. Para obtener más información, consulte Consideraciones y limitaciones en el tema Uso de un metastore de Hive externo.
-
Estadísticas de consultas: la información sobre el recuento de filas y el tamaño de los datos de entrada y salida de nivel de etapa no se muestra en las estadísticas de consulta de Athena cuando una consulta tiene filtros de nivel de fila definidos en Lake Formation. Para obtener información sobre cómo ver las estadísticas de las consultas de Athena, consulte Visualización de estadísticas y detalles de ejecución de consultas completadas y GetQueryRuntimeStatistics.
-
Grupos de trabajo: los usuarios del mismo grupo de trabajo de Athena pueden ver los datos que el control de acceso detallado de Lake Formation ha configurado para que el grupo de trabajo pueda acceder a ellos. Para obtener información sobre el uso de Athena para consultar datos registrados en Lake Formation, consulte Uso de Athena para consultar datos registrados en AWS Lake Formation.
Para obtener información sobre el uso del control de acceso detallado en Lake Formation, consulte Manage fine-grained access control using AWS Lake Formation
en el Blog de macrodatos de AWS. -
-
Consulta federada de Athena: ahora la consulta federada de Athena conserva el formato original de los nombres de campo de los objetos
struct. Anteriormente, los nombres de los camposstructse convertían automáticamente en minúsculas.
8 de noviembre de 2022
Publicado el 08/11/2022
Ahora puede utilizar la característica de almacenamiento en caché para reutilizar los resultados de las consultas a fin de acelerar las consultas repetidas en Athena. Una consulta repetida es una consulta SQL idéntica a una enviada recientemente que produce los mismos resultados. Cuando sea necesario ejecutar varias consultas idénticas, el almacenamiento en caché para reutilizar los resultados puede disminuir el tiempo necesario para producir resultados. El almacenamiento en caché para reutilizar los resultados también reduce los costos al reducir la cantidad de bytes escaneados.
Para obtener más información, consulte Reutilización de resultados de las consultas en Athena.
13 de octubre de 2022
Publicado el 13/10/2022
Athena anuncia la versión 3 del motor Athena.
Athena ha actualizado su motor de consultas SQL para incluir las características más recientes del proyecto de código abierto Trino
Para obtener más información, consulte Versión 3 del motor Athena.
10 de octubre de 2022
Publicado el 10/10/2022
Athena lanza la versión 2.0.33 del controlador JDBC. El controlador JDBC 2.0.33 incluye los siguientes cambios:
-
Se agregaron las propiedades de la nueva versión del controlador, la versión de JDBC y el nombre del complemento a la cadena de agente de usuario de la clase de proveedor de credenciales.
-
Se corrigieron los mensajes de error y se agregó la información necesaria.
-
Ahora se cancela la asignación de las instrucciones preparadas si la conexión se cierra o si se produce un error en la ejecución de la instrucción que prepara Athena.
Para obtener más información y descargar los nuevos controladores, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con JDBC.
23 de septiembre de 2022
Publicado el 26/09/2022
El conector de Amazon Athena para Neptune ahora admite la coincidencia sin distinción entre mayúsculas y minúsculas en los nombres de columnas y tablas.
-
El conector de orígenes de datos de Neptune puede resolver los nombres de las columnas en las tablas de Neptune que hacen distinción entre mayúsculas y minúscula, incluso si todos los nombres de las columnas aparecen en minúsculas en la tabla de AWS Glue. Para habilitar este comportamiento, establezca la variable de entorno
enable_caseinsensitivematchcomotrueen la función de Lambda del conector para Neptune. -
Dado que AWS Glue solo admite nombres de tablas en minúsculas, al crear una tabla de AWS Glue para Neptune, especifique el parámetro de tabla de AWS Glue
"glabel" =.table_name
Para obtener más información sobre el conector para Neptune, consulte Conector para Neptune de Amazon Athena.
13 de septiembre de 2022
Publicado el 13/09/2022
Athena anuncia las siguientes correcciones y mejoras.
-
Almacén de metadatos de Hive externo: Athena ahora devuelve el valor
NULLen lugar de una excepción cuando una cláusulaWHEREincluye una partición que no existe en un almacén de metadatos de Hive (EHMS). El nuevo comportamiento coincide con el de AWS Glue Data Catalog. -
Consultas parametrizadas: ahora se pueden enviar los valores de consultas parametrizadas al tipo de datos
DOUBLE. -
Apache Iceberg: las operaciones de escritura en tablas de Iceberg ahora se llevan a cabo correctamente cuando el bloqueo de objetos está activado en un bucket de Amazon S3.
31 de agosto de 2022
Publicado el 31/08/2022
Amazon Athena anuncia la disponibilidad de Athena y sus características
Esta versión amplía la disponibilidad de Athena en la región Asia-Pacífico e incluye Asia-Pacífico (Hong Kong), Asia-Pacífico (Yakarta), Asia-Pacífico (Bombay), Asia-Pacífico (Osaka), Asia-Pacífico (Seúl), Asia-Pacífico (Singapur), Asia-Pacífico (Sídney) y Asia-Pacífico (Tokio). Para obtener una lista completa de Servicios de AWS disponibles en estas y otras regiones, consulte la Lista de servicios por Región de AWS
23 de agosto de 2022
Publicado el 23/08/2022
La versión v2022.32.1
-
Se ha agregado compatibilidad con el conector de orígenes de datos Oracle de Amazon Athena para conexiones basadas en SSL a instancias de Amazon RDS. La compatibilidad se limita al protocolo de seguridad de la capa de transporte (TLS) y a la autenticación del servidor por parte del cliente. Dado que la autenticación mutua no se admite en Amazon RDS, la actualización no incluye la compatibilidad con la autenticación mutua.
Para obtener más información, consulte Conector Oracle de Amazon Athena.
3 de agosto de 2022
Publicado el 03/08/2022
Athena lanza el controlador JDBC versión 2.0.32. El controlador JDBC 2.0.32 incluye los siguientes cambios:
-
La cadena
User-Agentenviada al SDK de Athena se ha ampliado para incluir la versión del controlador, la versión de la especificación JDBC y el nombre del complemento de autenticación. -
Se solucionó una
NullPointerExceptionarrojada cuando no se proporcionó ningún valor para el parámetroCheckNonProxyHost. -
Se solucionó un problema con el análisis
login_urlen el complemento de autenticación BrowserSaml. -
Se solucionó un problema de host proxy que se produjo cuando el parámetro
UseProxyforIdpse estableció entrue.
Para obtener más información y descargar los nuevos controladores, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con JDBC.
1 de agosto de 2022
Publicado el 01/08/2022
Athena anuncia mejoras en el SDK de Athena Query Federation y en los conectores de origen de datos prediseñados de Athena. Las mejoras incluyen lo siguiente:
-
Análisis de estructuras: se ha corregido el problema de análisis
GlueFieldLexeren el SDK de Athena Query Federation que impedía que ciertas estructuras complicadas mostraran todos sus datos. Este problema afectó a los conectores creados en el SDK de Athena Query Federation. -
Tablas de AWS Glue: se ha agregado compatibilidad con los tipos de columna
setydecimalen las tablas de AWS Glue. -
Conector de DynamoDB: se agregó la posibilidad de ignorar las mayúsculas en los nombres de atributos de DynamoDB. Para obtener más información, consulte
disable_projection_and_casingen la sección Parámetros de la página Conector para DynamoDB de Amazon Athena.
Para obtener más información, consulte Versión v2022.30.2 de Athena Query Federation
21 de julio de 2022
Publicado el 21/07/2022
Ahora puede analizar y depurar sus consultas mediante métricas de rendimiento y herramientas de análisis de consultas visuales e interactivas en la consola de Athena. Los datos de rendimiento de la consulta y los detalles de ejecución pueden ayudarlo a identificar los cuellos de botella en las consultas, inspeccionar los operadores y las estadísticas de cada etapa de una consulta, rastrear el volumen de datos que fluyen entre las etapas y validar el impacto de los predicados de consulta. Ahora puede hacer lo siguiente:
-
Acceda al plan de ejecución distribuido y lógico de su consulta con un solo clic.
-
Explore las operaciones en cada etapa antes de que se ejecute la etapa.
-
Visualice el rendimiento de las consultas completadas con métricas del tiempo empleado en las etapas de colocación en cola, planificación y ejecución.
-
Obtenga información sobre el número de filas y la cantidad de datos de origen procesados y generados por la consulta.
-
Consulte detalles pormenorizados de la ejecución de sus consultas presentadas en contexto y en formato de gráfico interactivo.
-
Utilice detalles de ejecución precisos a nivel de etapa para comprender el flujo de datos a través de la consulta.
-
Analice los datos de rendimiento de las consultas de manera programada mediante API nuevas para obtener estadísticas de tiempo de ejecución, una característica que también se lanzó hoy.
Para obtener información sobre cómo utilizar estas funciones en sus consultas, vea el videotutorial Optimize Amazon Athena Queries with New Query Analysis Tools
Para obtener la documentación, consulte Visualización de planes de ejecución para consultas SQL y Visualización de estadísticas y detalles de ejecución de consultas completadas.
11 de julio de 2022
Publicado el 11/07/2022
Ahora puede ejecutar consultas parametrizadas directamente desde la consola o API de Athena sin preparar instrucciones SQL con anterioridad.
Ahora, cuando ejecute consultas en la consola de Athena que tienen parámetros en forma de signos de interrogación, la interfaz de usuario le pedirá que ingrese valores para los parámetros directamente. Esto elimina la necesidad de modificar los valores literales en el editor de consultas cada vez que quiera ejecutar la consulta.
Si usa la API mejorada query execution, ahora puede proporcionar los parámetros de ejecución y sus valores en una sola llamada.
Para obtener más información, consulte Uso de consultas parametrizadas en esta guía del usuario y la publicación del Blog de macrodatos de AWS Utilizar consultas parametrizadas de Amazon Athena para proporcionar datos como servicio
8 de julio de 2022
Publicado el 08/07/2022
Athena anuncia las siguientes correcciones y mejoras.
-
Se solucionó un problema con la gestión de la conversión de columnas
DATEpara los puntos de conexión de SageMaker IA (UDF) que provocaba errores en las consultas.
6 de junio de 2022
Publicado el 06/06/2022
Athena lanza el controlador JDBC versión 2.0.31. El controlador JDBC 2.0.31 incluye los siguientes cambios:
-
Problema de dependencia log4j: se ha resuelto el mensaje de error
No se puede encontrar clase de controladorcausado por una dependencia log4j.
Para obtener más información y descargar los nuevos controladores, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con JDBC.
25 de mayo de 2022
Publicado el 25/05/2022
Athena anuncia las siguientes correcciones y mejoras.
-
Soporte Iceberg
-
Se introdujo compatibilidad para consultas entre regiones. Ahora puede consultar las tablas de Iceberg en una Región de AWS diferente de la Región de AWS que está usando. No se admiten las consultas entre regiones en las regiones de China.
-
Se introdujo compatibilidad con la configuración de cifrado del lado del servidor. Ahora puede utilizar SSE-S3/SSE-KMS para cifrar los datos de las operaciones de escritura de Iceberg en Amazon S3.
Para obtener información acerca del uso de Apache Iceberg en Athena, consulte Consulta de tablas de Apache Iceberg.
-
-
Versión del controlador JDBC 2.0.30
El controlador JDBC 2.0.30 para Athena presenta las siguientes mejoras:
-
Soluciona un problema de carrera de datos que afectaba a las instrucciones preparadas parametrizadas.
-
Soluciona un problema de inicio de aplicaciones que se produjo en entornos de compilación de Gradle.
Para descargar el controlador JDBC 2.0.30, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con JDBC.
-
6 de mayo de 2022
Publicado el 06/05/2022
Se publicaron los controladores JDBC 2.0.29 y ODBC 1.1.17 para Athena.
Estos controladores incluyen los siguientes cambios:
-
Se ha actualizado el proceso de lanzamiento del navegador del complemento SAML.
Para obtener más información sobre estos cambios y, a fin de descargar los nuevos controladores, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con JDBC y Conexión a Amazon Athena con ODBC.
22 de abril de 2022
Publicado el 22/04/2022
Athena anuncia las siguientes correcciones y mejoras.
-
Se ha solucionado un problema en la sección de índices de partición y característica de filtrado
con la caché de particiones que se produjo cuando se cumplieron las siguientes condiciones: -
La clave
partition_filtering.enabledse estableció comotrueen las propiedades AWS Glue de tabla de una tabla. -
La misma tabla se utilizó varias veces con distintos valores de filtro de partición.
-
21 de abril de 2022
Publicado el 21/04/2022
Ahora puede utilizar Amazon Athena para ejecutar consultas federadas en orígenes de datos nuevos, incluidos Google BigQuery, Azure Synapse y Snowflake. Los nuevos conectores de orígenes de datos incluyen lo siguiente:
Para obtener una lista completa de los orígenes de datos admitidos por Athena, consulte Conectores de orígenes de datos disponibles.
Para facilitar la navegación por los orígenes disponibles y conectarse a los datos, ahora puede buscar, clasificar y filtrar los conectores disponibles desde una pantalla actualizada de Orígenes de datos en la consola de Athena.
Para obtener más información sobre las consultas de orígenes federados, consulte Uso de consulta federada de Amazon Athena y Ejecución de consultas federadas.
13 de abril de 2022
Publicado el 13/04/2022
Athena lanza el controlador JDBC versión 2.0.28. El controlador JDBC 2.0.28 incluye los siguientes cambios:
-
Soporte JWT: ahora es compatible con tokens web de JSON (JWT) para la autenticación. Para obtener información sobre la utilización de JWT con el controlador JDBC, consulte la guía de instalación y configuración, que se puede descargar desde la página del controlador JDBC.
-
Bibliotecas Log4j actualizadas: el controlador JDBC utiliza ahora las siguientes bibliotecas Log4j:
-
Log4j-api 2.17.1 (antes 2.17.0)
-
Log4j-core 2.17.1 (antes 2.17.0)
-
Log4J-jcl 2.17.2
-
-
Otras mejoras: el nuevo controlador también incluye las siguientes mejoras y correcciones de errores:
-
La característica de instrucciones preparadas por Athena ya está disponible a través de JDBC. Para obtener más información sobre las instrucciones preparadas, consulte Uso de consultas parametrizadas.
-
La federación SAML de Athena JDBC ahora funciona para las regiones de China.
-
Mejoras adicionales menores.
-
Para obtener más información y descargar los nuevos controladores, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con JDBC.
30 de marzo de 2022
Publicado el 30/03/2022
Athena anuncia las siguientes correcciones y mejoras.
-
Consultas entre regiones: ahora puede utilizar Athena para consultar datos ubicados en un bucket de Amazon S3 en Regiones de AWS incluidos Asia-Pacífico (Hong Kong), Medio Oriente (Baréin), África (Ciudad del Cabo) y Europa (Milán). No se admiten las consultas entre regiones en las regiones de China.
-
Para obtener una lista de Regiones de AWS en la que Athena está disponible, consulte Cuotas y puntos de conexión de Amazon Athena.
-
Para obtener más información acerca de cómo habilitar una Región de AWS que está deshabilitada de forma predeterminada, consulte Activación de una región.
-
Para obtener información sobre las consultas en todas las regiones, consulte Consultas entre regiones.
-
18 de marzo de 2022
Publicado el 18/03/2022
Athena anuncia las siguientes correcciones y mejoras.
-
Filtrado dinámico: se mejoró el filtrado dinámico para columnas enteras aplicando eficazmente el filtro a cada registro de una tabla correspondiente.
-
Iceberg: se ha corregido un error que provocaba errores al escribir archivos Iceberg Parquet de más de 2 GB.
-
Salida sin comprimir: las declaraciones CREATE TABLE ahora admiten la escritura de archivos sin comprimir. Para escribir archivos sin comprimir, utilice la siguiente sintaxis:
-
CREATE TABLE (archivo de texto o JSON): en
TBLPROPERTIES, especifiquewrite.compression = NONE. -
CREATE TABLE (Parquet): en
TBLPROPERTIES, especifiqueparquet.compression = UNCOMPRESSED. -
CREATE TABLE (ORC): en
TBLPROPERTIES, especifiqueorc.compress = NONE.
-
-
Compresión: se corrigió un problema con las inserciones de tablas de archivos de texto que creaban archivos comprimidos en un formato, pero utilizaban otra extensión de archivo de formato de compresión cuando se utilizaban métodos de compresión no predeterminados.
-
Avro: se corrigieron los problemas que se produjeron al leer decimales del tipo fijo de archivos Avro.
2 de marzo de 2022
Publicado el 02/03/2022
Athena anuncia las siguientes características y mejoras.
-
Ahora puede conceder al propietario del bucket de Simple Storage Service (Amazon S3) acceso de control total sobre los resultados de las consultas cuando estén habilitadas las ACL para el bucket de resultados de las consultas. Para obtener más información, consulte Especificación de una ubicación de resultados de consulta.
-
Ahora puede actualizar las consultas con nombre existentes. Para obtener más información, consulte Uso de consultas guardadas.
23 de febrero de 2022
Publicado el 23/02/2022
Athena anuncia las siguientes correcciones y mejoras de rendimiento.
-
Mejoras en la gestión de la memoria para mejorar el rendimiento y reducir los errores de memoria.
-
Athena ahora lee las columnas de marca temporal ORC con información de zona horaria almacenada en pies de página del conjunto seccionado (stripe) y escribe archivos ORC con zona horaria (UTC) en pies de página. Esto solo afecta al comportamiento de las lecturas de marca temporal ORC si el archivo ORC que se va a leer se ha creado en un entorno de zona horaria distinto a UTC.
-
Se corrigieron estimaciones incorrectas del tamaño de la tabla de enlaces simbólicos que generaban planes de consulta inferiores a los óptimos.
-
Ahora se pueden consultar vistas explosionadas laterales en la consola de Athena desde orígenes de datos de metaalmacén de Hive.
-
Mensajes de error de lectura de Simple Storage Service (Amazon S3) mejorados para incluir información más detallada de Código de error de Simple Storage Service (Amazon S3).
-
Se corrigió un error que provocaba que los archivos de salida en formato ORC se volvieran incompatibles con Apache Hive 3.1.
-
Se corrigió un error que provocaba que los nombres de tablas con comillas fallaran en determinadas consultas DML y DDL.
15 de febrero de 2022
Publicado el 15/02/2022
Amazon Athena ha aumentado la cuota de consulta DML activa en todas las regiones de AWS. Las consultas activas incluyen tanto las consultas en ejecución como en cola. Con este cambio, ahora puede haber más consultas DML en estado activo que antes.
Para obtener más información acerca de Service Quotas de Athena, consulte Service Quotas. Para obtener información sobre las cuotas de consulta de la región en la que utiliza Athena, consulte los puntos de conexión y cuotas de Amazon Athena en la Referencia general de AWS.
Para supervisar el uso de cuotas, puede utilizar las métricas de uso de CloudWatch. Athena publica la métrica ActiveQueryCount en el espacio de nombres AWS/Usage. Para obtener más información, consulte Supervisión de las métricas de uso de Athena con CloudWatch.
Después de revisar su uso, puede utilizar la consola de Service Quotas
14 de febrero de 2022
Publicado el 14/02/2022
En esta versión se agrega el subcampo ErrorType al objeto de respuesta AthenaError de la acción de la API GetQueryExecution de Athena.
Si bien el campo ErrorCategory existente indica el origen general de una consulta fallida (sistema, usuario u otro), el nuevo campo ErrorType proporciona información más detallada sobre el error que se ha producido. Combine la información de ambos campos para obtener información sobre las causas del error de la consulta.
Para obtener más información, consulte Catálogo de errores de Athena.
9 de febrero de 2022
Publicado el 09/02/2022
La consola antigua de Athena ya no está disponible. La nueva consola de Athena admite todas las características de la consola anterior, pero con una interfaz moderna y fácil de usar e incluye nuevas características que mejoran la experiencia de desarrollar consultas, analizar datos y administrar el uso. Para utilizar la nueva consola Athena, vaya a https://console.aws.amazon.com/athena/
8 de febrero de 2022
Publicado el 08/02/2022
Propietario esperado del bucket: como medida de seguridad adicional, ahora puede especificar opcionalmente el ID de la Cuenta de AWS que espera que sea la propietaria del bucket de la ubicación de salida de los resultados de la consulta en Athena. Si el ID de la cuenta del propietario del bucket de los resultados de la consulta no coincide con el ID de la cuenta especificado, los intentos de generar el bucket fallarán con un error de permisos de Amazon S3. Puede establecer esta configuración a nivel de cliente o de grupo de trabajo.
Para obtener más información, consulte Especificación de una ubicación de resultados de consulta.
28 de enero de 2022
Publicado el 28/01/2022
Athena anuncia las siguientes mejoras en las características del motor.
-
Apache Hudi: las consultas de instantáneas en las tablas Merge on Read (fusionar al leer, MoR) de Hudi ahora pueden leer columnas de marca de tiempo que tienen el tipo de datos
INT64. -
Consultas UNION: mejora del rendimiento y reducción del análisis de datos de determinadas consultas
UNIONque analizan la misma tabla varias veces. -
Consultas disyuntivas: mejora del rendimiento de las consultas que solo tienen valores disyuntivos en cada columna de partición en el filtro.
-
Mejoras en la proyección de particiones
-
Ahora se permiten varios valores disyuntivos en la condición de filtro en las columnas del tipo
injected. Para obtener más información, consulte Tipo inyectado. -
Mejora del rendimiento de columnas de tipos basados en cadenas como
CHARoVARCHARque solo tienen valores disyuntivos en el filtro.
-
13 de enero de 2022
Publicado el 13/01/2022
Se publicaron los controladores JDBC 2.0.27 y ODBC 1.1.15 para Athena.
El controlador JDBC 2.0.27 incluye los siguientes cambios:
-
El controlador se actualizó para recuperar catálogos externos.
-
El número ampliado de versión del controlador ahora se incluye en la cadena
user-agentcomo parte de la llamada a la API de Athena.
El controlador ODBC 1.1.15 incluye los siguientes cambios:
-
Corrige un problema con las segundas llamadas a
SQLParamData().
Para obtener más información sobre estos cambios y, a fin de descargar los nuevos controladores, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con JDBC y Conexión a Amazon Athena con ODBC.
Notas de la versión de Athena para 2021
26 de noviembre de 2021
Publicado el 26/11/2021
Athena anuncia la versión preliminar pública de las transacciones ACID de Athena, que agrega operaciones de escritura, eliminación, actualización y viaje en el tiempo al lenguaje de manipulación de datos SQL (DML) de Athena. Las transacciones ACID de Athena permiten que varios usuarios simultáneos hagan modificaciones fiables a nivel de fila en los datos de Amazon S3. Al estar basadas en el formato de tabla de Apache Iceberg
Las transacciones ACID de Athena y la conocida sintaxis SQL simplifican las actualizaciones de los datos empresariales y normativos. Por ejemplo, para responder a una solicitud de borrado de datos, puede llevar a cabo una operación DELETE de SQL. Para hacer correcciones manuales de registros, puede utilizar una sola instrucción UPDATE. Para recuperar los datos eliminados recientemente, puede emitir consultas de viaje en el tiempo mediante una instrucción SELECT. Las transacciones de Athena están disponibles a través de la consola de Athena, las operaciones API y los controladores ODBC y JDBC.
Para obtener más información, consulte Uso de las transacciones de ACID de Athena.
24 de noviembre de 2021
Publicado el 24/11/2021
Athena anuncia la compatibilidad con la lectura y escritura de datos ORC, Parquet y archivos de texto comprimidos en ZStandard
Para obtener información sobre la compresión de datos en Athena, consulte Uso de la compresión en Athena.
22 de noviembre de 2021
Publicado el 22/11/2021
A partir de ahora, puede administrar los flujos de trabajo de AWS Step Functions desde la consola de Amazon Athena, lo que facilita la creación de canalizaciones de procesamiento de datos escalables, la ejecución de consultas basadas en la lógica empresarial personalizada, la automatización de tareas administrativas y de alertas, etc.
Step Functions ahora está integrado en la consola actualizada de Athena y puede utilizarla para ver un diagrama de flujo de trabajo interactivo de las máquinas de estado que invocan Athena. Para comenzar a trabajar, seleccione Flujos de trabajo del panel de navegación izquierdo. Si tiene máquinas de estado existentes con consultas de Athena, seleccione una máquina de estado para ver un diagrama interactivo del flujo de trabajo. Si es la primera vez que utiliza Step Functions, puede comenzar con el lanzamiento de un proyecto de ejemplo desde la consola de Athena y su personalización para que se adapte a sus casos de uso.
Para obtener más información, consulte Creación y orquestación de canalizaciones de ETL con Amazon Athena y AWS Step Functions
18 de noviembre de 2021
Publicado el 18/11/2021
Athena anuncia nuevas características y mejoras.
-
Compatibilidad con vertido en disco para consultas de agregación que contienen
DISTINCT,ORDER BYo ambas, como en el siguiente ejemplo:SELECT array_agg(orderstatus ORDER BY orderstatus) FROM orders GROUP BY orderpriority, custkey -
Se solucionaron los problemas de gestión de la memoria en las consultas que utilizan
DISTINCT. Para evitar mensajes de error comoConsultar recursos agotados en este factor de escalacuando utilice consultasDISTINCT, elija las columnas que tengan una cardinalidad baja paraDISTINCTo reduzca el tamaño de los datos de la consulta. -
En las consultas
SELECT COUNT(*)que no especifican una columna específica, se mejoró el rendimiento y el uso de la memoria al mantener solo el recuento sin almacenamiento en búfer de filas. -
Se presentaron las siguientes funciones de cadena.
-
translate(source, from, to): devuelve la cadenasourcey los caracteres encontrados en la cadenafromreemplazados por los caracteres correspondientes en la cadenato. Si la cadenafromcontiene duplicados, solo se utiliza la primera. Si el caráctersourceno existe en la cadenafrom, el caráctersourcese copia sin traducción. Si el índice del carácter coincidente en la cadenafromes mayor que la longitud de la cadenato, el carácter se omite de la cadena resultante. -
concat_ws(string0, array(varchar)): devuelve la concatenación de elementos de la matriz mediantestring0como separador. Sistring0es NULL, el valor devuelto es NULL. Se omiten los valores NULL de la matriz.
-
-
Se corrigió un error por el que no se podían hacer consultas al intentar acceder a un subcampo que faltaba en una
struct. Las consultas devuelven ahora un valor NULL para el subcampo que falte. -
Se corrigió un problema de hash incoherente para el tipo de datos decimales.
-
Se corrigió un problema que provocaba que los recursos se agotaran cuando había demasiadas columnas en una partición.
17 de noviembre de 2021
Publicado el 17/11/2021
Amazon Athena
Al consultar las tablas particionadas, Athena recupera y filtra las particiones de tabla disponibles en el subconjunto pertinente para la consulta. A medida que se agregan nuevos datos y particiones, se necesita más tiempo para procesar las particiones y el tiempo de ejecución de consulta puede aumentar. Para optimizar el procesamiento de particiones y mejorar el rendimiento de las consultas en las tablas de muchas particiones, Athena ahora admite los índices de particiones de AWS Glue.
Para obtener más información, consulte Optimización de las consultas con indexación y filtrado de particiones de AWS Glue.
16 de noviembre de 2021
Publicado el 16/11/2021
La nueva y mejorada consola de Amazon Athena
-
Ir a varias pestañas de consulta, reorganizarlas o cerrarlas desde una barra de pestañas de consulta rediseñada.
-
Leer y editar consultas con más facilidad gracias a la mejora del formato de texto y SQL.
-
Copiar los resultados de las consultas en el portapapeles, además de descargar el conjunto de resultados completo.
-
Ordenar el historial de consultas, las consultas guardadas y los grupos de trabajo y elegir qué columnas mostrar u ocultar.
-
Utilizar una interfaz simplificada para configurar orígenes de datos y grupos de trabajo con menos clics.
-
Establecer preferencias para mostrar los resultados de las consultas, el historial de consultas, el ajuste de líneas y más.
-
Aumentar la productividad con métodos abreviados de teclado nuevos y mejorados y documentación de productos incrustada.
Con el anuncio de hoy, la consola rediseñada
Si lo desea, puede utilizar la consola anterior. Para ello, inicie sesión en su Cuenta de AWS, elija Amazon Athena y anule la selección New Athena experience (Nueva experiencia de Athena) del panel de navegación de la izquierda.
12 de noviembre de 2021
Publicado el 12/11/2021
Ahora puede utilizar Amazon Athena para ejecutar consultas federadas en orígenes de datos ubicados en una cuenta de AWS aparte de la suya. Hasta el día de hoy, la consulta de estos datos requería que el origen de datos y su conector usaran la mismaCuenta de AWS que el usuario que consultó los datos.
Como administrador de datos, puede habilitar las consultas federadas entre cuentas. Para ello, comparta el conector de datos con la cuenta de un analista de datos. Como analista de datos, puede agregar un conector de datos que un administrador de datos compartió con usted en su cuenta. Los cambios de configuración del conector de la cuenta de origen se aplican automáticamente al conector compartido.
Para obtener información sobre cómo habilitar las consultas federadas entre cuentas, consulte Habilitación de las consultas federadas entre cuentas. Para obtener más información sobre las consultas de orígenes federados, consulte Uso de consulta federada de Amazon Athena y Ejecución de consultas federadas.
2 de noviembre de 2021
Publicado el 02/11/2021
Ahora puede utilizar la instrucción EXPLAIN ANALYZE en Athena para ver el plan de ejecución distribuido y el costo de cada operación de las consultas SQL.
Para obtener más información, consulte Uso de EXPLAIN y EXPLAIN ANALYZE en Athena.
29 de octubre de 2021
Publicado el 29/10/2021
Athena publica los controladores JDBC 2.0.25 y ODBC 1.1.13 y anuncia características y mejoras.
Controladores JDBC y ODBC
Se lanzaron los controladores JDBC 2.0.25 y ODBC 1.1.13 para Athena. Ambos controladores ofrecen compatibilidad con la autenticación multifactor SAML del navegador que se puede configurar para que funcione con cualquier proveedor SAML 2.0.
El controlador JDBC 2.0.25 incluye los siguientes cambios:
-
Compatibilidad con la autenticación SAML de navegador. El controlador incluye un complemento SAML de navegador que se puede configurar para que funcione con cualquier proveedor SAML 2.0.
-
Compatibilidad con llamadas a la API AWS Glue. Puede utilizar el parámetro
GlueEndpointOverridepara anular el punto de conexión de AWS Glue. -
Se cambió la ruta de la clase
com.simba.athena.amazonawsporcom.amazonaws.
El controlador ODBC 1.1.13 incluye los siguientes cambios:
-
Compatibilidad con la autenticación SAML de navegador. El controlador incluye un complemento SAML de navegador que se puede configurar para que funcione con cualquier proveedor SAML 2.0. Para ver un ejemplo de cómo utilizar el complemento SAML del navegador con el controlador ODBC, consulte Configuración del inicio de sesión único con ODBC, SAML 2.0 y el proveedor de identidades Okta.
-
Ahora puede configurar la duración de la sesión del rol al utilizar ADFS, Azure AD o Azure AD de navegador para la autenticación.
Para obtener más información sobre estos y otros cambios y, a fin de descargar los nuevos controladores, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con JDBC y Conexión a Amazon Athena con ODBC.
Características y mejoras
Athena anuncia las siguientes características y mejoras.
-
Se presentó una nueva regla de optimización para evitar análisis de tablas duplicados en determinados casos.
4 de octubre de 2021
Publicado el 04/10/2021
Athena anuncia las siguientes características y mejoras.
-
SQL OFFSET: la cláusula
OFFSETde SQL ahora es compatible en las instruccionesSELECT. Para obtener más información, consulte SELECT. -
Métricas de uso de CloudWatch: Athena publica ahora la métrica
ActiveQueryCounten el espacio de nombresAWS/Usage. Para obtener más información, consulte Supervisión de las métricas de uso de Athena con CloudWatch. -
Planificación de consultas: se corrigió un error que, en raras ocasiones, podía provocar tiempos de espera de planificación de consultas.
16 de septiembre de 2021
Publicado el 16/09/2021
Athena anuncia las nuevas características y mejoras que se indican a continuación.
Características
-
Se agregó compatibilidad para especificar la compresión de archivos de texto y JSON en CTAS mediante la propiedad de tablas
write_compression. También puede especificar la propiedadwrite_compressionen CTAS para los formatos Parquet y ORC. Para obtener más información, consulte Propiedades de la tabla CTAS. -
El formato de compresión BZIP2 ahora es compatible para escribir archivos de texto y archivos JSON. Para obtener más información sobre los formatos de compresión en Athena, consulte Uso de la compresión en Athena.
Mejoras
-
Se corrigió un error por el que la información de identidad no se podía enviar a la función de Lambda de UDF.
-
Se corrigió un problema de inserción de predicados con condiciones de filtro disyuntivas.
-
Se corrigió un problema de hash de los tipos decimales.
-
Se corrigió un problema de recopilación de estadísticas innecesarias.
-
Se eliminó un mensaje de error incoherente.
-
Se mejoró el rendimiento de las uniones de difusión mediante la aplicación de la eliminación de particiones dinámica en el nodo de trabajo.
-
Para consultas federadas:
-
Se alteró la configuración para reducir la aparición de errores
CONSTRAINT_VIOLATIONen las consultas federadas.
-
15 de septiembre de 2021
Publicado el 15/09/2021
Ahora puede utilizar una consola de Amazon Athena rediseñada (versión preliminar). Se publicó un nuevo controlador JDBC de Athena.
Vista previa de la consola de Athena
A partir de ahora, puede utilizar una consola rediseñad de Amazon Athena
Para cambiar a la nueva consola
Comience a trabajar con la nueva consola
Controlador JDBC de Athena 2.0.24
Athena anuncia la disponibilidad del controlador JDBC versión 2.0.24 para Athena. Esta versión actualiza la compatibilidad de proxy de todos los proveedores de credenciales. El controlador ahora admite la autenticación proxy de todos los hosts que no son compatibles con la propiedad de conexión NonProxyHosts.
Para mayor comodidad, esta versión incluye descargas del controlador JDBC con y sin el SDK AWS. Esta versión del controlador JDBC le permite tener el SDK de AWS y el controlador JDBC de Athena integrados en el proyecto.
Para obtener más información y descargar el nuevo controlador, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con JDBC.
31 de agosto de 2021
Publicado el 31/08/2021
Athena anuncia las siguientes mejoras de características y correcciones de errores.
-
Mejoras de la federación de Athena: Athena agregó soporte para tipos de mapas y mejor soporte para tipos complejos como parte del SDK de Athena Query Federation
. Esta versión incluye también algunas mejoras de memoria y optimizaciones de rendimiento. -
Nuevas categorías de error: se presentaron las categorías de error
USERySYSTEMen los mensajes de error. Estas categorías lo ayudan a distinguir errores que puede corregir usted mismo (USER) y errores que pueden requerir asistencia del soporte técnico de Athena (SYSTEM). -
Mensajería de error de consultas federadas: actualización de categorizaciones de
USER_ERRORpara errores relacionados con consultas federadas. -
JOIN: se corrigieron errores relacionados con el vertido en disco y problemas de memoria para mejorar el rendimiento y reducir los errores de memoria en operaciones
JOIN.
12 de agosto de 2021
Publicado el 12/08/2021
Se publicó el controlador ODBC 1.1.12 para Athena. Esta versión corrige problemas relacionados con SQLPrepare(), SQLGetInfo() y EndpointOverride.
Para descargar el nuevo controlador, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con ODBC.
6 de agosto de 2021
Publicado el 06/08/2021
Amazon Athena anuncia la disponibilidad de Athena y sus características
Esta versión amplía la disponibilidad de Athena en Asia-Pacífico e incluye Asia-Pacífico (Hong Kong), Asia-Pacífico (Bombay), Asia-Pacífico (Osaka), Asia-Pacífico (Seúl), Asia-Pacífico (Singapur), Asia-Pacífico (Singapur), Asia-Pacífico (Sídney) y Asia-Pacífico (Tokio). Para obtener una lista completa de los Servicios de AWS disponibles en estas y otras regiones, consulte la Lista de servicios por Región de AWS
5 de agosto de 2021
Publicado el 05/08/2021
Puede utilizar la instrucción UNLOAD para escribir la salida de una consulta SELECT a los formatos PARQUET, ORC, AVRO y JSON.
Para obtener más información, consulte UNLOAD.
30 de julio de 2021
Publicado el 30/07/2021
Athena anuncia las siguientes mejoras de características y correcciones de errores.
-
Filtrado dinámico y poda de particiones: las mejoras aumentan el rendimiento y reducen la cantidad de datos analizados en determinadas consultas, como en el siguiente ejemplo.
En este ejemplo, se supone que
Table_Bes una tabla no particionada que tiene tamaños de archivo que suman menos de 20 MB. Para consultas como esta, se leen menos datos deTable_Ay la consulta se completa más rápidamente.SELECT * FROM Table_A JOIN Table_B ON Table_A.date = Table_B.date WHERE Table_B.column_A = "value" -
ORDER BY with LIMIT, DISTINCT with LIMIT: mejoras en el rendimiento de consultas que utilizan
ORDER BYoDISTINCTseguido de una cláusulaLIMIT. -
Archivos S3 Glacier Deep Archive: cuando Athena consulta una tabla que contiene una combinación de archivos S3 Glacier Deep Archive y archivos que no son S3 Glacier, Athena ahora omite los archivos de S3 Glacier Deep Archive por usted. Anteriormente, era necesario mover manualmente estos archivos desde la ubicación de la consulta, o la consulta generaba un error. Si desea utilizar Athena para consultar objetos en el almacenamiento de S3 Glacier Deep Archive, debe restaurarlos. Para obtener más información, consulte Restaurar un objeto archivado en la Guía del usuario de Amazon S3.
-
Se corrigió un error en el que archivos vacíos creados por la propiedad de tabla CTAS
bucketed_byno se cifraron correctamente.
21 de julio de 2021
Publicado el 21/07/2021
Con la publicación de julio de 2021 del Escritorio Microsoft Power BI
Dado que el conector utiliza el nombre de origen de datos (DSN) ODBC existente para conectarse y ejecutar consultas en Athena, requiere el controlador ODBC de Athena. Para descargar el controlador ODBC más reciente, consulte Conexión a Amazon Athena con ODBC.
Para obtener más información, consulte Uso del conector de Power BI de Amazon Athena.
16 de julio de 2021
Publicado el 16/07/2021
Amazon Athena actualizó su integración con Apache Hudi. Hudi es un marco de administración de datos de código abierto que se utiliza para simplificar el procesamiento incremental de datos en lagos de datos de Amazon S3. La integración actualizada le permite utilizar Athena para consultar tablas Hudi 0.8.0 administradas a través de Amazon EMR, Apache Spark, Apache Hive u otros servicios compatibles. Además, Athena ahora admite dos características adicionales: consultas de instantáneas en tablas Fusionar al leer (MoR, Merge-on-Read) y soporte de lectura en tablas de arranque.
Apache Hudi proporciona procesamiento de datos a nivel de registro que puede ayudarlo a simplificar el desarrollo de canalizaciones de captura de datos modificados (CDC), cumplir con las actualizaciones y eliminaciones impulsadas por el RGPD y administrar mejor los datos de transmisión desde sensores o dispositivos que requieren inserción de datos y actualizaciones de eventos. La versión 0.8.0 facilita la migración de tablas de Parquet grandes a Hudi sin copiar datos, de modo que pueda consultarlas y analizarlas a través de Athena. Puede utilizar la nueva compatibilidad de Athena para consultas de instantáneas para tener vistas casi en tiempo real de las actualizaciones de las tablas de transmisión.
Para obtener más información sobre el uso de Hudi con Athena, consulte Consulta de los conjuntos de datos de Apache Hudi.
8 de julio de 2021
Publicado el 08/07/2021
Se publicó el controlador ODBC 1.1.11 para Athena. El controlador ODBC ahora puede autenticar la conexión mediante un JSON Web Token (JWT). En Linux, el valor predeterminado de la propiedad de grupo de trabajo se estableció en Principal.
Para obtener más información y descargar el nuevo controlador, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con ODBC.
1 de julio de 2021
Publicado el 01/07/2021
El 1 de julio de 2021, finalizó la gestión especial de grupos de trabajo de vista previa. Aunque los grupos de trabajo AmazonAthenaPreviewFunctionality conservan su nombre, ya no tienen un estado especial. Puede continuar usando los grupos de trabajo AmazonAthenaPreviewFunctionality para ver, modificar, organizar y ejecutar consultas. Sin embargo, las consultas que utilizan características que anteriormente estaban en vista previa ahora están sujetas a los términos y condiciones de facturación estándar de Athena. Para obtener información sobre la facturación, consulte Precios de Amazon Athena
23 de junio de 2021
Publicado el 23/06/2021
Se publicaron los controladores JDBC 2.0.23 y ODBC 1.1.10 para Athena. Ambos controladores ofrecen un mejor rendimiento de lectura, instrucciones EXPLAIN de soporte y consultas parametrizadas.
Las instrucciones EXPLAIN muestran el plan de ejecución lógico o distribuido de una consulta SQL. Las consultas parametrizadas permiten que la misma consulta se utilice varias veces con diferentes valores suministrados en tiempo de ejecución.
La versión de JDBC también agrega compatibilidad con Active Directory Federation Services 2019 y una opción de anulación de puntos de conexión personalizada para AWS STS. La versión ODBC corrige un problema con las credenciales de perfil de IAM.
Para obtener más información y descargar el nuevo controlador, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con JDBC y Conexión a Amazon Athena con ODBC.
12 de mayo de 2021
Publicado el 12/05/2021
Ahora puede utilizar Amazon Athena para registrar un catálogo AWS Glue desde una cuenta que no sea la suya. Una vez configurados los permisos de IAM necesarios para AWS Glue, puede utilizar Athena para ejecutar consultas entre cuentas.
Para obtener más información, consulte Registrar un catálogo de datos desde otra cuenta y Configuración del acceso entre cuentas a los catálogos de datos de AWS Glue.
10 de mayo de 2021
Publicado el 10/05/2021
Se publicó la versión 1.1.9.1001 del controlador ODBC para Athena. Esta versión corrige un problema con el tipo de autenticación BrowserAzureAD cuando se utiliza Azure Active Directory (AD).
Para descargar los nuevos controladores, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con ODBC.
5 de mayo de 2021
Publicado el 05/05/2021
Ahora puede utilizar el conector de Amazon Athena Vertica en consultas federadas para consultar orígenes de datos Vertica desde Athena. Por ejemplo, puede ejecutar consultas analíticas a través de un almacenamiento de datos en Vertica y un lago de datos en Amazon S3.
Para implementar el conector Athena Vertica, visite la página AtenaVerticaConnector
El conector de Amazon Athena Vertica expone varias opciones de configuración a través de variables de entorno Lambda. Para obtener información sobre las opciones de configuración, los parámetros, las cadenas de conexión, la implementación y las limitaciones, consulte Conector para Vertica de Amazon Athena.
Para obtener información detallada acerca del uso de conector Vertica, consulte Consulta de un origen de datos Vertica en Amazon Athena mediante el SDK de consulta federada de Athena
30 de abril de 2021
Publicado el 30/04/2021
Se publicaron los controladores JDBC 2.0.21 y ODBC 1.1.9 para Athena. Ambas versiones admiten la autenticación SAML con Azure Active Directory (AD) y la autenticación SAML con PingFederate. La versión JDBC admite también consultas parametrizadas. Para obtener información acerca de las consultas parametrizadas en Athena, consulte Uso de consultas parametrizadas.
Para descargar los nuevos controladores, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con JDBC y Conexión a Amazon Athena con ODBC.
29 de abril de 2021
Publicado el 29/04/2021
Amazon Athena anuncia disponibilidad de la versión 2 del motor Athena en las regiones China (Pekín) y China (Ningxia).
26 de abril de 2021
Publicado el 26/04/2021
Las funciones de valor de ventana en la versión 2 del motor Athena ahora admiten IGNORE NULLS y RESPECT NULLS.
Para obtener más información, consulte Funciones de valor
21 de abril de 2021
Publicado el 21/04/2021
Amazon Athena anuncia disponibilidad de la versión 2 del motor Athena en las regiones Europa (Milán) y África (Ciudad del Cabo).
5 de abril de 2021
Publicado el 05/04/2021
Instrucción EXPLAIN
Ahora puede utilizar la instrucción EXPLAIN en Athena para ver el plan de ejecución de las consultas SQL.
Para obtener más información, consulte Uso de EXPLAIN y EXPLAIN ANALYZE en Athena y Descripción de los resultados de la instrucción EXPLAIN de Athena.
Modelos de machine learning de SageMaker IA en consultas SQL
La inferencia de modelos de machine learning con Amazon SageMaker IA ya está disponible de forma general para Amazon Athena. Utilice modelos de machine learning en consultas SQL para simplificar tareas complejas, como la detección de anomalías, el análisis de cohortes de clientes y las predicciones de serie temporal al invocar una función en una consulta SQL.
Para obtener más información, consulte Uso de machine learning (ML) con Amazon Athena.
Funciones definidas por el usuario (UDF)
Las funciones definidas por el usuario (UDF) ya están disponibles en general para Athena. Utilice UDF para aprovechar las funciones personalizadas que procesan registros o grupos de registros en una sola consulta SQL.
Para obtener más información, consulte Consulta con funciones definidas por el usuario.
30 de marzo de 2021
Publicado el 30/03/2021
Amazon Athena anuncia disponibilidad de la versión 2 del motor Athena en las regiones Asia-Pacífico (Hong Kong) y Medio Oriente (Baréin).
25 de marzo de 2021
Publicado el 25/03/2021
Amazon Athena anuncia la disponibilidad de la versión 2 del motor Athena en la región de Europa (Estocolmo).
5 de marzo de 2021
Publicado el 05/03/2021
Amazon Athena anuncia disponibilidad de la versión 2 del motor Athena en las regiones Canadá (centro), Europa (Fráncfort) y América del Sur (São Paulo).
25 de febrero de 2021
Publicado el 25/02/2021
Amazon Athena anuncia disponibilidad general de la versión 2 del motor Athena en las regiones Asia-Pacífico (Seúl), Asia-Pacífico (Singapur), Asia-Pacífico (Sídney), Europa (Londres) y Europa (París).
Notas de la versión de Athena para 2020
16 de diciembre de 2020
Publicado el 16/12/2020
Amazon Athena anuncia la disponibilidad de la versión 2 del motor Athena, la consulta federada de Athena y AWS PrivateLink en regiones adicionales.
Versión 2 del motor Athena y consulta federada de Athena
Amazon Athena anuncia disponibilidad general de la versión 2 del motor Athena y la consulta federada de Athena en las regiones Asia-Pacífico (Bombay), Asia-Pacífico (Tokio), Europa (Irlanda) y Oeste de EE. UU. (Norte de California). La versión 2 del motor Athena y las consultas federadas ya están disponibles en las regiones Este de EE. UU. (Norte de Virginia), Este de EE. UU. (Ohio) y Oeste de EE. UU. (Oregón).
AWS PrivateLink
AWS PrivateLink para Athena ahora está disponible en la región Europa (Estocolmo). Para obtener información acerca de AWS PrivateLink para Athena, consulte Conexión a Amazon Athena mediante un punto de conexión de VPC de tipo interfaz.
24 de noviembre de 2020
Publicado el 24/11/2020
Se publicaron los controladores JDBC 2.0.16 y ODBC 1.1.6 para Athena. Estas versiones, en el nivel de cuenta, admiten la autenticación multifactor (MFA) de Okta Verify. También puede utilizar la MFA de Okta para configurar la autenticación SMS y la autenticación de Google Authenticator como factores.
Para descargar los nuevos controladores, las notas de la versión y la documentación, consulte Conexión a Amazon Athena con JDBC y Conexión a Amazon Athena con ODBC.
11 de noviembre de 2020
Publicado el 11/11/2020
Amazon Athena anuncia disponibilidad general de la versión 2 del motor Athena y las consultas federadas en las regiones Este de EE. UU. (Norte de Virginia), Este de EE. UU. (Ohio) y Oeste de EE. UU. (Oregón).
Versión 2 del motor Athena
Amazon Athena anuncia disponibilidad general de una nueva versión del motor de consultas, la versión 2 del motor Athena, en las regiones Este de EE. UU. (Norte de Virginia), Este de EE. UU. (Ohio) y Oeste de EE. UU. (Oregón).
La versión 2 del motor Athena incluye mejoras de rendimiento y nuevas características, como compatibilidad con la evolución de esquemas para datos con formato Parquet, funciones geoespaciales adicionales, compatibilidad con la lectura de esquemas anidados para reducir costos y mejoras de rendimiento en operaciones JOIN y AGGREGATE.
-
Para obtener información acerca de cómo actualizar, consulte Cambio de las versiones del motor Athena.
-
Para obtener información acerca de las pruebas de consultas, consulte Pruebas de consultas antes de una actualización de la versión del motor.
Consultas de SQL federadas
Ahora puede utilizar la consulta federada de Athena en las regiones Este de EE. UU. (Norte de Virginia), Este de EE. UU. (Ohio) y Oeste de EE. UU. (Oregón) sin utilizar el grupo de trabajo AmazonAthenaPreviewFunctionality.
Utilice consultas de SQL federadas para ejecutar consultas de SQL en orígenes de datos relacionales, no relacionales, de objetos y personalizados. Con las consultas federadas, puede enviar una sola consulta SQL que examina los datos de varios orígenes alojados en la nube o que se ejecutan en las instalaciones.
La ejecución de análisis en datos repartidos entre aplicaciones puede ser compleja y consumir mucho tiempo por las siguientes razones:
-
Los datos necesarios para un análisis suelen distribuirse entre almacenes de datos relacionales, en memoria, de clave-valor, de documentos, de búsqueda, de gráficos, de objetos, de series temporales y de libro mayor.
-
A la hora de analizar los datos en estos orígenes, los analistas crean canalizaciones complejas para realizar extracciones, transformaciones y cargas en un almacenamiento de datos a fin de que los datos puedan consultarse.
-
Acceder a los datos desde varios orígenes requiere aprender nuevos lenguajes de programación y constructos de acceso a los datos.
Las consultas SQL federadas en Athena eliminan esta complejidad, ya que permiten a los usuarios consultar los datos de forma local independientemente de su ubicación. Los analistas pueden utilizar constructos de SQL conocidos para datos JOIN de varios orígenes con el objetivo de realizar un análisis rápido y almacenar los resultados en Amazon S3 para su posterior uso.
Conectores de origen de datos
Para procesar consultas federadas, Athena utiliza conectores de origen de datos de Athena que se ejecutan en AWS Lambda
Conectores de orígenes de datos personalizados
Mediante el SDK de Athena Query Federation
Siguientes pasos
-
Para obtener más información acerca de la característica de consulta federada, consulte Uso de consulta federada de Amazon Athena.
-
Para comenzar a utilizar un conector existente, consulte Cómo crear una conexión de origen de datos.
-
Para obtener información sobre cómo crear su propio conector de origen de datos mediante el SDK de Athena Query Federation, consulte Ejemplo de conector Athena
en GitHub.
22 de octubre de 2020
Publicado el 22/10/2020
Llame a Athena con AWS Step Functions. AWS Step Functions puede controlar algunos Servicios de AWS directamente mediante Amazon States Language. Puede utilizar Step Functions con Athena para iniciar y detener la ejecución de consultas, obtener resultados de consultas, ejecutar consultas de datos ad hoc o programadas y recuperar resultados de lagos de datos en Amazon S3.
Para obtener más información, consulte Llamar a Athena con Step Functions en la Guía para desarrolladores de AWS Step Functions.
29 de julio de 2020
Publicado el 29/07/2020
Se publicó la versión 2.0.13 del controlador JDBC. Esta versión admite el uso de varios catálogos de datos registrados en Athena, el servicio Okta para autenticación y las conexiones a puntos de conexión de VPC.
Para descargar y utilizar la nueva versión del controlador, consulte Conexión a Amazon Athena con JDBC.
9 de julio de 2020
Publicado el 09/07/2020
Amazon Athena agrega compatibilidad para consultar conjuntos de datos Hudi compactados y agrega el recurso AWS CloudFormation de AWS::Athena::DataCatalog para crear, actualizar o eliminar catálogos de datos que registre en Athena.
Consulta de conjuntos de datos de Apache Hudi
Apache Hudi es un marco de administración de datos de código abierto que simplifica el procesamiento incremental de datos. Amazon Athena ahora admite la consulta de la vista optimizada para lectura de un conjunto de datos Apache Hudi en el lago de datos basado en Amazon S3.
Para obtener más información, consulte Consulta de los conjuntos de datos de Apache Hudi.
Recurso AWS CloudFormation del catálogo de datos
Para utilizar la característica de consulta federada de Amazon Athena para consultar cualquier origen de datos, primero debe registrar el catálogo de datos en Athena. Ahora puede usar el recurso AWS CloudFormation de AWS::Athena::DataCatalog para crear, actualizar o eliminar catálogos de datos que registra en Athena.
Para obtener más información, consulte AmazonWebService::Athena::DataCatalog en la Guía del usuario de AWS CloudFormation.
1 de junio de 2020
Publicado el 01/06/2020
Uso de metaalmacenes de Apache Hive con Amazon Athena
Ahora puede conectar Athena a uno o más metaalmacenes de Apache Hive además de AWS Glue Data Catalog con Athena.
Para conectarse a un metaalmacén de Hive autoalojado, necesita un conector de metaalmacén de Athena Hive. Athena ofrece un conector de implementación de referencia que puede utilizar. El conector se ejecuta como una función de AWS Lambda en su cuenta.
Para obtener más información, consulte Uso de un metastore de Hive externo.
21 de mayo de 2020
Publicado el 21/05/2020
Amazon Athena agrega compatibilidad para la proyección de particiones. Utilice la proyección de particiones para acelerar el procesamiento de consultas de tablas altamente particionadas y automatizar la administración de particiones. Para obtener más información, consulte Uso de proyección de particiones con Amazon Athena.
1 de abril de 2020
Publicado el 01/04/2020
Además de la región Este de EE. UU. (Norte de Virginia), las características de consulta federada, funciones definidas por el usuario (UDF), inferencia de machine learning y metaalmacén externo de Hive de Amazon Athena ya están disponibles en versión preliminar en las regiones Asia-Pacífico (Bombay), Europa (Irlanda) y Oeste de EE. UU. (Oregón).
11 de marzo de 2020
Publicado el 11/03/2020
Amazon Athena ha publicado Amazon EventBridge para transiciones de estado de consulta. Cuando una consulta pasa de un estado a otro (por ejemplo, del estado “en ejecución” a un estado terminal, como “realizado con éxito” o “cancelado”), Athena publica un evento de cambio de estado de consulta en EventBridge. El evento contiene información acerca de la transición del estado de consulta. Para obtener más información, consulte Supervisión de los eventos de consultas de Athena con EventBridge.
6 de marzo de 2020
Publicado el 06/03/2020
Ahora puede crear y actualizar grupos de trabajo de Amazon Athena mediante el recurso AWS CloudFormation AWS::Athena::WorkGroup. Para obtener más información, consulte AmazonWebService::Athena::WorkGroup en la Guía del usuario de AWS CloudFormation.
Notas de la versión de Athena para 2019
26 de noviembre de 2019
Publicado el 17/12/2019
Amazon Athena agrega compatibilidad para ejecutar consultas SQL en orígenes de datos relacionales, no relacionales, de objetos y personalizados, invocar modelos de machine learning en consultas SQL, funciones definidas por el usuario (UDF) (vista previa), utilizar metaalmacenes de Apache Hive como catálogo de metadatos con Amazon Athena (vista previa), y cuatro métricas relacionadas con las consultas adicionales.
Consultas de SQL federadas
Utilice consultas de SQL federadas para ejecutar consultas de SQL en orígenes de datos relacionales, no relacionales, de objetos y personalizados.
Ahora puede utilizar la consulta federada de Athena para analizar datos almacenados en orígenes de datos relacionales, no relacionales, de objetos y personalizados. Con las consultas federadas, puede enviar una sola consulta SQL que examina los datos de varios orígenes alojados en la nube o que se ejecutan en las instalaciones.
La ejecución de análisis en datos repartidos entre aplicaciones puede ser compleja y consumir mucho tiempo por las siguientes razones:
-
Los datos necesarios para un análisis suelen distribuirse entre almacenes de datos relacionales, en memoria, de clave-valor, de documentos, de búsqueda, de gráficos, de objetos, de series temporales y de libro mayor.
-
A la hora de analizar los datos en estos orígenes, los analistas crean canalizaciones complejas para realizar extracciones, transformaciones y cargas en un almacenamiento de datos a fin de que los datos puedan consultarse.
-
Acceder a los datos desde varios orígenes requiere aprender nuevos lenguajes de programación y constructos de acceso a los datos.
Las consultas SQL federadas en Athena eliminan esta complejidad, ya que permiten a los usuarios consultar los datos de forma local independientemente de su ubicación. Los analistas pueden utilizar constructos de SQL conocidos para datos JOIN de varios orígenes con el objetivo de realizar un análisis rápido y almacenar los resultados en Amazon S3 para su posterior uso.
Conectores de origen de datos
Athena procesa consultas federadas con conectores de origen de datos de Athena que se ejecutan en AWS Lambda
Conectores de orígenes de datos personalizados
Mediante el SDK de Athena Query Federation
Disponibilidad de la vista previa
La consulta federada de Athena está disponible en vista previa en la región Este de EE. UU. (Norte de Virginia).
Siguientes pasos
-
Para comenzar la vista previa, siga las instrucciones de las Preguntas frecuentes sobre las características de la vista previa de Athena
. -
Para obtener más información sobre la característica de consulta federada, consulte Uso de consultas federadas de Amazon Athena (vista previa).
-
Para comenzar a utilizar un conector existente, consulte Cómo crear una conexión de origen de datos.
-
Para obtener información sobre cómo crear su propio conector de origen de datos mediante el SDK de Athena Query Federation, consulte Ejemplo de conector Athena
en GitHub.
Invocar modelos de Machine Learning en consultas de SQL
Ahora puede invocar modelos de machine learning para inferirlos directamente desde sus consultas de Athena. La posibilidad de utilizar modelos de machine learning en consultas de SQL permite que tareas complejas, como la detección de anomalías, el análisis de cohortes de clientes y las predicciones de ventas, sean tan simples como invocar una función en una consulta de SQL.
Modelos de ML
Puede utilizar más de una docena de algoritmos de machine learning integrados que proporciona Amazon SageMaker
Disponibilidad de la vista previa
La funcionalidad de ML de Athena está disponible hoy en vista previa en la región Este de EE. UU. (Norte de Virginia).
Siguientes pasos
-
Para comenzar la vista previa, siga las instrucciones de las Preguntas frecuentes sobre las características de la vista previa de Athena
. -
Para obtener más información sobre la característica de machine learning, consulte Uso de machine learning (ML) con Amazon Athena (vista previa).
Funciones definidas por el usuario (UDF) (Vista previa)
Ahora puede escribir funciones escalares personalizadas e invocarlas en sus consultas de Athena. Puede escribir sus UDF en Java utilizando el SDK de Athena Query FederationSELECT y FILTER de una consulta de SQL. Es posible invocar varias UDF en la misma consulta.
Disponibilidad de la vista previa
La funcionalidad de UDF de Athena está disponible hoy en vista previa en la región Este de EE. UU. (Norte de Virginia).
Siguientes pasos
-
Para comenzar la vista previa, siga las instrucciones de las Preguntas frecuentes sobre las características de la vista previa de Athena
. -
Para obtener más información, consulte Consultas con funciones definidas por el usuario (vista previa).
-
Para ver ejemplos de implementaciones de UDF, consulte Conector de UDF de Amazon Athena
en GitHub. -
Para obtener información sobre cómo escribir sus propias funciones mediante el SDK de Athena Query Federation, consulte Creación e implementación de una UDF mediante Lambda.
Uso del metaalmacén de Apache Hive como metacatálogo con Amazon Athena (vista previa)
Ahora puede conectar Athena a uno o más metaalmacenes de Apache Hive además de AWS Glue Data Catalog con Athena.
Conector Metastore
Para conectarse a un metaalmacén de Hive autoalojado, necesita un conector de metaalmacén de Athena Hive. Athena ofrece un conector de implementación de referencia
Disponibilidad de la vista previa
La característica de metaalmacén de Hive está disponible en la región Este de EE. UU. (Norte de Virginia).
Siguientes pasos
-
Para comenzar la vista previa, siga las instrucciones de las Preguntas frecuentes sobre las características de la vista previa de Athena
. -
Para obtener más información acerca de esta característica, visite Uso del conector de datos de Athena para metaalmacén externo de Hive (vista previa).
Nuevas métricas relacionadas con consultas
Athena ahora publica métricas de consulta adicionales que pueden ayudarlo a entender el rendimiento de Amazon Athena
-
Tiempo de planificación de consultas: el tiempo requerido para planificar la consulta. Esto incluye el tiempo dedicado a recuperar las particiones de tabla del origen de datos.
-
Tiempo de cola de consultas: el tiempo que la consulta estuvo en una cola en espera de recursos.
-
Tiempo de procesamiento del servicio: el tiempo requerido para escribir los resultados una vez que el motor de consultas finaliza el procesamiento.
-
Tiempo total de ejecución: el tiempo que Athena demoró en ejecutar la consulta.
Para utilizar estas métricas de consultas nuevas, puede crear paneles personalizados, establecer alarmas y desencadenadores en las métricas en CloudWatch, o utilizar paneles que se completan con antelación directamente desde la consola de Athena.
Siguientes pasos
Para obtener más información, consulte Monitoreo de métricas de Athena con Amazon CloudWatch.
12 de noviembre de 2019
Publicado el 17/12/2019
Amazon Athena ahora está disponible en la región de Medio Oriente (Baréin).
8 de noviembre de 2019
Publicado el 17/12/2019
Amazon Athena ahora está disponible en la región Oeste de EE. UU. (Norte de California) y Europa (París).
8 de octubre de 2019
Publicado el 17/12/2019
Amazon Athena
Para crear un punto de conexión de VPC de la interfaz para conectarse a Athena, puede usar la AWS Management Console o AWS Command Line Interface (AWS CLI). Para obtener información sobre la creación de un punto de conexión de tipo interfaz, consulte Creación de un punto de conexión de interfaz.
Cuando utiliza un punto de conexión de VPC de tipo interfaz, la comunicación entre su VPC y las API de Athena es segura y permanece dentro de la red de AWS. No hay costos adicionales de Athena para usar esta característica. Se aplican cargos
Para obtener más información acerca de esta característica, consulte Conectarse a Amazon Athena mediante un punto de conexión de VPC de tipo interfaz.
19 de septiembre de 2019
Publicado el 17/12/2019
Amazon Athena agrega compatibilidad para insertar nuevos datos en una tabla existente mediante la instrucción INSERT INTO. Puede insertar filas nuevas en una tabla de destino en función de una instrucción de consulta SELECT que se ejecute en una tabla de origen o en función de un conjunto de valores que se provee como parte de la instrucción de consulta. Los formatos de datos compatibles son Avro, JSON, ORC, Parquet y archivos de texto.
Las instrucciones INSERT INTO también pueden ayudarle a simplificar el proceso de ETL. Por ejemplo, puede usar INSERT INTO en una sola consulta para seleccionar datos a partir de una tabla de origen en formato JSON y escribir en una tabla de destino con formato Parquet.
Las instrucciones INSERT INTO se cargan en función del número de bytes que se analizan en la fase SELECT, de forma similar a cómo Athena cobra las consultas SELECT. Para obtener más información, consulte Precios de Amazon Athena
Para obtener más información sobre el uso de INSERT INTO, incluidos los formatos admitidos, SerDes y ejemplos, consulte INSERT INTO en la Guía del usuario de Athena.
12 de septiembre de 2019
Publicado el 17/12/2019
Amazon Athena ahora está disponible en la región Asia-Pacífico (Hong Kong).
16 de agosto de 2019
Publicado el 17/12/2019
Amazon Athena
Cuando un bucket de Amazon S3 se configura como pago por solicitante, el solicitante, no el propietario del bucket, paga los costos de solicitud y transferencia de datos de Amazon S3. En Athena, ahora los administradores de grupos de trabajo pueden ajustar la configuración del grupo de trabajo para permitir que los miembros del grupo de trabajo realicen consultas a los buckets de pagos por solicitante de S3.
Para obtener información acerca de cómo configurar la opción de pago por solicitante para el grupo de trabajo, consulte Crear un grupo de trabajo en la Guía del usuario de Amazon Athena. Para obtener más información sobre los buckets de pago por solicitante, consulte Buckets de pago por solicitante en la Guía para desarrolladores de Amazon Simple Storage Service.
9 de agosto de 2019
Publicado el 17/12/2019
Amazon Athena admite ahora la aplicación de las políticas de AWS Lake Formation
Puede utilizar esta característica en las siguientes Regiones de AWS: Este de EE. UU. (Ohio), Este de EE. UU. (Norte de Virginia), Oeste de EE. UU. (Oregón), Asia-Pacífico (Tokio) y Europa (Irlanda). El uso de esta característica no implica costos adicionales.
Para obtener más información sobre cómo usar esta característica, consulte Uso de Athena para consultar datos registrados en AWS Lake Formation. Para obtener más información acerca de AWS Lake Formation, consulte AWS Lake Formation
26 de junio de 2019
Amazon Athena ahora está disponible en la región Europa (Estocolmo). Para obtener una lista de las regiones compatibles, consulte Puntos de conexión y Regiones de AWS.
24 de mayo de 2019
Publicado el 24/05/2019
Amazon Athena ahora está disponible en las regiones AWS GovCloud (Este de EE. UU.) y AWS GovCloud (Oeste de EE. UU.). Para obtener una lista de las regiones compatibles, consulte Puntos de conexión y Regiones de AWS.
05 de marzo de 2019
Publicado el 05/03/2019
Amazon Athena ahora está disponible en la región Canadá (Central). Para obtener una lista de las regiones compatibles, consulte Puntos de conexión y Regiones de AWS. Se lanzó la nueva versión del controlador ODBC con compatibilidad para grupos de trabajo de Athena. Para obtener más información, consulte Notas de la versión del controlador ODBC
Para descargar el nuevo controlador ODBC versión 1.0.5 y su documentación, consulte Conexión a Amazon Athena con ODBC. Para obtener información acerca de esta versión, consulte el tema Notas de la versión del controlador ODBC
Para utilizar grupos de trabajo con el controlador ODBC, establezca la propiedad de la conexión nueva Workgroup, en la cadena de conexión tal y como se muestra en el siguiente ejemplo:
Driver=Simba Athena ODBC Driver;AwsRegion=[Region];S3OutputLocation=[S3Path];AuthenticationType=IAM Credentials;UID=[YourAccessKey];PWD=[YourSecretKey];Workgroup=[WorkgroupName]
Para obtener más información, busque “grupo de trabajo” en la Guía de instalación y configuración de la versión 1.0.5 del controlador ODBC
Esta versión del controlador le permite utilizar las acciones de grupo de trabajo de la API de Athena para crear y administrar grupos de trabajo, y las acciones de etiquetas de la API de Athena para agregar, enumerar o retirar etiquetas de grupos de trabajo. Antes de comenzar, asegúrese de que dispone de permisos de nivel de recursos en IAM para acciones en grupos de trabajo y etiquetas.
Para obtener más información, consulte:
Si utiliza el controlador JDBC o el SDK de AWS, actualice a la versión más reciente del controlador y el SDK, que incluyen compatibilidad para grupos de trabajo y etiquetas en Athena. Para obtener más información, consulte Conexión a Amazon Athena con JDBC.
22 de febrero de 2019
Publicado el 22/02/2019
Se agregó compatibilidad con la etiqueta para grupos de trabajo en Amazon Athena. Una etiqueta consta de una clave y un valor, ambos definidos por el usuario. Al etiquetar un grupo de trabajo, puede asignarle metadatos personalizados. Puede agregar etiquetas a grupos de trabajo para ayudar a categorizarlos siguiendo las prácticas recomendadas para etiquetado de AWS. Puede usar etiquetas para restringir el acceso a los grupos de trabajo y para realizar un seguimiento de los costos. Por ejemplo, cree un grupo de trabajo para cada centro de costos. A continuación, mediante la adición de etiquetas a estos grupos de trabajo, puede hacer un seguimiento del gasto de Athena para cada centro de costos. Para obtener más información, consulte Uso de etiquetas para facturación en la Guía del usuario de Administración de facturación y costos de AWS.
Puede trabajar con etiquetas mediante la consola de Athena o las operaciones de la API. Para obtener más información, consulte Etiquetado de recursos de Athena.
En la consola de Athena, puede agregar una o más etiquetas a cada uno de los grupos de trabajo y buscar por etiquetas. Los grupos de trabajo son un recurso controlado por IAM en Athena. En IAM, puede restringir quién puede agregar, eliminar o enumerar etiquetas en los grupos de trabajo que cree. También puede utilizar la operación de la API CreateWorkGroup que tiene el parámetro de etiqueta opcional para añadir una o varias etiquetas al grupo de trabajo. Para añadir, eliminar o enumerar etiquetas, utilice TagResource, UntagResource y ListTagsForResource. Para obtener más información, consulte Uso de operaciones de etiquetas de la AWS CLI y API.
Para permitir que los usuarios agreguen etiquetas al crear grupos de trabajo, asegúrese de que proporciona a cada usuario permisos de IAM a las acciones de la API TagResource y CreateWorkGroup. Para obtener más información y ejemplos, consulta Uso de políticas de control de acceso de IAM basado en etiquetas.
No se hacen cambios en el controlador JDBC cuando se utilizan etiquetas en grupos de trabajo. Si crea nuevos grupos de trabajo y utiliza el controlador JDBC o el SDK de AWS, deberá obtener la versión más reciente del controlador y del SDK. Para obtener más información, consulta Conexión a Amazon Athena con JDBC.
18 de febrero de 2019
Publicado el 18/02/2019
Se añadió la capacidad de controlar los costos de las consultas mediante la ejecución de consultas en grupos de trabajo. Para obtener más información, consulta Uso de grupos de trabajo para controlar el acceso a las consultas y los costos. Se ha mejorado el JSON OpenX SerDe utilizado en Athena, se ha corregido un problema que hacía que Athena no ignorara los objetos que hacían la transición a la clase de almacenamiento GLACIER y se han agregado ejemplos para realizar consultas a registros del Network Load Balancer.
Se realizaron los siguientes cambios:
-
Se añadió compatibilidad para grupos de trabajo. Utilice grupos de trabajo para separar usuarios, equipos, aplicaciones o cargas de trabajo y establecer límites en la cantidad de datos que puede procesar cada consulta o todo el grupo de trabajo. Como los grupos de trabajo funcionan como recursos de IAM, puede utilizar permisos de nivel de recursos para controlar el acceso a un grupo de trabajo específico. También puede ver métricas relacionadas con las consultas en Amazon CloudWatch, controlar los costos de las consultas mediante la configuración de los límites de la cantidad de datos escaneados, crear los umbrales y desencadenar acciones, como alarmas de Amazon SNS, cuando se superan estos umbrales. Para obtener más información, consulte Uso de grupos de trabajo para controlar el acceso a las consultas y los costos y Uso de CloudWatch y EventBridge para la supervisión de consultas y la administración de costos.
Los grupos de trabajo son un recurso de IAM. Para obtener una lista completa de acciones relacionadas con grupos de trabajo, recursos y condiciones en IAM, consulte Acciones, recursos y claves de condición de Amazon Athena en la Referencia de autorizaciones de servicio. Antes de crear grupos de trabajo nuevos, asegúrese de que utiliza políticas de IAM para grupos de trabajo y la Política administrada de AWS: AmazonAthenaFullAccess.
Puede utilizar grupos de trabajo en la consola, con las operaciones de la API de grupos de trabajo o con el controlador JDBC. Para obtener información acerca de la creación de grupos de trabajo, consulte Creación de un grupo de trabajo. Para descargar el controlador JDBC con compatibilidad para grupo de trabajo, consulte Conexión a Amazon Athena con JDBC.
Si utiliza grupos de trabajo con el controlador JDBC, debe establecer el nombre de grupo de trabajo en la cadena de conexión mediante el parámetro de configuración
Workgrouptal y como se muestra en el siguiente ejemplo:jdbc:awsathena://AwsRegion=<AWSREGION>;UID=<ACCESSKEY>; PWD=<SECRETKEY>;S3OutputLocation=s3://amzn-s3-demo-bucket/<athena-output>-<AWSREGION>/; Workgroup=<WORKGROUPNAME>;No hay cambios en la forma de ejecutar instrucciones SQL o realizar llamadas a la API de JDBC para el controlador. El controlador pasa el nombre del grupo de trabajo a Athena.
Para obtener más información acerca de las diferencias introducidas con grupos de trabajo, consulte Uso de las API de grupos de trabajo de Athena y Resolución de errores de grupos de trabajo.
-
Se mejoró el SerDe JSON de OpenX utilizado en Athena. Las mejoras incluyen, entre otras, lo siguiente:
-
Compatibilidad para la propiedad
ConvertDotsInJsonKeysToUnderscores. Cuando se estableceTRUE, permite que SerDe sustituya los puntos en los nombres de claves con guiones bajos. Por ejemplo, si el conjunto de datos de JSON contiene una clave con el nombre"a.b", puede utilizar esta propiedad para definir el nombre de la columna para que sea"a_b"en Athena. El valor predeterminado esFALSE. De forma predeterminada, Athena no permite puntos en los nombres de columnas. -
Compatibilidad para la propiedad
case.insensitive. De forma predeterminada, Athena exige que todas las claves de su conjunto de datos JSON utilicen minúscula. El uso deWITH SERDE PROPERTIES ("case.insensitive"= FALSE;)le permite usar nombres de clave que distinguen entre mayúsculas y minúsculas en sus datos. El valor predeterminado esTRUE. Cuando se establece enTRUE, el SerDe convierte todas las columnas en mayúscula a minúscula.
Para obtener más información, consulte SerDe JSON de OpenX.
-
-
Se corrigió un problema por el que Athena devolvía mensajes de error
"access denied"al procesar objetos de Amazon S3 archivados en Glacier por políticas de ciclo de vida de Amazon S3. Al solucionar este problema, Athena ignora objetos que han hecho la transición a la clase de almacenamientoGLACIER. Athena no es compatible con la consulta de datos de la clase de almacenamientoGLACIER.Para obtener más información, consulte Consideraciones sobre Amazon S3 y Transición a la clase de almacenamiento GLACIER (archivo de objetos) en la Guía del usuario de Amazon Simple Storage Service.
-
Se agregaron ejemplos para consultar los registros de acceso del Equilibrador de carga de red que reciben información acerca de las solicitudes de seguridad de la capa de transporte (TLS). Para obtener más información, consulte Consulta de los registros del Equilibrador de carga de red.
Notas de la versión de Athena para 2018
20 de noviembre de 2018
Publicado el 20/11/2018
Se lanzaron las nuevas versiones del controlador JDBC y ODBC con compatibilidad para acceso federado a la API de Athena con Active Directory Federation Services (AD FS) y SAML 2.0 (Lenguaje de marcado para confirmaciones de seguridad 2.0). Para obtener más información, consulte las Notas de la versión del controlador JDBC
Con esta versión, el acceso federado a Athena es compatible con Active Directory Federation Service (AD FS 3.0). El acceso se establece a través de las versiones de los controladores JDBC u ODBC que admiten SAML 2.0. Para obtener información acerca de la configuración del acceso federado a la API de Athena, consulte Habilitación del acceso federado a la API de Athena.
Para descargar el nuevo controlador JDBC versión 2.0.6 y su documentación, consulte Conexión a Amazon Athena con JDBC. Para obtener información acerca de esta versión, consulte el tema Notas de la versión del controlador JDBC
Para descargar el nuevo controlador ODBC versión 1.0.4 y su documentación, consulte Conexión a Amazon Athena con ODBC. Para obtener información acerca de esta versión, consulte el tema Notas de la versión del controlador ODBC
Para obtener más información acerca de la compatibilidad con SAML 2.0 en AWS, consulte Acerca de la federación SAML 2.0 en la Guía del usuario de IAM.
15 de octubre de 2018
Publicado el 15/10/2018
Si ha actualizado a AWS Glue Data Catalog, hay dos nuevas características que proporcionan compatibilidad para:
-
Cifrado de los metadatos del catálogo de datos. Si decide cifrar los metadatos del catálogo de datos, debe agregar las políticas específicas a Athena. Para obtener más información, consulte Acceso a metadatos cifrados del AWS Glue Data Catalog.
-
Permisos detallados para el acceso a recursos de AWS Glue Data Catalog Ahora puede definir políticas basadas en identidad (IAM) que restrinjan o permitan el acceso a bases de datos y tablas específicas del catálogo de datos usado en Athena. Para obtener más información, consulte Configuración del acceso a las bases de datos y tablas en el AWS Glue Data Catalog.
nota
Los datos residen en los buckets de Amazon S3 y el acceso a ellos se rige por el Control del acceso a Amazon S3 desde Athena. Para obtener acceso al contenido de las bases de datos y las tablas, siga utilizando las políticas de control de acceso a los buckets de Amazon S3 donde se almacenan.
10 de octubre de 2018
Publicado el 10/10/2018
Athena admite CREATE TABLE AS SELECT, que crea una tabla a partir del resultado de una instrucción de consulta SELECT. Para obtener información detallada, consulte Creación de una tabla a partir de los resultados de una consulta (CTAS).
Antes de crear consultas CTAS, es importante que conozca su comportamiento, descrito en la documentación de Athena. Esta documentación contiene información acerca de la ubicación para guardar los resultados de las consultas en Amazon S3, la lista de los formatos admitidos para almacenar los resultados de las consultas CTAS, el número de particiones que puede crear y los formatos de compresión admitidos. Para obtener más información, consulte Consideraciones y limitaciones de las consultas CTAS.
Utilice consultas CTAS para:
-
Crear una tabla a partir de los resultados de una consulta en un solo paso.
-
Crear consultas CTAS en la consola de Athena, utilizando los ejemplos. Para obtener información sobre la sintaxis, consulte CREATE TABLE AS.
-
Transformar los resultados de las consultas en otros formatos de almacenamiento, como PARQUET, ORC, AVRO, JSON y TEXTFILE. Para obtener más información, consulte Consideraciones y limitaciones de las consultas CTAS y Uso de formatos de almacenamiento en columnas.
6 de septiembre de 2018
Publicado el 06/09/2018
Se ha publicado la nueva versión del controlador ODBC (versión 1.0.3). La nueva versión del controlador ODBC transmite los resultados de forma predeterminada, en lugar de paginarlos, lo que permite a las herramientas de inteligencia empresarial obtener más rápidamente grandes conjuntos de datos. Esta versión incluye también mejoras, correcciones de errores y una documentación actualizada para “Uso de SSL con un servidor proxy”. Para obtener más información, consulte las notas de la versión
Para descargar el nuevo controlador ODBC versión 1.0.3 y su documentación, consulte Conexión a Amazon Athena con ODBC.
La característica de transmisión de resultados está disponible con esta nueva versión del controlador ODBC. También está disponible con el controlador JDBC. Para obtener más información sobre los resultados de transmisión, consulte la Guía de instalación y configuración del controlador ODBC
La versión 1.0.3 del controlador ODBC sustituye directamente a la versión anterior. Se recomienda migrar al controlador actual.
importante
Para utilizar la versión del controlador ODBC 1.0.3, siga estos requisitos:
-
Mantenga el puerto 444 abierto para el tráfico de salida.
-
Agregue la acción de política
athena:GetQueryResultsStreama la lista de políticas de Athena. Esta acción de política no se expone directamente con la API y solo se utiliza con los controladores ODBC y JDBC como parte de la funcionalidad de resultados en transmisión. Para ver una política de ejemplo, consulte Política administrada de AWS: AWSQuicksightAthenaAccess.
23 de agosto de 2018
Publicado el 23/08/2018
Se agregó compatibilidad para características de DDL y se corrigieron algunos errores, como se indica:
-
Se agregó compatibilidad para los tipos de datos
BINARYyDATEde Parquet y para los tipos de datosDATEyTIMESTAMPde Avro. -
Se agregó compatibilidad para
INTyDOUBLEen las consultas DDL.INTEGERes un alias deINTyDOUBLE PRECISIONes un alias deDOUBLE. -
Mejora del rendimiento de las consultas
DROP TABLEyDROP DATABASE. -
Se eliminó la creación de un objeto
_$folder$en Amazon S3 cuando un bucket de datos está vacío. -
Corregido un problema por el que
ALTER TABLE ADD PARTITIONgeneraba un error cuando no se indicaba un valor de partición. -
Corregido un problema por el que
DROP TABLEno tenía en cuenta el nombre de la base de datos al comprobar las particiones después de haberse especificado el nombre completo en la instrucción.
Para obtener más información sobre los tipos de datos admitidos en Athena, consulte Tipos de datos en Amazon Athena.
Para obtener más información acerca de la asignación entre los tipos de datos admitidos en Athena, el controlador JDBC y los tipos de datos de Java, consulte la sección “Tipos de datos” en la Guía de instalación y configuración del controlador JDBC
16 de agosto de 2018
Publicado el 16/08/2018
Se ha publicado el controlador JDBC versión 2.0.5. La nueva versión del controlador JDBC transmite los resultados de forma predeterminada, en lugar de paginarlos, lo que permite a las herramientas de inteligencia empresarial obtener más rápidamente grandes conjuntos de datos. En comparación con la versión anterior del controlador JDBC, se introducen las siguientes mejoras en el rendimiento:
-
Aproximadamente el doble de rendimiento al recuperar menos de 10 000 filas.
-
Aproximadamente 5 o 6 veces más rendimiento al recuperar más de 10 000 filas.
La característica de transmisión de resultados solo está disponible con el controlador JDBC. No está disponible con el controlador ODBC. No puede utilizarla con la API de Athena. Para obtener más información sobre la transmisión de resultados, consulte la guía de instalación y configuración del controlador JDBC
Para descargar el nuevo controlador JDBC versión 2.0.5 y su documentación, consulte Conexión a Amazon Athena con JDBC.
La versión 2.0.5 del controlador JDBC sustituye directamente a la versión anterior (2.0.2). Para asegurarse de poder utilizar la versión 2.0.5 del controlador JDBC, agregue la acción de política athena:GetQueryResultsStream a la lista de políticas para Athena. Esta acción de política no se expone directamente con la API y solo se utiliza con el controlador JDBC como parte de la funcionalidad de resultados de transmisión. Para ver una política de ejemplo, consulte Política administrada de AWS: AWSQuicksightAthenaAccess. Para obtener más información acerca de cómo migrar de la versión 2.0.2 a la versión 2.0.5 del controlador, consulte la Guía de migración del controlador JDBC
Si va a migrar desde un controlador 1.x a un controlador 2.x, tendrá que migrar las configuraciones existentes a la nueva configuración. Recomendamos encarecidamente que migre a la versión actual del controlador. Para obtener más información, consulte la Guía de migración del controlador JDBC
7 de agosto de 2018
Publicado el 07/08/2018
Ahora puede almacenar directamente registros de flujo de Amazon Virtual Private Cloud en Amazon S3 con formato GZIP, lo que le permite consultarlos en Athena. Para obtener más información, consulte Consulta de los registros de flujo de Amazon VPC y Ahora es posible entregar en S3 los registros de flujo de Amazon VPC
5 de junio de 2018
Publicado el 05/06/2018
Temas
Compatibilidad con vistas
Se ha agregado compatibilidad con vistas. A partir de ahora, puede utilizar CREATE VIEW y CREATE PROTECTED MULTI DIALECT VIEW, DESCRIBE VIEW, DROP VIEW, SHOW CREATE VIEW y SHOW VIEWS en Athena. La consulta que define la vista se ejecuta cada vez que se hace referencia a su vista en su consulta. Para obtener más información, consulte Trabajo con vistas.
Mejoras y actualizaciones de los mensajes de error
-
Incluye una biblioteca GSON 2.8.0 en el CloudTrail SerDe para resolver un problema con el CloudTrail SerDe y habilitar el análisis de cadenas JSON.
-
Mejora de la validación de esquemas de particiones en Athena para Parquet y, en algunos casos, para ORC, al permitir reordenar las columnas. De este modo, Athena puede afrontar mejor los cambios en la evolución de los esquemas y las tablas agregadas por el rastreador de AWS Glue. Para obtener más información, consulte Gestión de las actualizaciones de los esquemas.
-
Se añadió compatibilidad de análisis para
SHOW VIEWS. -
Se realizaron las siguientes mejoras en los mensajes de error más comunes:
-
Se reemplazó un mensaje de
Error internopor un mensaje de error descriptivo cuando un SerDe no logra analizar la columna de una consulta de Athena. Anteriormente, Athena generaba un error interno cuando se producían errores de análisis. El nuevo mensaje de error es el siguiente:HIVE_BAD_DATA: Error parsing field value for field 0: java.lang.String cannot be cast to org.openx.data.jsonserde.json.JSONObject. -
Se mejoraron los mensajes de error acerca de la falta de permisos añadiendo más detalles.
-
Correcciones de errores
Se corrigieron los siguientes errores:
-
Se solucionó un problema que permite la traducción interna de tipos de datos
REALaFLOAT. Esto mejora la integración con el rastreador de AWS Glue, que devuelve tipos de datosFLOAT. -
Se corrigió un problema que hacía que Athena no convirtiera
DECIMALde AVRO (un tipo lógico) a un tipoDECIMAL. -
Se corrigió un problema que hacía que Athena no devolviera resultados para las consultas de datos Parquet con cláusulas
WHEREque hacían referencia a valores con el tipo de datosTIMESTAMP.
17 de mayo de 2018
Publicado el 17/05/2018
Se incrementó la cuota de consultas simultáneas en Athena de cinco a veinte. Esto significa que puede enviar y ejecutar hasta veinte consultas DDL y veinte consultas SELECT a la vez. Tenga en cuenta que las cuotas de simultaneidad son independientes para las consultas DDL y SELECT.
Las cuotas de simultaneidad en Athena se definen como el número de consultas que se puede enviar al servicio de forma simultánea. Puede enviar hasta veinte consultas del mismo tipo (DDL o SELECT) de forma simultánea. Si envía una consulta que supera la cuota de consultas simultáneas, la API de Athena muestra un mensaje de error.
Una vez enviadas las consultas a Athena, este las procesa y les asigna recursos en función de la carga de servicio general y la cantidad de solicitudes entrantes. Monitorizamos de forma continua y realizamos ajustes del servicio para que sus consultas se procesen con la mayor rapidez posible.
Para obtener más información, consulta Service Quotas. Esta es una cuota ajustable. Puede utilizar la consola Service Quotas
19 de abril de 2018
Publicado el 19/04/2018
Se lanzó la nueva versión del controlador JDBC (versión 2.0.2) que permite devolver los datos de ResultSet como un tipo de datos Array, e incluye mejoras y correcciones de errores. Para obtener más información, consulte las notas de la versión
Para obtener información acerca de la descarga del nuevo controlador JDBC versión 2.0.2 y tener acceso a su documentación, consulte Conexión a Amazon Athena con JDBC.
La última versión del controlador JDBC es la 2.0.2. Si va a migrar desde un controlador 1.x a un controlador 2.x, tendrá que migrar las configuraciones existentes a la nueva configuración. Recomendamos encarecidamente que migre al controlador actual.
Para obtener información sobre los cambios introducidos en la nueva versión del controlador, conocer las diferencias entre las distintas versiones y ver ejemplos, consulte el documento Guía de migración del controlador JDBC
6 de abril de 2018
Publicado el 06/04/2018
Utilice la función de autocompletar para introducir las consultas en la consola de Athena.
15 de marzo de 2018
Publicado el 15/03/2018
Se agregó la capacidad de crear tablas de Athena de manera automática para archivos de registro de CloudTrail directamente desde la consola de CloudTrail. Para obtener más información, consulta Uso de la consola de CloudTrail para crear una tabla de Athena para registros de CloudTrail .
2 de febrero de 2018
Publicado el 12/02/2018
Se ha añadido la capacidad de descargar de forma segura datos intermedios en disco para consultas con uso intensivo de memoria que utilicen la cláusula GROUP BY. Esto mejora la fiabilidad de dichas consultas, para evitar los errores “Recurso de consulta agotado”.
19 de enero de 2018
Publicado el 19/01/2018
Athena utiliza Presto, un motor de consultas distribuido de código abierto, para ejecutar consultas.
Con Athena, no hay que administrar versiones. Hemos actualizado de forma transparente el motor subyacente en Athena a una versión basada en la versión 0.172 de Presto. No tiene que hacer nada.
Con la actualización, ahora puede usar las funciones y operadores de Presto 0.172, incluidas las expresiones Lambda de Presto 0.172 en Athena.
Las principales actualizaciones de esta versión, incluidas las correcciones a las que ha contribuido la comunidad, incluyen:
-
Compatibilidad para no tener en cuenta los encabezados. Puede utilizar la propiedad
skip.header.line.countal definir tablas para permitir que Athena no tenga en cuenta los encabezados. Se admite para las consultas que utilizan el LazySimpleSerDe y el SerDe de OpenCSV, pero no para Grok o Regex SerDes. -
Compatibilidad con el tipo de datos
CHAR(n)en las funcionesSTRING. El intervalo deCHAR(n)es[1.255], mientras que el intervalo de queVARCHAR(n)es[1,65535]. -
Compatibilidad con subconsultas correlacionadas.
-
Compatibilidad con funciones y expresiones Lambda de Presto.
-
Mejor rendimiento de los operadores y el tipo
DECIMAL. -
Compatibilidad con agregaciones filtradas como
SELECT sum(col_name) FILTER, dondeid > 0. -
Predicados de inserción abajo para los tipos de datos
DECIMAL,TINYINT,SMALLINTyREAL. -
Compatibilidad con los predicados de comparación de cuantificación:
ALL,ANYySOME. -
Se añadieron las funciones:
arrays_overlap(), array_except(), levenshtein_distance(), codepoint(), skewness(), kurtosis()y typeof(). -
Se añadió una variante de la función
from_unixtime()que toma un argumento de zona horaria. -
Se añadieron las funciones de agregación
bitwise_and_agg()y bitwise_or_agg(). -
Se añadieron las funciones
xxhash64()y to_big_endian_64(). -
Se añadió compatibilidad con comillas o barras diagonales inversas de escape utilizando una barra diagonal inversa con un subíndice de ruta JSON a las funciones
json_extract()y json_extract_scalar(). Esto cambia la semántica de cualquier invocación que utilice una barra diagonal inversa, ya que anteriormente dichas barras se trataban como caracteres normales.
Para obtener una lista completa de las funciones y los operadores, consulte Consultas, funciones y operadores de DML en esta guía y Funciones y operadores
Athena no es compatible con todas las características de Presto. Para obtener más información, consulte la sección sobre Límites.
Notas de la versión de Athena para 2017
13 de noviembre de 2017
Publicado el 13/11/2017
Se añadió compatibilidad para conectar Athena al controlador ODBC. Para obtener más información, consulta Conexión a Amazon Athena con ODBC.
1 de noviembre de 2017
Publicado el 01/11/2017
Se añadió compatibilidad con consultas de datos geoespaciales y con las regiones de Asia-Pacífico (Seúl), Asia-Pacífico (Bombay) y UE (Londres). Para obtener más información, consulte Consulta de datos geoespaciales y Puntos de conexión y Regiones de AWS.
19 de octubre de 2017
Publicado el 19/10/2017
Se añadió compatibilidad con la región UE (Fráncfort). Para obtener una lista de las regiones compatibles, consulte Puntos de conexión y Regiones de AWS.
3 de octubre de 2017
Publicado el 03/10/2017
Se han creado consultas de Athena con nombre por medio de AWS CloudFormation. Para obtener más información, consulte AmazonWebService::Athena::NamedQuery en la Guía del usuario de AWS CloudFormation.
25 de septiembre de 2017
Publicado el 25/09/2017
Se añadió compatibilidad con la región de Asia-Pacífico (Sídney). Para obtener una lista de las regiones compatibles, consulte Puntos de conexión y Regiones de AWS.
14 de agosto de 2017
Publicado el 14/08/2017
Se agregó integración con AWS Glue Data Catalog y un asistente de migración para actualizar del catálogo de datos administrado por Athena a AWS Glue Data Catalog. Para obtener más información, consulte Utilice AWS Glue Data Catalog para conectarse a los datos.
4 de agosto de 2017
Publicado el 04/08/2017
Se añadió compatibilidad con el SerDe de Grok, que proporciona una asociación de patrones más sencilla de los registros que se encuentran en archivos de texto no estructurados como registros. Para obtener más información, consulte El SerDe de Grok. Se añadieron métodos abreviados de teclado para desplazarse por el historial de consultas utilizando la consola (CTRL+⇧/⇩ con Windows, CMD+⇧/⇩ con Mac).
22 de junio de 2017
Publicado el 22/06/2017
Se añadió compatibilidad con las regiones de Asia-Pacífico (Tokio) y Asia-Pacífico (Singapur). Para obtener una lista de las regiones compatibles, consulte Puntos de conexión y Regiones de AWS.
8 de junio de 2017
Publicado el 08/06/2017
Se agregó compatibilidad con la región de Europa (Irlanda). Para obtener más información, consulte Puntos de conexión y Regiones de AWS.
19 de mayo de 2017
Publicado el 19/05/2017
Se agregó una API de Amazon Athena y compatibilidad con la AWS CLI para Athena; se actualizó el controlador JDBC a la versión 1.1.0; se solucionaron varios problemas.
-
Amazon Athena permite la programación de aplicaciones para Athena. Para obtener más información, consulte la sección de referencia de API de Amazon Athena. Los últimos SDK de AWS incluyen compatibilidad para la API de Athena. Para obtener enlaces con la documentación y las descargas, consulte la sección SDK de Herramientas para Amazon Web Services
. -
La AWS CLI contiene nuevos comandos para Athena. Para obtener más información, consulte la sección de referencia de API de Amazon Athena.
-
Un nuevo controlador JDBC 1.1.0 está disponible; es compatible con la nueva API de Athena, así como con las últimas características y correcciones de errores. Descargue el controlador en https://downloads.athena.us-east-1.amazonaws.com/drivers/AthenaJDBC41-1.1.0.jar
. Le recomendamos que realice la actualización al último controlador JDBC de Athena; no obstante, puede seguir utilizando la versión anterior. Las versiones anteriores del controlador no son compatibles con la API de Athena. Para obtener más información, consulte Conexión a Amazon Athena con JDBC. -
Las acciones específicas de instrucciones de políticas de las versiones anteriores de Athena se dejaron de utilizar. Si actualiza a la versión 1.1.0 del controlador JDBC y tiene políticas de IAM administradas por el cliente o insertadas asociadas a usuarios de JDBC, debe actualizar las políticas de IAM. En cambio, las versiones anteriores del controlador JDBC no son compatibles con la API de Athena, por lo que puede especificar únicamente acciones obsoletas en las políticas asociadas a usuarios de la versión anterior de JDBC. Por este motivo, no debería necesitar actualizar las políticas de IAM insertadas o administradas por el cliente.
-
Estas acciones específicas de la política se utilizaban en Athena antes del lanzamiento de la API de Athena. Estas acciones obsoletas deben usarse únicamente en políticas con versiones del controlador JDBC anteriores a la 1.1.0. Si actualiza el controlador JDBC, sustituya las instrucciones de política que permiten o deniegan acciones obsoletas por las acciones correspondientes de la API como se indica, o se producirán errores:
| Acción específica de política obsoleta | Acción de la API de Athena correspondiente |
|---|---|
|
|
|
|
|
|
Mejoras
-
Se aumentó la longitud de la cadena de consulta a 256 KB.
Correcciones de errores
-
Se corrigió un error que hacía que los resultados de las consultas parecieran tener un formato erróneo cuando el usuario se desplazaba por los resultados en la consola.
-
Se corrigió un error en el que una cadena de caracteres
\u0000de archivos de datos de Amazon S3 provocaba errores. -
Se corrigió un error que hacía que las solicitudes de cancelación de una consulta realizada a través del controlador JDBC generaran un error.
-
Se corrigió un error que hacía que el SerDe de AWS CloudTrail generara un error con datos de Amazon S3 en la región Este de EE. UU. (Ohio).
-
Se corrigió un error que hacía que
DROP TABLEgenerara un error en tablas con particiones.
4 de abril de 2017
Publicado el 04/04/2017
Se ha añadido compatibilidad con el cifrado de datos de Amazon S3 y se ha publicado una actualización del controlador JDBC (versión 1.0.1) con compatibilidad con el cifrado, mejoras y correcciones de errores.
Características
-
Se añadieron las siguientes características de cifrado:
-
Compatibilidad con la consulta de datos cifrados en Amazon S3.
-
Compatibilidad con el cifrado de los resultados de consultas de Athena.
-
-
Una nueva versión del controlador es compatible con las nuevas características de cifrado, añade mejoras y corrige problemas.
-
Se añadió la capacidad para añadir, reemplazar y cambiar columnas utilizando
ALTER TABLE. Para obtener más información, consulte la sección sobre cómo alterar columnasen la documentación de Hive. -
Se añadió compatibilidad para consultar datos comprimidos mediante LZO.
Para obtener más información, consulte Cifrado en reposo.
Mejoras
-
Mejor rendimiento de las consultas de JDBC con mejoras de tamaño de página, se devuelven 1000 filas en lugar de 100.
-
Se añadió la capacidad de cancelar una consulta mediante la interfaz del controlador JDBC.
-
Se añadió la capacidad de especificar opciones de JDBC en la URL de conexión de JDBC. Consulte Conexión a Amazon Athena con JDBC para obtener el controlador JDBC más reciente.
-
Se agregó la configuración PROXY al controlador, que ahora se puede establecer utilizando ClientConfiguration en el AWS SDK para Java.
Correcciones de errores
Se corrigieron los siguientes errores:
-
Se producían errores de limitación controlada cuando se emitían varias consultas con la interfaz del controlador JDBC.
-
El controlador JDBC se detenía al proyectar un tipo de datos decimal.
-
El controlador JDBC devolvía todos los tipos de datos como una cadena, sin tener en cuenta cómo se había definido el tipo de datos en la tabla. Por ejemplo, si seleccionaba una columna definida como tipo de datos
INTmedianteresultSet.GetObject(), se devolvía un tipo de datosSTRINGen lugar deINT. -
El controlador JDBC verificaba las credenciales en el momento en que se realizaba la conexión, en lugar de hacerlo en el momento de ejecución de una consulta.
-
Las consultas realizadas mediante el controlador JDBC generaban un error cuando se especificaba un esquema junto con la dirección URL.
24 de marzo de 2017
Publicado el 24/03/2017
Se agregó el SerDe de AWS CloudTrail, se mejoró el rendimiento y se corrigieron problemas de partición.
Características
-
Se agregó el SerDe de AWS CloudTrail, que desde entonces ha sido reemplazado por el El SerDe JSON de Hive para leer los registros de CloudTrail. Para obtener más información sobre la consulta de registros de CloudTrail, consulte Consulta de registros de AWS CloudTrail.
Mejoras
-
Se mejoró el rendimiento cuando se analiza un gran número de particiones.
-
Se mejoró el rendimiento en la operación
MSCK Repair Table. -
Se añadió la capacidad de consultar datos de Amazon S3 almacenados en regiones distintas de la región principal. Se aplican tasas estándar de transferencia de datos entre regiones para Amazon S3, además de las tasas estándar de Athena.
Correcciones de errores
-
Se corrigió un error del tipo “No se encontró la tabla” que podía producirse si no se cargaban particiones.
-
Se corrigió un error para evitar que se produzca una excepción con las consultas
ALTER TABLE ADD PARTITION IF NOT EXISTS. -
Se corrigió un error en
DROP PARTITIONS.
20 de febrero de 2017
Publicado el 20/02/2017
Se agregó compatibilidad para AvroSerDe y OpenCSVSerDe, la región Este de EE. UU. (Ohio) y la edición masiva de columnas en el asistente de la consola. Se ha mejorado el rendimiento en las tablas Parquet grandes.
Características
-
Se introdujo compatibilidad con los nuevos SerDes:
-
Lanzamiento para la región Este de EE. UU. (Ohio) (us-east-2). Ahora ya puede ejecutar consultas en esta región.
-
A partir de ahora, puede utilizar el formulario Crear tabla a partir de datos de bucket de S3 para definir esquemas de tablas en lote. En el editor de consultas, elija Crear, Datos del bucket de S3 y luego Agregar columnas por lotes en la sección Detalles de columna.
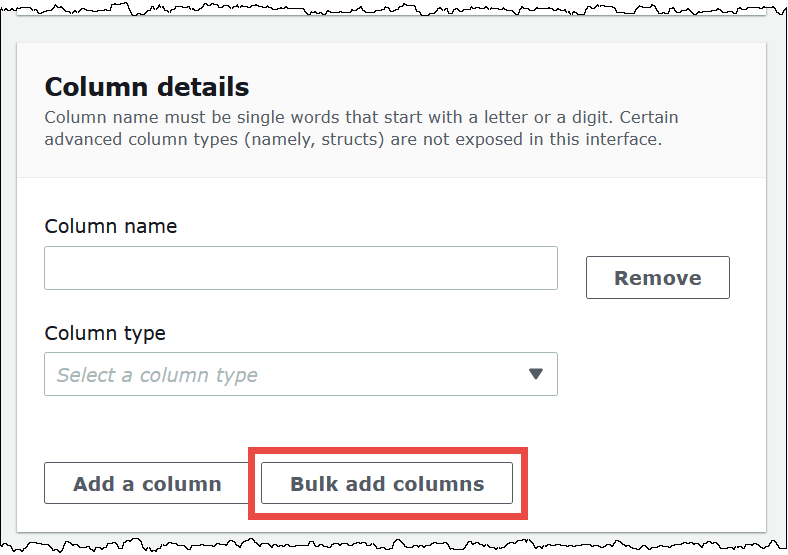
Escriba los pares de valor y nombre en el cuadro de texto y elija Añadir.
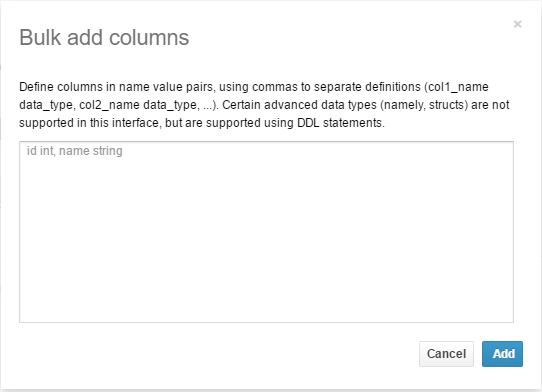
Mejoras
-
Se ha mejorado el rendimiento en las tablas Parquet grandes.
