本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
在 Amazon Aurora Global Database 中使用切換或容錯移轉
相較於 Aurora 資料庫叢集在單一 中提供的標準高可用性,Aurora Global Database 功能提供更多的業務持續性和災難復原 (BCDR) 保護 AWS 區域。透過使用 Aurora Global Database,您可以計劃更快地從罕見、意外的區域性災難復原,或快速完成服務層級中斷。
您可以使用 Aurora Global Database 功能,參閱下列指引和程序來規劃、測試和實作 BCDR 策略。
主題
規劃業務持續性和災難復原
為了規劃您的業務持續性和災難復原策略,了解下列產業術語以及這些術語與 Aurora Global Database 功能的關係會很有幫助。
災難復原通常是由以下兩個業務目標推動:
-
復原時間點目標 (RTO) - 系統在災難發生或服務中斷後傳回工作狀態所需的時間。換言之,RTO 會測量停機時間。對於 Aurora Global Database,RTO 的順序可以是分鐘。
-
復原點目標 (RPO) - 在災難發生或服務中斷後可能遺失的資料量 (以時間為單位)。此資料遺失通常是因為非同步複寫延遲所致。對於 Aurora 全域資料庫,RPO 通常以秒為單位進行測量。使用 Aurora PostgreSQL– 全域資料庫,您可以使用
rds.global_db_rpo參數來設定和追蹤 RPO 上限,但這麼做可能會影響主要叢集寫入器節點上的交易處理。如需詳細資訊,請參閱管理 Aurora PostgreSQL – 全域資料庫的 RPO。
使用 Aurora Global Database 執行切換或容錯移轉需要將次要資料庫叢集提升為主要資料庫叢集。「區域中斷」一詞通常用來描述各種故障情況。最壞的情況可能是影響數百平方英里的災難性事件導致大規模中斷。不過,大多數中斷都較侷限在本地,只會影響一小部分的雲端服務或客戶系統。請考量完整的中斷範圍,以確定跨區域容錯移轉是適當的解決方案,並選擇適當的容錯移轉方法來因應此情況。應該使用容錯移轉或轉換方法,取決於特定中斷案例:
-
容錯移轉 - 使用此方法從意外中斷的情況復原。使用此方法時,您會以 Aurora 全球資料庫中的次要資料庫叢集之一為目標,進行跨區域容錯移轉。此方法的 RPO 通常是以秒為單位測量的非零值。資料遺失量取決於失敗 AWS 區域 時跨 的 Aurora 全域資料庫複寫延遲。如需詳細資訊,請參閱 從計劃外中斷復原 Amazon Aurora 全域資料庫。
-
切換 – 此操作先前稱為「受管計劃容錯移轉」。將此方法用於受控案例,例如操作維護和其他計劃的操作程序,其中與其互動的所有 Aurora 叢集和其他服務都處於良好狀態。由於此功能會將次要資料庫叢集與主要資料庫叢集同步處理,再做出任何其他變更,因此 RPO 為 0 (不會遺失資料)。如需詳細資訊,請參閱 針對 Amazon Aurora 全球資料庫執行轉換。
注意
您必須先將資料庫執行個體新增至無周邊次要 Aurora 資料庫叢集,才能執行切換或容錯移轉。如需無周邊資料庫叢集的詳細資訊,請參閱 在次要區域中建立無周邊 Aurora 資料庫叢集。
針對 Amazon Aurora 全球資料庫執行轉換
注意
切換先前稱為受管計劃容錯移轉。
透過使用切換,您可以定期變更主要叢集的區域。此方法適用於受控情況,例如操作維護及其他計劃內操作程序。
有三種常見的轉換使用案例。
-
對於特定行業強制實施的「區域輪換」需求。例如,金融服務法規可能希望第 0 層系統切換到不同的區域數個月時間,以確保定期演練災難復原程序。
-
對於多區域「全天候」應用程式。例如,某家公司可能希望根據不同時區的營業時間,在不同區域提供較低的延遲寫入。
-
可作為在容錯移轉後,容錯回復至原始主要區域的零資料遺失方法。
注意
切換旨在用於 Aurora 全域資料庫,其中與其互動的所有 Aurora 叢集和其他服務都處於良好狀態。若要從意外中斷復原,請依照 從計劃外中斷復原 Amazon Aurora 全域資料庫 中適當的程序進行。
只有在主要和次要資料庫叢集具有相同的主要和次要引擎版本時,才能使用 Aurora Global Database 執行受管跨區域切換。根據引擎和引擎版本,修補程式層級可能需要相同,或者修補程式層級可能不同。如需允許具有不同修補程式層級之主要和次要叢集之間這些操作的引擎和引擎版本清單,請參閱 受管跨區域轉換和容錯移轉的修補程式等級相容性。開始轉換之前,請先檢查全域叢集中的引擎版本,以確定它們可支援受管跨區域轉換,並視需要進行升級。
在切換期間,Aurora 會讓所選次要區域中的叢集成為您的主要叢集。切換機制會維護您全域資料庫的現有複寫拓撲:它在相同區域中仍有相同數量的 Aurora 叢集。在 Aurora 開始切換程序之前,它會等待目標次要區域叢集與主要區域叢集完全同步。然後,主要區域中的資料庫叢集會變成唯讀。選擇的次要叢集會將其中一個唯讀節點提升為完整寫入器狀態,允許該次要叢集擔任主要叢集的角色。由於目標次要叢集在程序開始時與主要叢集同步,新的主要叢集會繼續 Aurora 全域資料庫的操作,而不會遺失任何資料。您的資料庫在短時間內無法使用,因為同時間主要叢集和選取的次要叢集會承擔其新角色。
注意
若要在執行切換後管理 Aurora PostgreSQL 的複寫槽,請參閱 管理 Aurora Postgre 的邏輯插槽SQL 。
若要最佳化應用程式可用性,建議您在使用此功能之前先執行下列動作:
-
在非尖峰時段或在寫入主要資料庫叢集最少時,執行此操作。
-
檢查 Aurora 全域資料庫中所有次要 Aurora 資料庫叢集的延遲時間。對於所有 Aurora PostgreSQL 型全球資料庫及 Aurora MySQL 型全球資料庫,從 3.04.0 及更高版本或 2.12.0 及更高版本引擎開始,請使用 Amazon CloudWatch 檢視所有次要資料庫叢集的
AuroraGlobalDBRPOLag指標。對於較低的次要版本 Aurora MySQL 型全球資料庫,請改為檢視AuroraGlobalDBReplicationLag指標。這些指標顯示複寫至次要資料庫叢集與複寫至主要資料庫叢集之間的差距 (以毫秒為單位)。此值與 Aurora 完成轉換所需的時間成正比。因此,延遲值越大,轉換所需的時間越長。當您檢查這些指標時,請從目前的主要叢集執行此操作。如需 Aurora 的 CloudWatch 指標相關詳細資訊,請參閱Amazon Aurora 的叢集層級指標。
-
在切換期間提升的次要資料庫叢集可能具有與舊主要資料庫叢集不同的組態設定。我們建議您在 Aurora 全域資料庫叢集中的所有叢集中保持以下類型的組態設定一致。這樣做有助於將切換後的效能問題、工作負載不相容和其他異常行為降至最低。
-
視需要設定新主要節點的 Aurora 資料庫叢集參數群組 – 當您提升次要資料庫叢集以接管主要角色時,次要節點的參數群組的設定可能會與主要節點不同。如果是這樣,請修改提升的次要資料庫叢集的參數群組,以符合主要叢集的設定。若要瞭解如何操作,請參閱修改 Aurora 全域資料庫的參數。
-
設定監控工具和選項,例如 Amazon CloudWatch Events 和警示 – 根據全域資料庫的需要,為提升的資料庫叢集設定相同的日誌記錄功能、警示等。與參數群組一樣,在轉換程序期間,這些功能的組態不會從主要叢集繼承。某些 CloudWatch 指標 (例如複寫延遲) 僅適用於次要區域。因此,轉換會改變檢視這些指標並對其設定警示的方式,而且可能需要變更任何預先定義的儀表板。如需 Aurora 資料庫叢集和監控的詳細資訊,請參閱 使用 Amazon CloudWatch 監控 Amazon Aurora 指標。
-
設定與其他 AWS 服務的整合 – 如果您的 Aurora 全域資料庫與 AWS 服務整合 AWS Secrets Manager AWS Identity and Access Management,例如 Amazon S3 和 AWS Lambda,請務必視需要設定與這些服務的整合。如需整合 Aurora 全域資料庫與 IAM、Amazon S3 和 Lambda 的詳細資訊,請參閱 將 Amazon Aurora 全域資料庫與其他 AWS 服務搭配使用。若要進一步了解 Secrets Manager,請參閱如何在 AWS Secrets Manager 中自動複寫秘密 AWS 區域
。
-
如果您使用的是 Aurora Global Database 寫入器端點,則不需要變更應用程式中的連線設定。確認 DNS 變更已傳播,而且您可以在新的主要叢集上連線和執行寫入操作。然後,您可以繼續應用程式的完整操作。
假設您的應用程式連線使用舊主要叢集的叢集端點,而不是全域寫入器端點。在這種情況下,請務必變更您的應用程式連線設定,以使用新主要叢集的叢集端點。如果您在建立 Aurora 全域資料庫時接受提供的名稱,則可透過從應用程式中提升叢集的端點字串移除 -ro 來變更端點。例如,當該叢集提升為主要叢集時,次要叢集的端點 my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com 會變成 my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com。
如果您使用的是 RDS Proxy,請務必將應用程式的寫入操作重新導向至與新主要叢集相關聯的代理的適當讀取/寫入端點。此代理端點可能是預設端點或自訂讀取/寫入端點。如需更多資訊,請參閱RDS Proxy 端點如何使用全域資料庫。
您可以使用 AWS Management Console、 AWS CLI或 RDS API 執行 Aurora 全域資料庫切換。
若要在 Aurora 全球資料庫上執行轉換
登入 AWS Management Console ,並在 https://console.aws.amazon.com/rds/
:// 開啟 Amazon RDS 主控台。 -
選擇資料庫,並尋找您要執行切換的 Aurora 全域資料庫。
-
從動作功能表選擇轉換或容錯移轉全球資料庫。
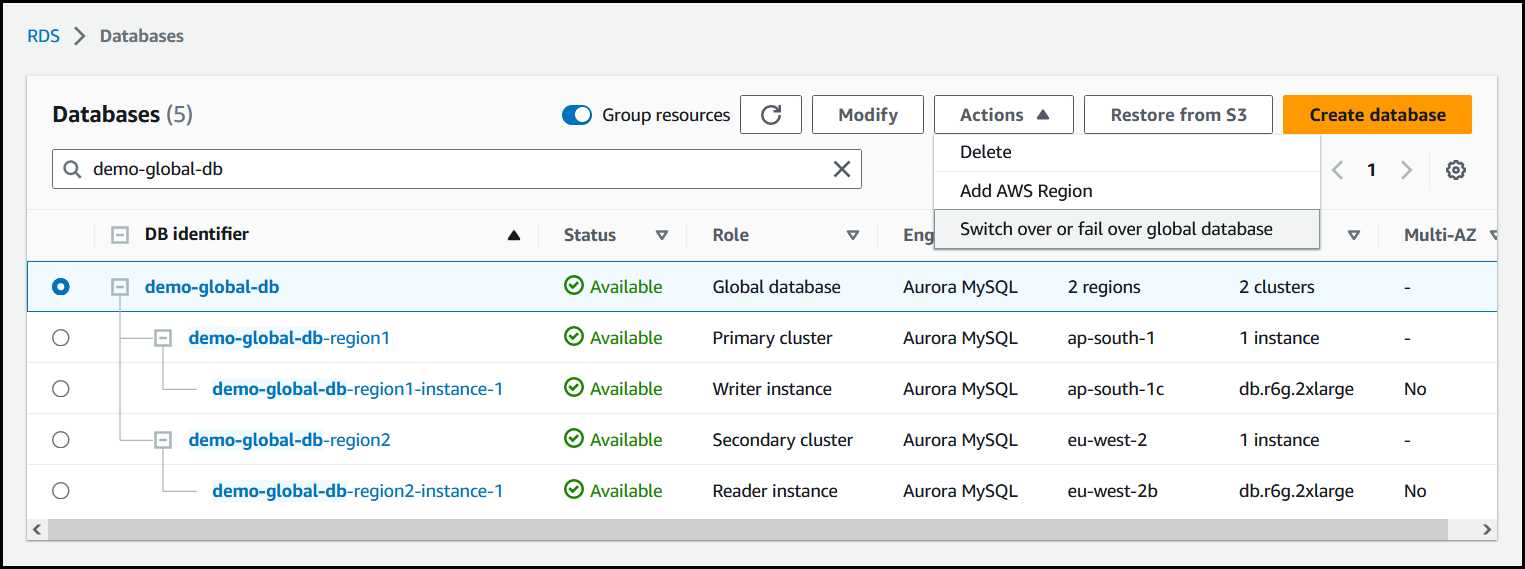
-
選擇轉換。
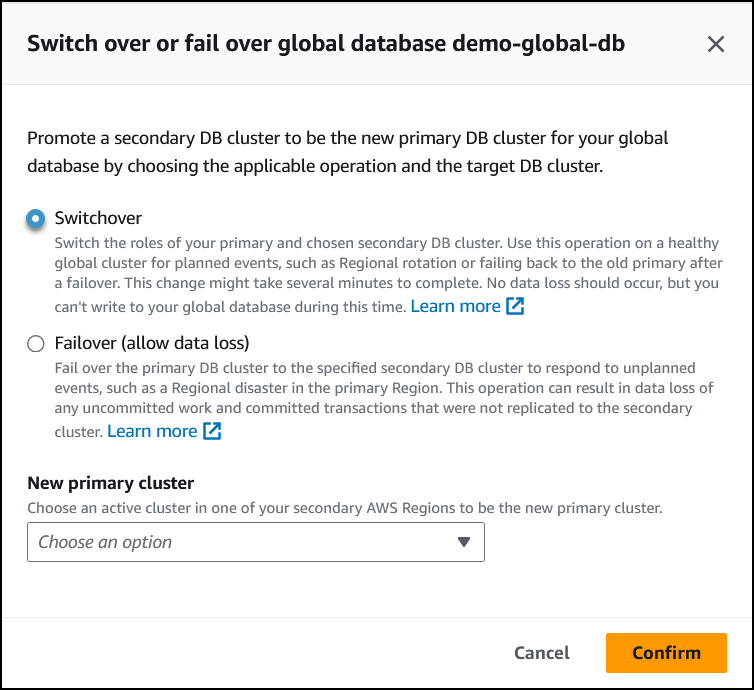
-
對於新的主要叢集,選擇其中一個次要 AWS 區域 中的使用中叢集,使其成為新的主要叢集。
-
選擇確認。
轉換完成後,您可以在資料庫清單中看到 Aurora 資料庫叢集及其目前角色,如下圖所示。
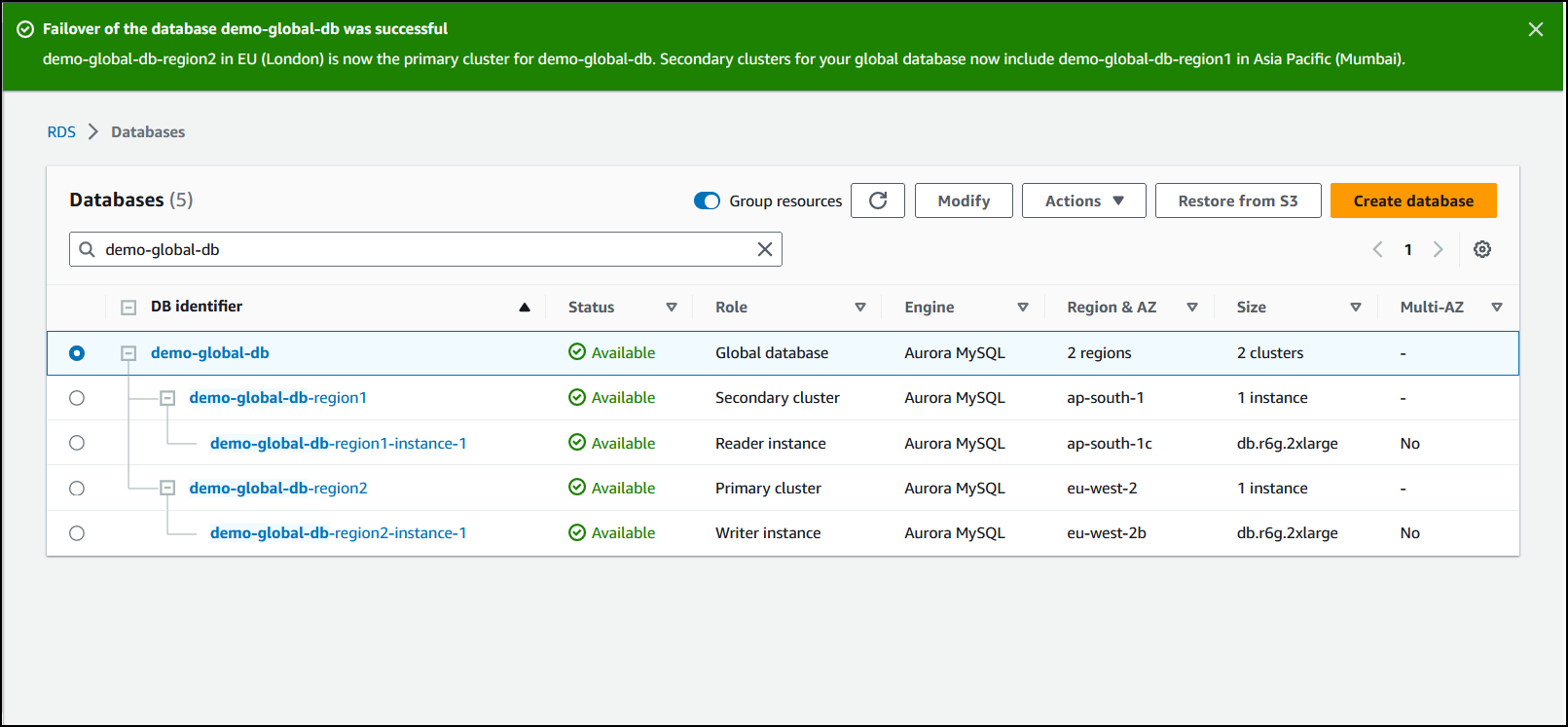
若要在 Aurora 全球資料庫上執行轉換
使用 switchover-global-cluster CLI 命令來執行 Aurora Global Database 的切換。使用命令,傳遞下列參數的值。
-
--region– 指定執行 Aurora 全域資料庫 AWS 區域 主要資料庫叢集的 。 -
--global-cluster-identifier– 指定 Aurora 全域資料庫的名稱。 -
--target-db-cluster-identifier– 指定要提升為 Aurora 全域資料庫之 Aurora 主要資料庫叢集的 Amazon Resource Name (ARN)。
對於 Linux、 macOS或 Unix:
aws rds --regionregion_of_primary\ switchover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote
在 Windows 中:
aws rds --regionregion_of_primary^ switchover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote
若要執行 Aurora Global Database 的切換,請執行 SwitchoverGlobalCluster API 操作。
從計劃外中斷復原 Amazon Aurora 全域資料庫
在極少數情況下,您的 Aurora 全域資料庫可能會在其主要資料庫發生意外中斷 AWS 區域。如果發生此情況,您的主要 Aurora 資料庫叢集及其寫入器節點將無法使用,而主要和次要資料庫叢集之間的複寫也會停止。若要將停機時間 (RTO) 和資料遺失 (RPO) 減至最低,您可以快速執行跨區域容錯移轉。
Aurora Global Database 有兩種容錯移轉方法,可用於災難復原情況:
-
受管容錯移轉 - 建議使用此方法進行災難復原。使用此方法時,當舊的主要區域再次可用時,Aurora 會自動將它新增回全球資料庫做為次要區域。如此便能維持全域叢集的原始拓撲。若要了解如何使用此方法,請參閱 針對 Aurora 全球資料庫執行受管容錯移轉。
-
手動容錯移轉 - 當無法選擇受管容錯移轉時,可以使用此替代方法,例如,當主要和次要區域執行不相容的引擎版本時。若要了解如何使用此方法,請參閱 針對 Aurora 全球資料庫執行手動容錯移轉。
重要
這兩種容錯移轉方法都可能導致未在容錯移轉事件發生之前複寫至所選次要叢集的寫入交易資料遺失。不過,當復原程序將所選次要資料庫叢集上的資料庫執行個體提升為主要主要寫入器資料庫執行個體時,就能保證資料在交易上處於一致狀態。容錯移轉也容易發生大腦分割問題。
針對 Aurora 全球資料庫執行受管容錯移轉
此方法的目的是在發生實際區域災難或服務完全中斷的情況下,提供業務持續性。
在受管容錯移轉期間,所選次要區域中的次要叢集會成為新的主要叢集。選擇的次要叢集會將其中一個唯讀節點提升為完整寫入器狀態。此步驟可讓叢集擔任主要叢集的角色。當此叢集擔任這個新角色時,您的資料庫在短時間內無法使用。一旦舊的主要區域正常運作且再次可用,Aurora 會自動將其新增回全域叢集做為次要區域。因此,會維護 Aurora 全域資料庫的現有複寫拓撲。
注意
若要在執行容錯移轉後管理 Aurora PostgreSQL 的複寫槽,請參閱 管理 Aurora Postgre 的邏輯插槽SQL 。
注意
只有在主要和次要資料庫叢集具有相同的主要和次要引擎版本時,才能使用 Aurora Global Database 執行受管跨區域容錯移轉。根據引擎和引擎版本,修補程式層級可能需要相同,或者修補程式層級可能不同。如需允許具有不同修補程式層級之主要和次要叢集之間這些操作的引擎和引擎版本清單,請參閱 受管跨區域轉換和容錯移轉的修補程式等級相容性。開始容錯移轉之前,請檢查全域叢集中的引擎版本,以確保它們支援受管跨區域切換,並視需要升級。如果您的引擎版本需要相同的修補程式層級,但正在執行不同的修補程式層級,您可以依照中的步驟手動執行容錯移轉針對 Aurora 全球資料庫執行手動容錯移轉。
受管容錯移轉不會等待所選次要區域與目前主要區域之間的資料同步。由於 Aurora Global Database 會以非同步方式複寫資料,因此在提升至接受完整讀取/寫入功能之前,可能並非所有交易都會複寫至所選的次要 AWS 區域。
為了確保資料處於一致狀態,Aurora 會在復原後為舊的主要區域建立新的儲存磁碟區。在區域中建立新的儲存磁碟 AWS 區之前,Aurora 會嘗試在故障時擷取舊儲存磁碟區的快照。如此一來,您就可以還原快照,並從中復原任何遺失的資料。如果此操作成功,Aurora 會將名為 的此快照放置在 的快照區段rds:unplanned-global-failover-中 AWS Management Console。您也可以使用 name-of-old-primary-DB-cluster-timestampdescribe-db-cluster-snapshots AWS CLI 命令或 DescribeDBClusterSnapshots API 操作來查看快照的詳細資訊。
當您啟動受管容錯移轉時,Aurora 也會嘗試透過高可用性的 Aurora 儲存層停止寫入流量。我們將此機制稱為「寫入圍欄」。如果程序成功,Aurora 會發出 RDS 事件,讓您知道寫入已停止。萬一某個區域發生多個可用區故障,寫入圍欄程序可能無法及時成功。在這種情況下,Aurora 會發出 RDS 事件,通知您停止寫入的程序已逾時。如果可以在網路上存取舊的主要叢集,Aurora 會在該處記錄這些事件。如果沒有,Aurora 會在新的主要叢集上記錄事件。若要進一步了解這些事件,請參閱 資料庫叢集事件。由於圍欄寫入是最佳嘗試,因此可能會在舊的主要區域中暫時接受寫入,從而導致分割大腦問題。
建議您先完成下列任務,再使用 Aurora Global Database 執行容錯移轉。這樣做可將分割大腦問題的可能性降至最低,或從舊主要叢集的快照中復原未複寫的資料。
-
若要防止寫入傳送至 Aurora Global Database 的主要叢集,請讓應用程式離線。
-
請確定連線至主要資料庫叢集的任何應用程式都使用全域寫入器端點。即使新的區域因為切換或容錯移轉而成為主要叢集,此端點的值也會保持不變。Aurora 實作額外的保護措施,將透過全域端點提交的寫入操作遺失資料的可能性降至最低。如需全域寫入器端點的詳細資訊,請參閱 連線至 Amazon Aurora Global Database。
-
如果您使用的是全域寫入器端點,且應用程式或聯網層快取 DNS 值,請將 DNS 快取的time-to-live(TTL) 降低為低值,例如 5 秒。如此一來,您的應用程式就能快速向全域寫入器端點註冊 DNS 變更。雖然 Aurora 嘗試封鎖舊主要區域中的寫入,但動作不保證成功。縮短 DNS 快取持續時間可進一步降低大腦分割問題的可能性。或者,您可以檢查 RDS 事件,在 Aurora 觀察到全域寫入器端點的 DNS 變更時通知您。如此一來,您可以在重新啟動應用程式寫入流量之前,驗證您的應用程式是否也已註冊 DNS 變更。
-
檢查 Aurora 全域資料庫中所有次要 Aurora 資料庫叢集的延遲時間。選擇複寫延遲最低的次要區域,即可將目前失敗的主要區域的資料遺失降到最低。
對於所有版本的 Aurora PostgreSQL 型全域資料庫,以及從引擎版本 3.04.0 及更高版本或 2.12.0 及更高版本開始的 Aurora MySQL 型全域資料庫,請使用 Amazon CloudWatch 來檢視所有次要資料庫叢集的
AuroraGlobalDBRPOLag指標。對於較低的次要版本 Aurora MySQL 型全球資料庫,請改為檢視AuroraGlobalDBReplicationLag指標。這些指標顯示複寫至次要資料庫叢集與複寫至主要資料庫叢集之間的差距 (以毫秒為單位)。如需 Aurora 的 CloudWatch 指標相關詳細資訊,請參閱Amazon Aurora 的叢集層級指標。
在受管容錯移轉期間,選擇的次要資料庫叢集會提升為作為主要資料庫叢集的新角色。但是,它不會繼承主要資料庫叢集的各種組態選項。組態不相符可能會導致效能問題、工作負載不相容,以及其他異常行為。若要避免此類問題,建議您針對下列各項解決 Aurora 全域資料庫叢集之間的差異:
-
視需要為新的主要叢集設定 Aurora 資料庫叢集參數群組 – 您可以為 Aurora Global Database 中的每個 Aurora 叢集獨立設定 Aurora 資料庫叢集參數群組。因此,當您提升次要資料庫叢集以接管主要角色時,其參數群組可能會設定與主要資料庫叢集不同的參數群組。如果是這樣,請修改提升的次要資料庫叢集的參數群組,以符合主要叢集的設定。若要瞭解如何操作,請參閱修改 Aurora 全域資料庫的參數。
-
設定監控工具和選項,例如 Amazon CloudWatch Events 和警示 – 根據全域資料庫的需要,為提升的資料庫叢集設定相同的日誌記錄功能、警示等。與參數群組一樣,在容錯移轉程序期間,這些功能的組態不會從主要叢集繼承。某些 CloudWatch 指標 (例如複寫延遲) 僅適用於次要區域。因此,容錯移轉會改變檢視這些指標並對其設定警示的方式,而且可能需要變更任何預先定義的儀表板。如需監控 Aurora 資料庫叢集的詳細資訊,請參閱 使用 Amazon CloudWatch 監控 Amazon Aurora 指標。
-
設定與其他 AWS 服務的整合 – 如果您的 Aurora Global Database 與其他 AWS 服務整合 AWS Secrets Manager AWS Identity and Access Management,例如 Amazon S3 AWS Lambda,而且您需要確保這些服務設定為從任何次要區域存取所需的。如需整合 Aurora 全域資料庫與 IAM、Amazon S3 和 Lambda 的詳細資訊,請參閱 將 Amazon Aurora 全域資料庫與其他 AWS 服務搭配使用。若要進一步了解 Secrets Manager,請參閱如何在 AWS Secrets Manager 中自動複寫秘密 AWS 區域
。
通常,選擇的次要叢集會在幾分鐘內擔任主要角色。一旦新的主要區域的寫入器資料庫執行個體可用,您就可以將應用程式連線到該執行個體,並繼續您的工作負載。Aurora 提升新的主要叢集之後,會自動重建所有其他次要區域叢集。
由於 Aurora 全球資料庫使用非同步複寫,因此每個次要區域的複寫延遲可能有所不同。Aurora 會重建這些次要區域,使其具有與新主要區域叢集完全相同的時間點資料。整個重建工作的期間可能持續幾分鐘到數小時,取決於儲存磁碟區的大小和區域之間的距離。當次要區域叢集從新的主要區域完成重建時,便可供讀取存取使用。
一旦新的主要寫入器進行提升且可用,新的主要區域的叢集就可以處理 Aurora 全球資料庫的讀取和寫入操作。
如果您使用的是 全域端點,則不需要變更應用程式中的連線設定。確認 DNS 變更已傳播,而且您可以在新的主要叢集上連線和執行寫入操作。然後,您可以繼續應用程式的完整操作。
如果您未使用 全域端點,請務必變更應用程式的端點,以使用新提升的主要資料庫叢集的叢集端點。如果您在建立 Aurora 全域資料庫時接受提供的名稱,則可透過從應用程式中提升叢集的端點字串移除 -ro 來變更端點。
例如,當該叢集提升為主要叢集時,次要叢集的端點 my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com 會變成 my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com。
如果您使用 RDS 代理,請務必將應用程式的寫入操作重新導向至與新主要叢集相關聯之代理的適當讀取/寫入端點。此代理端點可能是預設端點或自訂讀取/寫入端點。如需更多資訊,請參閱RDS Proxy 端點如何使用全域資料庫。
為了還原全球資料庫叢集的原始拓撲,Aurora 會監控舊主要區域的可用性。一旦該區域正常運作且再次可用,Aurora 就會自動將它新增回全域叢集作為次要區域。在舊的主要區域中建立新的儲存磁碟區之前,Aurora 會嘗試在故障點拍攝舊儲存磁碟區的快照。這樣做是為了讓您用它來復原任何遺失的資料。如果此操作成功,Aurora 會建立名為 的快照rds:unplanned-global-failover-。您可以在 的快照區段中找到此快照 AWS Management Console。您也會在 DescribeDBClusterSnapshots API 操作傳回的資訊中看到此快照。name-of-old-primary-DB-cluster-timestamp
注意
舊儲存磁碟區的快照是系統快照,會受到舊的主要叢集上設定的備份保留期限的限制。若要在保留期間之外保留此快照,您可以複製該快照並將它儲存為手動快照。若要進一步了解如何複製快照,包括定價在內,請參閱 資料庫叢集快照複製。
原始拓撲還原之後,您可以在最適合您的業務和工作負載時執行轉換操作,將全球資料庫容錯回復至原始主要區域。若要啟用,請依照「針對 Amazon Aurora 全球資料庫執行轉換」中的步驟進行。
您可以使用 AWS CLI、 或 RDS API 對 Aurora Global Database AWS Management Console執行容錯移轉。
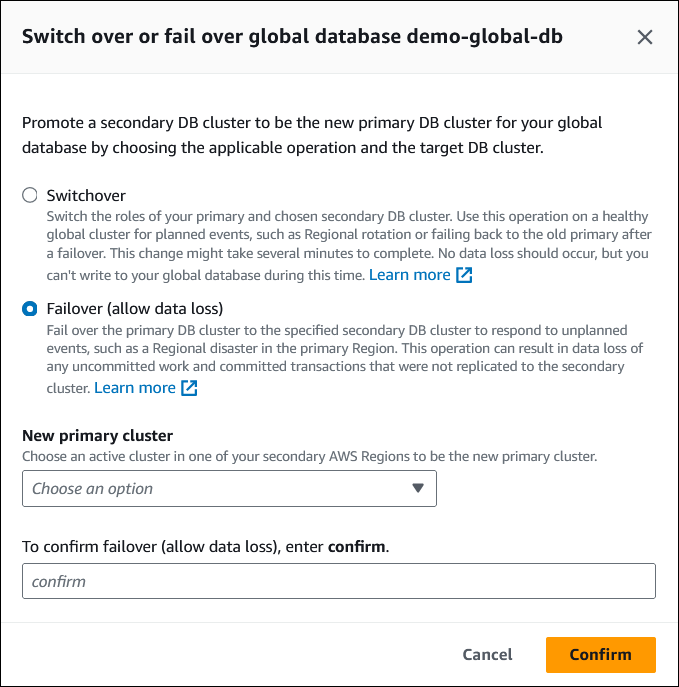
若要在 Aurora 全球資料庫上執行受管容錯移轉
登入 AWS Management Console 並開啟位於 https://https://console.aws.amazon.com/rds/
的 Amazon RDS 主控台。 -
選擇資料庫,並尋找您要執行容錯移轉的 Aurora 全域資料庫。
-
從動作功能表選擇轉換或容錯移轉全球資料庫。
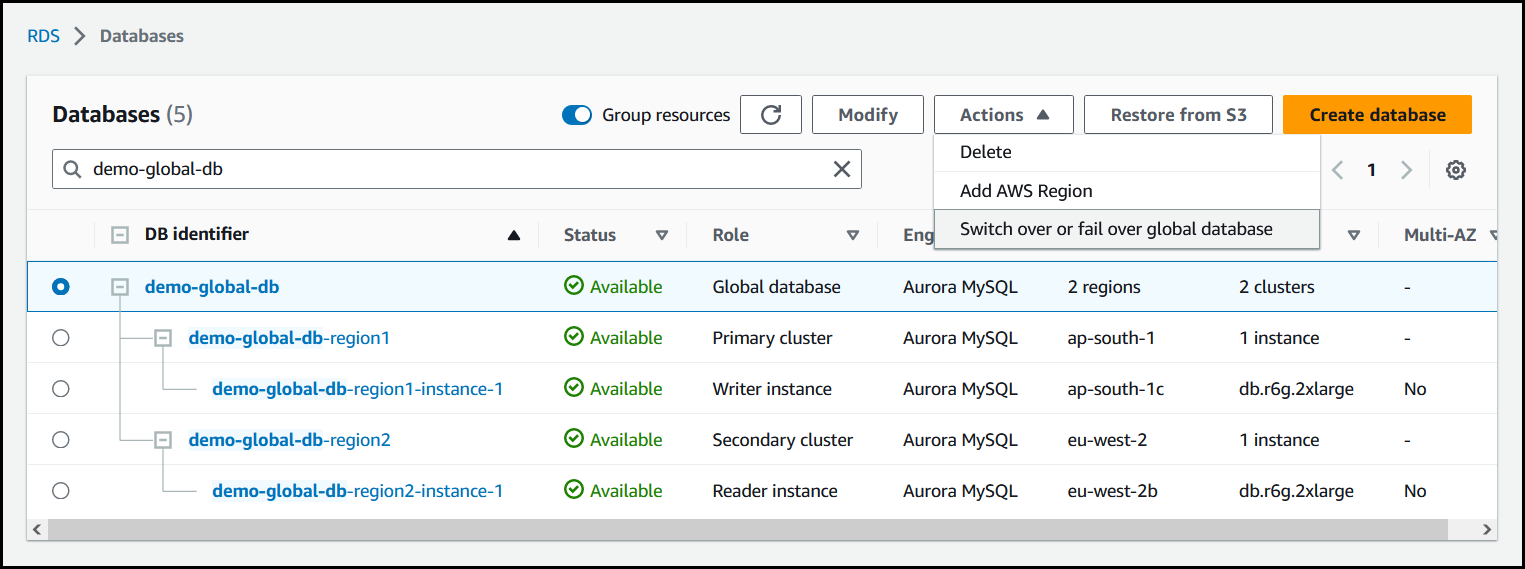
-
選擇容錯移轉 (允許資料遺失)。
-
對於新的主要叢集,選擇其中一個次要 AWS 區域 中的使用中叢集,使其成為新的主要叢集。
-
輸入
confirm,然後選擇確認。
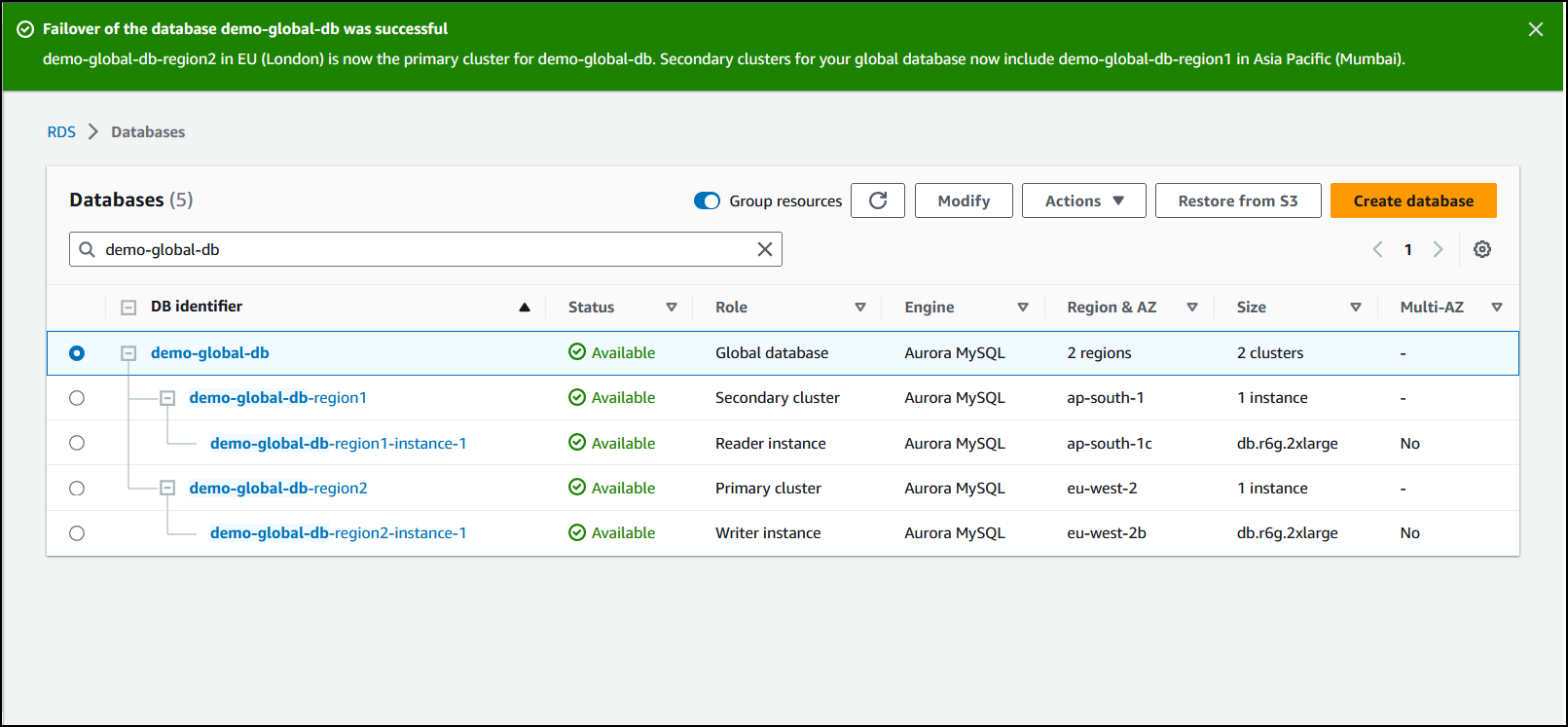
當容錯移轉完成時,您可以在資料庫清單中檢視 Aurora 資料庫叢集及其目前狀態,如下圖所示。
若要在 Aurora 全球資料庫上執行受管容錯移轉
使用 failover-global-cluster CLI 命令透過 Aurora Global Database 執行容錯移轉。使用命令,傳遞下列參數的值。
-
--region– 指定您要成為 Aurora 全域資料庫新主要資料庫叢集執行 AWS 區域 所在的 。 -
--global-cluster-identifier– 指定 Aurora 全域資料庫的名稱。 -
--target-db-cluster-identifier- 指定要提升為 Aurora 全球資料庫的新 Aurora 主要資料庫叢集的 Amazon Resource Name (ARN)。 -
--allow-data-loss- 明確使其成為容錯移轉操作,而不是轉換操作。如果非同步複寫元件尚未完成將所有複寫的資料傳送至次要區域,容錯移轉操作就可能導致部分資料遺失。
對於 Linux、 macOS或 Unix:
aws rds --regionregion_of_selected_secondary\ failover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote\ --allow-data-loss
在 Windows 中:
aws rds --regionregion_of_selected_secondary^ failover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote^ --allow-data-loss
若要使用 Aurora Global Database 執行容錯移轉,請執行 FailoverGlobalCluster API 操作。
針對 Aurora 全球資料庫執行手動容錯移轉
在某些情況下,您可能無法使用受管容錯移轉程序。舉例來說,如果您的主要和次要資料庫叢集未執行相容的引擎版本,就是這種情況。在此情況下,您可以遵循此手動程序來執行容錯移轉至目標次要區域。
提示
我們建議您在使用此程序之前先了解該程序。準備計劃,以便在出現第一個全區域問題跡象時快速執行。您可以使用 Amazon CloudWatch 定期追蹤次要叢集的延遲時間,藉此找出最低複寫延遲的次要區域。請務必測試您的計畫,以檢查程序是否完整且準確,以及員工在真正發生容錯移轉之前接受過災難復原容錯移轉的培訓。
在主要區域中意外中斷之後,執行手動容錯移轉至次要叢集
-
停止發出 DML 陳述式和其他寫入操作給發生中斷 AWS 區域 中的主要 Aurora 資料庫叢集。
-
從次要 識別 Aurora 資料庫叢集 AWS 區域 ,以用作新的主要資料庫叢集。如果您的 AWS 區域 Aurora 全域資料庫中有兩個或更多次要叢集,請選擇複寫延遲最短的次要叢集。
-
從 Aurora 全域資料庫中分離您選擇的次要資料庫叢集。
若從 Aurora 全域資料庫移除次要資料庫叢集,會立即停止從主要資料庫叢集複寫到該次要資料庫叢集,並將其提升為具有完整讀取/寫入功能的獨立佈建 Aurora 資料庫叢集。與發生中斷區域的主要叢集關聯的任何其他次要 Aurora 資料庫叢集仍然可用,並且可以接受應用程式的呼叫。它們也會取用資源。因您正在重新建立 Aurora 全域資料庫,請先移除其他次要資料庫叢集,再在後續步驟中建立新的 Aurora 全域資料庫。這樣可以避免 Aurora 全域資料庫的資料庫叢集之間出現資料不一致的情況 (稱為核心分裂問題)。
如需分離的詳細步驟,請參閱從 Amazon Aurora 全域資料庫中移除叢集。
-
重新設定您的應用程式,以使用其新端點將所有寫入操作傳送至這個目前獨立的 Aurora 資料庫叢集。如果您在建立 Aurora 全域資料庫時接受提供的名稱,則可透過從應用程式中叢集的端點字串移除
-ro來變更端點。例如,當該叢集從 Aurora 全域資料庫分離時,次要叢集的端點
my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com會變成my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com。當您開始在下一個步驟中新增區域時,此 Aurora 資料庫叢集會成為新的 Aurora 全域資料庫的主要叢集。
如果您使用 RDS 代理,請務必將應用程式的寫入操作重新導向至與新主要叢集相關聯之代理的適當讀取/寫入端點。此代理端點可能是預設端點或自訂讀取/寫入端點。如需更多資訊,請參閱RDS Proxy 端點如何使用全域資料庫。
-
將 AWS 區域 新增至資料庫叢集。當您執行這項操作時,從主要到次要的複寫程序即會開始。如需新增區域的詳細步驟,請參閱將 AWS 區域 新增至 Amazon Aurora 全域資料庫。
-
AWS 區域 視需要新增更多 ,以重新建立支援應用程式所需的拓撲。
請確定應用程式寫入會在做出這些變更之前、期間和之後,傳送至正確的 Aurora 資料庫叢集。這樣可以避免 Aurora 全域資料庫的資料庫叢集之間出現資料不一致的情況 (稱為核心分裂問題)。
如果您重新設定 以回應 中的中斷 AWS 區域,您可以在中斷解決之後再次讓 AWS 區域 成為主要 。若要這樣做,請將舊的 新增至 AWS 區域 新的全域資料庫,然後使用切換程序來切換其角色。您的 Aurora 全球資料庫必須使用支援轉換的 Aurora PostgreSQL 或 Aurora MySQL 版本。如需詳細資訊,請參閱針對 Amazon Aurora 全球資料庫執行轉換。
管理 Aurora PostgreSQL – 全域資料庫的 RPO
透過 Aurora PostgreSQL 型全球資料庫,您就可以使用 rds.global_db_rpo 參數來管理 Aurora 全球資料庫的復原點目標 (RPO)。RPO 表示發生中斷時可能遺失的最大資料量。
當您為 Aurora PostgreSQL – 全域資料庫設定 RPO 時,Aurora 會監控所有次要叢集的 RPO 延遲時間,以確定至少有一個次要叢集保留在目標 RPO 視窗。RPO 延遲時間是另一個以時間為基礎的指標。
當您的資料庫在容錯移轉 AWS 區域 後於新的 中恢復操作時,會使用 RPO。Aurora 會評估 RPO 和 RPO 延遲時間,以在主要叢集上遞交 (或封鎖) 交易,如下所示:
-
如果至少有一個次要資料庫叢集的 RPO 延遲時間小於 RPO,則會遞交交易。
-
如果所有次要資料庫叢集的 RPO 延遲時間大於 RPO,則會封鎖交易。它還會將事件記錄到 PostgreSQL 日誌檔案,並發出顯示已封鎖工作階段的「等待」事件。
換言之,如果所有次要叢集都落後於目標 RPO,Aurora 會暫停主要叢集上的交易,直至至少有一個次要叢集追趕上來。至少一個次要資料庫叢集的延遲時間變得小於 RPO 時,暫停的交易即會恢復並進行遞交。因此,在滿足 RPO 之前,沒有任何可以遞交的交易。
此 rds.global_db_rpo 參數是動態的。如果您決定不要讓所有寫入交易都停止,直到延遲降低到足夠的程度,那麼您可以快速重設它。在這種情況下,Aurora 會在經過短暫延遲後,辨識並實作變更。
重要
在只有兩個 AWS 區域的全域資料庫中,我們建議將rds.global_db_rpo參數的預設值保留在次要區域的參數群組中。否則,由於主要 AWS 區域遺失而執行容錯移轉可能會導致 Aurora 暫停交易。相反地,請等到 Aurora 完成重建舊故障 AWS 區域中的叢集,再變更此參數以強制執行最大 RPO。
如果您依照下列所述設定此參數,您也可以監控其產生的指標。您可以使用 psql 或其他工具來查詢 Aurora 全域資料庫的主要資料庫叢集,並取得有關您的 Aurora PostgreSQL – 全域資料庫操作的詳細資訊。若要瞭解如何操作,請參閱監控 Aurora Postgre SQL型全域資料庫。
設定復原點目標
該 rds.global_db_rpo 參數可控制 PostgreSQL 資料庫的 RPO 設定。Aurora PostgreSQL 支援此參數。rds.global_db_rpo 的有效值範圍為 20 秒至 2,147,483,647 秒 (68 年)。選擇符合您的業務需求和應用案例的實際值。例如,您可能想要允許最多 10 分鐘的 RPO,在此情況下,您可以將值設定為 600。
您可以使用 AWS Management Console、 AWS CLI或 RDS API,為 Aurora PostgreSQL 型全域資料庫設定該值。
設定 RPO
登入 AWS Management Console ,並在 https://console.aws.amazon.com/rds/
:// 開啟 Amazon RDS 主控台。 -
選擇 Aurora 全域資料庫的主要叢集,然後開啟 Configuration (組態) 標籤,以尋找其資料庫叢集參數群組。例如,執行 Aurora PostgreSQL 11.7 的主要資料庫叢集的預設參數群組為
default.aurora-postgresql11。無法直接編輯參數群組。而是執行下列動作:
-
使用適當的預設參數群組作為起點,建立自訂資料庫叢集參數群組。例如,根據
default.aurora-postgresql11建立自訂資料庫叢集參數群組。 -
在您的自訂資料庫參數群組上,設定 rds.global_db_rpo 參數的值,以符合您的應用案例。有效值範圍為 20 秒至最大整數值 2,147,483,647 (68 年)。
-
將修改後的資料庫叢集參數群組套用至您的 Aurora 資料庫叢集。
-
如需更多詳細資訊,請參閱 在 Amazon Aurora 中修改資料庫叢集參數群組中的參數。
若要設定 rds.global_db_rpo 參數,請使用 modify-db-cluster-parameter-group CLI 命令。在命令中,指定主要叢集參數群組的名稱和 RPO 參數的值。
下列範例會針對名稱為 my_custom_global_parameter_group 的主要資料庫叢集參數群組,將 RPO 設定為 600 秒 (10 分鐘)。
對於 Linux、 macOS或 Unix:
aws rds modify-db-cluster-parameter-group \ --db-cluster-parameter-group-namemy_custom_global_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
在 Windows 中:
aws rds modify-db-cluster-parameter-group ^ --db-cluster-parameter-group-namemy_custom_global_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
若要修改 rds.global_db_rpo 參數,請使用 Amazon RDS ModifyDBClusterParameterGroup API 操作。
檢視復原點目標
對於每個資料庫叢集,全域資料庫的復原點目標 (RPO) 會存放在 rds.global_db_rpo 參數中。您可以連線至要檢視之次要叢集的端點,並使用 psql 來查詢執行個體的該值。
show rds.global_db_rpo;db-name=>
如果未設定此參數,則查詢會傳回下列項目:
rds.global_db_rpo
-------------------
-1
(1 row)此下一個回應來自具有 1 分鐘 RPO 設定的次要資料庫叢集。
rds.global_db_rpo
-------------------
60
(1 row) 您還可以使用 CLI 來獲取值,來尋找 rds.global_db_rpo 是否在任何 Aurora 資料叢集上啟用,方法是透過使用 CLI 來獲取叢集所有 user 參數的值。
對於 Linux、 macOS或 Unix:
aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-namelab-test-apg-global\ --source user
在 Windows 中:
aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-namelab-test-apg-global* --source user
該命令會傳回所有 user 參數類似於下列各項的輸出。這不是 default-engine 或 system 資料庫叢集參數。
{
"Parameters": [
{
"ParameterName": "rds.global_db_rpo",
"ParameterValue": "60",
"Description": "(s) Recovery point objective threshold, in seconds, that blocks user commits when it is violated.",
"Source": "user",
"ApplyType": "dynamic",
"DataType": "integer",
"AllowedValues": "20-2147483647",
"IsModifiable": true,
"ApplyMethod": "immediate",
"SupportedEngineModes": [
"provisioned"
]
}
]
}
若要進一步了解如何檢視叢集參數群組的參數,請參閱檢視 Amazon Aurora 中資料庫叢集參數群組的參數值。
停用復原點目標
若要停用 RPO,請重設 rds.global_db_rpo 參數。您可以使用 AWS Management Console、 AWS CLI或 RDS API 來重設該參數。
停用 RPO
登入 AWS Management Console ,並在 https://console.aws.amazon.com/rds/
:// 開啟 Amazon RDS 主控台。 -
在導覽窗格中,選擇 Parameter groups (參數群組)。
-
在清單中,選擇主要資料庫叢集參數群組。
-
選擇 Edit parameters (編輯參數)。
-
選擇 rds.global_db_rpo 參數旁的方塊。
-
選擇 Reset (重設)。
-
當畫面顯示 Reset parameters in DB parameter group (重設資料庫參數群組中的參數) 時,選擇 Reset parameters (重設參數)。
如需如何使用主控台重設參數的詳細資訊,請參閱在 Amazon Aurora 中修改資料庫叢集參數群組中的參數。
若要重設 rds.global_db_rpo 參數,請使用 reset-db-cluster-parameter-group 命令。
對於 Linux、 macOS或 Unix:
aws rds reset-db-cluster-parameter-group \ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
在 Windows 中:
aws rds reset-db-cluster-parameter-group ^ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
若要重設 rds.global_db_rpo 參數,請使用 Amazon RDS API ResetDBClusterParameterGroup 操作。
