AWS Glue에서 스트리밍 ETL 작업
지속적으로 실행되고 Amazon Kinesis Data Streams, Apache Kafka 및 Amazon Managed Streaming for Apache Kafka(Amazon MSK)와 같은 스트리밍 소스의 데이터를 사용하는 스트리밍 추출, 변환, 로드 작업을 생성할 수 있습니다. 작업은 데이터를 정리 및 변환한 다음 결과를 Amazon S3 데이터 레이크 또는 JDBC 데이터 스토어에 로드합니다.
또한 Amazon Kinesis Data Streams 스트림용 데이터를 생성할 수 있습니다. 이 기능은 AWS Glue 스크립트를 작성할 때만 사용할 수 있습니다. 자세한 내용은 Kinesis 연결 섹션을 참조하세요.
기본적으로 AWS Glue는 100초 기간에 데이터를 처리하고 작성합니다. 이를 통해 데이터를 효율적으로 처리할 수 있으며 예상보다 늦게 도착하는 데이터에 대해 집계를 수행할 수 있습니다. 이 기간 크기를 수정하여 적시성 또는 집계 정확도를 높일 수 있습니다. AWS Glue 스트리밍 작업은 작업 북마크가 아닌 체크포인트를 사용하여 읽은 데이터를 추적합니다.
참고
AWS Glue는 ETL 스트리밍 작업이 실행되는 동안 시간당 요금을 청구합니다.
이 비디오에서는 스트리밍 ETL 비용 문제와 AWS Glue에서의 비용 절감 기능에 대해 설명합니다.
스트리밍 ETL 작업을 생성하려면 다음 단계를 수행합니다.
-
Apache Kafka 스트리밍 소스의 경우 Kafka 소스 또는 Amazon MSK 클러스터에 대한 AWS Glue 연결을 생성합니다.
-
스트리밍 소스에 대한 Data Catalog 테이블을 수동으로 생성합니다.
-
스트리밍 데이터 원본에 대한 ETL 작업을 생성합니다. 스트리밍 관련 작업 속성을 정의하고 자체 스크립트를 제공하거나 필요에 따라 생성된 스크립트를 수정합니다.
자세한 내용은 AWS Glue의 스트리밍 ETL 섹션을 참조하세요.
Amazon Kinesis Data Streams에 대한 스트리밍 ETL 작업을 생성할 때 AWS Glue 연결을 생성할 필요가 없습니다. 그러나 Kinesis Data Streams를 소스로 포함하는 AWS Glue 스트리밍 ETL 작업에 첨부된 연결이 있는 경우 Kinesis에 대한 Virtual Private Cloud(VPC) 엔드포인트가 필요합니다. 자세한 내용은 Amazon VPC 사용 설명서의 인터페이스 엔드포인트 생성을 참조하세요. 다른 계정에서 Amazon Kinesis Data Streams 스트림을 지정할 때 교차 계정 액세스를 허용하도록 역할과 정책을 설정해야 합니다. 자세한 내용은 예: 다른 계정의 Kinesis 스트림에서 읽기를 참조하세요.
AWS Glue 스트리밍 ETL 작업은 압축된 데이터를 자동으로 감지하고, 스트리밍 데이터를 투명하게 압축 해제할 수 있으며, 입력 소스에 대해 일반적인 변환을 수행하고, 출력 저장소에 로드할 수 있습니다.
AWS Glue에서는 입력 형식에 따라 다음과 같은 압축 유형에 대해 자동 압축 해제를 지원합니다.
| 압축 유형 | Avro 파일 | Avro 데이터 | JSON | CSV | Grok |
|---|---|---|---|---|---|
| bzip2 | 예 | 예 | 예 | 예 | 예 |
| GZIP | 아니요 | 예 | 예 | 예 | 예 |
| Snappy | 예(원시 Snappy) | 예(프레임 처리된 Snappy) | 예(프레임 처리된 Snappy) | 예(프레임 처리된 Snappy) | 예(프레임 처리된 Snappy) |
| XZ | 예 | 예 | 예 | 예 | 예 |
| ZSTD | 예 | 아니요 | 아니요 | 아니요 | 아니요 |
| DEFLATE | 예 | 예 | 예 | 예 | 예 |
주제
Apache Kafka 데이터 스트림에 대한 AWS Glue 연결 생성
Apache Kafka 스트림에서 읽으려면 AWS Glue 연결을 생성해야 합니다.
Kafka 소스에 대한 AWS Glue 연결을 생성하려면(콘솔)
https://console.aws.amazon.com/glue/
에서 AWS Glue 콘솔을 엽니다. -
탐색 창의 데이터 카탈로그에서 연결을 선택합니다.
-
연결 추가를 선택하고 연결 속성 설정 페이지에서 연결 이름을 입력합니다.
참고
연결 속성 지정에 대한 자세한 내용은 AWS Glue 연결 속성을 참조하세요.
-
연결 유형에서 Kafka를 선택합니다.
-
[Kafka 부트스트랩 서버 URL(Kafka bootstrap servers URLs)]에 Amazon MSK 클러스터 또는 Apache Kafka 클러스터용 부트스트랩 브로커의 호스트 및 포트 번호를 입력합니다. Kafka 클러스터에 대한 초기 연결을 설정하려면 전송 계층 보안(TLS) 엔드포인트만 사용합니다. Plaintext 엔드포인트는 지원되지 않습니다.
다음은 Amazon MSK 클러스터의 호스트 이름 및 포트 번호 페어 목록의 예입니다.
myserver1.kafka.us-east-1.amazonaws.com:9094,myserver2.kafka.us-east-1.amazonaws.com:9094, myserver3.kafka.us-east-1.amazonaws.com:9094부트스트랩 브로커 정보 가져오기에 대한 자세한 내용은 Amazon Managed Streaming for Apache Kafka Developer Guide의 Getting the Bootstrap Brokers for an Amazon MSK Cluster를 참조하세요.
-
Kafka 데이터 원본에 대한 보안 연결을 원하는 경우 [SSL 연결 필요(Require SSL connection)]를 선택하고 [Kafka 프라이빗 CA 인증서 위치(Kafka private CA certificate location)]에 사용자 정의 SSL 인증서에 대한 유효한 Amazon S3 경로를 입력합니다.
자체 관리형 Kafka에 대한 SSL 연결의 경우 사용자 정의 인증서가 필수입니다. Amazon MSK의 경우 선택 사항입니다.
Kafka에 대한 사용자 정의 인증서 지정에 대한 자세한 내용은 AWS Glue SSL 연결 속성 섹션을 참조하세요.
-
AWS Glue Studio 또는 AWS CLI를 사용하여 Kafka 클라이언트 인증 방법을 지정합니다. AWS Glue Studio에 액세스하려면 왼쪽 탐색 창의 ETL 메뉴에서 AWS Glue를 선택합니다.
Kafka 클라이언트 인증 방법에 대한 자세한 내용은 클라이언트 인증을 위한 AWS Glue Kafka 연결 속성 단원을 참조하세요.
-
필요에 따라 설명을 입력하고 [다음(Next)]을 선택합니다.
-
Amazon MSK 클러스터의 경우 Virtual Private Cloud (VPC), 서브넷 및 보안 그룹을 지정합니다. 자체 관리형 Kafka의 경우 VPC 정보는 선택 사항입니다.
-
[다음(Next)]을 선택하여 모든 연결 속성을 검토하고 [마침(Finish)]을 선택합니다.
AWS Glue 연결에 대한 자세한 정보는 데이터에 연결 섹션을 참조하세요.
클라이언트 인증을 위한 AWS Glue Kafka 연결 속성
- SASL/GSSAPI(Kerberos) 인증
-
이 인증 방법을 선택하면 Kerberos 속성을 지정할 수 있습니다.
- Kerberos Keytab
-
keytab 파일의 위치를 선택합니다. keytab은 하나 이상의 보안 주체에 대한 장기 키를 저장합니다. 자세한 내용은 MIT Kerberos Documentation: Keytab
(MIT Kerberos 설명서: Keytab)을 참조하세요. - Kerberos krb5.conf 파일(Kerberos krb5.conf file)
-
krb5.conf 파일을 선택합니다. 여기에는 KDC 서버의 기본 영역(동일한 KDC 아래에 있는 시스템 그룹을 정의하는 도메인과 유사한 논리 네트워크)과 위치가 포함됩니다. 자세한 내용은 MIT Kerberos Documentation: krb5.conf
(MIT Kerberos 설명서: krb5.conf)를 참조하세요. - Kerberos 보안 주체 및 Kerberos 서비스 이름(Kerberos principal and Kerberos service name)
-
Kerberos 보안 주체 및 서비스 이름을 입력합니다. 자세한 내용은 MIT Kerberos 설명서: Kerberos 보안 주체
(MIT Kerberos Documentation: Kerberos principal)을 참조하세요. - SASL/SCRAM-SHA-512 인증
-
이 인증 방법을 선택하면 인증 자격 증명을 지정할 수 있습니다.
- AWS Secrets Manager
-
이름 또는 ARN을 입력하여 검색 상자에서 토큰을 검색합니다.
- 사용자 이름 및 암호 직접 제공(Provide username and password directly)
-
이름 또는 ARN을 입력하여 검색 상자에서 토큰을 검색합니다.
- SSL 클라이언트 인증
-
이 인증 방법을 선택하면 Amazon S3를 검색하여 Kafka 클라이언트 키 스토어의 위치를 선택할 수 있습니다. 선택 사항으로 Kafka 클라이언트 키 스토어 암호와 Kafka 클라이언트 키 암호를 입력할 수 있습니다.
- IAM 인증.
-
이 인증 방법은 추가 사양이 필요하지 않으며 스트리밍 소스가 MSK Kafka인 경우에만 적용됩니다.
- SASL/PLAIN 인증
-
이 인증 방법을 선택하면 인증 자격 증명을 지정할 수 있습니다.
스트리밍 소스에 대한 Data Catalog 테이블 생성
데이터 스키마를 포함한 소스 데이터 스트림 속성을 지정하는 데이터 카탈로그 테이블을 스트리밍 소스에 대해 수동으로 생성할 수 있습니다. 이 테이블은 스트리밍 ETL 작업에 대한 데이터 원본으로 사용됩니다.
원본 데이터 스트림에 있는 데이터의 스키마를 모르는 경우 스키마 없이 테이블을 생성할 수 있습니다. 그런 다음 스트리밍 ETL 작업을 생성할 때 AWS Glue 스키마 감지 기능을 설정할 수 있습니다. AWS Glue는 스트리밍 데이터에서 스키마를 결정합니다.
AWS Glue 콘솔
참고
AWS Lake Formation 콘솔을 사용하여 테이블을 생성할 수 없습니다. AWS Glue 콘솔을 사용해야 합니다.
또한 Avro 포맷의 스트리밍 소스 또는 Grok 패턴을 적용할 수 있는 로그 데이터에 대한 다음 정보를 고려합니다.
Kinesis 데이터 원본
테이블 생성 시 다음 스트리밍 ETL 속성(콘솔)을 설정합니다.
- 소스 유형
-
Kinesis
- 동일한 계정에 있는 Kinesis 소스의 경우
-
- 리전
-
Amazon Kinesis Data Streams 서비스가 상주하는 AWS 리전입니다. 리전 및 Kinesis 스트림 이름은 함께 스트림 ARN으로 변환됩니다.
예: https://kinesis.us-east-1.amazonaws.com
- Kinesis 스트림 이름
-
Amazon Kinesis Data Streams Developer Guide의 Creating a Stream에 설명된 스트림 이름입니다.
- 다른 계정의 Kinesis 소스의 경우 이 예를 참조하여 교차 계정 액세스를 허용하도록 역할과 정책을 설정합니다. 다음 설정을 구성합니다.
-
- 스트림 ARN
-
소비자가 등록된 Kinesis 데이터 스트림의 ARN입니다. 자세한 내용은 AWS 일반 참조의 Amazon 리소스 이름(ARN) 및 AWS 서비스 네임스페이스를 참조하세요.
- 수임된 역할 ARN
-
수임할 역할의 Amazon 리소스 이름(ARN)입니다.
- 세션 이름(선택 사항)
-
수임한 역할 세션의 식별자입니다.
역할 세션 이름을 사용하여 다른 보안 주체가 동일한 역할을 수임할 때 또는 다른 이유로 세션을 고유하게 식별합니다. 교차 계정 시나리오에서는 역할을 소유하는 계정이 역할 세션 이름을 보고 로그할 수 있습니다. 역할 세션 이름은 수임한 역할 보안 주체의 ARN에도 사용됩니다. 즉, 임시 보안 자격 증명을 사용하는 후속 교차 계정 API 요청은 역할 세션 이름을 AWS CloudTrail 로그의 외부 계정에 노출합니다.
Amazon Kinesis Data Streams(AWS Glue API 또는 AWS CLI)에 대한 스트리밍 ETL 속성을 설정하려면
-
동일한 계정에서 Kinesis 소스에 대한 스트리밍 ETL 속성을 설정하려면
CreateTableAPI 작업 또는create_tableCLI 명령의StorageDescriptor구조에서streamName및endpointUrl파라미터를 지정합니다."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamName": "sample-stream", "endpointUrl": "https://kinesis.us-east-1.amazonaws.com" } ... }또는
streamARN을 지정합니다."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream" } ... } -
다른 계정에서 Kinesis 소스에 대한 스트리밍 ETL 속성을 설정하려면
CreateTableAPI 작업 또는create_tableCLI 명령의StorageDescriptor구조에서streamARN,awsSTSRoleARN및awsSTSSessionName(선택 사항) 파라미터를 지정합니다."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream", "awsSTSRoleARN": "arn:aws:iam::123456789:role/sample-assume-role-arn", "awsSTSSessionName": "optional-session" } ... }
Kafka 데이터 원본
테이블 생성 시 다음 스트리밍 ETL 속성(콘솔)을 설정합니다.
- 소스 유형
-
Kafka
- Kafka 소스의 경우:
-
- 주제 이름
-
Kafka에 지정된 주제 이름입니다.
- 연결
-
Apache Kafka 데이터 스트림에 대한 AWS Glue 연결 생성에 설명된 대로 Kafka 소스를 참조하는 AWS Glue 연결입니다.
AWS Glue Schema Registry 테이블 소스
AWS Glue Schema Registry를 스트리밍 작업에 사용하려면 사용 사례: AWS Glue Data Catalog에 있는 지침에 따라 Schema Registry 테이블을 생성하거나 업데이트합니다.
현재 AWS Glue 스트리밍은 스키마 추론이 false로 설정된 Glue Schema Registry Avro 포맷만 지원합니다.
Avro 스트리밍 소스에 대한 참고 사항 및 제한 사항
Avro 포맷의 스트리밍 소스에는 다음 참고 및 제한 사항이 적용됩니다.
-
스키마 감지가 설정되어 있으면 Avro 스키마가 페이로드에 포함되어야 합니다. 해제되어 있으면 데이터만 페이로드에 포함되어야 합니다.
-
일부 Avro 데이터 유형은 동적 프레임에서 지원되지 않습니다. AWS Glue 콘솔의 테이블 생성 마법사에서 [스키마 정의(Define a schema)] 페이지를 사용하여 스키마를 정의할 때 이러한 데이터 유형을 지정할 수 없습니다. 스키마 감지 중에 Avro 스키마에서 지원되지 않는 유형은 다음과 같이 지원되는 유형으로 변환됩니다.
-
EnumType => StringType -
FixedType => BinaryType -
UnionType => StructType
-
-
콘솔의 [스키마 정의(Define a schema)] 페이지를 사용하여 테이블 스키마를 정의하는 경우 스키마에 대한 암시적 루트 요소 유형은
record입니다.record이외의 루트 요소 유형(예:array또는map)을 원하는 경우 [스키마 정의(Define a schema)] 페이지를 사용하여 스키마를 지정할 수 없습니다. 대신 해당 페이지를 건너뛰고 테이블 속성으로 또는 ETL 스크립트 내에서 스키마를 지정해야 합니다.-
테이블 속성에서 스키마를 지정하려면 테이블 생성 마법사를 완료하고 테이블 세부 정보를 편집한 다음 [테이블 속성(Table properties)]에서 새 키-값 페어를 추가합니다. 다음 스크린샷과 같이 키
avroSchema를 사용하고 값에 대한 스키마 JSON 객체를 입력합니다.![[테이블 속성(Table properties)] 머리글 아래에는 2개의 텍스트 필드 열이 있습니다. 왼쪽 열 제목은 [키(Key)]이고 오른쪽 열 머리글은 [값(Value)]입니다. 첫 번째 행의 키/값 페어는 classification/avro입니다. 두 번째 행의 키/값 페어는 avroSchema/{"type":"array","items":"string"}입니다.](images/table_properties_avro.png)
-
ETL 스크립트에서 스키마를 지정하려면 다음 Python 및 Scala 예제와 같이
datasource0할당 문을 수정하고avroSchema키를additional_options인수에 추가합니다.
-
스트리밍 소스에 Grok 패턴 적용
로그 데이터 원본에 대한 스트리밍 ETL 작업을 생성하고 Grok 패턴을 사용하여 로그를 정형 데이터로 변환할 수 있습니다. 그러면 ETL 작업은 데이터를 정형 데이터 원본으로 처리합니다. 스트리밍 원본에 대한 Data Catalog 테이블을 생성할 때 적용할 Grok 패턴을 지정합니다.
Grok 패턴 및 사용자 정의 패턴 문자열 값에 대한 자세한 내용은 Grok 사용자 지정 분류자 작성 섹션을 참조하세요.
Data Catalog 테이블에 Grok 패턴 추가(콘솔)
-
테이블 생성 마법사를 사용하여 스트리밍 소스에 대한 Data Catalog 테이블 생성에 지정된 파라미터로 테이블을 생성합니다. 데이터 포맷을 Grok로 지정하고 [Grok 패턴(Grok pattern)] 필드를 채우고 필요에 따라 [사용자 정의 패턴(선택 사항)(Custom patterns (optional))] 아래에 사용자 정의 패턴을 추가합니다.
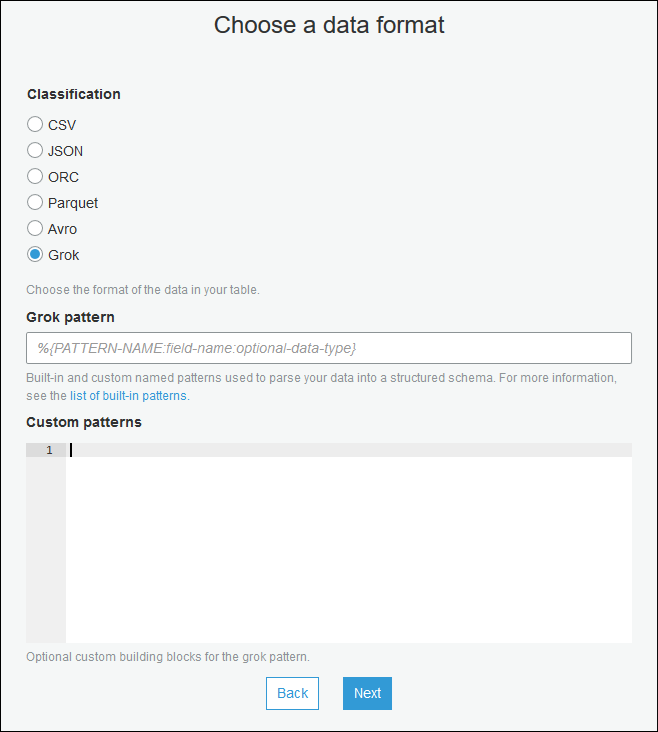
각 사용자 정의 패턴 다음에 Enter 키를 누릅니다.
Data Catalog 테이블에 Grok 패턴 추가(AWS Glue API 또는 AWS CLI)
-
CreateTableAPI 작업 또는create_tableCLI 명령에GrokPattern파라미터와CustomPatterns파라미터(선택 사항)를 추가합니다."Parameters": { ... "grokPattern": "string", "grokCustomPatterns": "string", ... },grokCustomPatterns를 문자열로 표현하고 패턴 사이의 구분 기호로 "\n"을 사용합니다.다음은 이러한 파라미터를 지정하는 예입니다.
"parameters": { ... "grokPattern": "%{USERNAME:username} %{DIGIT:digit:int}", "grokCustomPatterns": "digit \d", ... }
스트리밍 ETL 작업에 대한 작업 속성 정의
AWS Glue 콘솔에서 스트리밍 ETL 작업을 정의할 때 다음 스트림 관련 속성을 제공합니다. 추가 작업 속성에 대한 설명은 Spark 작업에 대한 작업 속성 정의 단원을 참조하십시오.
- IAM 역할
-
작업을 실행하고, 스트리밍 소스에 액세스하고, 대상 데이터 스토어에 액세스하는 데 사용되는 리소스에 대한 권한 부여에 사용되는 AWS Identity and Access Management(IAM) 역할을 지정합니다.
Amazon Kinesis Data Streams에 액세스하려면
AmazonKinesisFullAccessAWS 관리형 정책을 역할에 연결하거나 보다 세분화된 액세스를 허용하는 유사한 IAM 정책을 연결합니다. 샘플 정책은 IAM을 사용하여 Amazon Kinesis Data Streams 리소스에 대한 액세스 제어를 참조하십시오.AWS Glue 작업을 실행하는 권한에 대한 자세한 내용은 AWS Glue의 Identity and Access Management 단원을 참조하세요.
- 유형
-
Spark Streaming을 선택합니다.
- AWS Glue 버전
-
AWS Glue 버전에 따라 작업에 사용할 수 있는 Apache Spark와 Python 또는 Scala의 버전이 정해집니다. 작업에 사용 가능한 Python 또는 Scala 버전을 지정하는 선택 항목을 선택합니다. AWS Glue Python 3을 지원하는 버전 2.0은 스트리밍 ETL 작업의 기본값입니다.
- 유지보수 윈도우
-
스트리밍 작업을 다시 시작할 수 있는 기간을 지정합니다. AWS Glue 스트리밍을 위한 유지 관리 기간을(를) 참조하세요.
- 작업 제한 시간
-
필요에 따라 기간(분)을 입력합니다. 기본값은 빈 상태입니다.
스트리밍 작업의 제한 시간 값은 7일 또는 10,080분 미만이어야 합니다.
값을 비워 두면 유지 관리 기간을 설정하지 않은 경우 7일 후에 작업이 다시 시작됩니다. 유지 관리 기간을 설정한 경우 7일 후 유지 관리 기간에 작업이 다시 시작됩니다.
- 데이터 소스
-
스트리밍 소스에 대한 Data Catalog 테이블 생성에 생성된 테이블을 지정합니다.
- 데이터 대상
-
다음 중 하나를 수행합니다.
-
데이터 대상의 테이블 생성을 선택하고 다음 데이터 대상 속성을 지정합니다.
- 데이터 스토어
-
Amazon S3 또는 JDBC를 선택합니다.
- 형식
-
원하는 포맷을 선택합니다. 스트리밍에 모두 지원됩니다.
-
[데이터 카탈로그의 테이블 사용 및 데이터 대상 업데이트(Use tables in the data catalog and update your data target)]를 선택하고 JDBC 데이터 스토어에 대한 테이블을 선택합니다.
-
- 출력 스키마 정의
-
다음 중 하나를 수행합니다.
-
[각 레코드의 스키마 자동 감지(Automatically detect schema of each record)]를 선택하여 스키마 감지를 설정합니다. AWS Glue는 스트리밍 데이터에서 스키마를 결정합니다.
-
[모든 레코드에 대한 출력 스키마 지정(Specify output schema for all records)]을 선택하여 매핑 적용 변환을 사용하여 출력 스키마를 정의합니다.
-
- Script
-
필요에 따라 자체 스크립트를 제공하거나 생성된 스크립트를 수정하여 Apache Spark Structured Streaming 엔진이 지원하는 작업을 수행합니다. 사용 가능한 작업에 대한 자세한 내용은 스트리밍 데이터 프레임/데이터 세트에 대한 작업
을 참조하십시오.
스트리밍 ETL 참고 사항 및 제한 사항
다음 참고 사항 및 제한 사항에 유의하십시오.
-
AWS Glue 스트리밍 ETL 작업에 대한 자동 압축 해제는 지원되는 압축 유형에 대해서만 사용할 수 있습니다. 또한 다음을 참조하세요.
프레임 처리된 Snappy는 Snappy용 공식 프레이밍 형식
을 나타냅니다. Deflate는 Glue 버전 2.0이 아닌 Glue 버전 3.0에서 지원됩니다.
-
스키마 감지를 사용하는 경우 스트리밍 데이터의 조인을 수행할 수 없습니다.
-
AWS Glue 스트리밍 ETL 작업은 Avro 형식의 AWS Glue 스키마 레지스트리에 대한 Union 데이터 유형을 지원하지 않습니다.
-
ETL 스크립트는 AWS Glue의 기본 제공 변환과 Apache Spark Structured Streaming에 대한 기본 변환을 사용할 수 있습니다. 자세한 내용은 Apache Spark 웹 사이트의 Operations on streaming DataFrames/Datasets
또는 AWS Glue PySpark 변환 참조 섹션을 참조하세요. -
AWS Glue 스트리밍 ETL 작업은 체크포인트를 사용하여 읽은 데이터를 추적합니다. 따라서 중지되고 다시 시작된 작업은 스트림에서 중단된 부분부터 다시 시작됩니다. 데이터를 다시 처리하려는 경우 스크립트에서 참조된 체크포인트 폴더를 삭제할 수 있습니다.
-
작업 북마크는 지원되지 않습니다.
-
Kinesis Data Streams의 향상된 팬아웃 기능을 사용하려면 Kinesis 스트리밍 작업에서 향상된 팬아웃 사용 섹션을 참조하세요.
-
AWS Glue Schema Registry에서 생성된 Data Catalog 테이블을 사용하는 경우 새 스키마 버전을 사용할 수 있게 되면 새 스키마를 반영하기 위해 다음을 수행해야 합니다.
-
테이블과 연결된 작업을 중지합니다.
-
Data Catalog 테이블의 스키마를 업데이트합니다.
-
테이블과 연결된 작업을 다시 시작합니다.
-
