Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Tutorial: scrivere uno script ETL AWS Glue per Ray
Ray ti dà la possibilità di scrivere e scalare attività distribuite in modo nativo in Python. AWS Glue for Ray offre ambienti Ray senza server a cui è possibile accedere sia dai job che dalle sessioni interattive (le sessioni interattive di Ray sono disponibili in anteprima). Il AWS Glue job system offre un modo coerente per gestire ed eseguire le attività, in base a una pianificazione, da un trigger o dalla console. AWS Glue
La combinazione di questi AWS Glue strumenti crea una potente toolchain che puoi usare per i carichi di lavoro di estrazione, trasformazione e caricamento (ETL), un caso d'uso comune per. AWS Glue Questo tutorial ti illustrerà le basi per creare questa soluzione.
Supportiamo anche l'utilizzo di Spark AWS Glue per i tuoi carichi di lavoro ETL. Per un tutorial sulla scrittura di uno script AWS Glue per Spark, consulta. Tutorial: Scrivere uno script di AWS Glue for Spark Per ulteriori informazioni sui motori disponibili, consulta la pagina AWS Glue per Spark e AWS Glue per Ray. Ray è in grado di affrontare vari tipi di attività nell'ambito dell'analisi, del machine learning (ML) e dello sviluppo di applicazioni.
In questo tutorial, estrarrai, trasformerai e caricherai un set di dati CSV ospitato in Amazon Simple Storage Service (Amazon S3). Inizierai con il set di dati dei dati di record di viaggio della New York City Taxi and Limousine Commission (TLC), archiviato in un bucket Amazon S3 pubblico. Per ulteriori informazioni su questo set di dati, consulta il Registry of Open Data su AWS
Trasformerai i tuoi dati con le trasformazioni predefinite disponibili nella libreria Ray Data. Ray Data è una libreria per la preparazione di set di dati progettata da Ray e inclusa di default negli ambienti AWS Glue Ray. Per ulteriori informazioni sulle librerie incluse in modo predefinito, consulta la pagina Moduli disponibili con i processi Ray. Potrai quindi scrivere i dati trasformati in un bucket Amazon S3 da te controllato.
Prerequisiti: per questo tutorial, è necessario un AWS account con accesso ad AWS Glue Amazon S3.
Passaggio 1: creazione di un bucket in Amazon S3 per contenere i dati di output
Avrai bisogno di un bucket Amazon S3 da te controllato che funga da sink per i dati creati in questo tutorial. È possibile creare questo bucket con la procedura seguente.
Nota
Se desideri scrivere i tuoi dati in un bucket esistente sotto il tuo controllo, puoi saltare questo passaggio. Prendi nota del yourBucketName nome del bucket esistente, da utilizzare nei passaggi successivi.
Creazione di un bucket per l'output del processo Ray
-
Crea un bucket seguendo i passaggi descritti in Creating a bucket nella Guida per l'utente di Amazon S3.
-
Quando scegli il nome del bucket, prendi nota di
yourBucketNameciò a cui farai riferimento nei passaggi successivi. -
Per altre configurazioni, le impostazioni suggerite fornite nella console Amazon S3 dovrebbero funzionare correttamente in questo tutorial.
Ad esempio, la finestra di dialogo per la creazione del bucket potrebbe avere questo aspetto nella console Amazon S3.
-
Passaggio 2: creazione di un ruolo e una policy IAM per il processo Ray
Il tuo lavoro richiederà un ruolo AWS Identity and Access Management (IAM) con quanto segue:
-
Autorizzazioni concesse dalla policy gestita da
AWSGlueServiceRole. Queste sono le autorizzazioni di base necessarie per eseguire un AWS Glue lavoro. -
Autorizzazioni
Reada livello di accesso per la risorsanyc-tlc/*Amazon S3. -
Autorizzazioni
Writea livello di accesso per la risorsayourBucketName/* -
Una relazione di fiducia che consente al principale
glue.amazonaws.comdi assumere il ruolo.
È possibile creare questo ruolo con la procedura seguente.
Per creare un ruolo IAM per il tuo lavoro su AWS Glue for Ray
Nota
È possibile creare un ruolo IAM seguendo molte procedure diverse. Per ulteriori informazioni o opzioni su come effettuare il provisioning delle risorse IAM, consulta la documentazione di AWS Identity and Access Management.
-
Crea una policy che definisca le autorizzazioni Amazon S3 precedentemente delineate seguendo i passaggi descritti in Creating IAM policies (console) with the visual editor nella Guida per l'utente di IAM.
-
Quando selezioni un servizio, scegli Amazon S3.
-
Quando selezioni le autorizzazioni per la tua policy, collega i seguenti set di operazioni per le seguenti risorse (menzionate in precedenza):
-
Autorizzazioni con livello di accesso di lettura per la risorsa
nyc-tlc/*Amazon S3. -
Autorizzazioni con livello di accesso di scrittura per la risorsa
yourBucketName/*
-
-
Quando selezioni il nome della policy, prendi nota di
YourPolicyNameciò a cui farai riferimento in un passaggio successivo.
-
-
Crea un ruolo per il tuo lavoro in AWS Glue for Ray seguendo i passaggi descritti nella sezione Creazione di un ruolo per un AWS servizio (console) nella Guida per l'utente IAM.
-
Quando selezioni un'entità AWS di servizio affidabile, scegli
Glue. Questo creerà automaticamente la relazione di attendibilità necessaria per il processo. -
Quando selezioni le policy per la policy delle autorizzazioni, collega le seguenti policy:
-
AWSGlueServiceRole -
YourPolicyName
-
-
Quando selezionate il nome del ruolo, prendete nota di
YourRoleNameciò a cui farete riferimento nei passaggi successivi.
-
Passaggio 3: crea ed esegui un job AWS Glue for Ray
In questo passaggio, si crea un AWS Glue lavoro utilizzando il AWS Management Console, si fornisce uno script di esempio e si esegue il lavoro. Quando crei un processo, nella console viene creato uno spazio in cui archiviare, configurare e modificare lo script Ray. Per informazioni su come creare i processi, consulta Gestione dei AWS Glue lavori nella console AWS.
In questo tutorial, affrontiamo il seguente scenario ETL: vorresti leggere i record di gennaio 2022 dal set di dati New York City TLC Trip Record, aggiungere una nuova colonna (tip_rate) al set di dati combinando i dati nelle colonne esistenti, quindi rimuovere un numero di colonne che non sono rilevanti per la tua analisi attuale e quindi desideri scrivere i risultatiyourBucketName. Il seguente script Ray esegue questi passaggi:
import ray import pandas from ray import data ray.init('auto') ds = ray.data.read_csv("s3://nyc-tlc/opendata_repo/opendata_webconvert/yellow/yellow_tripdata_2022-01.csv") # Add the given new column to the dataset and show the sample record after adding a new column ds = ds.add_column( "tip_rate", lambda df: df["tip_amount"] / df["total_amount"]) # Dropping few columns from the underlying Dataset ds = ds.drop_columns(["payment_type", "fare_amount", "extra", "tolls_amount", "improvement_surcharge"]) ds.write_parquet("s3://yourBucketName/ray/tutorial/output/")
Per creare ed eseguire un job for Ray AWS Glue
-
In AWS Management Console, vai alla pagina di AWS Glue destinazione.
-
Nel riquadro di navigazione laterale, scegli Processi ETL.
-
In Crea processo, scegli Ray script editor, quindi scegli Crea, come nella figura seguente.
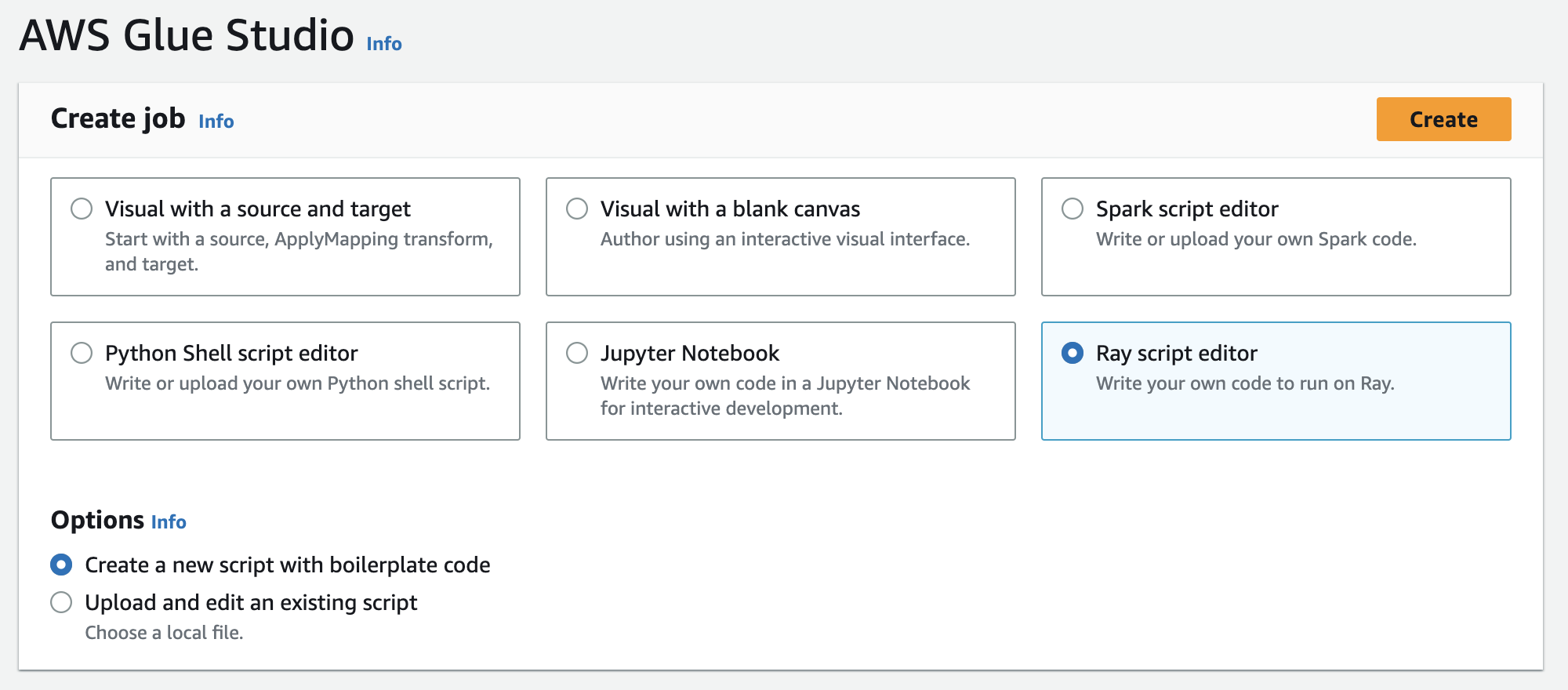
-
Incolla il testo completo dello script nel riquadro Script e sostituisci l'eventuale testo presente.
-
Vai ai dettagli di Job e imposta la proprietà IAM Role su
YourRoleName. -
Seleziona Salva, quindi scegli Esegui.
Passaggio 4: ispezione dell'output
Dopo aver eseguito il AWS Glue job, è necessario verificare che l'output corrisponda alle aspettative di questo scenario. È possibile farlo con la seguente procedura.
Verifica della corretta esecuzione del processo Ray
-
Nella pagina dei dettagli del processo, vai a Esecuzioni.
-
Dopo alcuni minuti, dovresti vedere un'esecuzione con lo Stato di esecuzione impostato su Operazione riuscita.
-
Accedi alla console Amazon S3 all'indirizzo https://console.aws.amazon.com/s3/
e ispeziona. yourBucketNameDovresti visualizzare i file scritti nel tuo bucket di output. -
Leggi i file Parquet e verificane il contenuto. Puoi farlo utilizzando gli strumenti esistenti. Se non disponi di un processo per la convalida dei file Parquet, puoi farlo nella AWS Glue console con una sessione AWS Glue interattiva, usando Spark o Ray (in anteprima).
In una sessione interattiva, hai accesso alle librerie Ray Data, Spark o pandas, fornite per impostazione predefinita (in base al motore scelto). Per verificare i contenuti del tuo file, è possibile utilizzare i metodi di ispezione comuni disponibili in tali librerie, ad esempio
count,schemaeshow. Per ulteriori informazioni sulle sessioni interattive nella console, consulta Uso dei notebook con Studio e. AWS Glue AWS GluePoiché hai confermato che i file sono stati scritti nel bucket, puoi affermare con relativa certezza che se l'output presenta problemi, non sono correlati alla configurazione IAM. Configura la sessione con
yourRoleNameper avere accesso ai file pertinenti.
Se non vedi i risultati previsti, esamina i contenuti per la risoluzione dei problemi in questa guida per identificare e correggere l'origine dell'errore. Puoi trovare i contenuti relativi alla risoluzione dei problemi nel capitolo Risoluzione dei problemi relativi a AWS Glue. Per errori specifici relativi ai processi Ray, consulta la sezione Risoluzione dei problemi relativi AWS Glue agli errori di Ray nei log nel capitolo sulla risoluzione dei problemi.
Passaggi successivi
Ora hai visto ed eseguito un processo ETL utilizzando AWS Glue for Ray dall'inizio alla fine. Puoi utilizzare le seguenti risorse per capire quali strumenti offre Ray AWS Glue per trasformare e interpretare i tuoi dati su larga scala.
-
Per ulteriori informazioni sul modello di attività di Ray, consulta la pagina Utilizzo di Ray Core e Ray Data in AWS Glue for Ray. Per una maggiore esperienza nell'uso delle attività di Ray, segui gli esempi nella documentazione di Ray Core. Consulta la pagina Ray Core: Ray Tutorials and Examples (2.4.0)
nella documentazione di Ray. -
Per indicazioni sulle librerie di gestione dei dati disponibili in AWS Glue for Ray, consultaConnessione ai dati nei processi Ray. Per ulteriori esperienze con Ray Data per trasformare e scrivere set di dati, segui gli esempi nella documentazione di Ray Data. Consulta la sezione Ray Data: Examples (2.4.0)
. -
Per ulteriori informazioni sulla configurazione AWS Glue per i lavori Ray, consultaLavorare con Ray Jobs in AWS Glue.
-
Per ulteriori informazioni sulla scrittura di script AWS Glue per Ray, continua a leggere la documentazione in questa sezione.
