Amazon Redshift ne prendra plus en charge la création de nouveaux Python UDFs à compter du 1er novembre 2025. Si vous souhaitez utiliser Python UDFs, créez la version UDFs antérieure à cette date. Le Python existant UDFs continuera à fonctionner normalement. Pour plus d'informations, consultez le billet de blog
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Stockage en colonnes
Cette section décrit le stockage en colonnes, qui est la méthode utilisée par Amazon Redshift pour stocker efficacement les données tabulaires.
Le stockage en colonnes des tables de base de données constitue un facteur important dans l’optimisation des performances des requêtes analytiques car il réduit considérablement les exigences globales d’I/O disque. Il permet de réduire la quantité de données que vous devez charger sur le disque.
La série d’illustrations suivantes décrit comment le stockage de données en colonnes garantit l’efficacité et comment celle-ci se traduit par une extraction efficace des données en mémoire.
Cette première illustration montre comment les enregistrements des tables de base de données sont généralement stockés en blocs de disque par ligne.

Dans une table de base de données relationnelle classique, chaque ligne contient les valeurs de champ d’un seul enregistrement. Dans le stockage de base de données en lignes, les blocs de données stockent les valeurs de manière séquentielle pour chaque colonne composant la totalité de la ligne. Si la taille de bloc est inférieure à celle de la taille d’un enregistrement, le stockage d’un enregistrement complet peut nécessiter plus d’un bloc. Si la taille de bloc est supérieure à celle de la taille d’un enregistrement, le stockage d’un enregistrement complet peut nécessiter moins d’un bloc, ce qui entraîne une utilisation inefficace de l’espace disque. Dans les applications de traitement transactionnel en ligne (OLTP), la plupart des transactions impliquent une lecture et une écriture fréquentes de toutes les valeurs de l’ensemble des enregistrements, généralement un enregistrement ou un petit nombre d’enregistrements à la fois. En conséquence, le stockage en ligne est optimal pour les bases de données OLTP.
L’illustration suivante montre comment, grâce au stockage en colonnes, les valeurs de chaque colonne sont stockées de manière séquentielle en blocs de disque.
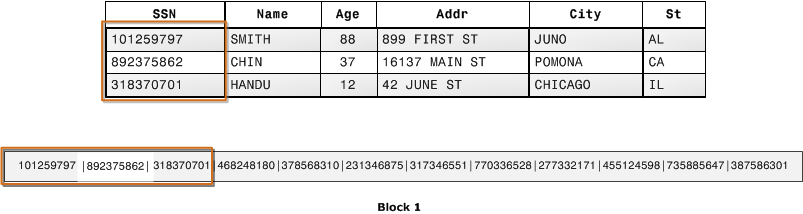
A l’aide du stockage en colonnes, chaque bloc de données stocke les valeurs d’une seule colonne pour plusieurs lignes. Au fur et à mesure que les enregistrements entrent dans le système, Amazon Redshift convertit les données de façon transparente en stockage en colonnes pour chacune des colonnes.
Dans cet exemple simplifié, à l’aide du stockage en colonnes, chaque bloc de données contient les valeurs des champs de colonne pour trois fois plus d’enregistrements que le stockage en lignes. Cela signifie que la lecture du même nombre de valeurs de champs de colonne pour le même nombre d’enregistrements nécessite un tiers des opérations d’I/O par rapport au stockage en lignes. En pratique, si vous utilisez des tables avec des nombres très élevés de lignes et de colonnes, l’efficacité du stockage est encore plus grande.
Un avantage supplémentaire est que, dans la mesure où chaque bloc contient le même type de données, les données de bloc peuvent utiliser un système de compression sélectionné spécifiquement pour le type de données de la colonne, réduisant encore plus l’espace disque et les I/O. Pour en savoir plus sur les encodages de compression basés sur les types de données, consultez encodages de compression.
Les économies d’espace obtenues pour stocker les données sur disque se répercutent dans l’extraction et dans le stockage de ces données en mémoire. Comme la plupart des opérations de base de données ont seulement besoin d’accéder à un petit nombre de colonnes à la fois ou de les exploiter, vous pouvez économiser de l’espace mémoire en extrayant uniquement les blocs des colonnes dont vous avez réellement besoin pour ne requête. Là où les transactions OLTP impliquent généralement la plupart ou la totalité des colonnes d’une ligne d’un petit nombre de documents, les requêtes sur les entrepôts des données ne lisent généralement que quelques colonnes d’un très grand nombre de lignes. Cela signifie que la lecture du même nombre de valeurs de champs de colonne pour le même nombre de ligne nécessite une fraction des opérations d’I/O. Elle utilise une fraction de la mémoire qui serait nécessaire pour traiter des blocs par ligne. En pratique, l’utilisation de tables avec de très grands nombres de colonnes et de lignes permet d’obtenir des gains en efficacité proportionnellement supérieurs. Par exemple, imaginons qu’une table contienne 100 colonnes. Une requête qui utilise cinq colonnes a uniquement besoin de lire environ 5 % des données contenues dans la table. Cette économie se reproduit pour les éventuels milliards, voire billions, d’enregistrements des bases de données volumineuses. En revanche, une base de données en lignes lit tout aussi bien les blocs contenant les 95 % de colonnes non nécessaires.
La taille d’un bloc de base de données classique varie de 2 à 32 Ko. Amazon Redshift utilise une taille de bloc de 1 Mo, ce qui est plus efficace et réduit le nombre de requêtes d’I/O nécessaires pour exécuter un chargement de base de données ou toute autre opération relevant de l’exécution de la requête.
