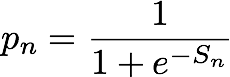Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Come funziona IP Insights
Amazon SageMaker AI IP Insights è un algoritmo non supervisionato che utilizza i dati osservati sotto forma di coppie (entità, IPv4 indirizzo) che associa le entità agli indirizzi IP. IP Insights determina quanto è probabile che un'entità utilizzi un particolare indirizzo IP apprendendo le rappresentazioni vettoriali latenti per le entità e gli indirizzi IP. La distanza tra queste due rappresentazioni può quindi servire da proxy per stabilire la probabilità di questa associazione.
L'algoritmo di IP Insights utilizza una rete neurale per apprendere le rappresentazioni vettoriali latenti per entità e indirizzi IP. Le entità vengono prima sottoposte a hash in un grande spazio hash fisso e quindi vengono codificate da un semplice livello di incorporamento. Le stringhe di caratteri, come i nomi utente o gli account, IDs possono essere inserite direttamente in IP Insights così come appaiono nei file di registro. Non è necessario preelaborare i dati per gli identificatori di entità. Puoi fornire le entità come valore di stringa arbitraria durante l’addestramento e l'inferenza. La dimensione dell'hash deve essere configurata con un valore sufficientemente elevato da garantire che il numero di collisioni che si verificano quando entità distinte vengono mappate sullo stesso vettore latente resti insignificante. Per ulteriori informazioni su come selezionare le dimensioni hash appropriate, consulta Feature Hashing for Large Scale Multitask Learning
Durante l’addestramento, IP Insights genera automaticamente esempi negativi accoppiando in modo casuale entità e indirizzi IP. Questi esempi negativi rappresentano dati che con meno probabilità ricorrono nella realtà. Il modello è addestrato a distinguere i esempi positivi osservati nei dati di addestramento e questi esempi negativi generati. Più precisamente, il modello è addestrato per minimizzare l'entropia incrociata, nota anche come perdita di log, definita come segue:
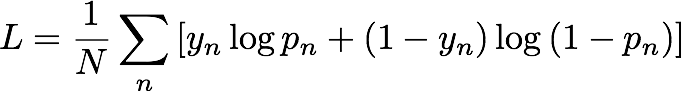
yn è l'etichetta che indica se l'esempio proviene dalla distribuzione reale che governa i dati osservati (yn= 1) o dalla distribuzione che genera gli esempi negativi (yn= 0). pn è la probabilità che l'esempio provenga dalla distribuzione reale, come previsto dal modello.
La generazione di esempi negativi è un processo importante che viene utilizzato per ottenere un modello accurato dei dati osservati. Se gli esempi negativi sono estremamente improbabili, ad esempio, se tutti gli indirizzi IP negli esempi negativi sono 10.0.0.0, il modello apprende banalmente a distinguere gli esempi negativi e non riesce a caratterizzare con accuratezza il set di dati effettivamente osservato. Per mantenere gli esempi negativi più realistici, IP Insights genera esempi negativi creando e selezionando in modo casuale gli indirizzi IP dai dati di addestramento. Puoi configurare il tipo di esempio negativo e le velocità con cui vengono generati gli esempi negativi con gli iperparametri random_negative_sampling_rate e shuffled_negative_sampling_rate.
Considerando una ennesima coppia entità-indirizzo IP, l'output del modello IP Insights è un punteggio, Sn, che indica il modo in cui l'entità è compatibile con l'indirizzo IP. Questo punteggio corrisponde all'odds ratio di log dell'entità-indirizzo IP specificati della coppia proveniente da una distribuzione reale rispetto a una distribuzione negativa. È definito come segue:

Il punteggio è essenzialmente la misura della somiglianza tra le rappresentazioni vettoriali dell'ennesima coppia entità-indirizzo IP. Può essere interpretato anche per avere la probabilità di osservazione di questo evento nella realtà che in un set di dati generato casualmente. Durante l'addestramento, l'algoritmo utilizza questo punteggio per calcolare una stima della probabilità di un esempio proveniente dalla distribuzione reale, pn, da usare per la riduzione al minimo dell'entropia incrociata, dove: