As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Métricas de SageMaker IA da Amazon na Amazon CloudWatch
Você pode monitorar a Amazon SageMaker AI usando a Amazon CloudWatch, que coleta dados brutos e os processa em métricas legíveis, quase em tempo real. Essas estatísticas são mantidas por 15 meses. Você pode acessar as informações históricas e ter uma perspectiva melhor sobre o desempenho da aplicação Web ou do serviço. No entanto, o CloudWatch console da Amazon limita a pesquisa às métricas que foram atualizadas nas últimas duas semanas. Essa limitação garante que os trabalhos mais atuais sejam mostrados em seu namespace.
Para representar graficamente as métricas sem usar uma pesquisa, especifique seu nome exato na exibição de origem. Você também pode definir alarmes que observam determinados limites e enviam notificações ou realizam ações quando esses limites são atingidos. Para obter mais informações, consulte o Guia CloudWatch do usuário da Amazon.
SageMaker Métricas e dimensões da IA
SageMaker Métricas de invocação de endpoints de IA
O namespace AWS/SageMaker inclui as seguintes métricas de solicitação de chamadas para InvokeEndpoint.
As métricas estão disponíveis a uma frequência de 1 minuto.
A ilustração a seguir mostra como um endpoint de SageMaker IA interage com a API Amazon SageMaker Runtime. O tempo total entre o envio de uma solicitação para um endpoint e o recebimento de uma resposta depende dos três componentes a seguir.
-
Latência de rede — o tempo que leva entre fazer uma solicitação e receber uma resposta da API SageMaker Runtime Runtime.
-
Latência de sobrecarga — o tempo necessário para transportar uma solicitação para o contêiner do modelo e transportar a resposta de volta para a API SageMaker Runtime Runtime.
-
Latência do modelo: o tempo que o contêiner do modelo leva para processar a solicitação e retornar uma resposta.
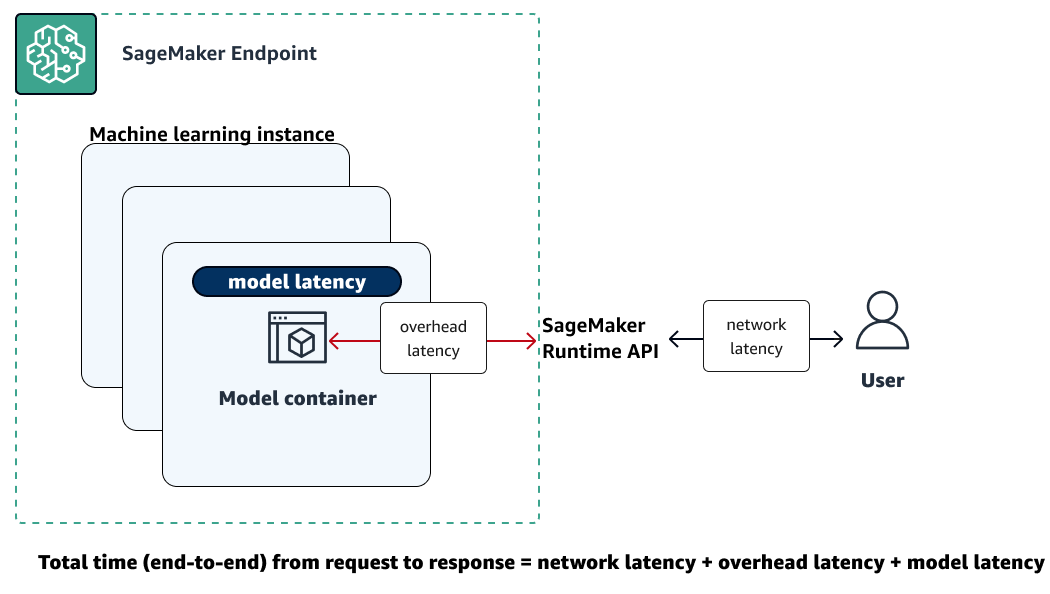
Para obter mais informações sobre a latência total, consulte Melhores práticas para testar a carga dos endpoints de inferência em tempo real da Amazon SageMaker AI
Métricas de invocação de endpoint
| Métrica | Descrição |
|---|---|
ConcurrentRequestsPerCopy |
O número de solicitações simultâneas sendo recebidas pelo componente de inferência, normalizado por cada cópia de um componente de inferência. Estatísticas válidas: Min, Max |
ConcurrentRequestsPerModel |
O número de solicitações simultâneas sendo recebidas pelo modelo. Estatísticas válidas: Min, Max |
Invocation4XXErrors |
O número de solicitações Unidades: nenhuma Estatísticas válidas: média e soma |
Invocation5XXErrors |
O número de solicitações Unidades: nenhuma Estatísticas válidas: média e soma |
InvocationModelErrors |
O número de solicitações de invocação do modelo que não resultaram em uma resposta HTTP 2XX. Isso inclui códigos de status 4XX/5XX, erros de soquete de baixo nível, respostas HTTP malformadas e tempos limite de solicitação. Para cada resposta de erro, 1 é enviado; caso contrário, 0 é enviado. Unidades: nenhuma Estatísticas válidas: média e soma |
Invocations |
O número de solicitações Para obter o número total de solicitações enviadas a um endpoint de modelo, use a estatística Sum. Unidades: nenhuma Estatísticas válidas: soma |
InvocationsPerCopy |
O número de invocações normalizadas por cada cópia de um componente de inferência. Estatísticas válidas: soma |
InvocationsPerInstance |
O número de invocações enviadas para um modelo, normalizado por Unidades: nenhuma Estatísticas válidas: soma |
ModelLatency |
O intervalo de tempo gasto por um modelo para responder a uma solicitação da API SageMaker Runtime. Esse intervalo inclui os tempos de comunicação locais necessários para enviar a solicitação e buscar a resposta de um contêiner modelo. Inclui também o tempo necessário para concluir a inferência no contêiner. Unidade: microssegundos Estatísticas válidas: média, soma, mín., máx., contagem de amostras, porcentagens |
ModelSetupTime |
O tempo necessário para lançar novos recursos computacionais para um endpoint com tecnologia sem servidor. O tempo pode variar dependendo do tamanho do modelo, do tempo necessário para baixar o modelo e do tempo de inicialização do contêiner. Unidade: microssegundos Estatísticas válidas: média, soma, mín., máx., contagem de amostras, porcentagens |
OverheadLatency |
O intervalo de tempo adicionado ao tempo necessário para responder a uma solicitação do cliente pelas despesas gerais de SageMaker IA. Esse intervalo é medido a partir do momento em que a SageMaker IA recebe a solicitação até retornar uma resposta ao cliente, menos o. Unidade: microssegundos Estatísticas válidas: média, soma, mín., máx., contagem de amostras |
Dimensões para métricas de invocação de endpoint
| Dimensão | Descrição |
|---|---|
EndpointName, VariantName |
Filtra as métricas de invocação de endpoint para uma |
InferenceComponentName |
Filtra métricas de invocação do componente de inferência. |
SageMaker Métricas do componente de inferência de IA
O /aws/sagemaker/InferenceComponents namespace inclui as seguintes métricas de chamadas InvokeEndpointpara endpoints que hospedam componentes de inferência.
As métricas estão disponíveis a uma frequência de 1 minuto.
| Métrica | Descrição |
|---|---|
CPUUtilizationNormalized |
O valor da métrica |
GPUMemoryUtilizationNormalized |
O valor da métrica |
GPUUtilizationNormalized |
O valor da métrica |
MemoryUtilizationNormalized |
O valor de |
Dimensões para métricas de componentes de inferência
| Dimensão | Descrição |
|---|---|
InferenceComponentName |
Filtra as métricas dos componentes de inferência. |
SageMaker Métricas de endpoint multimodelo de IA
O AWS/SageMaker namespace inclui as seguintes métricas de carregamento do modelo a partir de chamadas para. InvokeEndpoint
As métricas estão disponíveis a uma frequência de 1 minuto.
Para obter informações sobre por quanto tempo as CloudWatch métricas são retidas, consulte GetMetricStatisticsa Amazon CloudWatch API Reference.
Métricas de carregamento de modelos de endpoint multimodelo
| Métrica | Descrição |
|---|---|
ModelLoadingWaitTime |
O intervalo de tempo em que uma solicitação de invocação esperou o modelo de destino ser baixado, carregado, ou ambos para realizar a inferência. Unidade: microssegundos Estatísticas válidas: média, soma, mín., máx., contagem de amostras |
ModelUnloadingTime |
O intervalo de tempo necessário para descarregar o modelo por meio da chamada de API Unidade: microssegundos Estatísticas válidas: média, soma, mín., máx., contagem de amostras |
ModelDownloadingTime |
O intervalo de tempo necessário para baixar o modelo do Amazon Simple Storage Service (Amazon S3). Unidade: microssegundos Estatísticas válidas: média, soma, mín., máx., contagem de amostras |
ModelLoadingTime |
O intervalo de tempo necessário para carregar o modelo com a chamada de API Unidade: microssegundos Estatísticas válidas: média, soma, mín., máx., contagem de amostras |
ModelCacheHit |
O número de solicitações A estatística Média mostra a proporção de solicitações para as quais o modelo já foi carregado. Unidades: nenhuma Estatísticas válidas: média, soma, contagem de amostras |
Dimensões para métricas de carregamento de modelos de endpoint multimodelo
| Dimensão | Descrição |
|---|---|
EndpointName, VariantName |
Filtra as métricas de invocação de endpoint para uma |
Os namespaces /aws/sagemaker/Endpoints incluem as seguintes métricas de instância em chamadas para InvokeEndpoint.
As métricas estão disponíveis a uma frequência de 1 minuto.
Para obter informações sobre por quanto tempo as CloudWatch métricas são retidas, consulte GetMetricStatisticsa Amazon CloudWatch API Reference.
Métricas de instâncias de modelos para endpoint multimodelo
| Métrica | Descrição |
|---|---|
LoadedModelCount |
O número de modelos carregados nos contêineres do endpoint multimodelo. Esta métrica é emitida para cada instância. A estatística Média com um período de 1 minuto informa o número médio de modelos carregados por instância. A estatística Soma informa o número total de modelos carregados em todas as instâncias no endpoint. Os modelos que essa métrica rastreia não são necessariamente exclusivos, porque um modelo pode ser carregado em vários contêineres no endpoint. Unidades: nenhuma Estatísticas válidas: média, soma, mín., máx., contagem de amostras |
Dimensões para métricas de carregamento de modelos de endpoint multimodelo
| Dimensão | Descrição |
|---|---|
EndpointName, VariantName |
Filtra as métricas de invocação de endpoint para uma |
SageMaker Trabalhos de IA e métricas de endpoint
Os namespaces /aws/sagemaker/ProcessingJobs, /aws/sagemaker/TrainingJobs, /aws/sagemaker/TransformJobs e /aws/sagemaker/Endpoints incluem as seguintes métricas para trabalhos de treinamento e instâncias de endpoint:
As métricas estão disponíveis a uma frequência de 1 minuto.
nota
A Amazon CloudWatch oferece suporte a métricas personalizadas de alta resolução e sua melhor resolução é de 1 segundo. No entanto, quanto melhor for a resolução, menor será a vida útil das métricas. CloudWatch Para a resolução de frequência de 1 segundo, as CloudWatch métricas ficam disponíveis por 3 horas. Para obter mais informações sobre a resolução e a vida útil das CloudWatch métricas, consulte GetMetricStatisticsa Amazon CloudWatch API Reference.
dica
Para criar um perfil do seu trabalho de treinamento com uma resolução mais precisa de até 100 milissegundos (0,1 segundo) de granularidade e armazenar as métricas de treinamento indefinidamente no Amazon S3 para análise personalizada a qualquer momento, considere usar o Amazon Debugger. SageMaker SageMaker O Debugger fornece regras integradas para detectar automaticamente problemas comuns de treinamento. Ele detecta problemas de utilização de recursos de hardware (como CPU, GPU e I/O gargalos). Detecta também problemas de modelo não convergentes (como sobreajuste, gradientes que desaparecem e tensores explosivos). SageMaker O Debugger também fornece visualizações por meio do Studio Classic e seu relatório de criação de perfil. Para explorar as visualizações do Debugger, consulte Passo a passo do painel do SageMaker Debugger Insights, Passo a passo do relatório de criação de perfil do Debugger e Análise de dados usando a biblioteca cliente. SMDebug
Processing Job, Training Job, Batch Transform Job, and Endpoint Instance Metrics (Métricas de trabalho de processamento, trabalho de treinamento, trabalho de transformação em lote e instância de endpoint)
| Métrica | Descrição |
|---|---|
CPUReservation |
A soma das CPUs reservas por contêineres em uma instância. O valor varia de 0% a 100%. Nas configurações de um componente de inferência, você define a reserva de CPU com o parâmetro |
CPUUtilization |
A soma da utilização de cada núcleo de CPU individual. A utilização da CPU de cada faixa de núcleo é de 0 a 100. Por exemplo, se houver quatro CPUs, o CPUUtilization intervalo é de 0% a 400%. Para trabalhos de processamento, o valor é a utilização da CPU do contêiner de processamento na instância.Para trabalhos de treinamento, o valor é a utilização de CPU do contêiner de algoritmo na instância. Para trabalhos de transformação em lote, o valor é a utilização da CPU do contêiner de transformação na instância. Para variantes de endpoint, o valor é a soma da utilização de CPU dos contêineres principais e complementares na instância. notaPara trabalhos de múltiplas instâncias, cada instância relata métricas de utilização da CPU. No entanto, a visualização padrão CloudWatch mostra a utilização média da CPU em todas as instâncias. Unidades: percentual |
CPUUtilizationNormalized |
A soma normalizada da utilização de cada núcleo de CPU individual. O valor varia de 0% a 100%. Por exemplo, se houver quatro CPUs e a |
DiskUtilization |
A porcentagem de espaço em disco usada pelos contêineres em uma instância. Esse intervalo de valores é de 0% a 100%. Essa métrica não oferece apoio para trabalhos de transformação em lote. Para trabalhos de processamento, o valor é a utilização do espaço em disco do contêiner de processamento na instância.Para trabalhos de treinamento, o valor é a utilização do espaço em disco do contêiner de algoritmo na instância. Para variantes de endpoint, o valor é a soma da utilização do espaço em disco dos contêineres primário e complementar na instância. Unidades: percentual notaPara trabalhos de múltiplas instâncias, cada instância relata métricas de utilização do disco. No entanto, a visualização padrão CloudWatch mostra a utilização média do disco em todas as instâncias. |
GPUMemoryUtilization |
O percentual de memória de GPU usada pelos contêineres em uma instância. O intervalo de valores é de 0 a 100 e é multiplicado pelo número de. GPUs Por exemplo, se houver quatro GPUs, o Para trabalhos de treinamento, o valor é a utilização de memória de GPU do contêiner de algoritmo na instância. Para trabalhos de transformação em lote, o valor é a utilização de memória da GPU do contêiner de transformação na instância. Para variantes de endpoint, o valor é a soma da utilização de memória de GPU dos contêineres principais e complementares na instância. notaPara trabalhos de múltiplas instâncias, cada instância relata métricas de utilização de memória da GPU. No entanto, a visualização padrão CloudWatch mostra a utilização média da memória da GPU em todas as instâncias. Unidades: percentual |
GPUMemoryUtilizationNormalized |
O percentual normalizado de memória de GPU usada pelos contêineres em uma instância. O valor varia de 0% a 100%. Por exemplo, se houver quatro GPUs e a |
GPUReservation |
A soma das GPUs reservas por contêineres em uma instância. O valor varia de 0% a 100%. Nas configurações de um componente de inferência, você define a reserva da GPU por |
GPUUtilization |
O percentual de unidades de GPU usadas pelos contêineres em uma instância. O valor pode variar entre 0 e 100 e é multiplicado pelo número de. GPUs Por exemplo, se houver quatro GPUs, o Para trabalhos de treinamento, o valor é a soma da utilização de GPU do contêiner de algoritmo na instância. Para trabalhos de transformação em lote, o valor é a utilização da GPU do contêiner de transformação na instância. Para variantes de endpoint, o valor é a soma da utilização de GPU dos contêineres principais e complementares na instância. notaPara trabalhos de múltiplas instâncias, cada instância relata métricas de utilização da GPU. No entanto, a visualização padrão CloudWatch mostra a utilização média da GPU em todas as instâncias. Unidades: percentual |
GPUUtilizationNormalized |
O percentual normalizado de unidades de GPU usadas pelos contêineres em uma instância. O valor varia de 0% a 100%. Por exemplo, se houver quatro GPUs e a |
MemoryReservation |
A soma da memória reservada pelos contêineres em uma instância. O valor varia de 0% a 100%. Nas configurações de um componente de inferência, você define a reserva de memória com o parâmetro |
MemoryUtilization |
O percentual de memória usada pelos contêineres em uma instância. Esse intervalo de valores é de 0% a 100%. Para trabalhos de processamento, o valor é a utilização de memória do contêiner de processamento na instância.Para trabalhos de treinamento, o valor é a utilização de memória do contêiner de algoritmo na instância. Para trabalhos de transformação em lote, o valor é a utilização de memória do contêiner de transformação na instância. Para variantes de endpoint, o valor é a soma da utilização de memória dos contêineres principais e complementares na instância. Unidades: percentual notaPara várias instâncias, cada instância relata métricas de utilização de memória. No entanto, a visualização padrão CloudWatch mostra a utilização média da memória em todas as instâncias. |
Dimensions for Processing Job, Training Job and Batch Transform Job Instance Metrics (Métricas de dimensões de instância para trabalhos de processamento, trabalhos de treinamento e trabalhos de transformação em lote)
| Dimensão | Descrição |
|---|---|
Host |
Para trabalhos de processamento, o valor dessa dimensão tem o formato Para trabalhos de treinamento, o valor dessa dimensão tem o formato Para trabalhos de transformação em lote, o valor dessa dimensão tem o formato |
SageMaker Métricas de empregos do Inference Recommender
O namespace /aws/sagemaker/InferenceRecommendationsJobs inclui as seguintes métricas para trabalhos de recomendação de inferência:
Métricas do Inference Recommender
| Métrica | Descrição |
|---|---|
ClientInvocations |
O número de solicitações Unidades: nenhuma Estatísticas válidas: soma |
ClientInvocationErrors |
O número de Unidades: nenhuma Estatísticas válidas: soma |
ClientLatency |
O intervalo de tempo gasto entre o envio de uma chamada Unidade: milissegundos Estatísticas válidas: média, soma, mín., máx., contagem de amostras, porcentagens |
NumberOfUsers |
O número de usuários simultâneos enviando solicitações Unidades: nenhuma Estatísticas válidas: mínimo, máximo e média |
Dimensões para métricas de trabalho do Inference Recommender
| Dimensão | Descrição |
|---|---|
JobName |
Filtra as métricas do trabalho do Inference Recommender para o trabalho especificado do Inference Recommender. |
EndpointName |
Filtra as métricas de trabalho do Inference Recommender para o endpoint especificado. |
SageMaker Métricas do Ground Truth
Métricas do Ground Truth
| Métrica | Descrição |
|---|---|
ActiveWorkers |
Um único operador ativo em uma equipe de trabalho privada enviou, liberou ou recusou uma tarefa. Para obter o número total de operadores ativos, use a estatística Soma. Ground Truth procura entregar cada evento Unidades: nenhuma Estatísticas válidas: Soma e Contagem de amostras |
DatasetObjectsAutoAnnotated |
O número de objetos de conjunto de dados anotados automaticamente em um trabalho de rotulagem. Essa métrica é emitida apenas quando a rotulagem automatizada está habilitada. Para exibir o progresso do trabalho de rotulagem, use a métrica Max. Unidades: nenhuma Estatísticas válidas: Max |
DatasetObjectsHumanAnnotated |
O número de objetos de conjunto de dados anotados por um ser humano em um trabalho de rotulagem. Para exibir o progresso do trabalho de rotulagem, use a métrica Max. Unidades: nenhuma Estatísticas válidas: Max |
DatasetObjectsLabelingFailed |
O número de objetos de conjunto de dados que falharam na rotulagem de um trabalho de rotulagem. Para exibir o progresso do trabalho de rotulagem, use a métrica Max. Unidades: nenhuma Estatísticas válidas: Max |
JobsFailed |
Um único trabalho de etiquetagem falhou. Para obter o número total de trabalhos de rotulagem que falharam, use a estatística Sum. Unidades: nenhuma Estatísticas válidas: Soma e Contagem de amostras |
JobsSucceeded |
Um único trabalho de etiquetagem foi bem-sucedido. Para obter o número total de trabalhos de rotulagem que foram bem-sucedidos, use a estatística Sum. Unidades: nenhuma Estatísticas válidas: Soma e Contagem de amostras |
JobsStopped |
Um único trabalho de etiquetagem foi interrompido. Para obter o número total de trabalhos de rotulagem que foram interrompidos, use a estatística Sum. Unidades: nenhuma Estatísticas válidas: Soma e Contagem de amostras |
TasksAccepted |
Uma única tarefa foi aceita por um operador. Para obter o número total de tarefas aceitas pelos operadores, use a estatística Sum. Ground Truth tenta entregar cada evento Unidades: nenhuma Estatísticas válidas: Soma e Contagem de amostras |
TasksDeclined |
Uma única tarefa foi recusada por um funcionário. Para obter o número total de tarefas recusadas pelos operadores, use a estatística Sum. Ground Truth tenta entregar cada evento Unidades: nenhuma Estatísticas válidas: Soma e contagem de amostras |
TasksReturned |
Uma única tarefa foi retornada. Para obter o número total de tarefas retornadas, use a estatística Sum. Ground Truth tenta entregar cada evento Unidades: nenhuma Estatísticas válidas: Soma e Contagem de amostras |
TasksSubmitted |
Uma única tarefa foi submitted/completed feita por um funcionário particular. Para obter o número total de tarefas enviadas pelos operadores, use a estatística Sum. Ground Truth tenta entregar cada evento Unidades: nenhuma Estatísticas válidas: Soma e Contagem de amostras |
TimeSpent |
Tempo gasto em uma tarefa concluída por um operador privada. Essa métrica não inclui o momento em que um operador fez uma pausa ou fez uma pausa. Ground Truth tenta realizar cada evento Unidades: segundos Estatísticas válidas: Soma e Contagem de amostras |
TotalDatasetObjectsLabeled |
O número de objetos de conjunto de dados rotulados com êxito em um trabalho de rotulagem. Para exibir o progresso do trabalho de rotulagem, use a métrica Max. Unidades: nenhuma Estatísticas válidas: Max |
Dimensions for Dataset Object Metrics (Dimensões para métricas de objetos de conjunto de dados)
| Dimensão | Descrição |
|---|---|
LabelingJobName |
Filtra métricas de contagem de objetos de conjunto de dados para um trabalho de rotulagem. |
Métricas da Amazon SageMaker Feature Store
Métricas de consumo do Feature Store
| Métrica | Descrição |
|---|---|
ConsumedReadRequestsUnits |
O número de unidades de leitura consumidas durante o período especificado. Você pode recuperar as unidades de leitura consumidas para uma operação de runtime da feature store e seu arquivo de atributos correspondente. Unidades: nenhuma Estatística válida: Todas |
ConsumedWriteRequestsUnits |
O número de unidades de gravação consumidas durante o período especificado. Você pode recuperar as unidades de gravação consumidas para uma operação de runtime da feature store e seu arquivo de atributos correspondente. Unidades: nenhuma Estatística válida: Todas |
ConsumedReadCapacityUnits |
O número de unidades de capacidade de leitura provisionadas consumidas ao longo do período especificado. Você pode recuperar as unidades de capacidade de leitura consumidas para uma operação de runtime do arquivo de atributos e grupo de atributos correspondente. Unidades: nenhuma Estatística válida: Todas |
ConsumedWriteCapacityUnits |
O número de unidades de capacidade de gravação provisionadas consumidas ao longo do período especificado. Você pode recuperar as unidades de capacidade de gravação consumidas para uma operação de runtime do arquivo de atributos e seu grupo de atributos correspondente. Unidades: nenhuma Estatística válida: Todas |
Dimensões das métricas de consumo do Feature Store
| Dimensão | Descrição |
|---|---|
FeatureGroupName, OperationName |
Filtra as métricas de consumo de runtime do feature store e da operação que você especificou. |
Métricas operacionais do Feature Store
| Métrica | Descrição |
|---|---|
Invocations |
O número de solicitações feitas às operações de runtime da feature store durante o período especificado. Unidades: nenhuma Estatísticas válidas: soma |
Operation4XXErrors |
O número de solicitações feitas às operações de runtime do Feature Store em que a operação retornou um código de resposta HTTP 4xx. Para cada resposta 4xx, 1 é enviado; caso contrário, 0 é enviado. Unidades: nenhuma Estatísticas válidas: média e soma |
Operation5XXErrors |
O número de solicitações feitas às operações de runtime da feature store em que a operação retornou um código de resposta HTTP 5xx. Para cada resposta 5xx, 1 é enviado; caso contrário, 0 é enviado. Unidades: nenhuma Estatísticas válidas: média e soma |
ThrottledRequests |
O número de solicitações feitas às operações de runtime da feature store em que a solicitação foi limitada. Para cada solicitação controlada, 1 é enviado; caso contrário, 0 é enviado. Unidades: nenhuma Estatísticas válidas: média e soma |
Latency |
O intervalo de tempo para processar as solicitações feitas às operações de runtime do Feature Store. Esse intervalo é medido a partir do momento em que a SageMaker IA recebe a solicitação até retornar uma resposta ao cliente. Unidade: microssegundos Estatísticas válidas: média, soma, mín., máx., contagem de amostras, porcentagens |
Dimensões das métricas operacionais do Feature Store
| Dimensão | Descrição |
|---|---|
|
|
Filtra as métricas operacionais de runtime da feature store do arquivo de atributos e da operação que você especificou. Você pode usar essas dimensões para operações que não sejam em lote GetRecord PutRecord, como, DeleteRecord e. |
OperationName |
Filtra as métricas operacionais de runtime da feature store para a operação que você especificou. Você pode usar essa dimensão para operações em lote, como BatchGetRecord. |
SageMaker métricas de pipelines
O namespace AWS/Sagemaker/ModelBuildingPipeline inclui as métricas a seguir para execuções do pipeline.
Duas categorias de métricas de execução do Pipelines estão disponíveis:
-
Métricas de execução em todos os pipelines: métricas de execução do pipeline no nível da conta (para todos os pipelines na conta atual)
-
Métricas de execução de pipelines: métricas de execução de pipeline por pipeline
As métricas estão disponíveis a uma frequência de 1 minuto.
Métricas de execução de pipelines
| Métrica | Descrição |
|---|---|
ExecutionStarted |
O número de execuções de pipeline iniciadas. Unidades: contagem Estatísticas válidas: média e soma |
ExecutionFailed |
O número de execuções de pipeline que falharam. Unidades: contagem Estatísticas válidas: média e soma |
ExecutionSucceeded |
O número de execuções de pipeline que foram bem-sucedidas. Unidades: contagem Estatísticas válidas: média e soma |
ExecutionStopped |
O número de execuções do pipeline que pararam. Unidades: contagem Estatísticas válidas: média e soma |
ExecutionDuration |
A duração em milissegundos em que a execução do pipeline foi executada. Unidade: milissegundos Estatísticas válidas: média, soma, mín., máx., contagem de amostras |
Dimensões para métricas de execução por pipeline
| Dimensão | Descrição |
|---|---|
PipelineName |
Filtra as métricas de execução do pipeline para um pipeline especificado. |
Métricas de etapas do pipeline
O namespace AWS/Sagemaker/ModelBuildingPipeline inclui as métricas a seguir para as etapas de execuções do pipeline.
As métricas estão disponíveis a uma frequência de 1 minuto.
| Métrica | Descrição |
|---|---|
StepStarted |
O número de etapas iniciadas. Unidades: contagem Estatísticas válidas: média e soma |
StepFailed |
O número de chamadas que falharam. Unidades: contagem Estatísticas válidas: média e soma |
StepSucceeded |
O número de etapas que foram bem-sucedidas. Unidades: contagem Estatísticas válidas: média e soma |
StepStopped |
O número de etapas que pararam. Unidades: contagem Estatísticas válidas: média e soma |
StepDuration |
A duração da execução da etapa em milissegundos. Unidade: milissegundos Estatísticas válidas: média, soma, mín., máx., contagem de amostras |
Dimensões para métricas de etapas de Pipelines
| Dimensão | Descrição |
|---|---|
PipelineName, StepName |
Filtra métricas de etapas para um pipeline e uma etapa especificados. |
