Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Utilice el Informe de información y calidad de los datos para realizar un análisis de los datos que ha importado a Data Wrangler. Se recomienda crear el informe después de importar el conjunto de datos. Puede utilizar informe como ayuda para limpiar y procesar los datos. Le proporciona información como el número de valores ausentes y el número de valores atípicos. Si tiene problemas con los datos, como una fuga de objetivos o un desequilibrio, el informe de información puede indicarle esos problemas.
Utilice el siguiente procedimiento para crear un informe de información y calidad de los datos. Se supone que ya ha importado un conjunto de datos a su flujo de Data Wrangler.
Para crear un informe de información y calidad de datos
-
Elija el signo + junto a un nodo del flujo de Data Wrangler.
-
Seleccione Obtener información sobre los datos.
-
En Nombre del análisis, especifique un nombre para el informe de información.
-
De forma opcional, en Columna objetivo, especifique la columna objetivo.
-
En Tipo de problema, especifique Regresión o Clasificación.
-
Para Tamaño de los datos, especifique uno de los siguientes valores:
-
50 K: utiliza las primeras 50 000 filas del conjunto de datos que ha importado para crear el informe.
-
Conjunto de datos completo: utiliza todo el conjunto de datos que ha importado para crear el informe.
nota
Para crear un informe de información y calidad de los datos sobre todo el conjunto de datos se utiliza un trabajo SageMaker de procesamiento de Amazon. Un trabajo de SageMaker procesamiento proporciona los recursos informáticos adicionales necesarios para obtener información sobre todos sus datos. Para obtener más información sobre los trabajos de SageMaker procesamiento, consulteCargas de trabajo de transformación de datos con procesamiento SageMaker .
-
-
Seleccione Crear.
Los siguientes temas muestran las secciones del informe:
Puede descargar el informe o verlo en línea. Para descargar el informe, pulse el botón de descarga en la esquina superior derecha de la pantalla. En la siguiente imagen se muestra el botón.

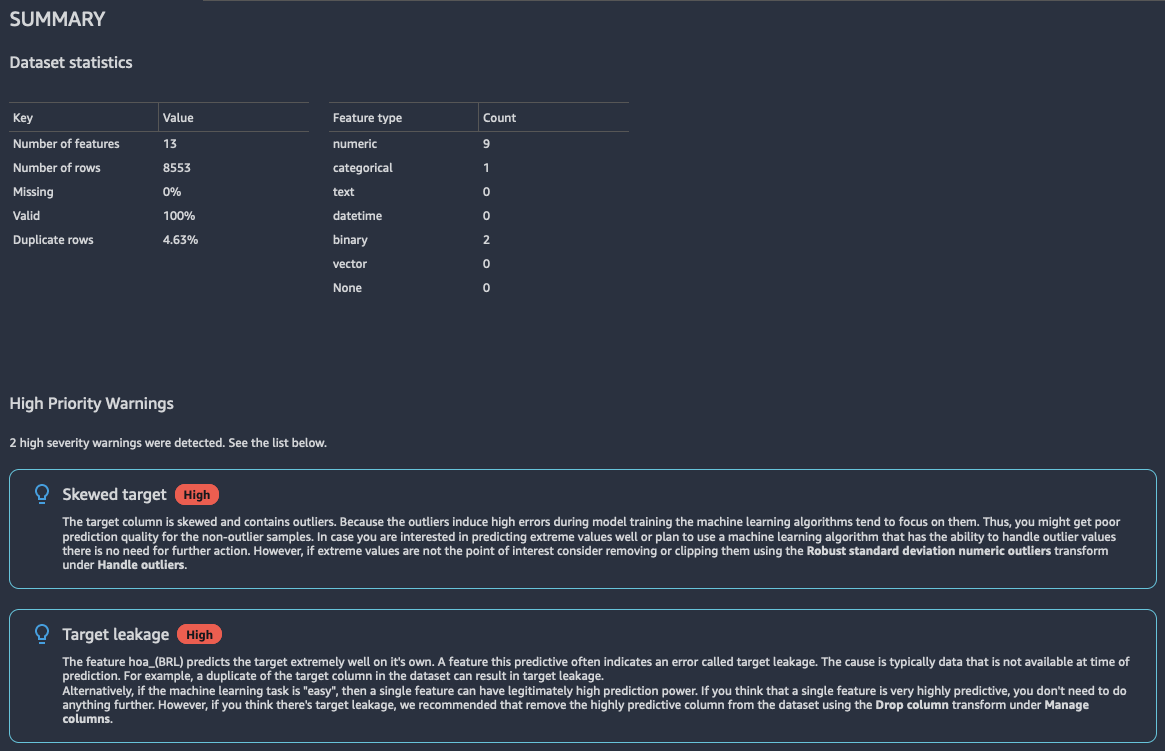
Resumen
El informe de análisis contiene un breve resumen de los datos que incluye información general, como valores ausentes, valores no válidos, tipos de características, recuentos de valores atípicos, etc. También puede incluir advertencias de alta gravedad que indiquen posibles problemas con los datos. Se recomienda investigar las advertencias.
A continuación, se muestra un ejemplo de este tipo de respuesta.
Columna objetivo
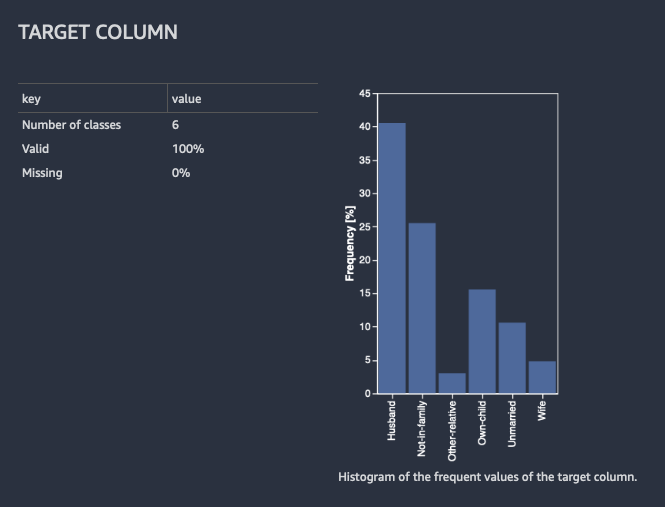
Cuando crea el informe de información y calidad de los datos, Data Wrangler le ofrece la opción de seleccionar una columna objetivo. La columna objetivo es una columna que intenta predecir. Cuando se elige una columna objetivo, Data Wrangler crea automáticamente un análisis de la columna objetivo. También clasifica las características en el orden de su poder predictivo. Al seleccionar una columna objetivo, debe especificar si va a intentar resolver un problema de regresión o de clasificación.
Para la clasificación, Data Wrangler muestra una tabla y un histograma de las clases más frecuentes. Una clase es una categoría. También presenta observaciones, o filas, con un valor objetivo que falta o que no es válido.
La siguiente imagen muestra un ejemplo de análisis de la columna objetivo para un problema de clasificación.
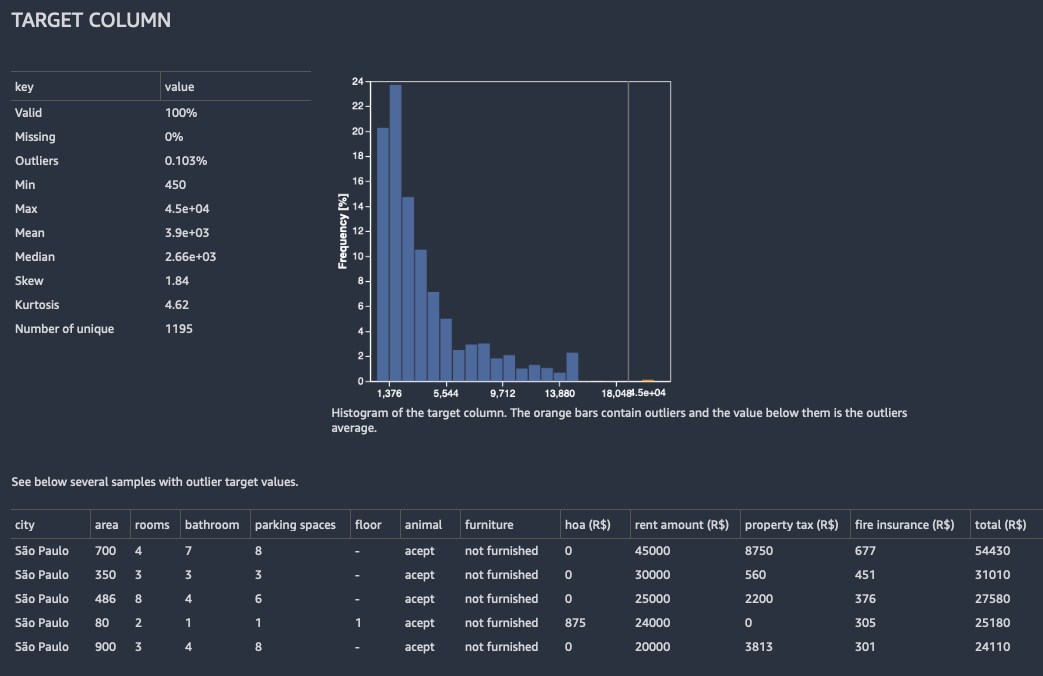
Para la regresión, Data Wrangler muestra un histograma de todos los valores de la columna objetivo. También presenta observaciones, o filas, con un valor objetivo que falta, que no es válido o que es atípico.
La siguiente imagen muestra un ejemplo de análisis de la columna objetivo para un problema de regresión.
Modelo rápido
El Modelo rápido proporciona una estimación de la calidad prevista de un modelo que se entrena con sus datos.
Data Wrangler divide los datos en pliegues de entrenamiento y validación. Utiliza el 80 % de las muestras para el entrenamiento y el 20 % de los valores para la validación. Para la clasificación, la muestra se divide estratificadamente. Para una división estratificada, cada partición de datos tiene la misma proporción de etiquetas. En lo que se refiere a los problemas de clasificación, es importante tener la misma proporción de etiquetas entre los pliegues de entrenamiento y de clasificación. Data Wrangler entrena el XGBoost modelo con los hiperparámetros predeterminados. Aplica una parada temprana a los datos de validación y realiza un preprocesamiento mínimo de la característica.
En el caso de los modelos de clasificación, Data Wrangler devuelve un resumen del modelo y una matriz de confusión.
A continuación, se muestra un ejemplo de un resumen de un modelo de clasificación. Para obtener más información acerca de la información que devuelve, consulte Definiciones.

A continuación, se muestra un ejemplo de una matriz de confusión que devuelve el modelo rápido.
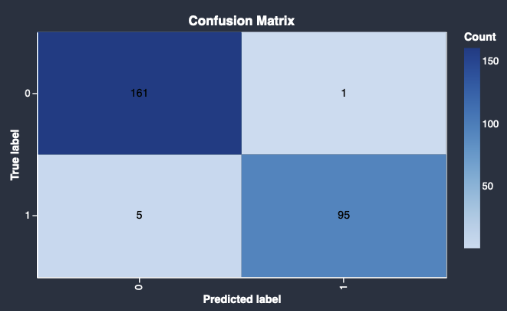
Una matriz de confusión le ofrece la siguiente información:
-
El número de veces que la etiqueta predicha coincide con la etiqueta verdadera.
-
El número de veces que la etiqueta predicha no coincide con la etiqueta verdadera.
La etiqueta verdadera representa una observación real de los datos. Por ejemplo, si utiliza un modelo para detectar transacciones fraudulentas, la etiqueta verdadera representa una transacción que en realidad es fraudulenta o no fraudulenta. La etiqueta predicha representa la etiqueta que el modelo asigna a los datos.
Puede usar la matriz de confusión para ver lo bien que predice el modelo la presencia o ausencia de una condición. Si predice transacciones fraudulentas, puede utilizar la matriz de confusión para hacerse una idea de la sensibilidad y la especificidad del modelo. La sensibilidad se refiere a la capacidad del modelo de detectar transacciones fraudulentas. La especificidad se refiere a la capacidad del modelo de evitar detectar transacciones no fraudulentas como fraudulentas.
A continuación, se muestra un ejemplo de los resultados de un modelo rápido para un problema de regresión.

Resumen de características
Al especificar una columna objetivo, Data Wrangler ordena las características por su poder de predicción. El poder de predicción se mide en los datos después de dividirlos en un 80 % de pliegues de entrenamiento y un 20 % de pliegues de validación. Data Wrangler encaja un modelo para cada característica independiente en el pliegue de entrenamiento. Aplica un preprocesamiento mínimo de la característica y mide el rendimiento de la predicción en los datos de validación.
Normaliza las puntuaciones al rango [0,1]. Las puntuaciones de predicción más altas indican columnas que son más útiles para predecir el objetivo por sí mismas. Las puntuaciones más bajas apuntan a columnas que no predicen la columna objetivo.
No es habitual que una columna que no sea predictiva por sí sola lo sea cuando se usa junto con otras columnas. Puede utilizar con confianza las puntuaciones de predicción para determinar si una característica de su conjunto de datos es predictiva.
Una puntuación baja suele indicar que la característica es redundante. Una puntuación de 1 implica una capacidad predictiva perfecta, lo que a menudo es señal de una fuga de objetivos. La fuga de objetivos suele producirse cuando el conjunto de datos contiene una columna que no está disponible en el momento de la predicción. Por ejemplo, podría ser un duplicado de la columna objetivo.
Los siguientes son ejemplos de la tabla y el histograma que muestran el valor de predicción de cada característica.
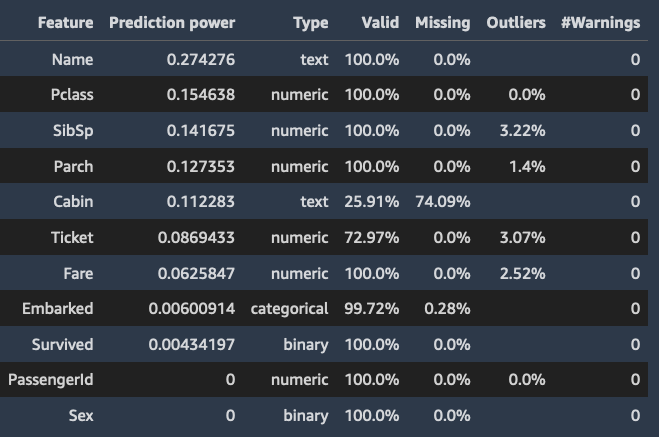
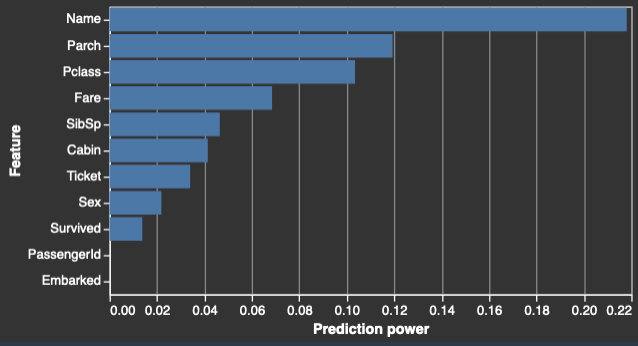
Muestras
Data Wrangler proporciona información sobre si sus muestras son anómalas o si hay duplicados en el conjunto de datos.
Data Wrangler detecta muestras anómalas mediante el algoritmo de bosque de aislamiento. El bosque de aislamiento asocia una puntuación de anomalía a cada muestra (fila) del conjunto de datos. Las puntuaciones de anomalías bajas indican muestras anómalas. Las puntuaciones altas se asocian a muestras no anómalas. Las muestras con una puntuación de anomalía negativa suelen considerarse anómalas y las muestras con una puntuación de anomalía positiva se consideran no anómalas.
Al observar una muestra que podría ser anómala, se recomienda prestar atención a los valores inusuales. Por ejemplo, es posible que tenga valores anómalos que se deban a errores en la recopilación y el procesamiento de los datos. Recomendamos utilizar el conocimiento del dominio y la lógica empresarial al examinar muestras anómalas.
Data Wrangler detecta filas duplicadas y calcula la proporción de filas duplicadas en los datos. Algunos orígenes de datos pueden incluir duplicados válidos. Otros orígenes de datos pueden tener duplicados que indiquen problemas en la recopilación de los datos. Las muestras duplicadas que resultan de una recopilación de datos defectuosa podrían interferir con los procesos de machine learning, que se basan en dividir los datos en grupos independientes de entrenamiento y validación.
Los siguientes son los elementos del informe de información que pueden verse afectados por la duplicación de muestras:
-
Modelo rápido
-
Estimación de la potencia predictiva
-
Ajuste automático de hiperparámetros
Puede eliminar las muestras duplicadas del conjunto de datos mediante la transformación Eliminar duplicados en Administrar filas. Data Wrangler le muestra las filas que se duplican con más frecuencia.
Definiciones
A continuación, se muestran las definiciones de los términos técnicos que se utilizan en el informe de información de datos.
Las siguientes son las definiciones de cada uno de los tipos de características:
-
Numérica: los valores numéricos pueden ser flotantes o enteros, como la edad o los ingresos. Los modelos de machine learning suponen que los valores numéricos están ordenados y que se define una distancia sobre ellos. Por ejemplo, 3 está más cerca de 4 que de 10 y 3 < 4 < 10.
-
Categórica: las entradas de la columna pertenecen a un conjunto de valores únicos, que suele ser mucho menor que el número de entradas de la columna. Por ejemplo, una columna de longitud 100 podría contener los valores únicos
Dog,CatyMouse. Los valores pueden ser numéricos, de texto o una combinación de ambos.Horse,House,8,Lovey3.1serían todos valores válidos y podrían encontrarse en la misma columna categórica. El modelo de machine learning no supone el orden ni la distancia en los valores de las características categóricas, a diferencia de las características numéricas, incluso cuando todos los valores son números. -
Binaria: las características binarias son un tipo de característica categórica especial en la que la cardinalidad del conjunto de valores únicos es 2.
-
Texto: una columna de texto contiene muchos valores únicos no numéricos. En casos extremos, todos los elementos de la columna son únicos. En un caso extremo, no hay dos entradas iguales.
-
Fecha y hora: una columna de fecha y hora contiene información sobre la fecha o la hora. Puede contener información tanto de la fecha como de la hora.
