기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
모델 훈련
전체 기계 학습(ML) 수명 주기의 훈련 스테이지는 훈련 데이터세트 액세스부터 최종 모델 생성, 배포할 최고 성능 모델 선택까지 다양합니다. 다음 섹션에서는 심층적인 기술 정보를 통해 가용한 SageMaker 훈련 기능 및 리소스에 대한 개요를 살펴보겠습니다.
SageMaker 훈련의 기본 아키텍처
SageMaker AI를 처음 사용하고 데이터세트에서 모델을 훈련하기 위한 빠른 ML 솔루션을 찾고 싶다면 SageMaker Canvas, SageMaker Studio Classic 내의 JumpStart SageMaker 또는 SageMaker Autopilot과 같은 노코드 또는 로우코드 솔루션을 사용하는 것이 좋습니다.
중급 코딩 경험을 원한다면 SageMaker Studio Classic 노트북 또는 SageMaker 노트북 인스턴스 사용을 고려하세요. 시작하려면 SageMaker AI 시작 안내서모델 훈련의 지침을 따르세요. ML 프레임워크를 사용하여 자체 모델 및 훈련 스크립트를 생성하는 사용 사례에 적용할 것을 권장합니다.
SageMaker AI 작업의 핵심은 ML 워크로드의 컨테이너화와 컴퓨팅 리소스 관리 기능입니다. SageMaker 훈련 플랫폼은 ML 훈련 워크로드에 대한 인프라 설정 및 관리와 관련된 과도한 부담을 처리합니다. SageMaker 훈련을 사용하면 모델 개발, 훈련 및 미세 조정에 집중할 수 있습니다.
다음 아키텍처 다이어그램은 SageMaker AI가 ML 훈련 작업을 관리하고 SageMaker AI 사용자를 대신하여 Amazon EC2 인스턴스를 프로비저닝하는 방법을 보여줍니다. SageMaker AI 사용자는 자체 훈련 데이터 세트를 가져와 Amazon S3에 저장할 수 있습니다. 사용 가능한 SageMaker AI 기본 제공 알고리즘에서 ML 모델 훈련을 선택하거나 인기 있는 기계 학습 프레임워크로 구축된 모델을 사용하여 자체 훈련 스크립트를 가져올 수 있습니다.
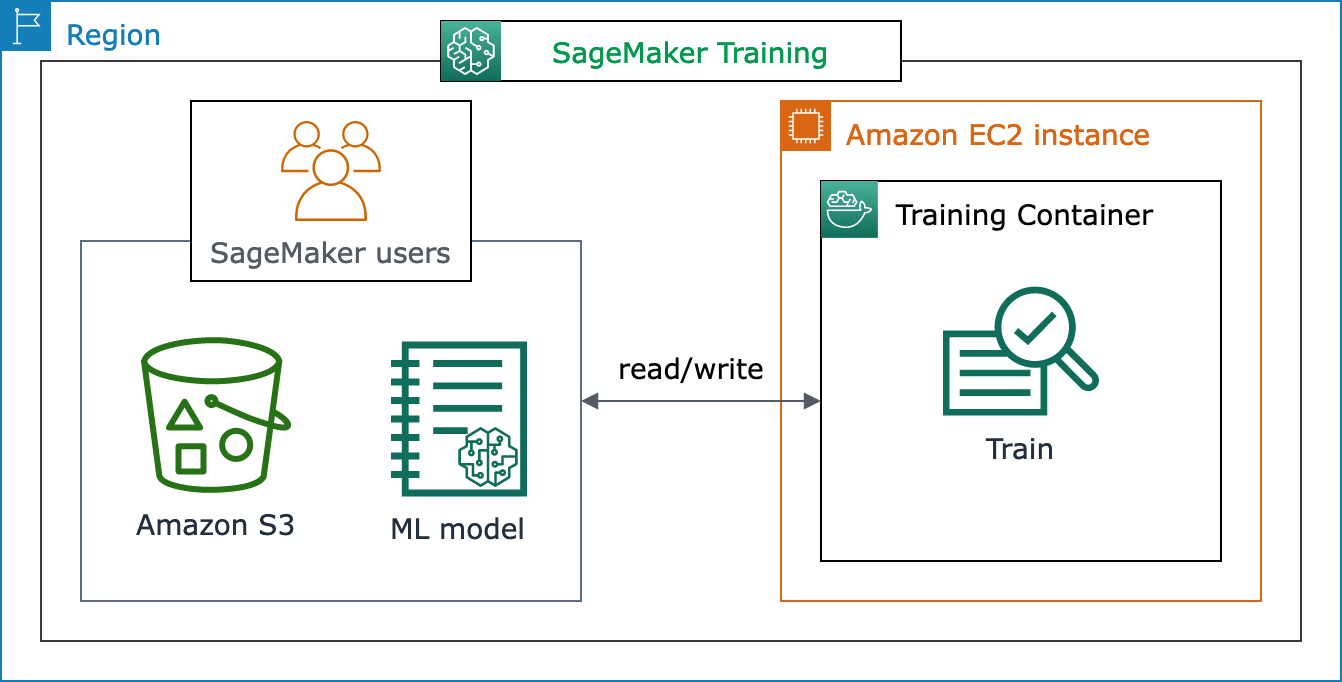
SageMaker 훈련 워크플로 및 기능 전체 보기
ML 훈련의 전 여정에는 데이터 수집을 넘어 ML 모델, 컴퓨팅 인스턴스에 대한 모델 훈련, 모델 아티팩트 및 출력 획득에 이르는 작업이 포함됩니다. 훈련 전, 중, 후 모든 단계를 평가하여 목표 정확도에 맞게 모델이 잘 훈련되었는지 확인해야 합니다.
다음 순서도에서 ML 수명 주기 훈련 단계 전반의 사용자 작업 개요(파란색 상자)와 사용 가능한 SageMaker 훈련 기능(밝은 파란색 상자)을 대략적으로 볼 수 있습니다.
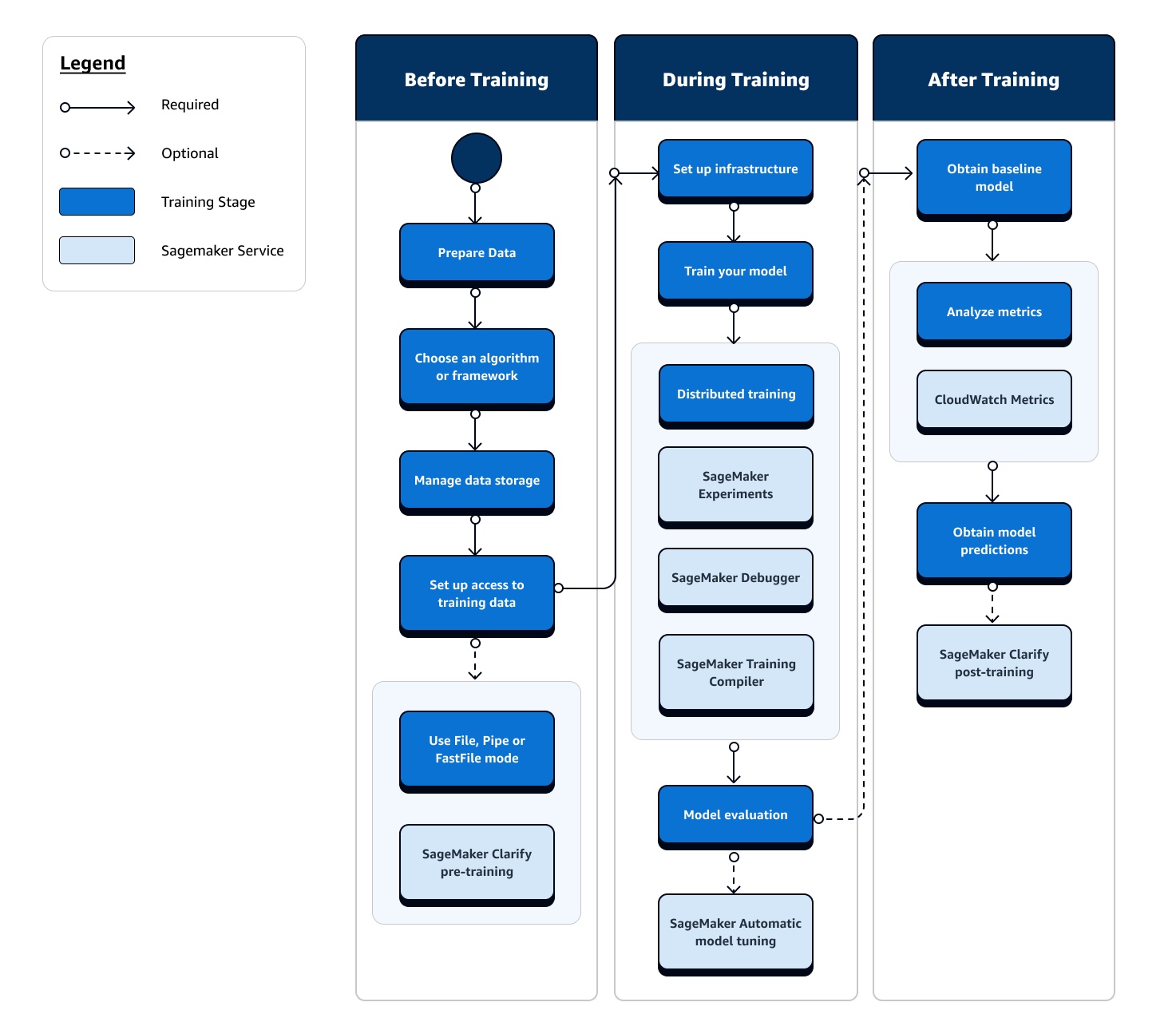
다음 섹션에서는 이전 흐름도에 표시된 훈련의 각 단계와 ML 훈련의 세 가지 하위 단계에서 SageMaker AI가 제공하는 유용한 기능을 안내합니다.
훈련 전
훈련 전에는 여러 가지 데이터 리소스 및 액세스 설정 시나리오를 고려해야 합니다. 다음 다이어그램과 훈련 전 각 단계의 세부 정보를 참조하여 어떤 결정을 내려야 하는지 살펴보세요.

-
데이터 준비: 훈련 전 데이터 준비 스테이지에서는 데이터 정리 및 특성 추출을 완료해야 합니다. SageMaker AI에는 도움이 되는 여러 레이블 지정 및 기능 엔지니어링 도구가 있습니다. 데이터 레이블 지정, 데이터세트 준비 및 분석, 데이터 처리, 특성 생성, 저장 및 공유에서 자세한 내용을 확인하세요.
-
알고리즘 또는 프레임워크 선택: 필요한 사용자 지정 정도에 따라 알고리즘 및 프레임워크에 대한 다양한 옵션이 있습니다.
-
사전 구축된 알고리즘의 로우코드 구현을 선호하는 경우 SageMaker AI에서 제공하는 기본 제공 알고리즘 중 하나를 사용합니다. 자세한 내용은 알고리즘 선택에서 확인하세요.
-
모델을 사용자 지정하는 데 더 많은 유연성이 필요한 경우 SageMaker AI 내에서 선호하는 프레임워크와 툴킷을 사용하여 훈련 스크립트를 실행합니다. 자세한 내용은 ML 프레임워크 및 툴킷에서 확인하세요.
-
사전 빌드된 SageMaker AI Docker 이미지를 자체 컨테이너의 기본 이미지로 확장하려면 사전 빌드된 SageMaker AI Docker 이미지 사용을 참조하세요.
-
사용자 지정 Docker 컨테이너를 SageMaker AI로 가져오려면 SageMaker AI로 작업하도록 자체 Docker 컨테이너 조정을 참조하세요. sagemaker-training-toolkit
을 컨테이너에 설치해야 합니다.
-
-
데이터 스토리지 관리: 데이터 스토리지(예: Amazon S3, Amazon EFS, Amazon FSx)와 Amazon EC2 컴퓨팅 인스턴스에서 실행되는 훈련 컨테이너 간의 매핑을 파악합니다. SageMaker AI는 훈련 컨테이너의 스토리지 경로와 로컬 경로를 매핑하는 데 도움이 됩니다. 수동 지정도 가능합니다. 매핑 완료 후 데이터 전송 모드(File, Pipe, FastFile 모드) 사용을 고려합니다. SageMaker AI가 스토리지 경로를 매핑하는 방법을 알아보려면 스토리지 폴더 훈련을 참조하세요.
-
훈련 데이터에 대한 액세스 설정: 보안에 가장 민감한 조직의 요구 사항을 충족 AWS KMS 하려면 Amazon SageMaker AI 도메인, 도메인 사용자 프로필, IAM, Amazon VPC 및를 사용합니다.
-
계정 관리는 Amazon SageMaker AI 도메인을 참조하세요.
-
IAM 정책 및 보안에 대한 전체 참조는 Amazon SageMaker AI의 보안을 참조하세요.
-
-
입력 데이터 스트리밍: SageMaker AI는 파일, 파이프 및 FastFile이라는 세 가지 데이터 입력 모드를 제공합니다. 기본 입력 모드인 파일 모드에서는 훈련 작업 초기화 중에 전체 데이터세트를 로드합니다. 데이터 스토리지에서 훈련 컨테이너로 데이터를 스트리밍하는 일반적인 모범 사례는 훈련 데이터 액세스에서 알아보세요.
파이프 모드에서는 증강 매니페스트 파일을 사용하여 Amazon Simple Storage Service(S3)에서 직접 데이터를 스트리밍하고 모델을 훈련시킬 수 있습니다. Amazon Elastic Block Store에서는 전체 훈련 데이터세트를 저장하는 대신 최종 모델 아티팩트만 저장하면 되므로 파이프 모드를 사용하면 디스크 공간이 줄어듭니다. 자세한 내용은 증강 매니페스트 파일을 사용하여 훈련 작업에 데이터세트 메타데이터 제공하기에서 확인하세요.
-
데이터 편향 분석: 훈련 전 데이터세트를 분석하고 비호감 집단에 대한 편향을 모델링하여 SageMaker Clarify로 모델이 편향되지 않은 데이터세트를 학습하는지 점검할 수 있습니다.
-
사용할 SageMaker SDK 선택: SageMaker AI에서 훈련 작업을 시작하는 방법에는 상위 수준 SageMaker AI Python SDK를 사용하거나 SDK for Python(Boto3) 또는 용 하위 수준 SageMaker APIs를 사용하는 두 가지가 있습니다 AWS CLI. SageMaker Python SDK는 하위 수준 SageMaker API를 추출하여 편리한 도구를 제공합니다. 에서 앞서 언급한 것처럼 SageMaker CanvasSageMaker 훈련의 기본 아키텍처, SageMaker Studio Classic 내의 JumpStart 또는 SageMaker AI Autopilot을 사용하여 코드 없음 또는 최소 코드 옵션을 추구할 수도 있습니다. SageMaker SageMaker
훈련 중
훈련 중에는 훈련 안정성, 훈련 속도, 훈련 효율성을 지속적으로 개선하는 동시에 컴퓨팅 리소스, 비용 최적화, 그리고 가장 중요한 모델 성능을 확장해야 합니다. 훈련 스테이지 중 및 관련 SageMaker 훈련 기능에 대한 자세한 내용은 뒤에 있습니다.
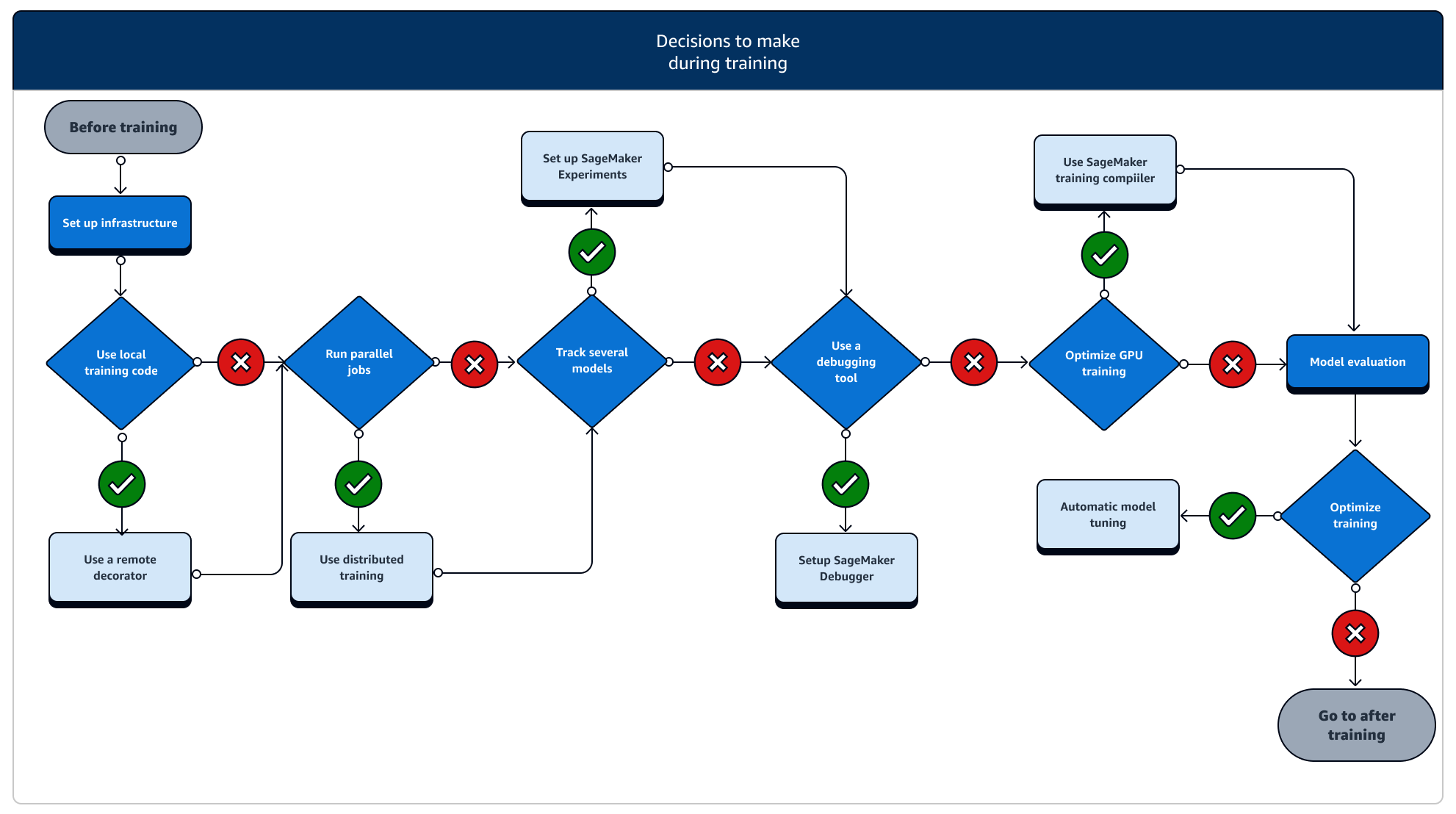
-
인프라 설정: 사용 사례에 적합한 인스턴스 유형과 인프라 관리 도구를 선택합니다. 소규모 인스턴스에서 시작하여 워크로드에 따라 확장할 수 있습니다. 테이블 형식 데이터세트를 기반으로 모델을 훈련시키려면 C4 또는 C5 인스턴스 패밀리 중 가장 작은 CPU 인스턴스부터 시작합니다. 컴퓨터 비전 또는 자연어 처리를 위한 대형 모델을 훈련시키려면 P2, P3, G4dn 또는 G5 인스턴스 패밀리 중 가장 작은 GPU 인스턴스부터 시작합니다. 또한 SageMaker AI에서 제공하는 다음 인스턴스 관리 도구를 사용하여 클러스터에서 다양한 인스턴스 유형을 혼합하거나 인스턴스를 웜 풀에 유지할 수 있습니다. 또한 영구 캐시를 사용하여 웜 풀에서만 지연 시간을 줄여 반복적인 훈련 작업의 지연 시간과 청구 가능 시간을 줄일 수 있습니다. 자세한 내용은 다음 주제를 참조하세요.
훈련 작업을 실행하려면 할당량이 충분해야 합니다. 할당량이 충분하지 않은 인스턴스에서 훈련 작업을 실행하면
ResourceLimitExceeded오류가 발생합니다. 사용자 계정에서 현재 사용 가능한 할당량은 Service Quotas Console에서 확인하세요. 할당량 증가 요청 방법은 지원되는 리전 및 할당량에서 알아보세요. 또한에 따라 요금 정보 및 사용 가능한 인스턴스 유형을 찾으려면 Amazon SageMaker 요금 페이지에서 테이블을 AWS 리전조회합니다. -
로컬 코드에서 훈련 작업 실행: Amazon SageMaker Studio Classic, Amazon SageMaker 노트북 또는 로컬 통합 개발 환경에서 원격 데코레이터로 로컬 코드에 주석을 달아 코드를 SageMaker 훈련 작업으로 실행할 수 있습니다. 자세한 내용은 로컬 코드를 SageMaker 훈련 작업으로 실행 섹션을 참조하세요.
-
훈련 작업 추적: SageMaker Experiments, SageMaker Debugger 또는 Amazon CloudWatch를 사용하여 훈련 작업을 모니터링하고 추적할 수 있습니다. 정확도와 수렴 측면에서 모델 성능을 관찰하고 SageMaker AI 실험을 사용하여 여러 훈련 작업 간의 지표 비교 분석을 실행할 수 있습니다. SageMaker Debugger 프로파일링 도구 또는 Amazon CloudWatch를 사용하여 컴퓨팅 리소스 사용률을 감시할 수 있습니다. 자세한 내용은 다음 주제를 참조하세요.
또한 딥 러닝 작업의 경우 Amazon SageMaker Debugger 모델 디버깅 도구와 내장 규칙을 사용하여 모델 수렴 및 가중치 업데이트 프로세스에서 더 복잡한 문제를 식별할 수 있습니다.
-
분산 훈련: 훈련 작업이 훈련 인프라의 잘못된 구성이나 메모리 부족 문제로 인해 중단되지 않고 안정 단계로 접어들고 있다면, 며칠 또는 몇 개월의 장기간으로 작업을 확장 실행할 수 있는 추가 옵션을 찾고 싶을 수 있습니다. 스케일 업 준비가 되면 분산 훈련을 고려합니다. SageMaker AI는 가벼운 ML 워크로드에서 무거운 딥 러닝 워크로드에 이르기까지 분산 계산을 위한 다양한 옵션을 제공합니다.
매우 큰 데이터 세트에서 매우 큰 모델을 훈련시키는 딥 러닝 작업의 경우 SageMaker AI 분산 훈련 전략 중 하나를 사용하여 데이터 병렬 처리, 모델 병렬 처리 또는이 둘의 조합을 확장하고 달성하는 것이 좋습니다. 또한 SageMaker 훈련 컴파일러를 사용하여 GPU 인스턴스에서 모델 그래프를 컴파일하고 최적화할 수도 있습니다. 이러한 SageMaker AI 기능은 PyTorch, TensorFlow 및 Hugging Face Transformer와 같은 딥 러닝 프레임워크를 지원합니다.
-
모델 하이퍼파라미터 튜닝: SageMaker AI를 사용한 자동 모델 튜닝을 사용하여 모델 하이퍼파라미터를 튜닝합니다. SageMaker AI는 그리드 검색 및 베이지안 검색과 같은 하이퍼파라미터 튜닝 방법을 제공하여 개선되지 않는 하이퍼파라미터 튜닝 작업을 위한 조기 중지 기능을 갖춘 병렬 하이퍼파라미터 튜닝 작업을 시작합니다.
-
스팟 인스턴스를 통한 체크포인트 및 비용 절감: 훈련 시간이 큰 문제가 되지 않는 경우, 관리형 스팟 인스턴스로 모델 훈련 비용을 최적화하는 안을 고려할 수 있습니다. 스팟 인스턴스 대체로 인한 간헐적 일시 중지 상태를 복원하려면 스팟 훈련용 체크포인트를 활성화해야 함에 유의하세요. 또한 예기치 않은 훈련 작업 종료의 경우 체크포인트 기능을 사용하여 모델을 백업할 수 있습니다. 자세한 내용은 다음 주제를 참조하세요.
훈련 후
훈련 후에는 모델 배포 및 추론 시 사용할 최종 모델 아티팩트를 확보합니다. 다음 다이어그램과 같이 훈련 후 단계에는 추가 작업이 포함됩니다.

-
기준 모델 확보: 모델 아티팩트 확보 후 기준 모델로 설정할 수 있습니다. 프로덕션으로 모델 배포로 이동하기 전에 다음 훈련 후 작업과 SageMaker AI 기능 사용을 고려하세요.
-
모델 성능 검사 및 편향 점검: Amazon CloudWatch 지표 및 SageMaker Clarify로 수신 데이터 및 모델에 있는 훈련 후 편향을 시간 경과에 따라 기준과 비교하여 탐지합니다. 새 데이터와 모델 예측을 새 데이터 기준으로 정기적으로 또는 실시간으로 평가해야 합니다. 이러한 기능을 사용하면 데이터와 모델의 급격한 변화 또는 이상은 물론 점진적인 변화 또는 드리프트에 대한 알림을 받을 수 있습니다.
-
SageMaker AI의 증분 훈련 기능을 사용하여 확장된 데이터 세트로 모델을 로드 및 업데이트(또는 미세 조정)할 수도 있습니다.
-
전체 ML 수명 주기를 오케스트레이션하기 위해 모델 훈련을 SageMaker AI 파이프라인의 단계로 등록하거나 SageMaker AI에서 제공하는 다른 워크플로 기능의 일부로 등록할 수 있습니다.
