Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Funktionsweise von Factorization Machines
Die Prognosenaufgabe für ein Factorization Machine-Modell besteht darin, eine Funktion ŷ aus einem Funktionsumfang x i für eine Zieldomain zu schätzen. Diese Domain ist reellwertig für die Regression und binär für die Klassifizierung. Das Factorization Machine-Modell wird überwacht und verfügt somit über ein Trainingsdatensatz (xi,yj). Die Vorteile dieses Modells liegen in der Art und Weise, wie es eine faktorisierte Parametrisierung zum Erfassen der paarweisen Funktionsinteraktionen verwendet. Dies kann mathematisch wie folgt dargestellt werden:
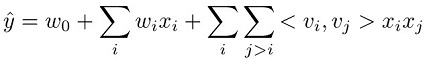
Die drei Ausdrücke in dieser Gleichung entsprechen den drei Komponenten des Modells:
-
Der w0 -Ausdruck stellt den globalen Bias-Wert dar.
-
Die wi linearen Ausdrücke modellieren die Stärke der ithVariable.
-
Die <vi,vj> Faktorisierungsbegriffe modellieren die paarweise Interaktion zwischen der ith und jth Variablen.
Die globalen Bias- und linearen Ausdrücke gleichen denen in einem linearen Modell. Die paarweisen Funktionsinteraktionen werden im dritten Ausdruck als inneres Produkt der korrespondierenden Faktoren, die für jede Funktion gelernt wurden, modelliert. Diese gelernten Faktoren können auch als einbettende Vektoren der einzelnen Funktion betrachtet werden. Wenn beispielsweise in einer Klassifizierungsaufgabe ein Funktionspaar häufiger gemeinsam in Stichproben mit positiver Bezeichnung vorkommt, ist das innere Produkt von deren Faktoren groß. Mit anderen Worten: Die einbettenden Vektoren liegen in Kosinus-Ähnlichkeit nahe zusammen. Weitere Informationen über das Factorization Machine-Modell finden Sie unter Factorization Machines
Bei Regressionsaufgaben wird das Modell trainiert, indem der quadratische Fehler zwischen der Modellvorhersage ŷn und dem Zielwert yn minimiert wird. Dies wird als quadratischer Verlust bezeichnet:
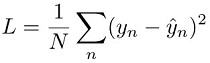
Für eine Klassifizierungsaufgabe wird das Modell trainiert, indem der Kreuz-Entropie-Verlust, auch als Protokollverlust bezeichnet, minimiert wird:
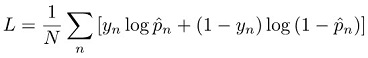
Wobei:
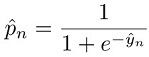
Weitere Informationen zu Verlustfunktionen für die Klassifizierung finden Sie unter Loss functions for classification
