Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Online-Erklärbarkeit mit Clarify SageMaker
Diese Anleitung zeigt, wie Sie die Online-Erklärbarkeit mit Clarify konfigurieren. SageMaker Mit SageMaker KI-Echtzeit-Inferenzendpunkten können Sie die Erklärbarkeit kontinuierlich in Echtzeit analysieren. Die Online-Erklärbarkeitsfunktion passt in den Teil „Für die Produktion bereitstellen“ des Amazon SageMaker AI Machine Learning Learning-Workflows.
So funktioniert die Verdeutlichung der Online-Erklärbarkeit
Die folgende Grafik zeigt die SageMaker KI-Architektur für das Hosten eines Endpunkts, der Erklärungsanfragen bedient. Sie zeigt Interaktionen zwischen einem Endpunkt, dem Modellcontainer und dem Clarify-Erklärer. SageMaker
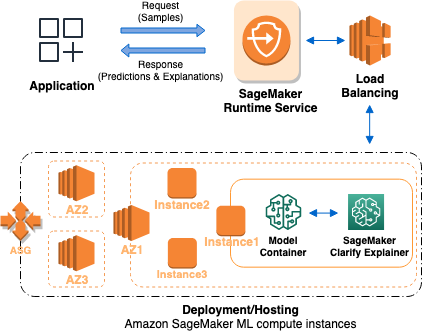
So funktioniert die Verdeutlichung der Online-Erklärbarkeit: Die Anwendung sendet eine InvokeEndpoint Anfrage im REST-Stil an den SageMaker AI Runtime Service. Der Dienst leitet diese Anfrage an einen SageMaker KI-Endpunkt weiter, um Vorhersagen und Erklärungen zu erhalten. Anschließend erhält der Service die Antwort vom Endpunkt. Schließlich sendet der Service die Antwort an die Anwendung zurück.
Um die Verfügbarkeit der Endgeräte zu erhöhen, versucht SageMaker KI automatisch, Endpunktinstanzen entsprechend der Anzahl der Instanzen in der Endpunktkonfiguration in mehreren Availability Zones zu verteilen. Auf einer Endpunktinstanz ruft der SageMaker Clarify-Erklärer bei einer neuen Anfrage zur Erläuterung den Modellcontainer für Vorhersagen auf. Anschließend werden die Funktionszuordnungen berechnet und zurückgegeben.
Hier sind die vier Schritte, um einen Endpunkt zu erstellen, der die Online-Erklärbarkeit von Clarify verwendet SageMaker :
-
Erstellen Sie mithilfe der API eine Endpunktkonfiguration mit der SageMaker Clarify-Erklärkonfiguration.
CreateEndpointConfig -
Erstellen Sie einen Endpunkt und stellen Sie SageMaker KI mithilfe der API die Endpunktkonfiguration zur Verfügung.
CreateEndpointDer Service startet die ML-Compute-Instance und stellt die Modelle gemäß der Konfiguration bereit. -
Rufen Sie den Endpunkt auf: Nachdem der Endpunkt in Betrieb ist, rufen Sie die SageMaker AI Runtime API
InvokeEndpointauf, um Anfragen an den Endpunkt zu senden. Der Endpunkt gibt dann Erklärungen und Prognosen zurück.
