Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verbinden zu Datenquellen
In Amazon SageMaker Canvas können Sie Daten von einem Speicherort außerhalb Ihres lokalen Dateisystems über einen AWS Service, eine SaaS-Plattform oder andere Datenbanken mithilfe von JDBC-Konnektoren importieren. So könnte es beispielsweise sein, dass Sie Tabellen aus einem Data Warehouse in Amazon Redshift importieren möchten, oder Sie möchten möglicherweise Google Analytics-Daten importieren.
Wenn Sie den Import-Workflow zum Importieren von Daten in der Canvas-Anwendung durchlaufen, können Sie Ihre Datenquelle und dann die Daten auswählen, die Sie importieren möchten. Für bestimmte Datenquellen, wie Snowflake und Amazon Redshift, müssen Sie Ihre Anmeldeinformationen angeben und eine Verbindung zur Datenquelle hinzufügen.
Der folgende Screenshot zeigt die Datenquellen-Symbolleiste im Import-Workflow, wobei alle verfügbaren Datenquellen hervorgehoben sind. Sie können nur Daten aus den Datenquellen importieren, die Ihnen zur Verfügung stehen. Wenden Sie sich an Ihren Administrator, wenn Ihre gewünschte Datenquelle nicht verfügbar ist.
Die folgenden Abschnitte enthalten Informationen zum Herstellen von Verbindungen zu externen Datenquellen und zum Importieren von Daten aus diesen. Lesen Sie zunächst den folgenden Abschnitt, um festzustellen, welche Berechtigungen Sie zum Importieren von Daten aus Ihrer Datenquelle benötigen.
Berechtigungen
Überprüfen Sie die folgenden Informationen, um sicherzustellen, dass Sie über die erforderlichen Berechtigungen zum Importieren von Daten aus Ihrer Datenquelle verfügen:
Amazon S3: Sie können Daten aus jedem Amazon S3 Bucket importieren, sofern Ihr Benutzer über Zugriffserlaubnis auf den Bucket verfügt. Weitere Informationen zur Verwendung von AWS IAM zur Steuerung des Zugriffs auf Amazon S3-Buckets finden Sie unter Identitäts- und Zugriffsmanagement in Amazon S3 im Amazon S3 S3-Benutzerhandbuch.
Amazon Athena: Wenn Sie die AmazonSageMakerFullAccessRichtlinie und die Richtlinie mit der AmazonSageMakerCanvasFullAccessAusführungsrolle Ihres Benutzers verknüpft haben, können Sie Ihre Anfrage AWS Glue Data Catalog bei Amazon Athena abfragen. Wenn Sie Teil einer Athena-Arbeitsgruppe sind, stellen Sie sicher, dass der Canvas-Benutzer berechtigt ist, Athena-Abfragen für die Daten auszuführen. Weitere Informationen finden Sie unter Verwendung von Arbeitsgruppen für die Ausführung von Abfragen im Amazon Athena-Benutzerhandbuch.
Amazon DocumentDB: Sie können Daten aus jeder Amazon DocumentDB DocumentDB-Datenbank importieren, sofern Sie über die Anmeldeinformationen (Benutzername und Passwort) verfügen, um eine Verbindung mit der Datenbank herzustellen, und dass der Ausführungsrolle Ihres Benutzers die minimalen Canvas-Basisberechtigungen zugewiesen sind. Weitere Informationen zu Canvas-Berechtigungen finden Sie unter. Voraussetzungen für die Einrichtung von Amazon SageMaker Canvas
Amazon Redshift: Informationen dazu, wie Sie sich die erforderlichen Berechtigungen zum Importieren von Daten aus Amazon Redshift erteilen können, finden Sie unter Benutzerberechtigungen für den Import von Amazon Redshift-Daten gewähren.
Amazon RDS: Wenn Sie die AmazonSageMakerCanvasFullAccessRichtlinie mit der Ausführungsrolle Ihres Benutzers verknüpft haben, können Sie von Canvas aus auf Ihre Amazon RDS-Datenbanken zugreifen.
SaaS-Plattformen: Wenn Sie die AmazonSageMakerFullAccessRichtlinie und die AmazonSageMakerCanvasFullAccessRichtlinie mit der Ausführungsrolle Ihres Benutzers verknüpft haben, verfügen Sie über die erforderlichen Berechtigungen, um Daten von SaaS-Plattformen zu importieren. Weitere Informationen zum Herstellen einer Verbindung zu einem bestimmten SaaS-Konnektor finden Sie unter Verwenden Sie SaaS-Konnektoren mit Canvas.
JDBC-Konnektoren: Für Datenbankquellen wie Databricks, MySQL oder MariaDB müssen Sie die Authentifizierung mit Benutzername und Passwort in der Quelldatenbank aktivieren, bevor Sie versuchen, eine Verbindung von Canvas aus herzustellen. Wenn Sie eine Verbindung zu einer Databricks-Datenbank herstellen, benötigen Sie die JDBC-URL, die die erforderlichen Anmeldeinformationen enthält.
Stellen Sie eine Connect zu einer Datenbank her, die in gespeichert ist AWS
Möglicherweise möchten Sie Daten importieren, die Sie gespeichert haben AWS. Sie können Daten aus Amazon S3 importieren, Amazon Athena verwenden, um eine Datenbank im abzufragen AWS Glue Data Catalog, Daten aus Amazon RDS importieren oder eine Verbindung zu einer bereitgestellten Amazon Redshift Redshift-Datenbank (nicht Redshift Serverless) herstellen.
Sie können mehrere Verbindungen zu Amazon Redshift erstellen. Für Amazon Athena können Sie auf alle Datenbanken zugreifen, die Sie in Ihrem AWS Glue Data Catalog haben. Für Amazon S3 können Sie Daten aus einem Bucket importieren, sofern Sie über die erforderlichen Berechtigungen verfügen.
In den folgenden Abschnitten finden Sie weitere Informationen.
Connect zu Daten in Amazon S3, Amazon Athena oder Amazon RDS her
Für Amazon S3 können Sie Daten aus einem Amazon-S3-Bucket importieren, sofern Sie über Zugriffsberechtigungen für den Bucket verfügen.
Für Amazon Athena können Sie auf Datenbanken in Ihrem zugreifen, AWS Glue Data Catalog sofern Sie über die entsprechenden Berechtigungen Ihrer Amazon Athena Athena-Arbeitsgruppe verfügen.
Wenn Sie für Amazon RDS die AmazonSageMakerCanvasFullAccessRichtlinie an die Rolle Ihres Benutzers angehängt haben, können Sie Daten aus Ihren Amazon RDS-Datenbanken in Canvas importieren.
Informationen zum Importieren von Daten aus einem Amazon-S3-Bucket oder zum Ausführen von Abfragen und Importieren von Datentabellen mit Amazon Athena finden Sie unter Erstellen eines Datensatzes. Sie können nur Tabellendaten aus Amazon Athena importieren, und Sie können Tabellen- und Bilddaten aus Amazon S3 importieren.
Stellen Sie eine Connect zu einer Amazon DocumentDB DocumentDB-Datenbank her
Amazon DocumentDB ist ein vollständig verwalteter, serverloser Dokumentendatenbankservice. Sie können unstrukturierte Dokumentdaten, die in einer Amazon DocumentDB DocumentDB-Datenbank gespeichert sind, als tabellarischen Datensatz in SageMaker Canvas importieren und anschließend Modelle für maschinelles Lernen mit den Daten erstellen.
Wichtig
Ihre SageMaker AI-Domain muss im Modus Nur VPC konfiguriert sein, um Verbindungen zu Amazon DocumentDB hinzuzufügen. Sie können nur in derselben Amazon VPC wie Ihre Canvas-Anwendung auf Amazon DocumentDB-Cluster zugreifen. Darüber hinaus kann Canvas nur eine Verbindung zu TLS-fähigen Amazon DocumentDB-Clustern herstellen. Weitere Informationen zur Einrichtung von Canvas nur im VPC-Modus finden Sie unterAmazon SageMaker Canvas in einer VPC ohne Internetzugang konfigurieren.
Um Daten aus Amazon DocumentDB DocumentDB-Datenbanken zu importieren, benötigen Sie Anmeldeinformationen für den Zugriff auf die Amazon DocumentDB DocumentDB-Datenbank und müssen den Benutzernamen und das Passwort angeben, wenn Sie eine Datenbankverbindung herstellen. Sie können detailliertere Berechtigungen konfigurieren und den Zugriff einschränken, indem Sie die Amazon DocumentDB DocumentDB-Benutzerberechtigungen ändern. Weitere Informationen zur Zugriffskontrolle in Amazon DocumentDB finden Sie unter Database Access Using Role-Based Access Control im Amazon DocumentDB Developer Guide.
Wenn Sie aus Amazon DocumentDB importieren, konvertiert Canvas Ihre unstrukturierten Daten in einen tabellarischen Datensatz, indem die Felder den Spalten in einer Tabelle zugeordnet werden. Zusätzliche Tabellen werden für jedes komplexe Feld (oder jede verschachtelte Struktur) in den Daten erstellt, wobei die Spalten den Unterfeldern des komplexen Felds entsprechen. Ausführlichere Informationen zu diesem Prozess und Beispiele für Schemakonvertierung finden Sie auf der Seite Amazon DocumentDB JDBC Driver Schema Discovery
Canvas kann nur eine Verbindung zu einer einzigen Datenbank in Amazon DocumentDB herstellen. Um Daten aus einer anderen Datenbank zu importieren, müssen Sie eine neue Verbindung herstellen.
Sie können Daten mit den folgenden Methoden aus Amazon DocumentDB in Canvas importieren:
-
Erstellen eines Datensatzes. Sie können Ihre Amazon DocumentDB DocumentDB-Daten importieren und einen tabellarischen Datensatz in Canvas erstellen. Wenn Sie diese Methode wählen, stellen Sie sicher, dass Sie das Verfahren zum Importieren von Tabellendaten befolgen.
-
Erstellen Sie einen Datenfluss. Sie können eine Datenvorbereitungspipeline in Canvas erstellen und Ihre Amazon DocumentDB DocumentDB-Datenbank als Datenquelle hinzufügen.
Um mit dem Import Ihrer Daten fortzufahren, folgen Sie dem Verfahren für eine der in der vorherigen Liste verlinkten Methoden.
Wenn Sie in einem der Workflows den Schritt zur Auswahl einer Datenquelle erreicht haben (Schritt 6 zum Erstellen eines Datensatzes oder Schritt 8 zum Erstellen eines Datenflusses), gehen Sie wie folgt vor:
Öffnen Sie für Data Source das Drop-down-Menü und wählen Sie DocumentDB.
Wählen Sie Add connection (Verbindung hinzufügen).
-
Geben Sie im Dialogfeld Ihre Amazon DocumentDB DocumentDB-Anmeldeinformationen an:
Geben Sie einen Verbindungsnamen ein. Dies ist ein Name, der von Canvas verwendet wird, um diese Verbindung zu identifizieren.
Wählen Sie für Cluster den Cluster in Amazon DocumentDB aus, der Ihre Daten speichert. Canvas füllt das Drop-down-Menü automatisch mit Amazon DocumentDB-Clustern in derselben VPC wie Ihre Canvas-Anwendung.
Geben Sie den Benutzernamen für Ihren Amazon DocumentDB-Cluster ein.
Geben Sie das Passwort für Ihren Amazon DocumentDB-Cluster ein.
Geben Sie den Namen der Datenbank ein, zu der Sie eine Verbindung herstellen möchten.
-
Die Einstellungsoption Lesen bestimmt, von welchen Instance-Typen auf Ihrem Cluster-Canvas die Daten gelesen werden. Wählen Sie eine der folgenden Optionen:
Sekundär bevorzugt — Canvas liest standardmäßig von den sekundären Instanzen des Clusters. Wenn jedoch keine sekundäre Instanz verfügbar ist, liest Canvas von einer primären Instance.
Sekundär — Canvas liest nur von den sekundären Instanzen des Clusters, wodurch verhindert wird, dass die Lesevorgänge die regulären Lese- und Schreibvorgänge des Clusters beeinträchtigen.
-
Wählen Sie Add connection (Verbindung hinzufügen). Die folgende Abbildung zeigt das Dialogfeld mit den vorherigen Feldern für eine Amazon DocumentDB DocumentDB-Verbindung.
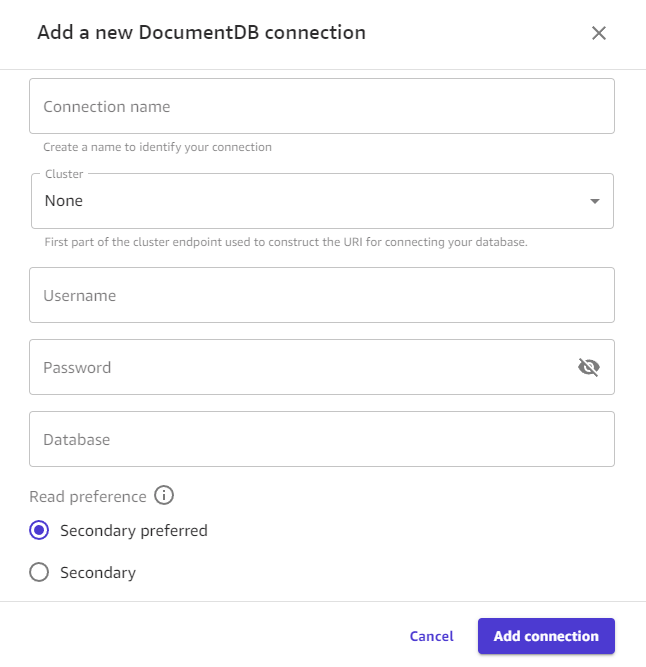
Sie sollten jetzt über eine Amazon DocumentDB DocumentDB-Verbindung verfügen und Ihre Amazon DocumentDB DocumentDB-Daten in Canvas verwenden, um entweder einen Datensatz oder einen Datenfluss zu erstellen.
Verbindung zu einer Amazon Redshift-Datenbank
Sie können Daten aus Amazon Redshift importieren, einem Data Warehouse, in dem Ihre Organisation ihre Daten aufbewahrt. Bevor Sie Daten aus Amazon Redshift importieren können, muss die AmazonRedshiftFullAccess verwaltete Richtlinie an die von Ihnen verwendete AWS IAM-Rolle angehängt sein. Anweisungen zum Anfügen der Richtlinie finden Sie unter Benutzern Berechtigungen zum Importieren von Amazon Redshift-Daten gewähren.
Um Daten aus Amazon Redshift zu importieren, führen Sie die folgenden Schritte aus:
-
Erstellen Sie eine Verbindung zu einer Amazon Redshift-Datenbank.
-
Wählen Sie die Daten aus, die Sie importieren möchten.
-
Importieren Sie die Daten.
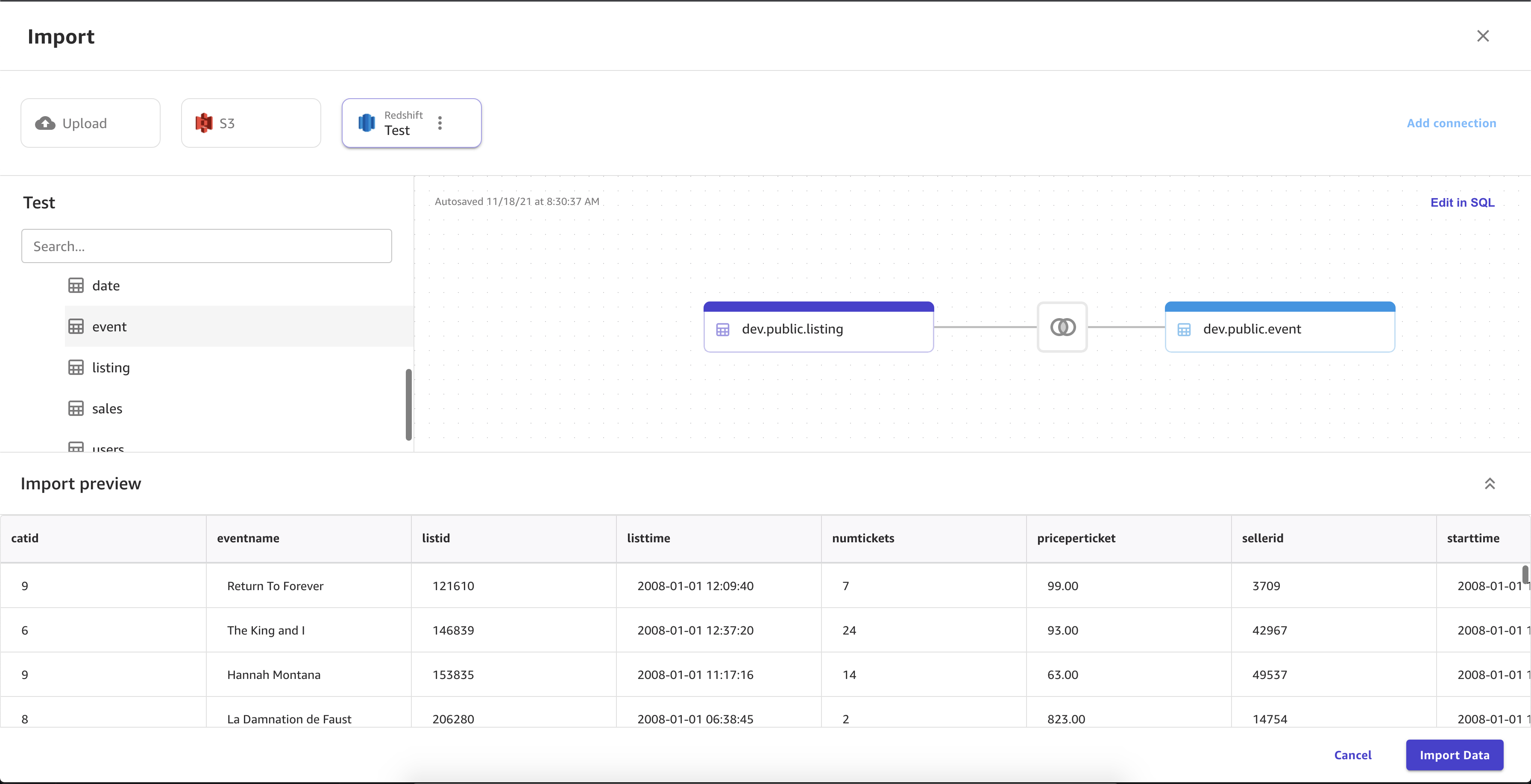
Sie können den Amazon Redshift Redshift-Editor verwenden, um Datensätze in den Importbereich zu ziehen und sie in SageMaker Canvas zu importieren. Für mehr Kontrolle über die im Datensatz zurückgegebenen Werte können Sie Folgendes verwenden:
-
SQL-Abfragen
-
Joins
Mit SQL-Abfragen können Sie anpassen, wie Sie die Werte in den Datensatz importieren. Sie können beispielsweise die im Datensatz zurückgegebenen Spalten oder den Wertebereich für eine Spalte angeben.
Sie können Joins verwenden, um mehrere Datensätze aus Amazon Redshift zu einem einzigen Datensatz zu kombinieren. Sie können Ihre Datensätze aus Amazon Redshift in das Fenster ziehen, in dem Sie die Datensätze verbinden können.
Sie können den SQL-Editor verwenden, um den Datensatz, den Sie verknüpft haben, zu bearbeiten und den verknüpften Datensatz in einen einzelnen Knoten zu konvertieren. Sie können einen anderen Datensatz mit dem Knoten verbinden. Sie können die Daten, die Sie ausgewählt haben, in SageMaker Canvas importieren.
Gehen Sie wie folgt vor, um Daten aus Amazon Redshift zu importieren.
Gehen Sie in der SageMaker Canvas-Anwendung zur Seite Datasets.
Wählen Sie Daten importieren und wählen Sie im Dropdownmenü die Option Tabellarisch aus.
-
Geben Sie einen Namen für den Datensatz ein und wählen Sie dann Erstellen.
Öffnen Sie für Datenquell das Dropdown-Menü und wählen Sie Redshift.
-
Wählen Sie Add connection (Verbindung hinzufügen).
-
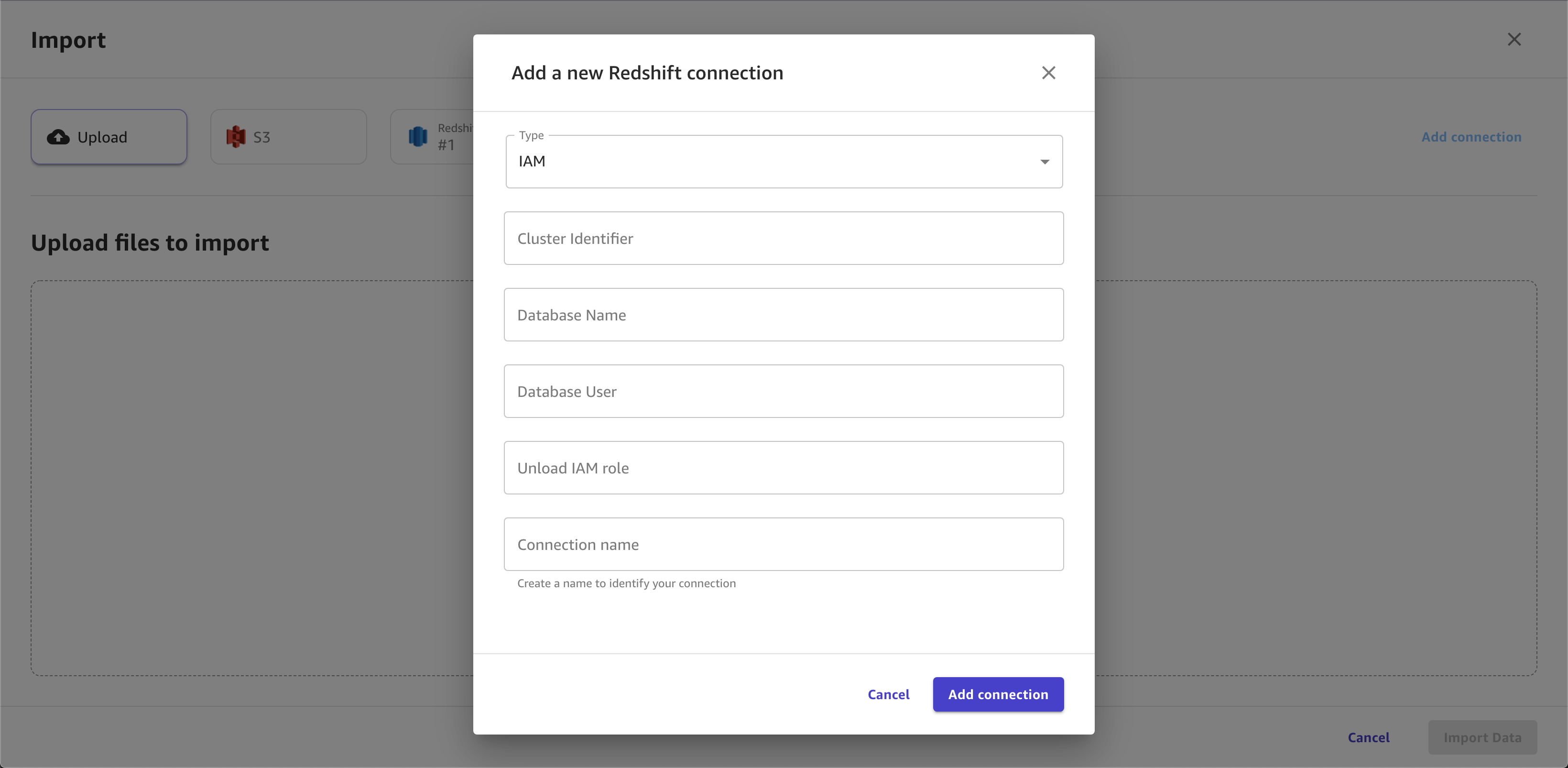
Geben Sie im Dialogfeld Ihre Amazon Redshift-Anmeldeinformationen ein:
-
Wählen Sie als Authentifizierungsmethode IAM aus.
-
Geben Sie die Cluster-ID ein, um anzugeben, mit welchem Cluster Sie eine Verbindung herstellen möchten. Geben Sie nur die Cluster-Kennung und nicht den vollständigen Endpunkt des Amazon-Redshift-Clusters ein.
-
Geben Sie den Datenbanknamen der Datenbank ein, mit der Sie eine Verbindung herstellen möchten.
-
Geben Sie einen Datenbankbenutzer ein, um den Benutzer zu identifizieren, den Sie für die Verbindung mit der Datenbank verwenden möchten.
-
Geben Sie für ARN den IAM-Rollen-ARN der Rolle ein, die der Amazon Redshift-Cluster übernehmen soll, um Daten zu Amazon S3 zu verschieben und zu schreiben. Weitere Informationen zu dieser Rolle finden Sie unter Authorizing Amazon Redshift to access other AWS services in Ihrem Namen im Amazon Redshift Management Guide.
-
Geben Sie einen Verbindungsnamen ein. Dies ist ein Name, der von Canvas verwendet wird, um diese Verbindung zu identifizieren.
-
-
Ziehen Sie die CSV-Datei, die Sie importieren, von der Registerkarte mit dem Namen Ihrer Verbindung in den Bereich Drag-and-Drop-Tabelle zum Importieren.
-
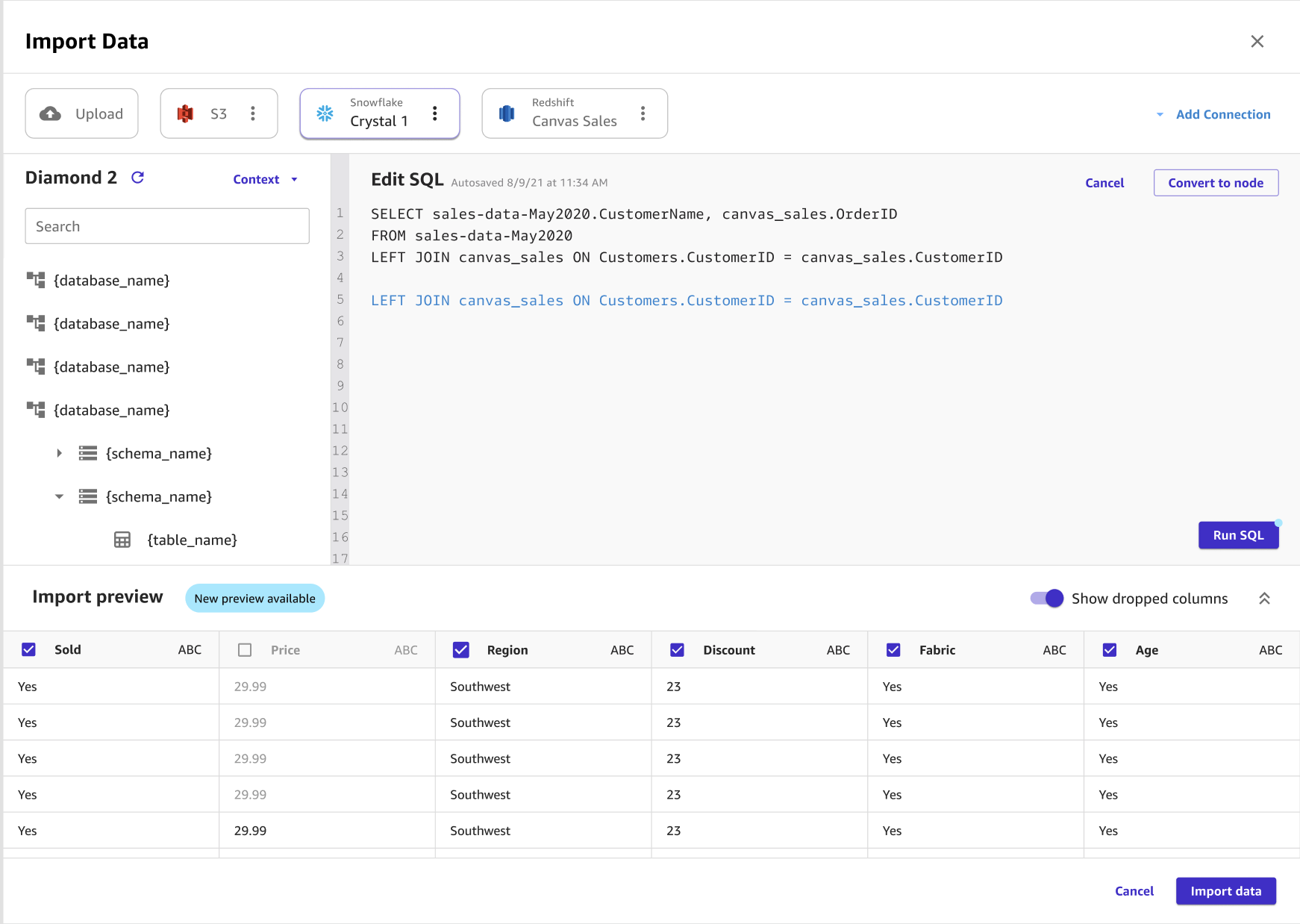
Optional: Ziehen Sie weitere Tabellen in den Importbereich. Sie können die GUI verwenden, um die Tabellen zu verbinden. Um Ihre Verknüpfungen genauer zu gestalten, wählen Sie In SQL bearbeiten aus.
-
Optional: Wenn Sie SQL verwenden, um die Daten abzufragen, können Sie Kontext wählen, um der Verbindung Kontext hinzuzufügen, indem Sie Werte für Folgendes angeben:
-
Lager
-
Datenbank
-
Schema
-
-
Wählen Sie Daten importieren.
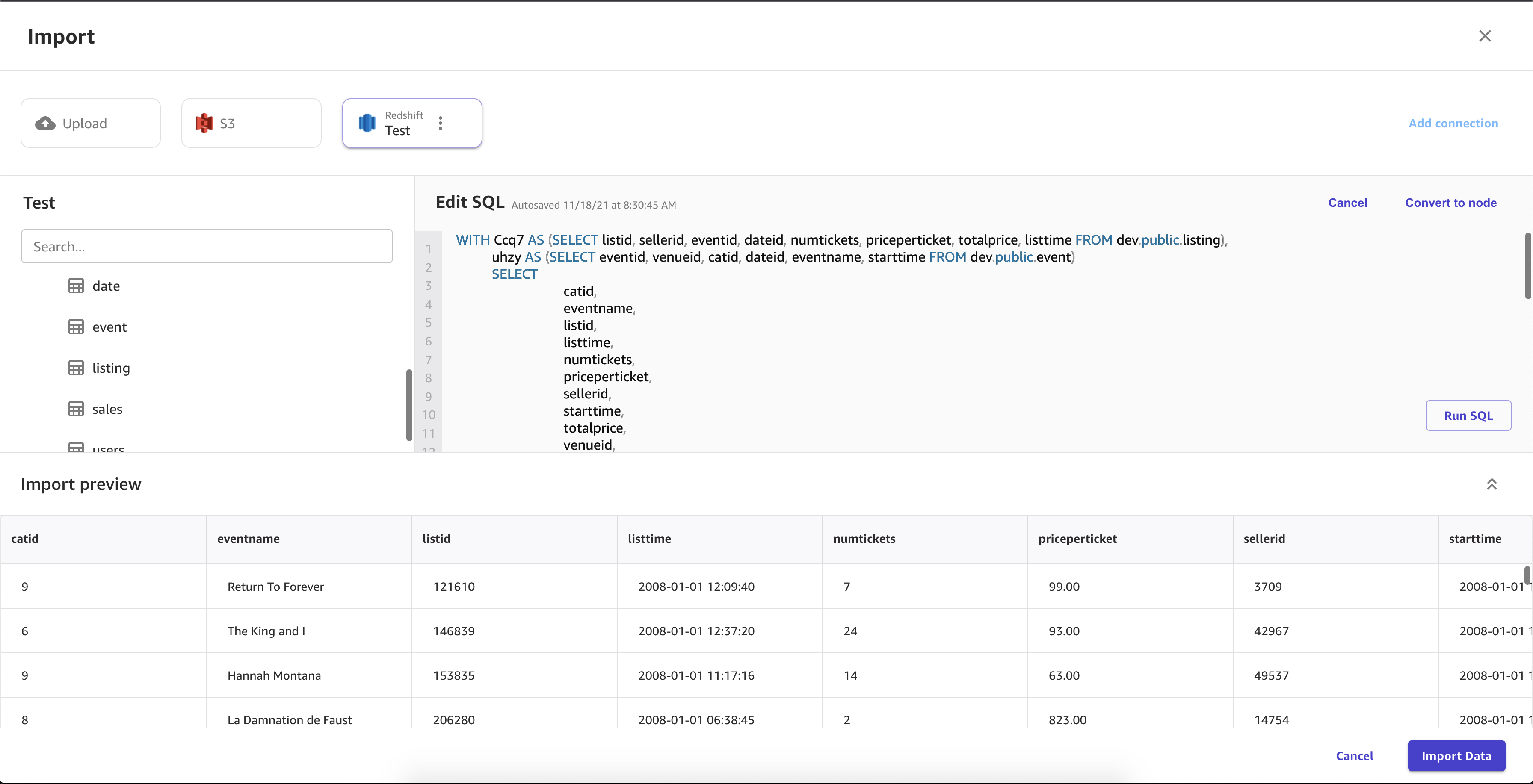
Die folgende Abbildung zeigt ein Beispiel für Felder, die für eine Amazon Redshift-Verbindung angegeben sind.
Die folgende Abbildung zeigt die Seite, die zum Verbinden von Datensätzen in Amazon Redshift verwendet wird.
Die folgende Abbildung zeigt eine SQL-Abfrage, die verwendet wird, um einen Join in Amazon Redshift zu bearbeiten.
Stellen Sie mit JDBC-Konnektoren eine Connect zu Ihren Daten her
Mit JDBC können Sie aus Quellen wie Databricks, MySQL, PostgreSQL, MariaDB SQLServer, Amazon RDS und Amazon Aurora eine Verbindung zu Ihren Datenbanken herstellen.
Sie müssen sicherstellen, dass Sie über die erforderlichen Anmeldeinformationen und Berechtigungen verfügen, um die Verbindung von Canvas aus herzustellen.
Für Databricks müssen Sie eine JDBC-URL angeben. Die URL-Formatierung kann zwischen den Databricks-Instances variieren. Informationen zum Auffinden der URL und zur Angabe der darin enthaltenen Parameter finden Sie in der Databricks-Dokumentation unter JDBC-Konfiguration und Verbindungsparameter
. Im Folgenden finden Sie ein Beispiel dafür, wie eine URL formatiert werden kann: jdbc:spark://aws-sagemaker-datawrangler.cloud.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/3122619508517275/0909-200301-cut318;AuthMech=3;UID=token;PWD=personal-access-tokenFür andere Datenbankquellen müssen Sie die Authentifizierung mit Benutzername und Passwort einrichten und diese Anmeldeinformationen dann angeben, wenn Sie von Canvas aus eine Verbindung zur Datenbank herstellen.
Darüber hinaus muss Ihre Datenquelle entweder über das öffentliche Internet zugänglich sein, oder wenn Ihre Canvas-Anwendung nur im VPC-Modus ausgeführt wird, muss die Datenquelle in derselben VPC ausgeführt werden. Weitere Informationen zur Konfiguration einer Amazon RDS-Datenbank in einer VPC finden Sie unter Amazon VPC VPCs und Amazon RDS im Amazon RDS-Benutzerhandbuch.
Nachdem Sie Ihre Datenquellenanmeldedaten konfiguriert haben, können Sie sich bei der Canvas-Anwendung anmelden und eine Verbindung zur Datenquelle herstellen. Geben Sie Ihre Anmeldeinformationen (oder bei Databricks die URL) an, wenn Sie die Verbindung herstellen.
Connect zu Datenquellen her mit OAuth
Canvas unterstützt die Verwendung OAuth als Authentifizierungsmethode für die Verbindung zu Ihren Daten in Snowflake und Salesforce Data Cloud. OAuth
Anmerkung
Sie können für jede Datenquelle nur eine OAuth Verbindung herstellen.
Um die Verbindung zu autorisieren, müssen Sie die unter Richten Sie Verbindungen zu Datenquellen ein mit OAuth beschriebene Ersteinrichtung befolgen.
Nachdem Sie die OAuth Anmeldeinformationen eingerichtet haben, können Sie wie folgt vorgehen, um eine Snowflake- oder Salesforce Data Cloud-Verbindung hinzuzufügen mit: OAuth
Melden Sie sich bei der Canvas Anwendung an.
Erstellen Sie einen tabellarischen Datensatz. Wenn Sie aufgefordert werden, Daten hochzuladen, wählen Sie Snowflake oder Salesforce Data Cloud als Datenquelle aus.
Erstellen Sie eine neue Verbindung zu Ihrer Snowflake- oder Salesforce Data Cloud-Datenquelle. Geben Sie OAuth als Authentifizierungsmethode an und geben Sie Ihre Verbindungsdetails ein.
Sie sollten jetzt in der Lage sein, Daten aus Ihren Datenbanken in Snowflake oder Salesforce Data Cloud zu importieren.
Stellen Sie eine Connect zu einer SaaS-Plattform her
Sie können Daten von Snowflake und über 40 anderen externen SaaS-Plattformen importieren. Die vollständige Liste der Steckverbinder finden Sie in der Tabelle unter Datenimport.
Anmerkung
Sie können nur tabellarische Daten, wie Datentabellen, von SaaS-Plattformen importieren.
Verwenden Sie Snowflake mit Canvas
Snowflake ist ein Datenspeicher- und Analysedienst, und Sie können Ihre Daten von Snowflake in Canvas importieren. SageMaker Weitere Informationen zu Snowflake finden Sie in der Snowflake-Dokumentation
Sie können mithilfe der folgenden Verfahren Daten aus Ihrem Snowflake-Konto importieren:
-
Stellen Sie eine Verbindung zur Snowflake-Datenbank her.
-
Wählen Sie die Daten aus, die Sie importieren möchten, indem Sie die Tabelle per Drag-and-Drop aus dem linken Navigationsmenü in den Editor ziehen.
-
Importieren Sie die Daten.
Sie können den Snowflake-Editor verwenden, um Datensätze in den Importbereich zu ziehen und sie in Canvas zu importieren. SageMaker Für mehr Kontrolle über die im Datensatz zurückgegebenen Werte können Sie Folgendes verwenden:
-
SQL-Abfragen
-
Joins
Mit SQL-Abfragen können Sie anpassen, wie Sie die Werte in den Datensatz importieren. Sie können beispielsweise die im Datensatz zurückgegebenen Spalten oder den Wertebereich für eine Spalte angeben.
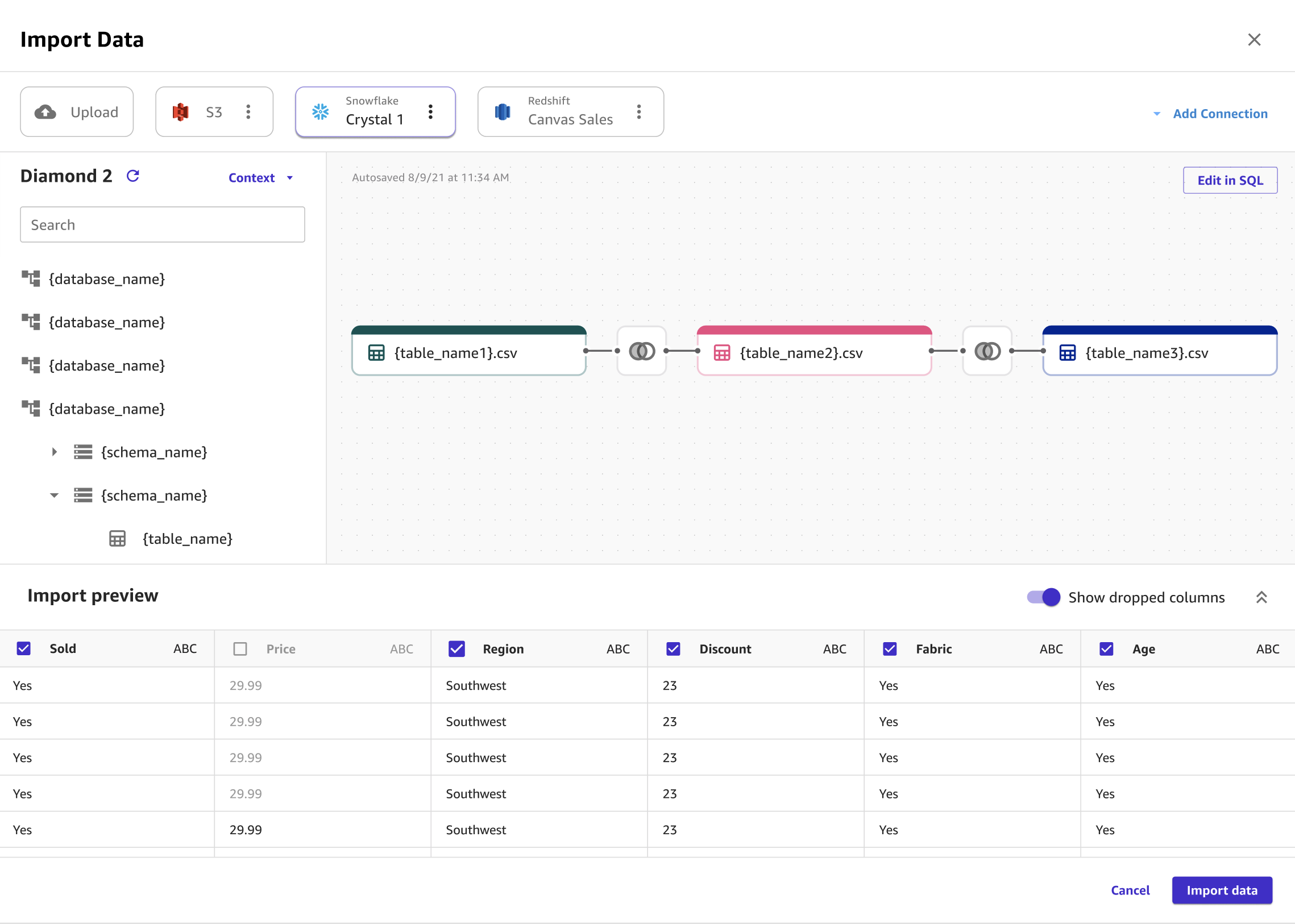
Sie können mehrere Snowflake-Datensätze zu einem einzigen Datensatz zusammenfügen, bevor Sie sie mithilfe von SQL oder der Canvas-Schnittstelle in Canvas importieren. Sie können Ihre Datensätze aus Snowflake in das Fenster ziehen, in dem Sie die Datensätze verbinden können, oder Sie können die Verknüpfungen in SQL bearbeiten und das SQL in einen einzelnen Knoten konvertieren. Sie können andere Knoten mit dem Knoten verbinden, den Sie konvertiert haben. Anschließend können Sie die Datensätze, die Sie verknüpft haben, zu einem einzigen Knoten kombinieren und die Knoten mit einem anderen Snowflake-Datensatz verbinden. Schließlich können Sie die ausgewählten Daten in Canvas importieren.
Gehen Sie wie folgt vor, um Daten von Snowflake nach Amazon SageMaker Canvas zu importieren.
Gehen Sie in der SageMaker Canvas-Anwendung zur Seite Datasets.
Wählen Sie Daten importieren und wählen Sie im Dropdownmenü die Option Tabellarisch aus.
-
Geben Sie einen Namen für den Datensatz ein und wählen Sie dann Erstellen.
Öffnen Sie für Datenquelle das Dropdown-Menü und wählen Sie Snowflake.
-
Wählen Sie Add connection (Verbindung hinzufügen).
-
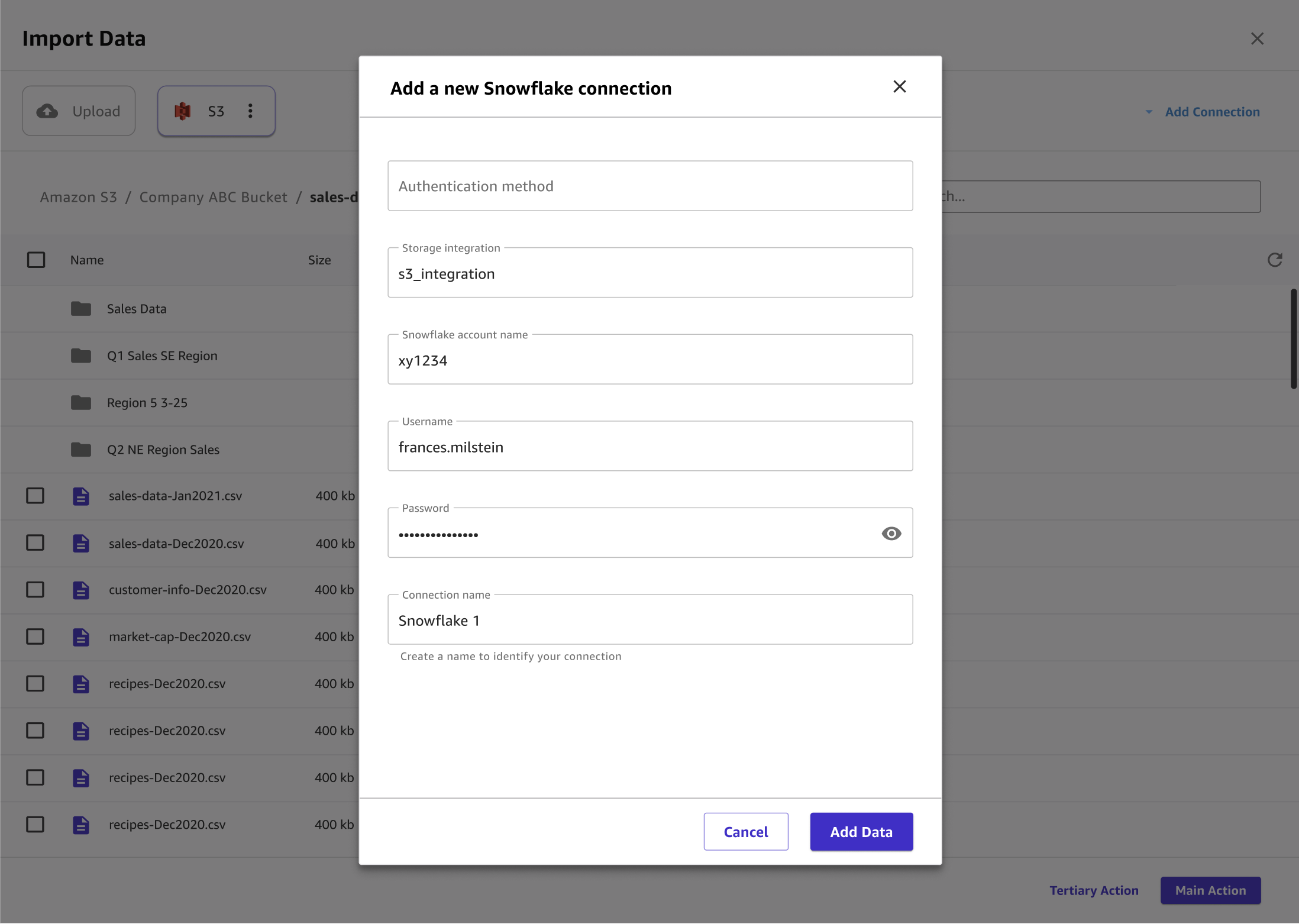
Geben Sie im Dialogfeld Neue Snowflake-Verbindung hinzufügen Ihre Snowflake-Anmeldeinformationen an. Wählen Sie für die Authentifizierungsmethode eine der folgenden Optionen:
Basic — Nutzername und Passwort — Geben Sie Ihre Snowflake-Konto-ID, Ihren Benutzernamen und Ihr Passwort ein.
-
ARN — Um den Schutz Ihrer Snowflake-Anmeldeinformationen zu verbessern, geben Sie den ARN eines AWS Secrets Manager Geheimnisses an, das Ihre Anmeldeinformationen enthält. Weitere Informationen finden Sie im AWS Secrets Manager Benutzerhandbuch unter Create an AWS Secrets Manager Secret.
In Ihrem Secret sollten Ihre Snowflake-Anmeldeinformationen im folgenden JSON-Format gespeichert sein:
{"accountid": "ID", "username": "username", "password": "password"} OAuth— OAuth ermöglicht die Authentifizierung ohne Angabe eines Passworts, erfordert jedoch eine zusätzliche Einrichtung. Weitere Informationen zum Einrichten von OAuth Anmeldeinformationen für Snowflake finden Sie unter. Richten Sie Verbindungen zu Datenquellen ein mit OAuth
-
Wählen Sie Add connection (Verbindung hinzufügen).
-
Ziehen Sie die CSV-Datei, die Sie importieren, von der Registerkarte mit dem Namen Ihrer Verbindung in den Bereich Drag-and-Drop-Tabelle zum Importieren.
-
Optional: Ziehen Sie weitere Tabellen in den Importbereich. Sie können die Benutzeroberfläche verwenden, um die Tabellen zu verbinden. Wenn Sie Ihre Verknüpfungen genauer gestalten möchten, wählen Sie In SQL bearbeiten aus.
-
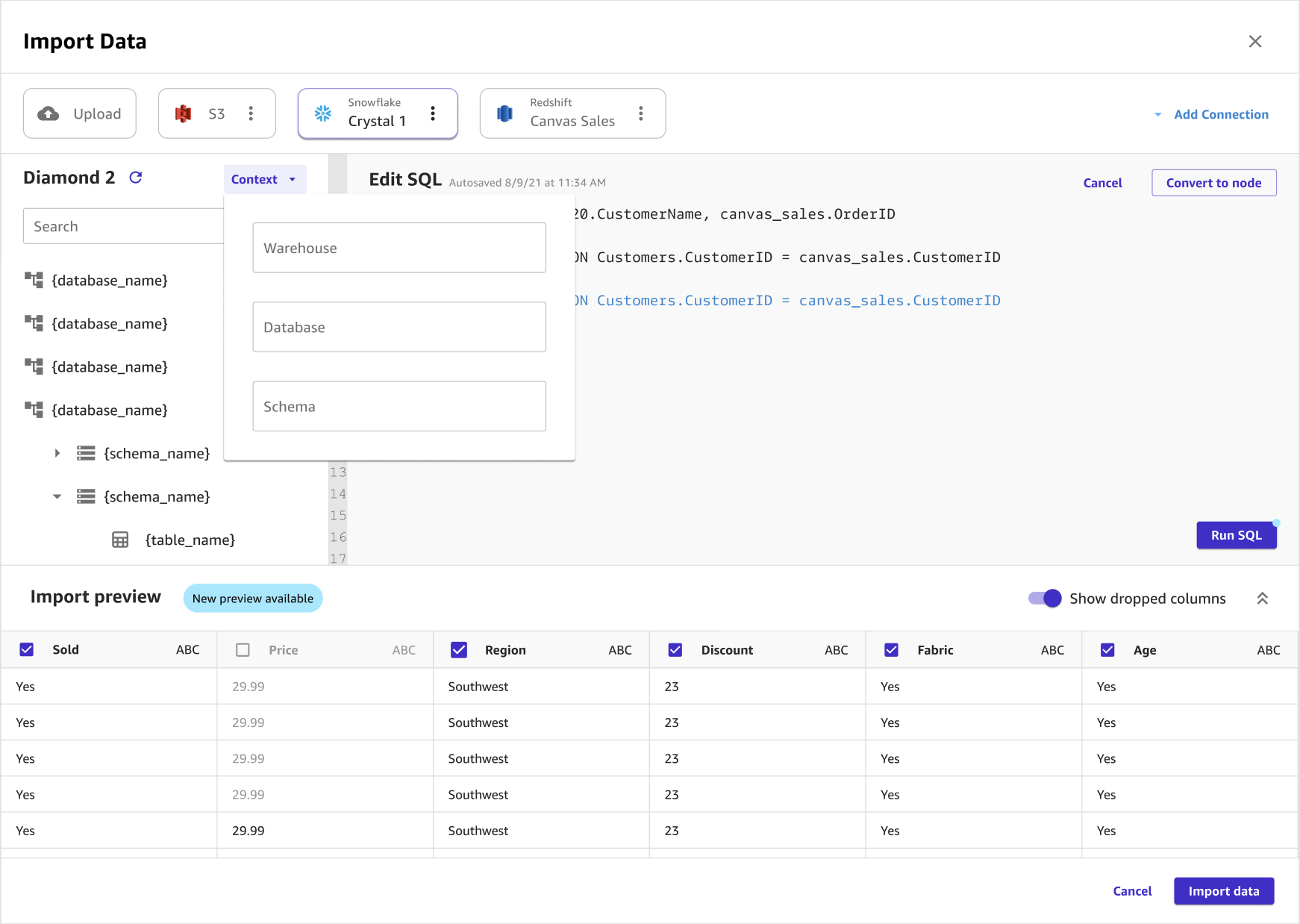
Optional: Wenn Sie SQL verwenden, um die Daten abzufragen, können Sie Kontext wählen, um der Verbindung Kontext hinzuzufügen, indem Sie Werte für Folgendes angeben:
-
Lager
-
Datenbank
-
Schema
Das Hinzufügen von Kontext zu einer Verbindung erleichtert die Spezifizierung zukünftlicher Abfragen.
-
-
Wählen Sie Daten importieren.
Die folgende Abbildung zeigt ein Beispiel für Felder, die für eine Snowflake-Verbindung angegeben wurden.
Die folgende Abbildung zeigt die Seite, die verwendet wird, um einer Verbindung Kontext hinzuzufügen.
Die folgende Abbildung zeigt die Seite, die zum Verbinden von Datensätzen in Snowflake verwendet wird.
Die folgende Abbildung zeigt eine SQL-Abfrage, die zum Bearbeiten einer Verknüpfung in Snowflake verwendet wird.
Verwenden Sie SaaS-Konnektoren mit Canvas
Anmerkung
Für SaaS-Plattformen außer Snowflake können Sie nur eine Verbindung pro Datenquelle haben.
Bevor Sie Daten von einer SaaS-Plattform importieren können, muss sich Ihr Administrator authentifizieren und eine Verbindung zur Datenquelle herstellen. Weitere Informationen darüber, wie Administratoren eine Verbindung mit einer SaaS-Plattform herstellen können, finden Sie unter AppFlow Amazon-Verbindungen verwalten im AppFlow Amazon-Benutzerhandbuch.
Wenn Sie ein Administrator sind, der AppFlow zum ersten Mal mit Amazon anfängt, finden Sie weitere Informationen unter Erste Schritte im AppFlow Amazon-Benutzerhandbuch.
Um Daten von einer SaaS-Plattform zu importieren, können Sie dem Importieren von Tabellendaten Standardverfahren folgen, das Ihnen zeigt, wie Sie tabellarische Datensätze in Canvas importieren.
