翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
因数分解機の仕組み
因数分解機モデルの予測タスクは、特徴セット xi からターゲットドメインに対する関数 ŷ を推定することです。このドメインは、回帰の場合は実数値であり、分類の場合は二項です。因数分解機モデルは教師ありモデルであるため、使用可能なトレーニングデータセット (xii,yj) があります。このモデルが示す利点は、ペアワイズ特徴相互作用をキャプチャするために因数分解パラメータ化を使用する方法にあります。これは数学的には次のように表すことができます。

この方程式の 3 つの項は、それぞれモデルの 3 つの要素に対応します。
-
w0 項は、グローバルバイアスを表します。
-
wi 線形項は、i 番目の変数の強度をモデル化したものです。
-
因数分解項 <vi,vj> は、i 番目と j 番目の変数間のペアワイズ相互作用をモデル化したものです。
グローバルバイアス項と線形項は線形モデルの場合と同じです。ペアワイズ特徴相互作用は、各特徴について学習された対応する係数の内積として第 3 項でモデル化されます。学習された係数は、各特徴の埋め込みベクトルと考えることもできます。たとえば、分類タスクでは、特徴のペアが正のラベルの付いたサンプルで同時に発生する傾向がある場合、それらの係数の内積は大きくなります。つまり、それらの埋め込みベクトルはコサイン類似度で相互に近くなります。因数分解機モデルの詳細については、「Factorization Machines」(因数分解機
回帰タスクの場合、モデル予測 ŷn とターゲット値 yn の間の二乗誤差を最小化することによってモデルをトレーニングします。これは二乗損失と呼ばれます。
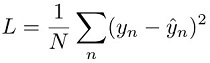
分類タスクの場合、対数損失とも呼ばれる交差エントロピー損失を最小化することによってモデルをトレーニングします。
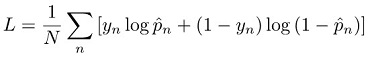
各パラメータの意味は次のとおりです。
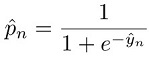
分類のための損失関数の詳細については、Loss functions for classification (分類のための損失関数)
